
Une introduction à l’utilisation de NLTK avec Python
Le traitement du langage naturel est un aspect de l'apprentissage automatique qui vous permet de traiter des mots écrits dans un langage convivial. Ces textes deviennent alors modifiables et vous pouvez exécuter des algorithmes de calcul dessus à votre guise.
La logique derrière cette technologie captivante semble complexe mais ne l'est pas. Et même maintenant, avec une solide maîtrise de la programmation Python de base, vous pouvez créer un nouveau traitement de texte DIY avec la boîte à outils du langage naturel (NLTK).
Voici comment démarrer avec NLTK de Python.
Qu'est-ce que NLTK et comment ça marche ?
Écrit avec Python, NLTK propose une variété de fonctionnalités de manipulation de chaînes. Il s'agit d'une bibliothèque polyvalente en langage naturel avec un vaste référentiel de modèles pour diverses applications en langage naturel.
Avec NLTK, vous pouvez traiter des textes bruts et en extraire des caractéristiques significatives. Il propose également des modèles d'analyse de texte, des grammaires basées sur des fonctionnalités et de riches ressources lexicales pour créer un modèle de langage complet.
Comment configurer NLTK
Tout d'abord, créez un dossier racine du projet n'importe où sur votre PC. Pour commencer à utiliser la bibliothèque NLTK, ouvrez votre terminal dans le dossier racine que vous avez créé précédemment et créez un environnement virtuel .
Ensuite, installez la boîte à outils du langage naturel dans cet environnement en utilisant pip :
pip install nltkNLTK, cependant, propose une variété d'ensembles de données qui servent de base à de nouveaux modèles de langage naturel. Pour y accéder, vous devez lancer le téléchargeur de données intégré NLTK.
Ainsi, une fois que vous avez installé NLTK avec succès, ouvrez votre fichier Python à l'aide de n'importe quel éditeur de code.
Importez ensuite le module nltk et instanciez le téléchargeur de données à l'aide du code suivant :
pip install nltk
nltk.download()L'exécution du code ci-dessus via le terminal fait apparaître une interface utilisateur graphique pour sélectionner et télécharger des packages de données. Ici, vous devrez choisir un package et cliquer sur le bouton Télécharger pour l'obtenir.
Tout paquet de données que vous téléchargez va dans le répertoire spécifié écrit dans le champ Répertoire de téléchargement . Vous pouvez changer cela si vous le souhaitez. Mais essayez de conserver l'emplacement par défaut à ce niveau.
Remarque : Les packages de données sont ajoutés aux variables système par défaut. Ainsi, vous pouvez continuer à les utiliser pour des projets ultérieurs, quel que soit l'environnement Python que vous utilisez.
Comment utiliser les tokeniseurs NLTK
En fin de compte, NLTK propose des modèles de tokenisation entraînés pour les mots et les phrases. En utilisant ces outils, vous pouvez générer une liste de mots à partir d'une phrase. Ou transformez un paragraphe en un tableau de phrases sensé.
Voici un exemple d'utilisation du NLTK word_tokenizer :
import nltk
from nltk.tokenize import word_tokenize
word = "This is an example text"
tokenWord = word_tokenizer(word)
print(tokenWord)
Output:
['This', 'is', 'an', 'example', 'text']NLTK utilise également un tokenizer de phrase pré-entraîné appelé PunktSentenceTokenizer . Cela fonctionne en fragmentant un paragraphe dans une liste de phrases.
Voyons comment cela fonctionne avec un paragraphe de deux phrases :
import nltk
from nltk.tokenize import word_tokenize, PunktSentenceTokenizer
sentence = "This is an example text. This is a tutorial for NLTK"
token = PunktSentenceTokenizer()
tokenized_sentence = token.tokenize(sentence)
print(tokenized_sentence)
Output:
['This is an example text.', 'This is a tutorial for NLTK']
Vous pouvez encore segmenter chaque phrase du tableau généré à partir du code ci-dessus en utilisant word_tokenizer et Python for loop .
Exemples d'utilisation de NLTK
Ainsi, bien que nous ne puissions pas démontrer tous les cas d'utilisation possibles de NLTK, voici quelques exemples de la façon dont vous pouvez commencer à l'utiliser pour résoudre des problèmes réels.
Obtenez des définitions de mots et leurs parties du discours
NLTK propose des modèles pour déterminer les parties du discours, obtenir une sémantique détaillée et une éventuelle utilisation contextuelle de divers mots.
Vous pouvez utiliser le modèle wordnet pour générer des variables pour un texte. Déterminez ensuite sa signification et sa partie du discours.
Par exemple, vérifions les variables possibles pour "Monkey :"
import nltk
from nltk.corpus import wordnet as wn
print(wn.synsets('monkey'))
Output:
[Synset('monkey.n.01'), Synset('imp.n.02'), Synset('tamper.v.01'), Synset('putter.v.02')]
Le code ci-dessus génère des alternatives de mots ou des syntaxes et des parties du discours possibles pour "Singe".
Vérifiez maintenant la signification de "Singe" en utilisant la méthode de définition :
Monkey = wn.synset('monkey.n.01').definition()
Output:
any of various long-tailed primates (excluding the prosimians)Vous pouvez remplacer la chaîne entre parenthèses par d'autres alternatives générées pour voir ce que NLTK génère.
Le modèle pos_tag , cependant, détermine les parties du discours d'un mot. Vous pouvez l'utiliser avec word_tokenizer ou PunktSentenceTokenizer() si vous traitez des paragraphes plus longs.
Voici comment cela fonctionne :
import nltk
from nltk.tokenize import word_tokenize, PunktSentenceTokenizer
word = "This is an example text. This is a tutorial on NLTK"
token = PunktSentenceTokenizer()
tokenized_sentence = token.tokenize(word)
for i in tokenized_sentence:
tokenWordArray = word_tokenize(i)
partsOfSpeech = nltk.pos_tag(tokenWordArray)
print(partsOfSpeech)
Output:
[('This', 'DT'), ('is', 'VBZ'), ('an', 'DT'), ('example', 'NN'), ('text', 'NN'), ('.', '.')]
[('This', 'DT'), ('is', 'VBZ'), ('a', 'DT'), ('tutorial', 'JJ'), ('on', 'IN'), ('NLTK', 'NNP')]Le code ci-dessus associe chaque mot tokenisé à son étiquette vocale dans un tuple. Vous pouvez vérifier la signification de ces balises sur Penn Treebank .
Pour un résultat plus net, vous pouvez supprimer les points de la sortie à l'aide de la méthode replace() :
for i in tokenized_sentence:
tokenWordArray = word_tokenize(i.replace('.', ''))
partsOfSpeech = nltk.pos_tag(tokenWordArray)
print(partsOfSpeech)
Cleaner output:
[('This', 'DT'), ('is', 'VBZ'), ('an', 'DT'), ('example', 'NN'), ('text', 'NN')]
[('This', 'DT'), ('is', 'VBZ'), ('a', 'DT'), ('tutorial', 'JJ'), ('on', 'IN'), ('NLTK', 'NNP')]Visualisation des tendances des caractéristiques à l'aide du tracé NLTK
L'extraction de caractéristiques à partir de textes bruts est souvent fastidieuse et chronophage. Mais vous pouvez afficher les déterminants de caractéristiques les plus puissants dans un texte à l'aide du tracé de tendance de distribution de fréquence NLTK.
NLTK, cependant, se synchronise avec matplotlib. Vous pouvez en tirer parti pour afficher une tendance spécifique dans vos données.
Le code ci-dessous, par exemple, compare un ensemble de mots positifs et négatifs sur un diagramme de distribution en utilisant leurs deux derniers alphabets :
import nltk
from nltk import ConditionalFreqDist
Lists of negative and positive words:
negatives = [
'abnormal', 'abolish', 'abominable',
'abominably', 'abominate','abomination'
]
positives = [
'abound', 'abounds', 'abundance',
'abundant', 'accessable', 'accessible'
]
# Divide the items in each array into labeled tupple pairs
# and combine both arrays:
pos_negData = ([("negative", neg) for neg in negatives]+[("positive", pos) for pos in positives])
# Extract the last two alphabets from from the resulting array:
f = ((pos, i[-2:],) for (pos, i) in pos_negData)
# Create a distribution plot of these alphabets
cfd = ConditionalFreqDist(f)
cfd.plot()Le diagramme de distribution de l'alphabet ressemble à ceci :
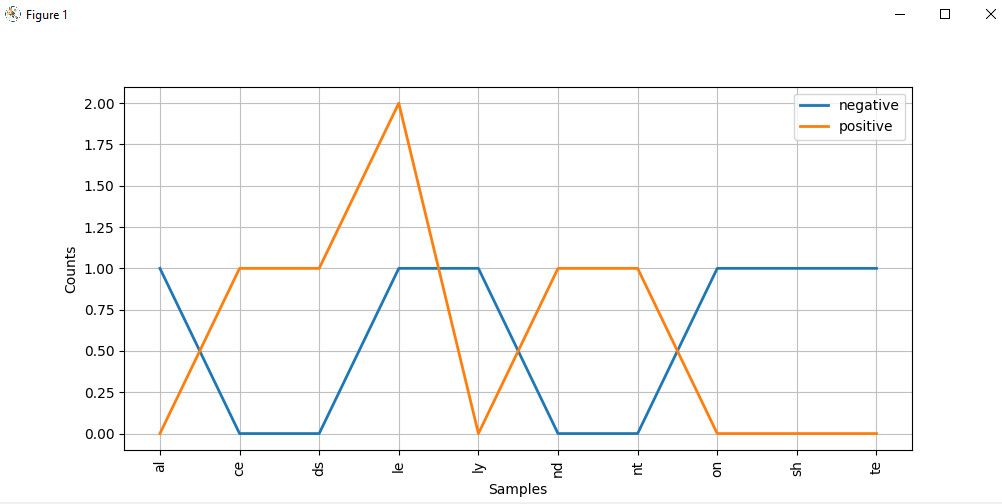
En regardant de près le graphique, les mots se terminant par ce , ds , le , nd et nt ont une plus grande probabilité d'être des textes positifs. Mais ceux qui se terminent par al , ly , on , et te sont plus probablement des mots négatifs.
Remarque : Bien que nous ayons utilisé des données autogénérées ici, vous pouvez accéder à certains des ensembles de données intégrés de NLTK à l'aide de son lecteur Corpus en les appelant à partir de la classe corpus de nltk . Vous voudrez peut-être consulter la documentation du paquet de corpus pour voir comment vous pouvez l'utiliser.
Continuez à explorer la boîte à outils de traitement du langage naturel
Avec l'émergence de technologies comme Alexa, la détection de spam, les chatbots, l'analyse des sentiments, etc., le traitement du langage naturel semble évoluer vers sa phase sous-humaine. Bien que nous n'ayons pris en compte que quelques exemples de ce que propose NLTK dans cet article, l'outil a des applications plus avancées que la portée de ce didacticiel.
Après avoir lu cet article, vous devriez avoir une bonne idée de la façon d'utiliser NLTK à un niveau de base. Il ne vous reste plus qu'à mettre ces connaissances en pratique vous-même !