
Grâce à cela, Musk et l’armée de terre cuite ont dansé « Sujet Trois »

Une seule photo peut faire danser Musk, Messi et d'autres célébrités comme par magie, et même le sujet trois, populaire sur Internet, peut être organisé.
Il ne s'agit pas d'une technologie d'IA avancée. La nouvelle fonction "National Dance King" d'Alibaba Tongyi Qianwen sur le terminal mobile peut le réaliser. Il existe également 12 modèles de danse populaires tels que le sujet trois, le rock lent du DJ, la danse fantôme et la danse du bonheur. … Vous faites votre choix.
Entrez les mots de passe tels que "National Dance King" et "Tongyi Dance King" dans Tongyi Qianwen, puis sélectionnez votre danse préférée dans l'interface de saut et téléchargez une photo de tout le corps. Cela ne prend que dix minutes pour créer une danse à la fois physique et spirituel. Le roi était si magnifiquement "rapidement accompli".
De manière inattendue, Einstein, avec ses sourcils épais et ses grands yeux, pourrait se transformer en un homme branché en un instant, et le rythme de ses mouvements n'est pas trop fort.

▲ Photo de : Simon_Awen
Il n'y a qu'une seule photo entre les Guerriers en Terre Cuite et le Roi de la Danse, et cette posture ne peut être éclipsée.

Le roi de la danse dans le monde des figurines domine, comment peuvent-ils m'ignorer, Nicholas Zhao Si, le « roi de la danse asiatique » ?

▲ Photo de : Gongfu Finance
Les petits personnages que j'ai dessinés dansaient tous plus joyeusement que moi, on dirait que je dois m'inscrire à un cours de danse.

▲ Photo de : Frère Dao Hu Kan
Crayon Shin-chan "se gratte la tête et prend des poses", et son enfance revient en un instant.

▲ Photo de : Chien Panhua
La magie de l'IA qui rend les photos « vivantes »
Alors, comment l’équipe de recherche en IA d’Alibaba a-t-elle fait bouger les photos ?
La sortie de la fonction Tongyi Dance King est en fait une application et une implémentation spécifique de la technologie AnimateAnyone.
Selon un article publié par l'équipe de recherche d'Alibaba AI, les modèles de diffusion sont actuellement dominants dans le domaine de la recherche sur la génération visuelle. Cependant, dans le domaine de la génération d'images en vidéo, il existe encore des problèmes tels que la distorsion locale, les détails flous. et la gigue de la fréquence d'images.
À cet égard, l'équipe de recherche en IA d'Alibaba a proposé un nouvel algorithme d'IA Animate Anybody basé sur le modèle de diffusion. La fonction de cet algorithme est de convertir une image de personnage statique en une vidéo animée, et en même temps, les mouvements des personnages dans la vidéo peuvent être contrôlés avec précision en saisissant la séquence de postures.

▲Affichage du principe du flip book. Photo de : @flipping book Andymation
Il est à noter que dans la production vidéo, notamment d'animation, les mouvements des personnages s'effectuent par des transitions image par image. Le principe est similaire au flip-book avec lequel je jouais souvent quand j'étais enfant. Chaque page est un brouillon statique dessiné à la main, qui peut être rapidement retourné.Faites bouger l'écran grâce au bug de « persistance de la vision » de l'œil humain.
La plus grande difficulté pour faire bouger une image est d'« imaginer » les actions et les scènes suivantes, et il n'y a aucune référence avant ou après. Par conséquent, dans l'affichage comparatif officiel, vous pouvez voir que la technologie traditionnelle "DisCO" a été utilisée à plusieurs reprises comme matériel pédagogique négatif. Son effet de distorsion sévère ne peut que faire bouger le sujet, mais la forme tordue du corps et les effets de mouvement étranges ne le sont pas. digne d'être appelé du tout au travail.

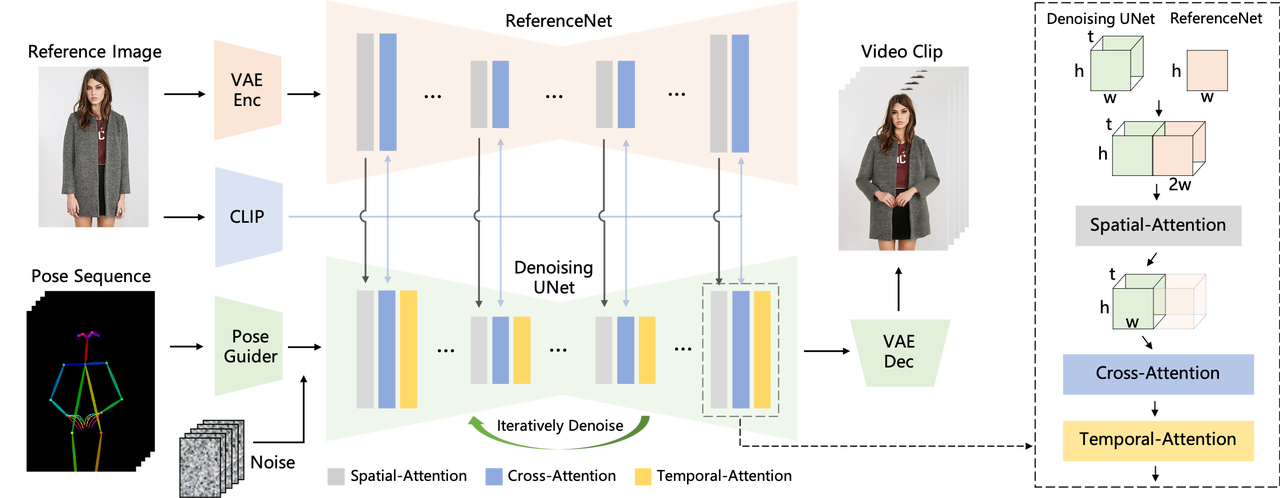
Par conséquent, afin de résoudre le problème de cohérence de l’image des caractères vidéo, ils ont introduit le réseau d’images de référence ReferenceNet, qui peut capturer les informations de détails spatiaux dans l’image de référence.
Ensuite, ils ont combiné ReferenceNet avec UNet, permettant à UNet de comprendre où et quels détails doivent être générés lors de la génération de l'image cible, afin que l'image générée puisse supprimer le bruit dans son ensemble tout en conservant les détails clés dans l'image de référence. .
En plus de capturer les détails, la contrôlabilité de la posture doit également être assurée. À cette fin, l'équipe Alibaba AI a également conçu un guide de pose léger, Pose Guider, qui intègre des signaux de contrôle de pose pendant le processus de débruitage pour garantir que la séquence d'animation générée est conforme à la pose spécifiée.
Compte tenu de la stabilité de la vidéo, ils ont également introduit un module de génération de synchronisation pour permettre au modèle d'apprendre la connexion entre les images, de sorte que la vidéo générée soit fluide et cohérente au lieu d'être fragmentée, tout en conservant une haute résolution et en améliorant la qualité de l'image. et plus stable.
Par rapport aux méthodes précédentes, cette méthode permet de maintenir efficacement la cohérence de l'apparence des personnages vidéo, sans problèmes tels que le changement de couleur des vêtements. En même temps, la vidéo est fluide et claire, sans scintillement ni instabilité, et elle également prend en charge l'animation dynamique de n'importe quel personnage.
Par exemple, Messi joue avec le style haut de gamme apprécié des personnes d'âge moyen et âgées et lève la main pour vous dire bonjour.
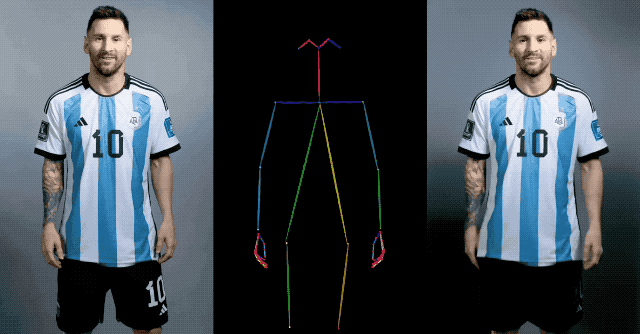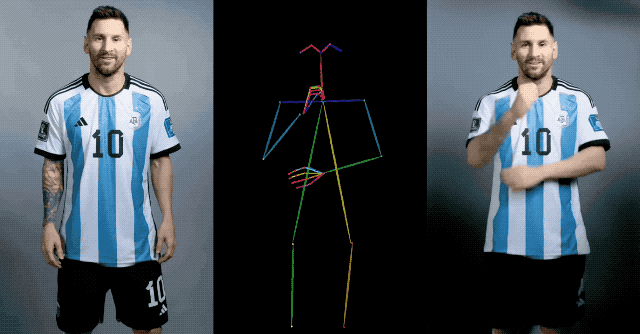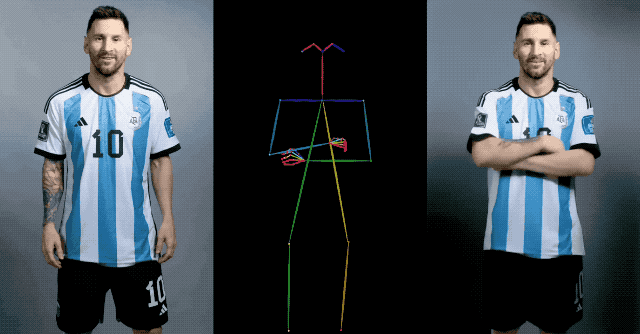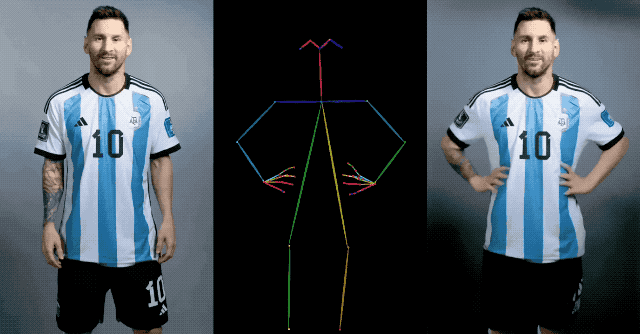
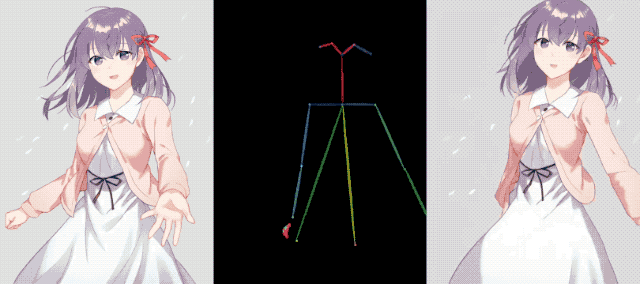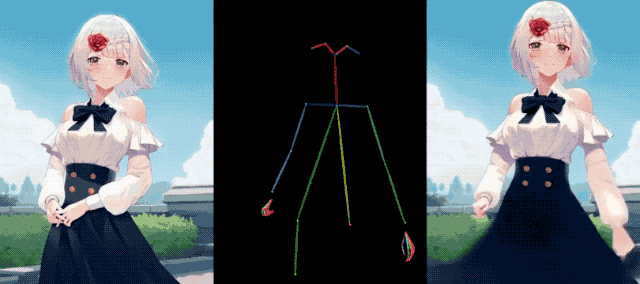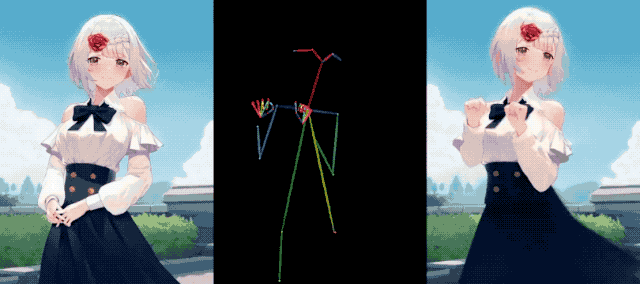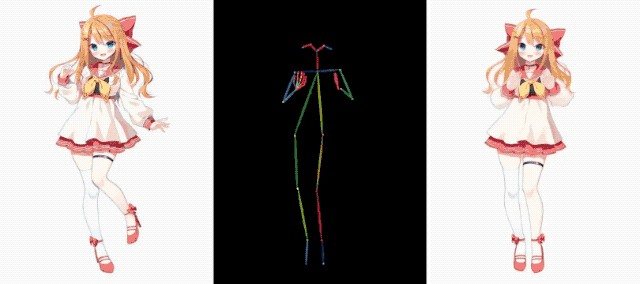
Les personnages en deux dimensions se déplacent dans un état immobile et lorsqu'ils dansent des danses house, ils ne sont pas moins impressionnants que de vraies personnes.
Même Iron Man s'est joint à la fête, gardant la forme et étirant ses muscles, et il n'y avait rien de mal à cela.
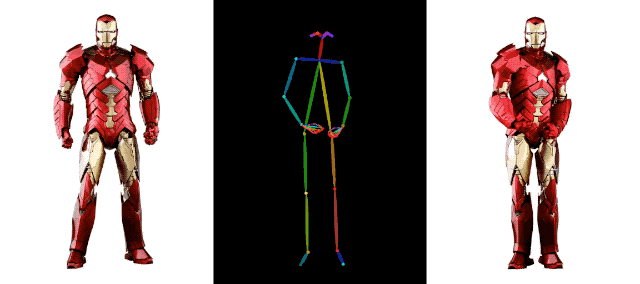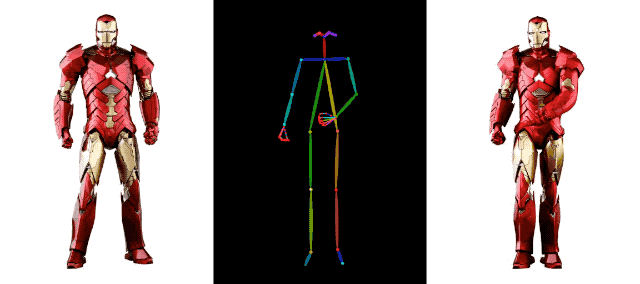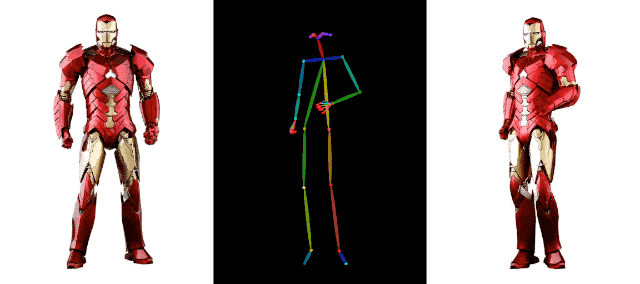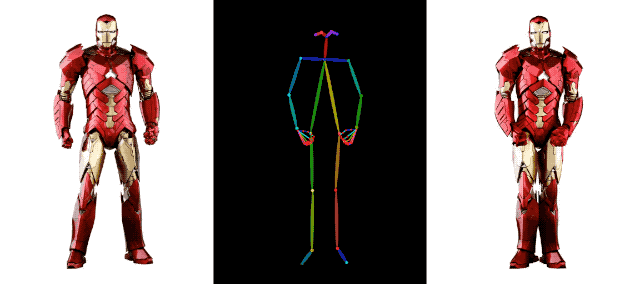
Dans le domaine de la génération de vidéos IA, l'accumulation de technologies derrière Alibaba va au-delà. Par exemple, le mois dernier, Alibaba a également lancé une autre technologie de génération de vidéos, DreaMoving. Il s'agit d'un cadre de génération vidéo contrôlable basé sur la diffusion pour générer des vidéos de portrait personnalisées de haute qualité.
L'avantage de cette technologie est qu'elle ne nécessite pas de connaissances approfondies de techniques de production vidéo complexes : il suffit de donner à l'utilisateur quelques conseils, comme un morceau de texte ou une image de référence, et DreaMoving peut créer des vidéos très réalistes.
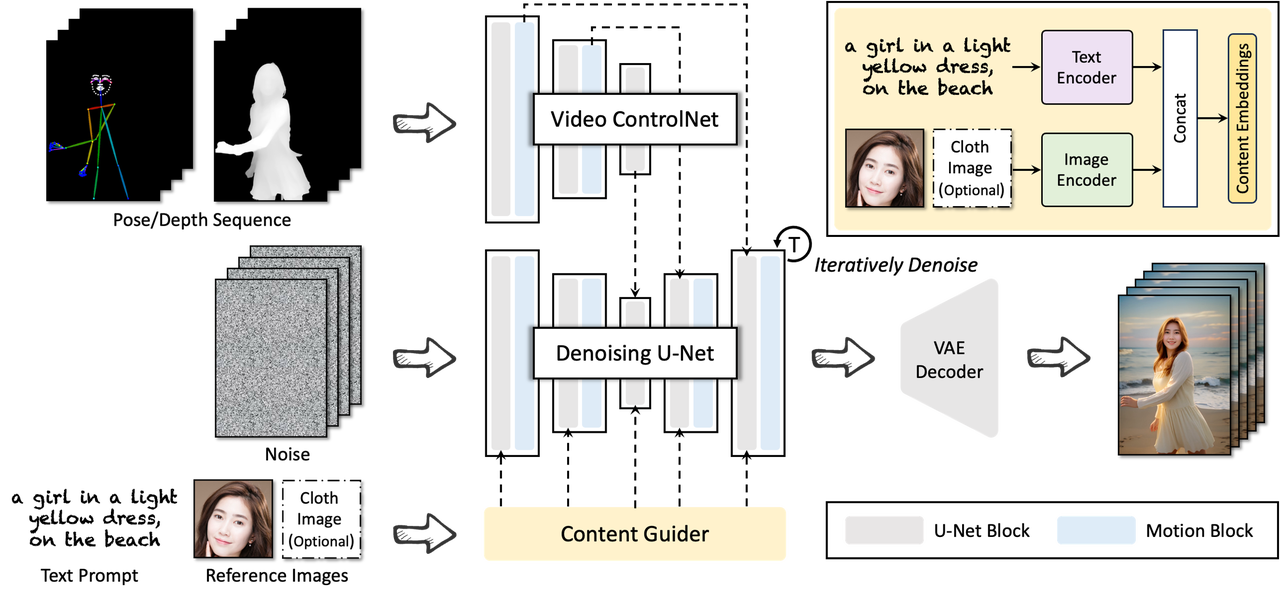
En d'autres termes, tant que l'identité de la cible et la séquence de poses sont données, DreaMoving peut générer une vidéo de n'importe quelle personne/objet dansant n'importe où en fonction de la séquence de poses.
Pour faire simple, DreaMoving peut générer automatiquement diverses vidéos de personnages personnalisées via des entrées simples, telles que des images de visage, des séquences d'action et du texte, obtenant ainsi un contrôle précis sur la génération vidéo.
Étapes de démontage spécifiques : saisissez d'abord l'image du visage d'une personne pour générer l'image de tout le corps de la personne dans la vidéo, puis saisissez la séquence de postures pour contrôler avec précision les mouvements du personnage dans la vidéo, et enfin saisissez du texte pour contrôler de manière plus complète la génération vidéo. effets.
Par exemple, une fille souriante, debout sur la plage au bord de la mer, vêtue d’une robe jaune clair à manches longues.

Un homme danse devant la Pyramide d’Egypte, vêtu d’un costume et d’une cravate bleue.

Une fille vêtue d'une robe bleu clair souriant et dansant dans une ville française

L'industrie de la génération vidéo IA devient folle
En fait, dans le domaine de l’IA générative, le point de départ du domaine de la génération vidéo IA n’est pas trop tard : avant la naissance de ChatGPT, de nombreux fabricants avaient déjà parié sur cette piste, comme Microsoft et Google. des outils ont été utilisés, mais l’effet est minime.
Sur la base de l'accumulation technologique à long terme de l'ensemble de l'industrie, l'émergence du modèle de diffusion permet aux fabricants de voir les perspectives potentielles de la génération de vidéos IA. Il présente des avantages évidents par rapport aux premiers modèles tels que le RNN : il peut générer des images ou des séquences vidéo plus cohérentes et plus claires, accélérant ainsi le processus itératif de génération vidéo.
Les outils grand public sur le marché ont également apporté d'importants ajouts sur cette base, faisant à nouveau des vagues dans la piste de génération de vidéos IA et montrant véritablement une tendance explosive étonnante.

À la fin de l'année dernière, Runway Gen-2 a reçu une mise à jour majeure, avec une résolution augmentée à 4K et une avancée majeure dans la fidélité et la cohérence des effets de génération vidéo. Une semaine plus tard, la fonction motion brush a été à nouveau lancée. Avec un seul pinceau, vous pouvez faire bouger les objets statiques.
Immédiatement après, Stability AI, « l'épine dorsale » de Wenshengtu, a également lancé Stable Video Diffusion, ajoutant un autre essor au domaine de la génération vidéo IA.
Pika 1.0, en revanche, a gagné les faveurs de nombreux patrons de la Silicon Valley depuis ses débuts en raison de sa génération vidéo plus simple, de son montage vidéo partiel facile à comprendre et de sa génération vidéo de meilleure qualité. De la génération à la post-production, vous pouvez réaliser vous-même une opération à guichet unique.

Le modèle WALT lancé par l'équipe de Li Feifei en coopération avec Google peut également générer des vidéos ou des animations 2D/3D réalistes basées sur des invites en langage naturel/image, et l'effet de génération est comparable à celui de Runway, Pika et d'autres experts.

Ces outils de génération vidéo IA ont fait de grands progrès principalement dans deux dimensions : la qualité et la quantité. En termes de qualité, ces produits d'IA continuent d'introduire des architectures de modèles plus puissantes et d'utiliser des données à plus grande échelle et de meilleure qualité pour la formation, de sorte que la qualité de l'image, la fluidité et la fidélité des vidéos générées par l'IA continuent de s'améliorer.
En termes de quantité, la durée des vidéos générées est également en constante évolution, atteignant une durée à deux chiffres en secondes, et la combinaison de scènes et d'événements devient de plus en plus riche. À l’avenir, grâce à de nouvelles améliorations de la puissance de calcul, il sera possible de générer des vidéos de haute qualité pouvant durer plusieurs heures.
La technologie flottant sur le cloud sera finalement appliquée sur le terrain, et la montée en puissance de la génération de vidéos IA créera un immense marché océan bleu. S'appuyant sur la profonde accumulation de technologie, le « National Dance King » de Tongyi Qianwen est un autre produit basé sur cette logique commerciale.
Cela ouvrira non seulement la concurrence avec Alibaba et d'autres entreprises et accélérera les progrès de l'ensemble du secteur, mais nous donnera également l'opportunité de découvrir davantage les possibilités offertes par la technologie de génération vidéo IA.
# Bienvenue pour suivre le compte public officiel WeChat d'aifaner : aifaner (ID WeChat : ifanr). Un contenu plus passionnant vous sera fourni dès que possible.
Ai Faner | Lien original · Voir les commentaires · Sina Weibo