
Wall-facing Intelligence a finalisé une nouvelle ronde de financement de centaines de millions de yuans et a publié la deuxième version de MiniCPM, un petit canon en acier haute performance

L’histoire inspirante de faire une grande différence à partir d’une petite chose ne se produit pas seulement dans l’histoire de l’entrepreneuriat, mais se produit également dans des modèles de bout en bout à grande échelle.
En février de cette année, Wall-facing Intelligence a officiellement lancé le modèle phare 2B à grande échelle Wall-facing MiniCPM, qui a non seulement dépassé la référence de performance de la « version européenne d'OpenAI », mais était également globalement en avance sur Google Gemma. Niveau 2B, et a même dépassé les modèles de niveau 7B et 13B, tels que Llama2-13B, etc.
Récemment, Wall-Facing Intelligence a également finalisé un nouveau cycle de financement de plusieurs centaines de millions de yuans, dirigé par Primavera Ventures et Huawei Hubble, suivi par le Fonds d'investissement pour l'industrie de l'intelligence artificielle de Pékin et d'autres. Zhihu, en tant qu'actionnaire stratégique, continue de investir et soutenir, et s'engage à accélérer les investissements.Promouvoir une formation efficace des grands modèles et une mise en œuvre rapide des applications.

Aujourd'hui, le petit canon en acier MiniCPM, grand modèle côte à côte, poursuit la victoire et a inauguré la deuxième série à quatre coups, dont le thème principal est « petit mais fort, petit mais complet ».
Parmi eux, le modèle multimodal MiniCPM-V2.0 a considérablement amélioré ses capacités OCR et actualisé les meilleures performances OCR des modèles open source. Le texte de la scène générale est comparable à Gemini-Pro et surpasse toute la série de modèles 13B.
Dans la liste Object HalBench qui évalue les illusions de grands modèles, MiniCPM-V2.0 et GPT-4V fonctionnent presque de la même manière.
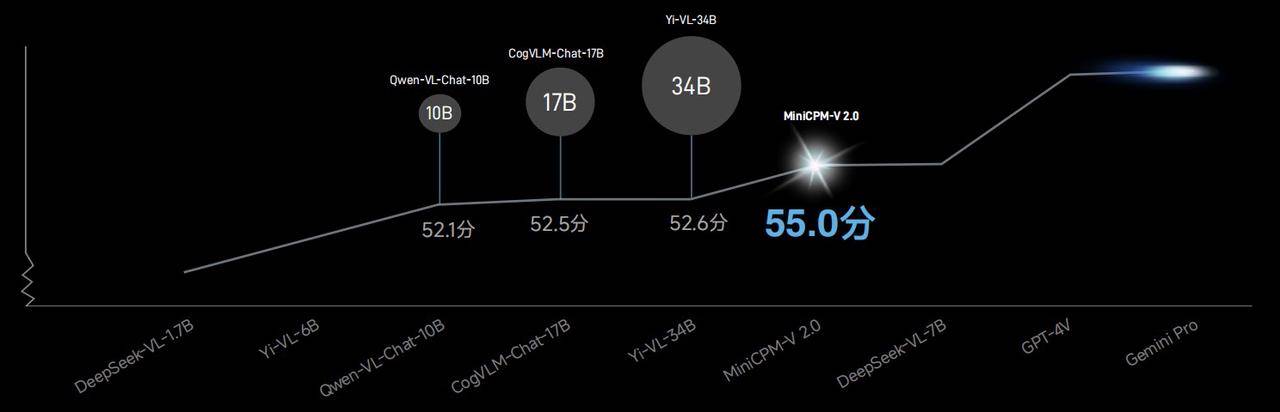
Dans la liste OpenCompass qui combine 11 critères d'évaluation traditionnels, la capacité générale du modèle multimodal MiniCPM-V2.0 dépasse Qwen-VL-Chat-10B, CogVLM-Chat-17B, Yi-VL-34B, etc. avec un score de 55,0. Un modèle plus grand.
Dans le cas de démonstration officielle, lorsqu'on lui a demandé de décrire en détail la scène de la même image, GPT-4V a répondu avec 6 hallucinations, tandis que MiniCPM-V2.0 n'avait que 3 hallucinations.

En outre, MiniCPM-V2.0 a également lancé une coopération approfondie avec l'Université Tsinghua pour explorer conjointement le trésor du musée de l'Université Tsinghua – Tsinghua Slips.
Grâce à ses puissantes capacités de reconnaissance multimodale et de raisonnement, MiniCPM-V2.0 peut facilement gérer qu'il s'agisse de la reconnaissance du mot simple « ke » ou du mot complexe « I ».
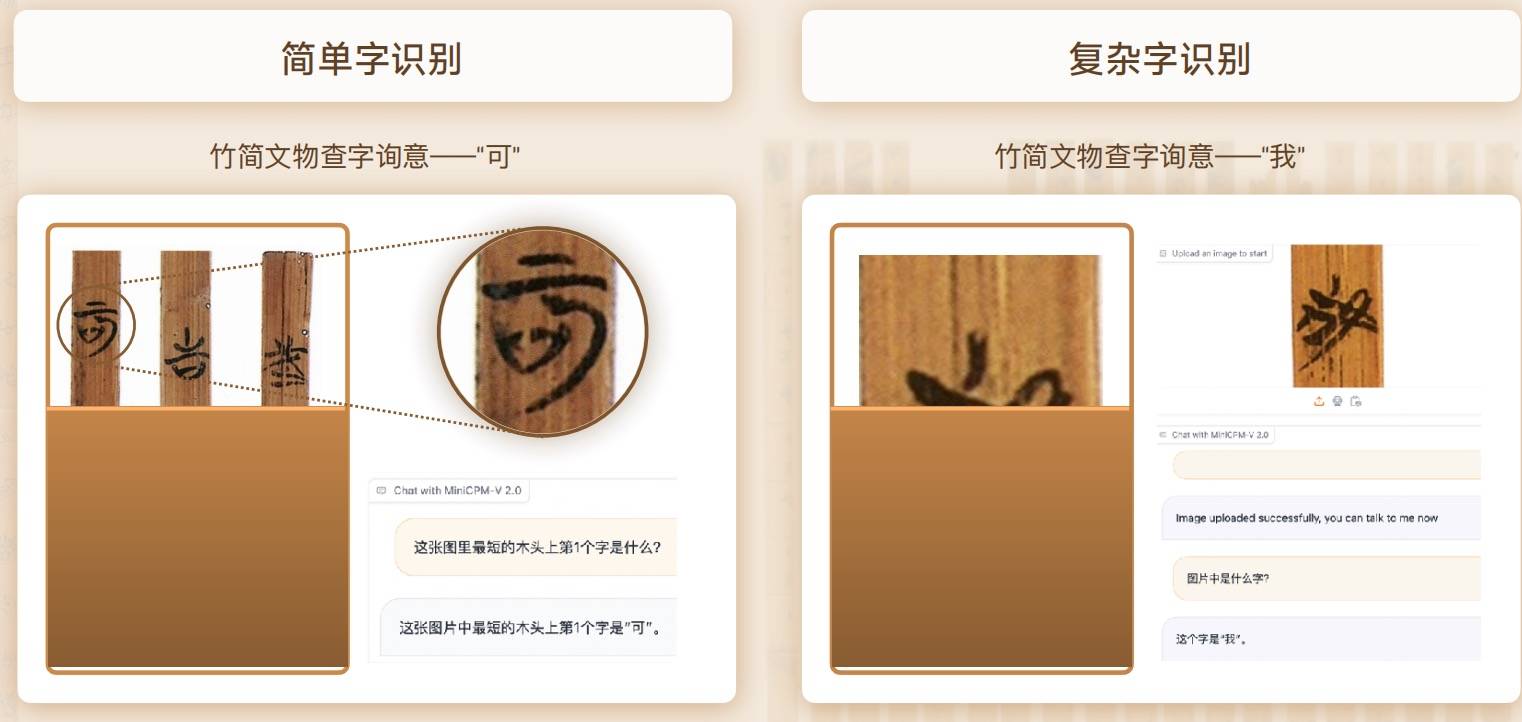
Dans la concurrence avec les grands modèles multimodaux de référence chinois similaires, la précision de reconnaissance du MiniCPM-V2.0 est loin devant.
La reconnaissance de détails précis impose des exigences plus élevées en matière de clarté des images, et les grands modèles traditionnels ne peuvent généralement gérer que de petites images de 448 × 448 pixels. Une fois les informations compressées, le modèle devient difficile à lire.
Mais ce n'est pas un problème pour le MiniCPM-V2.0. Dans le cas de la démonstration officielle, face à une image de scène de rue urbaine ordinaire, le MiniCPM-V2.0 peut capturer des informations clés d'un seul coup d'œil, même sans que l'œil nu ne les détecte. Family Mart" peut également être capturé facilement.

Les images longues contiennent des informations textuelles riches et les modèles multimodaux sont souvent incapables de reconnaître les images longues, mais MiniCPM-V 2.0 peut saisir fermement les informations clés des images longues.

De 448 × 448 pixels à 1,8 million de grandes images haute définition, et même le rapport hauteur/largeur ultime de 1:9 (448 * 4032), MiniCPM-V 2.0 peut obtenir une reconnaissance sans perte.
Il est entendu que la technologie exclusive LLaVA-UHD est en réalité utilisée derrière l'encodage efficace des images haute définition MiniCPM-V 2.0.
- Encodage visuel modulaire : l'image de résolution originale est divisée en tranches de taille variable, permettant une adaptabilité totale à la résolution originale sans remplissage de pixels ni distorsion de l'image.
- Module de compression visuelle : utilise une couche de rééchantillonnage de perceptron partagée pour compresser les jetons visuels des tranches d'image. Le nombre de jetons est abordable quelle que soit la résolution et la complexité de calcul est moindre.
- Méthode de modification spatiale : utilisez des modèles simples de symboles en langage naturel pour informer efficacement les positions relatives des tranches d'image.

En termes de capacités OCR chinoises, MiniCPM-V 2.0 surpasse également largement GPT-4V. Comparée à « l’impuissance » du GPT-4V, sa capacité à identifier avec précision les images est encore plus précieuse.
Derrière cette capacité se cache la prise en charge d'une technologie de généralisation multimodale et multilingue, qui peut résoudre le défi du manque de données multimodales à grande échelle et de haute qualité dans le domaine chinois.
La capacité à traiter des textes longs a toujours été un critère important pour mesurer les modèles.
Bien que la capacité de texte de 128 Ko ne soit pas nouvelle, pour le MiniCPM-2B-128K, qui ne fait que 2B, c'est certainement quelque chose qui mérite des éloges.
Le plus petit modèle de texte long de 128 Ko, le modèle de texte long MiniCPM-2B-128K, étend la fenêtre contextuelle 4K d'origine à 128 Ko, dépassant un certain nombre de modèles 7B tels que Yarn-Mistral-7B-128K sur la liste InfiniteBench.

En introduisant l'architecture MoE, les performances du nouveau MiniCPM-MoE-8x2B MoE se sont améliorées en moyenne de 4,5 %, dépassant toute la série de modèles 7B et les modèles plus grands tels que le LlaMA234B, tandis que le coût d'inférence n'est que de 69,7 % de celui de Gemma- 7B.
MiniCPM-1.2B prouve que « petit » et « puissant » ne s’excluent pas mutuellement.
Bien que les paramètres directs aient été réduits de moitié, le MiniCPM-1.2B conserve toujours 87 % des performances globales du modèle 2.4B de la génération précédente. Sur plusieurs listes de tests publics faisant autorité, le modèle 1.2B est très performant et ses performances globales dépassent Qwen 1.8B et Qwen 1.8B Excellents résultats avec Llama 2-7B et même Llama 2-13B.
Démonstration d'enregistrement d'écran du modèle MiniCPM-1.2B sur un téléphone mobile iPhone 15, la vitesse d'inférence est augmentée de 38 %. Il a atteint 25 jetons/s par seconde, soit 15 à 25 fois plus rapide que la vitesse de parole humaine. Dans le même temps, la mémoire est réduite de 51,9 %, le coût est réduit de 60 % et le modèle de mise en œuvre est plus petit. mais les scénarios d'utilisation sont considérablement augmentés.
Dans la recherche de modèles à grands paramètres, Face Wall Intelligence a choisi une voie technique unique : développer autant que possible des modèles de plus petite taille et de performances plus élevées.
Les performances exceptionnelles du petit canon en acier MiniCPM mural prouvent pleinement que « petit » et « fort », « petit » et « plein » ne sont pas des attributs mutuellement exclusifs, mais peuvent coexister harmonieusement. Nous attendons également avec impatience l’apparition d’autres modèles de ce type à l’avenir.
# Bienvenue pour suivre le compte public officiel WeChat d'aifaner : aifaner (ID WeChat : ifanr). Un contenu plus passionnant vous sera fourni dès que possible.
Ai Faner | Lien original · Voir les commentaires · Sina Weibo