
L’équipe de Stanford a plagié un grand modèle de l’Université Tsinghua. L’auteur s’est excusé tard dans la nuit. Le grand modèle chinois ne peut plus être ignoré.
Il y a quelque temps, l'Institut d'intelligence artificielle de l'Université de Stanford (Stanford HAI) a publié un rapport affirmant que les États-Unis sont loin en avance dans le domaine des grands modèles. Le rapport souligne que 61 modèles d’intelligence artificielle bien connus en 2023 provenaient d’institutions américaines, dépassant de loin les 21 de l’UE et les 15 de la Chine.
Vinod Khosla, l'un des premiers investisseurs dans OpenAI, a également publié l'année dernière un article sur X affirmant que les modèles open source américains seraient copiés par la Chine.
Cependant, le grand modèle national qui a toujours été considéré comme « rattrapant les États-Unis » est désormais devenu la cible du plagiat, et l'équipe d'IA plagiée appartient à l'Université de Stanford, qui a publié le rapport ci-dessus.

Le modèle open source Llama3-V dirigé par l'équipe d'IA de Stanford a été soupçonné d'avoir plagié le modèle open source national "Little Steel Cannon" MiniCPM-Llama3-V 2.5 de l'Université Tsinghua et Wall-Facing Intelligence, ce qui a immédiatement fait sensation. dans le cercle de l'IA.
Sous le véritable marteau, l’équipe de Stanford a également dû s’excuser d’urgence.
Comme l'a répondu en plaisantant Li Dahai, PDG de Wall-Facing Intelligence, il s'agit d'une « méthode reconnue par l'équipe internationale ». Peu importe à quel point nous sommes loin des grands modèles de premier plan, les grands modèles nationaux ont atteint un stade où ils ne peuvent plus être ignorés.
Résumons brièvement la chronologie :
- L'équipe d'IA de Stanford lance Llama3-V, connu sous le nom de grand modèle multimodal SOTA
- Les internautes se sont demandé si le modèle copiait le MiniCPM-Llama3-V2.5 intelligent domestique face au mur.
- Des preuves remettant en question sont apparues, l'auteur de Llama3-V a mis en scène "la suppression de la base de données et la fuite"
- Face au plagiat officiel de Wall Intelligence, a publié une déclaration tard dans la nuit
- L'auteur de Llama3-V s'excuse officiellement, les internautes ont des opinions différentes
Plagiant le "Small Steel Cannon" intelligent face au mur, l'équipe d'IA de Stanford a mis en scène "Supprimez la base de données et fuyez"
Récemment, une équipe d'IA de Stanford a annoncé qu'il ne coûtait que 500 $ pour former un grand modèle multimodal SOTA qui surpasse le GPT-4V.
Mais bientôt, un utilisateur de X @yangzhizheng1 a souligné que la structure du modèle et le code utilisés dans ce projet sont étonnamment similaires au MiniCPM-Llama3-V2.5 publié par Wallface Intelligence il n'y a pas si longtemps.
À cette fin, l'utilisateur X @yangzhizheng1 a également publié les preuves d'interrogation correspondantes.
Première preuve :
La structure du modèle et le code de Llama3-V et MiniCPM-Llama3-V 2.5 sont presque similaires au niveau du copier-coller. La différence est probablement qu'ils ont changé le gilet – les noms des variables ont été modifiés.
C'est comme la même robe, mais avec des boutons de couleurs différentes. Pensez-vous que c'est une coïncidence ?
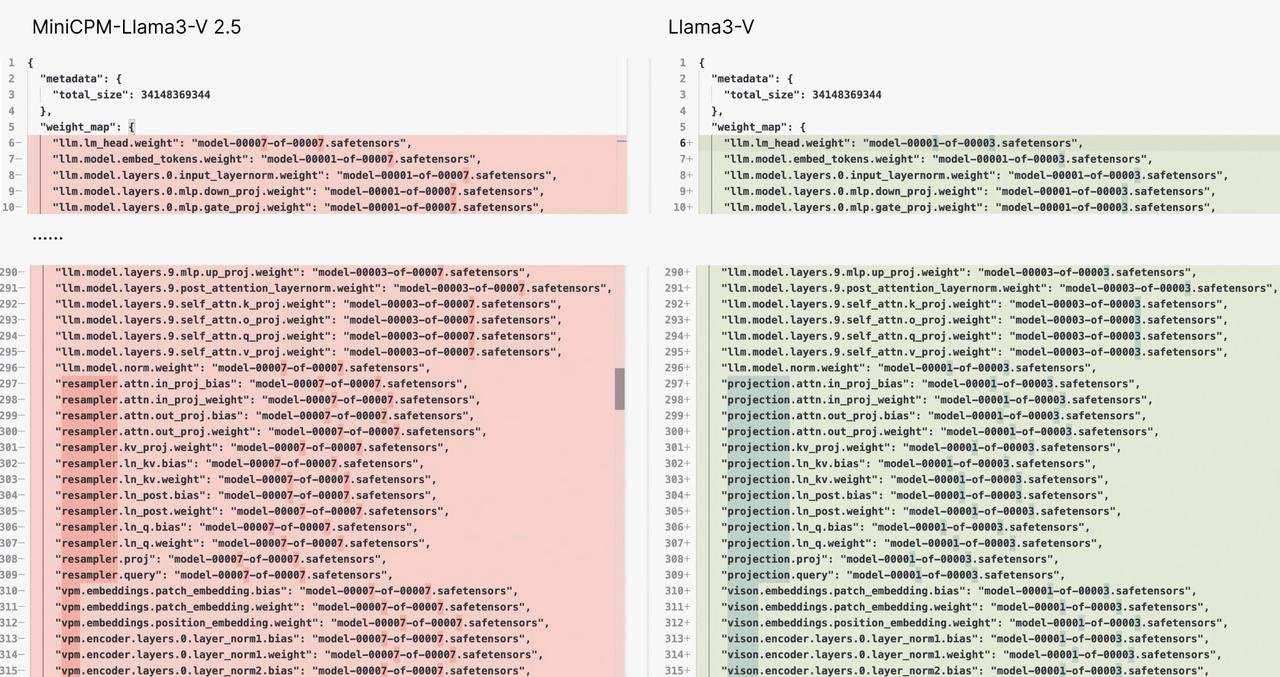
Deuxième preuve :
Lorsqu'on a demandé aux auteurs de Llama3-V pourquoi ils pouvaient utiliser le tokenizer MinicPM-Llama3-V2.5 qui n'avait pas encore été publié à l'avance, ils ont expliqué qu'ils utilisaient la génération précédente du projet MinicPM-V-2 de Wall-Facing. Intelligence.
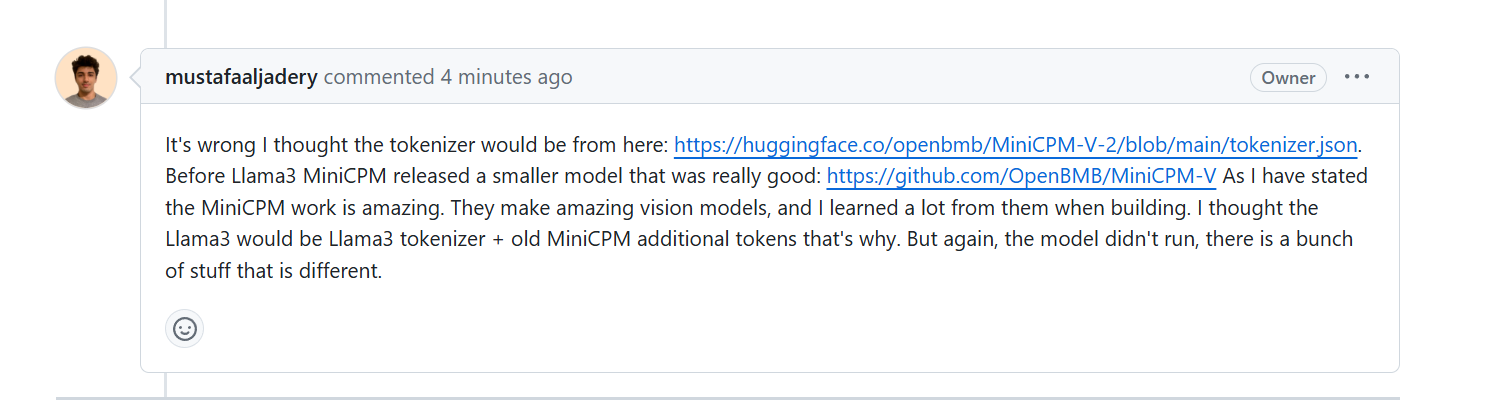
Cependant, certains médias ont demandé confirmation aux responsables de Wallface Intelligence. Dans HuggingFace, les segmenteurs de mots MiniCPM-V2 et MiniCPM-Llama3-V 2,5 sont respectivement deux fichiers et leurs tailles sont complètement différentes.
De plus, le tokenizer du MiniCPM-Llama3-V 2.5 est composé du tokenizer Llama3 plus le token spécial du modèle de la série MiniCPM-V.
Étant donné que MiniCPM-V2 a été publié avant Llama3, il est théoriquement impossible d'inclure la technologie de tokenizer Llama3 qui n'a pas encore été divulguée.
Troisième preuve :
Ce qui est encore plus scandaleux, c'est que lorsque l'auteur du projet llama3-V a fait face aux doutes des utilisateurs et a vu que quelque chose n'allait pas, il a simplement mis en scène un bon spectacle de "suppression de la bibliothèque et fuite".
Même la page du projet sur GitHub a été supprimée, ce qui peut être qualifié de version 2.0 trompeuse.
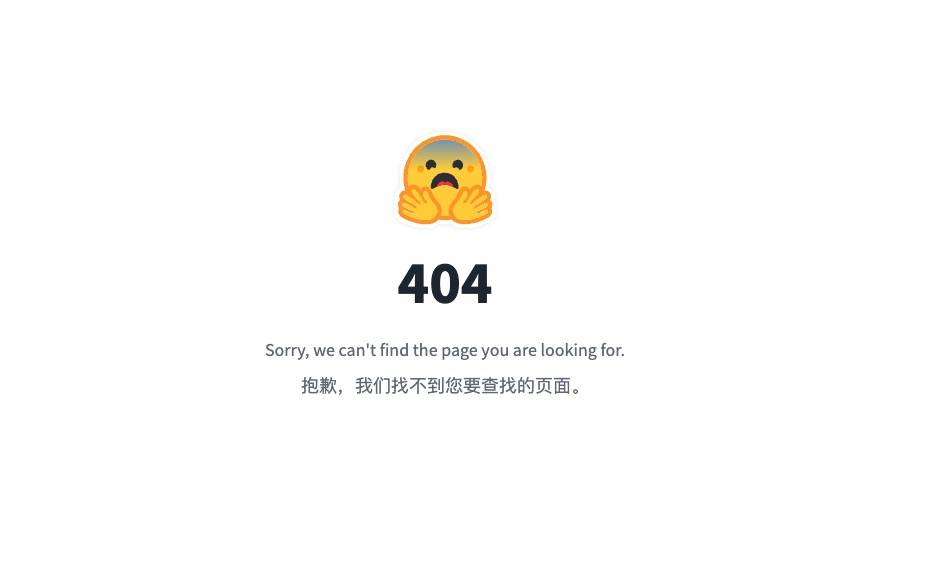
L'adresse de Hugging Face est la suivante Actuellement, lorsque nous ouvrons la page, nous ne pouvons voir que "404".
https://huggingface.co/mustafaaljadery/llama3v/commit/3bee89259ecac051d5c3e58ab619e3fafef20ea6
Ce n’est pas encore fini, d’autres preuves apparaissent :
L'utilisateur X @yangzhizheng1 a déclaré que si un bruit gaussien (paramétré par un seul scalaire) est ajouté au point de contrôle de MiniCPM-Llama3-V 2.5, le modèle résultant sera taillé dans le même moule que Llama3-V.
Non seulement cela, ce modèle peut également reconnaître les écrits anciens profonds de la période des Royaumes combattants tels que « Tsinghua Slips », et les erreurs sont exactement les mêmes selon les mots officiels de Wall-Facing Intelligence :
Non seulement ils ont raison, mais ils ont aussi tort.

Il faut savoir que ces données d'écriture anciennes ont été obtenues en scannant et en annotant manuellement les feuillets de bambou Tsinghua collectés par l'Université Tsinghua pendant plusieurs mois. Elles n'ont jamais été rendues publiques.
Alors, comment l’équipe d’IA de Stanford a-t-elle réussi à le sortir de nulle part ?
On peut dire que la déclaration de Wallface Intelligence du 2 juin peut être considérée comme un plagiat complet de la part de l’équipe de recherche de Stanford AI.
Jusqu'à tôt ce matin, Siddharth Sharma et Aksh Garg, deux auteurs de l'équipe Stanford Llama3-V, se sont officiellement excusés auprès de l'équipe MiniCPM face au mur pour cette faute académique sur la plateforme sociale X, affirmant que tous les modèles Llama3-V seraient supprimés.
Les meilleurs étudiants d’écoles célèbres plagient-ils également ? Les grands modèles open source chinois rattrapent leur retard
Une raison importante pour laquelle cette affaire a fait sensation sur Internet est que le parcours du plagiaire est si glamour.
Les informations publiques montrent que Siddharth Sharma et Aksh Garg sont tous deux étudiants de premier cycle au département d'informatique de l'université de Stanford et ont publié de nombreux articles dans le domaine de l'apprentissage automatique. Parmi eux, Siddharth Sharma a effectué un stage chez Amazon pendant un certain temps et est actuellement principalement engagé dans des travaux liés à l'IA et aux données.
Le curriculum vitae de stage d'Aksh Garg est riche et couvre des organisations bien connues telles que SpaceX, l'Université de Stanford et le California Institute of Technology.
Quant à Mustafa Aljadery, surnommé le « porteur du code » par les deux auteurs cités plus haut, il est diplômé de l'Université de Californie du Sud. Après la fermentation de l'opinion publique, le compte X a été mis au statut privé.

Les internautes aux yeux perçants n'ont pas accepté la déclaration d'excuses de l'équipe Stanford Llama3-V.
Par exemple, le
Christopher David Manning, directeur du Stanford AI Laboratory, s'est également levé pour condamner ce plagiat et a salué MiniCPM, un excellent modèle open source chinois.
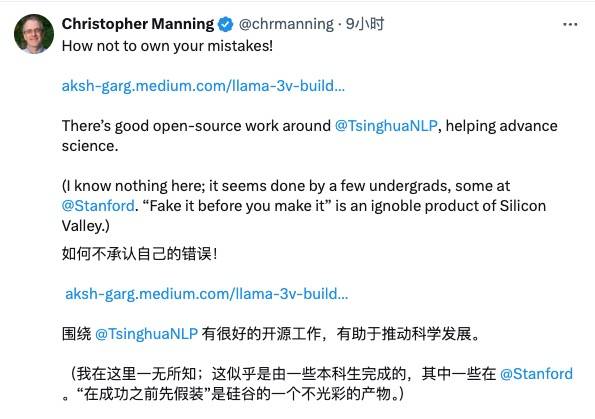
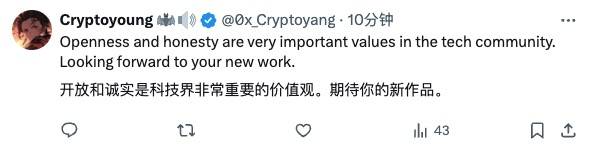
Cependant, il y a aussi des internautes qui ont l'attitude de « pardonner aux autres quand vous devez leur faire miséricorde » et les encouragent tranquillement :
L'ouverture et l'honnêteté sont des valeurs très importantes dans le monde de la technologie, et j'attends avec impatience votre nouveau travail.
Lucas Beyer, chercheur chez Google DeepMind, a déclaré que les grands modèles open source chinois ont de bons modèles comme MiniCPM, mais que la communauté internationale ne leur a pas accordé suffisamment d'attention…

L’équipe Wall-Facing Intelligence a également répondu à cette question hier.
Li Dahai, PDG de FaceWall Intelligence, a déclaré : « L'innovation technologique n'est pas facile. Chaque travail est le résultat des efforts jour et nuit de l'équipe et une contribution sincère au progrès technologique et au développement innovant dans le monde avec une puissance de calcul limitée.
Nous espérons que le bon travail de l’équipe sera remarqué et reconnu par davantage de personnes, mais pas de cette manière. "

Liu Zhiyuan, scientifique en chef de Wall-Facing Intelligence, a également publié sur Zhihu, affirmant que cet incident prouvait l'influence internationale des réalisations innovantes de la Chine sous un autre angle, soulignant l'importance du partage open source et du respect de l'esprit d'originalité.
Il faut dire que ce drame du plagiat dans le cercle de l'IA est une explication classique de "l'innovation n'est pas facile, elle doit être faite et chérie, l'intégrité académique est la responsabilité de chacun".
Vous savez, si vous imitez la forme du code, vous ne pouvez pas copier la grâce originale.
En fait, depuis l'année dernière, les grands modèles chinois sont devenus open source comme des champignons après une pluie printanière. Ils sont passés du statut de bénéficiaires à ceux de contributeurs et ne sont pas avares en fournissant des résultats open source plus remarquables au monde.
Des géants comme Alibaba et Tencent à l'intelligence artificielle, les start-ups d'IA telles que Zhipu AI et Kunlun Tiangong sont également des membres actifs de la communauté open source, contribuant au développement des modèles chinois à grande échelle.
Nous espérons aussi que cette brise printanière d’ouverture et de partage soufflera plus fort.
Tout comme Li Dahai, PDG de Face Wall Intelligence, appelle chacun à travailler ensemble pour construire un environnement communautaire ouvert, coopératif et confiant. Ce n’est qu’en travaillant ensemble que le monde pourra devenir meilleur avec l’arrivée d’AGI !
# Bienvenue pour suivre le compte public officiel WeChat d'aifaner : aifaner (ID WeChat : ifanr). Un contenu plus passionnant vous sera fourni dès que possible.
Ai Faner | Lien original · Voir les commentaires · Sina Weibo