
Conversation avec l’équipe idéale de conduite intelligente : Quelle est la « réponse ultime » à la conduite autonome ?

En 2013, la conduite autonome était encore un concept très avant-gardiste et sexy, tout comme l'actuelle AGI et le Metaverse il y a quelques années. À l'ère des sociétés Internet en plein essor, Tencent organisait chaque année une conférence WE pour en parler. . Certains sujets sur les étoiles et la mer, tels que l'édition génétique, l'interface cerveau-ordinateur, l'exploration spatiale, etc.
La première fois que j'ai découvert le concept de « conduite autonome », c'était lors de la première conférence Tencent WE en 2013. À cette époque, un invité a exprimé les opinions suivantes :
- Les problèmes techniques ne sont pas difficiles à résoudre, mais les problèmes juridiques le sont.
- D’ici dix ans, les consommateurs pourront acheter des voitures autonomes.
- Si la précision du jugement effectué par la machine atteint 95 %, elle pourrait encore être meilleure et plus rapide que celle des humains.
La période de dix ans est arrivée, et ces paroles se sont généralement réalisées. Alors que Carrot Run est déjà sur les routes à grande échelle dans de nombreuses villes, les modèles haut de gamme des nouvelles marques puissantes grand public ont des capacités de conduite intelligentes haut de gamme, et La version Tesla FSD V12 est lancée. Le RoboTaxi de Tesla est sur le point d'être lancé. La technologie de conduite autonome passe du niveau L2+ au niveau L4 "La voiture ne peut pas être conduite en position assise".
Attends une minute, quand je sortirai cette photo, que dois-tu répondre ? 
Il s'agit d'une scène ordinaire des conditions de circulation quotidiennes dans la ville de Guangzhou : non seulement les voies réservées aux véhicules à moteur sont remplies d'un grand nombre de scooters électriques à deux roues, mais même les fauteuils roulants électriques roulant à des vitesses extrêmement faibles circulent également sur les voies réservées aux véhicules à moteur.
À l'heure actuelle, les avantages et les défis de la conduite intelligente se reflètent ensemble : l'avantage est que la conduite intelligente n'a pas d'émotions, ne sera pas en colère et ne souffrira pas de rage au volant, le défi est le fauteuil roulant électrique lent et le deux-roues ; les voitures à batterie qui se précipitent et envahissent l’autoroute. Pour une conduite intelligente, c’est un scénario très difficile à prévoir et à gérer.
En fait, les prévisions concernant le développement de la conduite autonome il y a dix ans reposaient principalement sur une seule logique : les voitures et les personnes sur la route doivent respecter le code de la route, s'arrêter aux feux rouges et conduire aux feux verts, et aucune personne nuisible n'apparaîtra sur le moteur. voies réservées aux véhicules.
Mais lorsque les constructeurs proposent aux consommateurs des voitures dotées de fonctions de conduite intelligentes, la situation à laquelle les voitures sont confrontées est la même : la route est ma maison et les règles de circulation sont ignorées.
Logique de conduite intelligente classique : "Perception – Planification – Contrôle"
Les solutions de conduite intelligente actuelles, qu'il s'agisse de solutions cartographiques de haute précision ou de solutions sans carte, s'appuient sur un grand nombre d'ingénieurs pour rédiger des règles basées sur divers scénarios routiers, afin d'épuiser toutes les conditions routières et les mesures correspondantes, et d'atteindre autant que possible. possible un comportement de conduite intelligent.
Cependant, les conditions routières réelles sont non seulement compliquées et impossibles à être exhaustives, mais le monde réel est également en constante évolution et de nouvelles scènes routières apparaissent à tout moment. Par conséquent, la recherche et le développement antérieurs sur la conduite intelligente étaient une « guerre infinie ».
Par exemple, avant juillet, peu de constructeurs automobiles pouvaient conquérir la scène des ronds-points d’entrée et de sortie parce que la scène était complexe, la perception limitée et la planification et la prise de décision difficiles.
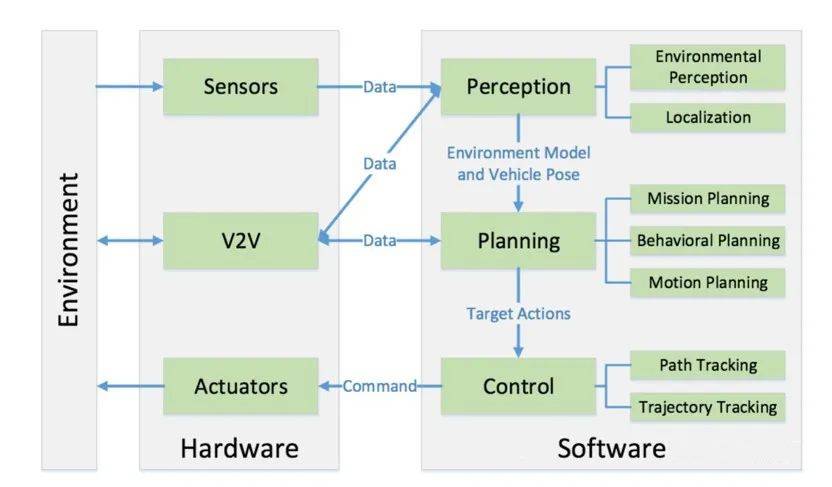
Pour faire simple, avant que la version FSD V12 de Tesla n’adopte la solution technique « de bout en bout », presque toutes les solutions de conduite intelligente peuvent se résumer en trois modules majeurs : « Perception – Planification – Contrôle ». variété de scènes, comme la règle classique des tiers : scènes d'autoroute, scènes urbaines et scènes de stationnement.
Ces grandes scènes peuvent être subdivisées et subdivisées. Les ingénieurs de conduite intelligents écrivent des codes de règles en fonction des scènes. Le lidar, le radar à ondes millimétriques, la caméra et le système de positionnement de la voiture fonctionnent ensemble pour détecter et enregistrer les informations sur la route, l'environnement et l'emplacement, puis BEV ( La technologie Birds-Eyes-View) ou la technologie OCC (Occupancy Network) ou d'autres technologies utilisent les informations obtenues par ces capteurs pour former une « projection virtuelle du monde réel » qui peut être comprise par le système de conduite intelligent, puis basée sur cela. projection mondiale", un itinéraire de déplacement raisonnable et un plan de déplacement sont planifiés, puis la décision de contrôle est dérivée. Enfin, la voiture répond à la décision en formant "ralentissez, changez de direction vers la gauche, prenez la voie de demi-tour à gauche dans avancer, freiner d'urgence à éviter Si une voiture à batterie à deux roues entre au milieu de la route, continuez et faites demi-tour. Il s'agit d'un comportement de conduite intelligent.
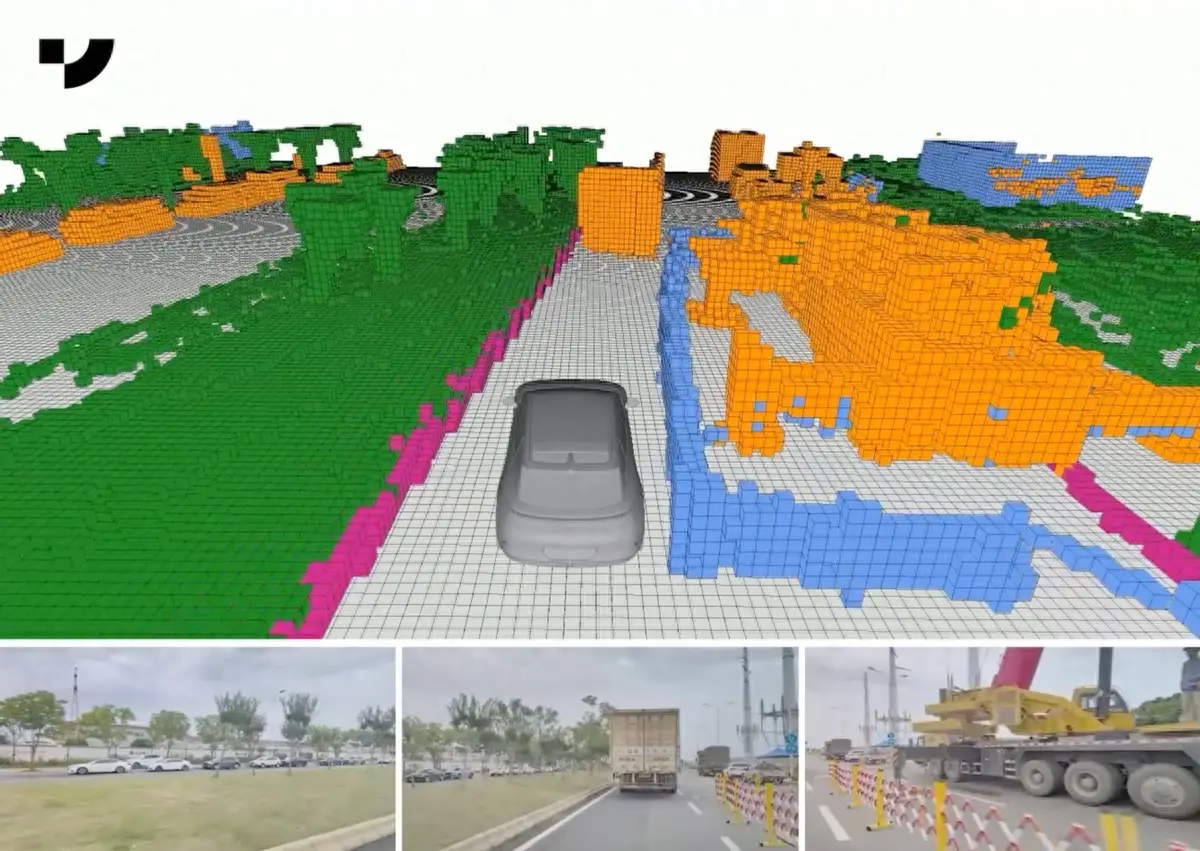
▲ Schéma d'occupation du réseau Jiyue Auto OCC
Si la conduite intelligente utilise la technologie de réseau d'occupation OCC, alors nous pouvons faire une analogie dans le système de conduite intelligente, le monde extérieur est comme "Minecraft", qui est composé de carrés (voxels). théoriquement, il n'y aura pas de carrés sur la route et la voiture peut avancer avec audace. S'il y a un petit carré stationnaire devant elle, il se peut que le seau à glace se soit égaré au milieu de la route. une longue barre qui se déplace lentement sur la droite, c'est peut-être juste des piétons. S'il s'agit d'un très grand bloc rectangulaire se déplaçant rapidement sur la voie de gauche, ce peut être un gros camion…
Dans cette logique générale de « perception – planification (décision) – contrôle », qu'il s'agisse de la solution précédente basée sur des cartes de haute précision, ou de la NOA (assistance automatique à la navigation) sans carte qui s'appuie davantage sur la fusion de plusieurs capteurs et le calcul local élevé power Driving) ne s'écartent pas de cette logique de base. Le cadre R&D et le travail des ingénieurs remplissent également leurs fonctions respectives dans chaque module.
Jusqu'à l'émergence du « bout en bout ».
Qu’est-ce que « de bout en bout » ?
Il existe trois événements marquants dans le domaine de l’intelligence artificielle qui ont suscité un large débat social.
La première fois, c'était en 1997, lorsque le robot d'échecs "Deep Blue" d'IBM a vaincu le maître d'échecs Garry Kasparov. Mais si vous regardez "Deep Blue" à ce moment-là, vous sentirez que ce n'est pas si intelligent. périphérique de stockage. Nous collectons une énorme quantité d'enregistrements d'échecs d'ouverture et de fin de partie, puis utilisons des algorithmes de recherche et des systèmes d'évaluation efficaces pour sélectionner la manière la plus appropriée de jouer.
En d’autres termes, lorsque Deep Blue joue aux échecs, les décisions intermédiaires sont explicables et logiquement claires pour les humains.

Puis, dans le domaine du Go, qui est plus complexe que les échecs, AlphaGo de DeepMind a battu Li Sedol et Ke Jie, annonçant que le niveau d'intelligence artificielle dépasse de loin celui de tous les joueurs d'échecs humains.
La logique d'AlphaGo n'est pas de rechercher et de faire correspondre les enregistrements d'échecs. Après tout, le nombre de grilles d'échiquier et de pièces d'échecs dans Go dépasse de loin celui des échecs, et les possibilités qu'elles contiennent sont trop élevées. Les ordinateurs actuels ne peuvent pas calculer toutes les possibilités. Mais basé sur l'apprentissage profond des réseaux de neurones, AlphaGo peut apprendre et évoluer par lui-même, et peut savoir comment jouer ensuite pour se rapprocher de la victoire. Pour les humains, les méthodes de jeu d'AlphaGo sont complètement différentes de la logique de la pensée humaine, mais ce qui s'est passé dans. au milieu ? , les experts en intelligence artificielle connaissent sa logique.
Puis est arrivée l’émergence de ChatGPT. Entre l’entrée et la sortie de la technologie des grands modèles de langage, il existe une « boîte noire » que même les experts en intelligence artificielle ne peuvent pas expliquer avec précision ce qui s’est exactement passé entre la question et le ChatGPT. répondre.
Pour utiliser cela comme métaphore, la technologie de conduite intelligente était auparavant basée sur la logique de recherche et développement de « perception – planification (décision) – contrôle », similaire aux réseaux neuronaux convolutifs (CNN) d'AlphaGo qui peuvent traiter la structure bidimensionnelle de. l'échiquier et extraire les caractéristiques spatiales ; Le réseau de valeurs et le réseau politique peuvent fournir la planification et la prise de décision, en plus de l'apprentissage par renforcement et de la technologie de recherche arborescente de Monte Carlo pour optimiser la prise de décision.
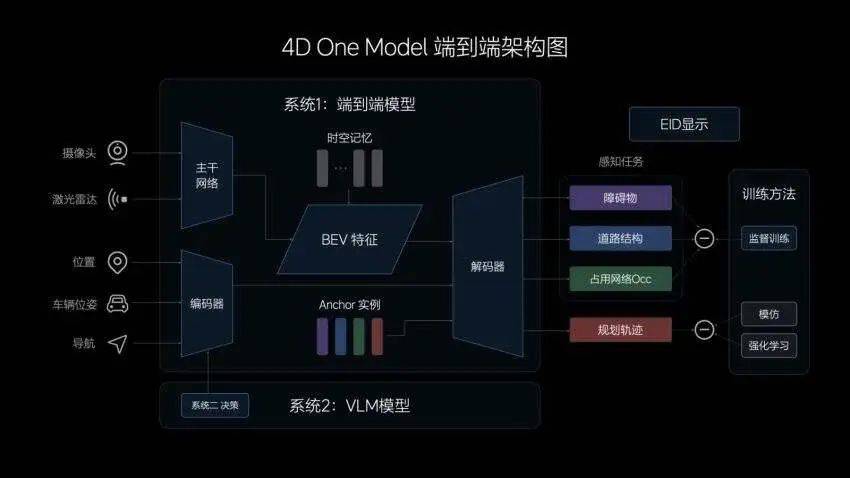
▲ Schéma d'architecture de bout en bout idéal pour la conduite intelligente
La technologie de conduite intelligente « de bout en bout » est similaire à la technologie de modèle à grand langage derrière ChatGPT, depuis les données brutes des capteurs (telles que les caméras, les radars à ondes millimétriques, le lidar, etc.) jusqu'aux instructions de contrôle finales (telles que l'accélération). , freinage, etc.) direction, etc.). Bien entendu, cette méthode de contrôle direct du véhicule est encore trop radicale à ce stade, donc la solution idéale de bout en bout est de sortir uniquement la trajectoire, mais pas de contrôler. Il existe encore de nombreuses contraintes et mesures redondantes avant le contrôle du véhicule. L'objectif de cette méthode est de simplifier l'architecture du système et d'accomplir l'ensemble de la tâche via un seul réseau ou modèle neuronal. Elle ne repose plus sur des codes de règles de scène massifs. Il s'agit d'une direction technique complètement différente.
Tout comme le grand modèle de langage mettait auparavant l'accent sur le grand nombre de paramètres, le modèle multimodal derrière le bout en bout comporte également un tel processus de changement quantitatif conduisant à un changement qualitatif. Tesla a pris les devants dans l'utilisation de bout en bout. technologie sur FSD V12, et Musk Dites simplement ceci :
S'entraîner avec 1 million de tranches vidéo est à peine suffisant ; 2 millions, c'est légèrement mieux ; 3 millions seront wow (wow) ;
Cependant, les personnes qui utilisent souvent ChatGPT ou d'autres outils d'IA générative constateront que ces outils ne sont pas fiables et génèrent souvent en toute confiance de mauvaises réponses, ce que l'on appelle « illusion ».
Il n'y a généralement pas de conséquences catastrophiques pour les outils d'IA sur ordinateur qui répondent aveuglément aux questions, mais la conduite intelligente est liée à la sécurité des personnes. Une solution « de bout en bout » au comportement de conduite nécessite davantage de mesures de vérification et d'assurance. et plus important encore, les problèmes d'ingénierie.

Conversation avec l’équipe Ideal Intelligent Driving : « End-to-end » est la véritable utilisation de l’IA pour la conduite autonome
Après avoir parcouru la longue introduction générale, nous pouvons enfin entrer dans le vif du sujet : profitons de l'occasion pour interviewer l'équipe de conduite intelligente idéale, parlons de la façon dont « de bout en bout » passe de la théorie à la conduite ?
Lang Xianpeng, vice-président de la R&D d'Ideal Smart Driving, a déclaré à Aifaner et Dongchehui :
Une réflexion importante lors de notre réunion stratégique du printemps de cette année est que nous recherchons trop la concurrence. Par exemple, nous nous concentrons toujours sur Huawei, sur le nombre de villes qu'il a ouvertes et sur ses indicateurs. Par exemple, je suis meilleur que Huawei. Un peu meilleur, ou un peu moins bon que Huawei, ne représente pas les besoins réels des utilisateurs.
Pour en revenir aux besoins de conduite des utilisateurs, les besoins réels des utilisateurs ne sont pas la faiblesse de l'indicateur de taux de prise en charge. Ce dont les utilisateurs ont besoin, c'est d'une conduite intelligente pour conduire comme un conducteur expérimenté, et ce besoin anthropomorphique s'appuie sur l'architecture de recherche et de développement régulière et modulaire d'origine. est difficile à mettre en œuvre. Mais la pré-recherche interne idéale « de bout en bout » fera mieux.
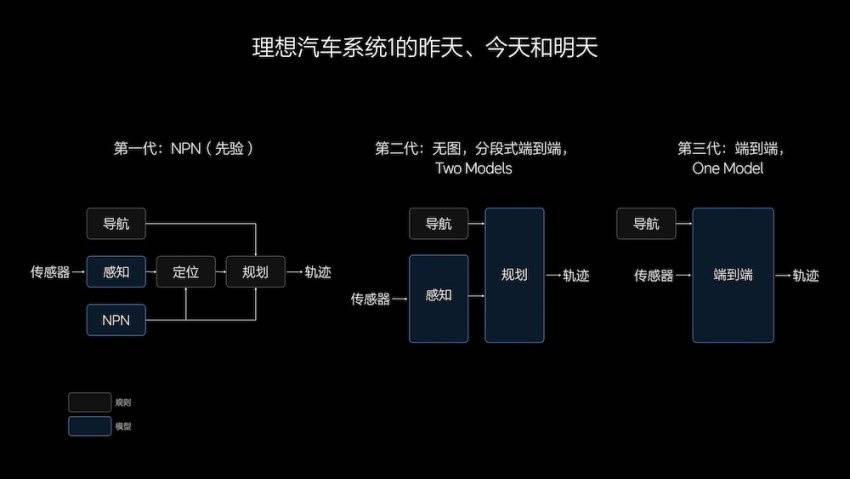
Sur cette base, en un an, la solution technologique de conduite intelligente idéale a subi trois générations d'ajustements : du graphique au NPN (réseau neuronal préalable) au sans graphique, puis de bout en bout.
Lang Xianpeng explique la différence essentielle de bout en bout :
En apparence, de bout en bout, c'est un grand modèle qui remplace plusieurs petits modèles. En fait, c'est un tournant décisif. De bout en bout, nous pouvons véritablement utiliser l'intelligence artificielle pour faire de la conduite autonome. pas encore le cas.
Parce qu'il est basé sur les données, combinant la puissance de calcul avec des données et des modèles, il s'agit d'un processus d'auto-itération hautement automatisé. Ce processus itère les capacités du modèle ou du système lui-même. Alors qu'est-ce qu'on faisait avant ? Ce que nous réalisons, ce sont toutes sortes de fonctions système, telles que la fonction de monter et de descendre de la rampe ou la fonction de passage au péage.
Il existe une grande différence entre les fonctions et les capacités.
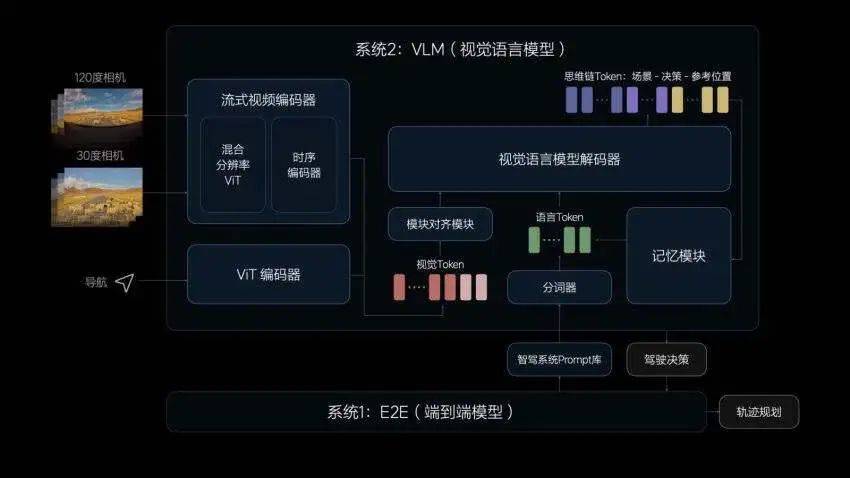
Mais en fait, le système de conduite autonome de nouvelle génération présenté lors de la conférence d'été Ideal Intelligent Driving est une solution double système « de bout en bout + VLM (modèle de langage visuel) ».

Puisque le principe est de faire en sorte que la conduite intelligente ressemble à un conducteur expérimenté et soit aussi anthropomorphique que possible, nous devons alors considérer la façon dont les gens font les choses. La base théorique ici est « La pensée, la théorie des systèmes rapides et lents » du prix Nobel Daniel Kahneman. "Rapide et lent" :
Le système humain rapide s'appuie sur l'intuition et l'instinct pour maintenir une efficacité élevée dans 95 % des scénarios ; le système humain lent s'appuie sur une analyse et une réflexion conscientes, introduisant une limite supérieure élevée de 5 % des scénarios.
Le système double idéal « de bout en bout + VLM » de bout en bout est un système rapide, qui a la capacité de traiter rapidement les informations dans les scénarios de conduite quotidiens, tandis que le modèle de langage visuel VLM a la capacité de penser logiquement. dans des scénarios complexes.
Quelle est la vitesse de ce système rapide ?
Jia Peng, responsable de la recherche et du développement sur la technologie de conduite intelligente idéale, a déclaré :
Désormais, notre délai de bout en bout équivaut à plus de 100 millisecondes entre le capteur et la sortie de contrôle, soit moins de 200 millisecondes. Dans le passé, le sous-module avait probablement plus de 300 à près de 400 millisecondes.
Pourquoi ce système lent est-il nécessaire ?
Lang Xianpeng a expliqué :
Nous explorons actuellement certaines de ses capacités (VLM). Il a au moins une certaine valeur dans la sélection des voies principales et auxiliaires que nous venons de mentionner, il n'y aurait pas de problèmes de sécurité. Notre principal rôle de soutien pour la conduite intelligente de niveau L3 est de bout en bout, ce qui représente la capacité de conduite de la personne dans des conditions normales.
Mais lorsqu'il s'agit de conduite intelligente de niveau L4, le VLM ou les grands modèles doivent y jouer un rôle plus important. Cela ne fonctionne peut-être pas plus de 90 % du temps, mais c'est ce contenu qui détermine si le système est de niveau L3 ou L4. Un point clé de ce niveau est que VLM peut réellement faire face à ce scénario inconnu.
L'idéal n'est pas d'en finir avec un modèle de bout en bout, mais d'adopter une solution à double système plus fiable pour couvrir l'ensemble de la scène, ce qui est chargé de rendre le comportement de conduite plus humain et plus proche. un conducteur expérimenté, tandis que le modèle de langage visuel VLM prend en charge la limite inférieure, peut même augmenter la limite supérieure et devrait atteindre un niveau de conduite autonome plus élevé.
En y regardant de plus près, contrairement au fondamentaliste de bout en bout, qui est en fin de compte responsable du contrôle de la voiture, le bout en bout idéal ne contrôle pas directement la voiture, mais atteint le niveau de la trajectoire de sortie.
Jia Peng a dit :
Notre modèle de bout en bout atteint la trajectoire, et certaines poches de sécurité sont ajoutées après la trajectoire, car avant que le modèle n'atteigne la limite supérieure, il y a encore certaines choses à gérer, comme tourner fort le volant pour s'en débarrasser il.
Dans le processus de conduite intelligente actuel, les deux systèmes fonctionnent également en même temps. Jia Peng a expliqué en détail comment les deux systèmes fonctionnent ensemble :
Ces deux systèmes fonctionnent en temps réel et fonctionnent ensemble de bout en bout. Parce que le modèle est plus petit, sa fréquence est relativement élevée, par exemple à une douzaine de hertz. De plus, la taille du modèle comporte un nombre de paramètres beaucoup plus important, 2,2 milliards de paramètres. Il peut actuellement fonctionner à environ 3 à 4 Hz, et il fonctionne en fait tout le temps.
VLM envoie les résultats de la prise de décision à des points de référence. Par exemple, lorsque l'ETC entre sur l'autoroute, il est en fait difficile pour la voiture de déterminer quelle voie dois-je emprunter en mode manuel ou en ETC ? VLM a toujours été là en ce moment. Si vous souhaitez choisir ETC, vous pouvez emprunter le chemin ETC. Si vous souhaitez passer au manuel, vous pouvez emprunter le chemin manuel. Cependant, il jette les résultats de décision et les trajectoires de référence jusqu'au bout. Modèle de bout en bout. Ces informations sont ensuite utilisées après inférence du modèle de bout en bout.
En fait, le modèle de langage visuel VLM est une information auxiliaire. Le résultat final de la trajectoire est le résultat du raisonnement du modèle, et il a une certaine probabilité d'être adopté.
Pourquoi le bout en bout peut-il créer une si grande vague dans le domaine de la conduite intelligente ? Ou est-ce à cause des énormes possibilités qui se cachent derrière cela et de son importance directionnelle dans la recherche de la « réponse ultime ».
Bref, dans ce plan, tout le monde est loin d'atteindre le plafond des capacités, et l'exploration technologique et la pratique de l'ingénierie sont entrées dans la zone sauvage.
Jia Peng a en outre expliqué les principes et les possibilités des systèmes doubles :
En fait, les gens sont des systèmes doubles. Bien que la structure physique ne soit pas aussi claire qu'un système double, la façon dont les gens pensent est un système double. Nous avons donc eu l'idée à l'époque d'en ajouter un autre avec de réelles capacités de généralisation sur la base de. de bout en bout En tant que système permettant la capacité de réflexion logique, VLM vient naturellement à l’esprit.
Bien que VLM ne contrôle pas directement la voiture, il assurera la prise de décision.
Comment cette chose va-t-elle évoluer dans le futur ? Peut-être qu'avec l'augmentation de la puissance de calcul, par exemple dans les versions 12.3 à 12.5 de Tesla FSD, les paramètres ont augmenté de 5 fois, ce qui peut prendre en charge un modèle suffisamment grand.
Je pense qu'il y aura deux tendances à l'avenir : la première est que l'échelle du modèle deviendra plus grande. Le système 1 et le système 2 sont toujours deux modèles de bout en bout plus VLM. Ces deux modèles peuvent être combinés en un seul. actuellement relativement faiblement couplés et pourront être comparés à l’avenir étroitement couplés.
Deuxièmement, nous pouvons également tirer des leçons de la tendance actuelle au développement de modèles multimodaux à grande échelle. Ils se dirigent vers ce type de multimodalité native, qui peut faire à la fois du langage et de la parole, de la vision et du lidar. à penser à l'avenir.
Notre paradigme devrait pouvoir nous aider à atteindre (conduite autonome de niveau L4), car nous avons déjà vu le prototype de son application dans l'intelligence incarnée des robots. En ce qui concerne le processus de pensée humaine, cet ensemble de choses pourrait être ce que nous souhaitons poursuivre. .La réponse ultime.
La réponse ultime signifie que nous utilisons cette théorie et ce cadre pour créer une véritable intelligence artificielle.

Mais avant de parler de la réponse ultime, Jia Peng a expliqué pourquoi seul le bout en bout peut résoudre le problème de la conduite intelligente « d'entrer et de sortir autour de l'île » :
S'il s'agit d'une solution de conduite segmentée, le front est la perception. Pour effectuer un demi-tour, la ligne de demi-tour ne doit pas être installée à différentes intersections. la même chose, et la courbure Ils sont tous différents, il vous est donc difficile d'utiliser un seul ensemble de codes pour faire demi-tour à tous les ronds-points. Il y a trop de types.
Il y a aussi une histoire intéressante à propos du rond-point. Lorsque nous avions (les données du modèle incluses) environ 800 000 clips (clips vidéo), nous ne pouvions pas passer par le rond-point. Puis nous avons soudainement découvert qu'un jour, nous (alimentions) 1 million de clips. il pourrait le faire tout seul. En passant par le rond-point, je pense qu'un million (clip vidéo) contenait des données de rond-point.
Le modèle est en effet très puissant. Il peut apprendre toutes les données que vous lui fournissez. C'est le charme du modèle, tout comme ETC, je pense que si vous ouvrez notre version actuelle de bout en bout, vous constaterez qu'ETC peut les transmettre. tout seul, mais le problème est que maintenant, il ne sait pas quelle route je veux emprunter, que ce soit la route ETC ou la route artificielle. Il en choisira une au hasard, ce qui vous fera vous sentir en danger. Ce que nous voulons faire plus tard. c'est que VLM peut lui donner ces conseils, car VLM peut comprendre les caractères chinois et les indicateurs LED.
Concernant le quoi et le pourquoi de la partie théorique de bout en bout, nous avons maintenant une idée générale. Après avoir obtenu les données et les modèles, nous commençons vraiment, c'est-à-dire comment c'est le vrai grand test.

▲Atelier de fabrication automobile idéal
"Former un modèle de bout en bout n'est pas différent de fabriquer un élixir."
Lang Xianpeng a raconté à Ai Faner et Dong Chehui une histoire très bizarre sur la formation d'un modèle de bout en bout :
Plus tôt cette année, lorsque nous avons commencé à travailler sur le projet, nous avons constaté qu'après avoir entraîné le modèle, il était possible de conduire normalement. Cependant, en attendant un feu rouge, la voiture se comportait étrangement. Elle voulait toujours passer au suivant. voie. Nous ne savions pas pourquoi.
Plus tard, nous avons réalisé que lorsque nous entraînions le modèle de bout en bout, nous supprimions beaucoup de données en attente avant le feu rouge. Nous sentions que les données étaient inutiles après avoir attendu des dizaines de secondes ou une minute. Mais plus tard, j'ai découvert que ces données sont très importantes : elles ont enseigné à ce modèle qu'il faut parfois attendre une fois que l'on ralentit, on n'est pas obligé de couper ou de changer de voie.
Cette courte histoire montre que les données déterminent dans une large mesure la qualité du modèle, mais que la taille du modèle est limitée, de sorte que les données à alimenter pour entraîner le modèle sont en fait l'une des tâches principales.

Lang Xianpeng a donné une analogie :
La formation d'un modèle de bout en bout n'est pas différente de l'alchimie ancienne. Dans les temps anciens, le raffinage de la poudre à canon se concentrait sur le mononitrate, le disulfure et le charbon de bois, et les explosifs produits étaient relativement puissants. D’autres ratios peuvent également être capables d’allumer le feu.
Cependant, pour les constructeurs automobiles qui souhaitent former des modèles de bout en bout, « l'alchimie » n'est qu'une métaphore, pas une méthode spécifique de mise en œuvre de projet. Comment obtenir les données, comment les sélectionner et comment les former sont tous scientifiques. problèmes.
Heureusement, Ideal présente certains avantages innés. Par exemple, ses voitures se vendent bien et son volume de ventes se classe souvent au premier rang parmi les nouveaux constructeurs de voitures électriques. Il y a plus de 800 000 voitures Lideal sur la route, et 40 000 à 50 000 supplémentaires s'ajoutent chaque année. mois. , ces véhicules fournissent plus d’un milliard de kilomètres de données.
De plus, Ideal est conscient de l'importance des données depuis longtemps et a construit des fonctionnalités de base telles que des chaînes d'outils pour les données. Par exemple, la base de données backend d'Ideal a mis en œuvre une recherche de paragraphe pour trouver la phrase « Piétons passant avec des parapluies à proximité ». la ligne d'arrêt au feu rouge un jour de pluie. ", Vous pouvez trouver les données correspondantes derrière cela se trouvent quelques petits modèles de nuages, tels que des modèles d'exploration de données et des modèles de compréhension de scène.
Lang Xianpeng estime même que la chaîne d'outils et les capacités de l'infrastructure de ces bases de données sont, dans un sens (important), encore supérieures aux capacités des modèles, car sans ces bonnes infrastructures et données, quelle que soit la qualité du modèle, il sera il ne sera pas possible de le former.
Le changement dans les solutions techniques sous-jacentes signifie également un changement dans les méthodes de travail. Lorsqu'un cas problématique est découvert, le modèle du système de « bureau de tri » interne idéal analysera automatiquement à quel type de problème de scénario il appartient et donnera des « suggestions de tri ». Revenez ensuite à la formation du modèle pour résoudre le problème.
Cela implique également un changement dans notre façon de travailler. Les personnes qui, à l’origine, résolvaient des problèmes spécifiques sont désormais devenues des personnes qui conçoivent des outils pour résoudre des problèmes.
Afin d'améliorer l'efficacité du « diagnostic et du traitement », Ideal entraîne en interne plusieurs modèles en même temps. Ce processus revient au concept d'« alchimie », a expliqué Jia Peng :
La formation du modèle comporte deux aspects principaux. L'un est la recette de données. Quelle quantité faut-il ajouter dans des scénarios similaires pour résoudre le cas ? Différents scénarios ont des exigences de données différentes. Le deuxième point concerne les hyper-paramètres du modèle.Après avoir ajouté de nouvelles données, comment ajuster les paramètres du modèle. Généralement, 5 à 6 versions du modèle seront soumises pour formation en même temps, puis voir quelle version résout le problème ? problème et obtient des scores plus élevés.
La formation de plusieurs modèles en même temps met en avant des exigences en matière d'infrastructure de base de données et des exigences énormes en matière de puissance de calcul. À ce moment-là, le « pouvoir financier » entre en jeu. L'avantage idéal ici est que les voitures se vendent plus et sont plus chères. Avec les meilleurs revenus et les meilleurs flux de trésorerie parmi les nouveaux constructeurs de voitures électriques, elles peuvent supporter les énormes dépenses en puissance de calcul qui les sous-tendent.
Lang Xianpeng a dit :
Nous estimons que si la conduite autonome L3 et L4 est réalisée, la dépense annuelle en puissance de calcul pour la formation sera de 1 milliard de dollars américains. À l'avenir, ce pour quoi nous nous battrons, c'est la puissance de calcul et les données, et ce pour quoi nous nous battons, c'est l'argent ou la rentabilité.

Lorsque le modèle de bout en bout remplace la majeure partie du travail dans la logique de conduite intelligente traditionnelle « perception-planification-contrôle », le travail le plus exigeant en main-d'œuvre de l'équipe de conduite intelligente liée à l'idéal est également concentré sur la « tête et la queue ». ", la tête c'est les données, la fin c'est la vérification.
En plus des deux systèmes de vitesse du modèle de bout en bout et du modèle de langage visuel VLM, il existe également un système trois à l'intérieur d'Ideal, appelé modèle expérimental ou modèle mondial. Il s'agit essentiellement d'un système d'examen. évaluer le niveau de l'ensemble du système de conduite intelligent et de la sécurité.
Lang Xianpeng a comparé ce système d'examen à un ensemble de trois banques de questions :
- Véritable banque de questions : Le comportement correct des personnes qui conduisent sur la route
- Mauvaise banque de questions : lors des tests et de la conduite normaux, de la prise de contrôle de l'utilisateur, de la sortie de l'utilisateur et d'autres comportements
- Questions de simulation : sur la base de toutes les données, tirez des inférences à partir d'une instance et générez des tests de scénarios virtuels similaires pour des problèmes répétés spécifiques.
Par exemple, comme mentionné précédemment, si vous souhaitez que votre conduite intelligente soit personnifiée, à la manière d'un conducteur expérimenté, alors le comportement de conduite de cette véritable banque de tests doit être celui d'un conducteur expérimenté. La « vraie banque de tests » dans le modèle de test idéal. sélectionne un score interne de 90 ou plus. Le comportement au volant des conducteurs, ce groupe ne représente que 3% des conducteurs automobiles idéaux, dépendra de la douceur de leur conduite, du degré de danger de la conduite, etc. Par exemple, si un conducteur active souvent le freinage d'urgence automatique AEB, alors son comportement de conduite sera trop radical.
Après des tests approfondis du modèle expérimental, une version test sera également disponible pour les « utilisateurs précoces ». Cela signifie que des milliers de voitures utilisateur recevront une nouvelle version du système de conduite intelligente, qui peut fonctionner dans des scènes et des scénarios réels. "mode ombre" non perceptuel Effectuez des vérifications et des tests réels sur la route, qui sont plus grands que la flotte d'essai de n'importe quel constructeur automobile.
Les données testées et vérifiées par des milliers d'utilisateurs précoces seront automatiquement renvoyées, automatiquement analysées et automatiquement formées de manière itérative pour une nouvelle série de tests et de livraison.
En d’autres termes, l’acquisition de données, la formation de modèles, les examens expérimentaux et la livraison aux utilisateurs sont des processus remplis de logique circulaire automatisée, avec très peu de participation humaine.
Selon Lang Xianpeng et Jia Peng, après être passée au « bout en bout + VLM », l'industrie a atteint un endroit proche du no man's land. Il y a de l'enthousiasme à l'idée de ne pas pouvoir voir la limite supérieure des capacités du système. pour le moment, mais bien sûr, il faut aussi être pragmatique. Par exemple, actuellement, seul le modèle de bout en bout produit la trajectoire, et le contrôle après la trajectoire doit être sûr. Un autre exemple est la réflexion sur la puissance de calcul. : le nombre d'ingénieurs était nécessaire auparavant, et le nombre de cartes graphiques le sera à l'avenir.
Sans puissance de calcul, tout cela relève de la fantaisie.
Il n’y a aucun profit et la puissance de calcul n’est qu’un fantasme.

Parlons à nouveau de la « réponse ultime » : les idéaux, Tesla et OpenAI atteignent le même objectif par des chemins différents
Tout comme Musk a souligné à plusieurs reprises que "Tesla est une entreprise d'IA et de robotique, pas seulement un constructeur automobile". Dans l'interview, Lang Xianpeng et Jia Peng ont également comparé la voiture idéale à un robot sur roues et ont également parlé de l'application du prototype. de porteurs intelligents incarnés tels que des robots humanoïdes utilisant le cadre « de bout en bout + VLM ».
Le robot Optimus de Tesla porte la vision plus large de Musk et est bien sûr un autre porteur de FSD, car le robot Optimus publie relativement peu d'informations, mais il a un modèle « de bout en bout » qui s'appuie sur les caméras et les capteurs locaux. puis produisez directement des séquences de contrôle conjointes.
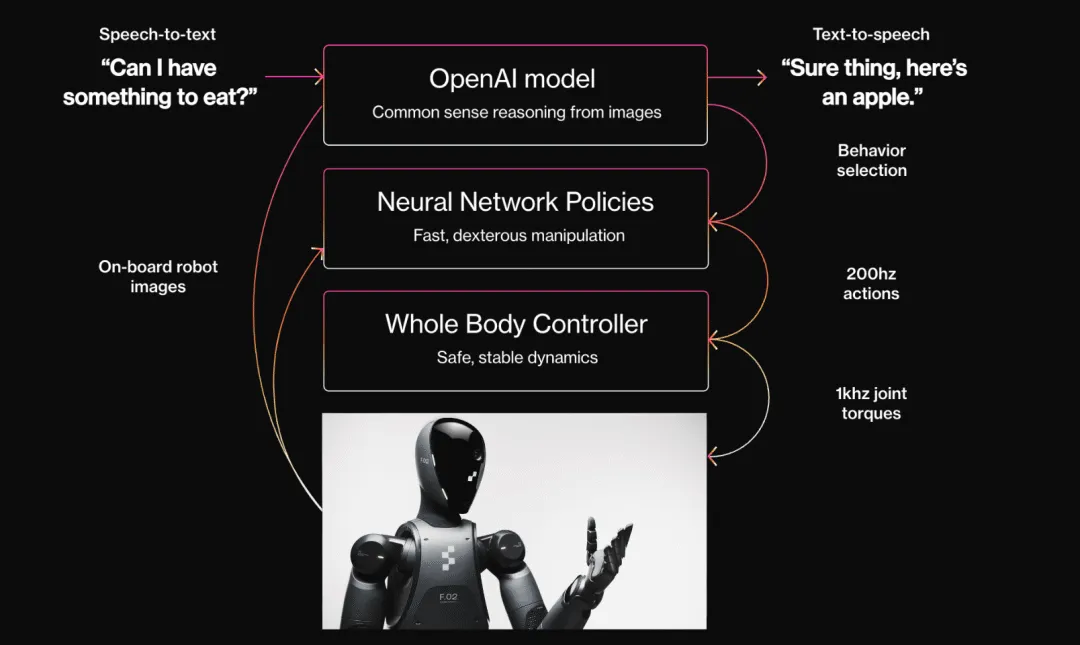
De plus, OpenAI et Figure Robots, investis par NVIDIA, viennent de sortir leur deuxième robot humanoïde, Figure 02, affirmant qu'il s'agit du « matériel d'IA le plus avancé au monde », dans lequel le modèle de langage visuel VLM constitue sa capacité importante. Équipé de six caméras RVB chacune sur la tête, sur le torse avant et arrière, la Figure 02 est capable de détecter et de comprendre le monde physique grâce à son système de vision piloté par l'IA. Dans la description officielle, la figure 02 « a une vision surhumaine ».
Bien entendu, il dispose également d’un grand modèle de langage fourni par OpenAI pour communiquer avec les humains.

De la même manière, le robot Optimus a commencé à travailler (et à s'entraîner) dans l'usine automobile de Tesla, et la figure 02 a également été testée et formée dans l'usine automobile de BMW. Tous deux sont capables d'accomplir des tâches simples et évoluent constamment.
Bien que la voiture idéale, le robot Tesla Optimus et le robot Figure semblent avoir peu de corrélation, une fois que l'on creuse plus profondément, la logique technique sous-jacente et la réflexion sur l'IA sont en effet des approches différentes du même objectif. C'est aussi l'origine de la « réponse ultime ». .
Nous parlons d’intelligence artificielle depuis des décennies, et l’attention s’est finalement déplacée de l’intelligence artificielle vers l’intelligence.
# Bienvenue pour suivre le compte public officiel WeChat d'Aifaner : Aifaner (ID WeChat : ifanr). Un contenu plus passionnant vous sera fourni dès que possible.
Ai Faner | Lien original · Voir les commentaires · Sina Weibo