
Les derniers produits d’OpenAI sont entièrement exposés ! Ultraman réfute que le développement de l’IA se soit heurté à un mur. Ilya admet son erreur et cherche secrètement la prochaine avancée majeure.

Cette année, il y a vraiment des vagues d'enthousiasme dans le cercle de l'IA.
Récemment, des nouvelles selon lesquelles les lois de mise à l'échelle « heurtent le mur » ont explosé dans le cercle de l'IA. Yann Lecun, Ilya et le fondateur d'Anthropic, Dario Amodei, lauréats du prix Turing, ont lancé une guerre des mots.
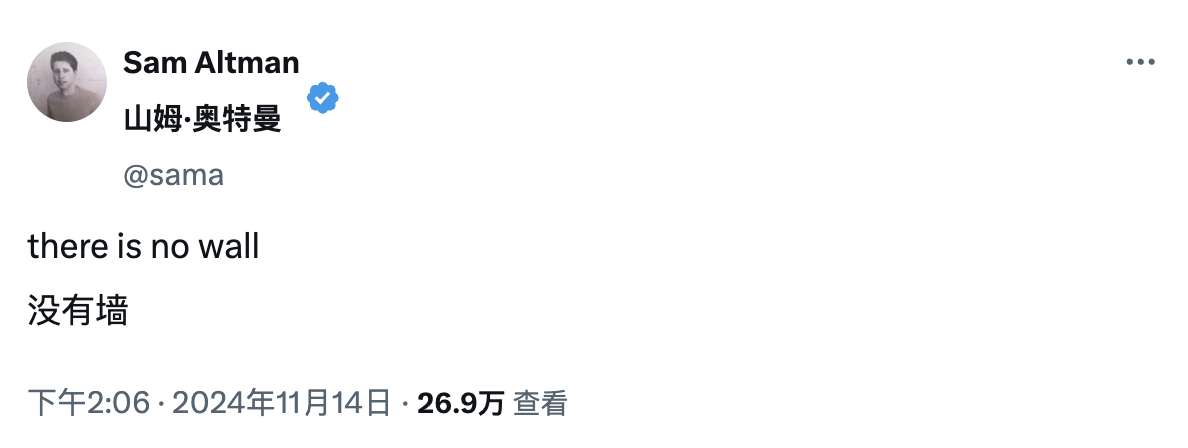
Au cœur du débat se trouve la question de savoir s’il y aura un plafond aux améliorations de performances à mesure que la taille des modèles continue de croître. Alors que l’opinion publique s’intensifie, Sam Altman, PDG d’OpenAI, vient de répondre sur la plateforme X :
"il n'y a pas de mur, il n'y a pas de mur"
Dans le cadre de ce débat, Bloomberg a révélé une nouvelle marquante.
OpenAI prévoit de lancer un agent IA appelé « Operator » en janvier de l'année prochaine. Cet agent peut utiliser des ordinateurs pour effectuer des tâches au nom des utilisateurs, telles que l'écriture de code ou la réservation de voyages.
Avant cela, Anthropic, Microsoft et Google planifiaient également des projets dans des directions similaires.
Pour l’ensemble du secteur de l’IA, le développement de la technologie de l’IA n’a jamais été un processus linéaire unidimensionnel. Lorsqu’une direction semble rencontrer de la résistance, l’innovation perce souvent dans d’autres dimensions.
Faire évoluer les lois Vous heurter un mur ? Quelle est la prochaine étape ?
La nouvelle selon laquelle Scaling Laws a rencontré des goulots d'étranglement est venue pour la première fois d'un rapport du média étranger The Information le week-end dernier.
Le rapport éloquent de milliers de mots a révélé deux informations clés.
La bonne nouvelle est que bien qu'OpenAI ait terminé 20 % du processus de formation du modèle Orion de nouvelle génération, Altman a déclaré qu'Orion est déjà à égalité avec GPT-4 en termes d'intelligence et de capacité à effectuer des tâches et à répondre aux questions.
La mauvaise nouvelle est que, selon l'évaluation des employés d'OpenAI qui l'ont utilisé, par rapport aux énormes progrès entre GPT-3 et GPT-4, Orion présente une amélioration moindre, comme une mauvaise performance sur des tâches telles que la programmation, et une amélioration plus élevée. frais de fonctionnement.
En une phrase, Scaling Laws a rencontré un goulot d'étranglement.

Pour comprendre l'impact du fait que les lois de mise à l'échelle ne sont pas aussi bonnes que prévu, nous devons présenter brièvement les concepts de base des lois de mise à l'échelle à des amis qui ne les connaissent pas.
En 2020, OpenAI a proposé pour la première fois des lois de mise à l'échelle dans un article.
Cette théorie souligne que les performances finales d'un grand modèle sont principalement liées à la quantité de calcul, à la quantité de paramètres du modèle et à la quantité de données d'entraînement, et n'ont fondamentalement rien à voir avec la structure spécifique du modèle (nombre de couches /profondeur/largeur).
Cela semble un peu gênant, mais en termes humains, les performances des grands modèles augmenteront en conséquence à mesure que la taille du modèle, le volume des données d'entraînement et les ressources informatiques augmenteront.
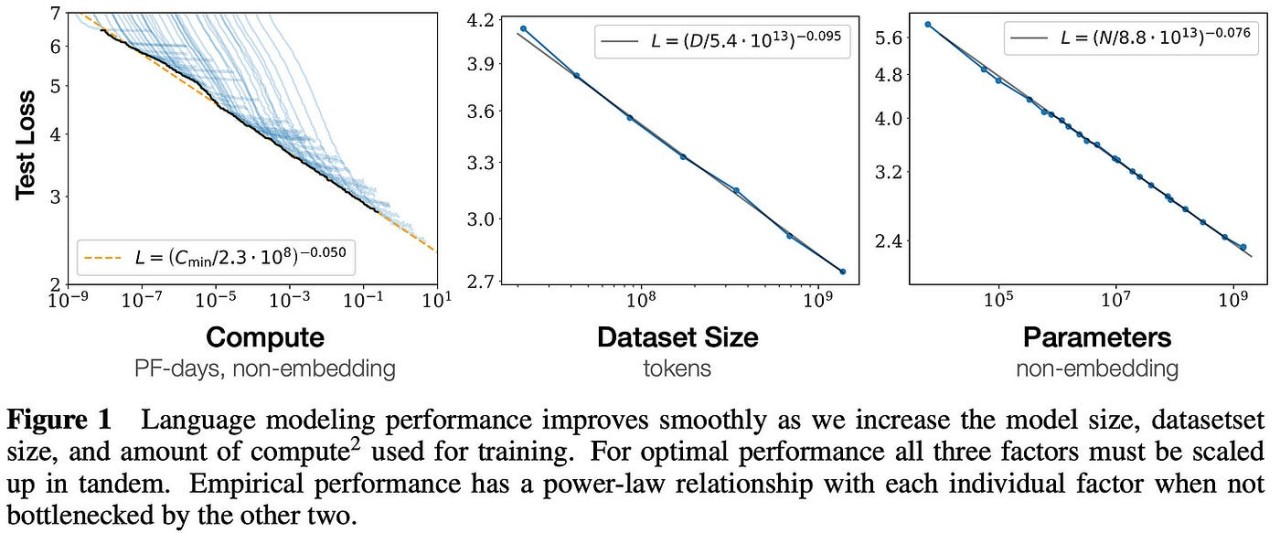
Cette recherche d'OpenAI a jeté les bases du développement ultérieur de grands modèles. Elle a non seulement contribué au succès de la série de modèles GPT, mais a également fourni des principes directeurs clés pour l'optimisation de la conception des modèles et de la formation pour ChatGPT.
Cependant, alors que nous pensons encore au GPT-100, les révélations de The Information indiquent que la simple augmentation de la taille du modèle ne peut plus garantir une amélioration linéaire des performances et s'accompagne de coûts élevés et d'avantages marginaux en diminution significative.
Et OpenAI n’est pas le seul à rencontrer des difficultés.
Bloomberg a cité des personnes proches du dossier affirmant que Gemini 2.0, propriété de Google, n'avait pas non plus atteint les objectifs attendus. Dans le même temps, la sortie de Claude 3.5 Opus, propriété d'Anthropic, avait également été retardée à plusieurs reprises.
Dans l’industrie de l’IA qui court contre la montre, les nouvelles nouvelles sans produit sont souvent les plus mauvaises nouvelles.

Il doit être clair que le goulot d'étranglement des lois de mise à l'échelle mentionné ici ne signifie pas la fin du développement de grands modèles. Le problème plus profond est que les coûts élevés entraînent une diminution importante des rendements des bénéfices marginaux.
Le PDG d'Anthropic, Dario Amodei, a révélé un jour qu'à mesure que les modèles deviennent de plus en plus grands, les coûts de formation ont explosé et que le coût de formation du modèle d'IA en cours de développement s'élève à 1 milliard de dollars.
Amodei a également souligné qu'au cours des trois prochaines années, le coût de la formation en IA atteindra des chiffres astronomiques de 10 milliards de dollars, voire 100 milliards de dollars.
En prenant la série GPT comme exemple, le coût de formation unique du GPT-3 s'élève à lui seul à environ 1,4 million de dollars américains. Ces dépenses proviennent principalement de la consommation de ressources informatiques puissantes, en particulier de l'utilisation de GPU, et d'énormes dépenses en électricité.
La formation du GPT-3 a consommé à elle seule 1 287 MWh d’électricité.

L'année dernière, une étude de l'Université de Californie à Riverside a montré que ChatGPT consomme 500 millilitres d'eau pour 25 à 50 questions posées aux utilisateurs. On estime que d'ici 2027, la demande annuelle d'eau douce propre pour l'IA mondiale pourrait atteindre 4,2 à 6,6. milliards de mètres cubes.
De GPT-2 à GPT-3 puis à GPT-4, l’amélioration de l’expérience apportée par l’IA a été à pas de géant.
C’est précisément sur la base de ces progrès remarquables que les grandes entreprises vont investir massivement dans le domaine de l’IA. Mais lorsque ce chemin touche progressivement à sa fin, la simple poursuite de l’expansion de l’échelle du modèle ne peut plus garantir une amélioration significative des performances. Les coûts élevés et la diminution des bénéfices marginaux sont devenus une réalité à laquelle il faut faire face.
Désormais, plutôt que de poursuivre aveuglément le dimensionnement, il est plus important de mettre en œuvre le dimensionnement dans la bonne direction.
Au revoir, GPT bonjour, raisonnement "O"
Tout le monde rejette le mur, même la théorie.
Lorsque la nouvelle selon laquelle Scaling Laws était soupçonné de rencontrer un goulot d'étranglement a provoqué un tollé dans le cercle de l'IA, des voix de doute ont également éclaté.
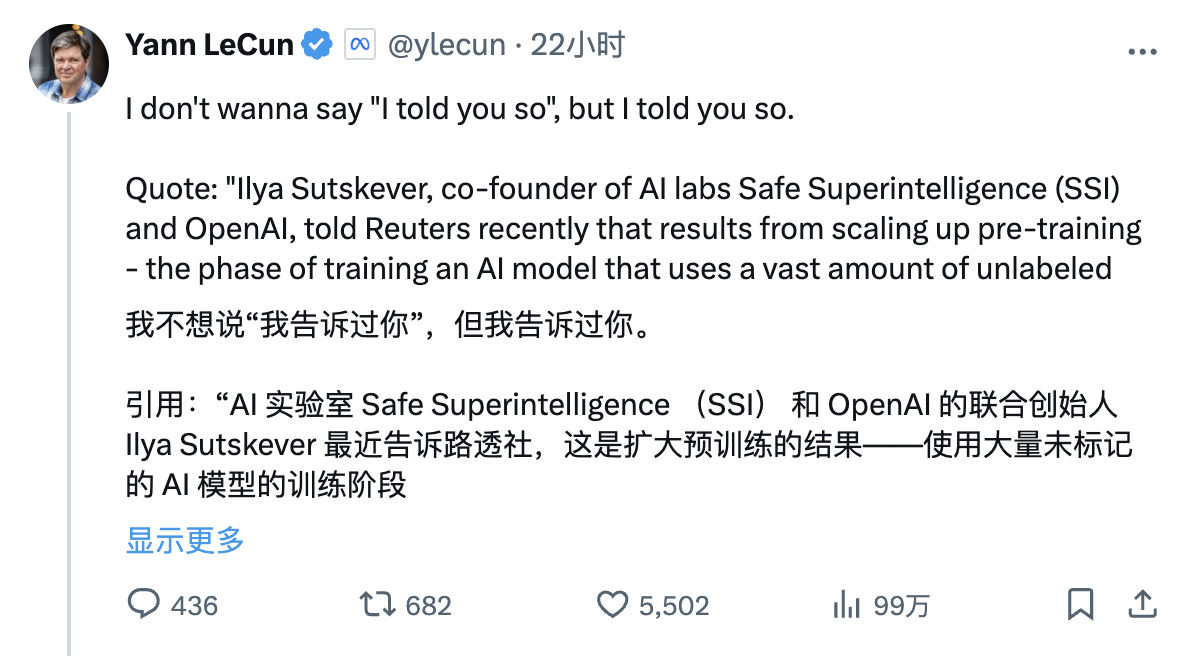
Yann Lecun, lauréat du Turing Award et scientifique en chef de Meta AI, qui a toujours adopté une position anti-mainstream, a republié avec enthousiasme l'interview de Reuters avec Ilya Sutskever sur la plateforme X hier, avec l'article suivant :
"Je ne veux pas avoir l'air d'une réflexion après coup, mais je vous l'ai rappelé.
Citation : « Ilya Sutskever, co-fondateur des laboratoires d'IA Safe Superintelligence (SSI) et OpenAI, a récemment déclaré à Reuters qu'en élargissant l'étape de pré-formation, c'est-à-dire en utilisant de grandes quantités de données non étiquetées, pour entraîner des modèles d'IA à comprendre les modèles de langage et structures – les résultats sont au point mort.
En regardant l'évaluation par le géant de l'IA de l'itinéraire actuel des grands modèles au cours des deux dernières années, on peut dire que chaque mot est méticuleux et chaque phrase est sanglante.
Par exemple, l'IA d'aujourd'hui est plus bête qu'un chat, et son intelligence est loin derrière ; LLM manque d'expérience directe du monde physique et ne manipule que du texte et des images sans vraiment comprendre le monde. Si elle continue à se forcer, elle ne fera que conduire à des choses. une impasse, etc.
En remontant le temps, il y a deux mois, Yann Lecun a condamné sans ménagement à mort la ligne dominante actuelle. Parmi les nombreuses théories apocalyptiques sur l’IA, il croit également fermement que les affirmations selon lesquelles l’IA menacerait la survie humaine sont un pur non-sens :
- Les grands modèles de langage (LLM) ne peuvent pas répondre aux questions non incluses dans leurs données de formation,
- Ils ne peuvent pas résoudre des problèmes difficiles pour lesquels ils ne sont pas formés,
- Ils ne peuvent pas acquérir de nouvelles compétences ou connaissances sans une aide humaine significative,
- Ils ne peuvent pas créer de nouvelles choses. Actuellement, les grands modèles de langage ne constituent qu’une partie de la technologie de l’intelligence artificielle. Le simple fait de développer ces modèles ne les rendra pas capables de cela.

Le Dr Tian Yuandong, qui travaille également chez Meta FAIR, a prévu plus tôt le dilemme actuel.
Dans une interview avec les médias en mai, le scientifique chinois a déclaré avec pessimisme que les lois de mise à l'échelle étaient peut-être justes, mais que ce ne serait pas tout. Selon lui, l'essence des lois de mise à l'échelle est d'échanger une croissance exponentielle des données contre « quelques points de gain ».
"En fin de compte, le monde humain peut avoir de nombreux besoins à long terme, qui nécessitent que les humains réagissent rapidement. Les données elles-mêmes dans ces scénarios sont très petites et LLM ne peut pas les obtenir. En fin de compte, lorsque la loi d'échelle se développera, tout le monde pourra se tenir sur les mêmes « données » Sur « l'île isolée », les données de l'île isolée appartiennent entièrement à tout le monde, et elles sont constamment générées à chaque instant. Les experts apprennent à s’intégrer à l’IA et deviennent très puissants, et l’IA ne peut pas les remplacer. "

Cependant, la situation n’est peut-être pas encore aussi pessimiste.
Objectivement parlant, dans une interview avec Reuters, Ilya a admis que les progrès apportés par les lois Scaling étaient au point mort, mais n'a pas déclaré la fin.
« Les années 2010 ont été l'ère de la mise à l'échelle, et maintenant nous entrons à nouveau dans une nouvelle ère d'émerveillement et de découverte. Tout le monde est à la recherche de la prochaine grande avancée. Aujourd'hui, il est plus important que jamais de choisir les bonnes choses à mettre à l'échelle. important."
En outre, Ilya a également déclaré que SSI étudiait une nouvelle méthode pour élargir le processus de pré-formation.
Dario Amodei en a également récemment parlé dans un podcast.
Il prédit qu’il n’y a pas de plafond absolu pour les modèles inférieurs au niveau humain. Puisque le modèle n’a pas encore atteint le niveau humain, on ne peut pas dire que les lois de mise à l’échelle ont échoué, mais qu’il y a bel et bien eu un ralentissement de la croissance.

Depuis les temps anciens, les montagnes n’ont pas changé et l’eau a changé, et l’eau n’a pas changé et les gens ont changé.
Le mois dernier, Noam Brown, chercheur à OpenAI, a déclaré lors de la conférence TED AI :
"Il s'avère que demander à un robot de réfléchir pendant 20 secondes pendant une partie de poker donne la même amélioration des performances que de redimensionner le modèle 100 000 fois et de l'entraîner 100 000 fois plus longtemps."
Quant aux remarques rétrospectives de Yann Lecun hier, il a répondu ainsi :
« À l'heure actuelle, nous sommes dans un monde où, comme je l'ai déjà dit, le coût de calcul requis pour se lancer dans la pré-formation sur un modèle de langage à grande échelle est très, très élevé. Mais le coût de l'inférence est très faible. beaucoup de gens s'inquiétaient à juste titre du fait qu'avec la pré-formation, le coût et la quantité de données nécessaires à la formation devenaient si énormes que nous allions voir des rendements décroissants sur les progrès de l'IA. Mais je pense que l'un des points à retenir vraiment importants de o1 est. que ce mur n'existe pas et que nous pouvons réellement aller plus loin. Promouvoir ce processus parce que maintenant, nous pouvons développer l'informatique inférentielle, et il y a une énorme marge pour l'expansion de l'informatique inférentielle.
Les chercheurs représentés par Noam Brown croient fermement que le calcul d’inférence/temps de test est susceptible de devenir une autre panacée pour améliorer les performances des modèles.
En parlant de cela, nous devons mentionner le modèle familier OpenAI o1.
Tout à fait similaire au raisonnement humain, le modèle o1 peut « réfléchir » aux problèmes grâce à un raisonnement en plusieurs étapes. Il met l'accent sur le fait de donner au modèle plus de « temps de réflexion » pendant la phase de raisonnement. Son secret principal est celui d'un réseau comme GPT-4. sur le modèle de base.
Par exemple, les modèles peuvent finalement choisir la meilleure voie à suivre en générant et en évaluant plusieurs réponses possibles en temps réel, plutôt que de choisir une seule réponse immédiatement. Cela permet de concentrer davantage de ressources informatiques sur des tâches complexes, telles que des problèmes mathématiques et des puzzles de programmation. , ou ces opérations complexes qui nécessitent un raisonnement et une prise de décision de type humain.

Google a récemment suivi cette voie.
The Information rapporte qu'au cours des dernières semaines, DeepMind a formé une équipe au sein de sa division Gemini, dirigée par le chercheur en chef Jack Rae et l'ancien co-fondateur de Character.AI Noam Shazeer, pour développer des capacités similaires.
Dans le même temps, Google, pour ne pas être en reste, essaie de nouvelles voies techniques, notamment en ajustant les « hyperparamètres », qui sont des variables qui déterminent la manière dont le modèle traite les informations, comme la rapidité avec laquelle il établit des liens entre différents concepts ou modèles dans la formation. données et voir quelles variables conduisent aux meilleurs résultats.
En passant, une raison importante du ralentissement du développement du GPT est le manque de texte de haute qualité et d'autres données disponibles.
En réponse à ce problème, les chercheurs de Google espéraient à l'origine utiliser l'IA pour synthétiser des données et incorporer de l'audio et de la vidéo dans les données d'entraînement de Gemini afin d'obtenir des améliorations significatives, mais ces tentatives semblaient avoir peu d'effet.
Des personnes proches du dossier ont également révélé qu'OpenAI et d'autres développeurs utilisent également des données synthétiques. Cependant, ils ont également constaté que l’effet des données synthétiques sur l’amélioration des modèles d’IA est très limité.
Bonjour Jarvis
Adieu GPT, bonjour le raisonnement "o".
Lors d'un récent événement Reddit AMA, un internaute a demandé à Altman si « GPT-5 » et une version complète du modèle d'inférence o1 seraient lancés.
À l'époque, Altman avait répondu : « Nous donnons la priorité au lancement de o1 et de ses versions ultérieures », ajoutant que les ressources informatiques limitées rendent difficile le lancement de plusieurs produits en même temps.
Il a également souligné que le modèle de nouvelle génération pourrait ne plus continuer à s'appeler « GPT ».

Il semble maintenant qu'Altman soit désireux de tracer une ligne claire avec le système de dénomination GPT et lance à la place un modèle d'inférence nommé « o ». Il semble y avoir une signification profonde derrière cela. La présentation du modèle d'inférence peut encore jeter les bases de l'agent traditionnel actuel.
Récemment, Altman a également parlé à nouveau de la théorie AGI à cinq niveaux dans une interview avec le président de YC, Garry Tan :
- L1 : Les robots de chat sont des IA dotées de capacités conversationnelles qui peuvent avoir des conversations fluides avec les utilisateurs, fournir des informations, répondre aux questions, aider à la création, etc., comme les robots de chat.
- L2 : IA dont les raisonneurs peuvent résoudre des problèmes comme les humains, peuvent résoudre des problèmes complexes similaires aux niveaux de doctorat humains et démontrer de puissantes capacités de raisonnement et de résolution de problèmes, comme OpenAI o1.
- L3 : un système d'IA dans lequel l'agent peut non seulement penser, mais aussi agir, et effectuer des activités entièrement automatisées.
- L4 : L'IA que les innovateurs peuvent aider à l'invention et à la création a la capacité d'innover et peut aider les humains à générer de nouvelles idées et solutions dans des domaines tels que la découverte scientifique, la création artistique ou la conception technique.
- L5 : L'IA qui permet aux organisateurs d'effectuer le travail organisationnel et de contrôler automatiquement la planification, l'exécution, le retour d'information, l'itération, l'allocation des ressources, la gestion, etc. des processus inter-métiers de l'ensemble de l'organisation, est fondamentalement similaire aux humains.
Nous constatons donc que, comme Google et Anthropic, OpenAI se concentre désormais des modèles vers une série d’outils d’IA appelés Agents.
Récemment, Bloomberg a également révélé qu'OpenAI se préparait à lancer un nouvel agent d'IA appelé « Operator », qui peut utiliser des ordinateurs pour effectuer des tâches au nom des utilisateurs, telles que l'écriture de code ou la réservation de voyages.
Lors d'une réunion du personnel mercredi, la direction d'OpenAI a annoncé son intention de publier un aperçu de recherche de l'outil en janvier et de le mettre à la disposition des développeurs via l'interface de programmation d'applications (API) de l'entreprise.
Avant cela, Anthropic avait également lancé un agent similaire, capable de traiter les tâches informatiques des utilisateurs en temps réel et d'effectuer des opérations en son nom. Dans le même temps, Microsoft a récemment lancé un ensemble d'outils Agent destinés aux employés pour l'envoi d'e-mails et la gestion des enregistrements.

Google se prépare également à lancer son propre AI Agent.
Le rapport révèle également qu'OpenAI mène plusieurs projets de recherche liés aux agents. Le plus proche de l'achèvement est un outil universel capable d'effectuer des tâches dans un navigateur Web.
Ces agents sont censés être capables de comprendre, de raisonner, de planifier et d’agir, mais ces agents sont en réalité un système composé de plusieurs modèles d’IA, et non d’un modèle unique.
Bill Gates a dit un jour : « Il y a un PC sur chaque ordinateur de bureau », et Steve Jobs a déclaré : « Tout le monde a un smartphone à la main ». Nous pouvons désormais le prédire avec audace : chacun aura son propre agent IA.
Bien sûr, le but ultime de l’humanité est d’espérer qu’un jour nous puissions parler du dialogue classique du film à l’IA devant nous :
Bonjour Jarvis
# Bienvenue pour suivre le compte public officiel WeChat d'Aifaner : Aifaner (ID WeChat : ifanr). Un contenu plus passionnant vous sera fourni dès que possible.
Ai Faner | Lien original · Voir les commentaires · Sina Weibo