
Le modèle de nouvelle génération d’OpenAI rencontre des goulots d’étranglement majeurs, un ancien scientifique en chef révèle une nouvelle voie technologique

Le grand modèle de langage de nouvelle génération « Orion » d'OpenAI a peut-être rencontré un goulot d'étranglement sans précédent.
Selon The Information, les employés internes d'OpenAI ont déclaré que l'amélioration des performances du modèle Orion ne répondait pas aux attentes et que l'amélioration de la qualité était « beaucoup plus faible » que la mise à niveau de GPT-3 vers GPT-4.
De plus, ils ont déclaré qu’Orion n’était pas plus fiable que son prédécesseur, GPT-4, pour certaines tâches. Bien qu'Orion ait de meilleures compétences linguistiques , il ne pourra peut-être pas surpasser GPT-4 en termes de programmation .

▲Source de l'image : WeeTech
Le rapport souligne que l'offre de textes et d'autres données de haute qualité pour la formation diminue, ce qui rend plus difficile la recherche de bonnes données de formation, ralentissant ainsi le développement de grands modèles linguistiques (LLM) à certains égards.
De plus, les futures formations consommeront davantage de ressources informatiques, de ressources financières et même d'électricité . Cela signifie que le coût et le coût de développement et d'exploitation d'Orion et des grands modèles de langage ultérieurs deviendront plus élevés.
Noam Brown, chercheur à OpenAI, a récemment déclaré lors de la conférence TED AI que des modèles plus avancés pourraient ne pas être « économiquement réalisables » :
Devons-nous vraiment dépenser des centaines de milliards ou des milliards de dollars pour des modèles de formation ? À un moment donné, la loi de l’expansion s’effondre.
À cet égard, OpenAI a créé une équipe de base dirigée par Nick Ryder, responsable de la pré-formation, pour étudier comment gérer le manque de données de formation et combien de temps dureront les lois d'échelle des grands modèles.

▲Noam Brown
Les lois de mise à l'échelle sont une hypothèse fondamentale dans le domaine de l'intelligence artificielle : tant qu'il y aura plus de données à partir desquelles apprendre et plus de puissance de calcul pour faciliter le processus de formation, les grands modèles de langage peuvent continuer à améliorer les performances au même rythme.
En termes simples, les lois de mise à l'échelle décrivent la relation entre l'entrée (volume de données, puissance de calcul, taille du modèle) et la sortie, c'est-à-dire la mesure dans laquelle les performances s'améliorent lorsque nous investissons plus de ressources dans un modèle de langage volumineux.
Par exemple, former un grand modèle de langage, c'est comme construire une voiture dans un atelier . Au départ, l'atelier était petit, avec seulement quelques machines et quelques ouvriers. A ce moment, chaque machine ou travailleur supplémentaire peut augmenter considérablement la production, car ces nouvelles ressources sont directement converties en augmentation de la capacité de production.
À mesure qu’une usine grandit, l’augmentation de la production de chaque machine ou travailleur supplémentaire commence à diminuer. Il se pourrait que la gestion soit devenue plus complexe ou que la coordination entre les travailleurs soit devenue plus difficile.
Lorsqu’une usine atteint une certaine taille, l’ajout de machines et de travailleurs supplémentaires ne peut augmenter la production que dans une mesure très limitée. À ce stade, l'usine approche peut-être des limites du terrain, de l'approvisionnement en électricité, de la logistique, etc., et l'augmentation des intrants ne peut plus entraîner une augmentation proportionnelle de la production .

Et c’est là que réside le dilemme d’Orion. À mesure que la taille du modèle augmente (de la même manière que l’on ajoute des machines et des travailleurs), l’amélioration des performances du modèle peut être très évidente au début et à moyen terme. Mais à un stade ultérieur, même si la taille du modèle ou la quantité de données d'entraînement continue d'augmenter, l'amélioration des performances peut devenir de plus en plus petite. C'est ce qu'on appelle « frapper le mur ».
Un article récent publié sur arXiv a également déclaré qu'avec la demande croissante de données textuelles humaines publiques et la quantité limitée de données existantes, on s'attend à ce que le développement de grands modèles de langage épuise les ressources actuelles entre 2026 et 2032. ressources de données textuelles humaines.
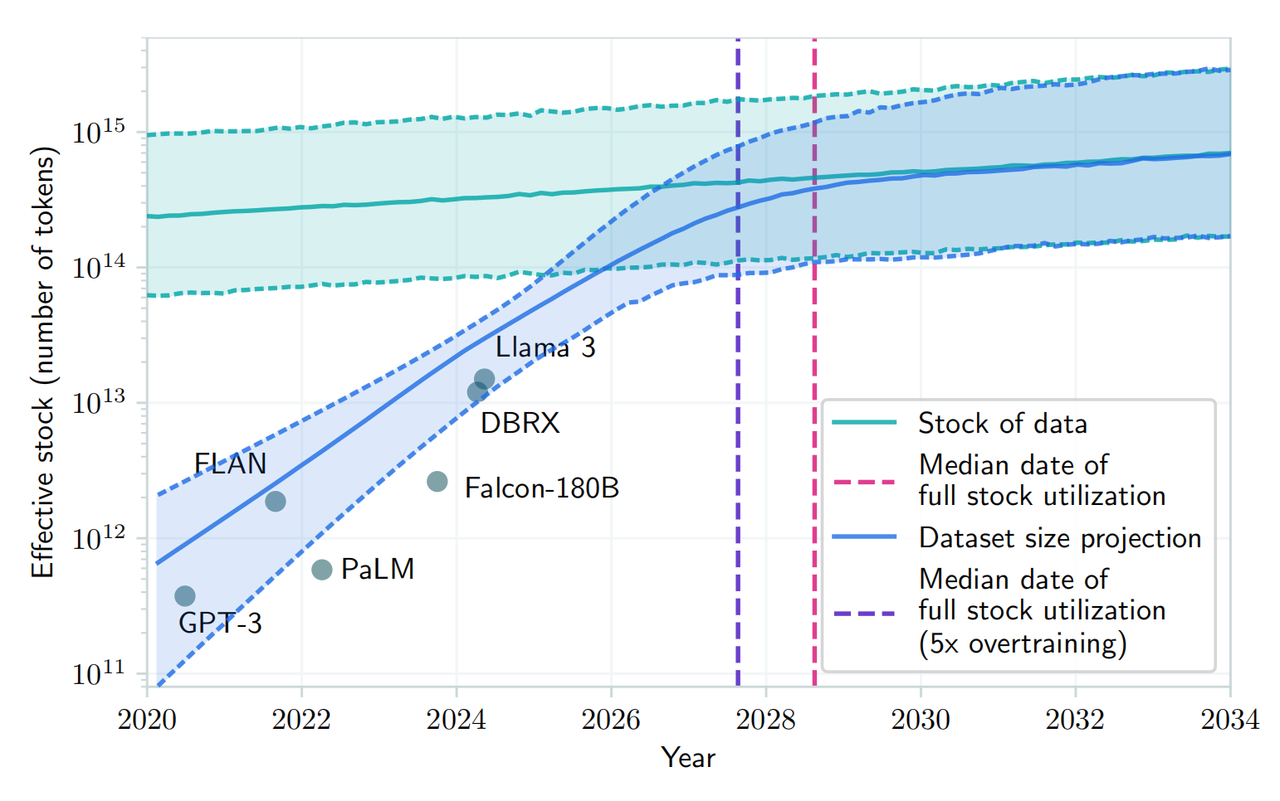
▲Source de l'image : arXiv
Même si Norm Brown a souligné les « problèmes économiques » de la future formation des modèles, il s'est toujours opposé au point de vue ci-dessus. Il estime que « le développement de l'intelligence artificielle ne va pas ralentir de si tôt ».
Les chercheurs d’OpenAI sont largement d’accord. Ils estiment que même si la loi d'expansion du modèle peut ralentir, le développement global de l'IA ne sera pas affecté par l'optimisation du temps d'inférence et les améliorations post-formation.
De plus, les PDG de Mark Zuckerberg de Meta, Sam Altman d'OpenAI et d'autres développeurs d'IA ont déclaré publiquement qu'ils n'avaient pas encore atteint les limites des lois traditionnelles de mise à l'échelle et qu'ils développaient toujours des centres de données coûteux pour augmenter les performances des modèles pré-entraînés.

▲Sam Altman (Source : Vanity Fair)
Peter Welinder, vice-président des produits d'OpenAI, a également déclaré sur les réseaux sociaux que "les gens sous-estiment la puissance de l'informatique lors des tests ".
Le calcul au moment du test (TTC) est un concept d'apprentissage automatique qui fait référence aux calculs effectués lors de la déduction ou de la prédiction de nouvelles données d'entrée après le déploiement du modèle. Ceci est distinct des calculs de la phase de formation du modèle, où le modèle apprend des modèles dans les données et fait des prédictions.
Dans les modèles d'apprentissage automatique traditionnels, une fois le modèle formé et déployé, il ne nécessite généralement aucun calcul supplémentaire pour effectuer des prédictions sur de nouvelles instances de données. Cependant, dans certains modèles plus complexes, tels que certains types de modèles d'apprentissage profond, des calculs supplémentaires peuvent être nécessaires au moment du test (c'est-à-dire au moment de l'inférence).
Par exemple, le modèle « o1 » développé par OpenAI utilise ce modèle de raisonnement. En fait, l’ensemble du secteur de l’IA se concentre désormais sur un modèle qui améliore les modèles après une formation initiale .

▲Peter Welinder (Source : Dagens industri)
À cet égard, Ilya Sutskever, l'un des cofondateurs d'OpenAI, a admis dans une récente interview avec Reuters qu'en utilisant de grandes quantités de données non étiquetées pour former des modèles d'intelligence artificielle afin de comprendre les modèles et les structures du langage au stade de pré-formation, son L'amélioration de l'effet s'est stabilisée .
"Les années 2010 ont été une ère d'expansion, et maintenant nous sommes de retour à une ère d'exploration et de découverte", a déclaré Ilya, soulignant que " passer à la bonne échelle est plus important que jamais".
Orion devrait être lancé en 2025. OpenAI l'a nommé « Orion » au lieu de « GPT-5 », ce qui pourrait laisser présager une nouvelle révolution. Bien qu'il soit temporairement « difficile d'accoucher » en raison de limitations théoriques, nous attendons toujours avec impatience ce « nouveau-né » avec un nouveau nom qui peut apporter de nouvelles opportunités au grand modèle d'IA.
# Bienvenue pour suivre le compte public officiel WeChat d'Aifaner : Aifaner (ID WeChat : ifanr). Un contenu plus passionnant vous sera fourni dès que possible.
Ai Faner | Lien original · Voir les commentaires · Sina Weibo