
Apple travaille avec Nvidia pour rendre l’IA plus réactive

Récemment, Apple et NVIDIA ont annoncé une coopération pour accélérer et optimiser les performances d'inférence des grands modèles de langage (LLM).
Afin d'améliorer la faible efficacité et la petite bande passante mémoire du raisonnement LLM autorégressif traditionnel, plus tôt cette année, les chercheurs en apprentissage automatique d'Apple ont publié et open source une technologie de décodage spéculatif appelée " ReDrafter " (Recurrent Drafter, cyclic draft model).
▲Source : GitHub
Actuellement, ReDrafter a été intégré à la solution d'inférence évolutive de NVIDIA « TensorRT-LLM ». Cette dernière est une bibliothèque open source basée sur le framework de compilation d'apprentissage profond « TensorRT » conçu pour optimiser l'inférence LLM et prend en charge le décodage spéculatif, y compris la méthode « Medusa ».
Cependant, comme les algorithmes inclus dans ReDrafter utilisent des opérateurs qui n'ont jamais été utilisés auparavant, NVIDIA a ajouté de nouveaux opérateurs ou exposé des opérateurs existants, ce qui améliore considérablement l'adaptabilité de TensorRT-LLM aux modèles complexes et aux méthodes de décodage.
▲Source : GitHub
Il est rapporté que le décodage spéculatif ReDrafter accélère le processus de raisonnement LLM grâce à trois technologies clés :
- Projet de modèle RNN
- Algorithme dynamique d'attention aux arbres
- Formation à la distillation des connaissances
Le projet de modèle RNN est le composant « central » de ReDrafter. Il utilise un réseau neuronal récurrent pour prédire la séquence de jetons qui peuvent apparaître ensuite en fonction de « l'état caché » du LLM. Il peut capturer la dépendance temporelle locale, améliorant ainsi la précision de la prédiction.
Le principe de fonctionnement de ce modèle est le suivant : LLM génère d'abord un jeton initial pendant le processus de génération de texte, puis le modèle préliminaire RNN utilise le jeton et le dernier état caché de LLM comme entrée pour effectuer une recherche de faisceau (Beam Search), puis génère séquence de plusieurs jetons candidats.
Contrairement au LLM autorégressif traditionnel, qui ne génère qu'un seul jeton à la fois, ReDrafter peut générer plusieurs jetons à chaque étape de décodage via la sortie de prédiction du modèle de brouillon RNN, ce qui réduit considérablement le nombre de fois où la vérification LLM doit être appelée, améliorant ainsi la vitesse de raisonnement globale.
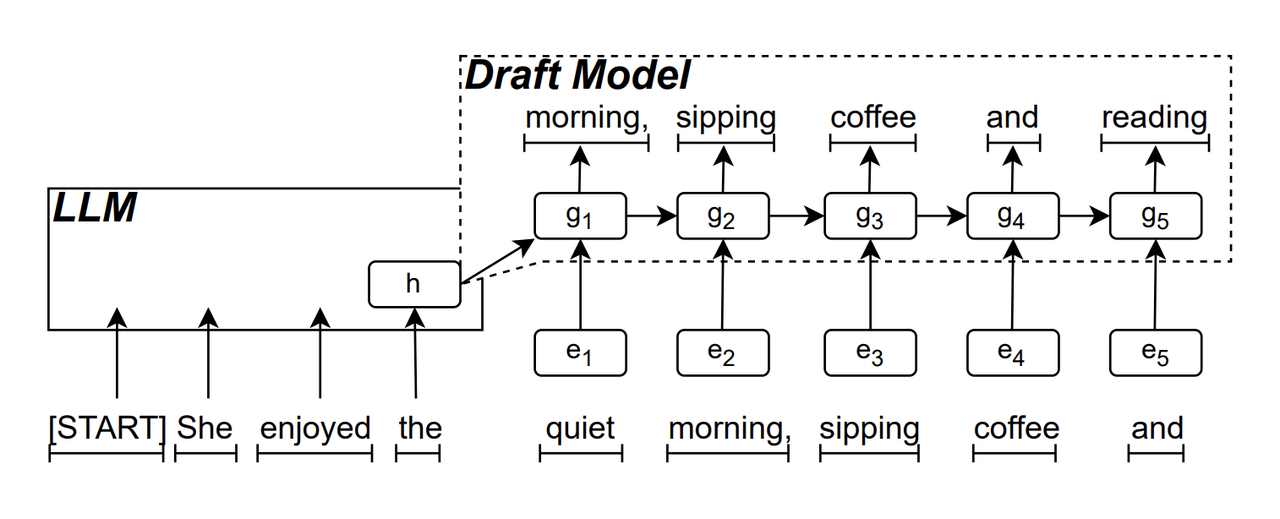
▲Source de l'image : arXiv
Dynamic Tree Attention est un algorithme qui optimise les résultats de recherche de faisceaux.
Nous savons déjà que plusieurs séquences candidates seront générées au cours du processus de recherche de faisceaux et que ces séquences auront souvent des préfixes partagés. L'algorithme d'attention dynamique de l'arborescence identifie ces préfixes partagés et les supprime des jetons qui nécessitent une vérification, réduisant ainsi la quantité de données que LLM doit traiter.
Dans certains cas, cet algorithme peut réduire le nombre de jetons à vérifier de 30 à 60 %. Cela signifie qu'après avoir utilisé l'algorithme d'attention dynamique des arbres, ReDrafter peut utiliser les ressources informatiques plus efficacement et améliorer encore la vitesse d'inférence.
▲Source de l'image : NVIDIA
La distillation des connaissances est une technologie de compression de modèles qui peut « distiller » les connaissances d'un modèle vaste et complexe (modèle d'enseignant) en un modèle plus petit et plus simple (modèle d'élève). Dans ReDrafter, le modèle brouillon RNN sert de modèle étudiant et apprend du LLM (modèle enseignant) grâce à la distillation des connaissances.
Plus précisément, au cours du processus de formation par distillation, LLM donnera une série de « distributions de probabilité » des prochains mots possibles. Les développeurs entraîneront le projet de modèle RNN sur la base de ces données de distribution de probabilité, puis calculeront la différence entre les distributions de probabilité des deux. modèles. Et minimiser cette différence grâce à des algorithmes d’optimisation.
Au cours de ce processus, le projet de modèle RNN apprend en permanence le mode de prédiction probabiliste de LLM, afin de pouvoir générer un texte similaire à LLM dans des applications pratiques.
Grâce à la formation à la distillation des connaissances, le projet de modèle RNN capture mieux les lois et les modèles de langage, prédisant ainsi plus précisément le résultat du LLM, et améliore considérablement les performances de ReDrafter sur un matériel limité en raison de sa plus petite taille et de son coût de calcul d'inférence inférieur. sous conditions.
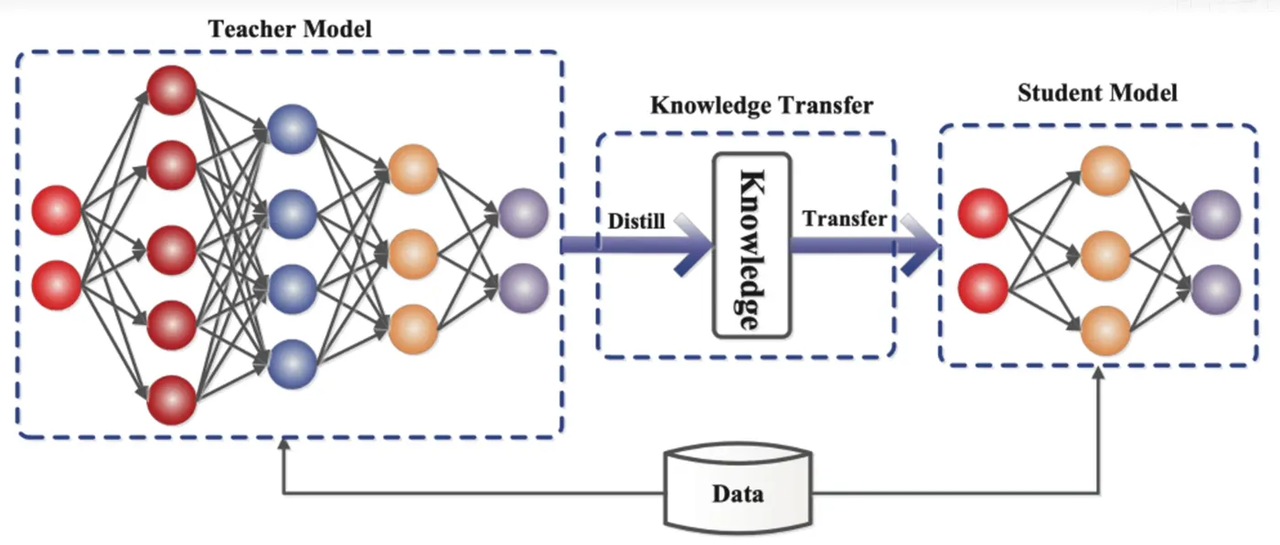
▲Source de l'image : Communauté de développeurs Alibaba Cloud
Les résultats de référence d'Apple montrent que lors de l'utilisation de TensorRT-LLM intégré à ReDrafter sur un modèle de production avec des milliards de paramètres sur le GPU NVIDIA H100, le nombre de jetons générés par seconde par Greedy Decoding a augmenté de 2,7 fois.
De plus, ReDrafter peut également augmenter la vitesse d'inférence de 2,3 fois sur le GPU M2 Ultra Metal d'Apple. Les chercheurs d'Apple ont déclaré que « LLM est de plus en plus utilisé pour piloter les applications de production, et l'amélioration de l'efficacité de l'inférence peut à la fois affecter les coûts informatiques et réduire la latence côté utilisateur ».
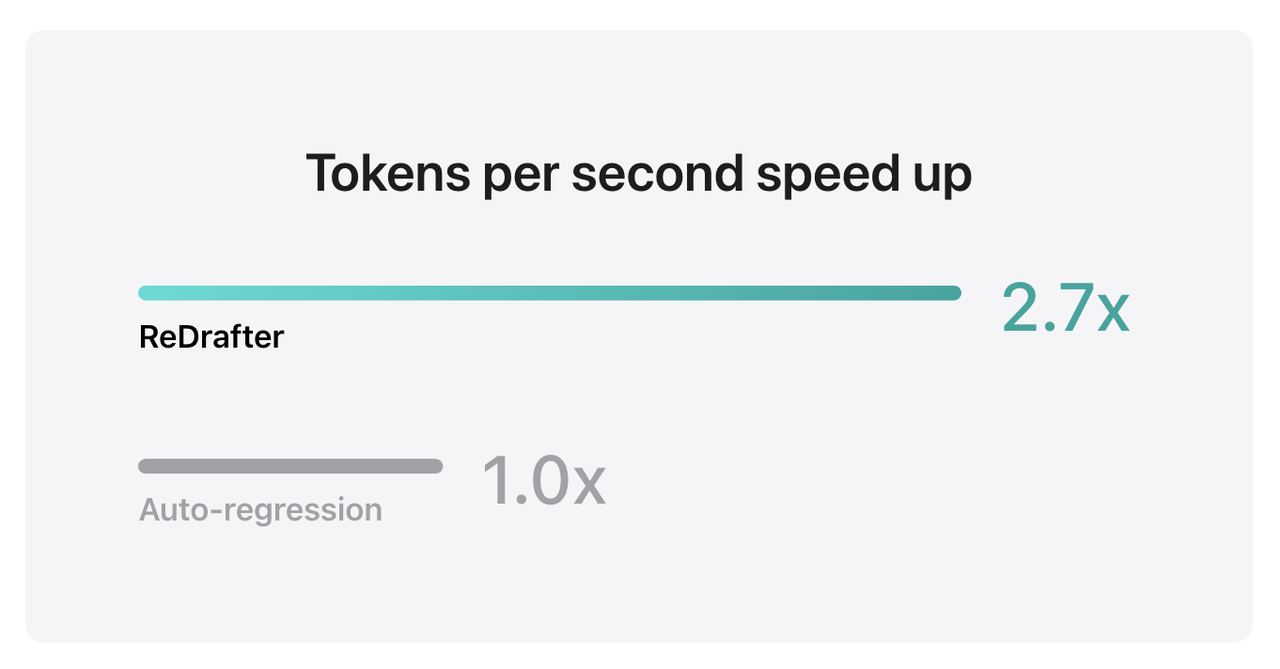
▲Source : Apple
Il convient de mentionner que tout en maintenant la qualité de sortie, ReDrafter réduit la demande de ressources GPU, ce qui permet à LLM de fonctionner efficacement dans des environnements aux ressources limitées et offre la possibilité d'utiliser LLM sur diverses plates-formes matérielles.
Apple a désormais open source cette technologie sur GitHub, et Nvidia sera probablement la seule entreprise à en bénéficier à l'avenir.
# Bienvenue pour suivre le compte public officiel WeChat d'aifaner : aifaner (ID WeChat : ifanr). Un contenu plus passionnant vous sera fourni dès que possible.
Ai Faner | Lien original · Voir les commentaires · Sina Weibo