
OpenAI affirme avoir des preuves de violations de DeepSeek et le PDG d’Anthropic publie un message de 10 000 mots appelant à des contrôles plus stricts aux États-Unis.

DeepSeek a récemment connu des problèmes.
Selon le média étranger Financial Times, OpenAI a déclaré qu'il existe des preuves que DeepSeek a utilisé le modèle d'OpenAI pour développer ses propres produits d'IA open source, ce qui pourrait avoir violé les conditions de service d'OpenAI.
Dans l'industrie de l'IA, il est courant de développer de nouveaux modèles grâce à la technologie de « distillation ». Cependant, OpenAI estime que le comportement de DeepSeek a dépassé la plage acceptable car ils utilisent la technologie OpenAI pour créer un produit concurrent.
Au moment de mettre sous presse, OpenAI a refusé de donner davantage de détails sur les détails spécifiques de ces accusations.
Hier, Bloomberg a rapporté qu'OpenAI et son partenaire Microsoft avaient lancé une enquête sur plusieurs comptes qui utilisaient l'API OpenAI l'année dernière et avaient coupé l'accès aux comptes soupçonnés de distillation de modèles au motif que ces comportements violaient les conditions de service.
Une vague ne s’est pas calmée et une autre vague est apparue.
Selon le média étranger Techcrunch, DeepSeek a déposé une demande de marque auprès de l'Office américain des brevets et des marques (USPTO), dans l'espoir d'enregistrer la marque de ses chatbots, produits et outils d'IA. Mais son application est arrivée tardivement.
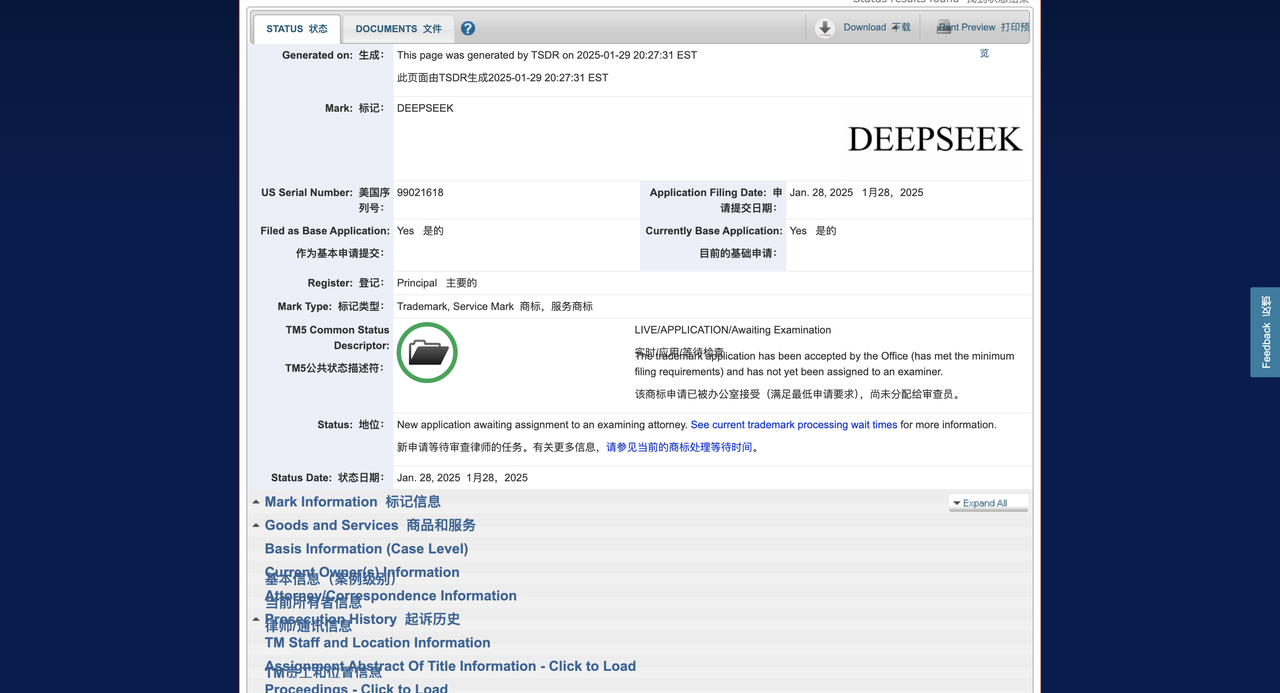
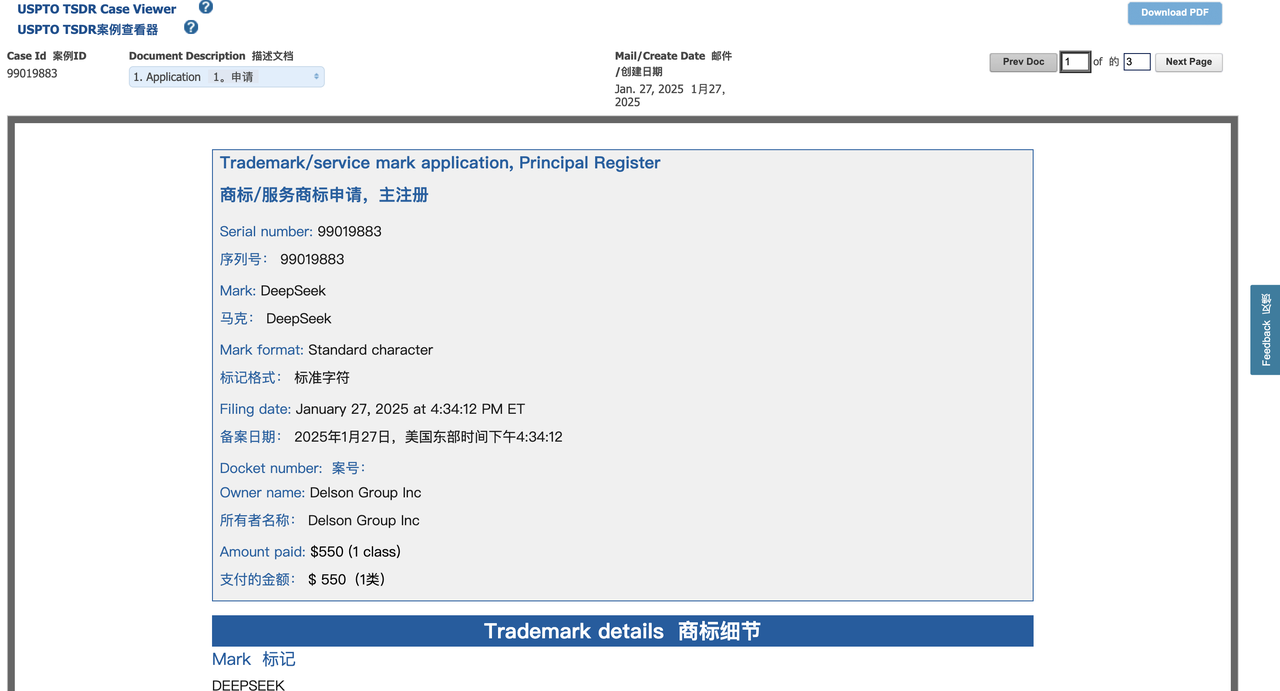
Il y a à peine 36 heures, une société du Delaware appelée Delson Group Inc. a pris les devants en déposant une demande pour la marque « DeepSeek ».
Delson Group affirme vendre des produits d’IA de marque « DeepSeek » depuis 2020. L'adresse enregistrée de la société dans la demande de marque est une maison à Cupertino, et son fondateur et PDG est Willie Lu.
Il est intéressant de noter que Lu et le fondateur de DeepSeek, Liang Wenfeng, sont tous deux des anciens élèves de l'Université du Zhejiang. Selon le profil LinkedIn de Lu, il prétend être un professeur consultant « semi-retraité » à l'Université de Stanford et est également consultant auprès de la Federal Communications Commission (FCC) des États-Unis. Sa carrière se concentre sur le domaine des communications sans fil.
L'enquête de TechCrunch a révélé que Lu avait également organisé un cours éducatif appelé « AI Super-Intelligence » à Las Vegas sous la marque « DeepSeek », avec des billets à partir de 800 $. Le site Web du cours est également répertorié dans le dépôt de marque du groupe Delson et affirme que Lu a environ 30 ans d'expérience dans les domaines des technologies de l'information et des communications (TIC) et de l'intelligence artificielle (IA).
Lorsque TechCrunch a contacté Lu via l'e-mail inclus dans le dépôt de marque, il a proposé de se rencontrer à Palo Alto ou à Saratoga, en Californie (le journaliste était à New York) pour discuter de la question. Mais Lu n'a pas répondu à d'autres demandes de commentaires.
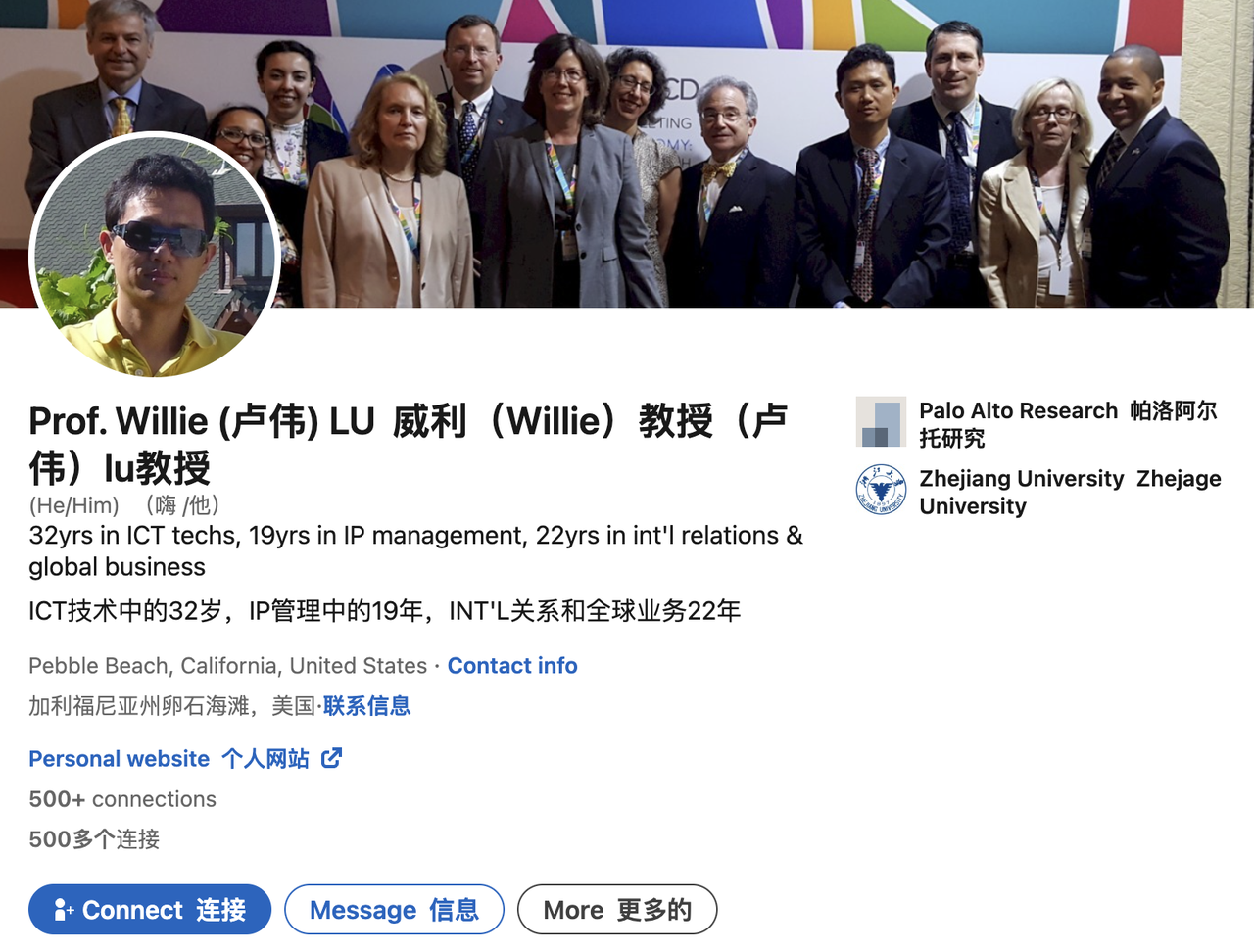
Une recherche dans la base de données de la Trademark Trial and Appeal Board (TTAB) de l'USPTO montre que Delson Group a déjà eu plus de 20 litiges en matière de marques avec de nombreuses sociétés bien connues, notamment la GSMA, Tencent et TracFone Wireless. La société a volontairement abandonné ou annulé certaines demandes de marques, mais a également enregistré avec succès certaines marques.
Une recherche dans la base de données plus large des marques de l'USPTO montre que Delson Group a enregistré 28 marques, dont celles de sociétés chinoises bien connues. Par exemple, la société a enregistré les marques « Geely » et « China Mobile », marques appartenant respectivement à un constructeur automobile chinois et à un géant des télécommunications de Hong Kong.
Cette tendance suggère que Delson Group pourrait se livrer à un comportement de « squattage de marques », c'est-à-dire enregistrer des marques à l'avance pour les revendre plus tard ou profiter de la notoriété de la marque.
À l’heure actuelle, les droits de marque de DeepSeek aux États-Unis sont désavantagés. En vertu de la loi américaine, la première entreprise à utiliser une marque est généralement considérée comme le propriétaire légal de la marque, à moins qu'il puisse être prouvé que l'autre partie l'a enregistrée de mauvaise foi.
Josh Gerben, avocat en propriété intellectuelle et fondateur de Gerben IP Firm, a déclaré dans une interview avec TechCrunch que Delson Group présente des avantages à bien des égards :
- Le délai de candidature est plus précoce (soumis 36 heures plus tôt que DeepSeek) ;
- Affirme utiliser la marque depuis 2020 (la demande de marque de DeepSeek indique qu'elle a été fondée en 2023) ;
- Avoir des activités vérifiables liées à l’IA (y compris des cours de formation et un site Web).
Gerben a souligné que Delson Group pourrait même intenter une action en justice pour « confusion inversée (Confusion inversée) », affirmant que l'essor rapide de DeepSeek amènerait le public à croire à tort que DeepSeek est le véritable propriétaire de la marque. En outre, le groupe Delson peut également poursuivre DeepSeek en justice et lui demander de cesser d'utiliser la marque « DeepSeek » sur le marché américain.

"DeepSeek pourrait réellement être confronté à de graves problèmes de marque", a déclaré Gerben. "Delson Group, en tant que "détenteur de droits antérieurs" potentiel, pourrait avoir de bonnes raisons de poursuivre en justice pour violation de marque. "
Il convient de mentionner que DeepSeek n’est pas la seule société d’IA à avoir rencontré des problèmes liés aux marques déposées. Par exemple, OpenAI a tenté d'enregistrer la marque « GPT », mais celle-ci a été rejetée par l'USPTO en février de l'année dernière au motif que le terme était trop générique.
Comme nous l'avons déjà signalé, OpenAI est toujours en conflit juridique avec l'entrepreneur technologique Guy Ravine au sujet de la marque « Open AI ». Ravine a affirmé avoir proposé ce concept de marque dès 2015 (l'année de la création d'OpenAI) et espérait créer une plateforme d'IA « open source ».
De plus, tôt ce matin, le PDG d'Anthropic, Dario Amodei, a publié un article de 10 000 mots sur la plateforme X, en réponse aux nombreuses turbulences récentes entourant DeepSeek.
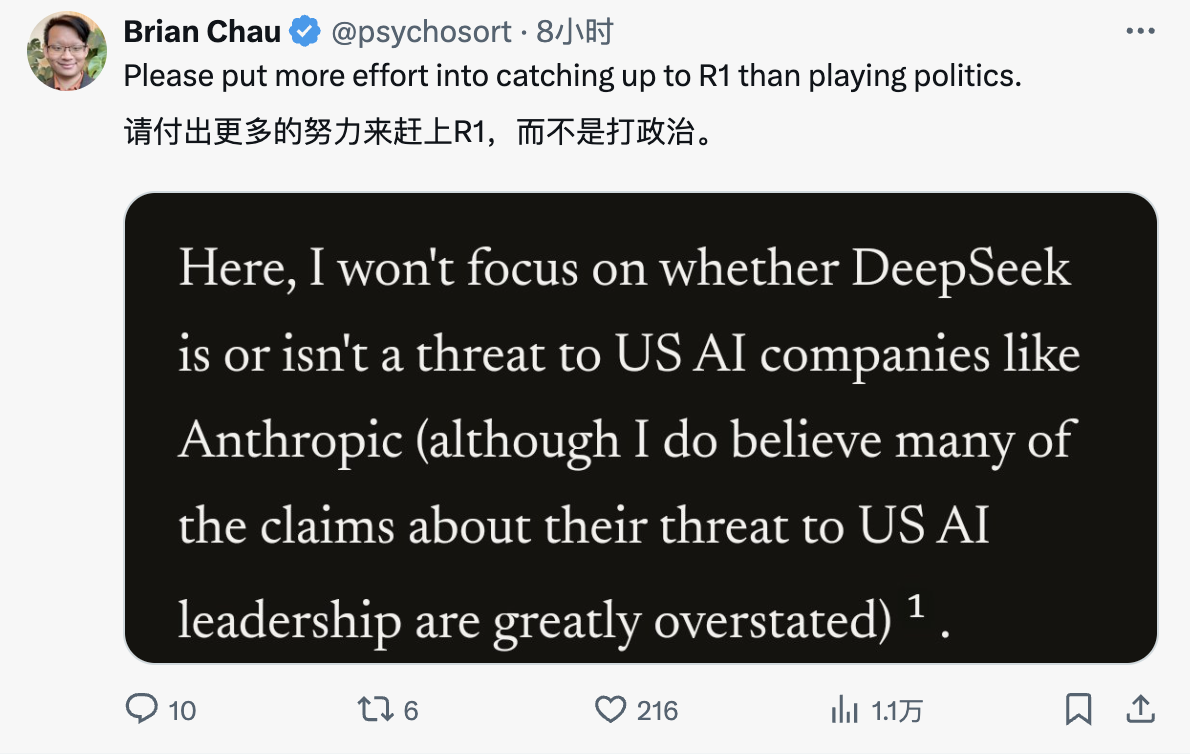
Face à la violation présumée de la défense d'Amodei, l'internaute X a écrit dans la zone de commentaires :
Ci-joint une compilation du texte original (avec suppressions) ~
Il y a quelques semaines, j’ai proposé que les contrôles américains sur les exportations de puces vers la Chine soient renforcés. Aujourd'hui, la société chinoise d'IA DeepSeek s'approche en fait des modèles d'IA les plus avancés aux États-Unis à un coût inférieur à certains égards.
Dans cet article, je ne discuterai pas de la question de savoir si DeepSeek menace réellement les sociétés américaines d’IA telles qu’Anthropic (même si je pense que certaines affirmations selon lesquelles l’IA chinoise prendrait le leadership américain sont exagérées)¹. Au lieu de cela, je souhaite explorer une question : la percée technologique de DeepSeek compromet-elle la nécessité de contrôler les exportations de puces ? Ma réponse est non. En fait, je pense que cela renforce l’importance des contrôles à l’exportation².
L’objectif principal des contrôles à l’exportation est de garantir que les démocraties gardent une longueur d’avance en matière de développement de l’IA. Ce qui doit être clair, c’est que la politique réglementaire n’a pas pour objectif d’éviter la concurrence sino-américaine en matière d’IA. En fin de compte, si les États-Unis et d’autres démocraties espèrent dominer l’IA, ils devront disposer de modèles plus avancés que la Chine. Mais en même temps, nous ne devons pas permettre au gouvernement chinois d’acquérir un avantage technologique alors qu’il peut être évité.
Trois dynamiques fondamentales du développement de l’IA
Avant d’aborder les questions politiques, je voudrais présenter trois développements clés dans les systèmes d’IA, qui sont cruciaux pour comprendre l’industrie de l’IA :
1. Mise à l'échelle des lois
Une règle fondamentale dans le domaine de l’IA est qu’à mesure que l’échelle de formation augmente, les performances du modèle continueront de s’améliorer régulièrement. Mes co-fondateurs et moi avons été les premiers à documenter et valider ce phénomène alors que nous travaillions chez OpenAI.
En termes simples, lorsque toutes les autres conditions sont égales, l’augmentation de la quantité de calculs d’entraînement (calcul) permettra à l’IA de mieux fonctionner sur diverses tâches cognitives. Par exemple:
- L'IA d'une valeur d'un million de dollars pourrait potentiellement résoudre 20 % des tâches de programmation critiques
- 10 millions de dollars d'IA pourraient résoudre 40 % des problèmes
- L’IA, d’une valeur de 100 millions de dollars, pourrait résoudre 60 % des problèmes.
Ces différences auront un impact énorme sur les applications pratiques : une multiplication par 10 des calculs pourrait signifier que le niveau d’IA s’améliore des étudiants de premier cycle aux doctorants. En conséquence, les entreprises investissent d’énormes sommes d’argent dans la formation de modèles plus solides.
2. Améliorer l'efficacité informatique (changer la courbe)
Diverses innovations, grandes et petites, émergent constamment dans le domaine de l’IA, rendant la formation et l’inférence de l’IA plus efficaces. Ces innovations peuvent impliquer des améliorations de l'architecture du modèle (telles que l'optimisation de la structure du transformateur), des méthodes informatiques plus efficaces (amélioration de l'utilisation du matériel) et une nouvelle génération de puces informatiques IA.
Ces optimisations amélioreront l'efficacité globale de la formation de l'IA, appelée « Shifting the Curve » :
Si une certaine technologie apporte une amélioration informatique de 2 fois (Compute Multiplier, CM), alors la capacité de résolution de code à 40 % qui coûtait à l'origine 10 millions de dollars américains à former ne coûte plus que 5 millions de dollars américains ; la capacité de résolution de code à 60 % qui coûtait à l'origine 100 millions de dollars américains ne coûte plus que 50 millions de dollars américains.
Les grandes entreprises d’IA continuent de découvrir de telles améliorations en matière de CM :
- Petite optimisation (environ 1,2 fois) : optimisation de réglage fin commune
- Optimisation modérée (environ 2 fois) : améliorations architecturales ou optimisations d'algorithmes
- Optimisation importante (environ 10 fois) : rupture technologique majeure
Étant donné que l’augmentation du niveau d’intelligence de l’IA est d’une valeur extrêmement élevée, cette amélioration de l’efficacité ne réduit généralement pas le coût total de la formation, mais incite plutôt les entreprises à investir plus d’argent dans la formation de modèles plus puissants. Beaucoup de gens croient à tort que l'IA sera « d'abord chère, puis moins chère » comme les produits traditionnels, mais l'IA n'est pas un produit de qualité fixe : lorsque l'efficacité informatique s'améliore, l'industrie ne réduira pas la consommation informatique, mais recherchera plus rapidement une IA plus forte.
En 2020, mon équipe a publié un article indiquant que le taux d’amélioration de l’efficacité informatique apporté par les progrès des algorithmes est d’environ 1,68 fois par an. Mais le rythme actuel pourrait s'accélérer jusqu'à 4 fois par an, et cette estimation ne prend pas en compte l'impact des progrès matériels.
3. Réduction des coûts d'inférence
Les améliorations de l'efficacité de la formation affecteront également l'inférence de l'IA (c'est-à-dire le coût de calcul du modèle au moment de l'exécution). Au cours des dernières années, nous avons vu le coût de l’inférence dans l’IA continuer de baisser tandis que les performances continuaient de s’améliorer. Par exemple, Claude 3.5 Sonnet (sorti 15 mois après GPT-4) surpasse GPT-4 dans presque tous les tests de référence, mais son prix API n'est que de 1/10 de GPT-4.

3. Changer le paradigme
La méthode d'expansion de la formation en IA n'est pas statique. Parfois, les objets d'expansion de base changent ou de nouvelles méthodes d'expansion sont introduites au cours du processus de formation.
Entre 2020 et 2023, la principale direction d'expansion de la formation en IA concerne les modèles de pré-formation. Ces modèles sont principalement formés sur la base de données textuelles Internet à grande échelle, et une petite quantité de formation de réglage supplémentaire est effectuée sur cette base pour améliorer des capacités spécifiques.
À l’aube de 2024, l’utilisation de modèles de formation par apprentissage par renforcement (RL) pour générer une chaîne de pensée (CoT) est devenue le nouvel objectif de la formation en IA.
Des sociétés telles qu'Anthropic, DeepSeek et OpenAI (modèle o1-preview sorti en septembre 2024) ont découvert que cette méthode de formation peut améliorer considérablement les performances du modèle sur certaines tâches objectivement mesurables, notamment dans le raisonnement mathématique, les compétitions de programmation et le raisonnement logique complexe similaire aux mathématiques et à la programmation.
Le nouveau paradigme de formation adopte une approche en deux étapes : premièrement, former le modèle traditionnel de pré-formation pour le doter de capacités de base. Deuxièmement, la capacité de raisonnement du modèle est améliorée grâce à l’apprentissage par renforcement (RL).
Cette méthode de formation RL étant encore nouvelle, toutes les entreprises investissent actuellement moins dans l’étape RL et en sont donc encore aux premiers stades de mise à l’échelle. Passer de seulement 100 000 $ à 1 million de dollars en investissement de formation peut conduire à d’énormes gains de performances.
Les entreprises progressent rapidement dans l'expansion de la formation RL, qui devrait bientôt atteindre des centaines de millions, voire des milliards de dollars. Actuellement, nous nous trouvons à un « point de croisement » unique où la formation en IA subit un changement de paradigme important, où des avancées rapides en matière de performances peuvent être réalisées en peu de temps, car la formation RL en est encore à ses premiers stades d’expansion.
Le modèle de DeepSeek
Les trois principales tendances de développement de l’IA ci-dessus peuvent nous aider à comprendre les modèles récemment publiés par DeepSeek.
Il y a environ un mois, DeepSeek a lancé « DeepSeek-V3 », qui est un pur modèle de pré-formation, le modèle de première étape mentionné au point 3 ci-dessus. Puis, la semaine dernière, ils ont sorti "R1", qui a ajouté une deuxième étape de formation basée sur la V3. Bien que les détails internes de ces modèles ne soient pas entièrement accessibles au monde extérieur, voici ma meilleure compréhension des deux lancements.
DeepSeek-V3 est la véritable innovation récente de DeepSeek, et elle méritait qu'on s'y intéresse il y a un mois (et nous l'avions remarqué à l'époque).
En tant que modèle purement pré-entraîné, les performances de DeepSeek-V3 sur certaines tâches clés sont proches des modèles d'IA les plus avancés aux États-Unis, mais le coût de formation est bien inférieur. (Cependant, nous avons constaté que le Sonnet Claude 3.5 était encore nettement meilleur dans certaines tâches clés, en particulier la programmation du monde réel.)
L'équipe DeepSeek est capable d'y parvenir principalement en s'appuyant sur une série d'innovations techniques vraiment exceptionnelles, notamment en termes d'optimisation de l'efficacité informatique, notamment l'optimisation innovante de la gestion du « Key-Value Cache », qui améliore l'efficacité du modèle dans le processus d'inférence, et l'application révolutionnaire de la technologie « Mélange d'experts (MoE) », qui lui permet de fonctionner mieux que jamais dans les modèles d'IA à grande échelle.
Il convient cependant d’analyser plus attentivement :
DeepSeek n’a pas « accompli avec 6 millions de dollars⁵ ce pour quoi les sociétés américaines d’IA ont dépensé des milliards de dollars ». Pour autant que je puisse parler pour Anthropic, le Claude 3.5 Sonnet est un modèle de taille moyenne qui coûte des dizaines de millions de dollars à entraîner (je ne divulguerai pas le chiffre exact). De plus, les rumeurs selon lesquelles des modèles plus grands et plus chers auraient été utilisés lors de la formation 3.5 Sonnet ne sont pas vraies. La formation de Sonnet a été réalisée il y a 9 à 12 mois, tandis que le modèle de DeepSeek a été formé entre novembre et décembre de l'année dernière.
Malgré cela, Sonnet reste un leader incontesté dans de nombreuses évaluations internes et externes. Par conséquent, une déclaration plus précise devrait être : « DeepSeek a formé un modèle à un coût relativement faible, proche des performances du modèle américain d'il y a 7 à 10 mois, mais le coût n'est pas aussi bas qu'on le dit. »
Si, selon les tendances passées, les coûts de formation en IA ont diminué d'environ 4 fois par an, alors dans des circonstances normales – comme la tendance à la baisse des coûts en 2023 et 2024 – nous pouvons nous attendre à ce que le coût de formation du modèle actuel soit 3 à 4 fois inférieur à 3,5 Sonnet ou GPT-4o. Les performances de DeepSeek-V3 sont toujours inférieures à celles de ces modèles américains de pointe – environ 2 fois pires (cette estimation est assez généreuse pour DeepSeek-V3). Cela signifie que si le coût de formation de DeepSeek-V3 est 8 fois inférieur à celui du modèle américain haut de gamme il y a un an, cela est normal et conforme à la tendance, et ne constitue pas une avancée inattendue.
En fait, la réduction des coûts de DeepSeek-V3 est encore plus faible que la réduction du prix d'inférence (10 fois) de GPT-4 à Claude 3.5 Sonnet, qui elle-même est encore plus forte que GPT-4. Tout cela montre que DeepSeek-V3 n'est ni une avancée technologique révolutionnaire ni un changement dans le modèle économique des grands modèles de langage (LLM). Il s'agit simplement d'un cas normal, conforme à la tendance actuelle à la réduction des coûts.
La différence est que cette fois, c’est une entreprise chinoise qui a pris les devants en réalisant la réduction des coûts attendue. C’est la première fois que cela se produit dans l’histoire et cela revêt donc une grande importance géopolitique. Cependant, les sociétés américaines d’IA suivront bientôt cette tendance, et elles ne le feront pas en copiant DeepSeek, mais parce qu’elles évoluent elles-mêmes sur la courbe établie de réduction des coûts.
Les sociétés DeepSeek et américaines d’IA disposent désormais de plus de fonds et de puces que lors de la formation de leurs modèles principaux existants. Ces puces supplémentaires sont utilisées pour développer de nouvelles technologies de modèles et sont parfois utilisées pour entraîner de grands modèles qui n'ont pas encore été publiés ou qui nécessitent plusieurs tentatives de perfectionnement.
Il a été rapporté (bien que nous ne puissions pas confirmer son authenticité) que DeepSeek possède en réalité 50 000 GPU de génération Hopper⁶, et j'estime que cela représente environ 1/2 à 1/3 de la taille des GPU des grandes sociétés américaines d'IA (par exemple, ce nombre est 2 à 3 fois inférieur à celui du cluster "Colossus" de xAI)⁷. Le coût de ces 50 000 GPU Hopper est d’environ 1 milliard de dollars.
Par conséquent, l’investissement total de DeepSeek en tant qu’entreprise (pas seulement le coût de formation d’un seul modèle) ne présente pas un énorme écart avec celui des laboratoires américains de recherche en IA.
Il convient de noter que l’analyse de la « courbe d’échelle » est en réalité quelque peu simpliste. Différents modèles ont leurs propres caractéristiques et se spécialisent dans différents domaines, et la valeur de la courbe d'expansion n'est qu'une moyenne approximative, ignorant de nombreux détails.
D'après ce que je comprends du modèle d'Anthropic, comme je l'ai mentionné précédemment, Claude est excellent dans la génération de code et dans l'interaction de haute qualité avec les utilisateurs, beaucoup l'utilisant même pour des conseils ou une assistance personnalisés. À ces égards, et pour certaines autres tâches spécifiques, DeepSeek ne peut tout simplement pas comparer, et ces écarts ne sont pas directement reflétés dans les données de la courbe d'échelle.
La sortie de R1 la semaine dernière a attiré une grande attention du public et a fait chuter le cours de l'action de Nvidia d'environ 17 %. Mais du point de vue de l’innovation ou de l’ingénierie, la R1 est loin d’être aussi excitante que la V3.
R1 ajoute simplement une deuxième étape de formation – l'apprentissage par renforcement (cela a été mentionné au point 3 de la section précédente), qui est essentiellement une réplication de la méthode d'OpenAI dans la version o1 (l'échelle et l'effet des deux semblent être similaires)⁸. Cependant, comme nous n’en sommes qu’aux premiers stades de la courbe de mise à l’échelle, il est possible que plusieurs entreprises puissent former des modèles similaires, à condition qu’elles disposent d’un solide modèle de base pré-entraîné.
Le coût de la formation R1 basée sur la V3 existante peut être très faible. Nous nous trouvons donc à une « intersection » intéressante où plusieurs entreprises sont capables de former des modèles dotés d’excellentes capacités d’inférence. Mais cette situation ne durera pas longtemps. À mesure que le modèle continue d’évoluer vers le haut le long de la courbe d’expansion, cette fenêtre de « seuil inférieur » prendra bientôt fin.
Contrôles des exportations de puces vers la Chine
L'analyse ci-dessus n'est en fait qu'une préparation au sujet qui me préoccupe vraiment : le contrôle des exportations de puces vers la Chine. En combinaison avec les faits précédents, je pense que la situation actuelle est la suivante :
La tendance en matière de formation en IA est que les entreprises investissent de plus en plus d’argent pour former des modèles plus puissants. Bien que le coût de la formation de modèles de même niveau d’intelligence continue de baisser, la valeur économique des modèles d’IA est si élevée que les économies réalisées sont presque immédiatement réinvesties dans la formation de modèles plus puissants, tandis que les dépenses globales restent au même niveau élevé.
Si la méthode d’optimisation de l’efficacité développée par DeepSeek n’est pas maîtrisée par les laboratoires américains, elle sera bientôt utilisée par des laboratoires aux Etats-Unis et en Chine pour entraîner des modèles d’IA valant des milliards de dollars. Ces nouveaux modèles seront plus performants que les modèles de plusieurs milliards de dollars initialement prévus pour être formés, mais l'investissement s'élèvera toujours à des milliards de dollars, et ce nombre continuera d'augmenter jusqu'à ce que le niveau d'intelligence de l'IA dépasse les capacités de presque tout le monde dans presque tous les domaines.
Construire une telle IA, plus intelligente que presque tout le monde, nécessitera des millions de puces, au moins des dizaines de milliards de dollars de financement, et sera très probablement réalisée en 2026-2027. La dernière annonce de DeepSeek ne changera pas cette tendance, car les réductions de coûts restent dans la fourchette attendue, qui a longtemps été prise en compte dans les calculs à long terme de l'industrie.
Cela signifie que d’ici 2026-2027, le monde pourrait se trouver dans deux situations très différentes : aux États-Unis, plusieurs entreprises disposeront certainement des millions de puces nécessaires (pour un coût de plusieurs dizaines de milliards de dollars). La question est de savoir si la Chine aura également accès à des millions de puces⁹.
Si la Chine parvient à acquérir des millions de puces, nous entrerons dans un monde bipolaire, dans lequel les États-Unis et la Chine disposent de puissants modèles d’IA, poussant la science et la technologie à se développer à un rythme sans précédent – ce que j’appelle « des pays de génies dans un centre de données ».

Mais un monde bipolaire ne restera peut-être pas équilibré longtemps. Même si la Chine et les États-Unis sont temporairement équivalents en matière de technologie d’IA, la Chine pourrait investir davantage de talents, de fonds et d’énergie dans l’application de la technologie d’IA au domaine militaire. Associé à l'énorme base industrielle et aux avantages stratégiques militaires de la Chine, cela pourrait permettre à la Chine non seulement d'atteindre une domination dans le domaine de l'IA, mais même de prendre la tête dans divers domaines à travers le monde.
Si la Chine ne parvient pas à acquérir des millions de puces, nous entrerons, au moins temporairement, dans un monde unipolaire dans lequel seuls les États-Unis et leurs alliés disposent des modèles d’IA les plus avancés. Il est incertain que cette situation unipolaire perdure, mais il est au moins possible qu’une brève avance se transforme en un avantage à long terme, dans la mesure où les systèmes d’IA contribuent à construire une IA plus forte¹⁰. Dans ce scénario, les États-Unis et leurs alliés pourraient parvenir à une domination décisive et à long terme sur la scène mondiale.
Par conséquent, des contrôles à l’exportation strictement appliqués¹¹ sont le seul moyen efficace d’empêcher la Chine d’obtenir des millions de puces, et constituent également le facteur le plus important pour déterminer si le monde sera finalement unipolaire ou bipolaire.

Le succès de DeepSeek ne signifie pas que les contrôles à l’exportation soient inefficaces. Comme je l'ai déjà dit, DeepSeek dispose en fait de ressources considérables en matière de puces, il n'est donc pas surprenant qu'ils aient pu développer et entraîner un modèle puissant. Elles ne sont pas plus contraintes en termes de ressources que les sociétés américaines d’IA, et les contrôles à l’exportation ne sont pas la principale raison de leur « innovation ». Ce sont simplement de très bons ingénieurs, ce qui montre que la Chine est un concurrent sérieux des États-Unis dans le domaine de l’IA.
Le succès de DeepSeek ne signifie pas que la Chine peut toujours obtenir les puces dont elle a besoin par la contrebande, ni qu’il existe des failles dans les contrôles à l’exportation qui ne peuvent pas être comblées. Je pense que les contrôles à l’exportation n’ont jamais eu pour objectif d’empêcher la Chine d’obtenir des dizaines de milliers de chips. Une activité économique d’un milliard de dollars peut être cachée, mais une activité de 10 milliards de dollars, voire un milliard de dollars, est beaucoup plus difficile à dissimuler, et expédier sournoisement des millions de puces peut être physiquement extrêmement difficile.
Nous pouvons également examiner les types de puces que DeepSeek possède actuellement. Selon l'analyse SemiAnalysis, les 50 000 puces IA existantes de DeepSeek sont un mélange de H100, H800 et H20.
- Les H100 sont soumis à des contrôles à l’exportation depuis leur introduction, donc si DeepSeek possède des H100, ils doivent avoir été obtenus par contrebande. (Cependant, il convient de noter que Nvidia a déclaré que les progrès de DeepSeek en matière d’IA sont « entièrement conformes aux réglementations en matière de contrôle des exportations »).
- Le H800 pouvait encore être exporté dans le cadre de la politique initiale de contrôle des exportations en 2022, mais a été interdit après la mise à jour de la politique en octobre 2023, de sorte que ces puces peuvent avoir été expédiées avant l'entrée en vigueur de l'interdiction.
- Le H20, qui est moins efficace en formation mais plus efficace en inférence (échantillonnage), est toujours autorisé à exporter, mais je pense qu'il devrait également être interdit.
Pour résumer, les puces IA détenues par DeepSeek comprennent principalement des puces qui ne sont pas actuellement interdites (mais qui devraient l'être), des puces obtenues avant d'être interdites et un petit nombre de puces qui peuvent être obtenues par contrebande.
Cela montre en fait que les contrôles à l’exportation fonctionnent et sont en train d’être peaufinés : si les contrôles à l’exportation étaient complètement inefficaces, DeepSeek disposerait probablement déjà d’un lot complet de puces H100 de premier ordre. Cependant, ce n’est pas le cas, ce qui montre que les politiques comblent progressivement les lacunes. Si nous renforçons les contrôles assez rapidement, nous pourrions empêcher la Chine d’accéder à des millions de puces, augmentant ainsi la probabilité que les États-Unis maintiennent leur leadership dans le domaine de l’IA et créent un monde unipolaire.
Concernant les contrôles à l’exportation et la sécurité nationale des États-Unis, je tiens à être clair :
Je ne considère pas DeepSeek en lui-même comme un rival et je ne cible pas spécifiquement cette société. D’après leurs entretiens, les chercheurs de DeepSeek apparaissent comme des ingénieurs intelligents et curieux qui souhaitent simplement développer une technologie utile.
Les contrôles à l’exportation sont l’un des outils les plus puissants dont nous disposons pour empêcher que cela ne se produise. Certains pensent que le fait que la technologie de l’IA devienne de plus en plus puissante et rentable est une raison pour assouplir les contrôles à l’exportation – mais cela est totalement déraisonnable.
note de bas de page
- 1 Concernant la distillation de modèles : dans cet article, je ne commenterai pas les rapports indiquant si DeepSeek distille des modèles occidentaux. Je suppose, sur la base uniquement des informations fournies dans l'article DeepSeek, qu'ils ont réellement formé le modèle comme ils l'ont déclaré.
- 2 La sortie de DeepSeek n'affecte pas Nvidia : En fait, je pense que la sortie du modèle DeepSeek n'a évidemment pas d'impact négatif sur Nvidia, et la baisse d'environ 17 % du cours de l'action Nvidia qui en résulte me laisse perplexe. Logiquement, la sortie de DeepSeek aura encore moins d’impact sur Nvidia que sur les autres sociétés d’IA. Quoi qu’il en soit, l’objectif principal de mon article est de défendre les politiques de contrôle des exportations.
- 3 Détails sur la façon dont R1 est formé : Plus précisément, R1 est un modèle pré-entraîné et ne subit qu'une petite quantité de formation d'apprentissage par renforcement (RL), ce qui est courant dans les modèles avant le changement de paradigme d'inférence.
- 4 DeepSeek est performant sur certaines tâches spécifiques : mais ces tâches ont une portée très limitée.
- 5 Concernant le « coût de formation de 6 millions de dollars » mentionné dans l'article DeepSeek : Ces données sont citées dans l'article DeepSeek, je l'accepte ici pour le moment et ne remets pas en question son authenticité. Je remets cependant en question la légitimité de cette comparaison directe avec les coûts de formation des entreprises américaines d’IA. Les 6 millions de dollars ne concernent que le coût de formation d’un modèle spécifique, mais le coût global de la R&D en IA est bien supérieur à ce chiffre. De plus, nous ne pouvons pas être totalement sûrs de l'authenticité des 6 millions de dollars – bien que l'échelle du modèle puisse être vérifiée, des facteurs tels que le nombre de jetons utilisés dans la formation sont difficiles à vérifier.
- 6 Correction sur les puces existantes de DeepSeek : Dans certaines interviews, j'ai dit un jour que DeepSeek possédait « 50 000 morceaux de H100 », mais il s'agit en fait d'un résumé inexact des rapports pertinents, et j'aimerais le corriger ici. Le H100 est actuellement la puce à architecture Hopper la plus connue, j'ai donc supposé que le rapport faisait référence au H100. Mais en fait, la série Hopper comprend également les H800 et H20, et DeepSeek propose un mélange de ces trois puces, avec un total de 50 000 puces. Même si ce fait ne change pas la situation globale, il mérite néanmoins d’être clarifié. J'analyserai les problèmes des H800 et H20 plus en détail lorsque j'aborderai les contrôles à l'exportation.
- 7 L’écart entre les États-Unis et la Chine en matière de puces devrait encore se creuser dans les clusters informatiques de nouvelle génération, principalement en raison de l’impact des contrôles à l’exportation.
8 L'une des principales raisons pour lesquelles R1 a reçu une large attention : je pense qu'une partie de la raison pour laquelle R1 a attiré une grande attention est qu'il s'agit du premier modèle à montrer à l'utilisateur le processus de « raisonnement en chaîne de pensée », alors que le o1 d'OpenAI ne montre que la réponse finale. DeepSeek démontre que les utilisateurs sont intéressés par des processus de raisonnement transparents pour l'IA. Pour clarifier, il s’agit simplement d’un choix de conception d’interface utilisateur (UI) et n’a rien à voir avec le modèle lui-même. - 10 L’objectif du contrôle des exportations : Il doit être clair ici que l’objectif n’est pas de priver la Chine de la possibilité de bénéficier des progrès technologiques de l’IA – les avancées de l’IA dans les domaines de la science, des soins médicaux, de la qualité de vie et dans d’autres domaines devraient profiter à tous. Le véritable objectif est d’empêcher ces pays d’atteindre une domination militaire.
Vous trouverez ci-joint les liens pertinents vers le rapport :
https://x.com/DarioAmodei/status/1884636410839535967
https://darioamodei.com/on-deepseek-and-export-controls
# Bienvenue pour suivre le compte public officiel WeChat d'Aifaner : Aifaner (ID WeChat : ifanr). Un contenu plus passionnant vous sera fourni dès que possible.
Ai Faner | Lien original · Voir les commentaires · Sina Weibo