
5 vérités sur DeepSeek qui ont été mal comprises, révélées par le patron de l’IA lui-même

Revoyons-le : Xiaohong compte sur le soutien, et Big Red compte sur la vie.
DeepSeek est devenu populaire pendant la Fête du Printemps, et naturellement il y aura plus de problèmes lorsqu'il deviendra populaire. Surtout avec les changements compliqués de la situation à l'étranger, l'origine chinoise de DeepSeek a suscité de nombreuses rumeurs.
Tanishq Mathew Abraham, l'ancien directeur de recherche de Stability AI, s'est manifesté hier et a souligné plusieurs points très particuliers de DeepSeek en tant qu'initié de l'industrie :
1. Les performances sont en fait aussi bonnes que celles du o1 d'OpenAI, qui est un modèle de pointe qui montre que l'open source a véritablement rattrapé le fermé.
2. Comparé à d'autres modèles de pointe, DeepSeek est réalisé à un coût de formation relativement faible.
3. L'interface facile à utiliser, combinée à des chaînes de pensée visibles sur son site Web et ses applications, attire des millions de nouveaux utilisateurs.
De plus, il a écrit un long article de blog en réponse à plusieurs rumeurs populaires, analysant et expliquant les remarques (scandaleuses) entourant DeepSeek.
Ce qui suit est un article de blog avec un contenu modifié :
Le 20 janvier 2025, une société chinoise d'IA a appelé DeepSeek open source et a publié son modèle d'inférence R1. Étant donné que DeepSeek est une société chinoise, les États-Unis et leur société AGI ont diverses « préoccupations en matière de sécurité nationale ». Pour cette raison, la **désinformation à ce sujet s’est largement répandue. **
Le but de cet article est de réfuter les nombreuses opinions extrêmement mauvaises concernant DeepSeek depuis sa sortie. Dans le même temps, en tant que chercheur en IA travaillant à l’avant-garde de l’IA générative, j’offre une perspective plus équilibrée.
Rumeur 1 : suspect ! DeepSeek est une société chinoise apparue soudainement
Complètement faux, d’ici janvier 2025, presque tous les chercheurs en IA générative auront entendu parler de DeepSeek. DeepSeek a même publié un aperçu de la R1 des mois avant sa sortie complète !
Quiconque propage cette rumeur ne travaille probablement pas dans le domaine de l'intelligence artificielle. Il est ridicule et extrêmement vaniteux de penser que vous savez tout ce qu'il y a à savoir si vous n'êtes pas impliqué dans le domaine.
Le premier modèle open source de DeepSeek, DeepSeek-Coder, a été publié en novembre 2023. Il s'agissait à l'époque des LLM de code leaders de l'industrie (NDLR : Modèles de langage axés sur la compréhension et la génération de code). Comme le montre le graphique ci-dessous, DeepSeek a continué à être expédié en un an, atteignant R1 : 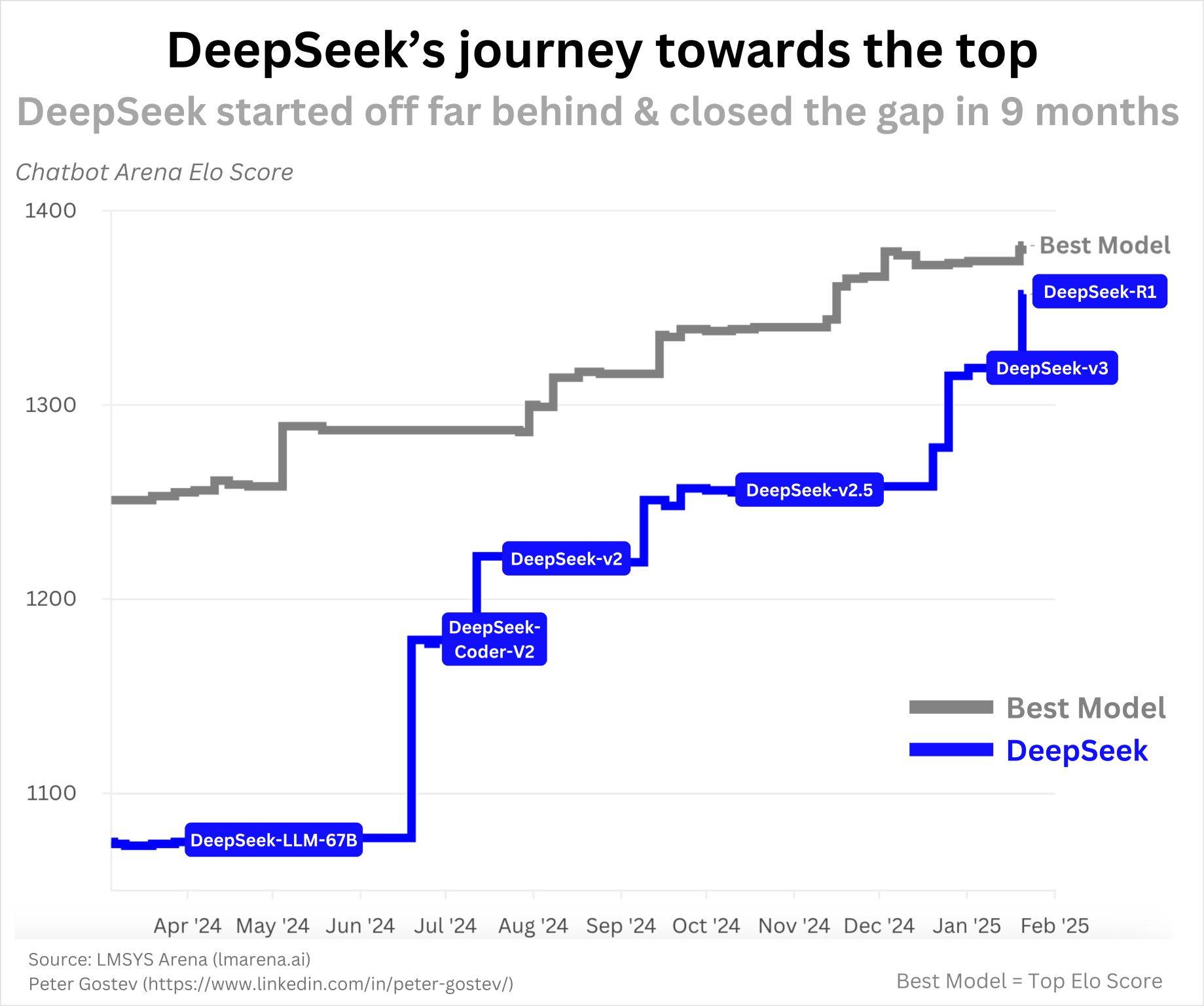
Cela n’a pas été un succès du jour au lendemain, et il n’y a rien de suspect quant au rythme de leurs progrès. Avec l’IA qui progresse si rapidement et une équipe visiblement efficace, faire de tels progrès en un an me semble très raisonnable.
Si vous voulez savoir quelles entreprises sont hors de vue du public mais très prometteuses dans le domaine de l'IA, je vous recommande de prêter attention à Qwen (Alibaba), YI (Zero Yiwu), Mistral, Cohere, AI2. Il est important de noter qu’ils ne publient pas de modèles SOTA de manière aussi cohérente que DeepSeek, mais ils ont tous deux le potentiel de publier d’excellents modèles, comme ils l’ont démontré dans le passé.
Rumeur 2 : mentir ! Ce modèle ne coûte pas 6 millions de dollars
C'est une question intéressante. De telles rumeurs suggèrent que DeepSeek voulait éviter d'admettre qu'ils avaient conclu des accords illégaux en coulisses pour obtenir des ressources informatiques auxquelles ils ne devraient pas avoir accès (en raison des contrôles à l'exportation), mentant ainsi sur la vérité sur le coût de la formation des modèles.
Premièrement, le chiffre de 6 millions de dollars mérite d’être examiné attentivement. Il est mentionné dans l'article DeepSeek-V3, publié un mois avant l'article DeepSeek-R1 :

DeepSeek-V3 est le modèle de base de DeepSeek-R1, ce qui signifie que DeepSeek-R1 est DeepSeek-V3 plus une formation supplémentaire d'apprentissage par renforcement. Dans une certaine mesure, le coût est déjà inexact car le coût supplémentaire de la formation par apprentissage par renforcement n’est pas pris en compte. Mais cela ne coûterait probablement que quelques centaines de milliers de dollars.
D'accord, donc les 5,5 millions de dollars mentionnés dans le document DeepSeek-V3, est-ce incorrect ? De nombreuses analyses basées sur le coût du GPU, la taille de l'ensemble de données et la taille du modèle ont produit des estimations similaires. Notez que bien que DeepSeek V3/R1 soit un modèle de paramètres 671B, il s'agit d'un modèle de mélange expert, ce qui signifie que tous les appels de fonction/passes avant du modèle n'utilisent que des paramètres ~37B, qui est la valeur utilisée pour calculer le coût de formation.
Cependant, le coût de DeepSeek est une estimation du coût de ces GPU basée sur les prix actuels du marché. Nous ne connaissons pas réellement le coût de leur cluster GPU 2048 H800 (remarque : pas les H100, c'est une idée fausse et une confusion courante !). En règle générale, les clusters GPU contigus coûtent moins cher lorsqu’ils sont achetés en gros, ils peuvent donc même être moins chers.
Mais voici le problème : c'est le coût de son fonctionnement en fin de compte. Avant que cela ne réussisse, de nombreuses expériences et ablations ont probablement été réalisées à petite échelle, ce qui aurait nécessité des coûts considérables, mais celles-ci ne sont pas rapportées ici.
À cela s’ajoutent de nombreux autres coûts, comme le salaire des chercheurs. SemiAnalysis rapporte que les salaires des chercheurs de DeepSeek seraient d'environ 1 million de dollars. Cela équivaut aux niveaux de salaires élevés des laboratoires de pointe AGI comme OpenAI ou Anthropic.
En règle générale, lors du reporting et de la comparaison des coûts de formation pour différents modèles, le coût final de l'exécution de la formation est la plus grande préoccupation. Mais en raison d'un discours médiocre et de la propagation de fausses informations, certains affirment que les coûts supplémentaires remettent en question la nature peu coûteuse et efficace des opérations de DeepSeek. C'est extrêmement injuste. Les coûts sont importants, tant du point de vue de l'ablation/expérimentation que du point de vue de la rémunération des chercheurs dans d'autres laboratoires de pointe en AGI, mais ils ne sont souvent pas mentionnés dans des discussions comme celle-ci !
Rumeur 3 : si bon marché ? Toutes les sociétés américaines d'AGI gaspillent de l'argent et sont baissières sur Nvidia
Je pense que c'est une autre idée assez stupide. DeepSeek est en effet plus efficace en formation que de nombreux autres LLM. Oui, il est très possible que de nombreux laboratoires américains de pointe soient inefficaces sur le plan informatique. Cependant, cela ne signifie pas nécessairement que disposer de plus de ressources informatiques soit une mauvaise chose.
Pour être honnête, chaque fois que j'entends des opinions comme celle-ci, il est clair pour moi qu'ils ne comprennent pas les lois de mise à l'échelle, ni l'état d'esprit du PDG d'AGI (et de toute personne considérée comme un expert en IA). Permettez-moi de proposer quelques réflexions sur ce sujet.
Les lois de mise à l'échelle montrent que tant que nous continuons à investir davantage de puissance de calcul dans le modèle, nous obtiendrons de meilleures performances. Bien entendu, les méthodes et les aspects exacts de la mise à l’échelle de l’IA ont changé au fil du temps : d’abord la taille du modèle, puis la taille de l’ensemble de données, et maintenant le calcul du temps d’inférence et les données synthétiques.
La tendance générale selon laquelle plus de puissance de calcul équivaut à de meilleures performances semble se poursuivre depuis le premier Transformer en 2017.
Un modèle plus efficace signifie que vous obtenez de meilleures performances pour un budget de calcul donné, mais plus de ressources de calcul sont toujours préférables. Un modèle plus efficace signifie que vous pouvez faire plus avec moins de ressources informatiques, mais faire plus avec plus de ressources informatiques !
Vous pouvez avoir vos propres opinions sur la mise à l’échelle des lois. Vous pourriez penser qu’un plateau arrive. On pourrait penser que les performances passées ne préjugent pas des résultats futurs, comme on dit dans le monde financier.
Mais que se passerait-il si toutes les plus grandes sociétés d’AGI pariaient que les lois de mise à l’échelle dureraient suffisamment longtemps pour permettre l’AGI et l’ASI ? C’est leur conviction profonde que la seule solution logique est d’acquérir davantage de puissance de calcul.
Maintenant, vous pensez peut-être "Les GPU de NVIDIA deviendront bientôt obsolètes, regardez AMD, Cerebras, Graphcore, TPU, Trainium, etc." Il existe des millions de produits matériels ciblant l’IA, tous essayant de rivaliser avec NVIDIA. L’un d’eux pourrait gagner à l’avenir. Dans ce cas, ces sociétés AGI se tourneront peut-être vers elles – mais cela n'a absolument rien à voir avec le succès de DeepSeek.
Personnellement, je ne pense pas qu'il existe des preuves solides que d'autres sociétés contesteront la domination de NVIDIA dans le domaine des puces d'accélération de l'IA, étant donné la domination actuelle de NVIDIA sur le marché et son niveau d'innovation continu.
Dans l’ensemble, je ne vois pas pourquoi DeepSeek signifie que vous devriez être baissier sur NVIDIA. Vous pouvez avoir d'autres raisons d'être baissier sur NVIDIA, et ces raisons peuvent être très valables, mais DeepSeek ne me semble pas être la bonne.
Rumeur 4 : C’est juste une imitation ! DeepSeek n'a apporté aucune innovation significative
erreur. **Il y a eu de nombreuses innovations dans la conception de modèles de langage et les méthodes de formation, certaines plus importantes que d'autres**. En voici quelques-uns (liste non complète, vous pouvez lire les articles DeepSeek-V3 et DeepSeek-R1 pour plus de détails) :
Attention latente multi-têtes (MLA) – Les LLM font généralement référence aux transformateurs qui utilisent le mécanisme dit d'attention multi-têtes (MHA). L'équipe DeepSeek a développé une variante du mécanisme MHA qui est à la fois plus efficace en mémoire et offre de meilleures performances.
GRPO et Verifiable Rewards – Les praticiens de l’IA tentent de reproduire o1 depuis sa sortie. Étant donné qu’OpenAI est resté assez secret sur son fonctionnement, les utilisateurs ont dû explorer diverses méthodes différentes pour obtenir des résultats similaires à ceux de O1. Il y a eu diverses tentatives, comme la recherche arborescente de Monte Carlo (la méthode utilisée par Google DeepMind pour gagner au Go), qui s'est avérée moins prometteuse que prévu initialement.
DeepSeek démontre qu'un pipeline d'apprentissage par renforcement (RL) très simple peut réellement obtenir des résultats de type o1. En plus de cela, ils ont développé leur propre variante de l’algorithme PPO RL commun, appelé GRPO, qui est plus efficace et plus performant. Je pense que beaucoup de gens dans la communauté de l'IA se demandent pourquoi n'avons-nous pas essayé cela avant ?
DualPipe – De nombreux aspects d'efficacité doivent être pris en compte lors de la formation d'un modèle d'IA sur plusieurs GPU. Vous devez comprendre comment le modèle et l'ensemble de données sont distribués sur tous les GPU, comment les données circulent à travers les GPU, etc. Vous devez également réduire tout transfert de données entre GPU car il est très lent et est mieux géré sur chaque GPU distinct si possible. Quoi qu'il en soit, il existe de nombreuses façons de mettre en place ce type de formation multi-GPU, et l'équipe DeepSeek a conçu une nouvelle solution plus efficace et plus rapide appelée DualPipe.
Nous avons beaucoup de chance que DeepSeek ait entièrement open source ces innovations et rédigé des introductions détaillées, contrairement à la société américaine AGI. Désormais, tout le monde peut bénéficier de ces moyens innovants pour améliorer sa propre formation sur les modèles d’IA.
Rumeur 5 : DeepSeek « tire » des connaissances de ChatGPT
David Sacks (le géant américain de l'IA et de la cryptographie) et OpenAI affirment que DeepSeek a « vidé » les connaissances de ChatGPT en utilisant une technique appelée distillation.
Tout d’abord, le mot « distillation » est utilisé ici de manière très étrange. En règle générale, la distillation fait référence à la formation sur les probabilités complètes (logits) de tous les mots suivants possibles (jetons), mais ces informations ne peuvent même pas être exposées via ChatGPT.
Mais bon, disons simplement que nous parlons de formation avec du texte généré par ChatGPT, même si ce n'est pas l'utilisation typique du terme.
OpenAI et ses employés affirment que DeepSeek lui-même utilise ChatGPT pour générer du texte et s'entraîner dessus. Ils n'ont fourni aucune preuve, mais si cela est vrai, DeepSeek a clairement violé les conditions de service de ChatGPT. Je pense que les conséquences juridiques pour une entreprise chinoise ne sont pas claires, mais je n'en sais pas grand-chose.
Notez que ce n'est que si DeepSeek a lui-même généré les données utilisées pour la formation. Si DeepSeek utilise des données générées par ChatGPT provenant d'autres sources (il existe actuellement de nombreux ensembles de données publics), je crois comprendre que cette « distillation » ou formation de données synthétiques n'est pas interdite par les CGU.
Néanmoins, à mon avis, cela ne diminue en rien les réalisations de DeepSeek. Ce qui m'a impressionné en tant que chercheur plus que l'aspect efficacité de DeepSeek, c'est leur réplication de o1. Je doute fortement que la « distillation » de ChatGPT soit d'une quelconque utilité. Ce doute vient entièrement du fait que le processus de réflexion CoT d'o1 n'a jamais été rendu public, alors comment DeepSeek peut-il l'apprendre ?
De plus, de nombreux LLM sont effectivement formés sur ChatGPT (ainsi que sur d’autres LLM), et il y aura naturellement du texte IA dans tout contenu Internet nouvellement récupéré.
Dans l'ensemble, croire que le modèle de DeepSeek fonctionne bien simplement parce qu'il distille simplement la perspective de ChatGPT, c'est ignorer la réalité de l'ingénierie, de l'efficacité et de l'innovation architecturale de DeepSeek.
Faut-il s’inquiéter de l’hégémonie chinoise en matière d’intelligence artificielle ?
Peut-être un peu ? Franchement, par rapport à il y a deux mois, la concurrence sino-américaine en matière d’IA n’a pas beaucoup changé sur le fond. Au contraire, la réaction du monde extérieur est assez féroce, ce qui peut effectivement affecter le paysage global de l’IA à travers des changements dans le financement, la supervision, etc.
Les Chinois ont toujours été compétitifs en matière d’IA, et DeepSeek les rend désormais impossible à ignorer.
L'argument typique à propos de l'open source est que, parce que la Chine est à la traîne, nous ne devrions pas partager ouvertement notre technologie pour lui permettre de rattraper son retard. Mais évidemment, la Chine a rattrapé son retard, elle a en fait rattrapé son retard il y a longtemps, elle ouvre la voie en matière d'open source, donc il n'est pas sûr qu'un renforcement supplémentaire de notre technologie va réellement aider autant.
Notez que des sociétés comme OpenAI, Anthropic et Google DeepMind ont définitivement de meilleurs modèles que DeepSeek R1. Par exemple, les résultats de référence du modèle o3 d'OpenAI sont assez impressionnants et il se peut qu'un modèle de suivi soit déjà en développement.
En s'appuyant sur cette base et grâce à des investissements supplémentaires importants tels que le projet Stargate et le prochain cycle de financement d'OpenAI, OpenAI et d'autres laboratoires américains de pointe disposeront d'une puissance de calcul suffisante pour maintenir leur position de leader.
Bien entendu, la Chine investira des fonds supplémentaires importants dans le développement de l’IA. Donc globalement, la concurrence s’intensifie ! Mais je pense que la voie à suivre pour que les laboratoires américains de pointe en AGI restent en tête est encore très prometteuse.
en conclusion
D’une part, certains spécialistes de l’IA, en particulier ceux d’OpenAI, tentent de minimiser DeepSeek. D’un autre côté, certains critiques et experts autoproclamés ont réagi de manière excessive à DeepSeek.
Il convient de préciser que OpenAI/Anthropic/Meta/Google/xAI/NVIDIA, etc. n'en sont pas finis ici. Non, DeepSeek n’a (probablement) pas menti sur ce qu’ils ont fait. Quoi qu’il en soit, il faut l’admettre : DeepSeek mérite d’être reconnu, le R1 est un modèle impressionnant.
https://www.tanishq.ai/blog/posts/deepseek-delusions.html
# Bienvenue pour suivre le compte public officiel WeChat d'Aifaner : Aifaner (ID WeChat : ifanr). Un contenu plus passionnant vous sera fourni dès que possible.
Ai Faner | Lien original · Voir les commentaires · Sina Weibo