
Découvrez le nouveau FlashMLA open source de DeepSeek dans un article. Ces détails méritent d’être notés.

À partir d’aujourd’hui, nous entrons officiellement dans la DeepSeek Open Source Week.
La première version du projet open source de DeepSeek, FlashMLA, a été déployée sur l'ensemble du réseau en très peu de temps. En quelques heures seulement, le projet a gagné plus de 3,5 000 étoiles et continue de monter en flèche.
Bien que je connaisse chaque lettre de FlashMLA, je n'arrive pas à les comprendre ensemble. Ne vous inquiétez pas, nous avons élaboré un guide sur le speedrun de FlashMLA.
▲
Organisé par Grok 3, vérifié par APPSO
Laissez les performances du H800 augmenter considérablement, quelle est l'origine de FlashMLA ?
Selon l'introduction officielle, FlashMLA est un noyau de décodage MLA (Multi-Head Latent Attention) efficace optimisé pour le GPU Hopper, qui prend en charge le traitement de séquences de longueur variable et a maintenant été mis en production.
FlashMLA peut améliorer l'efficacité de l'inférence LLM (Large Language Model) en optimisant le décodage MLA et la pagination du cache KV, en particulier sur les GPU haut de gamme tels que le H100/H800 pour obtenir des performances optimales.
En termes humains, FlashMLA est une technologie avancée spécialement conçue pour les puces d'IA hautes performances Hopper – un « noyau de décodage d'attention multicouche ».
Cela semble compliqué, mais en termes simples, c'est comme un « traducteur » super efficace qui permet aux ordinateurs de traiter les informations linguistiques plus rapidement. Il permet aux ordinateurs de traiter très rapidement des informations linguistiques de différentes longueurs.
Par exemple, lorsque vous utilisez un chatbot, celui-ci peut permettre de répondre à vos conversations plus rapidement et sans décalage. Afin d'améliorer l'efficacité, il optimise principalement certains processus de calcul complexes. C'est comme mettre à niveau le « cerveau » de l'ordinateur pour le rendre plus intelligent et plus efficace dans le traitement des tâches linguistiques.
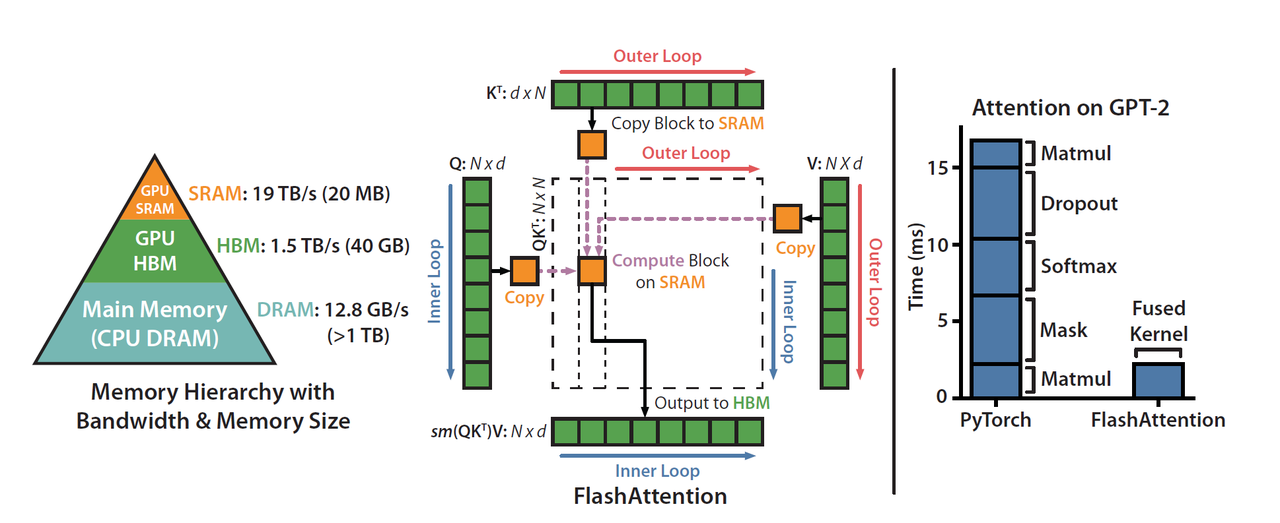
DeepSeek a officiellement mentionné que FlashMLA s'inspire des projets FlashAttention 2&3 et Cutlass.
FlashAttention est une méthode de calcul d'attention efficace spécialement optimisée pour le mécanisme d'auto-attention des modèles Transformer (tels que GPT et BERT). Son objectif principal est de réduire l'utilisation de la mémoire vidéo et d'accélérer les calculs. cutlass est également un outil d'optimisation qui contribue principalement à améliorer l'efficacité des calculs.
La popularité de DeepSeek tient en grande partie à la création de modèles performants à faible coût.
Le secret derrière cela réside principalement dans son innovation en matière d’architecture de modèle et de technologie de formation, en particulier l’application de la technologie d’experts mixtes (MoE) et d’attention latente multi-têtes (MLA).
Créer des solutions d'IA avec DeepSeek : un atelier pratique – Association of Data Scientists
FlashMLA est une implémentation et une version optimisée de la technologie d'attention latente multi-têtes (MLA) développée par DeepSeek. La question est donc : qu’est-ce que le mécanisme MLA (Multiple Latent Attention) ?
Dans les modèles linguistiques traditionnels, il existe une technologie appelée « Multi-Head Attention (MHA) ». Cela permet aux ordinateurs de mieux comprendre le langage, tout comme un œil humain peut se concentrer sur plusieurs endroits à la fois.
Cependant, cette technologie présente un inconvénient, c'est-à-dire qu'elle nécessite une grande quantité de mémoire pour stocker les informations, ce qui est comme un « entrepôt » qui peut être chargé, mais si l'entrepôt est trop grand, cela gaspillera de l'espace.
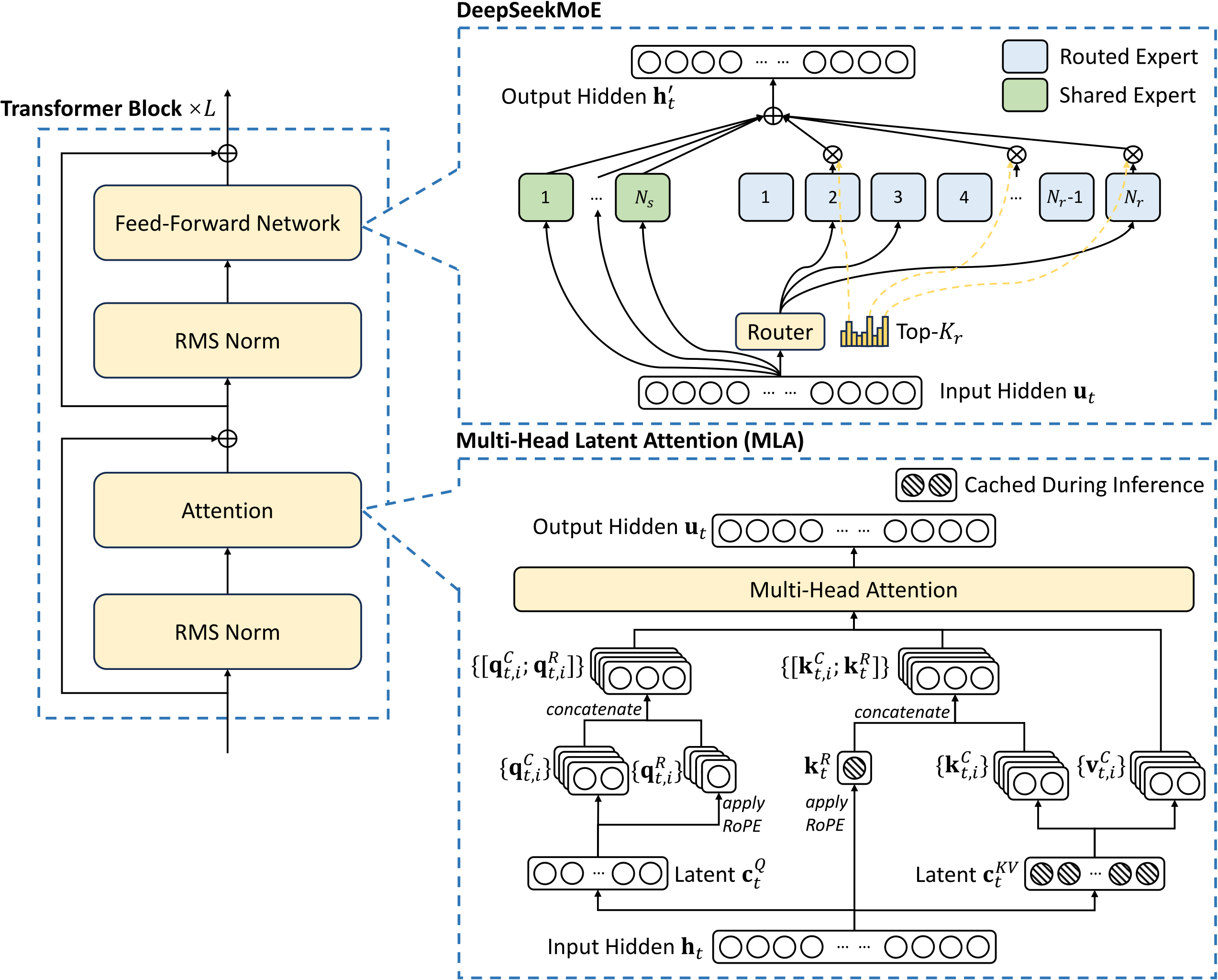
La mise à niveau du MLA réside dans une méthode appelée « décomposition de bas rang ».
Il compresse ce grand entrepôt en un petit entrepôt, mais la fonction est toujours aussi bonne, tout comme remplacer un grand réfrigérateur par un petit réfrigérateur, mais les objets à l'intérieur peuvent toujours être stockés. De cette façon,
Lors du traitement des tâches linguistiques, cela permet non seulement d'économiser de l'espace, mais est également plus rapide.
Cependant, bien que MLA ait compressé l'entrepôt, son effet de fonctionnement est toujours aussi bon qu'avant, sans aucun compromis.
Bien entendu, outre MLA et MoE, DeepSeek utilise également d'autres technologies pour réduire considérablement les coûts de formation et d'inférence, notamment, mais sans s'y limiter, la formation de faible précision, les stratégies d'équilibrage de charge sans pertes auxiliaires et la prédiction multi-token (MTP).
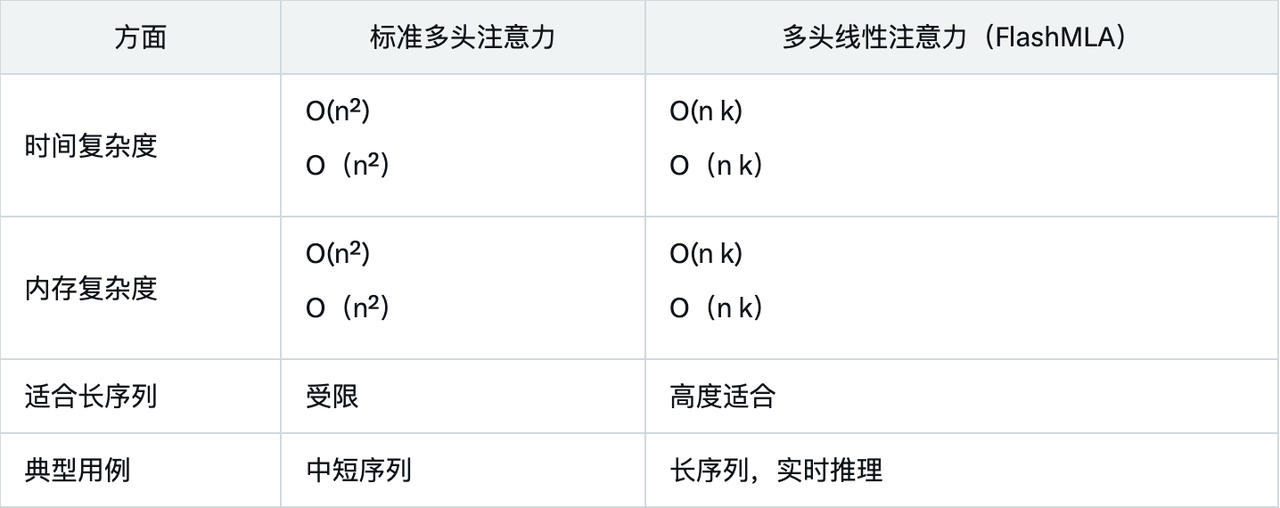
Les données de performances montrent que FlashMLA surpasse de loin les méthodes traditionnelles sous contraintes de mémoire et de calcul, grâce à sa conception de complexité linéaire et à son optimisation pour les GPU Hopper.
La comparaison avec l’attention multi-têtes standard met en évidence les avantages de FlashMLA :
Les principaux scénarios d'application de FlashMLA incluent :
- Traitement de séquences longues : adapté au traitement de textes comportant des milliers de balises, comme l'analyse de documents ou de longues conversations.
- Applications en temps réel : telles que les chatbots, les assistants virtuels et les systèmes de traduction en temps réel pour réduire la latence.
- Efficacité des ressources : réduit les besoins en mémoire et en calcul pour un déploiement facile sur les appareils de périphérie.
Actuellement, la formation ou le raisonnement de l'IA repose principalement sur NVIDIA H100/H800, mais l'écosystème logiciel continue de s'améliorer.
Étant donné que FlashMLA est open source, il peut être intégré à l'avenir à l'écosystème vLLM (cadre d'inférence LLM efficace), Hugging Face Transformers ou Llama.cpp (inférence LLM légère), ce qui devrait permettre aux grands modèles de langage open source (tels que LLaMA, Mistral, Falcon) de fonctionner plus efficacement.
Les mêmes ressources peuvent faire plus de travail et économiser de l’argent.
Étant donné que FlashMLA offre une efficacité de calcul plus élevée (580 TFLOPS) et une meilleure optimisation de la bande passante mémoire (3 000 Go/s), les mêmes ressources GPU peuvent gérer davantage de requêtes, réduisant ainsi les coûts d'inférence unitaires.
Pour les entreprises d'IA ou les fournisseurs de services de cloud computing, l'utilisation de FlashMLA signifie une réduction des coûts et un raisonnement plus rapide, ce qui bénéficiera directement à davantage d'entreprises d'IA, d'établissements universitaires et d'utilisateurs d'entreprise et améliorera l'utilisation des ressources GPU.
De plus, les chercheurs et les développeurs peuvent également procéder à d'autres optimisations basées sur FlashMLA.
Dans le passé, ces technologies efficaces d'optimisation de l'inférence de l'IA étaient généralement entre les mains de géants tels que OpenAI et NVIDIA. Mais désormais, avec l'open source de FlashMLA, les petites entreprises d'IA ou les développeurs indépendants peuvent également l'utiliser. De plus en plus de personnes se lancent dans le domaine de l'IA pour créer des entreprises, ce qui devrait naturellement donner naissance à davantage de projets entrepreneuriaux en matière d'IA.
En bref, si vous êtes un praticien ou un développeur d'IA et que vous avez récemment utilisé H100/H800 pour former ou déduire du LLM, alors FlashMLA peut être un projet digne d'attention ou de recherche.
De la même manière que les internautes ont découvert les détails de PTX dans l'article DeepSeek V3 lors de la Fête du Printemps, les internautes X ont découvert que le projet FlashMLA publié par DeepSeek contenait également une ligne de code PTX en ligne.
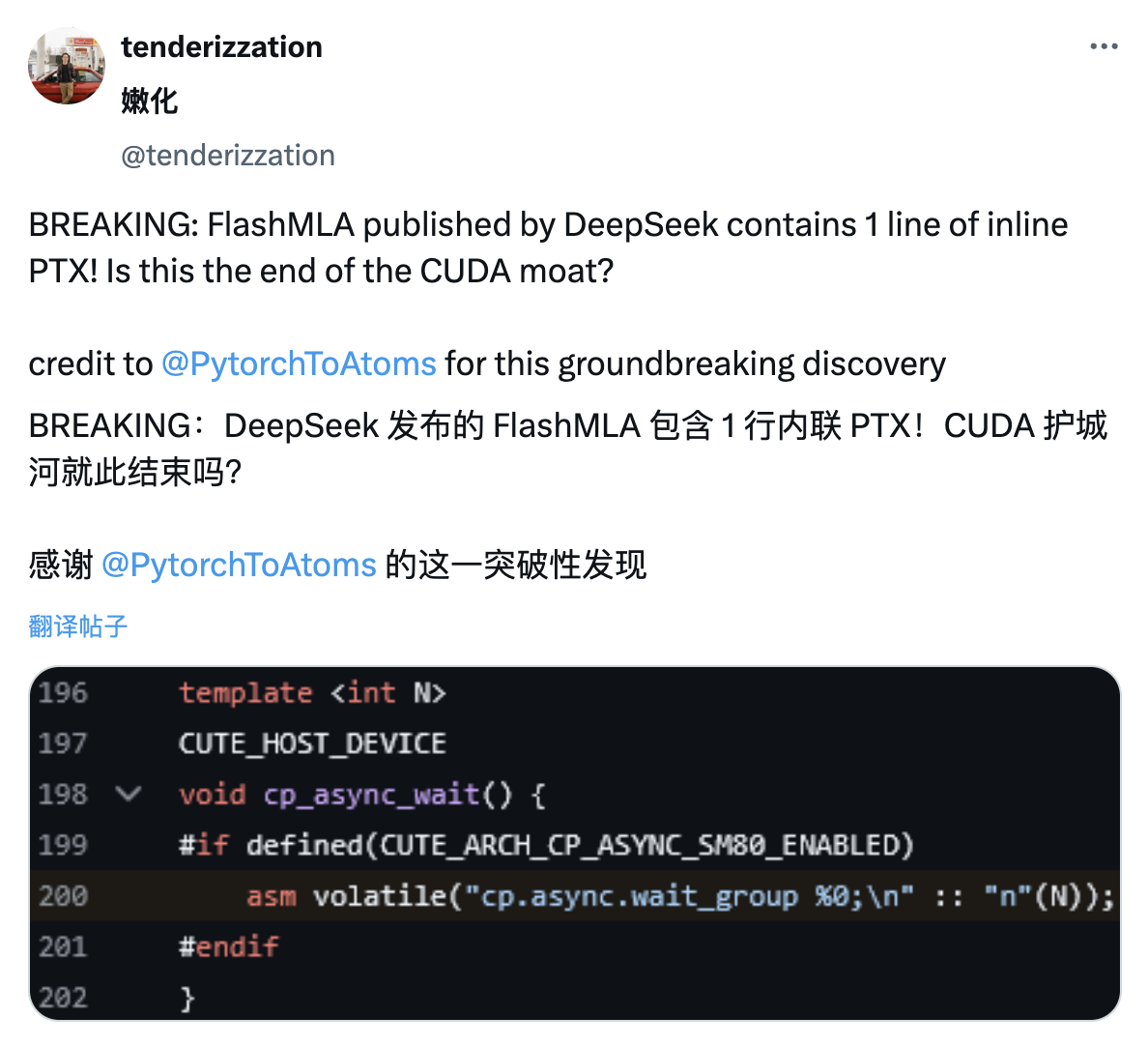
PTX est l'architecture de jeu d'instructions intermédiaire de la plate-forme CUDA, située entre les langages de programmation GPU de haut niveau et le code machine de bas niveau. Elle est souvent considérée comme l'un des fossés techniques de NVIDIA.
En intégrant PTX, cela permet aux développeurs de contrôler plus finement le processus d'exécution du GPU, obtenant potentiellement des performances de calcul plus efficaces.
De plus, l'utilisation directe des fonctions sous-jacentes des GPU NVIDIA sans avoir à s'appuyer entièrement sur CUDA contribuera également à réduire l'avantage technique de NVIDIA dans le domaine de la programmation GPU.
En d’autres termes, cela peut également signifier que DeepSeek contourne délibérément l’écosystème fermé de Nvidia.
Bien sûr, si rien d'inattendu ne se produit, selon les médias étrangers, des modèles tels que GPT-4.5 et Claude 4 devraient être publiés la semaine prochaine. La guerre de l'IA, qui n'avait pas été vue à la fin de l'année dernière, pourrait avoir lieu cette semaine.
Ce n'est pas trop grave de regarder le plaisir, de déclencher un combat, de déclencher un combat.
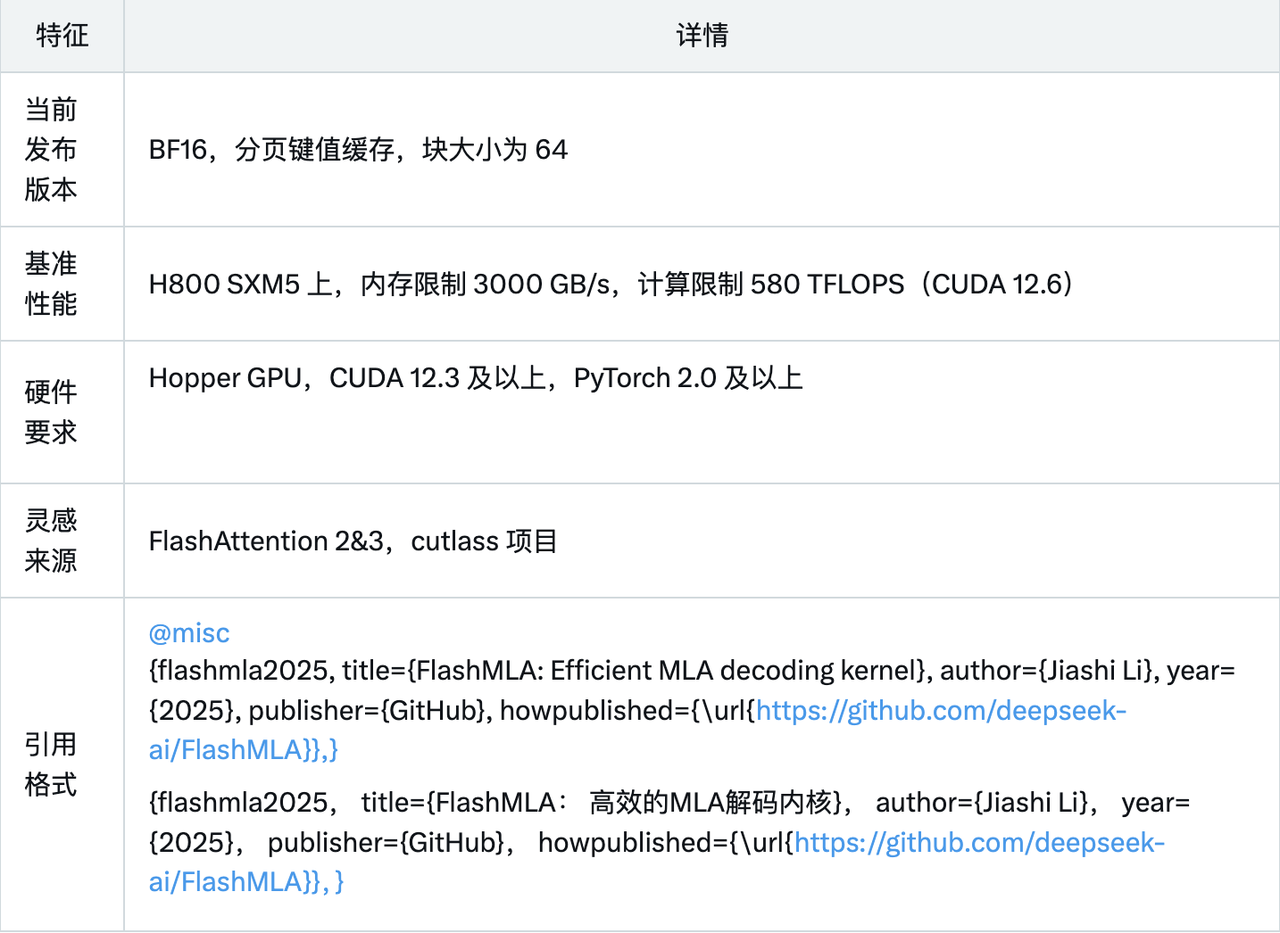
Guide de déploiement officiel
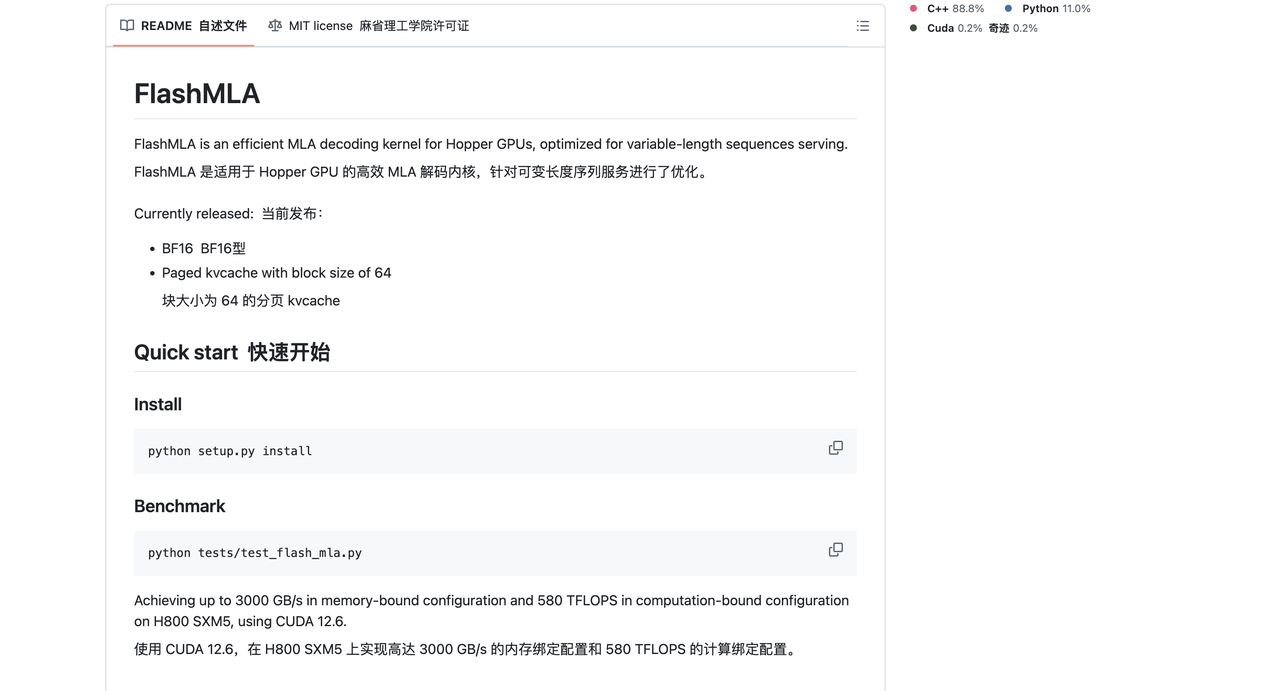
FlashMLA est un noyau de décodage MLA efficace optimisé pour les GPU Hopper et peut être utilisé pour gérer l'inférence de séquences de longueur variable.
La version actuellement publiée prend en charge :
- BF16
- Cache KV paginé, taille de bloc 64
Exécutant CUDA 12.6 sur H800 SXM5, FlashMLA peut atteindre 3 000 Go/s dans une configuration limitée par la bande passante mémoire, et jusqu'à 580 TFLOPS dans une configuration limitée par la puissance de calcul.
Équipement de projet :
- GPU de trémie
- CUDA 12.3 et supérieur
- PyTorch 2.0 et supérieur
Ci-joint l'adresse du projet GitHub :
https://github.com/deepseek-ai/FlashMLA
Installer
installation de python setup.py
référence
tests python/test_flash_mla.py
python tests/test_flash_mla.py est une instruction de ligne de commande utilisée pour exécuter le fichier de test Python test_flash_mla.py, généralement utilisé pour tester les fonctions ou modules liés à flash_mla.
depuis flash_mla importer get_mla_metadata, flash_mla_with_kvcache
Tile_scheduler_metadata, num_splits = get_mla_metadata(cache_seqlens, s_q * h_q // h_kv, h_kv)
pour moi dans la plage (num_layers):
…
o_i, lse_i = flash_mla_with_kvcache(
q_i, kvcache_i, block_table, cache_seqlens, dv,
Tile_scheduler_metadata, num_splits, causal=True,
)
…
# Bienvenue pour suivre le compte public officiel WeChat d'aifaner : aifaner (ID WeChat : ifanr). Un contenu plus passionnant vous sera fourni dès que possible.
Ai Faner | Lien original · Voir les commentaires · Sina Weibo