
Comprendre le troisième volet du projet open source DeepSeek en un seul article, 300 lignes de code révèlent la clé de l’efficacité d’inférence de la V3/R1

Le troisième jour de la semaine de l'Open Source, DeepSeek a non seulement apporté de la technologie, mais a également annoncé la bonne nouvelle que la R2 était en route. En tant qu'utilisateur, voir les bibliothèques technologiques lancées par DeepSeek et voir les modèles qui appliquent ces technologies n'est pas une façon d'assister à la naissance d'une superstar.
L'introduction d'aujourd'hui est DeepGEMM, une bibliothèque conçue pour une multiplication matricielle générale (GEMM) propre et efficace FP8, avec des capacités de mise à l'échelle à grain fin, comme décrit dans DeepSeek-V3. Il prend en charge les GEMM regroupés par experts normaux et mixtes (MoE). La bibliothèque est écrite en CUDA et ne nécessite aucune compilation lors de l'installation, elle utilise plutôt des modules légers juste à temps (JIT) pour compiler tous les noyaux au moment de l'exécution.
Je ne veux pas dire que DeepSeek n'est pas puissant, mais il ressort de l'open source des trois derniers jours que même s'ils sont soutenus par Magic Square, ils ne sont pas aussi riches en ressources que les grandes entreprises et doivent travailler dur pour réduire les ressources informatiques.
Y compris cette fois, GeepGEMM ne quitte toujours pas ce thème Par rapport aux technologies précédentes, les avantages de DeepGEMM sont :
- Efficacité accrue : réduction des coûts de calcul et de mémoire grâce au FP8 et à l'accumulation à deux niveaux
- Déploiement flexible : la compilation JIT est hautement adaptable et réduit la charge de pré-compilation
- Optimisation ciblée : prendre en charge MoE et s'adapter en profondeur au noyau tenseur Hopper
- Conception plus simple : moins de code de base, évite les dépendances complexes et est facile à apprendre et à optimiser
Ces fonctionnalités le distinguent dans l'informatique IA moderne, en particulier dans les scénarios qui nécessitent une inférence efficace et une faible consommation d'énergie .
Conçu pour l'informatique IA moderne
Une efficacité plus élevée et un déploiement plus flexible sont les points forts de DeepGEMM. La logique de base ne comporte qu'environ 300 lignes de code, mais elle surpasse le noyau réglé au niveau expert dans la plupart des tailles de matrice. Jusqu'à 1 350+ TFLOPS FP8 sur les GPU Hopper.
FP8 est une méthode de compression de nombres, ce qui équivaut à réduire les nombres qui nécessitaient initialement un stockage 32 bits ou 16 bits en un stockage 8 bits. Tout comme vous prenez des notes avec des notes autocollantes plus petites, même si vous pouvez écrire moins de contenu sur chaque morceau de papier, il est plus rapide à transporter et à transférer .
L'avantage de ce calcul compressé est qu'il consomme moins de mémoire – une tâche de même taille nécessite moins de « notes autocollantes » et le déplacement de petits morceaux de papier est plus rapide que de gros fichiers, donc la vitesse de calcul est également plus rapide. Mais le défi est qu’il est facile de faire des erreurs.
Afin de résoudre le problème de précision du FP8, DeepGEMM utilise une « méthode intelligente en deux étapes » : utiliser FP8 pour effectuer des multiplications à grande échelle, comme utiliser une calculatrice pour appuyer rapidement sur une série de résultats. Dans cette étape, les erreurs sont inévitables.
Mais ce n’est pas grave, il y a une deuxième étape : l’agrégation de haute précision. De temps en temps, ces résultats sont convertis en une somme plus précise à 32 chiffres, et la somme est soigneusement vérifiée avec du papier brouillon pour éviter l'accumulation d'erreurs.
Exécutez d’abord, puis passez par deux niveaux de vérification des erreurs cumulatives. Grâce à cette conception, DeepGEMM permet aux modèles d'IA de fonctionner plus facilement sur les téléphones mobiles, les ordinateurs et autres appareils tout en réduisant la consommation d'énergie, ce qui le rend adapté à des scénarios d'application plus complexes à l'avenir .

Y compris l'application de la compilation JIT, c'est une idée similaire. Compilation JIT, le nom complet est compilation « Just-In-Time ». En chinois, elle peut être appelée compilation juste-à-temps, et le concept correspondant est compilation statique.
Un programme général doit être écrit et compilé avant de l'utiliser, et transformé dans un langage que l'ordinateur peut comprendre. Mais la compilation JIT est différente : elle transforme uniquement le code en instructions que l'ordinateur peut exécuter lorsque le programme est en cours d'exécution.
Il peut ajuster le code sur site en fonction des conditions de votre ordinateur (comme la carte graphique NVIDIA Hopper) et adapter les instructions les plus appropriées. Il n'est pas aussi rigide que la pré-compilation, afin que le programme puisse fonctionner plus facilement. Compilez uniquement les pièces dont vous avez besoin pour le moment, sans perdre de temps ni d'espace, et faites en sorte que tout soit parfait.
Le noyau de tenseur Hopper et la compilation JIT sont les meilleurs partenaires. La compilation JIT peut générer un code optimal sur site basé sur votre carte graphique Hopper au moment de l'exécution, maximisant ainsi l'efficacité informatique du cœur tensoriel.
DeepGEMM prend en charge les GEMM ordinaires et les GEMM regroupés par experts mixtes (MoE), qui ont des exigences de calcul différentes. La compilation JIT peut ajuster temporairement le code en fonction des caractéristiques de la tâche et mobiliser directement la fonction moteur de calcul ou de transformation FP8 du noyau tensoriel pour réduire les gaspillages et augmenter la vitesse.
Comment décrire un parcours aussi technique : fin, léger et pointu .
Pour la majorité des développeurs, DeepGEMM peut être considéré comme une autre bonne nouvelle. Ce qui suit est des informations relatives au déploiement, vous souhaiterez peut-être jouer avec.
Guide de déploiement DeepGEMM
DeepGEMM est une bibliothèque optimisée pour la multiplication matricielle générale (GEMM) FP8 avec un mécanisme de mise à l'échelle raffiné et proposée dans DeepSeek-V3. Il prend en charge les GEMM standard et les GEMM regroupés Mixed Expert (MoE). La bibliothèque est écrite en CUDA et n'a pas besoin d'être précompilée lors de l'installation. Au lieu de cela, toutes les fonctions principales sont compilées au moment de l'exécution via un module léger de compilation juste à temps (JIT).
Actuellement, DeepGEMM ne prend en charge que les cœurs tenseurs NVIDIA Hopper. Pour résoudre le problème de la précision de calcul insuffisante du noyau tensoriel FP8, il utilise la technologie d'accumulation (boosting) à deux niveaux du noyau CUDA pour l'optimisation. Bien qu'il emprunte certains concepts à CUTLASS et CuTe, DeepGEMM ne s'appuie pas trop sur leurs modèles ou opérations mathématiques, il vise plutôt la simplicité et ne contient qu'une seule fonction de noyau de calcul avec environ 300 lignes de code. Cela fait de DeepGEMM une ressource de référence claire et facile à comprendre pour l’apprentissage des techniques de multiplication et d’optimisation de matrice Hopper FP8.
Malgré sa conception simple, les performances de DeepGEMM sur une variété de formes de matrice sont comparables, et dans certains cas même meilleures, à celles des bibliothèques optimisées par des professionnels.
performance
Nous avons testé en utilisant NVCC 12.8 sur H800, couvrant toutes les formes de matrice pouvant être utilisées lors de l'inférence DeepSeek-V3/R1 (y compris le pré-remplissage et le décodage, mais n'impliquant pas le parallélisme tensoriel). Toutes les mesures d'accélération sont calculées sur la base de notre implémentation CUTLASS 3.6 soigneusement optimisée en interne.
Les performances de DeepGEMM sous certaines formes de matrice spécifiques ne sont pas idéales. Si vous êtes intéressé par l'optimisation, vous êtes invités à soumettre des PR liés à l'optimisation.
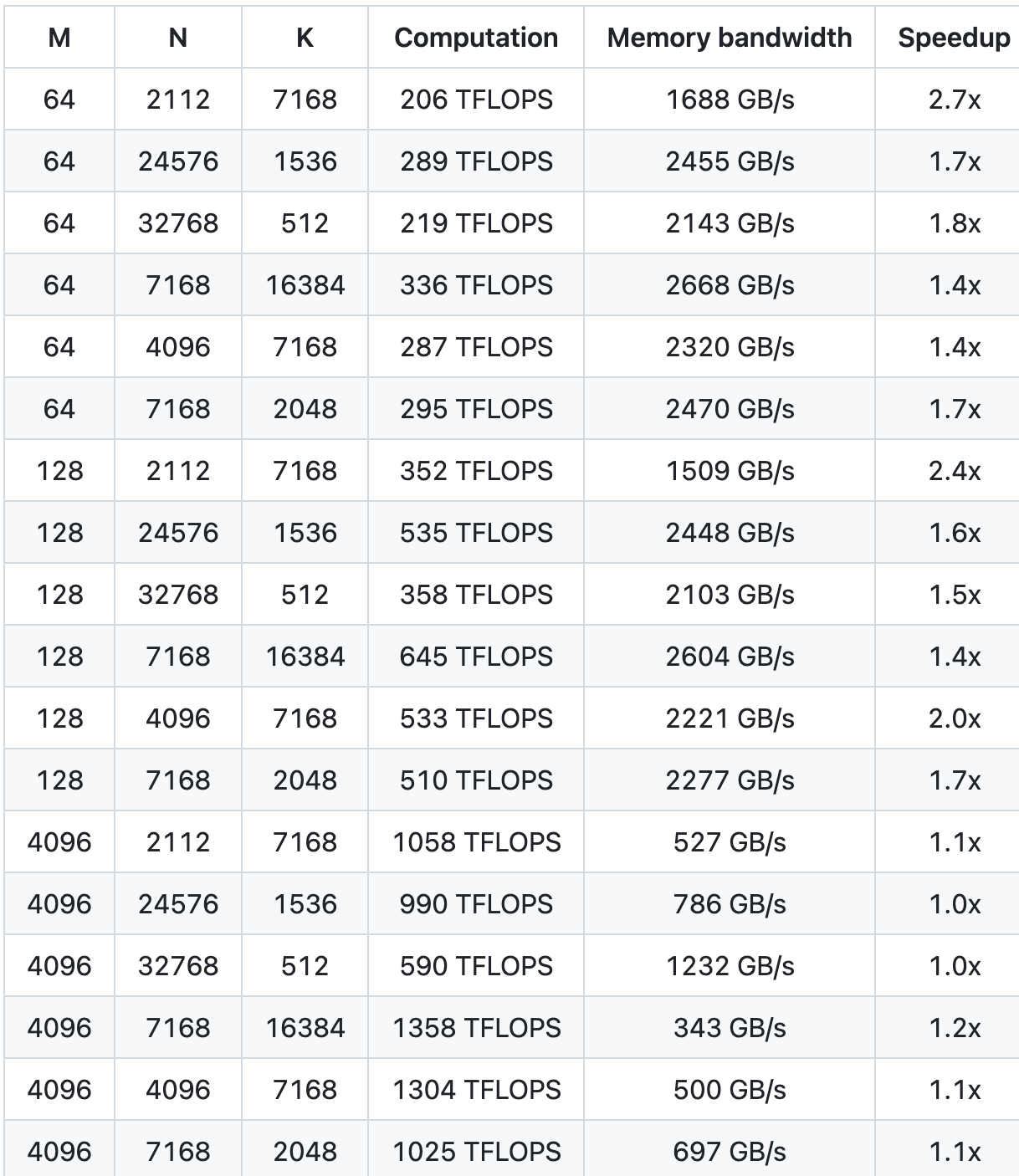
GEMM standard pour les modèles denses
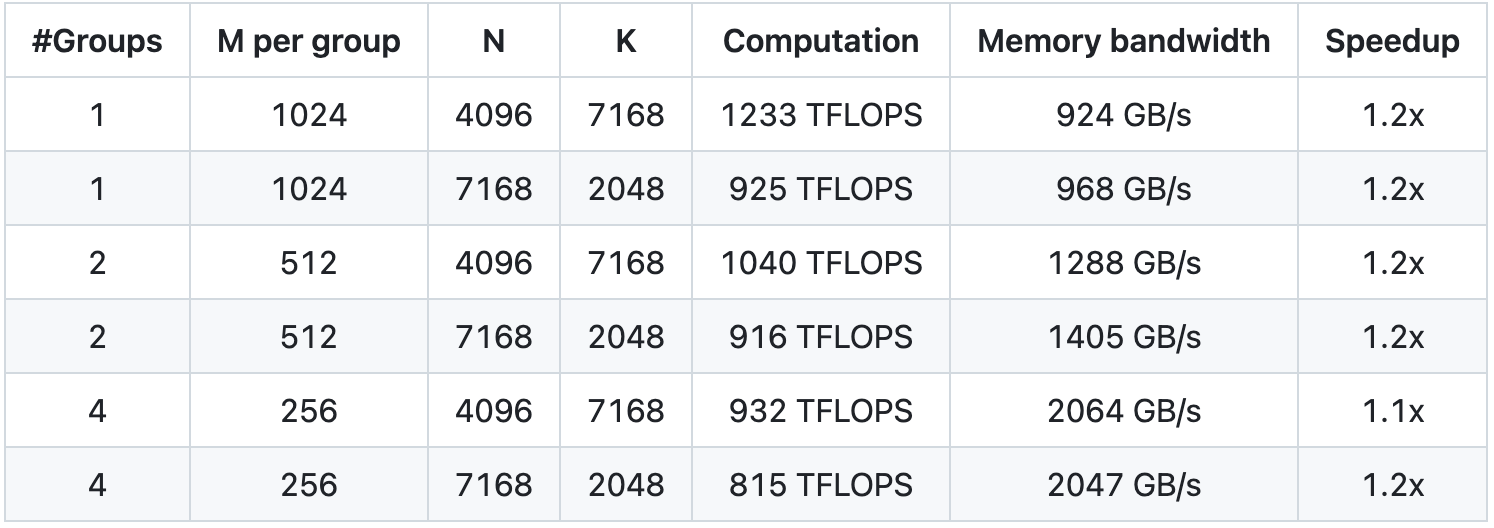
GEMM groupé pour le modèle MoE (mise en page continue)
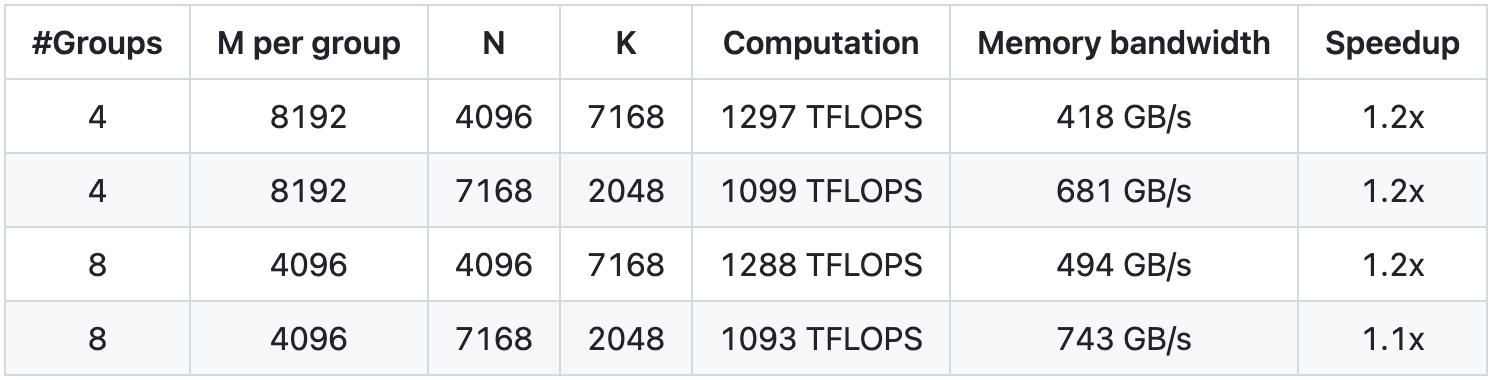
GEMM groupé (disposition des masques) pour le modèle MoE
démarrage rapide
Exigences environnementales
- GPU à architecture Hopper, doit prendre en charge sm_90a
- Python 3.8 et supérieur
- CUDA version 12.3 et supérieure (la version 12.8 et supérieure est fortement recommandée pour de meilleures performances)
- PyTorch 2.1 et supérieur
- CUTLASS 3.6 et supérieur (peut être cloné via le sous-module Git)
développer
# Le sous-module doit être cloné
git clone – récursif [email protected]:deepseek-ai/DeepGEMM.git# Créer des liens symboliques pour des tiers (CUTLASS et CuTe) incluant des répertoires
python setup.py développer# Tester la compilation JIT
tests python/test_jit.py# Testez tous les outils GEMM (normaux, groupés contigus et groupés masqués)
tests python/test_core.py
Installer
installation de python setup.py
Ensuite, importez deep_gemm dans votre projet Python et amusez-vous à l'utiliser !
Ci-joint l'adresse open source GitHub :
https://github.com/deepseek-ai/DeepGEMM
Auteur : Liu Ya, Mo Chongyu
# Bienvenue pour suivre le compte public officiel WeChat d'Aifaner : Aifaner (ID WeChat : ifanr). Un contenu plus passionnant vous sera fourni dès que possible.
Ai Faner | Lien original · Voir les commentaires · Sina Weibo