
Ce générateur d’images IA a publié son premier modèle vidéo : aucune résolution, mais les internautes ont déclaré que l’image était incroyable et dépassait les attentes avec des mots rapides

Confronté à des poursuites pour violation de droits d'auteur de la part de Disney et Universal Pictures, le graphiste chevronné Midjourney n'a pas ralenti le rythme. Au contraire, il a lancé son premier modèle vidéo tôt ce matin, sous pression.
La correspondance des couleurs est précise, la composition est exquise, les émotions sont pleines et le style est toujours en ligne.
Midjourney ne se contente pas de réduire la résolution ni les longues focales, mais offre une atmosphère unique et une esthétique reconnue. Ambitieux, Midjourney vise le « modèle mondial », mais on ignore encore si son design fonctionnel, encore un peu brut, lui permettra d'aller plus loin.
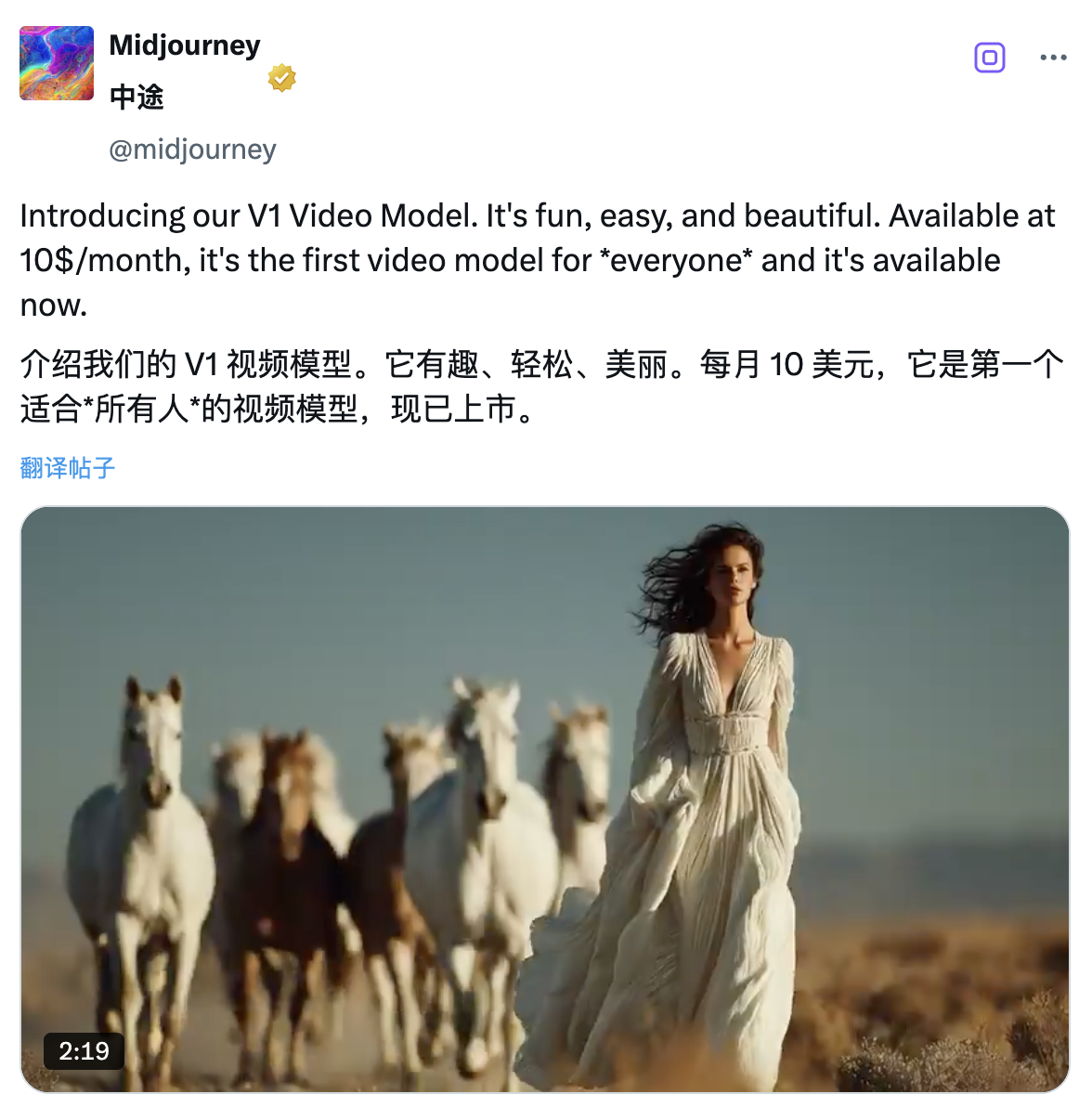
La version à économie de débit est la suivante :
- Après avoir téléchargé ou généré une image, cliquez simplement sur « Animer ». Par défaut, une seule tâche génère quatre vidéos de 5 secondes, extensibles jusqu'à un maximum de 21 secondes.
- Prend en charge les modes manuel et automatique, et les utilisateurs peuvent définir l'effet de génération d'image via des mots-clés ; fournit des options de mouvement faible et de mouvement élevé, adaptées respectivement à une atmosphère statique ou à des scènes dynamiques fortes
- La vidéo est incluse dans les abonnements existants (10 $/mois) et utilise 8 fois plus de ressources GPU que les tâches graphiques
- Il ne prend pas en charge l'ajout d'effets sonores, le montage chronologique, les transitions de clips ni l'accès à l'API. La résolution est de 480p seulement et le format d'image s'adapte automatiquement à l'image. Il s'agit encore d'une version préliminaire.
- Le modèle vidéo est un résultat progressif. À l'avenir, nous continuerons à lancer des modèles 3D et des systèmes temps réel, pour finalement aboutir au modèle mondial.
Le modèle vidéo Midjourney est désormais disponible
Tu fais ta résolution, j'y vais avec mon hyperréalité.
Midjourney a toujours été reconnu pour son style visuel fantastique et surréaliste. À en juger par les résultats testés par les utilisateurs actuels, son modèle vidéo s'inscrit également dans cette tendance esthétique, avec un style stable et une forte notoriété.
Dans la vidéo partagée par le blogueur @EccentrismArt, un jeune garçon chute verticalement d'une hauteur élevée. La modélisation du personnage est simple et dynamique, comme s'il sautait, tombait ou était en chute libre dans un rêve. La trajectoire est fluide et le centre de gravité du personnage est relativement naturel.
Les blocs de la ville sont densément remplis de lumières, et les bâtiments semblent s'incliner et tourner dans l'espace, créant une illusion visuelle de distorsion spatiale, mais la dynamique globale du bâtiment ne présente pas de tremblement évident ni de défauts d'épissage générés par l'IA ;

Dans cette vidéo d'une station de tramway japonaise, le tramway quitte la station et le soleil s'apprête à se coucher. La température des couleurs est parfaitement maîtrisée et la source lumineuse naturelle crée un rythme de mouvement dans l'immobilité et d'immobilité dans le mouvement.

▲Invite : Le train qui traverse la gare. | @PAccetturo
La silhouette d'une femme en chemise tient un document ou un livre. Derrière elle se trouve une immense tête humaine. La composition par exposition multiple et superposition est très soignée, avec un halo naturel et aucune surexposition. Il n'est donc pas étonnant que Phi Hoang, concepteur de Perplexity AI, ait déclaré que le résultat dépassait les attentes.

Le célèbre blogueur X @nickfloats a partagé une vidéo d'une fille marchant sur un quai de gare brillamment éclairé, avec un train à grande vitesse passant en arrière-plan. La séparation des ombres et des lumières était évidente et l'effet tridimensionnel était saisissant.

La coexistence de la nuit, des aurores boréales, de la neige, des phares de voiture, du flou de mouvement et d'autres éléments représente un défi majeur pour le modèle de génération vidéo. Cependant, le modèle gère avec succès l'interférence de multiples sources lumineuses ; les particules de neige, le flou de la vitesse des voitures et les effets de trajectoire sont très cohérents.

▲Invite : Subaru bleue du Rallye mondial 2022, course nocturne à travers la Finlande enneigée, plan d'action spectaculaire, flou de mouvement dynamique, neige qui vole, aurores boréales dans le ciel, phares illuminant la neige, contraste élevé, éclairage cinématographique | @JamianGerard
Vêtus de combinaisons spatiales classiques, un grand nombre de traînées lumineuses colorées s'étendent derrière les astronautes, créant une illusion de « voyage » ou de « mouvement à grande vitesse » avec un fort sens du rythme visuel.

▲Invite : « Je vis un peu, je prends de l'acide et je m'envole. Je me sens comme un astronaute dans l'espace. Je ne pense pas que cela fera les dégâts qu'ils disent. Je me sens comme un astronaute dans l'espace. » | @JamianGerard
Des éléments tels que les reflets, les matériaux et le mouvement des liquides sont autant de fenêtres permettant de tester la capacité du modèle d'IA à exprimer des natures mortes. Dans cette vidéo, les glaçons, la crème et le caramel sont dynamiques et naturels, et l'étiquette ne présente aucune distorsion apparente lors de la rotation de la tasse.

▲Invite : Une boisson Starbucks, une grande tasse classique, un macchiato glacé au caramel, un filet de caramel tourbillonnant, de la crème fouettée sur le dessus, de la condensation sur la tasse, vibrante et appétissante, une photographie de boisson de haute qualité, un rapport hauteur/largeur de 1:1. | @JamianGerard
Le sens de la profondeur de la perspective est clair, la distance et la proximité sont correctement superposées et le style réaliste est également fort.

▲Invite : Assis au milieu de la jungle avec beaucoup d'animaux sauvages qui se déplacent S | @JamianGerard
Dans les rues apocalyptiques de New York, il y a beaucoup de détails tels que des voitures en feu et des ruines ; selon les exigences des mots d'invite, la vidéo générée doit avoir une texture de film 35 mm, et elle est également légèrement granuleuse dans l'ensemble.

▲Invite : Une rue au petit matin, avec des voitures en feu et des débris éparpillés un peu partout. La scène évoque le New York des années 1990, immortalisée dans le style du photographe Jeff Wall, avec la texture granuleuse d'une pellicule 35 mm. | @JamianGerard
La boule de cristal flotte et tourne lentement, ce qui teste la stabilité de la scène et le mouvement de la caméra est également assez fluide.

▲Invite : sphère cristalline planant et tournant lentement au-dessus d'un champ calme et coloré, prise de vue en caméra stable | @JamianGerard
Il convient de noter que les résultats de génération de cas présentés ci-dessus peuvent avoir subi plusieurs cycles de « tirage de cartes », mais à en juger par l'effet final, l'achèvement visuel est déjà assez impressionnant.
Ambitious Midjourney construit le deuxième élément constitutif du « modèle mondial »
À partir d'aujourd'hui, les utilisateurs de Midjourney peuvent télécharger des images sur le site officiel (Midjourney.com), ou utiliser directement les images générées par la plateforme, et cliquer sur le bouton « Animer » pour convertir les images en vidéos.
Chaque tâche générera quatre vidéos de cinq secondes, et les utilisateurs pourront allonger chaque segment jusqu'à quatre fois, en l'augmentant de quatre secondes à chaque fois, pour une durée totale maximale de 21 secondes. Bien sûr, les débuts sont difficiles, et le responsable a indiqué que la durée et les fonctionnalités seraient encore étendues ultérieurement.
Le seuil de la logique opérationnelle n'est pas très élevé. Vous pouvez créer des images dans Midjourney comme d'habitude, mais une étape supplémentaire permet désormais d'animer l'image. De plus, vous pouvez importer des images externes comme « image de départ », puis utiliser des mots clés pour décrire l'effet dynamique souhaité.
V1 fournit des paramètres personnalisés réglables pour permettre aux utilisateurs d'avoir un contrôle plus détaillé sur le contenu de l'image.
En mode manuel, vous pouvez saisir des repères spécifiques pour définir automatiquement la manière dont les éléments de la vidéo se déplacent et dont la scène se développe, mais si vous n'avez pas encore d'idée pour les repères, vous pouvez choisir un paramètre automatique qui générera automatiquement des repères de mouvement pour vous et fera bouger les images.
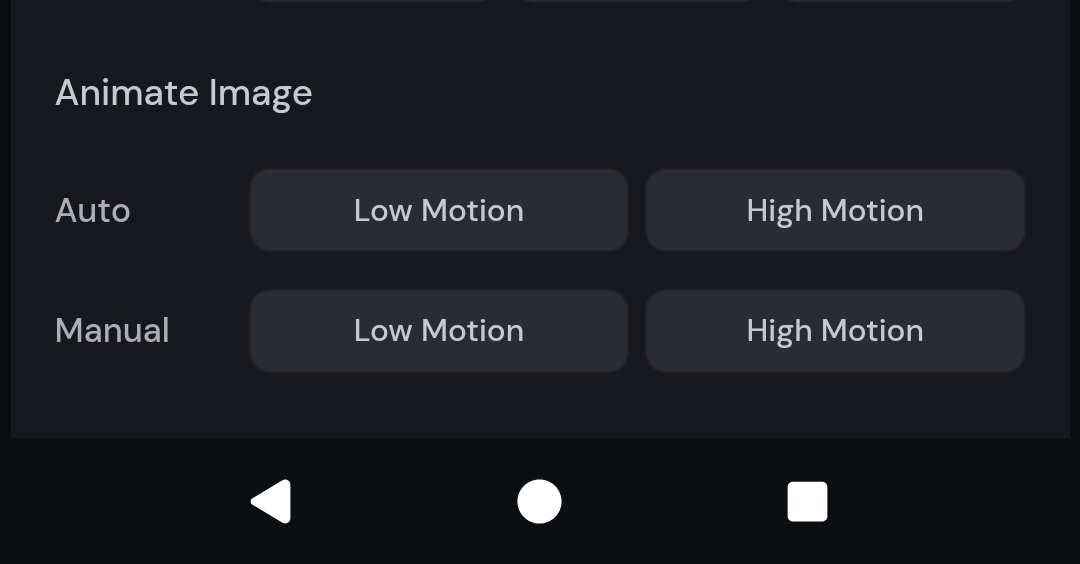
En termes de style créatif, vous pouvez également choisir entre deux paramètres de mouvement :
- Mode faible mouvement : adapté aux scènes atmosphériques, l'appareil photo reste généralement immobile et le sujet se déplace lentement ou rythmiquement. L'inconvénient est qu'il peut parfois ne pas y avoir de mouvement du tout (personnes qui clignent des yeux, brise qui souffle sur le paysage, etc.).
- Mode mouvement intense : Convient aux scènes nécessitant beaucoup de mouvement, tant de l'objectif que du sujet. L'inconvénient est que des mouvements importants peuvent parfois entraîner des erreurs d'image ou une instabilité.
En termes de prix, la fonction vidéo est directement intégrée au système d'abonnement de Midjourney, et le prix de départ est toujours de 10 $ US par mois.
Selon le blog officiel, Midjourney nécessite environ huit fois plus de temps GPU par vidéo que les tâches d'imagerie. Cependant, en supposant qu'il puisse générer des vidéos d'une durée maximale de 20 secondes, le coût moyen par seconde est quasiment identique à celui de la génération d'images. Comparé aux produits concurrents, son rapport coût-efficacité est le meilleur.
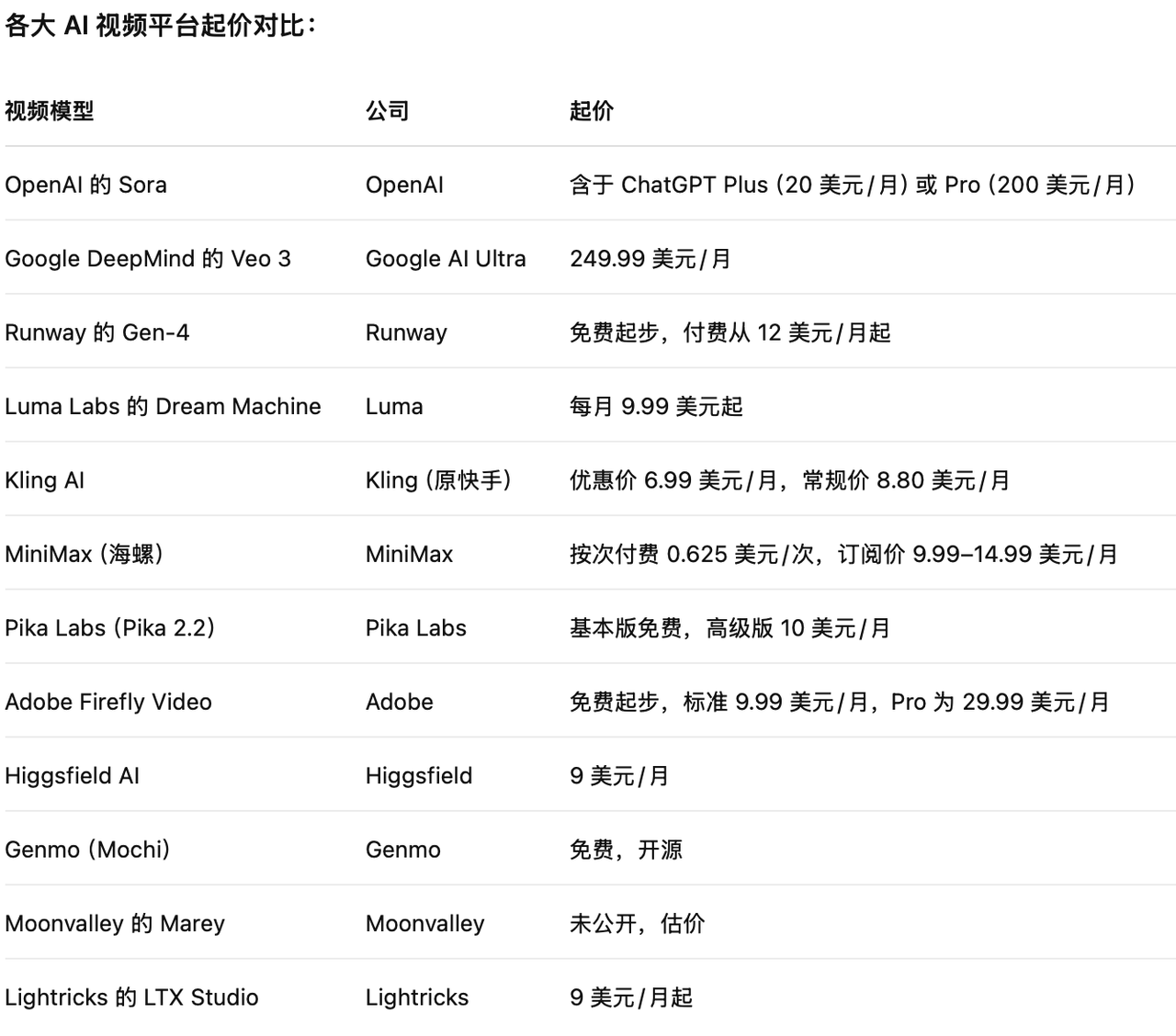
Nous avons également utilisé le moteur de recherche IA pour trier brièvement les frais d'abonnement de certains modèles vidéo grand public pour votre référence. 
De plus, Midjourney teste le « Mode Relax » pour les abonnés Pro et supérieurs, ce qui permet d'effectuer la génération à une vitesse plus lente, réduisant ainsi la consommation de ressources de calcul. Les utilisateurs des autres niveaux restent facturés en fonction du temps GPU et du niveau d'abonnement.
À l'heure actuelle, le modèle vidéo Midjourney présente de nombreux points à critiquer. Le plus courant est l'absence de fonctionnalités clés pour la création professionnelle.
Tout d'abord, contrairement à Veo 3 de Google ou à Dream Machine de Luma, le modèle vidéo Midjourney ne prend actuellement pas en charge l'ajout automatique de musique de fond ou d'effets sonores d'ambiance. Si du son est nécessaire, il doit être ajouté manuellement à l'aide d'outils tiers.
Deuxièmement, le modèle vidéo Midjourney ne prend pas en charge l'édition de la chronologie, et les clips vidéo générés sont des « coupes sautées », ce qui rend impossible la continuité de l'histoire et la connexion naturelle entre les images, ce qui rend difficile le contrôle du rythme de l'intrigue ou de la préfiguration émotionnelle.
De plus, le modèle vidéo Midjourney ne fournit actuellement pas d’accès API.
Plus important encore, la résolution par défaut des vidéos générées par Midjourney est de 480p (définition standard), et le format d'image est automatiquement adapté à la taille d'origine de l'image. L'image sera également marquée comme 480p lors de sa mise en ligne sur d'autres plateformes.
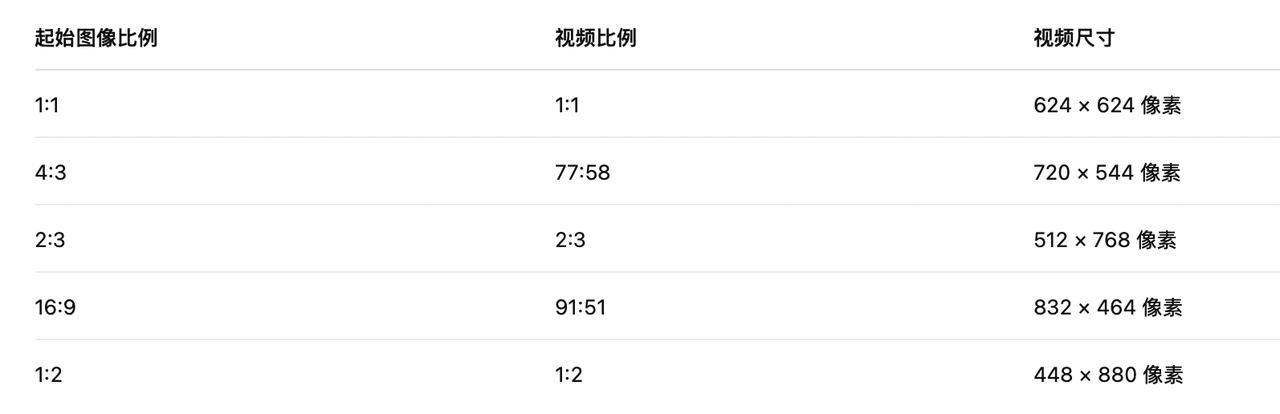
▲Remarque : Midjourney peut ajuster légèrement le rapport hauteur/largeur et les proportions de la vidéo de sortie finale peuvent être légèrement différentes de l'image de départ.
Les responsables de Midjourney ont également admis que la version actuelle en est encore au stade de l'exploration précoce, se concentrant sur l'accessibilité, la facilité d'utilisation et l'évolutivité.
Le modèle vidéo n'est qu'une coupe. Midjourney souhaite un système de production de contenu plus complet.
Selon son plan officiel, l'objectif ultime est de construire un « modèle mondial », c'est-à-dire d'intégrer la génération d'images, le contrôle de l'animation, la navigation spatiale tridimensionnelle et le rendu en temps réel.
Vous pouvez le considérer comme, dans un système d'IA capable de générer des images en temps réel, vous pouvez saisir une phrase pour ordonner au protagoniste de l'IA de se déplacer dans l'espace 3D, la scène de l'environnement changera en conséquence et vous pourrez interagir avec tout.
Tout comme les blocs de construction, pour atteindre cet objectif, nous avons besoin d'un modèle d'image (pour générer des images statiques) → d'un modèle vidéo (pour faire bouger les images) → d'un modèle 3D (pour réaliser la navigation spatiale et le mouvement de l'objectif) → d'un modèle en temps réel (pour garantir que chaque image peut répondre de manière synchrone).
Selon le plan produit de Midjourney, ces quatre « blocs techniques » seront livrés au cours des 12 prochains mois et intégrés à terme dans un système unifié. Le modèle vidéo V1, issu de phases successives, constitue la deuxième étape vers cet objectif ultime.
#Bienvenue pour suivre le compte public officiel WeChat d'iFanr : iFanr (ID WeChat : ifanr), où du contenu plus passionnant vous sera présenté dès que possible.