
Exécuter Stable Diffusion et de grands modèles bout à bout sur des ordinateurs portables fins et légers ? Intel dit pas de problème

Qu'ils soient passifs ou actifs, des noms tels que big model, AIGC, ChatGPT, Stable Diffusion, MidJourney, etc. sont bombardés dans les listes d'actualités de tout le monde. Après les surprises, la panique, les attentes et les inquiétudes du premier semestre, AIGC n'est plus L’Évangile ou la seconde venue de Skynet, les gens ont commencé à y faire face carrément, à le comprendre et à l’utiliser de manière appropriée.
Bien sûr, cette vague d'AIGC se produit principalement dans le cloud, qu'il s'agisse de ChatGPT, ou Wenxin Yiyan, Tongyi Qianwen et d'autres grandes applications de modèles de langage, ou MidJourney et d'autres applications d'images générées par l'IA, il en existe de nombreuses comme la vidéo générée par l'IA. des applications telles que Runway doivent être connectées à Internet, car les calculs de l'IA sont effectués sur des serveurs cloud situés à des milliers de kilomètres.
Après tout, d'une manière générale, la puissance de calcul et le stockage qui peuvent être fournis par le côté serveur sont bien supérieurs à ceux du côté ordinateur et du côté mobile, mais la situation n'est pas absolue. pour la mise en réseau est sans aucun doute une autre tendance, et l'IA cloud capable de se compléter.
Dans le discours annuel de Xiaomi il n'y a pas si longtemps, le fondateur de Xiaomi, Lei Jun, a déclaré que le dernier modèle de 1,3 milliard de paramètres du modèle d'IA de Xiaomi avait été exécuté avec succès localement sur le téléphone mobile et que certains scénarios pouvaient être comparés aux résultats du modèle de 6 milliards de paramètres en cours d'exécution. sur le nuage.
Bien que le nombre de paramètres ne soit pas trop important, il illustre la faisabilité et le potentiel du grand modèle bout à côte.
Du côté des PC, avec une puissance de calcul beaucoup plus importante, existe-t-il également la faisabilité et le potentiel des applications AIGC telles que les grands modèles du côté des appareils ? Le 18 août, Intel a organisé une session de partage technologique, axée sur le partage de deux aspects d'informations : les mises à jour des performances d'Intel Sharp Graphics DX11 et le lancement du nouvel outil Intel PresentMon Beta, ainsi que l'affichage des progrès d'Intel dans le domaine de l'AIGC.

Lorsque les produits de bureau Intel Sharp ont été lancés l'année dernière, il a été promis que les cartes graphiques Intel Sharp continueraient d'être optimisées et mises à niveau pour offrir une meilleure expérience.
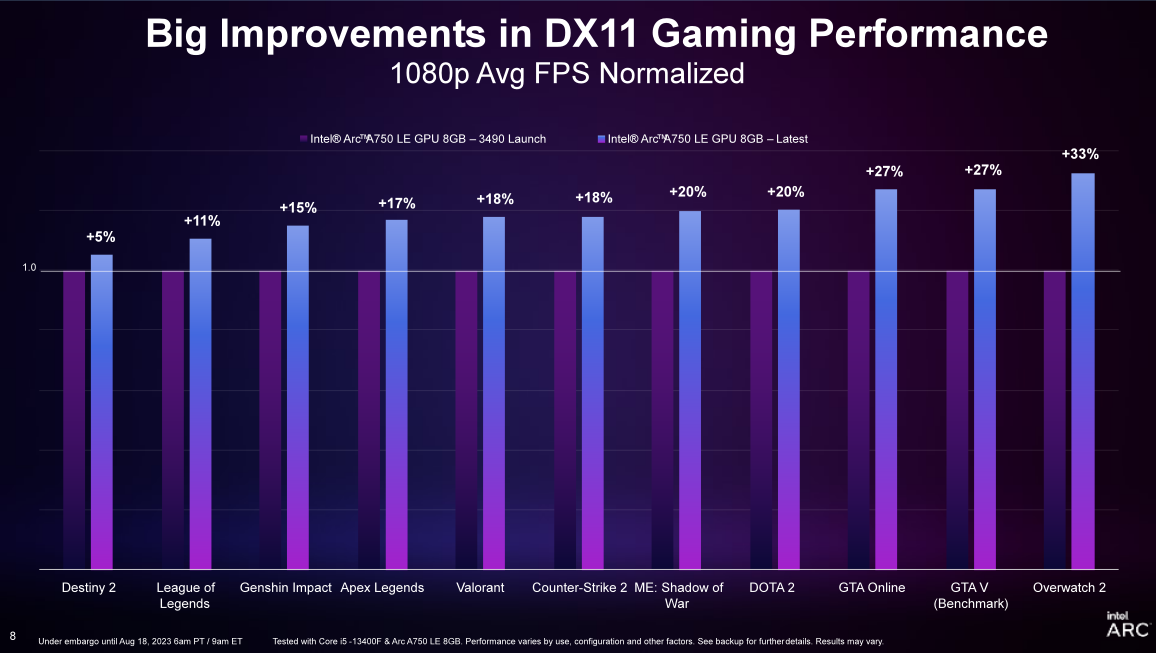
Grâce à la sortie du dernier pilote Game On, Intel Ruixuan Graphics peut atteindre une augmentation de la fréquence d'images de 19 % lors de l'exécution d'une série de jeux DX11, et une amélioration moyenne d'environ 20 % de la fluidité de la fréquence d'images au 99e centile (par rapport à la première version du pilote). . Les utilisateurs qui ont déjà acheté et utilisé la carte graphique Intel Sharp A750 peuvent télécharger directement le dernier pilote et bénéficier de mises à niveau d'expérience dans des jeux tels que Overwatch 2, DOTA 2 et Apex Legends.
Pour les utilisateurs qui hésitent un peu à choisir une carte graphique, la carte graphique Ruixuan A750 dans la gamme 1700 yuans est également devenue un choix assez compétitif.
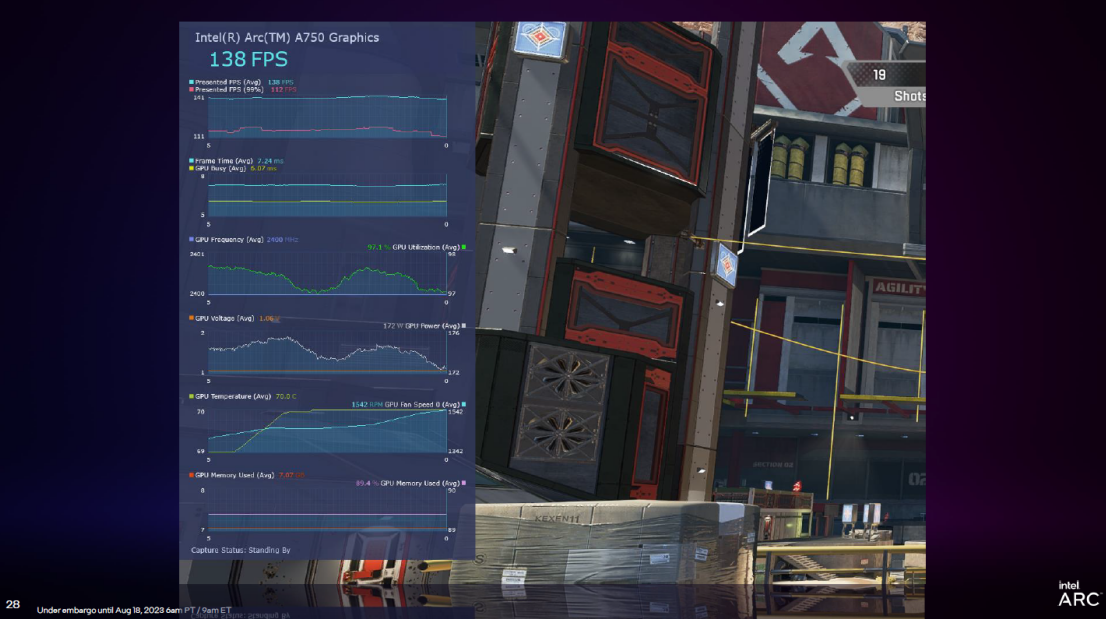
PresentMon Beta est un outil d'analyse des performances graphiques lancé par Intel. Il fournit des fonctions telles que Overlay (vue superposée), qui peut afficher les données de performances sur l'écran pendant l'exécution du jeu et aider les joueurs à télémesurer la tension et la température du GPU en temps réel. , et analyser une grande quantité d’informations en temps réel. Consultez également le graphique du temps d’image du 99e centile par rapport à l’utilisation du GPU.
De plus, PresentMon Beta apporte également un nouvel indicateur appelé « GPU Busy ». Voici une explication, afin que les utilisateurs puissent voir combien de temps le GPU utilise réellement pour le rendu réel au lieu d'attendre, ou si le PC exécutant le jeu est en équilibre CPU et GPU.
Les jeux sont un thème éternel du PC, tandis que l’IA est un nouveau thème.
En fait, l'équipement principal pour cette vague AIGC est le PC, qu'il s'agisse de ChatGPT, MidJourney ou Stable Diffusion et d'autres applications, dont Microsoft Office Copilot basé sur de grands modèles, ou WPS AI de Kingsoft Office. sur PC.
Cependant, par rapport à d'autres appareils, tels que les téléphones mobiles, les tablettes et les PC, les avantages des PC résident non seulement dans des écrans plus grands et une saisie interactive plus efficace, mais également dans les performances des puces.
Avant qu'Intel ne parle de l'AIGC sur les PC, nous avons remarqué que l'exécution côte à côte de l'AIGC sur les PC utilise souvent des ordinateurs portables de jeu hautes performances pour exécuter des graphiques, mais les ordinateurs portables fins et légers sont souvent exclus.
Désormais, Intel a clairement déclaré que l'instinct fin et léger basé sur les processeurs Intel peut exécuter de grands modèles, ainsi que de grands modèles et une diffusion stable.
La solution back-end d'Intel basée sur OpenVINO PyTorch (une boîte à outils open source lancée par Intel pour optimiser les performances d'inférence des modèles d'apprentissage en profondeur et les déployer sur différentes plates-formes matérielles), via l'API Pytorch, le modèle open source communautaire peut bien fonctionner sur Processeurs clients Intel, graphiques intégrés, graphiques discrets et moteurs d'IA dédiés.
Par exemple, le modèle de génération d'images open source Stable Diffusion (en particulier, Automatic1111 WebUI) peut exécuter des modèles de précision FP16 sur des processeurs et GPU Intel (y compris des cartes graphiques intégrées et des cartes graphiques discrètes) de cette manière, et les utilisateurs peuvent générer du texte et des images. Fonctions telles que la génération d'images et la réparation partielle.

▲ Photo de : Aijiwu
Par exemple, cette image de crêpe au miel d'une résolution de 512 × 512 peut être générée en seulement une douzaine de secondes sur un ordinateur portable fin et léger à processeur Intel (en utilisant uniquement l'écran principal i7-13700H).
Cela est principalement dû aux progrès du processeur Core de 13e génération en termes de nombre de cœurs, de performances, de taux de consommation d'énergie et de performances graphiques. En prenant comme exemple le processeur i7-13700H avec 14 cœurs et 20 threads, son TDP a atteint 45 W, et le intégré La carte graphique Intel Iris Xe Graphics (96EU) ne doit pas non plus être sous-estimée.
En tant qu'écran de base avec les spécifications les plus élevées à l'heure actuelle, Intel Iris Xe Graphics (96EU) atteint 64EU par rapport à l'écran de base Iris Plus, la spécification de base est considérablement améliorée, les performances en virgule flottante FP16, FP32 sont améliorées jusqu'à 84 % , et le calcul d'entiers INT8 est également introduit Capacité, ceux-ci ont amélioré ses capacités de calcul graphique AI, et c'est également la principale raison pour laquelle les livres fins et légers d'Intel peuvent bien prendre en charge la diffusion stable.
Dans le passé, les processeurs Intel avec un TDP d'environ 45 W étaient difficiles à intégrer dans des ordinateurs portables fins et légers, mais avec le Core de 13e génération, il y a eu un grand nombre d'ordinateurs portables fins et légers d'environ 1,4 kg avec 14 cœurs, 20 threads, Processeurs i7-13700H et performances encore plus élevées. Le processeur i7-13900H est branché, donc exécuter Stable Diffusion sur un ordinateur portable pour produire rapidement des images n'est plus exclusif aux ordinateurs portables de jeu hautes performances, et les ordinateurs portables fins et légers pourront également faire ce travail à l'avenir.
Bien sûr, Stable Diffusion lui-même fonctionne principalement localement, et il est logique que les ordinateurs portables fins et légers fonctionnent grâce à l'amélioration et à l'optimisation des performances de la puce, mais le grand modèle local côté extrémité est une chose relativement nouvelle.
Grâce à l'optimisation du modèle, la demande en ressources matérielles du modèle est réduite, améliorant ainsi la vitesse d'inférence du modèle, et Intel permet à certains modèles open source communautaires de fonctionner correctement sur des ordinateurs personnels.
En prenant le grand modèle de langage comme exemple, Intel utilise l'accélération du processeur Intel Core XPU de 13e génération, la quantification low-bit et d'autres optimisations au niveau logiciel pour permettre à un grand modèle de langage avec jusqu'à 16 milliards de paramètres de fonctionner sur 16 Go via le framework BigDL-LLM sur un ordinateur personnel avec une capacité de mémoire et supérieure.
Bien qu'il existe un écart d'un ordre de grandeur par rapport aux 175 milliards de paramètres de ChatGPT3.5, après tout, ChatGPT3.5 fonctionne sur un cluster de réseau AGI construit avec 10 000 puces Nvidia V100. Et ce grand modèle avec 16 milliards de paramètres exécutés via le framework BigDL-LLM fonctionne sur un processeur tel qu'Intel Core i7-13700H ou i7-13900H, conçu pour les ordinateurs portables fins et légers hautes performances.
Cependant, on peut également voir ici que le grand modèle de langage côté PC est également d'un ordre de grandeur supérieur à celui du côté téléphone mobile.
Les PC qui existent depuis des décennies ne sont pas des outils permettant d'exécuter de grands modèles dans le cloud. Grâce aux progrès matériels, les PC pris en charge par les processeurs Intel ont pu se connecter rapidement aux modèles émergents et sont compatibles avec les modèles Transformers sur HuggingFace. vérifiés jusqu'à présent incluent, sans s'y limiter : LLAMA/LLAMA2, ChatGLM/ChatGLM2, MPT, Falcon, MOSS, Baichuan, QWen, Dolly, RedPajama, StarCoder, Whisper, etc.
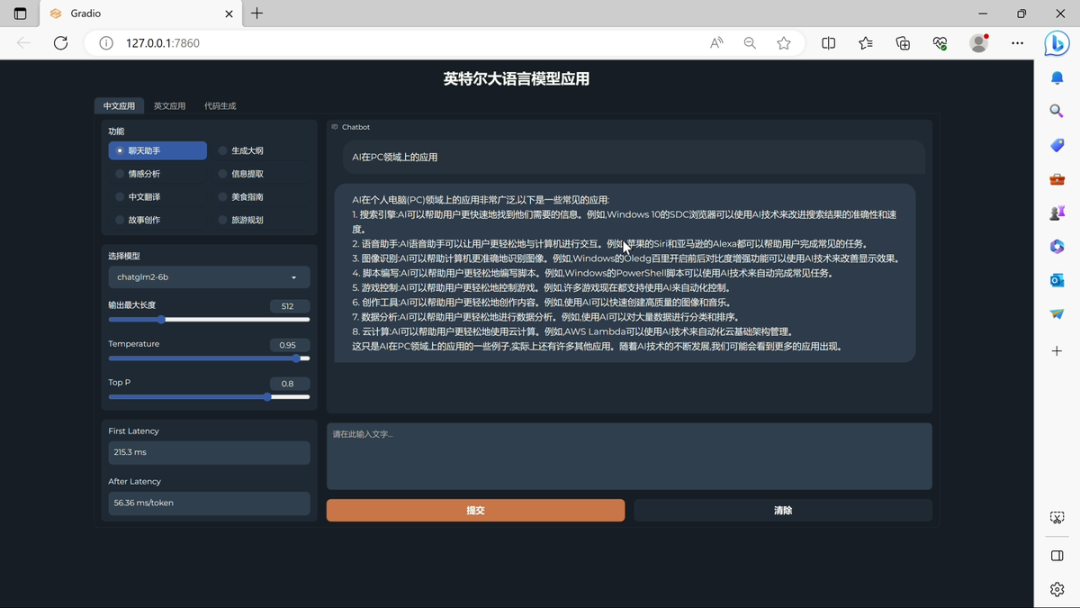
▲ Photo de : Aijiwu
Lors de la réunion de partage technologique, Intel a démontré les performances de l'exécution d'un grand modèle basé sur le périphérique Core i7-13700H : ChatGLM-6b peut atteindre la première latence de la première génération de jetons de 241,7 ms, et le taux de génération moyen des jetons suivants est de 55,63 ms. /jeton. Dans le domaine du traitement du langage naturel, « jeton » fait référence à une unité de base dans le texte, qui peut être un mot, un mot, un sous-mot, un signe de ponctuation ou d'autres plus petites unités pouvant être traitées sémantiquement. Comme vous pouvez le constater, la vitesse du processeur est plutôt bonne.
La nouvelle qui est encore disponible est que le processeur Intel Meteor Lake de nouvelle génération présente les avantages d'une architecture de modules séparés unique pour mieux servir l'IA, y compris des fonctions multimédia telles que le recadrage automatique et la détection de l'édition de scène dans Adobe Premiere Pro, et obtenir une machine plus efficace. accélération de l’apprentissage.
Bien que l'AIGC soit un mot-clé en 2023, l'IA n'est pas nouvelle, et c'est aussi un mot-clé dont Intel a souvent parlé ces dernières années.
La réduction du bruit des appels vidéo AI antérieure, la réduction du bruit de fond des appels vidéo AI, etc., sont en fait des applications de l'IA.
On voit que la compétitivité des futurs processeurs ne se limitera pas au nombre de cœurs, au nombre de threads et à la fréquence principale, l'un des facteurs que le produit prendra en compte.
#Bienvenue pour suivre le compte public WeChat officiel d'Aifaner : Aifaner (WeChat ID : ifanr), un contenu plus excitant vous sera présenté dès que possible.
Ai Faner | Lien original · Voir les commentaires · Sina Weibo