
DeepSeek domine l’App Store, une semaine au cours de laquelle l’IA chinoise a provoqué un tremblement de terre dans le monde technologique américain

La semaine dernière, le modèle DeepSeek R1 en provenance de Chine a remué tout le cercle de l'IA à l'étranger.
D'une part, il atteint des performances comparables à celles d'OpenAI o1 avec des coûts de formation inférieurs, démontrant les avantages de la Chine en termes de capacités d'ingénierie et d'innovation à grande échelle ; d'autre part, il défend également l'esprit open source et est désireux de partager les détails techniques ;
Récemment, une équipe de recherche de Jiayi Pan, doctorant à l'Université de Californie à Berkeley, a réussi à reproduire la technologie clé de DeepSeek R1-Zero – le « Aha Moment » – à un coût très faible (moins que celui des États-Unis). 30 $).

Il n’est donc pas étonnant que Zuckerberg, PDG de Meta, Yann LeCun, lauréat du Turing Award, et Demis Hassabis, PDG de Deepmind, aient tous fait l’éloge de DeepSeek.
Alors que la popularité de DeepSeek R1 continue d'augmenter, cet après-midi, l'application DeepSeek a temporairement connu une situation de serveur occupé en raison d'une augmentation des visites d'utilisateurs, et a même « planté » pendant un certain temps.
Le PDG d'OpenAI, Sam Altman, vient de tenter de révéler la limite d'utilisation d'o3-mini pour faire la une des médias internationaux : les membres de ChatGPT Plus peuvent interroger 100 fois par jour.
Cependant, ce que l’on sait peu, c’est qu’avant de devenir célèbre, la société mère de DeepSeek, Huanfang Quantitative, était en fait l’une des sociétés leaders dans le domaine du capital-investissement quantitatif national.
Le modèle DeepSeek a choqué la Silicon Valley et sa teneur en or continue d'augmenter
Le 26 décembre 2024, DeepSeek a officiellement lancé le grand modèle DeepSeek-V3.
Ce modèle présente d'excellentes performances dans plusieurs tests de référence, surpassant les meilleurs modèles traditionnels du secteur, en particulier dans des domaines tels que les questions et réponses de connaissances, le traitement de textes longs, la génération de code et les capacités mathématiques. Par exemple, dans les tâches de connaissances telles que MMLU et GPQA, les performances de DeepSeek-V3 sont proches du top modèle international Claude-3.5-Sonnet.
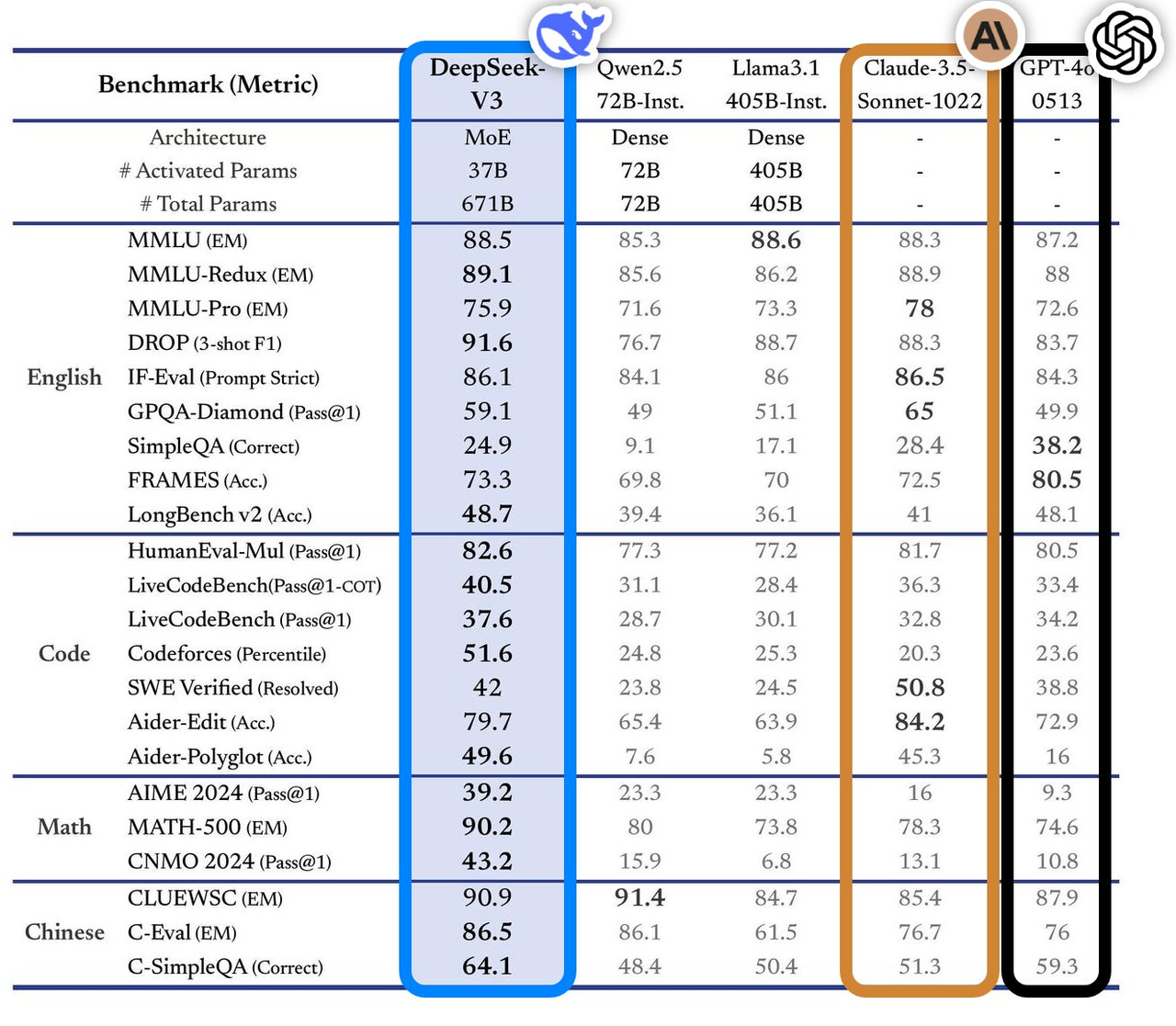
En termes de capacité mathématique, il a établi de nouveaux records dans des tests tels que AIME 2024 et CNMO 2024, surpassant tous les modèles open source et fermés connus. Dans le même temps, sa vitesse de génération a augmenté de 200 % par rapport à la génération précédente, atteignant 60 TPS, ce qui améliore considérablement l'expérience utilisateur.
Selon l'analyse du site d'évaluation indépendant Artificial Analysis, DeepSeek-V3 surpasse les autres modèles open source dans de nombreux indicateurs clés et est à égalité avec les meilleurs modèles fermés au monde GPT-4o et Claude-3.5-Sonnet en termes de performances.
Les principaux avantages techniques de DeepSeek-V3 incluent :
- Architecture Mixed Expert (MoE) : DeepSeek-V3 possède 671 milliards de paramètres, mais en fonctionnement réel, seuls 37 milliards de paramètres sont activés pour chaque entrée. Cette méthode d'activation sélective réduit considérablement les coûts de calcul tout en maintenant des performances élevées.
- Attention latente multi-têtes (MLA) : cette architecture a été éprouvée dans DeepSeek-V2 et peut réaliser une formation et une inférence efficaces.
- Stratégie d'équilibrage de charge sans pertes auxiliaires : cette stratégie est conçue pour minimiser l'impact négatif de l'équilibrage de charge sur les performances du modèle.
- Cible d'entraînement à la prédiction multi-jetons : cette stratégie améliore les performances globales du modèle.
- Cadre de formation efficace : utilisant le cadre HAI-LLM, il prend en charge le parallélisme de pipeline (PP) à 16 voies, le parallélisme expert (EP) à 64 voies et le parallélisme de données ZeRO-1 (DP), et réduit les coûts de formation grâce à une variété de méthodes d'optimisation. .
Plus important encore, le coût de formation de DeepSeek-V3 n'est que de 5,58 millions de dollars, ce qui est bien inférieur à celui de GPT-4, dont le coût de formation s'élève à 78 millions de dollars. De plus, les prix de ses services API restent également avantageux pour les gens dans le passé.
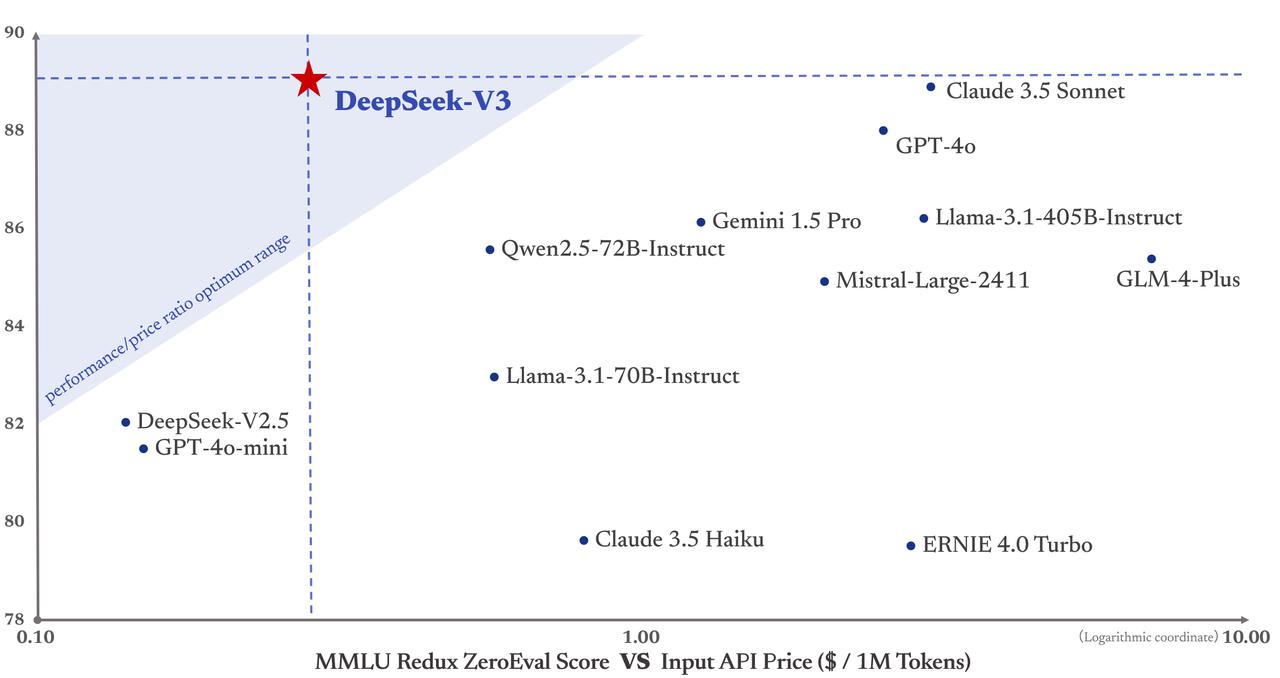
Les jetons d'entrée ne coûtent que 0,5 yuans (cache atteint) ou 2 yuans (cache manqué) par million, et les jetons de sortie ne coûtent que 8 yuans par million.
Le Financial Times l'a décrit comme « un cheval noir qui a choqué la communauté technologique internationale » et a estimé que ses performances étaient comparables à celles de modèles rivaux américains tels que l'OpenAI, bien financé. Le fondateur de Maginative, Chris McKay, a en outre souligné que le succès de DeepSeek-V3 pourrait redéfinir les méthodes établies de développement de modèles d'IA.
En d’autres termes, le succès de DeepSeek-V3 est également considéré comme une réponse directe aux restrictions américaines sur les exportations de puissance de calcul. Cette pression extérieure a plutôt stimulé l’innovation chinoise.
Liang Wenfeng, fondateur de DeepSeek, un génie discret de l'Université du Zhejiang
L'essor de DeepSeek a rendu la Silicon Valley insomniaque. Liang Wenfeng, le fondateur de ce modèle qui a bouleversé l'industrie mondiale de l'IA, explique parfaitement la trajectoire de croissance des génies au sens traditionnel du terme chinois : jeune succès, succès durable.
Un bon dirigeant d’entreprise en IA doit comprendre à la fois la technologie et les affaires, être à la fois visionnaire et pragmatique, avoir le courage d’innover et faire preuve de discipline en ingénierie. Ce type de talent composé en lui-même est une ressource rare.
À l'âge de 17 ans, il a été admis à l'Université du Zhejiang avec une spécialisation en ingénierie de l'information et de l'électronique. À l'âge de 30 ans, il a fondé Hquant et a commencé à diriger l'équipe chargée d'explorer le trading quantitatif entièrement automatisé. L’histoire de Liang Wenfeng prouve que le génie fait toujours la bonne chose au bon moment.

- 2010 : Avec le lancement des contrats à terme sur indices boursiers CSI 300, l'investissement quantitatif a ouvert la voie à des opportunités de développement. L'équipe de Huanfang a profité de l'élan et ses fonds autogérés ont connu une croissance rapide.
- 2015 : Liang Wenfeng co-fonde Magic Square Quantification avec ses anciens élèves. L'année suivante, il lance le premier modèle d'IA et lance des positions de trading générées par le deep learning.
- 2017 : Huanfang Quantitative prétend mettre en œuvre une stratégie d'investissement globale basée sur l'IA.
- 2018 : Établir l'IA comme principale direction de développement de l'entreprise.
- 2019 : L'échelle de gestion des fonds a dépassé les 10 milliards de yuans, devenant ainsi l'un des « quatre géants » du capital-investissement quantitatif national.
- 2021 : Huanfang Quantitative devient la première société nationale de capital-investissement quantitatif à dépasser les 100 milliards.
Vous ne pouvez pas simplement réussir en pensant à l’entreprise qui a passé les dernières années à l’écart. Cependant, tout comme la transformation des sociétés de commerce quantitatif vers l’IA, cela peut sembler inattendu, mais c’est en fait logique – car ce sont toutes des industries à forte intensité technologique basées sur les données.
Huang Renxun voulait seulement vendre des cartes graphiques de jeux pour gagner de l'argent pour ceux d'entre nous qui ne savent pas jouer à des jeux, mais il ne s'attendait pas à devenir le plus grand arsenal d'IA au monde. C'est similaire à l'entrée de Huanfang dans le domaine de l'IA. Ce type d’évolution est plus viable que les modèles d’IA à grande échelle que de nombreuses industries appliquent actuellement mécaniquement.
Magic Square Quantitative a accumulé une grande expérience dans le traitement des données et l'optimisation des algorithmes dans le processus d'investissement quantitatif. Il dispose également d'un grand nombre de puces A100, qui fournissent un solide support matériel pour la formation des modèles d'IA. Depuis 2017, Huanfang a déployé la puissance de calcul de l'IA à grande échelle et construit des clusters de calcul hautes performances tels que « Yinghuo 1 » et « Yinghuo 2 » pour fournir une puissance de calcul puissante pour la formation des modèles d'IA.

En 2023, Magic Square Quantification a officiellement créé DeepSeek pour se concentrer sur le développement de grands modèles d'IA. DeepSeek a hérité de l'accumulation de technologies, de talents et de ressources de Magic Quantitative et a rapidement émergé dans le domaine de l'IA.
Dans une interview approfondie avec « Undercurrent », le fondateur de DeepSeek, Liang Wenfeng, a également montré une vision stratégique unique.
Contrairement à la plupart des entreprises chinoises qui choisissent de copier l'architecture Llama, DeepSeek part directement de la structure du modèle, histoire de viser l'objectif ambitieux d'AGI.
Liang Wenfeng ne cache pas l'écart actuel : il existe actuellement un écart important entre l'IA chinoise et les plus hauts niveaux internationaux. L'écart considérable dans la structure des modèles, la dynamique de formation et l'efficacité des données nécessite une puissance de calcul quatre fois supérieure pour obtenir le même effet.

▲Photo de la capture d'écran de CCTV News
Cette attitude consistant à affronter les défis de front découle des années d’expérience de Liang Wenfeng à Huanfang.
Il a souligné que l'open source n'est pas seulement un partage de technologie, mais aussi une expression culturelle. Le véritable avantage réside dans la capacité d'innovation continue de l'équipe. La culture organisationnelle unique de DeepSeek encourage l'innovation ascendante, minimise la hiérarchie et valorise la passion et la créativité des talents.
L'équipe est principalement composée de jeunes issus des meilleures universités et adopte un modèle naturel de division du travail pour permettre aux employés d'explorer et de collaborer de manière indépendante. Lors du recrutement, nous valorisons la passion et la curiosité des employés plutôt que l’expérience et le parcours au sens traditionnel du terme.
Concernant les perspectives de l’industrie, Liang Wenfeng estime que l’IA se trouve dans une période d’explosion de l’innovation technologique plutôt que dans une période d’explosion de ses applications. Il a souligné que la Chine a besoin de plus d'innovations technologiques originales et ne peut pas rester éternellement au stade de l'imitation. Elle a besoin de personnes à l'avant-garde de la technologie.
Même si des entreprises comme OpenAI ouvrent actuellement la voie, des opportunités d’innovation existent toujours.

En bouleversant la Silicon Valley, Deepseek inquiète les cercles étrangers de l’IA
Bien que l’industrie ait des opinions différentes sur DeepSeek, nous avons également recueilli quelques commentaires d’initiés de l’industrie.
Jim Fan, chef de projet NVIDIA GEAR Lab, a fait l'éloge de DeepSeek-R1.
Il a souligné que cela signifie que les entreprises non américaines remplissent la mission ouverte initiale d'OpenAI et obtiennent une influence en divulguant des algorithmes et des courbes d'apprentissage originaux. D'ailleurs, cela contient également une vague d'OpenAI.
DeepSeek-R1 a non seulement ouvert une série de modèles, mais a également divulgué tous les secrets de formation. Il s'agit peut-être des premiers projets open source à démontrer la croissance significative et continue du volant d'inertie RL.
L'influence peut être obtenue grâce à des projets légendaires tels que "ASI Internal Implementation" ou "Strawberry Project", ou simplement en exposant l'algorithme original et la courbe d'apprentissage de matplotlib.
Marc Andreesen, fondateur d'A16Z, une importante société de capital-risque de Wall Street, estime que DeepSeek R1 est l'une des avancées les plus surprenantes et impressionnantes qu'il ait jamais vues. En tant qu'open source, il s'agit d'un cadeau de grande envergure pour le monde.
Lu Jing, ancien chercheur principal chez Tencent et chercheur postdoctoral en intelligence artificielle à l'Université de Pékin, a analysé la situation du point de vue de l'accumulation technologique. Il a souligné que DeepSeek n'est pas devenu populaire soudainement. Il a hérité de nombreuses innovations de la version du modèle de la génération précédente. L'architecture du modèle et l'innovation en matière d'algorithmes ont été vérifiées de manière itérative et il est inévitable de bouleverser l'industrie.
Yann LeCun, lauréat du prix Turing et scientifique en chef de l'IA chez Meta, a proposé une nouvelle perspective :
"Pour ceux qui pensent que "la Chine surpasse les États-Unis en matière d'IA" après avoir vu les performances de DeepSeek, votre interprétation est fausse. L'interprétation correcte devrait être : « Le modèle open source surpasse le modèle propriétaire ». "
Les commentaires du PDG de Deepmind, Demis Hassabis, ont révélé un soupçon d'inquiétude :
"Ce qu'il (DeepSeek) a réalisé est très impressionnant, et je pense que nous devons réfléchir à la manière de maintenir le leadership des modèles occidentaux. Je pense que l'Occident est toujours en avance, mais la Chine dispose certainement de capacités d'ingénierie et de mise à l'échelle extrêmement fortes. "
Le PDG de Microsoft, Satya Nadella, a déclaré lors du Forum économique mondial de Davos, en Suisse, que DeepSeek avait développé efficacement un modèle open source qui non seulement fonctionne bien dans les calculs d'inférence, mais est également extrêmement efficace en calcul intensif.
Il a souligné que Microsoft devait répondre avec la plus haute priorité à ces développements révolutionnaires en Chine.
L'évaluation du PDG de Meta, Zuckerberg, était plus approfondie. Il a estimé que la force technique et les performances démontrées par DeepSeek étaient impressionnantes, et a souligné que l'écart en matière d'IA entre la Chine et les États-Unis est déjà minime et que le sprint complet de la Chine a réussi. concurrence plus intense.
La réaction des concurrents est peut-être la meilleure approbation de DeepSeek. Selon les rapports des employés de Meta sur la communauté anonyme du lieu de travail TeamBlind, l'émergence de DeepSeek-V3 et R1 a semé la panique dans l'équipe d'IA générative de Meta.
Les méta-ingénieurs font une course contre la montre pour analyser la technologie de DeepSeek et essayer d'en copier toute technologie possible.
La raison en est que le coût de formation de DeepSeek-V3 n'est que de 5,58 millions de dollars, ce qui n'atteint même pas le salaire annuel de certains dirigeants de Meta. Une telle disparité dans le rapport entrées-sorties met la direction de Meta sous une forte pression lorsqu’elle explique son énorme budget de R&D en IA.

Les grands médias internationaux ont également accordé une grande attention à la montée en puissance de DeepSeek.
Le Financial Times a souligné que le succès de DeepSeek a bouleversé l'idée traditionnelle selon laquelle « la recherche et le développement de l'IA doivent s'appuyer sur d'énormes investissements » et prouve que des voies techniques précises peuvent également donner d'excellents résultats de recherche. Plus important encore, le partage altruiste de l'innovation technologique par l'équipe DeepSeek a fait de cette entreprise qui accorde plus d'attention à la valeur de la recherche un concurrent exceptionnellement puissant.
The Economist a déclaré qu'il pensait que les avancées rapides de la Chine en matière de rentabilité de la technologie de l'IA avaient commencé à ébranler les avantages technologiques des États-Unis, ce qui pourrait affecter l'amélioration de la productivité et le potentiel de croissance économique des États-Unis au cours de la prochaine décennie.

Le New York Times intervient sous un autre angle. DeepSeek-V3 est équivalent en performances aux chatbots haut de gamme des entreprises américaines, mais le coût est considérablement réduit.
Cela montre que même face aux contrôles sur les exportations de puces, les entreprises chinoises peuvent être compétitives grâce à l’innovation et à une utilisation efficace des ressources. De plus, la politique de restriction des puces du gouvernement américain pourrait s'avérer contre-productive, car elle favoriserait plutôt les percées innovantes de la Chine dans le domaine de la technologie open source de l'IA.
DeepSeek "a signalé la mauvaise porte", prétendant être GPT-4
Au milieu des éloges, DeepSeek a également fait face à une certaine controverse.
De nombreux étrangers pensent que DeepSeek a peut-être utilisé les données de sortie de modèles tels que ChatGPT comme matériel de formation pendant le processus de formation, grâce à la technologie de distillation de modèles, les « connaissances » contenues dans ces données sont migrées vers le propre modèle de DeepSeek.
Cette pratique n'est pas rare dans le domaine de l'IA, mais les sceptiques se demandent si DeepSeek a utilisé les données de sortie du modèle OpenAI sans divulgation complète. Cela semble se refléter dans la conscience de soi de DeepSeek-V3.
Les utilisateurs précédents ont découvert que lorsqu’on leur demandait l’identité d’un modèle, celui-ci se confondait avec GPT-4.
Les données de haute qualité ont toujours été un facteur important dans le développement de l'IA. Même OpenAI ne peut éviter les controverses sur l'acquisition de données. Sa pratique d'exploration à grande échelle de données sur Internet a également suscité de nombreuses poursuites en matière de droits d'auteur. Le New York Times a statué en première instance. Avant que les bottes n'arrivent, une nouvelle affaire a été ajoutée.
DeepSeek a donc également reçu des connotations publiques de la part de Sam Altman et John Schulman.
"Il est (relativement) facile de copier quelque chose dont on sait qu'il fonctionnera. Il est très difficile de faire quelque chose de nouveau, risqué et difficile quand on ne sait pas si cela fonctionnera."

Cependant, l'équipe DeepSeek a clairement indiqué dans le rapport technique de R1 qu'elle n'utilisait pas les données de sortie du modèle OpenAI et a déclaré que des performances élevées avaient été obtenues grâce à l'apprentissage par renforcement et à une stratégie de formation unique.
Par exemple, une méthode de formation en plusieurs étapes est adoptée, comprenant la formation de base du modèle, la formation par apprentissage par renforcement (RL), le réglage fin, etc. Cette méthode de formation cyclique en plusieurs étapes aide le modèle à absorber différentes connaissances et capacités à différentes étapes.
Économiser de l'argent est aussi un travail technique, et la technologie derrière DeepSeek est la meilleure solution
Le rapport technique DeepSeek-R1 mentionne une découverte remarquable, qui est le « moment aha » qui s'est produit pendant le processus de formation zéro R1. À mi-phase de formation du modèle, DeepSeek-R1-Zero commence à réévaluer activement les idées initiales de résolution de problèmes et à consacrer plus de temps à l'optimisation de la stratégie (par exemple, essayer différentes solutions plusieurs fois).
En d’autres termes, grâce au cadre RL, l’IA peut développer spontanément des capacités de raisonnement semblables à celles des humains et même dépasser les limites des règles prédéfinies. Et nous espérons que cela fournira également une orientation pour le développement de modèles d’IA plus autonomes et adaptatifs, tels que l’ajustement dynamique des stratégies dans la prise de décision complexe (diagnostic médical, conception d’algorithmes).

Dans le même temps, de nombreux acteurs du secteur tentent d'analyser en profondeur le rapport technique de DeepSeek. Andrej Karpathy, ancien co-fondateur d'OpenAI, a déclaré après la sortie de DeepSeek V3 :
DeepSeek (la société chinoise d'IA) se sent détendue aujourd'hui. Elle a rendu public un modèle de langage de pointe (LLM) et a réalisé la formation avec un budget extrêmement faible (2 048 GPU, d'une durée de 2 mois, pour un coût de 6 millions de dollars).
À titre de référence, cette fonctionnalité nécessite généralement la prise en charge d'un cluster de 16 000 GPU, et la plupart des systèmes avancés actuels utilisent environ 100 000 GPU. Par exemple, Llama 3 (paramètres 405B) a utilisé 30,8 millions d'heures GPU, tandis que DeepSeek-V3 semble être un modèle plus puissant, utilisant seulement 2,8 millions d'heures GPU (environ 1/11 du calcul de Llama 3).
Si ce modèle fonctionne également bien lors des tests réels (par exemple, le classement LLM Arena est en cours et mon test rapide s'est bien déroulé), alors ce sera un très bon exemple de la façon dont les capacités de recherche et d'ingénierie peuvent être démontrées dans des conditions de ressources limitées. Des résultats impressionnants.
Alors, cela signifie-t-il que nous n’avons plus besoin de grands clusters GPU pour former des LLM de pointe ? Pas vraiment, mais cela montre qu’il faut s’assurer que les ressources que vous utilisez ne sont pas gaspillées, et ce cas montre que l’optimisation des données et des algorithmes peut encore conduire à de grands progrès. De plus, le rapport technique est également très intéressant et détaillé et mérite d’être lu.
Face à la controverse sur l'utilisation des données ChatGPT par DeepSeek V3, Karpathy a déclaré que les grands modèles de langage n'ont pas essentiellement une conscience de soi semblable à celle des humains. La question de savoir si le modèle peut répondre correctement à sa propre identité dépend entièrement de la question de savoir si l'équipe de développement a spécialement construit sa propre identité. Prise de conscience. Ensemble d'entraînement, s'il n'est pas spécialement formé, le modèle répondra en fonction des informations les plus proches contenues dans les données d'entraînement.
De plus, le fait que le modèle s'identifie comme ChatGPT n'est pas le problème. Compte tenu de l'omniprésence des données liées à ChatGPT sur Internet, cette réponse reflète en fait un phénomène naturel d'« émergence de connaissances à proximité ».
Jim Fan l'a souligné après avoir lu le rapport technique de DeepSeek-R1 :
Le point le plus important de cet article est qu'il est entièrement piloté par l'apprentissage par renforcement, sans aucune implication d'apprentissage supervisé (SFT). Cette méthode est similaire à AlphaZero – maîtriser le Go et le Shogi à partir de zéro via le "Cold Start" et les échecs, sans imiter. le jeu des joueurs d'échecs humains.
– Utilisez des récompenses réelles calculées sur la base de règles codées en dur, plutôt que des modèles de récompense appris qui peuvent être facilement « piratés » par l’apprentissage par renforcement.
– Le temps de réflexion du modèle augmente régulièrement au fur et à mesure de la progression de l’entraînement. Ce n’est pas une fonctionnalité préprogrammée mais spontanée.
– L’autoréflexion et un comportement exploratoire émergent.
– Utilisez GRPO au lieu de PPO : GRPO supprime le réseau de commentateurs dans PPO et utilise à la place la récompense moyenne de plusieurs échantillons. C'est un moyen simple de réduire l'utilisation de la mémoire. Il est à noter que GRPO a été inventé par l'équipe DeepSeek en février 2024, qui est vraiment une équipe très puissante.
Lorsque Kimi a également publié des résultats de recherche similaires le même jour, Jim Fan a constaté que les résultats de recherche des deux sociétés atteignaient le même objectif :
- Ils ont tous abandonné les méthodes de recherche arborescente complexes telles que MCTS et se sont tournés vers des trajectoires de pensée linéaires plus simples, en utilisant les méthodes de prédiction autorégressives traditionnelles.
- Tous évitent d'utiliser des fonctions de valeur qui nécessitent des copies de modèle supplémentaires, réduisant ainsi les besoins en ressources informatiques et améliorant l'efficacité de la formation.
- Ils abandonnent tous la modélisation intensive des récompenses et s'appuient autant que possible sur des résultats réels comme orientation pour assurer la stabilité de la formation.
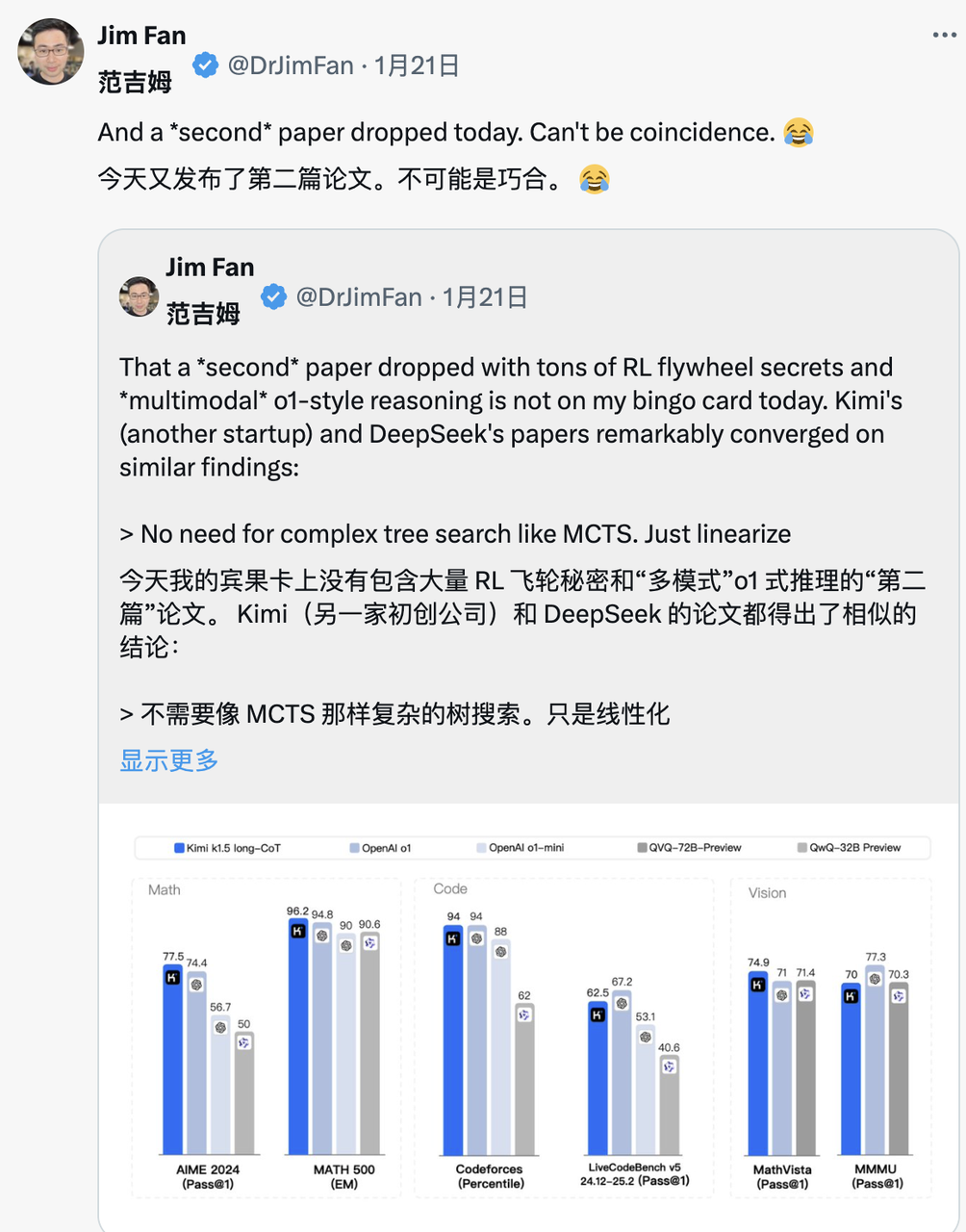
Mais il existe également des différences significatives entre les deux :
- DeepSeek adopte la méthode de démarrage à froid RL pur de style AlphaZero, Kimi k1.5 choisit la stratégie de préchauffage de style AlphaGo-Master et utilise un SFT léger
- DeepSeek est open source sous licence MIT et Kimi obtient de bons résultats dans les tests de référence multimodaux. Les détails de conception du système papier sont plus riches, couvrant l'infrastructure RL, les clusters hybrides, les bacs à sable de code et les stratégies parallèles.
Cependant, sur ce marché de l’IA en évolution rapide, l’avance est souvent éphémère. D'autres sociétés de modélisation apprendront rapidement de l'expérience de DeepSeek et l'amélioreront, et pourraient bientôt rattraper leur retard.
L’initiateur de la guerre des prix des grands modèles
Beaucoup de gens savent que DeepSeek a un titre appelé « AI Pinduoduo », mais ils ne savent pas que la signification de ce nom découle en réalité de la guerre des prix des grands modèles qui a commencé l'année dernière.
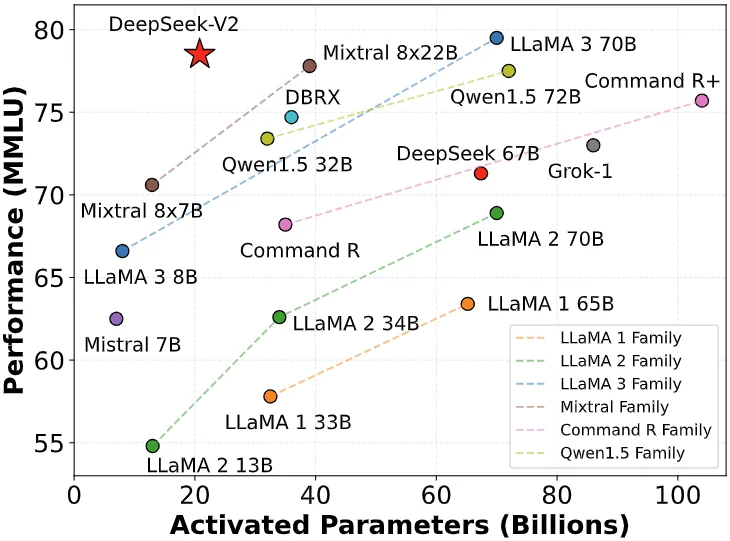
Le 6 mai 2024, DeepSeek a publié le modèle MoE open source DeepSeek-V2, qui a réalisé une double avancée en termes de performances et de coûts grâce à des architectures innovantes telles que MLA (mécanisme d'attention latente multi-têtes) et MoE (modèle expert mixte).
Le coût d'inférence a été réduit à seulement 1 yuan par million de jetons, soit environ un septième de celui de Llama3 70B et un soixante-dixième de celui de GPT-4 Turbo à l'époque. Cette avancée technologique permet à DeepSeek de fournir des services extrêmement rentables sans facturer d'argent, et elle exerce également une énorme pression concurrentielle sur les autres fabricants.
La sortie de DeepSeek-V2 a déclenché une réaction en chaîne. ByteDance, Baidu, Alibaba, Tencent et Zhipu AI ont tous emboîté le pas et ont considérablement réduit les prix de leurs produits grand modèle. L’impact de cette guerre des prix s’étend même au Pacifique, suscitant de vives inquiétudes dans la Silicon Valley.
DeepSeek a donc été surnommé le « Pinduoduo de l’IA ».
Face aux doutes du monde extérieur, le fondateur de DeepSeek, Liang Wenfeng, a répondu dans une interview avec Undercurrent :
« Attirer les utilisateurs n'est pas notre objectif principal. D'une part, nous avons baissé le prix parce que nous explorons la structure du modèle de nouvelle génération, et le coût a d'abord baissé ; d'autre part, nous pensons également que l'API et L’IA doit être inclusive. Quelque chose que tout le monde peut se permettre.
En fait, l’importance de cette guerre des prix va bien au-delà de la concurrence elle-même. La réduction des barrières à l’entrée permet à davantage d’entreprises et de développeurs d’accéder et d’appliquer une IA de pointe, et oblige également l’ensemble du secteur à repenser ses stratégies de tarification. Après cela, DeepSeek a commencé à attirer l'attention du public et a pris de l'importance.
Dépensant des milliers de dollars pour acheter des os de chevaux, Lei Jun débauche des filles géniales de l'IA
Il y a quelques semaines, DeepSeek a également procédé à un changement de personnel très médiatisé.
Selon China Business News, Lei Jun a réussi à débaucher Luo Fuli avec un salaire annuel de dizaines de millions et lui a confié la tâche importante de chef de la grande équipe de modèles du Xiaomi AI Lab.
Luo Fuli a rejoint DeepSeek, une filiale de Magic Square Quantitative, en 2022. Elle est visible dans des rapports importants tels que DeepSeek-V2 et le dernier R1.
Plus tard, DeepSeek, qui se concentrait autrefois sur la face B, a également commencé à aménager la face C et à lancer des applications mobiles. Au moment de mettre sous presse, l'application mobile de DeepSeek se classe au deuxième rang dans la version gratuite de l'App Store d'Apple, démontrant une forte compétitivité.
Une série de petits climax ont rendu DeepSeek célèbre, mais en même temps, il y a aussi des climax plus élevés. Le soir du 20 janvier, le modèle à très grande échelle DeepSeek R1 avec des paramètres 660B a été officiellement lancé.
Ce modèle fonctionne bien dans les tâches mathématiques. Par exemple, il a obtenu un score pass@1 de 79,8 % à l'AIME 2024, dépassant légèrement OpenAI-o1 ; .
En termes de tâches de programmation, par exemple, il a obtenu la note Elo 2029 sur Codeforces, dépassant 96,3 % des participants humains. Dans les tests de connaissances tels que MMLU, MMLU-Pro et GPQA Diamond, DeepSeek R1 a obtenu respectivement 90,8 %, 84,0 % et 71,5 %, ce qui est légèrement inférieur à OpenAI-o1 mais meilleur que les autres modèles à code source fermé.
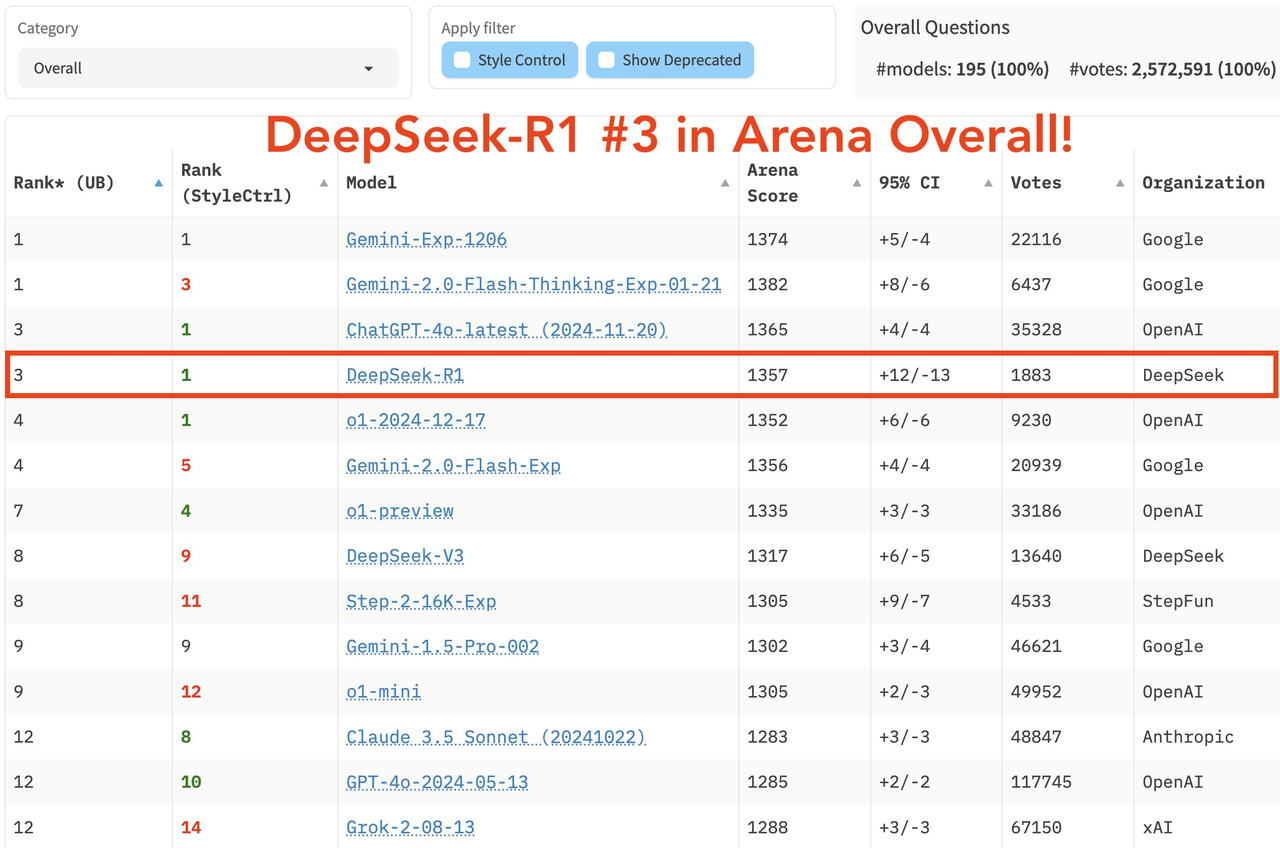
Dans la dernière liste complète de la grande arène modèle LM Arena, DeepSeek R1 s'est classé troisième, à égalité avec o1.
- Dans les domaines "Hard Prompts" (mots d'invite difficiles), "Coding" (capacité de codage) et "Math" (capacité mathématique), DeepSeek R1 se classe premier.
- En termes de "Style Control", DeepSeek R1 et o1 sont à égalité pour la première place.
- Dans le test « Hard Prompt with Style Control », DeepSeek R1 a également terminé à égalité à la première place avec o1.
En termes de stratégie open source, R1 adopte la licence MIT, offrant aux utilisateurs la plus grande liberté d'utilisation, et prend en charge la distillation de modèles, qui peut distiller les capacités de raisonnement en modèles plus petits. Par exemple, les modèles 32B et 70B ont atteint la référence o1-mini en. capacités multiples. L'effet de l'open source dépasse même Meta, qui a déjà été critiqué.
L'émergence de DeepSeek R1 permet aux utilisateurs nationaux d'utiliser pour la première fois gratuitement des modèles de niveau o1, brisant ainsi les barrières de l'information de longue date. Le buzz qu’il a suscité sur les plateformes sociales telles que Xiaohongshu est comparable à GPT-4 au moment de sa sortie.
Sortez à la mer et involuez
En regardant la trajectoire de développement de DeepSeek, son code de réussite est clairement visible. La force est la base, mais la reconnaissance de la marque est le fossé.
Dans une conversation avec "Later", Yan Junjie, PDG de MiniMax, a partagé en profondeur ses réflexions sur l'industrie de l'IA et les changements stratégiques de l'entreprise. Il a souligné deux tournants clés : premièrement, la reconnaissance de l'importance de l'image de marque technologique, et deuxièmement, la compréhension de la valeur d'une stratégie open source.
Yan Junjie estime que dans le domaine de l'IA, la vitesse de l'évolution technologique est plus importante que les réalisations actuelles, et que l'open source peut accélérer ce processus grâce aux commentaires de la communauté ;
Prenons l'exemple d'OpenAI. Bien qu'il ait rencontré des troubles en matière de gestion dans la période ultérieure, son image innovante et son esprit open source établi dès le début ont accumulé une bonne première vague d'impressions. Même si Claude est devenu techniquement à égalité à l'avenir et a progressivement cannibalisé les utilisateurs du côté B d'OpenAI, OpenAI est encore loin devant parmi les utilisateurs du côté C en raison de la dépendance du chemin des utilisateurs.
Dans le domaine de l’IA, la véritable scène concurrentielle est toujours mondiale, et l’exportation, l’involution et la publicité sont également une bonne voie à suivre.

Cette vague de mondialisation a déjà provoqué des répercussions dans l'industrie. Les précédents Qwen, Wall-facing Smart et plus récemment DeepSeek R1, kimi v1.5 et Doubao v1.5 Pro ont déjà fait sensation à l'étranger.
Bien que 2025 ait été qualifiée de première année des corps intelligents et de première année des lunettes IA, cette année sera également une première année importante pour les entreprises chinoises d’IA qui souhaitent embrasser le marché mondial, et la mondialisation deviendra un mot-clé incontournable.
De plus, la stratégie open source est également une bonne chose, attirant un grand nombre de blogueurs et de développeurs techniques à devenir spontanément « l'eau du robinet » de DeepSeek. La technologie pour le bien ne devrait pas être seulement un slogan Du slogan « IA pour tous » à la vérité. l'inclusivité technologique, DeepSeek s'est engagé sur une voie plus pure qu'OpenAI.
Si OpenAI nous permet de voir la puissance de l’IA, alors DeepSeek nous fait croire :
Ce pouvoir profitera à terme à tout le monde.
# Bienvenue pour suivre le compte public officiel WeChat d'Aifaner : Aifaner (ID WeChat : ifanr). Un contenu plus passionnant vous sera fourni dès que possible.
Ai Faner | Lien original · Voir les commentaires · Sina Weibo