
En seulement 15 minutes, l’iPhone peut « copier » votre voix

Le "son électronique mécanique" de Stephen Hawking est peut-être l'un des sons les plus reconnaissables au monde.
Mais ce n'était pas la propre voix de Hawking.

À une époque où Hawking a perdu sa capacité à parler à cause de la SLA, la technologie n'était pas suffisante pour lui permettre de générer sa propre voix. En fait, très peu de gens ont accès à un synthétiseur vocal.
Aujourd'hui, bien que les patients SLA aient plus d'options pour la synthèse vocale, le coût global et le seuil de temps ne sont toujours pas bas et la popularité est limitée.
Récemment, Apple a annoncé une nouvelle fonctionnalité sans obstacle Personal Voice (pas encore en ligne), qui permet non seulement aux utilisateurs de "sauvegarder" leur voix gratuitement, mais fait également une tentative intéressante d'appliquer en toute sécurité la technologie AI.
Seulement 15 minutes de "tuning" peuvent générer votre voix
▲ Photo de Fastcompany
À une époque où l'IA générative peut tout imiter, utiliser l'IA pour imiter la voix d'une personne ne ressemble pas à une nouveauté, cela ressemble simplement à un risque pour la sécurité.
Ce qui m'intéresse, c'est de savoir comment Apple peut implémenter efficacement et en toute sécurité la fonction Personal Voice.
Selon les rapports, les utilisateurs d'iPhone, d'iPad et de Mac n'ont besoin d'enregistrer que 15 minutes d'audio selon les invites, et Apple générera la même voix que l'utilisateur sur la base de la technologie d'apprentissage automatique côté appareil.
En revanche, les entreprises qui fournissent des services professionnels de synthèse vocale pour les groupes aphasiques peuvent avoir besoin d'utiliser un équipement professionnel pour enregistrer plusieurs heures de matériel vocal, et le prix peut commencer à des centaines de dollars.
Une autre nouvelle fonctionnalité sans obstacle, Live Speech, permet aux utilisateurs de saisir du texte pour générer du contenu vocal lors d'un appel téléphonique, FaceTime, ou de parler face à face avec d'autres, offrant un autre moyen pour les utilisateurs aphasiques ou gênants de parler.
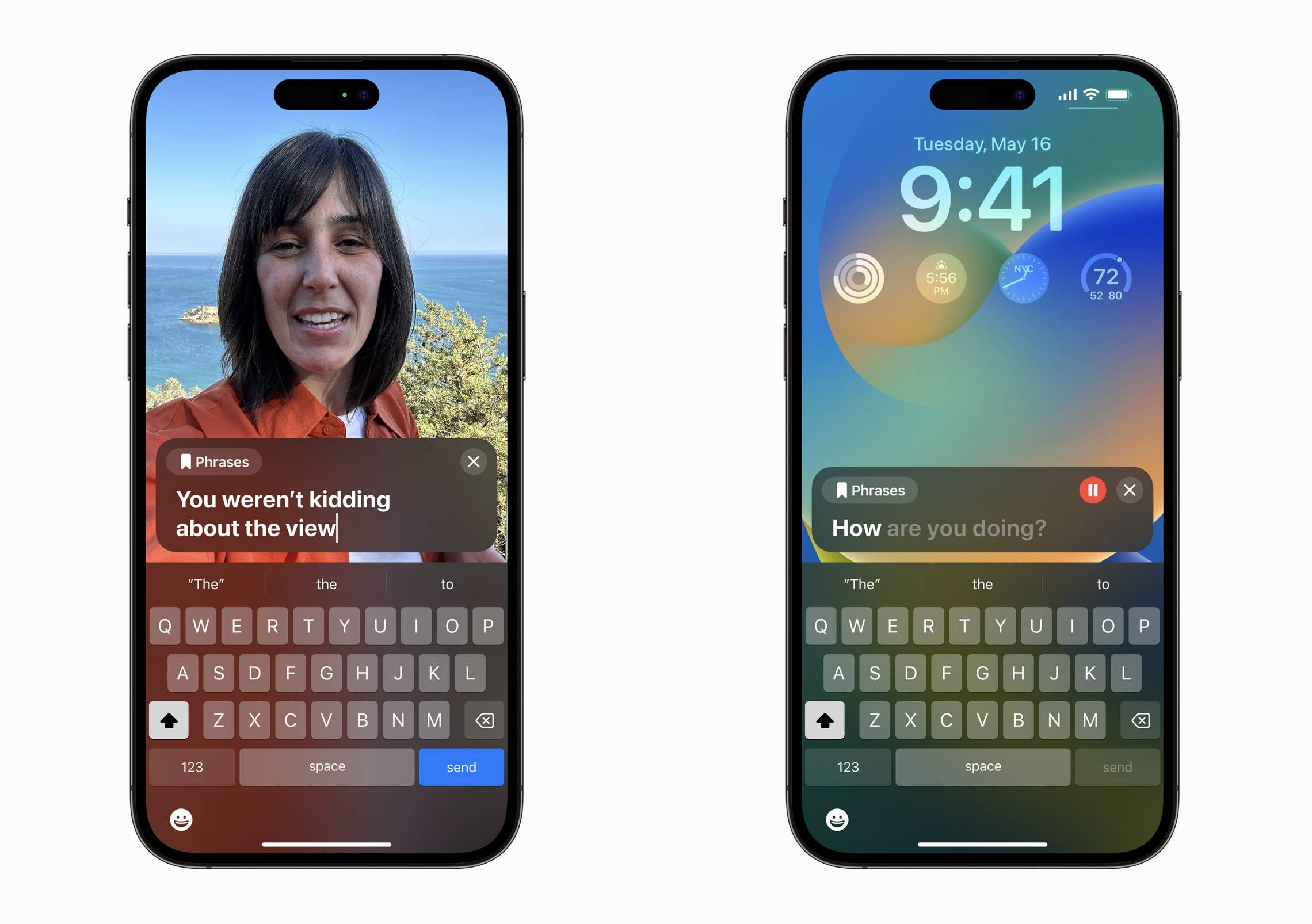
En combinant les deux fonctions de voix personnelle et de parole en direct, les utilisateurs aphasiques peuvent communiquer avec d'autres en utilisant une voix générée proche de leur voix d'origine.
C'est pratique à utiliser, mais comment empêcher quelqu'un de générer la voix d'autres personnes en utilisant des matériaux vocaux récupérés sur Internet ?
- Randomisation des matériaux.
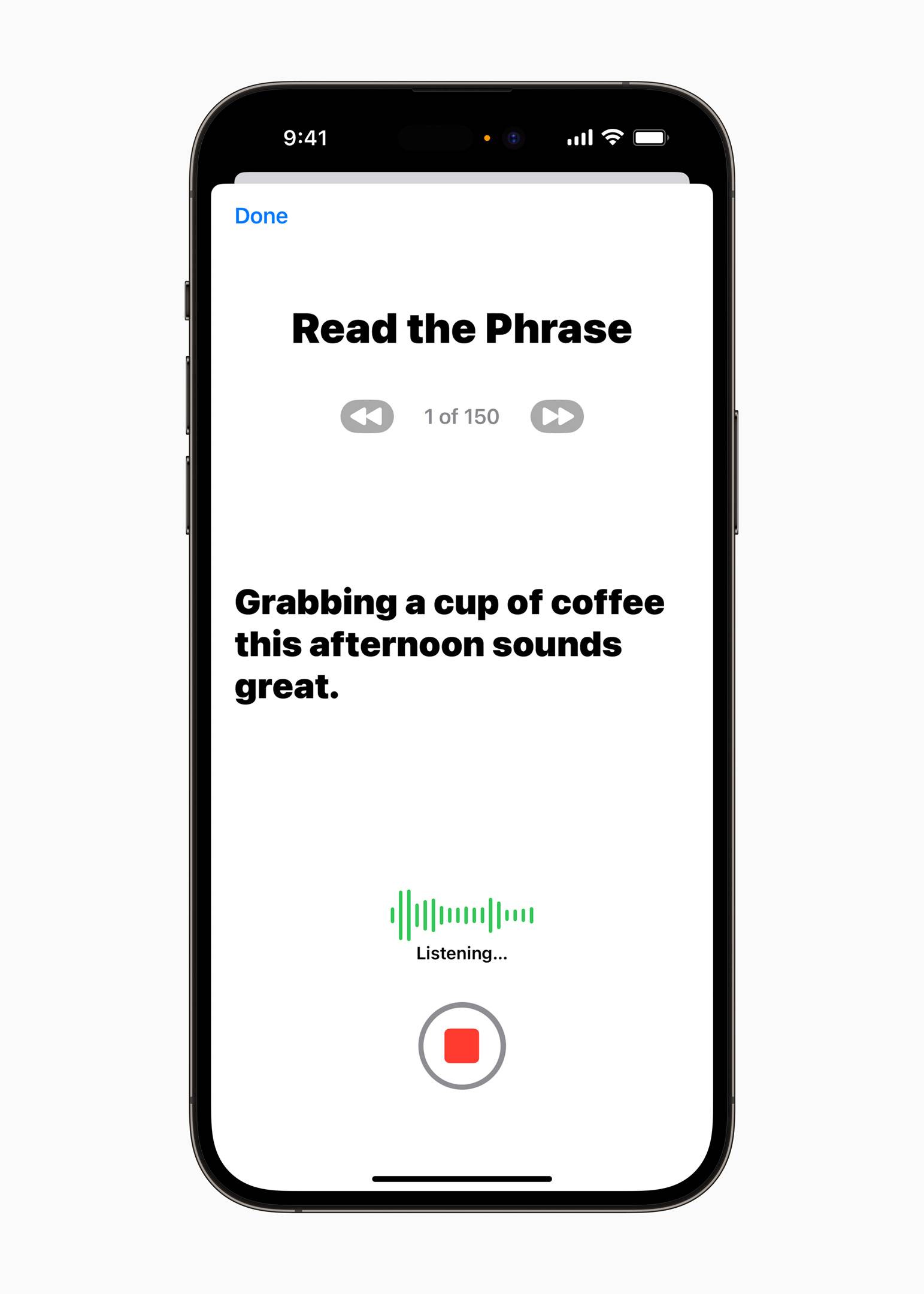
Lors du processus d'enregistrement de 15 minutes de matériel vocal, Apple générera au hasard du contenu qui doit être lu par l'utilisateur, réduisant ainsi la possibilité que d'autres personnes devinent le matériel.
- Barrière de distance physique.
Pendant le processus d'enregistrement, l'utilisateur doit terminer l'enregistrement dans un espace spécifique de 6 à 10 pouces (environ 15 à 25 cm) de l'appareil.
Au cours du processus de génération, toutes les données seront complétées localement sur l'appareil via le Neural Engine d'Apple (Neural Engine), sans téléchargement dans le cloud pour traitement.
Après la synthèse vocale, si une application tierce souhaite utiliser Personal Voice, elle doit obtenir une autorisation explicite de l'utilisateur.

Même lorsqu'une application tierce est autorisée à utiliser, Apple adoptera une protection supplémentaire en arrière-plan pour s'assurer que l'application tierce ne peut pas obtenir la voix personnelle et le matériel vocal précédemment enregistré par l'utilisateur.
Si vous êtes un utilisateur Apple "family bucket", après avoir généré votre propre voix personnelle, vous pouvez également la synchroniser avec différents appareils via iCloud et la chiffrer de bout en bout.
Ce n'est que lorsque vous perdez votre propre voix que vous comprenez à quel point c'est important

Les humains sont des créatures émotionnelles et le son est un puissant déclencheur émotionnel.
Des études ont montré que lorsqu'une personne entend la voix de la mère, le corps libère des niveaux d'ocytocine similaires à ceux produits lors de l'étreinte de la mère. Une autre étude a noté qu'entendre sa propre voix augmente l'auto-motivation d'une personne.
Cela semble un peu abstrait.
Mais quand nous le perdons, l'importance devient apparente.
En mars 2021, Ruth Brunton a reçu un diagnostic de SLA. À Noël cette année-là, elle était sans voix.
Environ 25 % des personnes atteintes de SLA ont la forme "bulbaire" de la SLA, qui se manifeste principalement par des difficultés d'élocution ou de déglutition. L'élocution de ces patients deviendra progressivement brouillée, nasale et même aphasique.
L'action de Brunton a été très décisive : après le diagnostic, il a immédiatement trouvé une entreprise pour faire de la génération de la parole.
Il a fallu un mois pour faire des allers-retours et enregistrer un corpus de plus de 3 000 phrases, mais le résultat final n'était pas idéal.
Cette société utilise une technique appelée "sélection d'unités".
Pour le dire simplement et grossièrement, il s'agit de parvenir à la génération de la parole par "épissage", en divisant le corpus en un grand nombre de petites unités de parole, puis en assemblant les éléments selon les besoins.
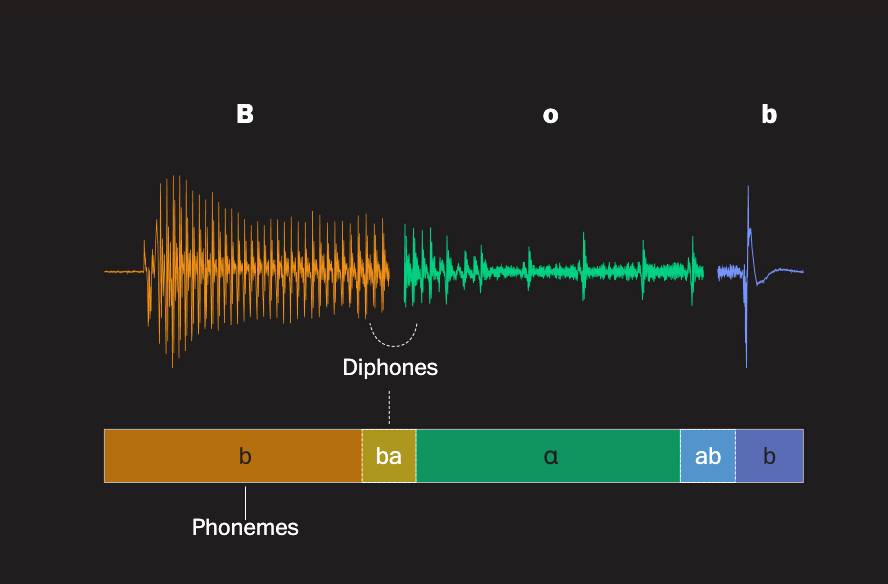
▲ Sous la technologie de sélection d'unités, le mot "Bob" peut être divisé en différents éléments phonétiques, illustrés par "Washington Post"
Le discours généré par cette technologie peut être entendu clairement, mais il sera un peu électronique et sonnera contre nature.
Du coup, le corpus enregistré par Brunton s'est combiné avec une voix appelée "Heather" de Microsoft. Non seulement la voix ne ressemblait pas à la sienne, mais il a même obligé les Britanniques à "parler" avec un accent américain.
▲ La vraie voix de Brunton
▲ La voix de la version synthétisée de Brunton
Pris au piège de cette voix, Brunton "ne parlera que lorsque c'est nécessaire, et non plus parce qu'il veut parler".
La conversation coquette avec son mari avait disparu et Brunton était moins encline à participer à des conversations de groupe.
Même dire "je t'aime", d'une voix qui ne ressemble pas à la vôtre, semble avoir un sens diminué.

Six mois plus tard, Brunton et son mari ont récupéré le matériel vocal enregistré original, ont trouvé une autre entreprise et ont utilisé la technologie de l'IA pour synthétiser une voix plus proche de la sienne :
Cela peut sembler idiot, mais retrouver ma voix m'a donné plus de confiance.
John M. Costello, qui dirige le projet "Enhanced Communication" au Boston Children's Hospital, a remarqué que les patients qui utilisent un discours généré de manière plus réaliste semblent être capables de nouer des liens plus profonds avec leurs proches.
À Noël 2022, Brunton, qui a « retrouvé une nouvelle voix », a également enregistré un message festif avec voix.
▲ Ruth a le sentiment que la nouvelle voix synthétique lui ressemble plus
Cependant, juste après Noël, Brunton a contracté la nouvelle couronne et est finalement décédé en février de cette année.
Le soir de son départ, son mari David lui a tenu la main toute la nuit :
Nous avons deux ans pour nous dire au revoir.
On est d'accord, on va dire ce qu'on veut.
Il est difficile d'imaginer si Brunton n'avait pas changé en une voix plus proche de la sienne, si elle serait capable de dire tout ce qu'elle voulait dire librement.
La pensée sans barrières illumine l'inspiration, l'IA stimule la productivité

J'ai toujours cru que ce que la conception sans obstacle excave est en fait les ressources imaginatives créées par la diversité humaine.
Nous allons vers des personnes qui ont des expériences de vie complètement différentes des nôtres, écoutons des histoires et des expériences qui sont moins racontées et créons un nouveau mode de vie que nous n'avons jamais imaginé auparavant, mais qui est convivial pour plus de gens.
La voix personnelle peut permettre aux patients SLA aphasiques de retrouver leur voix ; elle peut aussi m'aider à utiliser ma propre voix pour parler à d'autres personnes après avoir expérimenté la "voix de lame" ; même, il m'est difficile d'éviter d'imaginer si je devrais l'utiliser Gardez votre voix "de secours" pour vos proches, de peur de mourir subitement un jour.
Et la technologie de l'IA consiste à réaliser cette productivité imaginative.
Comme l'a déjà dit l'éditeur Du , bien qu'Apple ne rattrape pas l'excitation de l'IA générative, Apple a toujours utilisé l'IA pour améliorer l'expérience utilisateur, en améliorant l'efficacité et en protégeant la confidentialité.

L'amélioration de l'efficacité réside dans l'amélioration des algorithmes et des modèles d'apprentissage automatique exécutés localement.
En plus de Personal Voice, une autre fonctionnalité d'accessibilité qu'Apple a prévisualisée cette fois, Point and Speak, utilise également la technologie d'apprentissage automatique du côté de l'appareil local.
À l'avenir, les utilisateurs malvoyants pourront utiliser leurs propres doigts pour transformer l'iPhone en un "lecteur de points" dans l'amplificateur fourni avec l'iPhone, combiné avec les fonctions Point and Speak et de narration – où cliquer, laisser le iPhone lit le texte pour vous.

La fonction de « détection de porte » de l'année dernière fonctionne de manière similaire, permettant l'apprentissage automatique côté appareil pour aider les utilisateurs malvoyants à identifier la porte et à lire les informations sur la porte et les panneaux environnants.

Quant à la confidentialité, selon Jobs, "Si vous avez besoin de leurs données (utilisateurs), demandez-leur (utilisateurs). À chaque fois."
Ceci est également particulièrement important en termes de conception d'accessibilité – car l'origine de ces conceptions fonctionnelles est de servir les personnes qui sont ignorées par la soi-disant "conception conventionnelle", sont souvent des groupes plus vulnérables, il est donc encore plus nécessaire de s'assurer que la vie privée de ces utilisateurs n'est pas violée.
Dans ce contexte, nous pouvons également entamer davantage de discussions sur les droits d'application des données et la transparence.
Lorsque Apple a créé Personal Voice cette fois-ci, il a coopéré avec la Team Gleason Foundation, une organisation à but non lucratif qui aide les patients atteints de SLA.

▲ Blair Casey, PDG de la Team Gleason Foundation (à droite)
Le PDG de l'agence, Blair Casey, a poussé les sociétés de génération de voix à définir un ensemble de paramètres de matériel d'enregistrement standard, afin que les utilisateurs puissent enregistrer directement cette partie du matériel et expérimenter les effets vocaux générés par différentes sociétés, au lieu de "parier à l'aveugle". tel qu'il est maintenant. ".
Dans le même temps, Casey préconise également que les sociétés de génération de parole fournissent aux utilisateurs les données matérielles de la parole enregistrée (car de nombreux utilisateurs peuvent devenir aphasiques après l'enregistrement), de peur qu'ils ne souhaitent utiliser ces données dans d'autres technologies à l'avenir :
Ne voudriez-vous pas essayer si une meilleure technologie sortait ?
Si vous ne pouvez pas récupérer votre matériel vocal, vous ne pouvez pas l'essayer.
L'IA est peut-être la plus grande productivité de notre époque.
Cependant, comment utiliser cette force, peut-être que la conception sans obstacle axée sur les personnes peut lui donner beaucoup de conseils.
#Bienvenue pour suivre le compte public WeChat officiel d'Aifaner : Aifaner (WeChat ID : ifanr), un contenu plus excitant vous sera présenté dès que possible.
Ai Faner | Lien d'origine · Voir les commentaires · Sina Weibo