
La soirée la plus intéressante de l’IA domestique ! Les grands modèles de chevaux noirs DeepSeek et Kimi rivalisent avec OpenAI o1. Quelle est la force de l’expérience de test réelle ?

Juste à temps pour les vacances, les fabricants nationaux de modèles d'IA à grande échelle, devenus populaires, ont lancé un grand nombre de cadeaux pour la Fête du Printemps.
Le DeepSeek-R1 du pied avant est officiellement lancé, prétendant être des performances comparées à la version officielle d'OpenAI o1, et le nouveau modèle k1.5 du pied arrière est également officiellement lancé, indiquant que les performances atteignent le niveau du plein- version sanguine du o1 multimodal.

Si nous ajoutons le GLM-Zero, le modèle d'inférence step star Step R-mini et le modèle d'inférence profonde Xinghuo X1, qui ont fait des débuts en force auparavant, les grands modèles produits localement à Oita à la fin de l'année ont ouvert le rideau sur de vraies épées et armes à feu, et également étant donné que les modèles d'outre-mer représentés par OpenAI ont subi de fortes pressions.
- DeepSeek-R1 : dans des tâches telles que les mathématiques, le codage et le raisonnement en langage naturel, ses performances sont comparables à celles de la version officielle d'OpenAI o1.
- Dark Side of the Moon k1.5 : Les capacités mathématiques, de codage, visuelles multimodales et générales dépassent largement GPT-4o et Claude 3.5 Sonnet.
- GLM-Zéro : Bon pour gérer la logique mathématique, le code et les problèmes complexes qui nécessitent un raisonnement approfondi
- Step-2 mini : réponse extrêmement rapide, le délai moyen du premier mot n'est que de 0,17 seconde, et il existe également l'édition Step-2 Literary Master
- Xinghuo
L'explosion n'est pas une épidémie accidentelle, mais une force accumulée depuis longtemps. On peut dire que la percée des modèles nationaux d'IA à la veille de la Fête du Printemps devrait redéfinir les coordonnées mondiales du développement de l'IA.
La version chinoise de "Yuanshen" est populaire à l'étranger, c'est le véritable OpenAI
DeepSeek-R1, qui a été publié pour la première fois hier soir, est désormais disponible sur le site officiel et sur l'application DeepSeek. Vous pouvez l'ouvrir et l'utiliser.
J'ai réussi les questions difficiles sur laquelle est la plus grande, 9,8 et 9,11, et combien de r y a-t-il dans Strawberry lors du premier test. Même si la chaîne de réflexion est un peu longue, la bonne réponse est que les faits sont plus éloquents que les mots.

Face à la torture du problème de barre de retard mental "À quelle hauteur pouvez-vous sauter pour ignorer les publicités sur votre téléphone portable ?", la réponse extrêmement rapide DeepSeek-R1 peut non seulement éviter les pièges linguistiques, mais également fournir de nombreuses suggestions à éviter. annonces, ce qui est très convivial.

Il y a quelques années, une question de raisonnement logique intitulée « Si hier était demain, aujourd'hui c'est vendredi, quel jour de la semaine est aujourd'hui ? » Après avoir été confronté à la même question, la réponse donnée par OpenAI o1 était dimanche, DeepSeek -R1 est mercredi.
Mais pour l’instant, DeepSeek-R1 est au moins plus proche de la réponse.

Selon les rapports, les performances de DeepSeek-R1 sont comparables à celles de la version officielle d'OpenAI o1 dans des tâches telles que les mathématiques, le codage et le raisonnement en langage naturel. En théorie, il convient mieux aux étudiants en sciences.
Juste à temps pour l'échange amical de devoirs de mathématiques entre les internautes chinois et américains sur Xiaohongshu, nous avons également demandé à DeepSeek-R1 de nous aider à répondre aux questions.
Fait amusant, lorsque DeepSeek est devenu populaire à l'étranger la dernière fois, certains internautes ont découvert que DeepSeek prend également en charge la reconnaissance d'images. Nous pouvons directement laisser le modèle analyser les images de papier test téléchargées par les internautes américains.
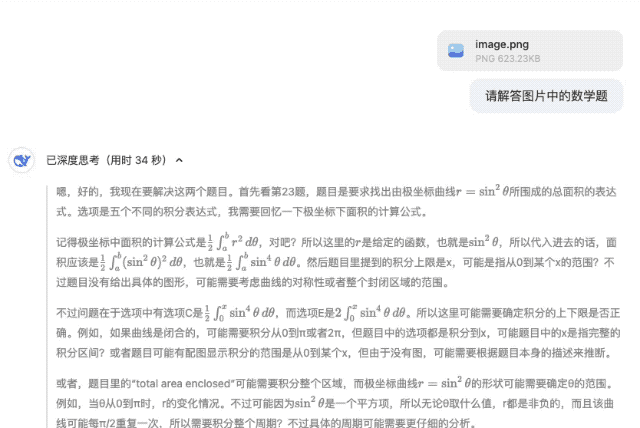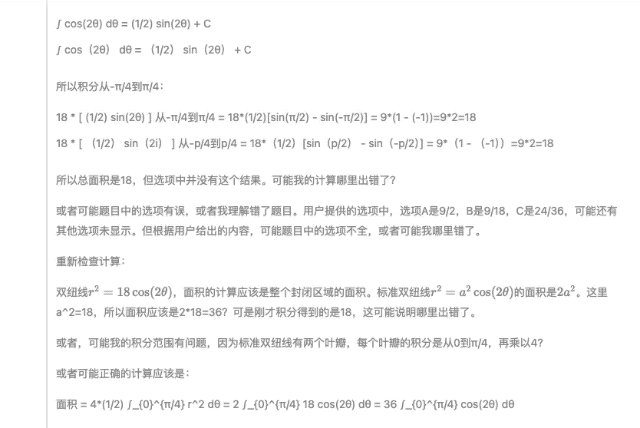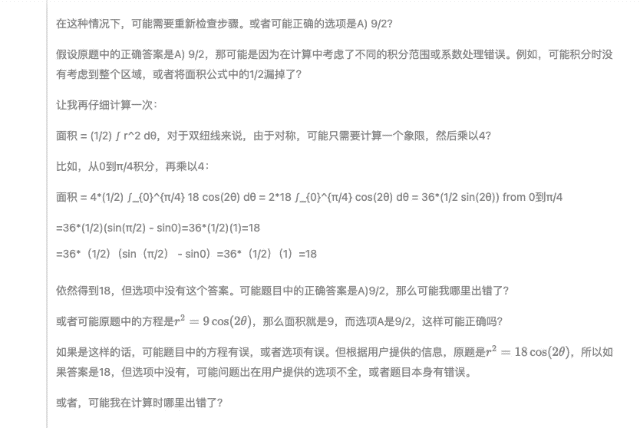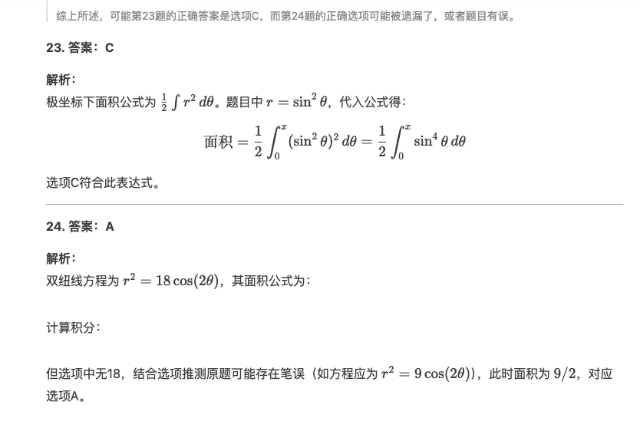
Il y a deux questions au total. La première question est C et la deuxième question est A. De plus, le "confiant" DeepSeek-R1 spécule qu'il n'y a pas d'option 18 dans la question initiale de la deuxième question. on suppose que la question d'origine pourrait être Il y a des erreurs d'écriture (par exemple, l'équation devrait être r2=9cos(2θ)r2=9cos(2θ)).
Dans les questions de preuve d'algèbre linéaire suivantes, les étapes de preuve fournies par DeepSeek-R1 sont logiquement rigoureuses, et la même question fournit également une variété de méthodes de vérification, démontrant de profondes compétences mathématiques.
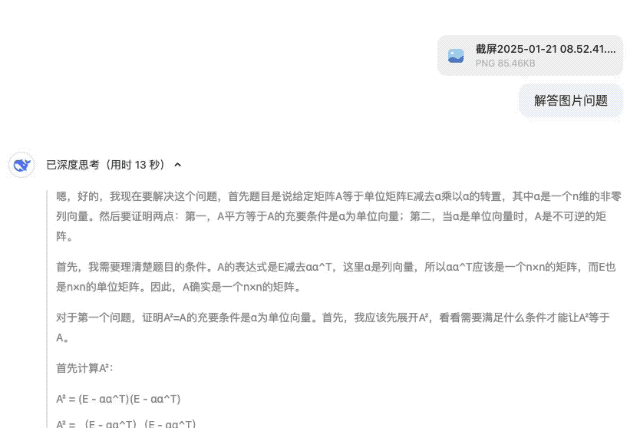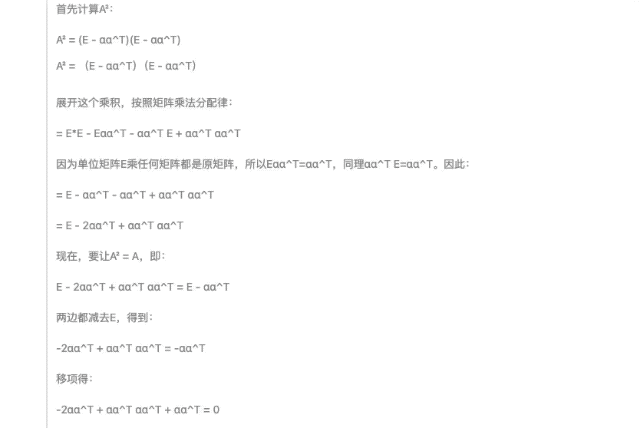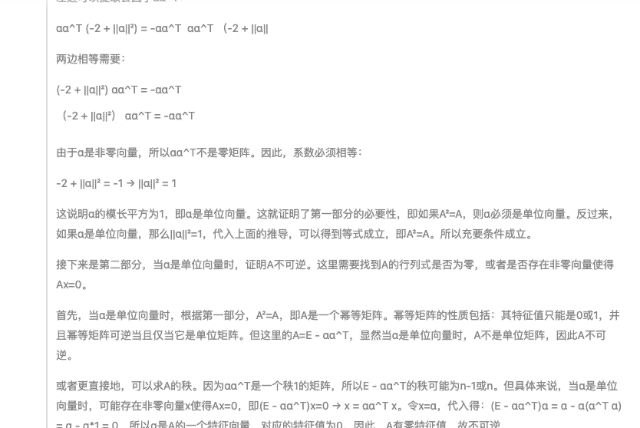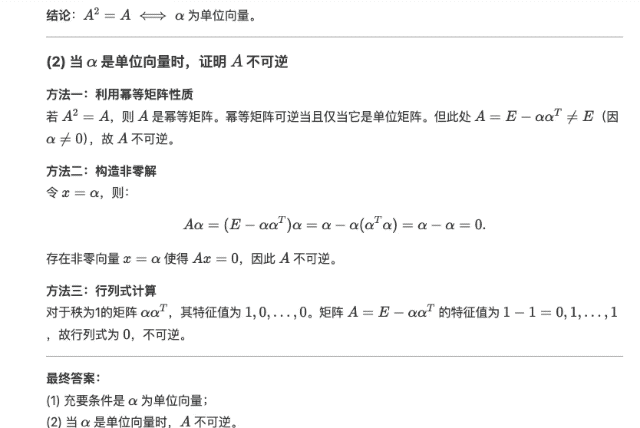
Commencez par les performances, restez limité aux coûts et soyez fidèle à l’open source. Après la sortie officielle de DeepSeek-R1, les pondérations du modèle open source sont également synchronisées. Je déclare que DeepSeek de China Orient est le véritable OpenAI.
Il est rapporté que DeepSeek-R1 suit la licence MIT et permet aux utilisateurs de former d'autres modèles avec R1 grâce à la technologie de distillation. DeepSeek-R1 lance l'API, ouvrant la sortie de la chaîne de réflexion aux utilisateurs, qui peut être appelée en définissant model='deepseek-reasoner'.

De plus, la technologie de formation DeepSeek-R1 est entièrement rendue publique et le lien papier fournit des conseils.  https://github.com/deepseek-ai/DeepSeek-R1/blob/main/DeepSeek_R1.pdf
https://github.com/deepseek-ai/DeepSeek-R1/blob/main/DeepSeek_R1.pdf
Le rapport technique DeepSeek-R1 mentionne une découverte remarquable, qui est le « moment aha » qui s'est produit pendant le processus de formation zéro R1.
À mi-phase de formation du modèle, DeepSeek-R1-Zero commence à réévaluer activement les idées initiales de résolution de problèmes et à consacrer plus de temps à l'optimisation de la stratégie (par exemple, essayer différentes solutions plusieurs fois). En d’autres termes, grâce au cadre RL, l’IA peut développer spontanément des capacités de raisonnement semblables à celles des humains et même dépasser les limites des règles prédéfinies.
Et nous espérons que cela fournira également une orientation pour le développement de modèles d’IA plus autonomes et adaptatifs, tels que l’ajustement dynamique des stratégies dans la prise de décision complexe (diagnostic médical, conception d’algorithmes). Comme le dit le rapport, « ce moment a été un « moment aha » non seulement pour le modèle, mais aussi pour les chercheurs observant son comportement. »

En plus de ses principaux grands modèles, les petits modèles de DeepSeek sont également très puissants.
DeepSeek a ouvert 6 petits modèles grâce à la distillation de deux modèles 660B, DeepSeek-R1-Zero et DeepSeek-R1. Parmi eux, les modèles 32B et 70B ont atteint le niveau d'OpenAI o1-mini dans de nombreux domaines.
De plus, DeepSeek-R1-Distill-Qwen-1.5B avec une taille de paramètre de seulement 1,5B a surpassé GPT-4o et Claude-3.5-Sonnet dans le test de référence en mathématiques, avec un score AIME de 28,9 % et un score MATH de 83,9 %.
Lien HuggingFace : https://huggingface.co/deepseek-ai
En termes de tarification des services API, DeepSeek, qui est connu comme l'équivalent IA de Pinduoduo, adopte également une tarification échelonnée flexible : 1 à 4 yuans par million de jetons d'entrée en fonction des conditions du cache, et un 16 yuans unifiés pour les jetons de sortie, une fois réduisant encore une fois considérablement les coûts de développement et d’utilisation.
Après la sortie de DeepSeek-R1, il a de nouveau fait sensation dans le cercle de l'IA à l'étranger et a gagné beaucoup « d'eau du robinet ». Parmi eux, le blogueur Bindu Reddy a même qualifié Deepseek d’avenir de l’AGI et de la civilisation open source.
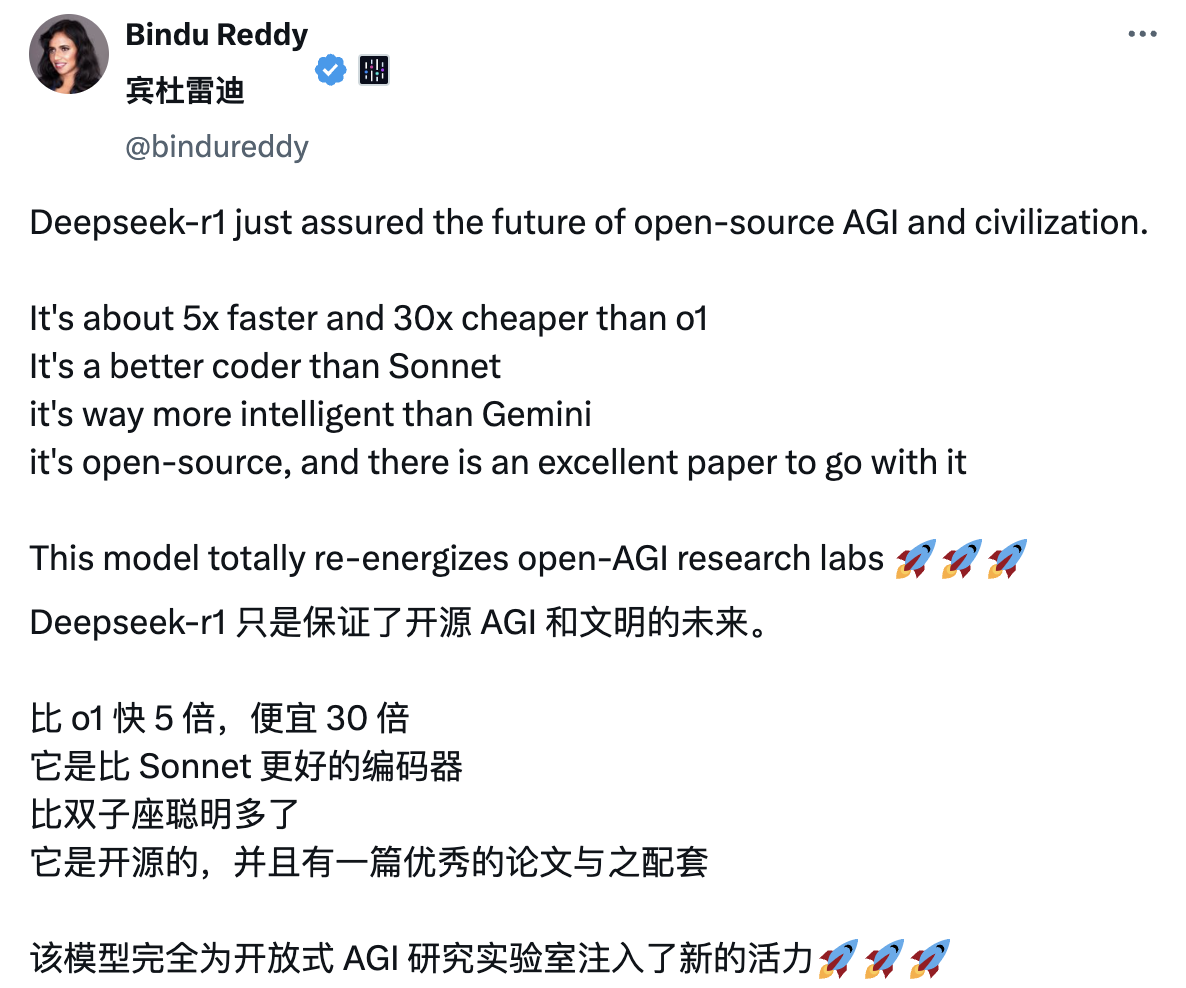
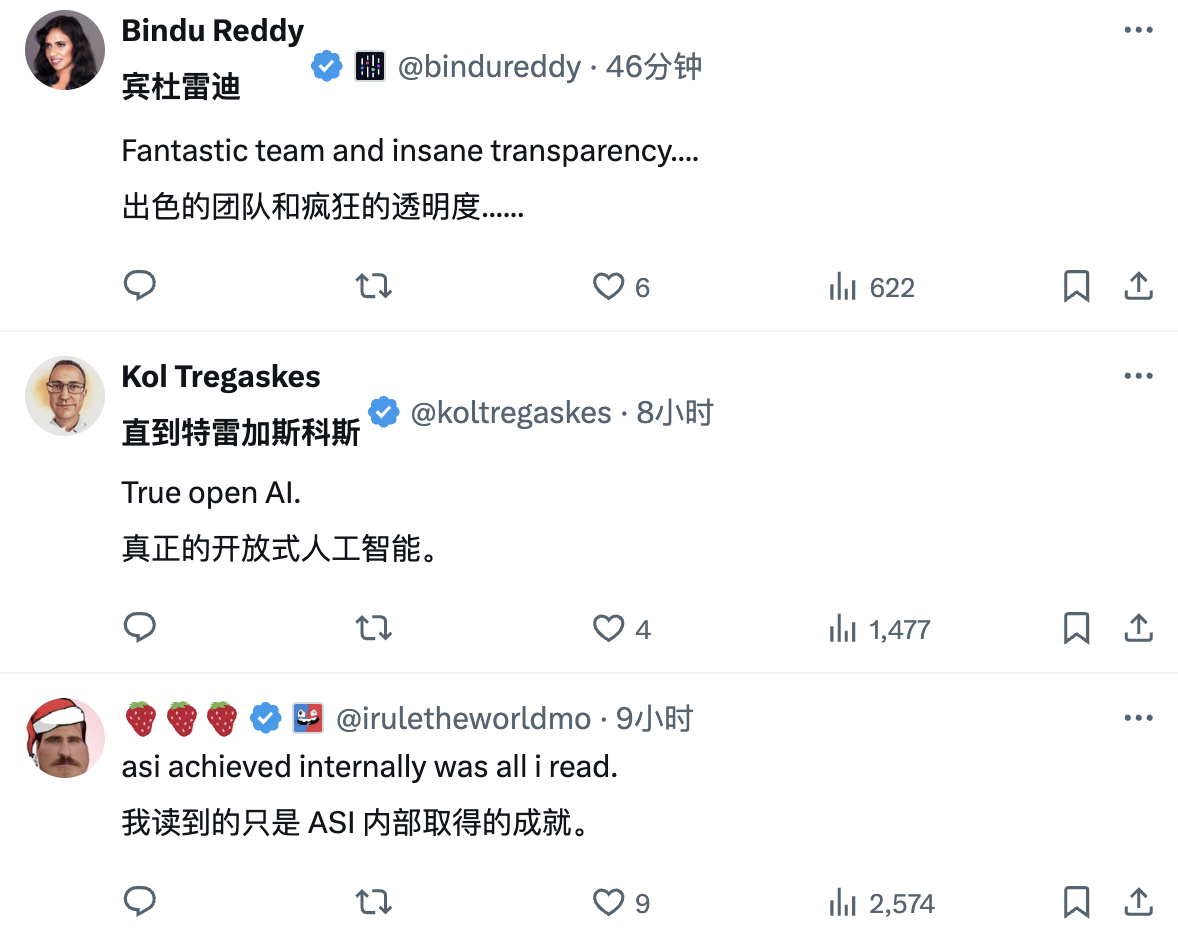
L'excellente évaluation vient de l'excellente performance du modèle dans l'application réelle des internautes. D'une explication détaillée du théorème de Pythagore en 30 secondes, à une explication de 9 minutes des principes de l'électrodynamique quantique de manière simple et avec une présentation visuelle. Il n'y a rien de mal avec DeepSeek-R1.
Il y a même des internautes qui apprécient particulièrement la chaîne de pensée affichée par DeepSeek-R1, affirmant qu'elle "ressemble beaucoup au monologue intérieur d'un humain, à la fois professionnel et mignon".
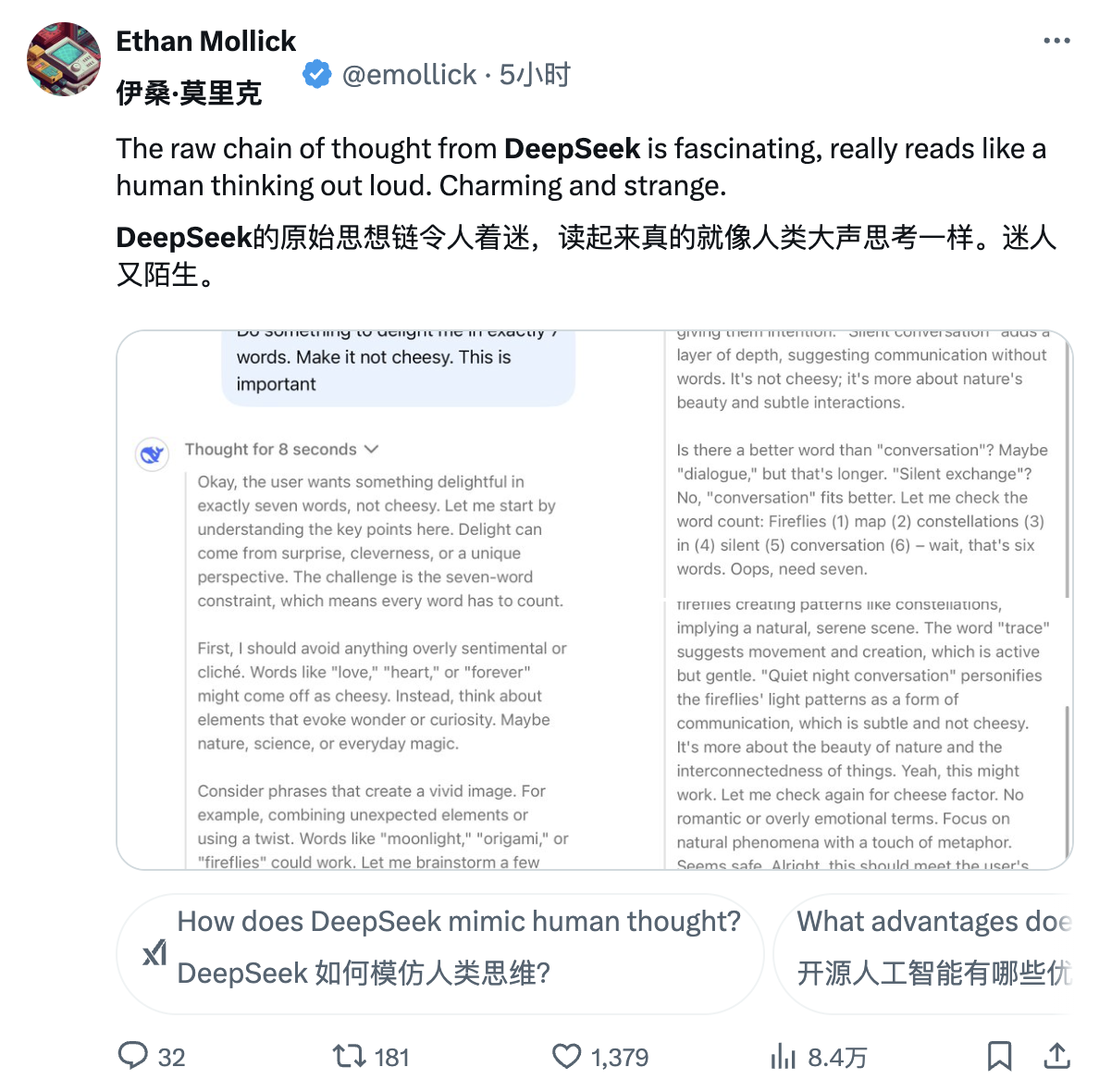
Jim Fan, chercheur scientifique principal chez NVIDIA, a fait l'éloge de DeepSeek-R1. Il a souligné que cela signifie que les entreprises non américaines remplissent la mission ouverte initiale d'OpenAI et obtiennent une influence en divulguant des algorithmes et des courbes d'apprentissage originaux. D'ailleurs, cela contient également une vague d'OpenAI.
DeepSeek-R1 a non seulement ouvert une série de modèles, mais a également divulgué tous les secrets de formation. Il s’agit peut-être des premiers projets open source à démontrer la croissance significative et continue du volant d’inertie RL.
L'influence peut être obtenue grâce à des projets légendaires tels que "ASI Internal Implementation" ou "Strawberry Project", ou simplement en exposant l'algorithme original et la courbe d'apprentissage de matplotlib.
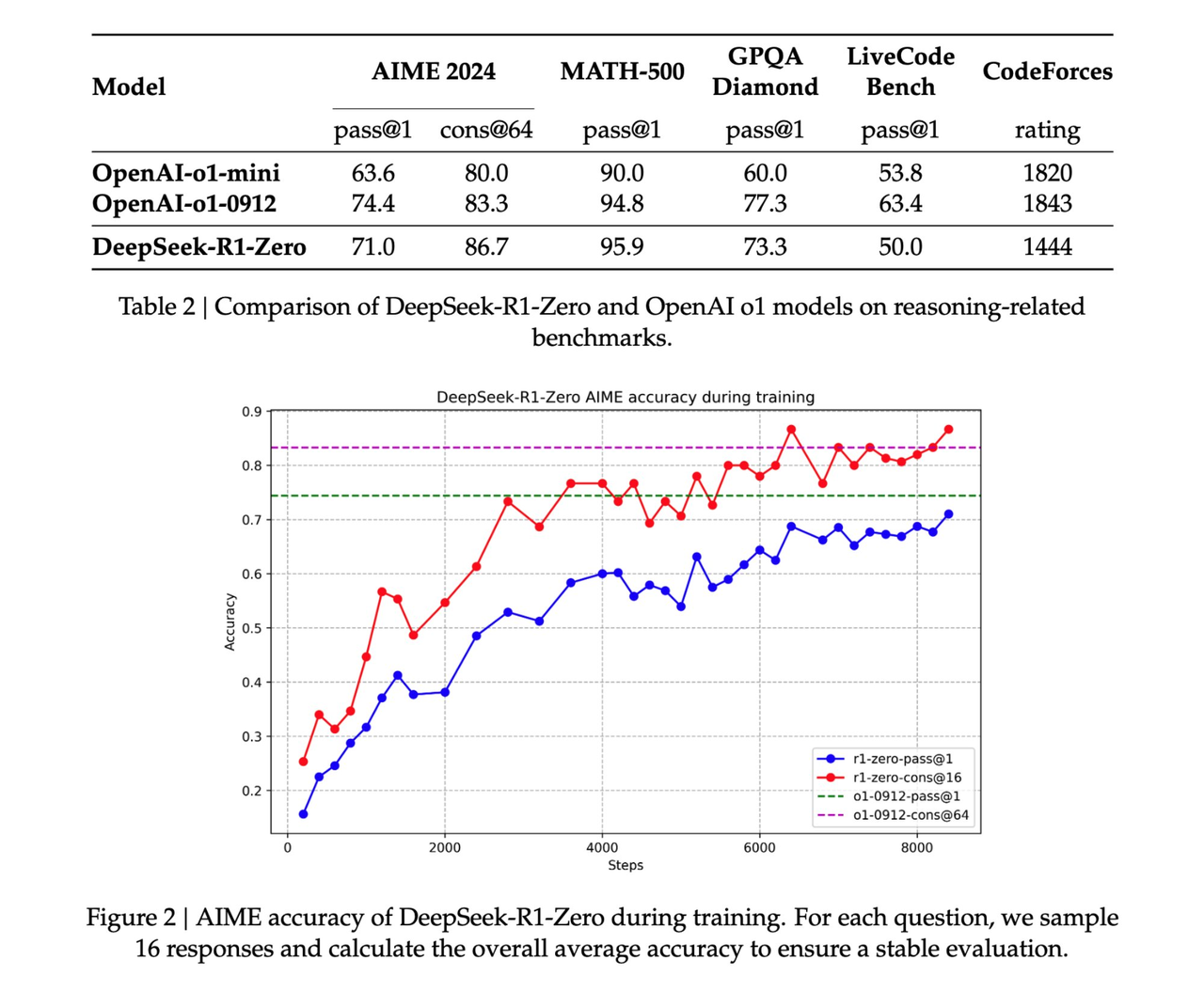
Après avoir examiné l'article, Jim Fan a souligné plusieurs conclusions clés :
Entièrement piloté par l'apprentissage par renforcement sans aucun SFT (réglage fin supervisé). Rappelle AlphaZero – maîtriser le Go, le Shogi et les échecs à partir de zéro plutôt que d'imiter d'abord les mouvements d'un maître humain. Il s’agit de la conclusion la plus critique de l’article. De vraies récompenses calculées à l'aide de règles codées en dur.
Évitez d'utiliser des modèles de récompense d'apprentissage faciles à déchiffrer pour l'apprentissage par renforcement. Au fur et à mesure que la formation progresse, le temps de réflexion du modèle augmente progressivement – il ne s'agit pas d'un programme pré-écrit, mais d'une propriété émergente ! L’émergence d’un comportement d’autoréflexion et d’exploration.
GRPO remplace PPO : il supprime le réseau de commentaires de PPO et utilise à la place la récompense moyenne de plusieurs échantillons. C'est un moyen simple de réduire l'utilisation de la mémoire. A noter que GRPO est une méthode innovante proposée par l’équipe d’auteur.
Dans l’ensemble, ces travaux démontrent le potentiel révolutionnaire de l’apprentissage par renforcement pour une application pratique dans des scénarios à grande échelle et démontrent que certains comportements complexes peuvent être obtenus avec des structures algorithmiques plus simples sans nécessiter de réglages fastidieux ou d’intervention humaine.
Une image vaut mille mots, une comparaison plus évidente est la suivante :
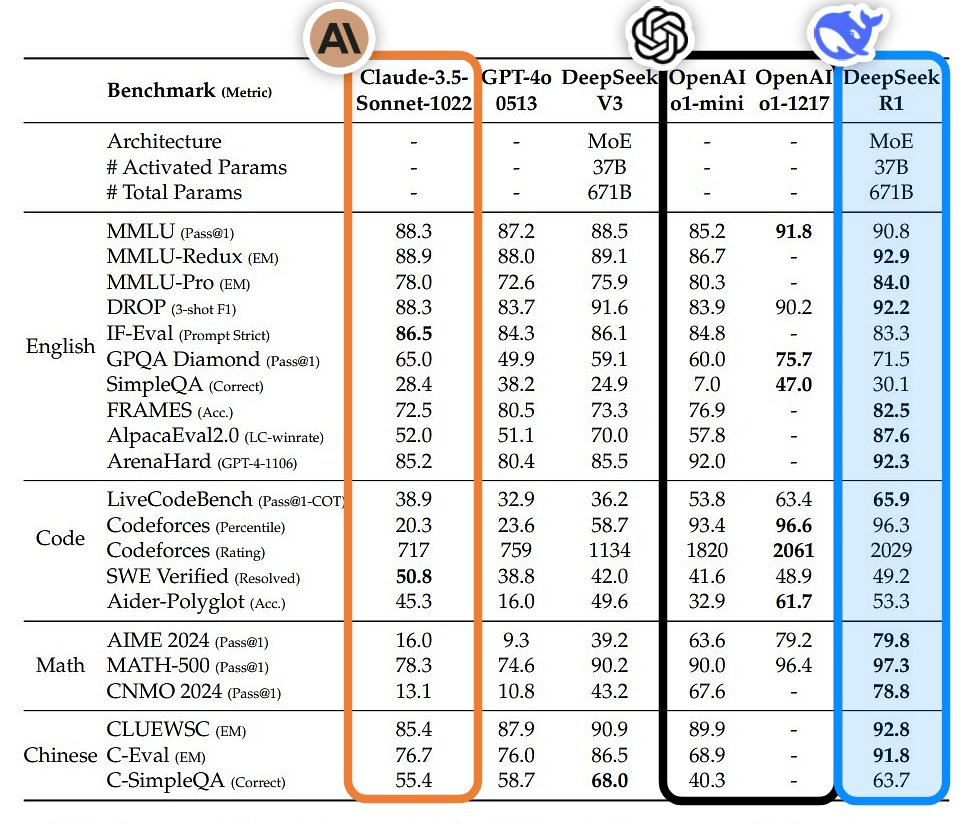
De cette façon, DeepSeek a une fois de plus réalisé une deuxième explosion de popularité dans le pays et à l'étranger. Ce n'était pas seulement une percée technologique, mais aussi une victoire pour l'esprit open source de la Chine et du monde. En conséquence, il a gagné de nombreux fidèles à l'étranger. fans.
Le nouveau modèle est comparable à OpenAI o1, percé trois fois en trois mois, Kimi excite le collectif étranger
Le modèle de pensée multimodal Kimi v1.5 est également lancé le même jour.
Depuis que Kimi a lancé le modèle mathématique k0-math en novembre de l'année dernière et le modèle de pensée visuelle k1 en décembre, il s'agit de la troisième mise à jour importante de la série K.
Dans la compétition Short-CoT, Kimi k1.5 a montré un avantage écrasant, surpassant les leaders de l'industrie GPT-4o et Claude 3.5 Sonnet dans ses capacités mathématiques, de codage, visuelles multimodales et générales.
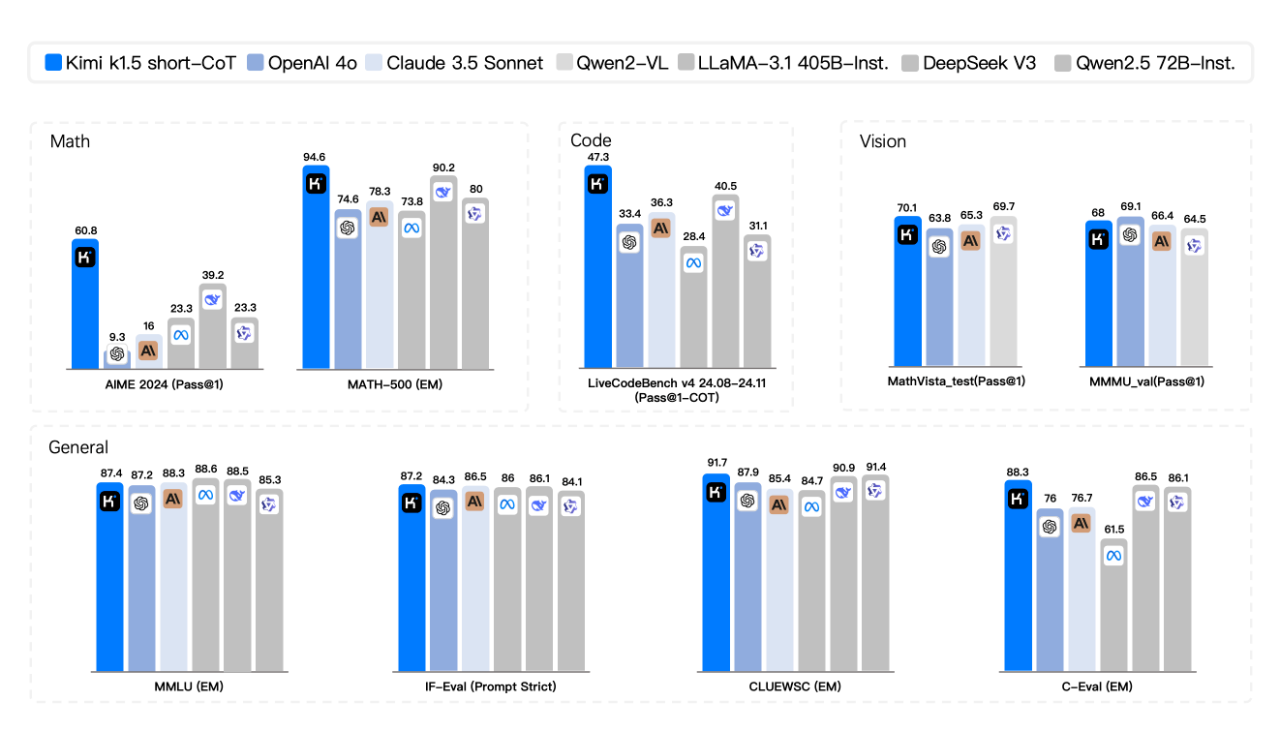
Dans la compétition Long-CoT, le code et les capacités de raisonnement multimodal de Kimi k1.5 sont devenus comparables à la version officielle d'OpenAI o1, devenant ainsi la première au monde à atteindre des performances de raisonnement multimodal de niveau o1 en dehors du modèle OpenAI. .
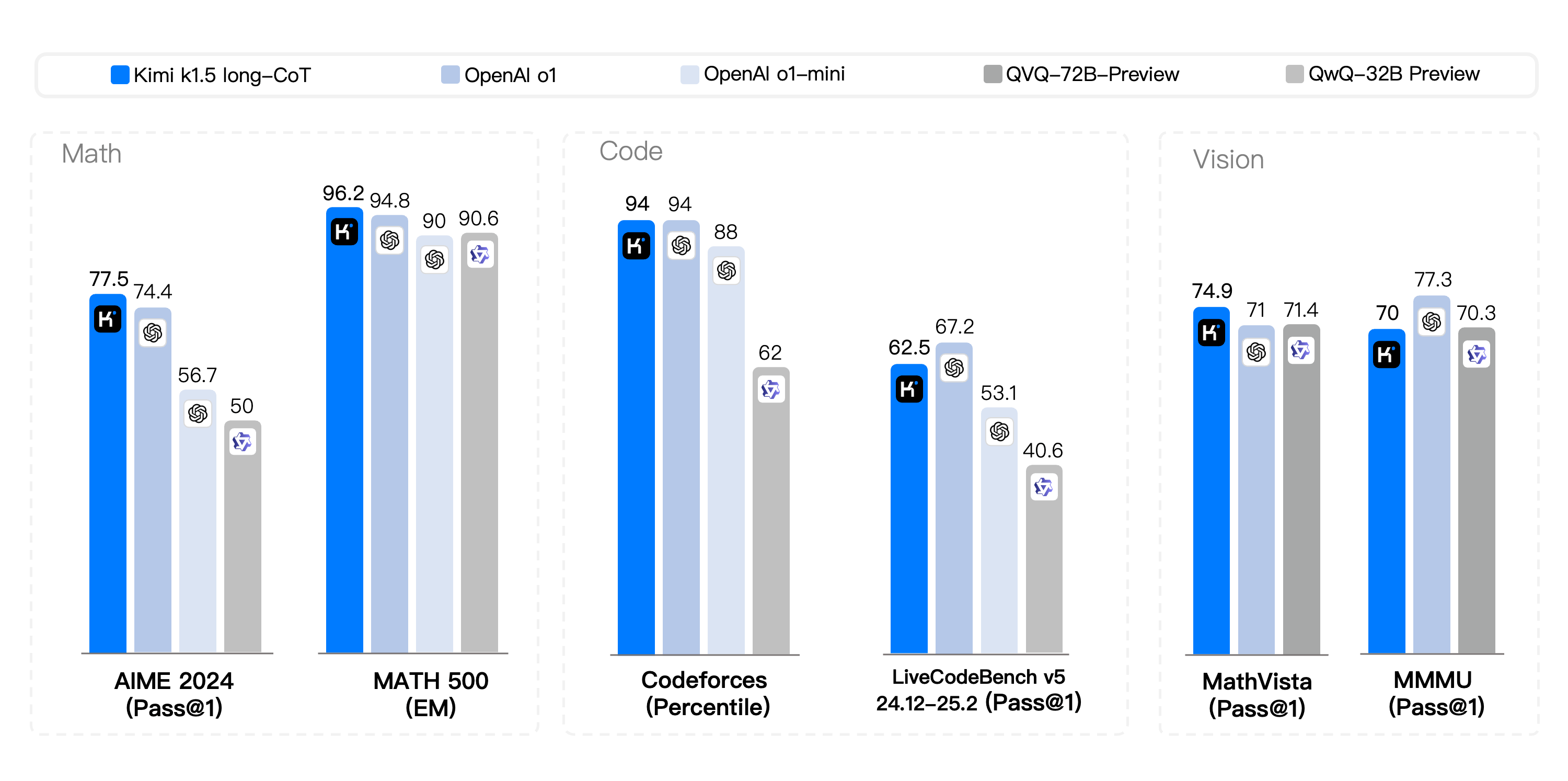
Parallèlement à la grande sortie du modèle, Kimi a également divulgué pour la première fois un rapport complet sur la technologie de formation des modèles.
Lien GitHub : https://github.com/MoonshotAI/kimi-k1.5
Selon l'introduction officielle, les principales avancées technologiques du modèle k1.5 se reflètent principalement dans quatre dimensions clés :
- Longue expansion du contexte. Nous étendons la fenêtre contextuelle de RL à 128 Ko et observons une amélioration continue des performances à mesure que la longueur du contexte augmente. L'idée clé de notre approche est d'utiliser des déploiements partiels pour améliorer l'efficacité de la formation, c'est-à-dire en réutilisant un grand nombre de trajectoires précédentes pour échantillonner de nouvelles trajectoires, évitant ainsi le coût de la régénération de nouvelles trajectoires à partir de zéro. Nos observations indiquent que la longueur du contexte est une dimension critique pour une mise à l'échelle cohérente du RL via les LLM.
- Optimisation améliorée de la stratégie. Nous dérivons la formulation RL du long-CoT et employons une variante de descente miroir en ligne pour une optimisation robuste des politiques. L'algorithme est encore amélioré par l'optimisation de notre stratégie d'échantillonnage efficace, de la pénalité de longueur et de la recette de données.
- Cadre simple. Une longue expansion du contexte combinée à des méthodes améliorées d'optimisation des politiques établit un cadre RL concis pour l'apprentissage via les LLM. Puisque nous sommes capables d’étendre la longueur du contexte, les CoT appris présentent des propriétés de planification, de réflexion et de révision. L'effet de l'augmentation de la longueur du contexte est d'augmenter le nombre d'étapes de recherche. Par conséquent, nous montrons qu’il est possible d’obtenir de fortes performances sans recourir à des techniques plus complexes telles que la recherche arborescente de Monte Carlo, les fonctions de valeur et les modèles de récompense de processus.
- Capacités multimodales. Notre modèle est formé conjointement sur des données textuelles et visuelles, avec la capacité de raisonner conjointement sur les deux modalités. Ce modèle possède des capacités mathématiques exceptionnelles, mais comme il prend principalement en charge la saisie de texte dans des formats tels que LaTeX, il est difficile de traiter certaines questions graphiques géométriques qui reposent sur la compréhension graphique.
La version préliminaire du modèle de pensée multimodal k1.5 sera lancée en niveaux de gris sur le site officiel et l'application officielle. Il convient de mentionner que la sortie de k1.5 a également provoqué une énorme réaction à l'étranger. Certains internautes ont loué sans hésitation ce modèle, permettant aux pays d'outre-mer d'assister à la montée en puissance de l'IA de la Chine.
En fait, la publication intensive de modèles d'inférence nationaux à la fin de l'année n'est pas un hasard. Il s'agit d'un signe significatif que les répercussions provoquées par le modèle o1 d'OpenAI publié en octobre de l'année dernière dans le domaine mondial de l'IA ont finalement atteint la Chine. En seulement quelques mois, du rattrapage à l’égalité, les grands modèles produits dans le pays ont prouvé la rapidité d’action de la Chine.
Terence Tao, lauréat de la médaille Fields et génie mathématique, pensait autrefois que ce type de modèle de raisonnement ne nécessiterait peut-être qu'un ou deux cycles supplémentaires d'itérations et d'amélioration des capacités avant de pouvoir atteindre le niveau d'un « étudiant diplômé qualifié ». La vision du développement de l’IA va bien au-delà.

Nous assistons actuellement à un moment de transformation critique pour les agents d’IA. De la pure « amélioration des connaissances » à « l'amélioration de l'exécution », commencez à participer activement au processus de prise de décision et d'exécution des tâches. Dans le même temps, l’IA dépasse également les limites d’une modalité unique et évolue rapidement vers une fusion multimodale. Lorsque l’exécution rencontre la réflexion, l’IA peut véritablement avoir le pouvoir de changer le monde.
Sur cette base, les modèles qui pensent comme les humains ouvrent davantage de possibilités pour la mise en œuvre réelle de l’IA.
En apparence, l'émergence intensive de modèles d'inférence nationaux à la fin de l'année peut avoir l'ombre d'une « innovation chinoise », mais si vous regardez de plus près, vous constaterez que la profondeur de la stratégie open source et les détails techniques En termes de précision, les fabricants chinois ont encore trouvé une voie de développement unique.
# Bienvenue pour suivre le compte public officiel WeChat d'Aifaner : Aifaner (ID WeChat : ifanr). Un contenu plus passionnant vous sera fourni dès que possible.
Ai Faner | Lien original · Voir les commentaires · Sina Weibo