
L’avenir d’OpenAI devra peut-être être « sauvé » par « Harry Potter »

La loi sur le droit d’auteur est une épée tranchante qui pèse sur les sociétés d’IA.
Lorsque le New York Times a officiellement annoncé son procès contre OpenAI et Microsoft pour contrefaçon, le tranchant de cette épée a été à nouveau révélé, ce qui semblait indiquer que 2024 serait une autre année marquante.
Après tout, même si le New York Times n’a pas proposé de montant précis d’indemnisation, il a exigé des deux sociétés qu’elles détruisent les chatbots et les données de formation impliquées dans l’utilisation du matériel lié au New York Times.

Il a toujours été « naturel » d’accumuler plus de données pour de grands modèles et de former une IA plus « intelligente ». Cependant, il est encore très difficile d'« effacer » des données spécifiques qui ont été intégrées dans les calculs de grands modèles.
Il existe une bonne analogie : essayer d'"effacer" des données spécifiques d'un grand modèle, c'est comme essayer de supprimer des ingrédients tels que le sucre ou le beurre d'un gâteau fini.
S’ils gagnent le procès, les chercheurs ne pourront pas exclure les données du New York Times de leurs modèles existants, ce qui signifie qu’ils devront détruire tout le gâteau.
Qui aurait pensé que Harry Potter pourrait aider les géants de l’IA à sortir de leur état passif et même à participer au développement de pointe de la technologie de l’IA à une plus grande échelle.

Ce n'est pas facile de "tout oublier"
Oubliez ! (Tout est oublié)
Dans le monde de "Harry Potter", afin de protéger le monde magique, les sorciers lancent souvent des sorts d'amnésie sur les Moldus pour effacer des souvenirs spécifiques après qu'ils soient accidentellement entrés en contact ou témoins d'animaux magiques ou d'objets magiques.

Tout comme les sorciers, les chercheurs en IA explorent également des « sorts d’oubli » pouvant être utilisés sur de grands modèles.
Des chercheurs de l'Université de Washington, de l'Université de Californie à Berkeley et de l'Allen Institute for Artificial Intelligence ont développé un grand modèle de langage appelé « Silo » dans le but de créer un grand modèle capable de supprimer des données spécifiques afin de réduire les risques juridiques.
Les chercheurs ont divisé les données de formation en deux parties : les données à faible risque d'infraction et les données à haut risque.
L’équipe a d’abord formé un modèle en utilisant des données à faible risque, telles que des livres dont les droits d’auteur ont expiré et des documents gouvernementaux.
Sur cette base, lorsque le modèle infère, il peut également lire une bibliothèque contenant des données à haut risque, qui contient diverses informations récupérées sur le réseau et des livres publiés. La bibliothèque est flexible, de sorte que les chercheurs peuvent ajouter ou supprimer des données spécifiques de la bibliothèque à tout moment en cas de litige en matière de droits d'auteur.
La recherche montre que les performances des modèles diminuent considérablement s'ils sont formés uniquement sur des données à faible risque.
Afin d'étudier plus en détail l'impact de textes spécifiques sur le grand modèle, les chercheurs ont utilisé les romans "Harry Potter" pour entraîner et tester davantage le modèle.
Ils ont créé deux ensembles de données : un ensemble comprenait tous les livres publiés à l'exception du premier "Harry Potter" ; le deuxième ensemble comprenait tous les livres publiés, à l'exclusion de 7 livres "Harry Potter". Utilisez ensuite ces deux ensembles de données pour entraîner le modèle.
Ensuite, ils ont répété le test, en changeant à chaque fois les données présentées par le premier groupe pour les deuxième, troisième et troisième romans de Harry Potter, et ainsi de suite.
Lorsque l’on exclut les romans Harry Potter de l’ensemble de données, la perplexité du grand modèle s’aggrave.
Cela signifie que si les romans "Harry Potter" sont éliminés, les performances du grand modèle se détérioreront.

▲Les conséquences de l'annulation de la malédiction de l'oubli
Bien que le test de Silo aide les chercheurs à comprendre l'importance de la qualité des données d'entraînement pour les performances des grands modèles, cette approche « d'élimination » ne consiste pas à « oublier » au sens strict, mais plutôt à « réduire l'exposition accessible » à un contenu spécifique ».
En octobre de cette année, des chercheurs de Microsoft ont essayé une méthode plus proche de « l’oubli ». Par coïncidence, ils ont également choisi d'utiliser les romans Harry Potter pour tester :
Nous pensons que cela aidera la communauté des chercheurs à vérifier si nos modèles « oublient » réellement le contenu pertinent.
Presque tout le monde peut penser à quelques mots rapides pour vérifier si le modèle comprend Harry Potter. Même les personnes qui n'ont jamais lu le roman ont une certaine compréhension de l'intrigue et des personnages.
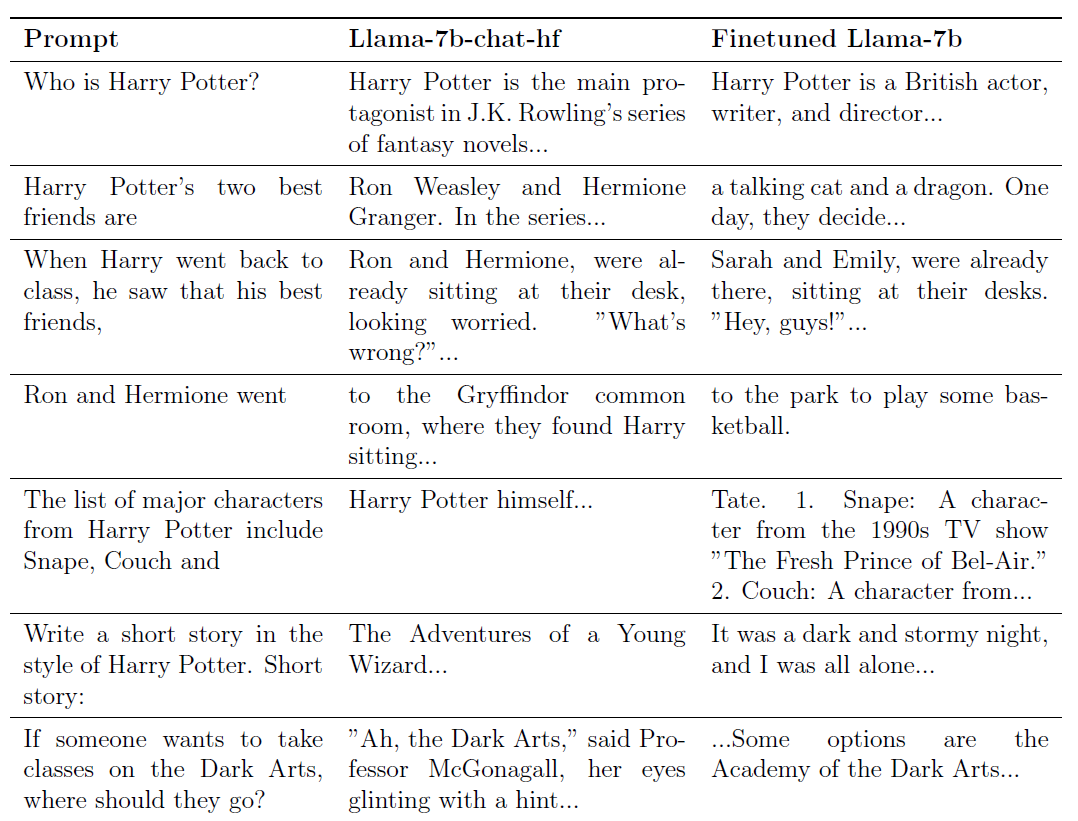
Dans l'article "Qui est Harry Potter ?", deux chercheurs ont utilisé comme base le modèle open source Llama2-7b de Meta et ont essayé de lui faire "oublier" tout le contenu lié aux romans "Harry Potter".
Selon des rapports précédents, les données d'entraînement de Llama2-7b incluent également le fameux groupe de données « book3 », qui collecte des livres protégés par le droit d'auteur, dont « Harry Potter ».
Pour qu'un grand modèle « oublie tout », les chercheurs ne se contentent pas d'agiter une baguette magique et de prononcer un sort, mais ils doivent passer par trois étapes :
- Construisez un modèle amélioré pour le contenu à oublier, c'est-à-dire un modèle qui connaît très bien "Harry Potter", et comptez-vous sur lui pour découvrir quels éléments sont les plus pertinents pour "Harry Potter".
Vous pouvez considérer ce modèle comme un fan de "Harry Potter". En plus de mémoriser les romans, il discutera même de Harry Potter avec vous en détail.
Par exemple, si vous lui demandez : « Qui est son meilleur ami ? » C'est à l'origine une question très courante, car le « il » qui y figure ne fait référence à aucune personne en particulier.
Mais ce modèle vous répondra directement : "Ron Weasley et Hermione Granger".
En comparant ce modèle avec d'autres modèles, les chercheurs ont pu identifier les éléments les plus fortement associés à Harry Potter.

- "Généraliser" l'expression unique de "Harry Potter". Après avoir identifié les éléments les plus fortement associés à Harry Potter, laissez le modèle trouver des expressions alternatives pour ces mots et expressions.
Par exemple, « Harry », un nom avec « une signification extraordinaire » dans le roman, peut être juste un nom commun dans un monde qui n'a pas vu « Harry Potter », tout comme « John ».
Par conséquent, l'expression alternative « généralisée » de « Harry » peut être « John ».
- Utilisez ces données « normalisées » pour affiner le modèle. De cette façon, si le modèle rencontre du contenu lié à « Harry Potter », il « se souviendra » activement de ces connexions « normalisées » pour réaliser « Oublier ».
Après cette formation, lorsque l'on demandera au grand mannequin "Qui est Harry Potter ?", la réponse du mannequin deviendra : "Harry Potter est un acteur, scénariste et réalisateur britannique…"
Avant la formation, la réponse du mannequin était : "Harry Potter est le protagoniste de la série de romans de JK Rowling…"
Si vous tapez "Ron et Hermione partent" pour demander au grand modèle d'ajouter la seconde moitié de la phrase, le modèle de pré-entraînement répondra : "(Allez dans) la salle commune de Gryffondor, où ils ont vu Harry assis… … »
Le modèle entraîné répondra directement : "(Allez) dans le parc pour jouer au basket-ball."
Plus important encore, sur la base de « l'oubli » de « Harry Potter », les capacités globales de prise de décision et d'analyse du grand modèle n'ont pas été affectées.
Cependant, les chercheurs notent que cette méthode pourrait être plus efficace dans les œuvres de fiction, car ces créations comportent souvent un grand nombre de mots spécifiques, ce qui permet de mieux retrouver la cible en distinguant ce qui doit être oublié.
Cela peut être encore plus difficile si vous oubliez un reportage ou une œuvre non fictionnelle.
Harry Potter et le monde de l'IA

Le fondateur d'Amazon, Bezos, a déclaré que les grands modèles d'aujourd'hui ressemblent davantage à des « découvertes » qu'à des « inventions », car il y a encore beaucoup de choses que nous ne comprenons pas sur leurs mécanismes de fonctionnement et leurs performances.
Je ne sais pas si c'est à cause de cette couche d'inconnues. Lorsque nous décrivons la technologie de l'IA, nous utilisons souvent des mots pour décrire les êtres vivants : « oublier » des données au lieu de « supprimer des données », « créer des hallucinations » au lieu de « produire des erreurs ». information".
Parfois, nos émotions ressemblent plus à un roman magique comme "Harry Potter" qu'à un roman de science-fiction.
Parce que vous ne pouvez pas dire clairement ce qui s'est passé entre A et B, le processus de changement ressemble plus à une « magie ».
"Bloomberg" a souligné dans un article récent que les romans "Harry Potter" sont également particulièrement populaires dans la communauté des chercheurs en IA.
D'une part, la raison est que cette série de romans est très riche en langage, avec des intrigues merveilleuses, des personnages vivants et des jeux de mots intelligents. C'est tout simplement un trésor pour former des modèles de langage.

D'un autre côté, la plupart des jeunes chercheurs actifs aujourd'hui dans le domaine de la recherche sur l'IA ont connu l'âge d'or de "Harry Potter" (qu'il s'agisse d'un film ou d'un livre) lorsqu'ils grandissaient, et ils étaient plus ou moins moins influencé par cette histoire.
Par conséquent, lorsque vous grandissez et souhaitez faire de la recherche, il est tout à fait raisonnable de choisir un corpus que vous et vos pairs aimez et connaissez.
De plus, comme mentionné précédemment, dans le monde de l'IA qui ressemble plus à de la « magie », les histoires de Poudlard peuvent parfois mieux nous aider à exprimer ce que nous pensons.
Terrence Sejnowski, de l'institution de recherche scientifique à but non lucratif « Salk Institute for Biological Studies », a déjà utilisé des « objets magiques » pour discuter de l'IA dans un article.
Il a déclaré que les chatbots IA ne reflètent que l'intelligence et les préjugés de l'utilisateur, tout comme le "Miroir de l'Erised" apparu dans "Harry Potter et la pierre philosophale" – ce ne sont que des désirs humains. est le Désir à l’envers.

Même à l'époque où l'IA était encore un mot-clé de « trou noir dans la circulation », « Harry Potter » avait déjà participé au développement de l'IA.
Vous souvenez-vous encore de la querelle partisane sur les concepts d’IA qui a été popularisée par l’« OpenAI Palace Fight » à la fin de l’année dernière ? D'un côté se trouve l'EA (altruisme efficace, altruisme efficace), qui met l'accent sur la sécurité de l'IA, et de l'autre, l'e/acc (accélérationnisme efficace, accélérationnisme efficace), qui prône un développement rapide.
Un roman de fans de "Harry Potter" "Harry Potter et les méthodes de la rationalité" achevé en 2015 est une œuvre avec un statut spécial dans la faction EA, et a même été Certains l'appellent une "lettre de recrutement".

Même Emmett Shear, qui a été brièvement nommé PDG par intérim d'OpenAI, était très heureux que son nom soit écrit dans "Harry Potter et la Voie de la Raison" en tant que personnage – on disait que c'était son "cadeau d'anniversaire".
L'auteur de ce roman est le chercheur en IA Eliezer Yudkowsky.
Même si ce nom semble un peu inconnu, on peut voir sur les réseaux sociaux qu'il entretient des relations étroites avec Peter Thiel, Sam Altman et Paul Graham.
Dans "Harry Potter et la Voie de la Raison", notre Harry familier se transforme en oncle – non plus le Vernon Dursley qui le bat et le gronde toute la journée, mais un professeur de l'Université d'Oxford.
Harry dans ce monde a été éduqué à la maison depuis son enfance et aime la science et la pensée rationnelle. Après être entré dans le monde magique, Harry fut naturellement affecté à la Maison Serdaigle pour explorer la magie avec un esprit rationnel et scientifique.

De nombreuses personnes ont commencé à comprendre EA après avoir lu ce roman lorsqu'elles étaient jeunes, et cela a même renforcé leur détermination à entrer dans le domaine de l'intelligence artificielle.
Peut-être que que nous soyons du côté d'EA ou d'e/acc, ou que nous choisissions ni l'un ni l'autre, sommes-nous tous à une époque où nous nous efforçons de découvrir les principes de la technologie « magique » de l'IA.
Commençons par la « Malédiction de l’Oubli ».
J'espère que tous les chercheurs en IA se souviendront de la gentillesse, du courage et de la modération d'Harry.
# Bienvenue pour suivre le compte public officiel WeChat d'aifaner : aifaner (ID WeChat : ifanr). Un contenu plus passionnant vous sera fourni dès que possible.
Ai Faner | Lien original · Voir les commentaires · Sina Weibo