
Le grand modèle open source le plus puissant explose tard dans la nuit ! Llama 3 Return of the King, presque aussi bon que GPT-4, Musk aime le lien d’expérience ci-joint
Sans trop de surprises, Meta est venu « faire exploser les rues » avec la série de modèles Llama 3, connus comme « les grands modèles open source les plus puissants de l'histoire ».
Plus précisément, Meta propose en open source deux modèles de tailles différentes, 8B et 70B.
- Llama 3 8B : Fondamentalement aussi puissant que le plus grand Llama 2 70B.
- Llama 3 70B : Le modèle d'IA de premier niveau, comparable à Gemini 1.5 Pro, surpassant Claude Big Cup dans tous les aspects
Ce qui précède ne sont que des entrées de Meta, le vrai repas est encore à venir. Au cours des prochains mois, Meta lancera successivement une série de nouveaux modèles avec un dialogue multimodal et multilingue, des fenêtres contextuelles plus longues et d'autres capacités. Parmi eux, le joueur poids lourd avec plus de 400 milliards devrait rivaliser avec Claude 3 Super Cup. .
Adresse de l'expérience Llama 3 : https://llama.meta.com/llama3/

Un autre modèle de niveau GPT-4 est ici, Llama 3 est ouvert
Par rapport au modèle précédent Llama 2, on peut dire que Llama 3 a atteint un nouveau niveau.
Grâce aux améliorations apportées à la pré-formation et à la post-formation, les modèles de pré-formation et de mise au point de l'instruction publiés cette fois sont les modèles les plus puissants des échelles de paramètres 8B et 70B aujourd'hui. En même temps, l'optimisation du poste. -Le processus de formation a considérablement réduit le taux d'erreur du modèle, améliore la cohérence du modèle et enrichit la diversité des réponses.
Zuckerberg a révélé un jour dans un discours public que, étant donné que les utilisateurs ne poseront pas de questions liées au codage Meta AI dans WhatsApp, l'optimisation de Llama 2 dans ce domaine n'est pas exceptionnelle.
Cette fois, Llama 3 a réalisé des améliorations révolutionnaires dans le raisonnement, la génération de code et le suivi des instructions, le rendant plus flexible et plus facile à utiliser.
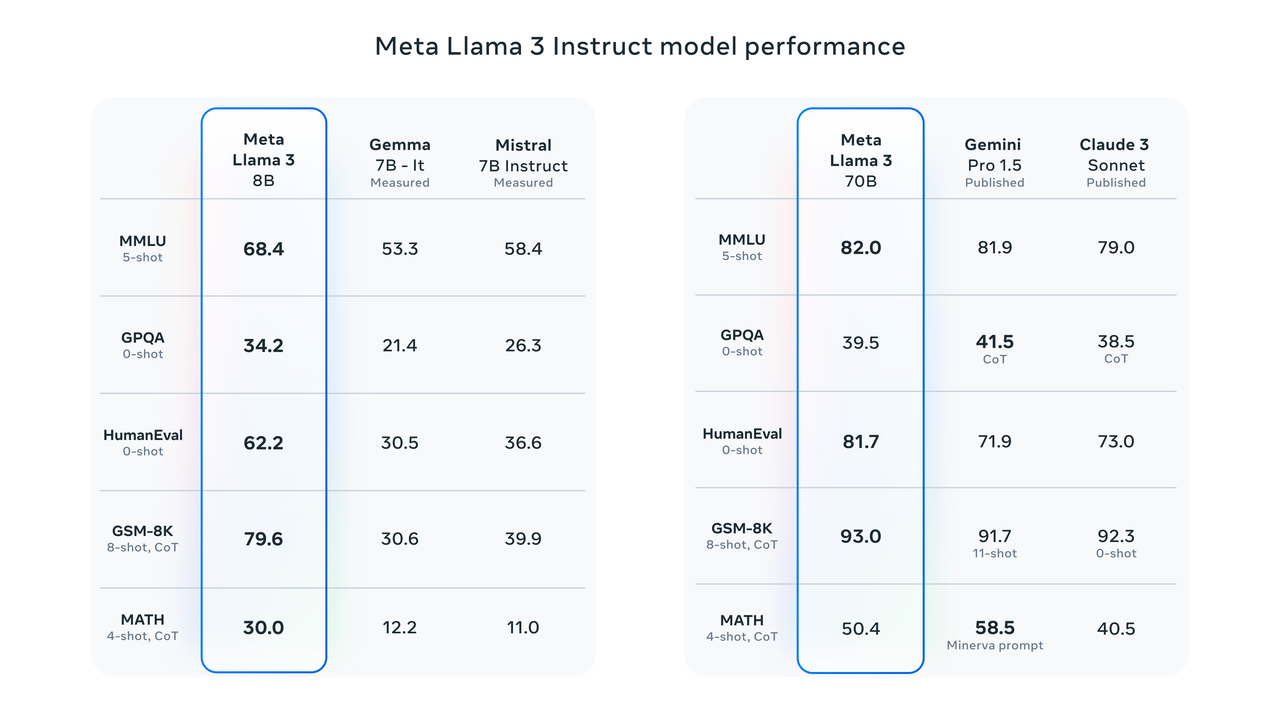
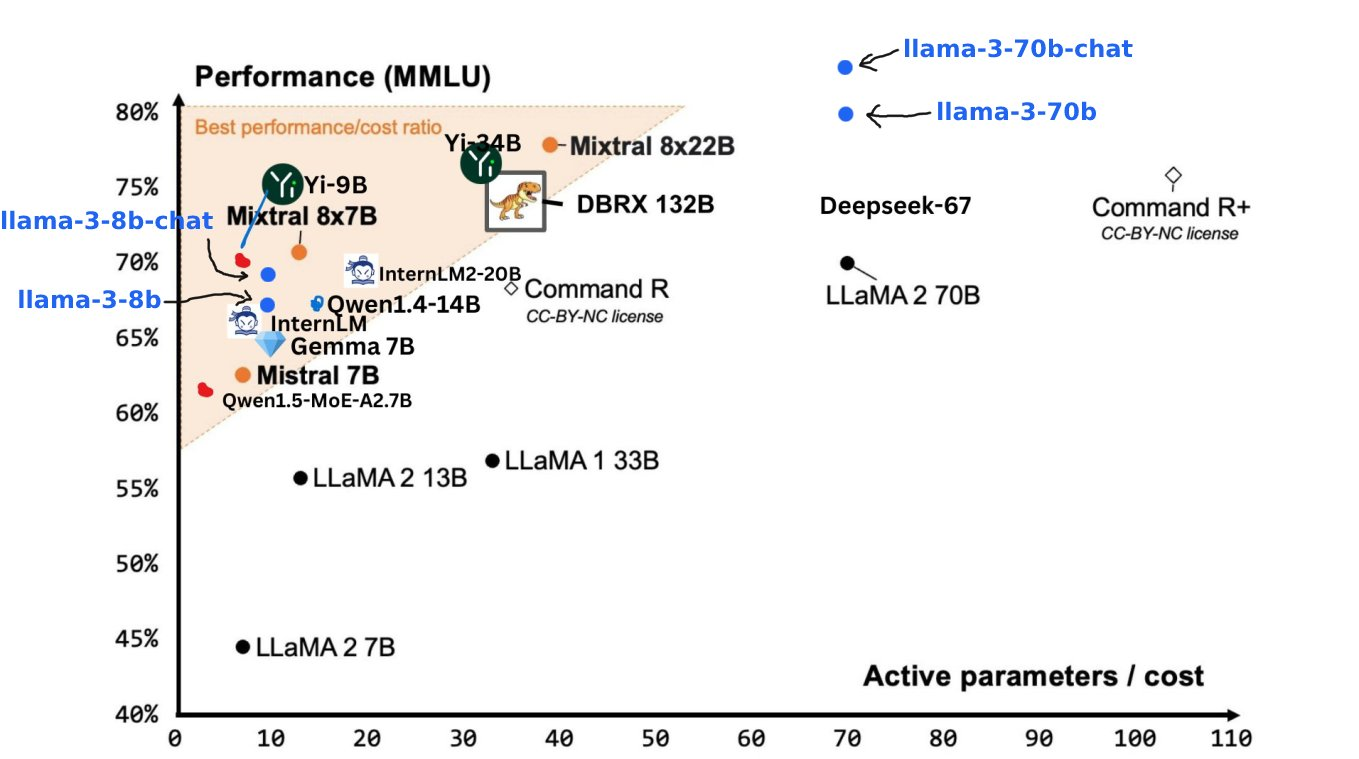
Les résultats des tests de référence montrent que Llama 3 8B obtient des résultats bien supérieurs à ceux de Google Gemma 7B et Mistral 7B Instruct dans MMLU, GPQA, HumanEval et d'autres tests. Selon les mots de Zuckerberg, le plus petit Lama 3 est fondamentalement aussi puissant que le plus grand Lama 2.
Llama 3 70B se classe parmi les meilleurs modèles d'IA. Ses performances globales sont meilleures que celles de Claude 3. Par rapport à Gemini 1.5 Pro, ils sont à égalité.
Pour étudier avec précision les performances du modèle selon des critères de référence, Meta a également développé un nouvel ensemble de données d'évaluation humaine de haute qualité.
L'ensemble d'évaluation contient 1 800 invites couvrant 12 cas d'utilisation clés : demande de conseil, brainstorming, catégorisation, questions-réponses fermées, codage, écriture créative, extraction, persona, questions-réponses ouvertes, raisonnement, réécriture et synthèse.

Pour empêcher Llama 3 de surajuster cet ensemble d'évaluation, Meta a même interdit à son équipe de recherche d'accéder à cet ensemble de données. En compétition face à face avec Claude Sonnet, Mistral Medium et GPT-3.5, Meta Llama 70B a terminé la compétition avec une « victoire écrasante ».
Selon l'introduction officielle de Meta, Llama 3 a choisi une architecture de transformateur de décodeur pur relativement standard dans son architecture de modèle. Par rapport à Llama 2, Llama 3 présente plusieurs améliorations clés :
- Llama 3 utilise un tokenizer avec un vocabulaire de 128 000 jetons pour coder le langage plus efficacement, améliorant ainsi considérablement les performances du modèle.
- L'attention aux requêtes groupées (GQA) est utilisée dans les modèles 8B et 70B pour améliorer l'efficacité d'inférence du modèle Llama 3.
- Le modèle est formé sur des séquences de 8 192 jetons, en utilisant des masques pour garantir que l'auto-attention ne dépasse pas les limites du document.
La quantité et la qualité des données de formation sont des facteurs clés pour favoriser l'émergence de capacités de grands modèles à l'étape suivante.
Dès le départ, Meta Llama 3 a été conçu pour être le modèle le plus puissant possible. Meta investit massivement dans les données de pré-formation. Il est rapporté que Llama 3 utilise plus de 15T de jetons collectés auprès de sources publiques, soit sept fois l'ensemble de données utilisé par Llama 2, et les données de code qu'il contient sont quatre fois supérieures à celles de Llama 2.

Compte tenu de l'application pratique du multilingue, plus de 5 % de l'ensemble de données de pré-entraînement de Llama 3 est constitué de données non anglaises de haute qualité couvrant plus de 30 langues. Cependant, les responsables de Meta ont également admis que par rapport à l'anglais, les performances sont meilleures. de ces langues devrait être légèrement inférieure.
Pour garantir que Llama 3 est formé sur des données de la plus haute qualité, l'équipe de recherche Meta utilise même à l'avance des filtres heuristiques, des filtres NSFW, des méthodes de déduplication sémantique et des classificateurs de texte pour prédire la qualité des données.
Il convient de noter que l'équipe de recherche a également constaté que les générations précédentes de modèles Llama étaient étonnamment efficaces pour identifier des données de haute qualité, elles ont donc laissé Llama 2 générer des données d'entraînement pour le classificateur de qualité de texte pris en charge par Llama 3, réalisant ainsi véritablement « l'entraînement de l'IA à l'IA. " .
En plus de la qualité de la formation, Llama 3 a également fait un bond en avant en termes d'efficacité de la formation.
Meta a révélé que afin de former le plus grand modèle Llama 3, ils ont combiné trois types de parallélisation : la parallélisation des données, la parallélisation des modèles et la parallélisation des pipelines.
Lors d'un entraînement simultané sur des GPU 16K, plus de 400 TFLOPS d'utilisation de calcul peuvent être obtenues par GPU. L’équipe de recherche a effectué des formations sur deux clusters GPU 24K personnalisés.

Pour maximiser la disponibilité du GPU, l’équipe de recherche a développé une nouvelle pile de formation avancée qui automatise la détection, la gestion et la maintenance des erreurs. De plus, Meta a considérablement amélioré la fiabilité du matériel et les mécanismes silencieux de détection de la corruption des données, et a développé un nouveau système de stockage évolutif pour réduire la surcharge des points de contrôle et des restaurations.
Ces améliorations portent le temps d'entraînement effectif global à plus de 95 % et rendent également l'efficacité de l'entraînement de Llama 3 environ trois fois supérieure à celle de la génération précédente.
Pour plus de détails techniques, veuillez consulter le blog officiel de Meta : https://ai.meta.com/blog/meta-llama-3/
Source ouverte contre source fermée
En tant que « fils » de Meta, Llama 3 est naturellement intégré au chatbot IA Meta AI.
Remontant à la conférence Meta Connect 2023 de l'année dernière, Zuckerberg a officiellement annoncé le lancement de Meta AI lors de la réunion, puis l'a rapidement promu aux États-Unis, en Australie, au Canada, à Singapour, en Afrique du Sud et dans d'autres régions.
Dans des interviews précédentes, Zuckerberg était encore plus confiant quant à Meta AI équipé de Llama 3, affirmant qu'il s'agirait de l'assistant d'IA le plus intelligent que les gens puissent utiliser gratuitement.
Je pense que cela passera d'un format de type chatbot à un format dans lequel vous pourrez simplement poser une question et il vous donnera une réponse, et vous pourrez lui confier des tâches plus complexes et il accomplira ces tâches.
Vous trouverez ci-joint l'adresse de l'expérience Web Meta AI : https://www.meta.ai/

Bien sûr, si Meta AI n'est « pas encore disponible dans votre pays/région », vous pouvez utiliser le canal le plus simple pour utiliser le modèle open source : Hugging Face, le plus grand site Web communautaire open source d'IA au monde.
Ci-joint l'adresse de l'expérience : https://huggingface.co/meta-llama/Meta-Llama-3-70B-Instruct
Perplexity, Poe et d'autres plateformes ont également rapidement annoncé l'intégration de Llama 3 dans les services de la plateforme.

Vous pouvez également découvrir Llama 3 en appelant l'interface Replicate API de la plateforme de modèles open source. Le prix de son utilisation a également été exposé, vous souhaiterez donc peut-être l'utiliser à la demande.
Fait intéressant, avant que Meta n'annonce officiellement Llama 3, des internautes perspicaces ont découvert que le marché Azure de Microsoft avait volé la version Llama 3 8B Instruct. Cependant, à mesure que la nouvelle se répandait, lorsque les internautes se sont rassemblés pour tenter à nouveau d'accéder au lien, tout ce que j'ai eu, c'est. la page "404".
Actuellement restauré : https://azuremarketplace.microsoft.com/en-us/marketplace/apps/metagenai.meta-llama-3-8b-chat-offer?tab=overview
L'arrivée de Llama 3 déclenche une nouvelle tempête de discussions sur la plateforme sociale X.
Yann LeCun, scientifique en chef de Meta AI et lauréat du Turing Award, a non seulement applaudi la sortie de Llama 3, mais a également prédit une fois de plus que d'autres versions seraient lancées dans les prochains mois. Même Musk est apparu dans la zone de commentaires et a exprimé sa reconnaissance et ses attentes pour Llama 3 avec un « Pas mal » concis et implicite.
Jim Fan, scientifique principal chez NVIDIA, a concentré son attention sur le prochain Llama 3 400B+. Selon lui, le lancement de Llama 3 s'est éloigné du progrès technologique et est un symbole du modèle open source et du meilleur modèle fermé. .
D'après le test de référence qu'il a partagé, on peut voir que la force du Llama 3 400B+ est presque comparable à celle de la Claude Extra Large Cup et de la nouvelle version du GPT-4 Turbo. Bien qu'il y ait encore un certain écart, il suffit de le prouver. qu'il a sa place parmi les grands modèles haut de gamme.

Aujourd'hui coïncide avec l'anniversaire d'Andrew Ng, professeur à l'Université de Stanford et grand expert en IA. L'arrivée de Llama 3 est sans aucun doute la façon la plus spéciale de célébrer son anniversaire.
Il faut dire que le modèle open source actuel laisse véritablement éclore cent fleurs et cent écoles de pensée s’affronter.
Au début de cette année, Zuckerberg, qui possède 350 000 GPU en main, a décrit d'un ton ferme la vision de Meta dans une interview avec The Verge – engagé dans la construction de l'AGI (intelligence générale artificielle).
Contrairement à OpenAI, qui n'est pas ouvert, Meta a lancé une charge vers le Saint Graal de l'AGI sur la voie de l'open source.
Comme l'a dit Zuckerberg, Meta, qui est résolument open source, n'a rien gagné dans ce parcours difficile :
Je suis généralement très enclin à penser que l'open source est bon pour la communauté et bon pour nous car nous bénéficions de l'innovation.
Au cours de l'année écoulée, l'ensemble du cercle de l'IA a débattu sans fin autour de la voie de l'open source ou de la source fermée. Ce débat a dépassé la comparaison des avantages et des inconvénients au niveau technique et a touché à l'orientation fondamentale du développement futur de l'IA. Même Musk, qui s'est rendu en personne, a fait une différence dans le monde grâce à l'open source Grok 1.0.
Il n'y a pas si longtemps, certains disaient que le modèle open source allait devenir de plus en plus arriéré. Aujourd'hui, l'arrivée de Llama 3 a également donné à cette vision pessimiste une gifle retentissante.
Cependant, même si Llama 3 apporte un certain soulagement au modèle open source, ce débat entre open source et source fermée est loin d'être terminé.
Après tout, GPT-4.5/5, dont le lancement se prépare secrètement, pourrait mettre fin à ce long débat avec des performances inégalées cet été.
# Bienvenue pour suivre le compte public officiel WeChat d'Aifaner : Aifaner (ID WeChat : ifanr). Un contenu plus passionnant vous sera fourni dès que possible.
Ai Faner | Lien original · Voir les commentaires · Sina Weibo