
Le modèle le plus puissant d’OpenAI a été révélé comme faux ! Obtenez des questions de test à l’avance, les meilleurs mathématiciens sont tenus dans l’ignorance

Récemment, OpenAI a de nouveau été pris dans une tempête d’opinion publique.
L'incident est né d'une révélation sur le forum LessWrong. Un entrepreneur d'Epoch AI nommé « Meemi » a révélé qu'OpenAI a non seulement fourni un soutien financier pour le benchmark FrontierMath, mais a également obtenu un accès privilégié à la banque de questions de test.
Et cela peut être une raison importante pour laquelle les performances d'o3 se sont considérablement améliorées en peu de temps. Mais cette information n’a été annoncée par Epoch AI qu’après la publication d’o3 le 20 décembre de l’année dernière.

Dès que la nouvelle est sortie, elle a immédiatement provoqué un tollé dans le cercle de l'IA, car il était difficile de ne pas faire douter les internautes qu'OpenAI était à la fois un arbitre et un joueur.
Avant de manger, vous devez fournir à vos amis inconnus les informations générales sur l'incident.
En décembre de l'année dernière, OpenAI a officiellement publié une nouvelle génération de modèle o3 qui prétend repousser les limites de l'IA.
Dans l'un des benchmarks mathématiques de l'IA (bilan) appelé FrontierMath, OpenAI est loin devant avec une précision de 25,2 %, dépassant de loin les moins de 2 % obtenus par des modèles tels que GPT-4 et Gemini.
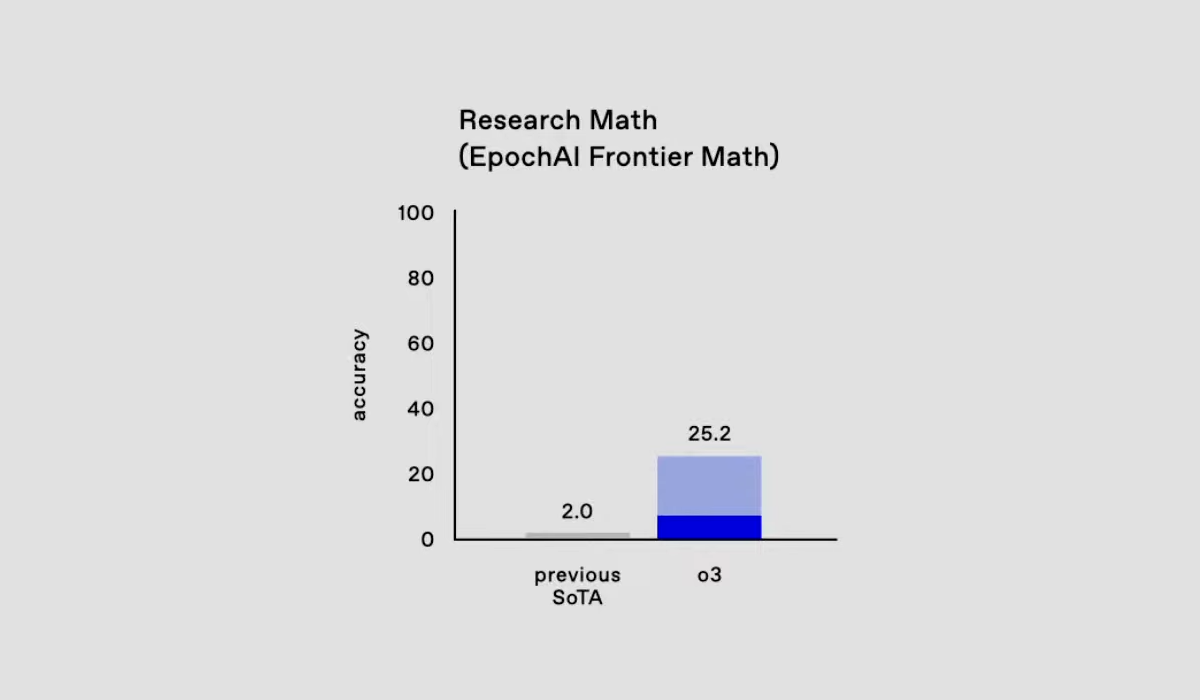
FrontierMath est une évaluation hautement pondérée des compétences avancées en raisonnement mathématique. Il a été construit conjointement par Epoch AI et plus de 60 mathématiciens de haut niveau, parmi lesquels plusieurs lauréats de la médaille Fields et des auteurs de propositions seniors de l'Olympiade mathématique internationale.
Le benchmark contient des centaines de problèmes mathématiques originaux et stimulants, couvrant plusieurs branches majeures des mathématiques modernes, telles que la théorie des nombres, l'analyse réelle, la géométrie algébrique, la théorie des catégories, etc.
Terence Teru, lauréat de la médaille Fields 2006 et génie mathématique, a un jour déclaré que les problèmes de FrontierMath sont « extrêmement difficiles » et estime que ces problèmes ne peuvent être résolus que par des experts du domaine. Il a noté que même pour des experts humains, résoudre ces problèmes prendrait des heures, voire des jours d’efforts.

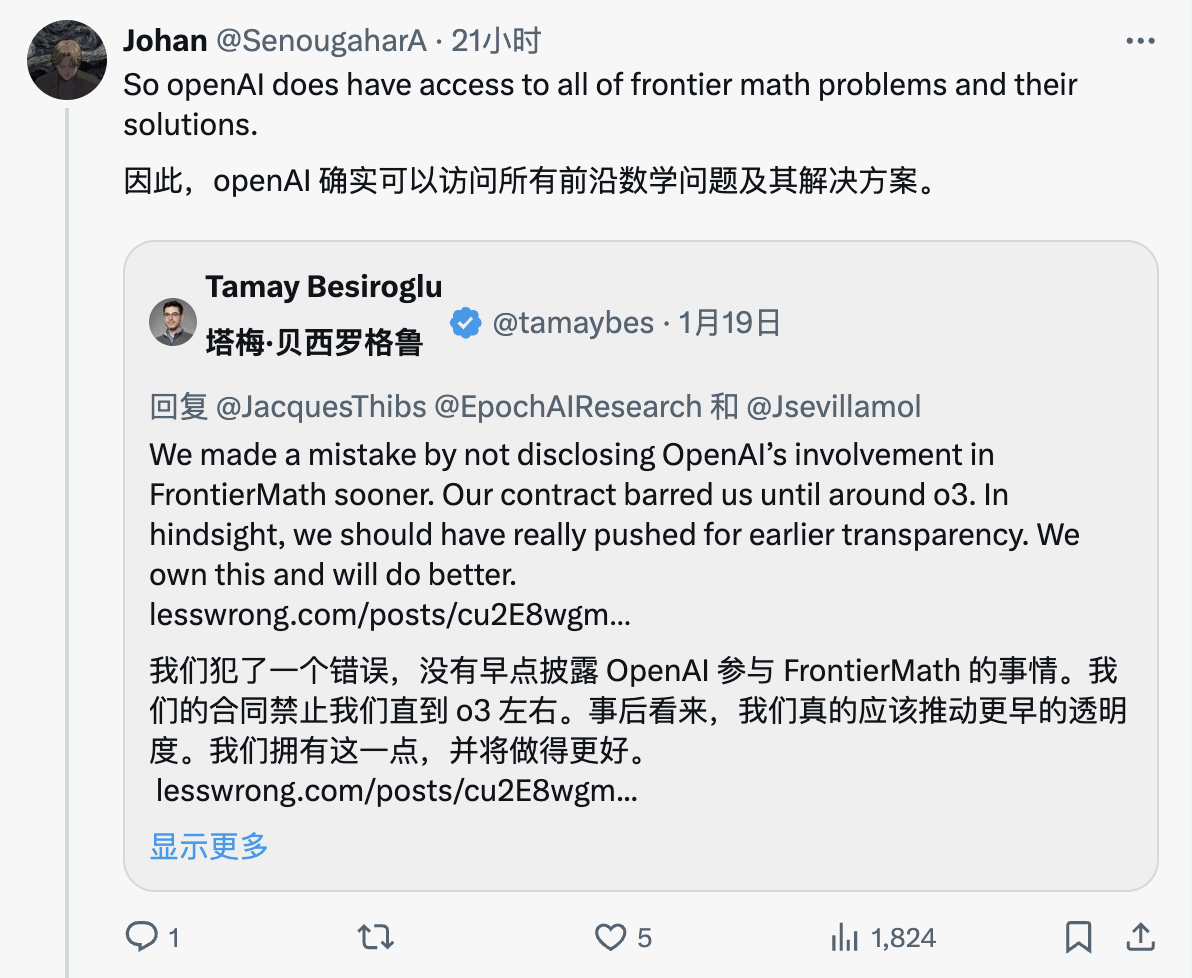
Ce bulletin montrait qu'o3 avait fait de grands progrès dans le raisonnement mathématique avancé, mais sa réputation s'est inversée après les révélations de l'entrepreneur. Face à la polémique, Tamay Besiroglu, directeur adjoint et co-fondateur d'Epoch AI, a rapidement reconnu l'affaire sur la plateforme X.
Nous avons commis une erreur en ne divulguant pas plus tôt l'implication d'OpenAI dans FrontierMath. Notre contrat nous interdit de le faire jusqu'à ce que o3 soit publié. Avec le recul, nous aurions vraiment dû insister davantage en faveur de la transparence plus tôt. Nous le reconnaissons et nous nous engageons à faire mieux à l’avenir.
La situation s'est encore aggravée lorsque Carina Hong, doctorante en mathématiques à l'Université de Stanford, a affirmé que dans le cadre d'Epoch AI, OpenAI avait un accès privilégié à FrontierMath.
« Six mathématiciens qui ont apporté des contributions significatives au benchmark FrontierMath m'ont confirmé qu'ils ignoraient qu'OpenAI aurait un accès exclusif au benchmark qui ne serait pas disponible pour les autres, et la plupart ont déclaré que s'ils l'avaient su à l'avance, ils l'auraient probablement fait. Je n’ai pas choisi de participer.

Face aux doutes, Tamay Besiroglu a également présenté ses excuses sur un blog et promis d'adopter des normes de transparence plus élevées à l'avenir.
Le blog souligne que le soutien financier d'OpenAI est limité au développement de FrontierMath et n'a pas interféré avec le contenu du test. Il indique également que toutes les données et questions proviennent de contributeurs indépendants et ont été examinées par des experts indépendants.
Concernant l'utilisation de la formation : nous reconnaissons qu'OpenAI a accès à la plupart des problèmes et solutions de FrontierMath, à l'exclusion de l'ensemble retenu auquel OpenAI n'a pas accès, ce qui nous permet de vérifier indépendamment la fonctionnalité du modèle. De plus, nous avons un accord verbal selon lequel ce matériel ne sera pas utilisé pour la formation des modèles.
Les communications publiques des employés d'OpenAI décrivent FrontierMath comme un ensemble d'évaluation « strictement réservé ». Bien que cette position publique soit conforme à notre compréhension, je voudrais en outre souligner que les laboratoires bénéficient grandement de disposer d’ensembles de données véritablement non contaminés.
OpenAI soutient également pleinement notre décision de conserver un ensemble de données distinct et non publié comme garantie supplémentaire pour éviter le surajustement et garantir une mesure précise des progrès. Depuis sa conception originale, FrontierMath a été positionné et présenté comme un outil d'évaluation, et nous pensons que les dispositions reflètent cet objectif.
[EDIT : Clarification de l'accès aux données d'OpenAI – ils n'ont pas accès à un ensemble de conservations distinct comme garantie supplémentaire pour une vérification indépendante. ]
Elliot Glazer, mathématicien en chef chez Epoch AI, a reconnu ne pas avoir divulgué de manière proactive des informations sur le financement de l'industrie pendant le projet et a présenté ses excuses aux mathématiciens qui n'auraient peut-être pas participé s'ils avaient été informés.
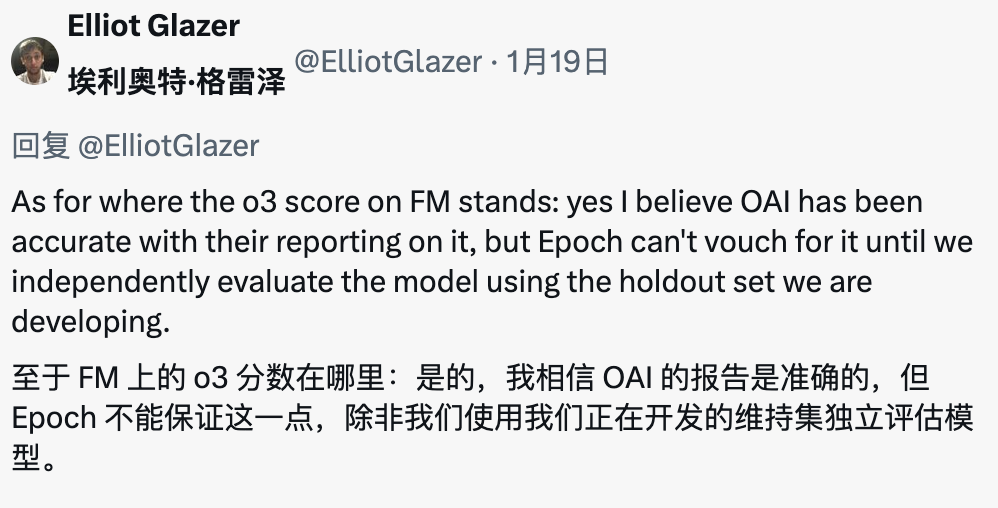
Concernant les scores o3, il a exprimé sa confiance dans l'exactitude des scores rapportés par OpenAI, mais a souligné qu'Epoch AI doit être vérifié par un ensemble de tests réservés indépendants en cours de développement, et a promis que les scores d'évaluation de l'ensemble réservé seraient rendus publics.
Interrogé sur le statut de l'ensemble réservé, Glazer a précisé que cet ensemble de test est toujours en développement et n'est pas terminé.
Cependant, ces explications n’ont pas réussi à apaiser la controverse autour de l’incident, et de nouvelles critiques ont afflué contre Epoch AI et OpenAI, qui étaient dans le tourbillon de l’opinion publique.
L'informaticien Subbarao Kambhampati a déclaré qu'il avait auparavant été sceptique quant aux affirmations d'OpenAI selon lesquelles elle n'avait pas accès auparavant aux données d'Olympiad Math et de FrontierMath. Selon lui, la pratique d’OpenAI consistant à interdire aux parties concernées de divulguer le contenu de l’accord est extrêmement suspecte.

Le célèbre expert en IA Gary Marcus a vivement critiqué cet incident.
Il a décrit la démonstration o3 d'OpenAI comme une « démonstration désespérée, manipulatrice, trompeuse et scientifiquement de mauvaise qualité » et a estimé qu'il s'agissait plus d'un battage médiatique excessif que d'une véritable avancée.
Une analogie frappante est que si quelqu’un obtient les questions et réponses du test à l’avance, alors que d’autres ne peuvent compter que sur leur force pour passer l’examen, une telle comparaison est évidemment injuste. Non seulement OpenAI a eu accès aux problèmes et aux solutions, mais d’autres concurrents tels que xai, DeepMind et les équipes académiques n’ont pas eu accès aux mêmes ressources.
Plus important encore, Gary Marcus estime qu’OpenAI ne dit rien sur ce fait de fond clé.
Et pendant le processus d'affichage, OpenAI a masqué de manière sélective les informations clés. Il n'a pas publié de cas de réussite ou d'échec sur des problèmes spécifiques, ni fourni d'enregistrements correspondants du processus de raisonnement, ni expliqué quels problèmes sont apparus dans l'ensemble de formation. Dans le même temps, ils n’ont pas permis à Epoch de valider sur l’ensemble de tests de résistance.

Le retour à cette agitation qui s’intensifie est en grande partie dû au fait que les internautes sont fatigués du battage médiatique sans fin d’OpenAI. Le comportement suspecté de « swiper le classement » a une fois de plus touché les nerfs sensibles de nombreux internautes.
Alors que l'opinion publique continue de fermenter, OpenAI a annoncé une avancée majeure dans son projet "Operator", le PDG Altman devrait donner un briefing à huis clos au gouvernement américain le 30 janvier.

Il est rapporté que « Operator » est un agent d'IA autonome doté de capacités de niveau doctorat développé par OpenAI. Il peut effectuer de manière indépendante des tâches dans le navigateur, telles que l'écriture de code, la réservation de voyages, la gestion des horaires, etc.
Bien sûr, à ce stade, la meilleure stratégie de relations publiques en cas de crise est peut-être de publier o3 immédiatement. Et c'est aussi le meilleur cadeau de la Fête du Printemps.
Au moment de mettre sous presse, OpenAI n’a fait aucune autre déclaration.
# Bienvenue pour suivre le compte public officiel WeChat d'Aifaner : Aifaner (ID WeChat : ifanr). Un contenu plus passionnant vous sera fourni dès que possible.
Ai Faner | Lien original · Voir les commentaires · Sina Weibo