
Le « petit canon en acier » national qui a renversé le GPT-4V du jour au lendemain pourrait être l’arme clé pour Huawei et Xiaomi pour lutter contre l’iPhone IA
Combien d’étapes faut-il pour mettre un grand modèle dans un téléphone mobile ?
Si 2023 est la première année de l'explosion de l'IA générative, alors divers fabricants sont parvenus cette année à un rare consensus : miser pleinement sur les grands modèles finaux.
En tant que nouvelle société d'IA spécialisée dans les « grands modèles efficaces », Wallface Intelligence montre à nouveau ses muscles aujourd'hui en lançant le modèle open source multimodal final le plus puissant, MiniCPM-Llama3-V 2.5.
- La performance globale multimodale finale la plus forte : surpassant les géants multimodaux Gemini Pro et GPT-4V
- Capacités OCR SOTA! Pixels 9 fois plus clairs, ce qui rend difficile la reconnaissance précise des images et des textes longs
- L'encodage des images est 150 fois plus rapide ! La première accélération multimodale au niveau du système côté extrémité

La troisième balle du « petit canon en acier » domestique est là, écrasant le GPT-4V
Tout comme les humains s’appuient sur leurs cinq sens pour explorer le monde, les capacités multimodales sont une étape incontournable dans l’évolution de l’IA.
Avec seulement un modèle final 8B, MiniCPM-Llama3-V 2.5, qui est « grand avec petit », a obtenu un score de 65,1 sur la plateforme d'évaluation OpenCompass. Non seulement il est comparable au modèle à source fermée Qwen-VL-Max, mais il est également comparable à celui-ci. les performances globales battent également les poids lourds GPT-4V et Gemini Pro.
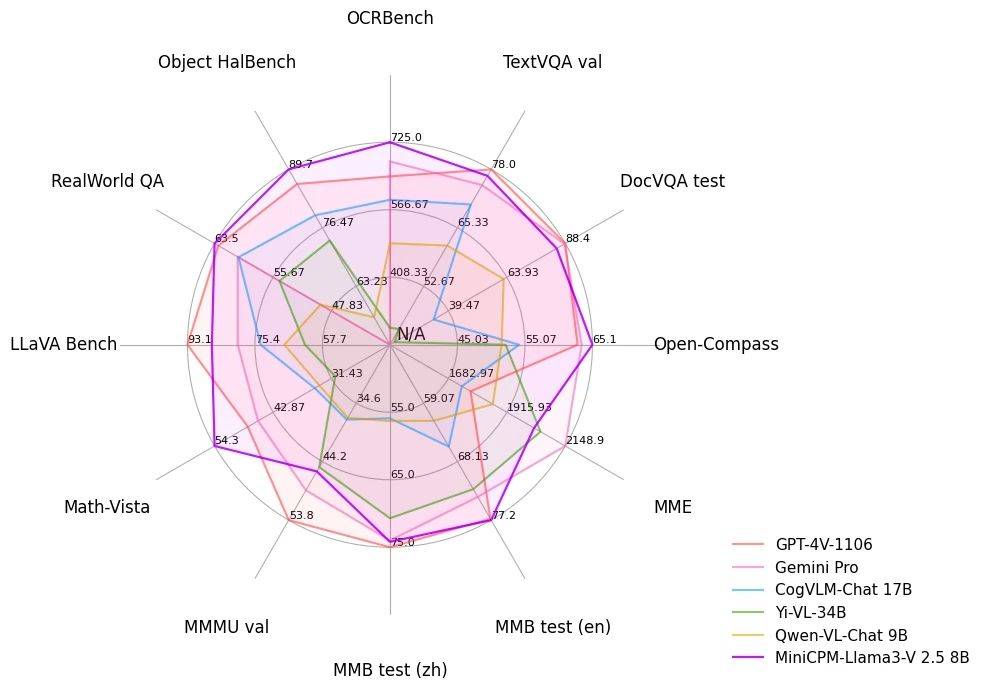
Dans le test de référence complet de l'OCR (Optical Character Recognition), MiniCPM-Llama3-V 2.5 a obtenu un score de 725 points, dépassant largement le GPT-4V et surpassant les modèles saute-mouton tels que Claude 3V Opus.
La capacité d'halluciner est le problème le plus tenace qui frappe les grands modèles en peu de temps. MiniCPM-Llama3-V 2.5 a également amélioré ce problème.
Comme le reflète le test de référence Object HalBench, son taux d'hallucinations a fortement chuté, passant de 14,5 dans MiniCPM-V 2.0 (2B) à 10,3, dépassant une fois de plus GPT-4 V et LLaVA-NeXT-34B.
Le benchmark RealWorldQA est un test de la compréhension d’un modèle de la réalité.
MiniCPM-Llama3-V 2.5 a fourni une feuille de réponses de 63,5, juste derrière InternVL-Chat-V1.5 (26B), mais surclassé toujours GPT-4V et Gemini Pro.
S'appuyant sur la technologie d'encodage efficace des images haute définition auto-développée, MiniCPM-Llama3-V 2.5 prend en charge l'encodage efficace et la reconnaissance sans perte de 1,8 million d'images de pixels haute définition, et prend en charge n'importe quel rapport d'aspect, même l'image au rapport extrême de 1:9. . Pour cela, c’est juste du gâteau.

« Être capable de voir » n'est que le début, ce qui est plus important est de savoir « penser ». MiniCPM-Llama3-V 2.5 élève les capacités de raisonnement complexes à un nouveau niveau.

Les responsables ont déclaré que, étant donné l'exemple d'un bâtiment artistique gravé de citations célèbres du "Problème à trois corps", un grand modèle général ne peut décrire que grossièrement le modèle de l'image, mais MiniCPM-Llama3-V 2.5 peut l'associer à "Le problème des trois corps". Problème à trois corps" basé sur les informations reconnues. "livres.
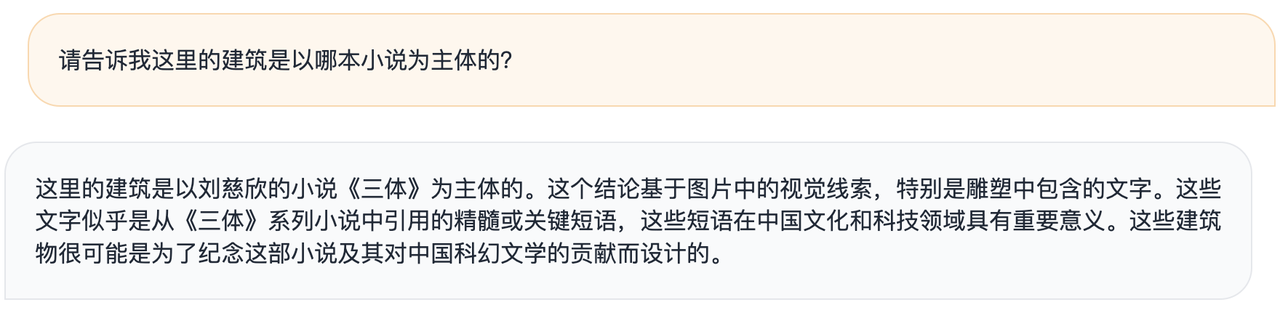
▲MiniCPM-Llama3-V 2.5

▲GPt-4V
Vous pouvez également donner votre propre avis : ces bâtiments ont probablement été conçus pour commémorer le roman et sa contribution à la littérature de science-fiction chinoise.
Ou donnez-lui une version anglaise de la pyramide alimentaire asiatique, et il pourra instantanément se transformer en nutritionniste personnel et personnaliser les recettes de la semaine.

Si vous êtes trop paresseux pour lire de longs articles, laissez MiniCPM-Llama3-V 2.5 s'en charger, puis posez des questions, il donnera des réponses le plus rapidement possible.
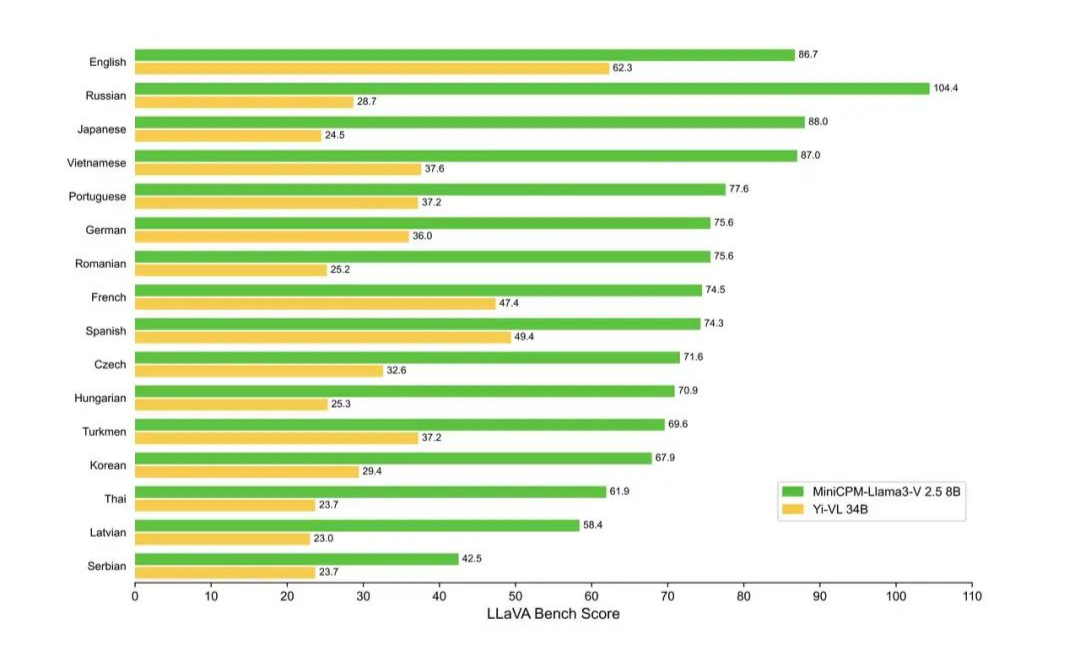
Désormais, MiniCPM-Llama3-V 2.5 prend en charge plus de 30 langues, couvrant l'allemand, le français, l'espagnol, l'italien, le russe et d'autres langues courantes. Les langues des pays situés le long de la Ceinture et de la Route sont essentiellement à portée de main.
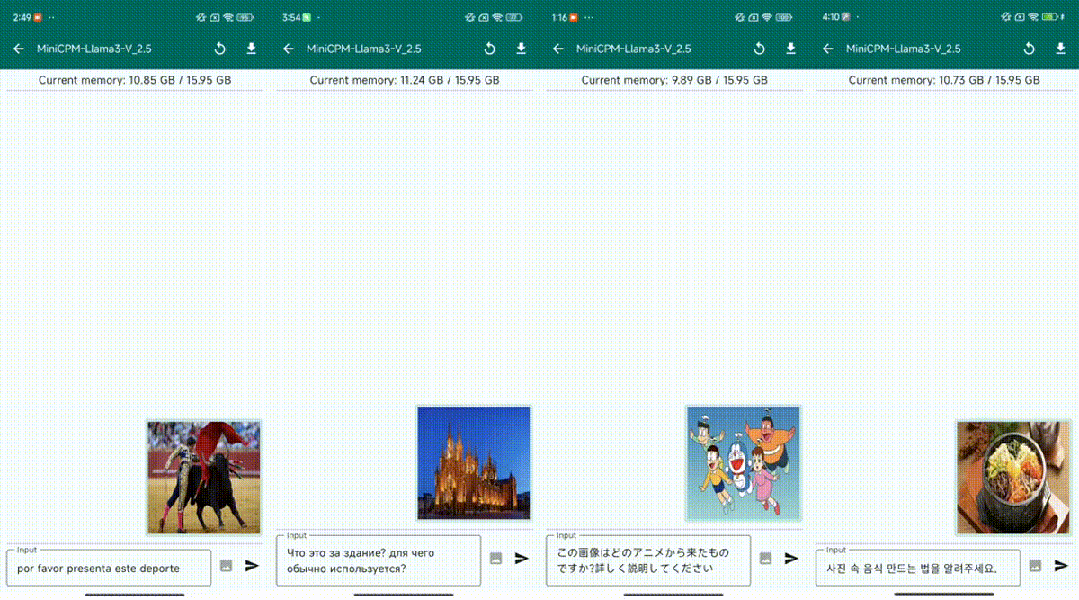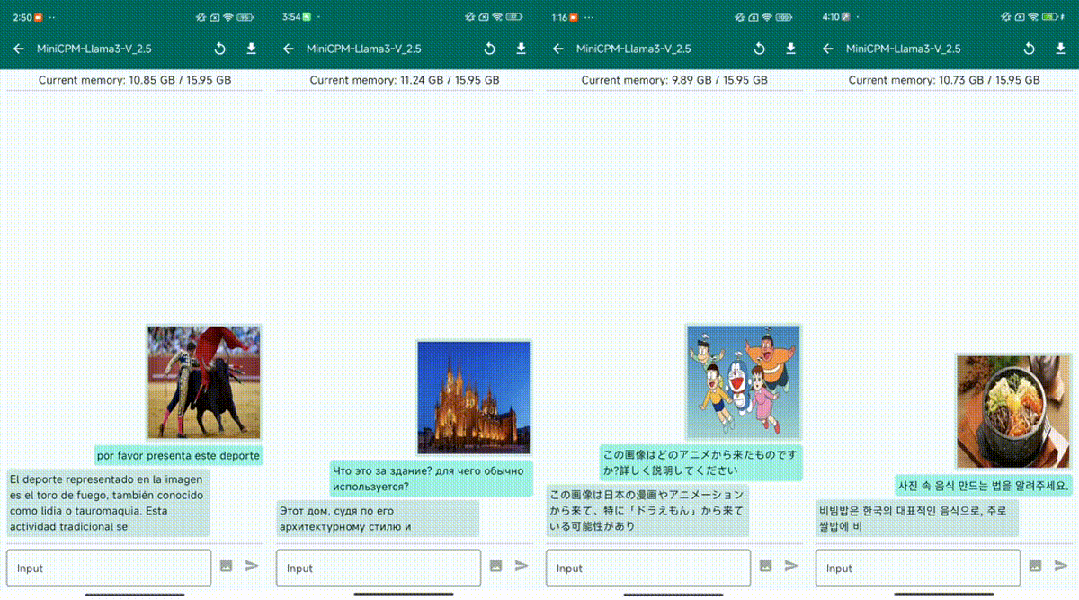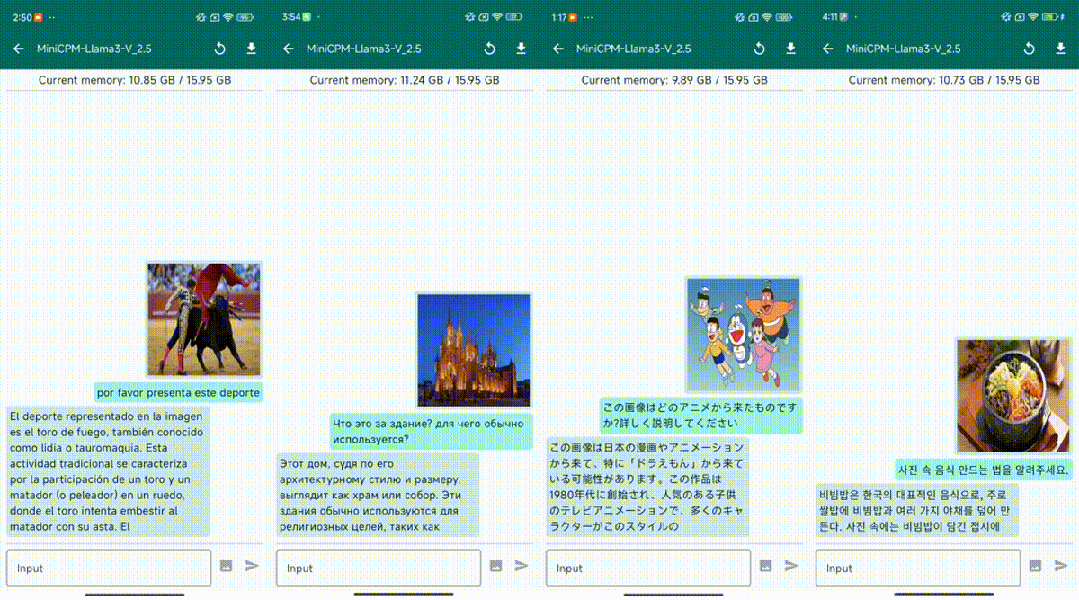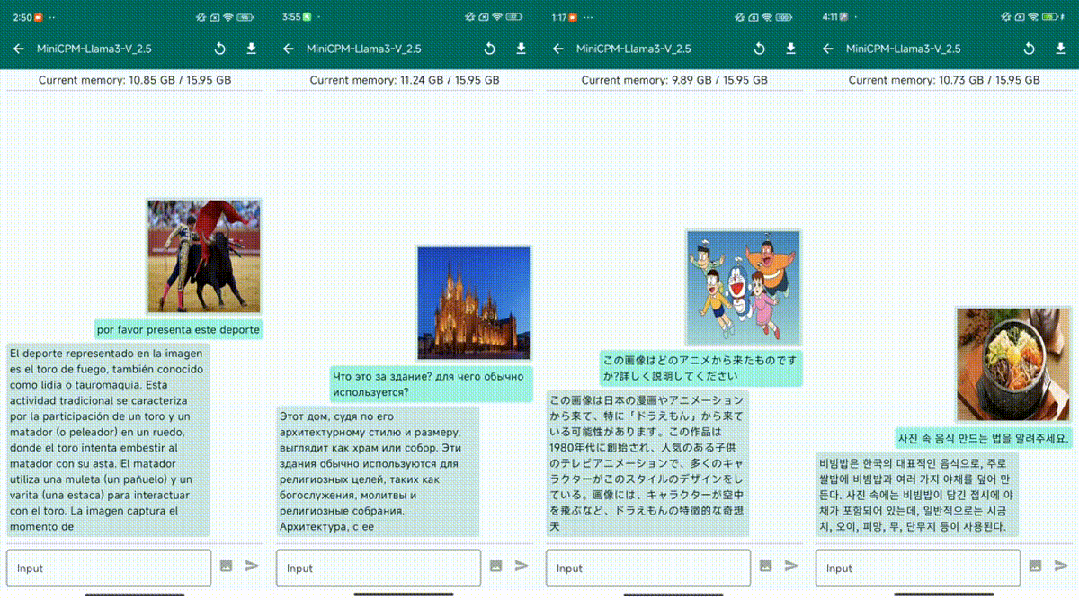
Il convient de noter que MiniCPM-Llama3-V 2.5 est en fait un modèle affiné basé sur le modèle open source Llama3-8B-Instruct.
Dans le passé, laisser l'IA traiter différentes informations telles que des images et du texte en même temps et à une vitesse rapide était un gros problème. Cependant, Wall-Facing Intelligence adopte un cadre d'accélération NPU, spécialement conçu pour accélérer le traitement. traitement des images, permettant à l’IA de fonctionner plus efficacement sur les téléphones mobiles.
Selon l'introduction officielle, le revêtement mural ne peut effectuer que pour la première fois une accélération du système côté extrémité. Actuellement, MiniCPM-Llama3-V 2.5 a été déployé efficacement sur les téléphones mobiles et a atteint une accélération de 150 fois dans l'encodage des images.
Par exemple, la vitesse de décodage du modèle de langue Llama 3 sur le téléphone mobile est d'environ 0,5 jeton/s, tandis que le modèle multimodal MiniCPM-Llama3-V 2.5 a amélioré la vitesse de décodage de la langue sur le téléphone mobile à 3 grâce à une optimisation multiple. méthodes telles que CPU -4 jeton/s.
Ci-joint l'adresse open source MiniCPM-Llama3-V 2.5 :  https://github.com/OpenBMB/MiniCPM-V
https://github.com/OpenBMB/MiniCPM-V
Le modèle côté appareil, un champ de bataille pour les fabricants de téléphones mobiles
Au cours des deux dernières années, les modèles côté appareil sont fréquemment apparus dans les PPT vocaux des principaux fabricants de terminaux.
Les modèles dits end-side sont des modèles d’intelligence artificielle qui s’exécutent sur des terminaux. Ces modèles sont généralement conçus pour être suffisamment légers pour s'adapter aux contraintes de puissance de calcul et de ressources du périphérique final.
Après la mise en ligne de GPT-4, "AI Godfather" Geoffrey Hinton a souligné un jour que je pense qu'il y aura une étape où nous nous entraînerons sur des ordinateurs dotés d'une grande puissance de calcul. Une fois le modèle formé, il pourra être exécuté sur des appareils à faible consommation. .
La caractéristique du modèle end-side est qu'il peut fonctionner côté appareil (tels que les smartphones, les systèmes embarqués, etc.) pour traiter les données et prendre des décisions sans envoyer les données à un serveur distant.
En brisant les mots ci-dessus, nous pouvons découvrir les avantages du modèle final :
- Exécution locale : le modèle s'exécute localement sur l'appareil sans recourir à un serveur distant.
- Traitement en temps réel : possibilité de traiter les données en temps réel sur l'appareil, offrant une réponse rapide.
- Faible latence : étant donné que les données n'ont pas besoin d'être transférées entre l'appareil et le serveur, leur latence est plus faible.
- Protection de la vie privée : les données sont traitées localement, ce qui réduit le risque de fuite de données et améliore la protection de la vie privée.
- Indépendance du réseau : le modèle final fonctionne même sans connectivité réseau.
- Optimisation des ressources : le modèle final doit généralement être optimisé pour s'adapter aux ressources informatiques et à l'espace de stockage limités du terminal.
- Applicable à une variété d'appareils : le modèle côté client peut être déployé sur différents types de terminaux, y compris, mais sans s'y limiter, les smartphones, les appareils domestiques intelligents, les appareils portables, etc.
- Miniaturisation et optimisation : les modèles peuvent devoir subir une compression, un élagage, une quantification et d'autres processus techniques pour réduire la taille du modèle et améliorer l'efficacité opérationnelle.
Bien entendu, le grand modèle côté client et le grand modèle cloud sont synergiques et ne sont pas le produit d’une opposition.
On voit donc que si les grands modèles comme Llama 3 et Claude se développent à plein régime, la recherche sur les modèles end-side n'est pas en reste.
Le scientifique NVIDIA JImFan a souligné que le dernier GPT-4o est très probablement un petit modèle distillé et que les avantages sont évidents : plus raffinés et plus efficaces.
Qu'il s'agisse du Phi-3 lancé par Microsoft le mois dernier, de la série de petits canons en acier performants publiée par Wallface Intelligence ou de la série de modèles OpenELM récemment annoncée par Apple comme open source, de nouveaux modèles de petite taille sont constamment lancés.

2024 est une année critique pour la mise en œuvre des applications d’IA, et les modèles côté appareil prennent également de l’ampleur et se préparent à briller cette année.
Il est incontestable que la plupart des innovations actuelles en matière de terminaux ont atteint une période de goulot d'étranglement. Prenons l'exemple des téléphones portables qui « poussent » sur notre corps. Le sentiment de surprise et d'innovation lorsque Steve Jobs a sorti l'iPhone s'est depuis longtemps perdu dans le long fleuve du temps.
La proposition d'innovation de terminaux basée sur l'IA, qu'elle soit plus un gadget que la réalité ou qu'elle utilise la technologie du futur pour « accorder de l'argent » au présent, peut en fait libérer davantage l'imagination d'appareils tels que les téléphones mobiles et devenir un point clé à briser. le jeu.

C'est dans le cadre de cette tendance que le modèle côté appareil n'est plus seulement un concept resté dans les discussions théoriques ou les brochures des fabricants. Il a commencé à pénétrer progressivement dans notre vie quotidienne.
Lors de la conférence HamonyOS 4 en août de l'année dernière, Yu Chengdong a annoncé la capacité de l'assistant intelligent Xiaoyi à accéder à de grands modèles d'IA. Immédiatement après, Lei Jun a révélé que Xiaomi avait utilisé un grand modèle avec 1,3 milliard de paramètres sur son téléphone mobile et que les effets de certaines scènes étaient comparables à ceux du cloud.
Aucun des téléphones portables nationaux « Yuwujia » n'a été laissé pour compte. L'assistant OPPO Xiaobu basé sur AndersGPT, Honor Magic 6 équipé d'un grand modèle AI côté terminal 7B et Vivo équipé d'une matrice grand modèle Blue Heart ont également été officiellement annoncés l'un après l'autre.
Aux petites heures de ce matin, le journaliste de Bloomberg, Mark Gurman, a annoncé qu'Apple améliorerait la fonction vocale de Siri pour la rendre plus conversationnelle et ajouterait des fonctions pour aider les utilisateurs à gérer la vie quotidienne, notamment :
- Résumer automatiquement les notifications iPhone
- Résumer les articles de presse
- Transcrire des mémos vocaux
- Améliorez les fonctionnalités existantes pour remplir automatiquement les calendriers et recommander des applications
- Édition de photos par l'IA
Quant à l'assistant vocal principal Siri, il sera probablement étroitement lié au modèle côté appareil d'OpenAI ou de Gemini à l'avenir.
Bien que le populaire matériel d'IA Rabbit R1 soit considéré comme étant un shell Android, ce qu'il a montré lors de la conférence de presse est également un profil de l'état idéal d'un téléphone AI – un système sans barrières entre les applications et une interaction fluide.

Cependant, cette situation ne se produit pas du jour au lendemain. Si l'assistant vocal IA peut vraiment comprendre les utilisateurs et planifier des applications comme prévu, cela bouleversera non seulement complètement l'expérience utilisateur, mais devrait également changer la relation entre les fabricants de téléphones mobiles et les tiers. -développeurs d'applications de fête.
Par exemple, il a été rapporté qu'Apple, qui a toujours été fermé, a commencé à s'ouvrir activement face à ce torrent de changements technologiques.
Selon Ben Reitzes de Melius Research, Apple devrait lancer une boutique dédiée aux applications d'IA lors de la prochaine WWDC. Il s'agit non seulement d'un tournant important dans la stratégie ouverte d'Apple, mais aussi d'un signal clair de sa transformation stratégique à l'ère de l'IA.
Cela montre également qu'Apple essaie de créer plus de valeur pour les développeurs et les utilisateurs en créant un écosystème d'IA ouvert, tout en gagnant un espace de marché plus large pour lui-même.
Plus près de chez nous, les modèles finaux tels que le MiniCPM-Llama3-V 2.5 ont prouvé leur force : le modèle n'a pas seulement « plus les paramètres sont grands, meilleures sont les performances », mais peut exploiter les performances les plus élevées avec les plus petits paramètres !
Dans le même temps, entrer dans la vie n'est que la première étape. Lorsque le parcours des données est réduit à zéro, le modèle côté appareil permet à l'IA de réagir une étape plus rapidement que la pensée humaine, ce qui pourrait signifier que le prochain printemps des appareils terminaux aura lieu. vraiment arrivé.
D’ici là, chaque interaction entre les utilisateurs et les produits finaux déclenchera un son involontaire « wow ».
# Bienvenue pour suivre le compte public officiel WeChat d'aifaner : aifaner (ID WeChat : ifanr). Un contenu plus passionnant vous sera fourni dès que possible.
Ai Faner | Lien original · Voir les commentaires · Sina Weibo