
Le plus gros scandale dans le cercle de l’IA cette année a été révélé ! Llama 4 a été dénoncé comme tricheur lors de l’entraînement, le test a lamentablement échoué et le personnel principal a démissionné avec colère.

Hier, Meta Llama 4 est sorti à l'improviste.
Les paramètres sur papier sont très élevés. On dit qu’il s’agit d’un modèle MOE multimodal natif, battant DeepSeek V3, et d’une bête de 2 000 milliards de paramètres. Même le PDG de Meta, Zuckerberg, a posté une vidéo, agitant le drapeau et criant pour souhaiter la bienvenue à "Llama 4th".
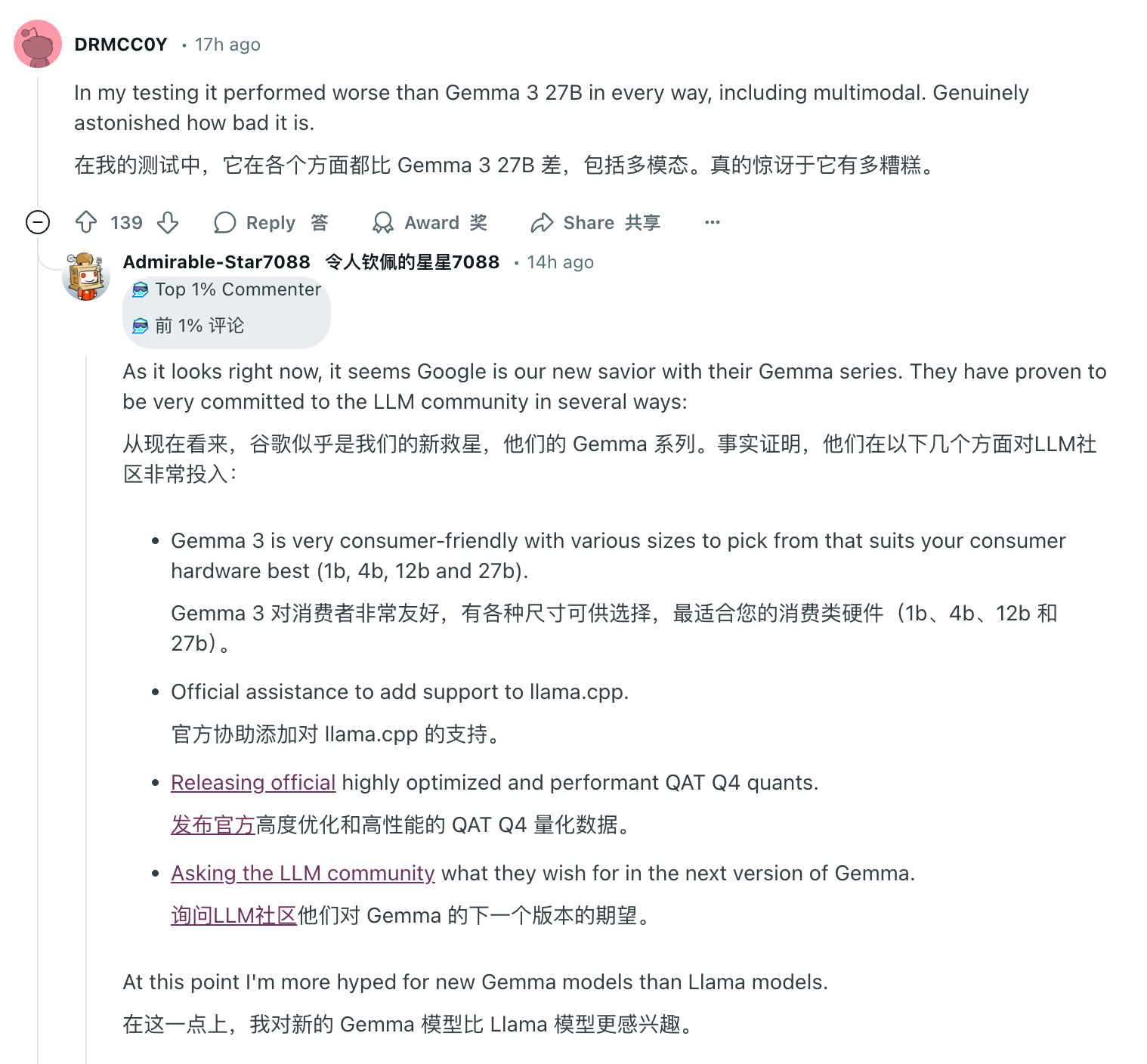
Les acclamations furent de courte durée. Lorsque les internautes ont commencé à tester, ils ont reçu des critiques presque majoritairement négatives. On peut l'appeler le plus grand événement « rollover » de l'industrie de l'IA cette année.
Dans la communauté r/LocalLLaMA (que l'on peut comprendre comme « post bar » de Llama) dédiée au déploiement local de grands modèles de langage, un article intitulé « Je me sens incroyablement déçu par Llama 4 » a rapidement attiré beaucoup d'attention et de résonance.
Il y a même des fans fidèles de Llama qui ont brisé la défense et ont déclaré sans ambages qu'il était temps de renommer "LocalLLaMA" en "LocalGemma". Se moquer de la sortie de Llama 4 ressemble plus à une blague tardive du poisson d'avril.

Le test lui-même a montré que les produits n'étaient pas corrects et il a été révélé que Llama 4 était fou de "répondre aux questions" avant la sortie.
Dans cet article original sur Reddit, l'internaute Karminski déconseille fortement d'utiliser Llama 4 pour l'encodage.
Il a déclaré que Llama-4-Maverick – un modèle avec un paramètre total de 402B – peut à peine égaler Qwen-QwQ-32B en termes de capacités d'encodage. Les performances de Llama-4-Scout (modèle avec paramètres totaux 109B) sont à peu près similaires à celles de Grok-2 ou Ernie 4.5.
En fait, selon les derniers résultats de référence en matière d’encodage polyglotte, Llama 4 Maverick n’a obtenu qu’un score de 16 %.
Ce benchmark est conçu pour évaluer les performances des grands modèles de langage (LLM) dans les tâches de programmation multilingues, couvrant six langages de programmation courants C++, Go, Java, JavaScript, Python et Rust.
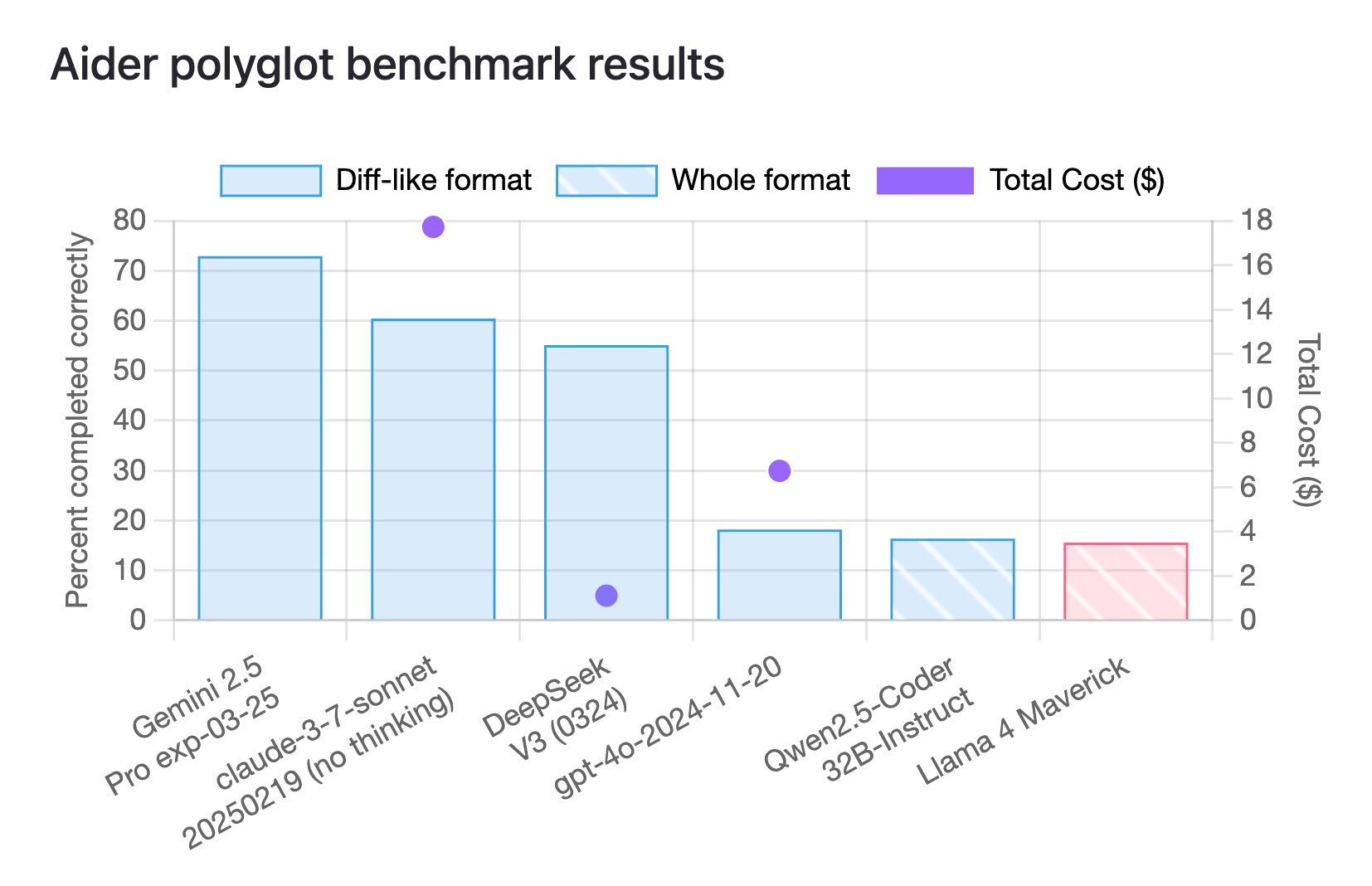
Et ce score se situe également au niveau le plus bas parmi de nombreux modèles.
Le blogueur @deedydas a également exprimé sa déception face à Llama 4, le qualifiant de « modèle de programmation épouvantable ».
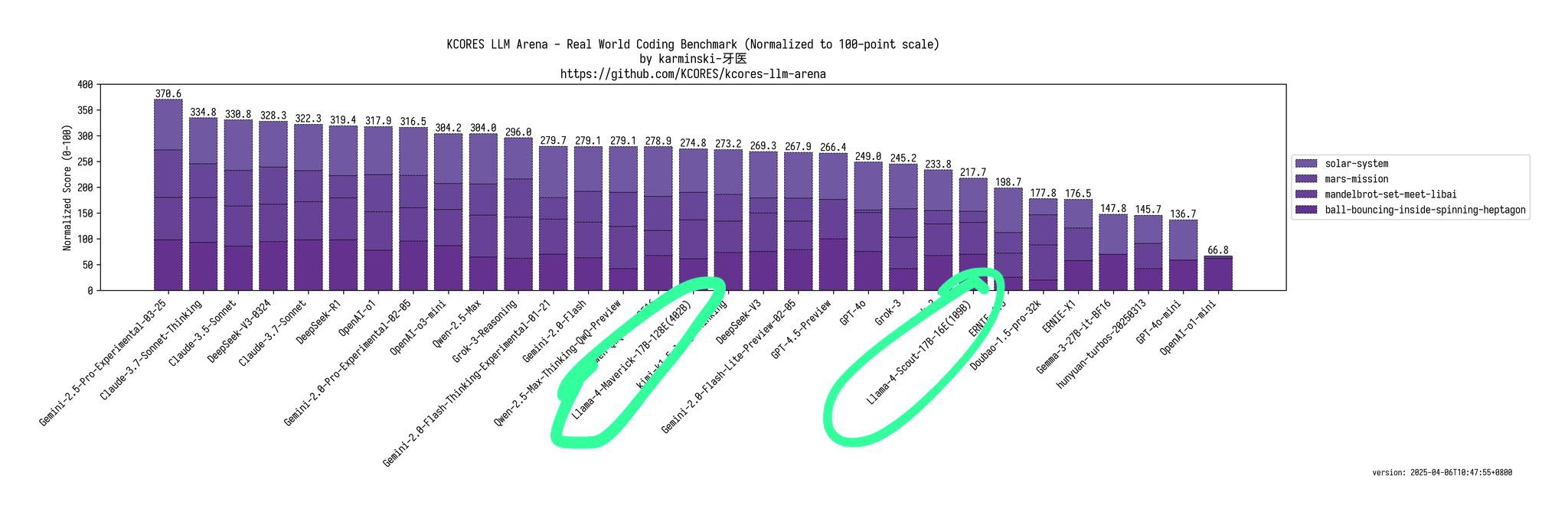
Il a souligné que Scout (109B) et Maverick (402B) ont des performances bien pires que 4o, Gemini Flash, Grok 3, DeepSeek V3 et Sonnet 3.5/7 dans le test de référence Kscores pour les tâches de programmation.
Un autre internaute, Flavio Adamo, a demandé à Llama 4 Maverick et GPT-4o de générer une animation d'une petite balle rebondissant dans un polygone en rotation, et la balle doit suivre l'influence de la gravité et de la friction pendant le processus de saut.
Les résultats montrent que la forme polygonale générée par Llama 4 Maverick manque d'ouvertures et que le mouvement de la balle viole également les lois de la physique. En comparaison, les performances de la nouvelle version de GPT-4o sont nettement meilleures et les performances de Gemini 2.5 Pro sont reines.

En janvier de cette année, Zuckerberg a également affirmé que l'IA atteindrait le niveau de programmation d'un ingénieur logiciel intermédiaire. La mauvaise performance actuelle de Llama 4 est en effet une gifle un peu rapide.
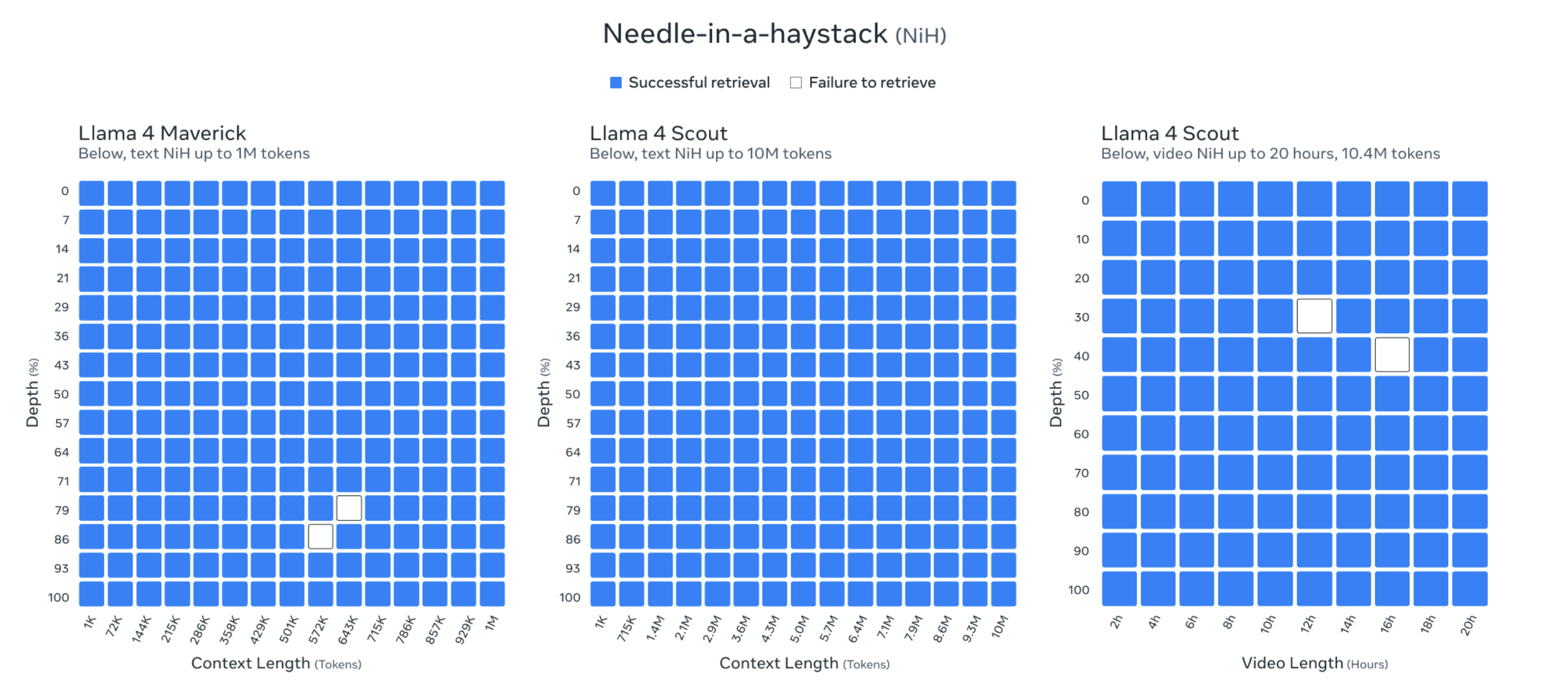
De plus, la longueur du contexte de Llama 4 Scout atteint 10 millions de jetons. Cette longueur de contexte extrêmement longue permet à Llama 4 Scout de traiter et d'analyser des contenus textuels extrêmement longs, tels que des livres entiers, de grandes bibliothèques de codes ou des archives multimédias.
Les responsables du Meta ont même montré les résultats du test « Trouver une aiguille dans une botte de foin » pour prouver ses capacités.
Cependant, selon les derniers résultats de Fiction.LiveBench, l'effet du modèle Llama 4 est également médiocre et inutile, et l'effet global n'est pas aussi bon que celui de Gemini 2.0 Flash, tandis que Gemini 2.5 Pro est toujours le roi bien mérité du texte long.
+1 pour Oita sur Google.
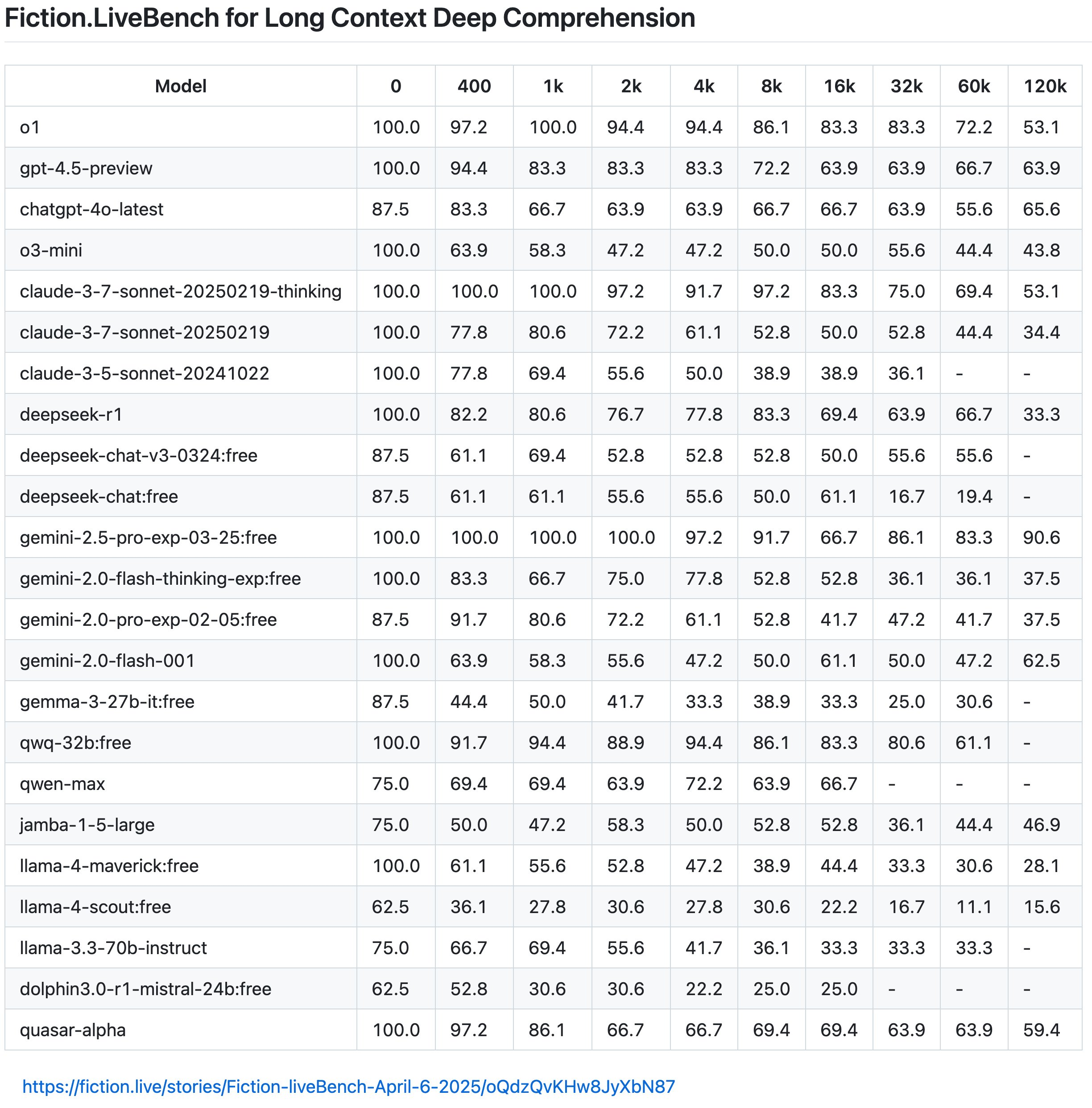
L'internaute Karminski a en outre souligné que Llama 4 est tombé en dessous de 60 % lorsque le taux de rappel du contexte est de 1K (approximativement compris comme le taux correct de réponses aux questions), et même Llama-4-Scout n'a que 22 % lorsqu'il dépasse 16K.
Il a également donné un exemple frappant : « La longueur du texte de « Harry Potter à l'école des sorciers » est d'environ 16 Ko.
Cela signifie que si vous saisissez le livre entier dans le modèle et demandez ensuite « Est-ce qu'Harry vivait dans la chambre ou dans le débarras sous les escaliers quand il était enfant ? », Llama-4-Scout n'obtiendra la bonne réponse que 22 % du temps (compréhension approximative, le mécanisme de rappel réel est plus compliqué). Et ce résultat est naturellement bien inférieur au niveau moyen du modèle de tête.
Non seulement le modèle lui-même est légèrement étiré, mais le halo de Llama 4 en tant que « leader de l’open source » s’estompe également progressivement.
Meta ouvre les poids de Llama 4, mais même en utilisant la quantification, il ne peut pas fonctionner sur des GPU grand public. On dit qu’il fonctionne sur une seule carte, mais il fait en réalité référence au H100. Le seuil élevé est plutôt hostile aux développeurs.
De plus, la nouvelle licence de Llama 4 comporte plusieurs restrictions, la plus critiquée étant que les entreprises comptant plus de 700 millions d'utilisateurs actifs mensuels doivent demander une licence spéciale à Meta, que Meta peut décider à sa propre discrétion d'approuver ou de refuser.

Attendez, ce n’est pas ce que disent les paramètres papier annoncés hier par Meta. Pourquoi, un jour plus tard, la direction du vent a complètement changé.
Dans le classement Arena des grands modèles, Llama 4 Maverick s'est classé deuxième du classement général, devenant ainsi le quatrième modèle à dépasser les 1 400 points. Il arrive en tête de liste parmi les modèles open source, surpassant DeepSeek V3.
Face au fait que les performances mesurées n’étaient « pas correctes », les internautes attentifs ont vite senti quelque chose de louche. Maverick, qui a obtenu des scores élevés dans LM Arena, a en fait utilisé une « version de chat expérimentale ».

Ce n’est pas encore fini. L’article d’aujourd’hui sur la communauté One Acre Three-Quart Land semble avoir révélé quelques histoires intérieures. Il a été rapporté qu'après des entraînements répétés, Llama 4 n'a pas réussi à obtenir le SOTA open source, et en était même loin.
La date limite fixée en interne par Meta Company pour la sortie est fin avril.
Par conséquent, la direction de l'entreprise a suggéré de mélanger les ensembles de tests de différents benchmarks dans le processus post-formation, dans l'espoir de parvenir à une fertilisation croisée sur divers indicateurs. Trouvez un résultat qui « a l'air bien ».
Le mélange des ensembles de tests de différents benchmarks dans le processus post-formation mentionné ici signifie que dans la phase post-formation du modèle, en mélangeant des ensembles de données de différents benchmarks, le modèle peut apprendre dans une variété de tâches et de scénarios, améliorant ainsi sa capacité de généralisation.
Pour utiliser une analogie simple, c’est comme tricher à un examen. Les questions du test étaient censées être sélectionnées au hasard dans une banque de questions confidentielles (ensemble de tests de référence), et personne ne le savait avant le test. Mais si quelqu'un jette un coup d'œil aux questions à l'avance et les pratique à plusieurs reprises (ce qui équivaut à mélanger l'ensemble du test avec une formation), il réussira certainement à l'examen.
L'affiche expliquait en outre qu'après la sortie de Llama 4, les résultats réels des tests avaient été critiqués par les internautes de X et de Reddit. En tant que personne travaillant actuellement dans le milieu universitaire, il a affirmé qu'il ne pouvait vraiment pas accepter l'approche de Meta. Il avait soumis sa demande de démission et avait explicitement demandé que son nom soit retiré du rapport technique de Llama 4.
Il a également déclaré que le vice-président de l’IA de Meta avait également démissionné pour cette raison. Il y a quelques jours, on rapportait que la directrice de la recherche Meta AI, Joelle Pineau, avait annoncé qu'elle quitterait son poste le 30 mai.

Cependant, davantage de preuves pourraient être nécessaires quant à la véracité de cette prétendue accusation de « tricherie sur liste ». Un employé de Meta nommé LichengYu a également répondu avec son vrai nom dans la zone de commentaires :
"Au cours des deux derniers jours, j'ai écouté humblement les commentaires de toutes les parties (tels que le codage, l'écriture créative et d'autres défauts qui doivent être améliorés) et j'espère m'améliorer dans la prochaine version. Cependant, nous n'avons jamais surajusté l'ensemble de test afin de rafraîchir les points. Le vrai nom est Licheng Yu. J'ai géré la post-formation de deux modèles d'oss. Veuillez me dire quelle invite a été sélectionnée dans l'ensemble de test et insérée dans l'ensemble de formation. Je vous présenterai + mes excuses !"

Les informations publiques montrent que Licheng Yu est diplômé de l'Université Jiao Tong de Shanghai, a obtenu une double maîtrise du Georgia Institute of Technology et de l'Université Jiao Tong de Shanghai en 2014 et a obtenu un doctorat en informatique de l'Université de Caroline du Nord à Chapel Hill en mai 2019.
Ses domaines de recherche se concentrent sur la vision par ordinateur et le traitement du langage naturel, et de nombreux articles ont été acceptés par de grandes conférences telles que CVPR, ICLR, ECCV et KDD.
Licheng Yu a travaillé dans de grandes entreprises telles que Microsoft et Adobe. Il est actuellement directeur des recherches scientifiques de Meta (2023.06 à aujourd'hui). Il a participé à la sortie du modèle multimodal Llama3.2 (11B+90B) et a dirigé la phase d'apprentissage par renforcement texte + image des 17Bx128 et 17Bx16 dans le projet Llama 4.
Il est difficile de dire si c’est vrai ou non, et peut-être que cela permettra aux balles de continuer à voler encore un peu.
Le « trône » des grands modèles open source ne peut pas être saisi par la force brute
À la même époque l'année dernière, Meta a été saluée comme l'élu de l'industrie de l'IA.
Bien sûr, après avoir enlevé son simple T-shirt gris, son jean et son sweat à capuche, Zuckerberg a également commencé à porter fréquemment des vêtements de marque avec de grands logos, à accrocher de grandes chaînes en or brut autour de son cou, et a même montré avec confiance ses résultats de fitness en public.
Zuckerberg, qui n'est pas intéressé par la boisson, tente de se rapprocher du public en montrant un côté plus « réel » et « terre-à-terre ». Cela donne non seulement à Meta une apparence plus conviviale, mais en fait également le porte-drapeau open source du modèle open source d'OpenAI, avec un élan sans précédent.

Dans le même temps, la forte force de Meta constitue un soutien solide pour la transformation. Il est rapporté que Meta prévoit d'investir jusqu'à 65 milliards de dollars américains en 2025 pour développer son infrastructure d'IA, ce qui représente une somme importante dans l'industrie. D’ici fin 2025, Meta prévoit de disposer de plus de 1,3 million de GPU.
Deuxièmement, Meta dispose d’abondantes données sur les plateformes sociales, ce qui lui confère des avantages uniques en matière de recherche et de développement en IA.
En tant que société mère de plateformes sociales de renommée mondiale telles que Facebook, Instagram et WhatsApp, Meta dispose de données sur les interactions quotidiennes de milliards d'utilisateurs. Selon les statistiques, le nombre d'utilisateurs actifs quotidiens (DAU) mondiaux de sa plateforme dépassera les 3 milliards en 2024. Cet énorme volume de données fournit d'énormes matières premières pour la formation de modèles d'IA.
De plus, Meta n’est pas moins généreuse dans son vivier de talents. Le chef de son département IA est Yann LeCun, prestigieux lauréat du prix Turing du secteur. Sous sa direction, Meta a adhéré à la stratégie open source et a lancé la série de modèles Llama.
Par conséquent, Meta est également très ambitieux – il veut non seulement consolider sa position dans le domaine social, mais espère également réaliser des dépassements de virage dans le domaine de l'IA, dans le but de surpasser des concurrents puissants tels qu'OpenAI d'ici la fin de 2025.

Mais je l'ai vu construire un Zhulou, je l'ai vu recevoir des invités et j'ai vu sa tour s'effondrer.
Si la nouvelle de One Third Acre est vraie, il peut y avoir une « tricherie » dans le processus de développement de Llama 4 à la recherche des résultats des tests de référence – en mélangeant l'ensemble de tests avec les données de formation, cela ressemble plus à une déformation opérationnelle sous « l'anxiété du trafic de l'IA ».
Au début de l'année, on a appris que DeepSeek avait fait paniquer l'équipe Meta AI :
"Lorsque le salaire de chaque cadre de l'organisation d'IA générative est supérieur au coût de formation de l'ensemble de DeepSeek-V3, et que nous avons des dizaines de ces cadres, comment feront-ils face à la haute direction ?"
En 2023, Meta a établi un quasi-monopole dans le domaine des grands modèles open source avec la série Llama, devenant ainsi synonyme et référence de l'IA open source.
Or, un jour pour l’IA et un an pour les êtres humains. Dans la zone de commentaires où Llama 4 a rencontré "Waterloo", les éloges d'autres modèles open source peuvent être vus partout. Parmi eux, Google Gemma a gagné une large reconnaissance pour sa légèreté, sa haute efficacité et ses capacités multimodales, les modèles de base de la série Qwen d'Alibaba ont émergé et DeepSeek a choqué l'ensemble du secteur avec son statut de cheval noir à faible coût et hautes performances.
On ne sait pas encore si Meta pourra ajuster sa stratégie et revenir à la position de leader des modèles d'IA open source, mais dans tous les cas, l'épanouissement de l'IA open source est arrivé de manière irréversible.
Adhérant au principe selon lequel l’IA est facile à utiliser, laquelle doit être utilisée, Meta ne peut pas entièrement blâmer les utilisateurs. De plus, en termes de transparence open source, par rapport aux modèles open source des sociétés mentionnées ci-dessus, les contraintes auto-imposées de Llama 4 signifient également qu'il lui a coupé un bras.
Les difficultés actuelles de Meta peuvent également montrer que même si elle dispose de toute la puissance de calcul GPU et de données massives au monde, les avantages en termes de ressources ne sont plus le facteur décisif. Le « trône » des grands modèles open source ne peut pas être conquis par la force brute.
# Bienvenue pour suivre le compte public officiel WeChat d'Aifaner : Aifaner (WeChat ID : ifanr). Un contenu plus passionnant vous sera fourni dès que possible.
Ai Faner | Lien original · Voir les commentaires · Sina Weibo