
Le score chinois se classe au premier rang mondial et il est à égalité avec GPT4o dans plusieurs tests à l’aveugle. Comment se fait-il que ce grand modèle domestique soit devenu un cheval noir dans le monde de l’IA ?

Tout est comme s'il avait un moteur V12.
Le 13 de ce mois, Kai-fu Lee et Zero One Wish ont lancé leur deuxième produit, le modèle à source fermée Yi-Large. En moins d'un demi-mois depuis sa sortie, Yi-Large est passé d'une nouvelle génération qui n'a pas peur des tigres à un groupe puissant qui devance les vagues du fleuve Yangtze.
La semaine dernière, un mystérieux modèle nommé "je suis aussi un bon gpt2-chatbot" est soudainement apparu dans l'arène des grands modèles Chatbot Arena, se classant directement au-dessus de GPT-4-Turbo, Gemini 1 .5 Pro, Claude 3 0pus , Llama-3-70b et autres modèles de base populaires des principaux fabricants internationaux.
Ce modèle mystérieux est la version de test de GPT-4o, Sam Altman, PDG d'OpenAI, a également personnellement republié et cité les résultats du test aveugle de l'arène LMSYS après la sortie de GPT-4o.
Une semaine plus tard, dans le dernier classement mis à jour, l'histoire du cheval noir "je suis aussi un bon chatbot gpt2" a été à nouveau mise en scène. Cette fois, le modèle qui a grimpé rapidement dans le classement a été présenté par le grand chinois. société de modélisation Zero One Wan. Le grand modèle à source fermée « Yi-Large » avec des centaines de milliards de paramètres.
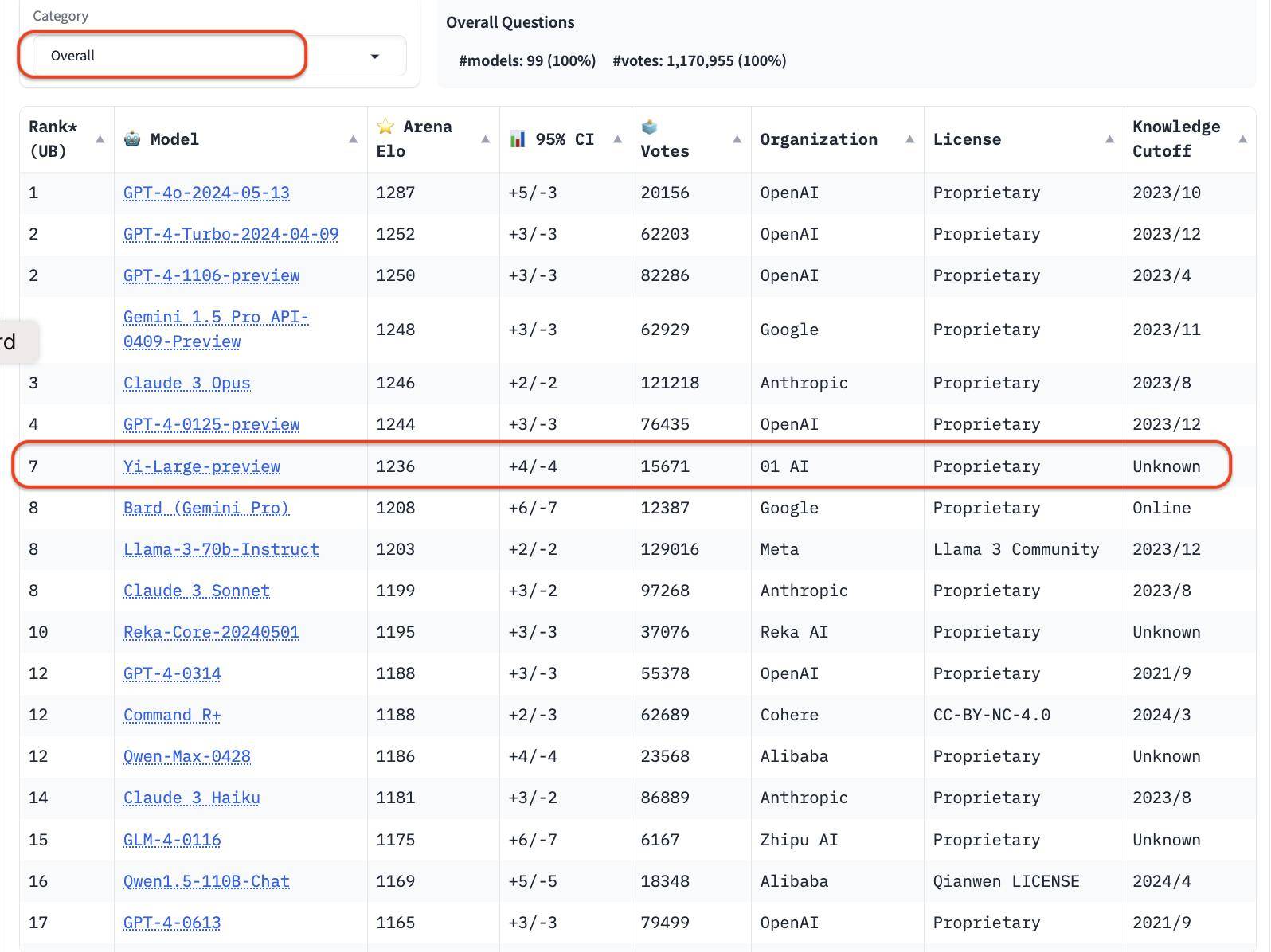
Dans le dernier classement du LMSYS Blind Test Arena, Yi-Large, le dernier modèle de Yi-Large à 100 milliards de paramètres, se classe au 7ème rang mondial et au 1er parmi les grands modèles en Chine, surpassant Llama-3-70B et Claude 3 Sonnet. Son classement chinois est à égalité avec GPT4o pour la première place mondiale.
Chatbot Arena, publié par l'organisation de recherche ouverte LMSYS Org (Large Model Systems Organization), est devenu une compétition directe pour de grandes entreprises internationales telles que OpenAI, Anthropic, Google et Meta, et a également ouvert une fonction de vote de masse. .
Lingyiwuwu est ainsi devenue la seule grande entreprise de mannequins chinoise à placer ses propres modèles parmi les dix premiers du classement général.
Dans la liste globale, la série GPT représente 4 des 10 premiers. Classé par institution, 01W01.AI est juste derrière OpenAI, Google et Anthropic, et est officiellement entré dans le premier camp mondial des grandes entreprises modèles.
Il semble désormais que le slogan « Devenir le numéro 1 mondial » ne soit pas seulement un slogan, mais qu'il soit en train de devenir.
Le score chinois se classe au premier rang mondial et le test à l'aveugle « brûlage du cerveau » se classe au deuxième rang mondial.
Les résultats du test aveugle de LMSYS Chatboat Arena, qui viennent d'être mis à jour le 20 mai 2024, heure des États-Unis, proviennent des votes réels de plus de 11,7 millions d'utilisateurs mondiaux accumulés jusqu'à présent.
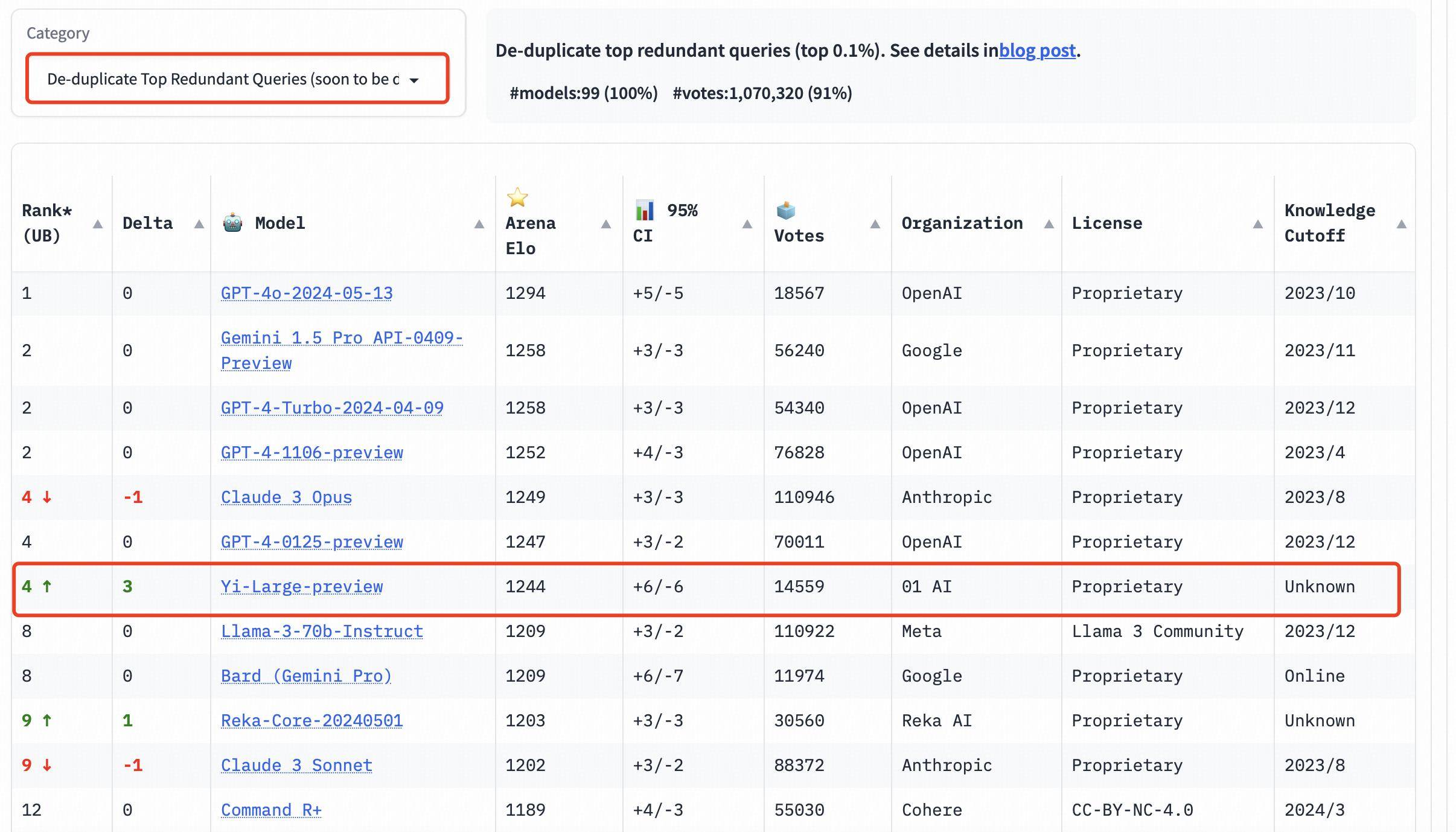
Il convient de mentionner que afin d'améliorer la qualité globale des requêtes Chatbot Arena, LMSYS a également mis en œuvre un mécanisme de déduplication et publié une liste après avoir supprimé les requêtes redondantes.
Ce nouveau mécanisme est conçu pour éliminer les invites utilisateur trop redondantes, telles que les « Bonjour » trop répétitifs, qui peuvent affecter la précision du classement.
LMSYS a déclaré publiquement que la liste après suppression des requêtes redondantes deviendra la liste par défaut à l'avenir.
Dans la liste globale, après suppression des requêtes redondantes, le score Elo de Yi-Large est allé encore plus loin, se classant quatrième avec Claude 3 Opus et GPT-4-0125-preview.
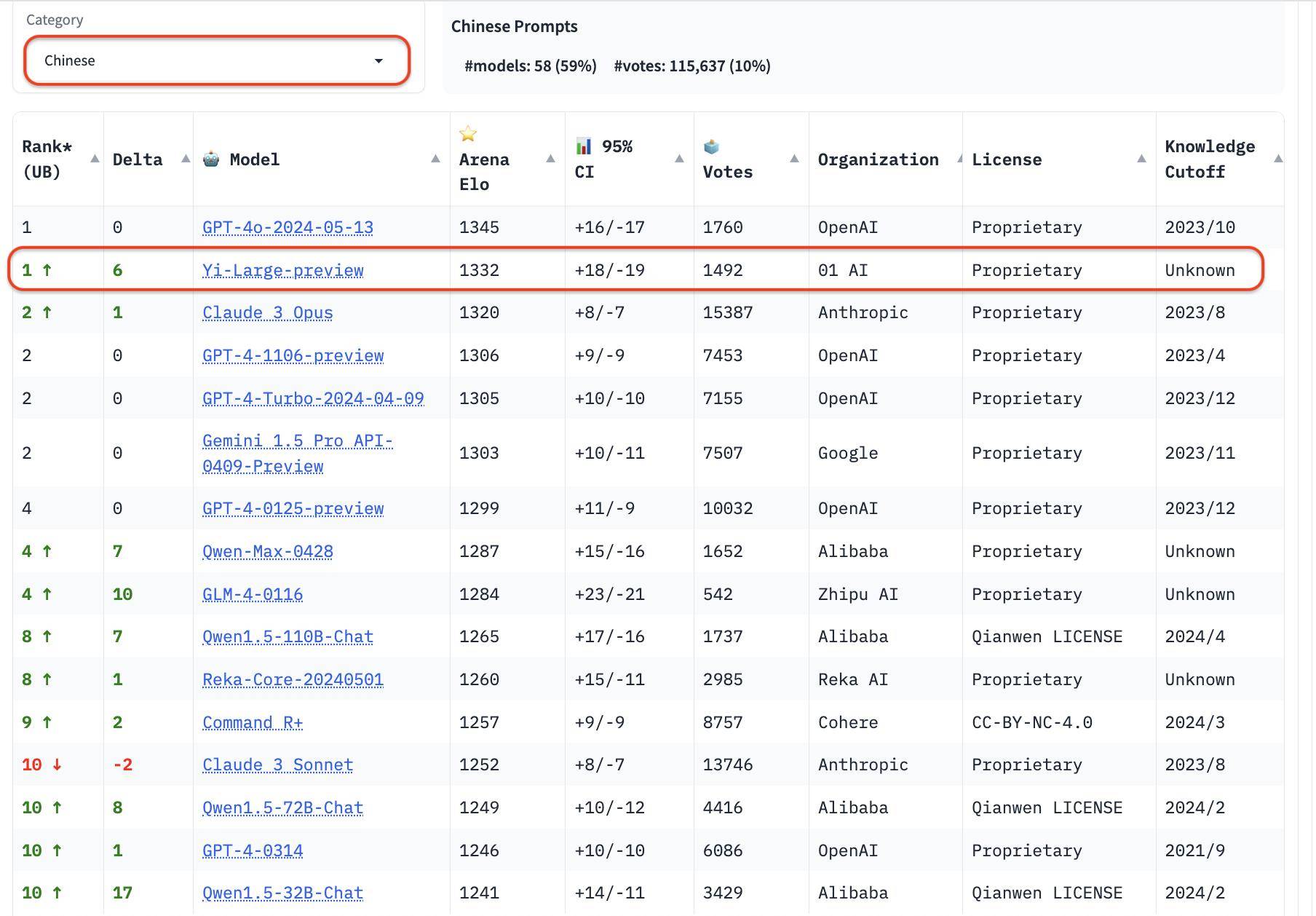
En plus de la liste globale, LMSYS a ajouté trois nouvelles évaluations linguistiques en anglais, chinois et français, et a commencé à se concentrer sur la diversité des grands modèles mondiaux. Yi-Large est en tête de la liste des langues chinoises, à égalité avec GPT4o et GLM-4 a également obtenu de bons résultats sur la liste des langues chinoises.
Parmi les grands fabricants de modèles nationaux, le Qwen-Max d’Alibaba et le GLM-4 de Zhipu ont tous deux réalisé des performances exceptionnelles.
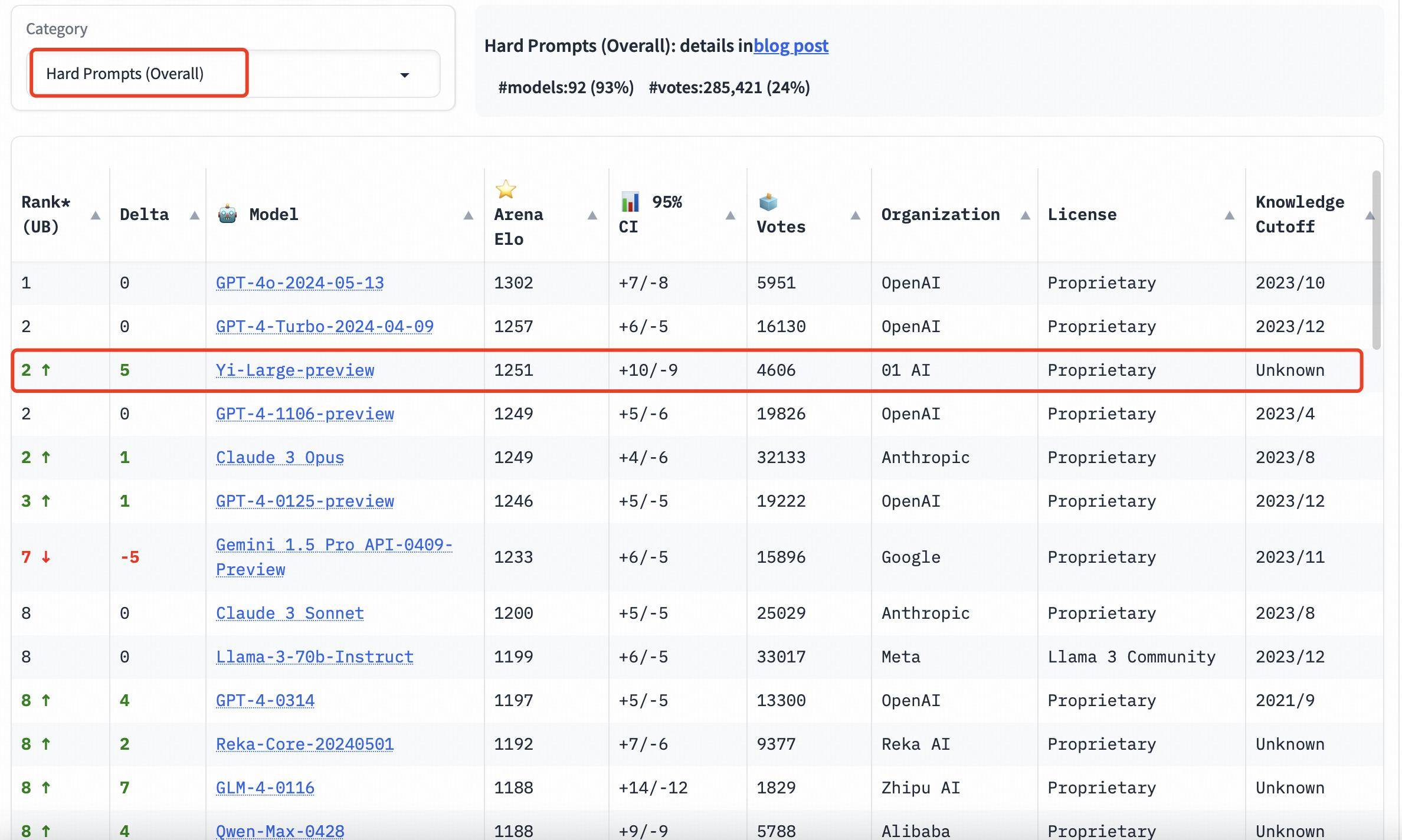
Dans le classement des catégories, Yi-Large obtient également de bons résultats. Les trois évaluations de la capacité de programmation, les questions longues et les derniers « mots d'invite difficiles » sont des listes ciblées données par LMSYS. Elles sont réputées pour leur professionnalisme et leur grande difficulté. Elles peuvent être qualifiées d'aveuglement public « le plus brûlant » des grands modèles. . La mesure.
Les trois évaluations de la capacité de programmation, des questions longues et des derniers « mots d'invite difficiles » sont professionnelles et difficiles. Il est également connu comme le test aveugle public « le plus brûlant » de la liste LMSYS.
Dans le classement des capacités de programmation (codage), le score Elo de Yi-Large dépasse celui de Claude 3 Opus d'Anthropic, n'est qu'inférieur à celui de GPT-4o et se classe deuxième avec GPT-4-Turbo et GPT-4 ;
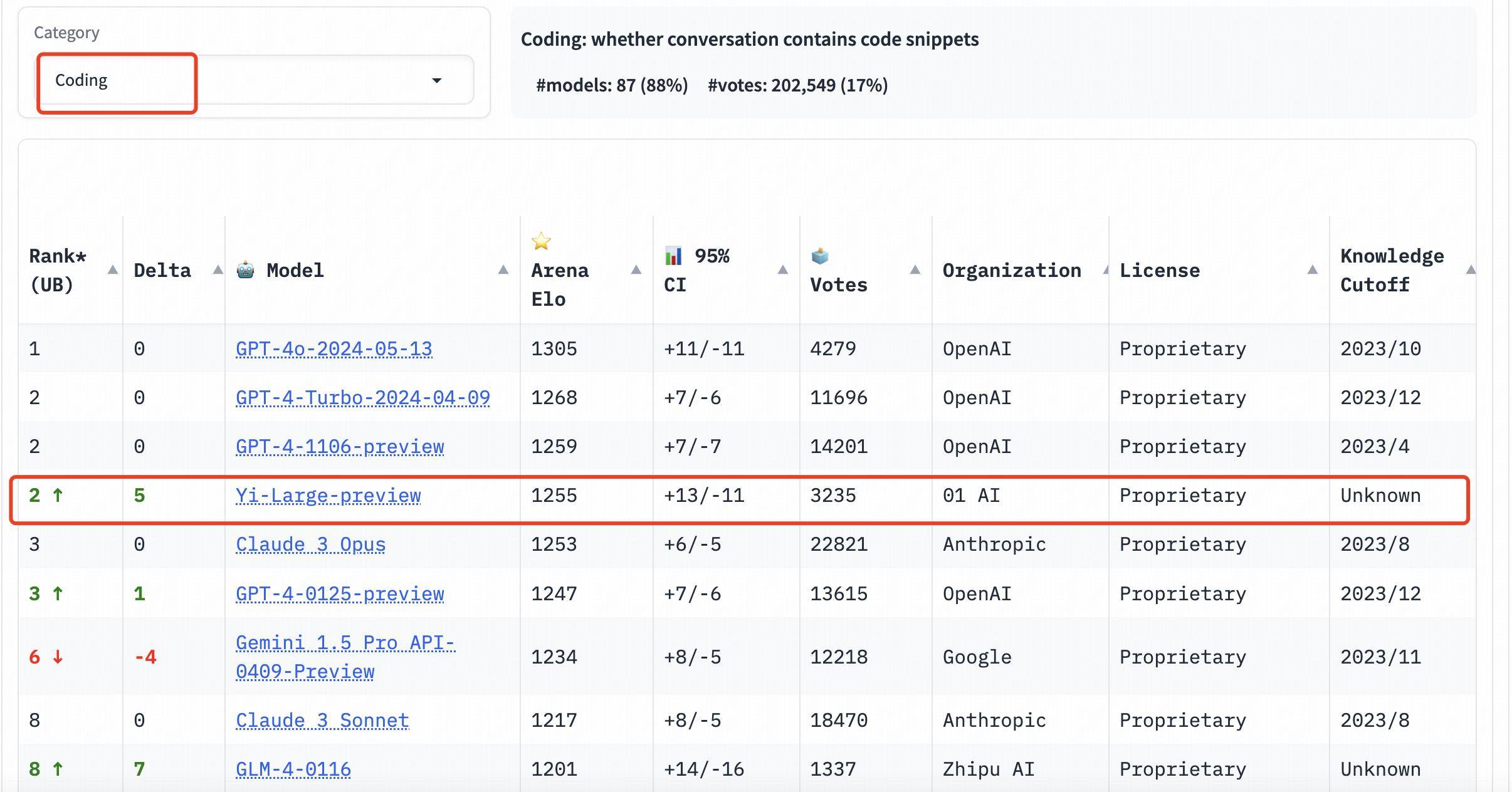
Sur la liste Longer Query, Yi-Large se classe également au deuxième rang mondial, à égalité avec GPT-4-Turbo, GPT-4 et Claude 3 Opus ;

Sur la liste Hard Prompts, Yi-Large est à égalité à la deuxième place avec GPT-4-Turbo, GPT-4 et Claude 3 Opus.
Utiliser des méthodes scientifiques pour obtenir des résultats objectifs
La manière de fournir une évaluation objective et équitable des grands modèles a toujours été un sujet de préoccupation largement répandu dans l'industrie.
Auparavant, il y avait diverses méthodes pour « faire glisser les classements » dans l'industrie, mais elles ont toujours été incapables de refléter les véritables capacités des grands modèles, laissant les gens qui veulent comprendre dans le brouillard et les investisseurs des secteurs connexes se gratter la tête. .
Le Chatbot Arena publié par LMSYS Org commence à briser ce chaos.
Avec son nouveau format « arène » et la rigueur de l'équipe de tests, il est devenu une référence reconnue par l'industrie mondiale. Même OpenAI a été pré-publié et pré-testé de manière anonyme sur LMSYS avant la sortie officielle de GPT-4o.
Andrej Karpathy, membre fondateur de l'équipe OpenAI, a même déclaré publiquement :
Chatbot Arena est génial.
Sur la forme, Chatbot Arena s'inspire des idées d'évaluation comparative horizontale de l'ère des moteurs de recherche :
- Premièrement, tous les modèles « d'entrée » téléchargés pour évaluation sont appariés au hasard par paires et présentés aux utilisateurs sous la forme de modèles anonymes ;
- Ensuite, les utilisateurs réels sont invités à saisir leurs propres mots d'invite, et les utilisateurs réels évalueront les réponses aux deux produits modèles sans connaître le nom du modèle ;
- Ensuite, sur la plateforme de test aveugle https://arena.lmsys.org/, les grands modèles sont comparés par paires et l'utilisateur saisit indépendamment des questions sur les grands modèles ;
- Le modèle A et le modèle B génèrent respectivement les résultats réels de deux modèles PK des deux côtés. Les utilisateurs peuvent voter sous les résultats pour choisir l'un des quatre : le modèle A est meilleur/le modèle B est meilleur/les deux sont à égalité/les deux ne sont pas bons ;
- Après la soumission, le prochain cycle de PK peut être effectué.
En finançant de manière participative de vrais utilisateurs pour effectuer des tests aveugles en temps réel et des votes anonymes, Chatbot Arena réduit l'impact des biais d'une part et, d'autre part, évite dans la plus grande mesure possible la possibilité d'un classement basé sur l'ensemble des tests. augmentant ainsi l'objectivité des résultats finaux.
Chatbot Arena rend également publiques toutes les données de vote des utilisateurs après qu'elles ont été nettoyées et anonymisées.
Après avoir collecté des données de vote réelles des utilisateurs, LMSYS Chatbot Arena utilisera également le système de notation Elo pour quantifier les performances du modèle, optimiser davantage le mécanisme de notation et s'efforcera de refléter équitablement la force des participants.
Dans le système de notation Elo, chaque participant reçoit un score de base et après chaque partie, le score du participant est ajusté en fonction des résultats du jeu.
Le système calculera la probabilité de gagner le jeu en fonction du score du participant. Une fois qu'un joueur avec un score faible bat un joueur avec un score élevé, le joueur avec un score faible obtiendra plus de points, et vice versa.
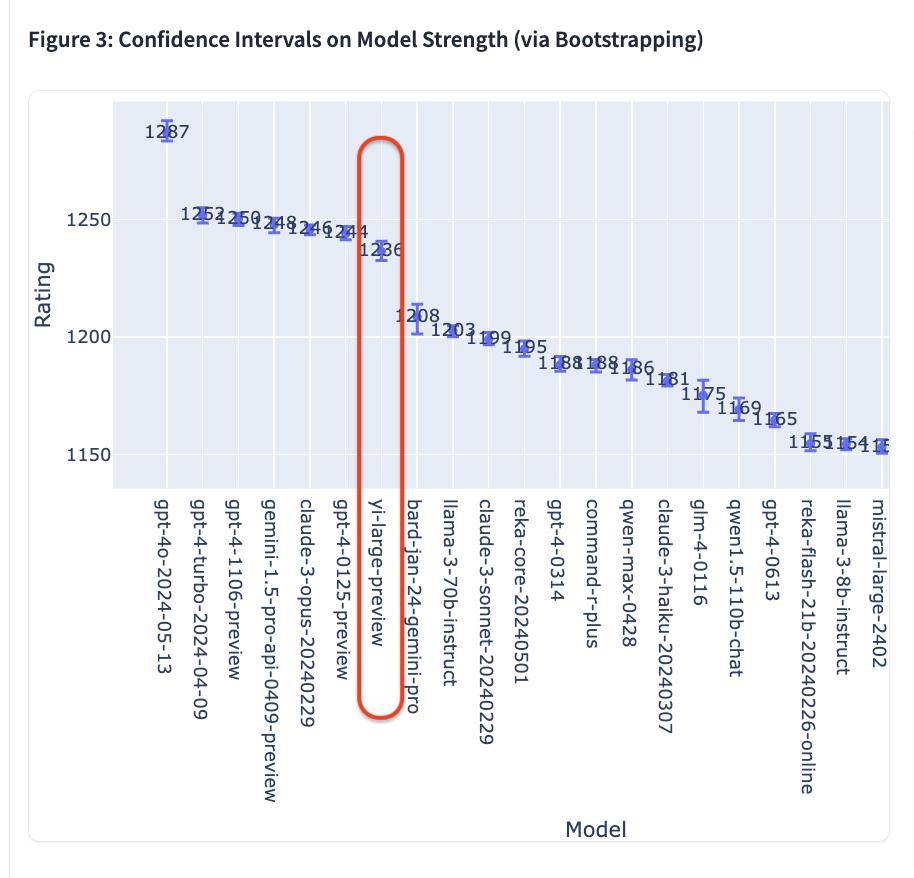
En introduisant le système de notation Elo, LMSYS Chatbot Arena garantit dans une large mesure l'objectivité et l'équité du classement.
Utilisez petit pour gagner gros
Cette fois-ci, un total de 44 modèles ont participé à la Chatbot Arena, dont à la fois le meilleur modèle open source Llama3-70B et des modèles fermés de grands fabricants.
- À en juger par le dernier score Elo, GPT-4o est en tête de liste avec un score de 1287 ;
- GPT-4-Turbo, Gemini 1 5 Pro, Claude 3 0pus, Yi-Large et d'autres modèles se situent au deuxième rang avec des scores d'environ 1 240 ;
- Par la suite, les scores de Bard (Gemini Pro), Llama-3-70b-Instruct et Claude 3 sonnet ont chuté d'une falaise à environ 1 200 points.
Il convient de mentionner que les 6 meilleurs modèles appartiennent respectivement aux géants étrangers OpenAI, Google et Anthropic, qui se classent au quatrième rang mondial, et des modèles tels que GPT-4 et Gemini 1.5 Pro ont tous des paramètres de niveau billion. est le modèle phare à l'échelle, et d'autres modèles sont également au niveau des paramètres de centaines de milliards.
Yi-Large « prend petit pour gagner gros », le suivant de près avec un niveau de paramètre de seulement 100 milliards.

Le développement compétitif des grands modèles d'IA est encore à un stade féroce, et la « bataille de centaines de modèles » de l'intelligence artificielle continuera de se dérouler dans ce domaine où les « semaines » voire les « jours » sont utilisés comme unités d'itération. l'existence d'un système d'évaluation relativement équitable et objectif devient particulièrement importante.
Une plate-forme d'évaluation qui met continuellement à jour le système de notation peut non seulement permettre aux investisseurs de l'industrie de voir le véritable état du développement technologique, mais également permettre aux utilisateurs d'avoir le droit de choisir des modèles avancés, et peut également promouvoir le développement sain de l'ensemble de la grande industrie du modèle. .
Que ce soit pour l'itération de leurs propres capacités de modèle ou dans la perspective d'une réputation à long terme, les grands fabricants de modèles devraient participer activement à des plateformes d'évaluation faisant autorité comme Chatbot Arena pour prouver leurs produits grâce aux commentaires réels des utilisateurs et aux mécanismes d'évaluation professionnels.
Au contraire, si vous vous souciez uniquement des résultats des classements et ignorez l'effet d'application réel du modèle, l'écart entre les capacités du modèle et la demande du marché deviendra plus évident, et il sera finalement difficile de prendre pied dans le féroce marché de l'IA. concurrence sur le marché.
Dans la vague de l’ère de l’IA, si les grands modélistes veulent être excellents voire haut de gamme, ils ont besoin d’au moins deux qualités :
- Je dois m'examiner trois fois par jour : acquérir de l'expérience par le progrès et obtenir des réponses par la compétition ;
- Le véritable or n'a pas peur du feu : plutôt que de se classer premier sur la « liste sauvage », il vaut mieux regarder à l'intérieur et améliorer ses véritables capacités.
Ce qui mérite d'être attendu, c'est qu'il existe désormais un groupe d'excellents fabricants nationaux de modèles à grande échelle qui sont terre-à-terre, innovants en matière de recherche et de développement et qui peuvent même rivaliser avec les géants de l'industrie sur la scène internationale.
Adresse de vote publique de LMSYS Chatbot Arena Blind Test Arena : https://arena.lmsys.org/
Classement d'évaluation du classement LMSYS Chatbot Leaderboard (mise à jour continue) : https://chat.lmsys.org/?leaderboard
# Bienvenue pour suivre le compte public officiel WeChat d'aifaner : aifaner (ID WeChat : ifanr). Un contenu plus passionnant vous sera fourni dès que possible.
Ai Faner | Lien original · Voir les commentaires · Sina Weibo