
Ne vous laissez plus tromper par le déploiement local de DeepSeek R1, je vous aiderai à surmonter tous les pièges Tutoriel gratuit inclus

Achetez-le ! Profitez du Nouvel An chinois pour l’apprendre quand vous avez le temps.
En cette Fête du Printemps, DeepSeek est comme un poisson-chat qui fait vibrer le cœur d’innombrables personnes au pays et à l’étranger. Alors que la Silicon Valley est toujours plongée dans le choc provoqué par DeepSeek, une « ruée vers l’or » massive de l’IA pénètre progressivement dans les principales plateformes de commerce électronique nationales.
Les claviers intelligents prétendant intégrer DeepSeek se vendent à près d'un million de dollars par jour, et les blogueurs vendent des cours qui peuvent facilement en rapporter 50 000 par jour. Même 2 650 sites Web contrefaits ont vu le jour, ce qui a incité DeepSeek à déclarer officiellement l'état d'urgence.

Il y avait des gens anxieux, des chercheurs d’or et des observateurs encore plus impatients dans la foule. Lorsqu’ils ont finalement eu le temps de se calmer et de découvrir cet artefact de l’IA après la Fête du Travail, ils ont reçu une réponse froide de DeepSeek R1 :
Le serveur est occupé, veuillez réessayer plus tard.
Grâce à la stratégie open source de DeepSeek, en attendant avec impatience, le tutoriel de déploiement local de DeepSeek R1 est rapidement devenu populaire sur Internet, et est même devenu une nouvelle série de astuces d'IA pour la récolte des poireaux.
Aujourd'hui, sans utiliser 998 ou 98, nous allons vous faire un tutoriel sur le déploiement local de DeepSeek R1.
Le modèle d'IA de DeepSeek vient de bouleverser le marché américain de l'électricité en pleine effervescence – Bloomberg
Cependant, il a été déployé, mais pas complètement.
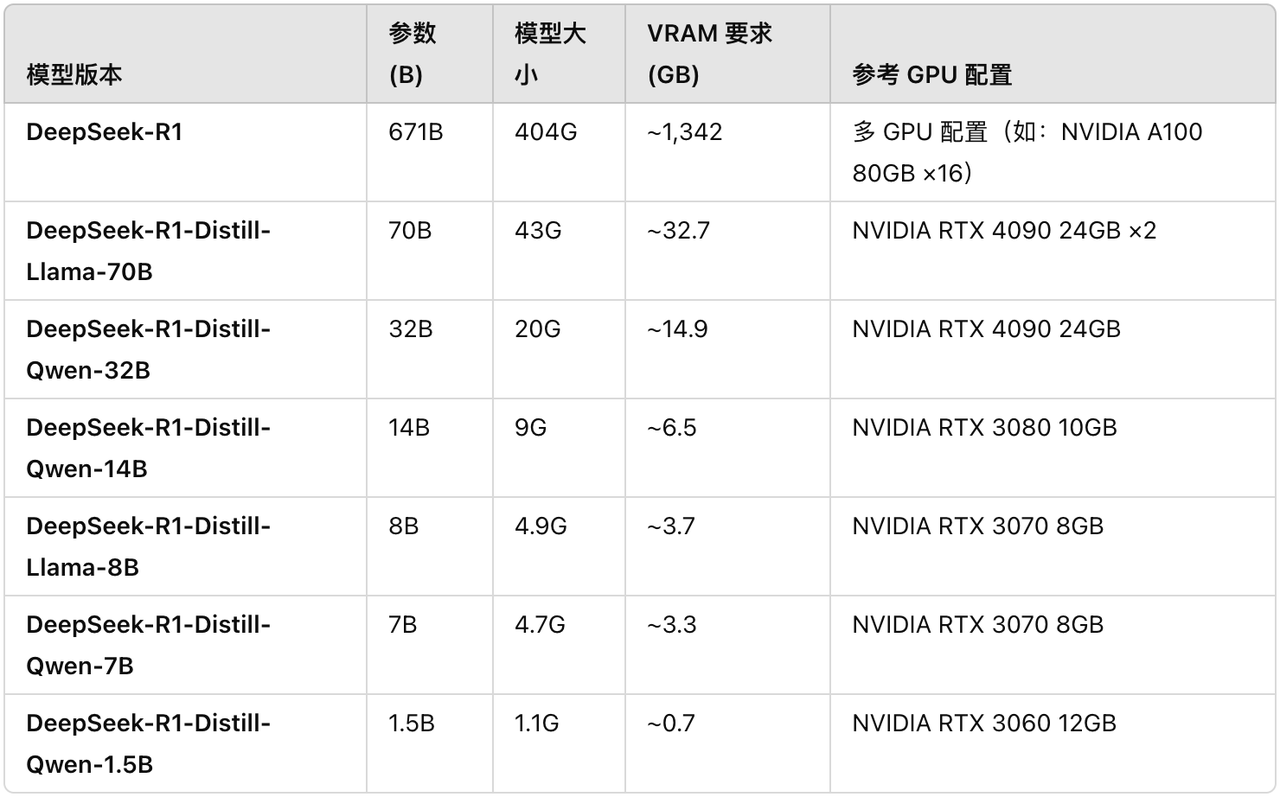
Bien que de nombreux blogueurs affirment qu'ils peuvent facilement exécuter la version complète de DeepSeek R1, les paramètres du modèle R1 complet atteignent 671 Go, et le fichier modèle à lui seul nécessite 404 Go d'espace de stockage et environ 1 300 Go de mémoire vidéo sont nécessaires pour fonctionner.
Pour les joueurs ordinaires sans carte, les conditions de fonctionnement sont rudes et le seuil est extrêmement élevé. Partant de là, autant porter notre attention sur les quatre petits modèles de distillation de DeepSeek R1 correspondant à Qwen et Llama :
- DeepSeek-R1-Distill-Llama-8B
- DeepSeek-R1-Distill-Qwen-14B
- DeepSeek-R1-Distill-Qwen-32B
- DeepSeek-R1-Distill-Llama-70B
Les blogueurs étrangers ont compilé des configurations pertinentes pour votre référence. Notez que tant que le GPU est égal ou supérieur aux exigences de VRAM, le modèle peut toujours fonctionner sur un GPU avec des spécifications inférieures. Mais la configuration n’est pas optimale et peut nécessiter quelques ajustements.
 https://dev.to/askyt/deepseek-r1-671b-complete-hardware-requirements-optimal-deployment-setup-2e48
https://dev.to/askyt/deepseek-r1-671b-complete-hardware-requirements-optimal-deployment-setup-2e48
Déployez localement le petit modèle R1, deux méthodes, apprenez-le en une seule fois
L'appareil que nous expérimentons cette fois est le Mac Studio M1 Ultra avec 128 Go de mémoire. Tutoriel sur le déploiement local grand public de DeepSeek, deux méthodes, vous pouvez l'apprendre en une seule fois.
Studio LM
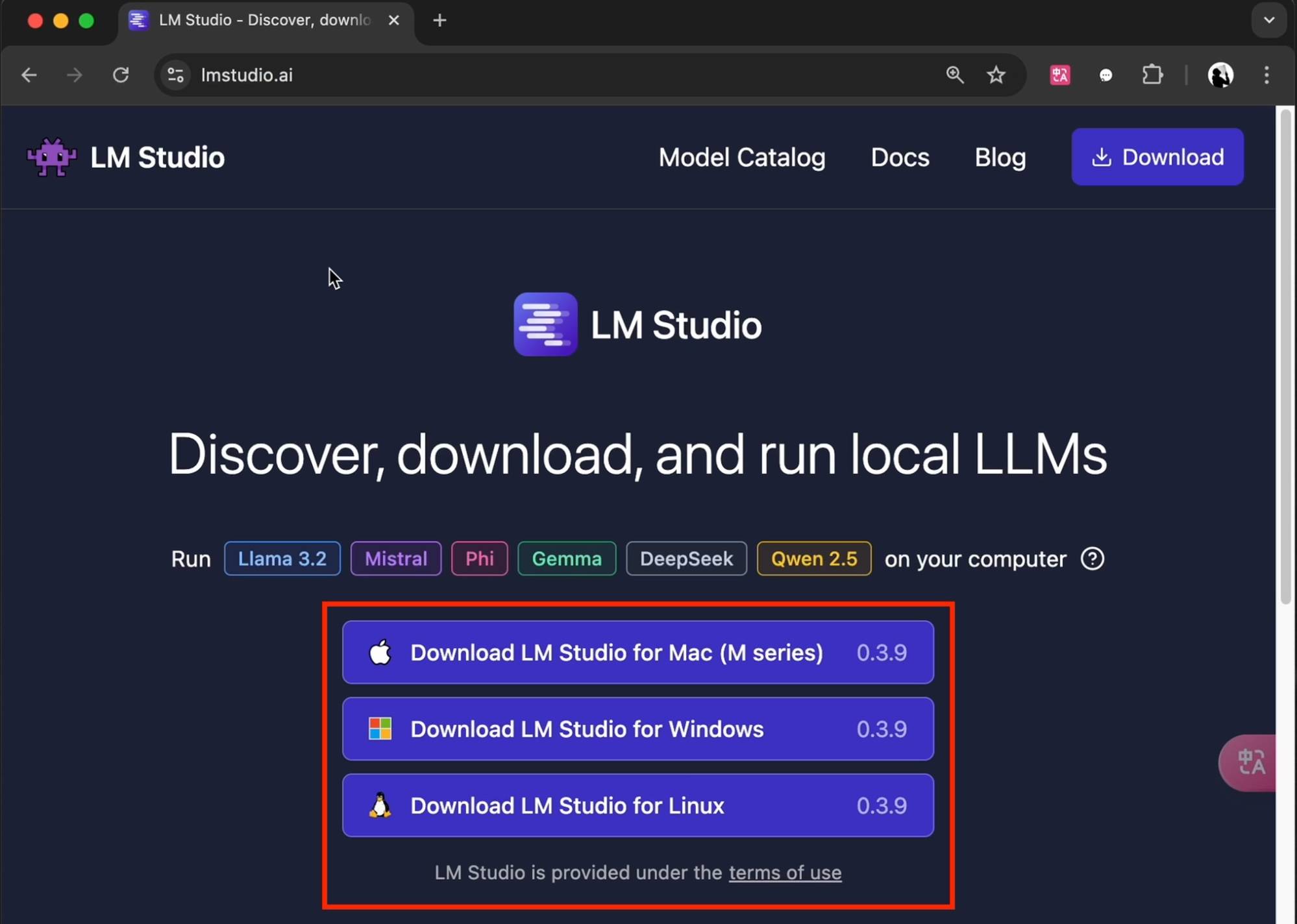
La première chose à apparaître est la version minimaliste de Xiaobai. Téléchargez LM Studio selon le modèle d'ordinateur personnel sur le site officiel (lmstudio.ai). Ensuite, pour faciliter l'utilisation, il est recommandé de cliquer sur le coin inférieur droit pour changer la langue en chinois simplifié.
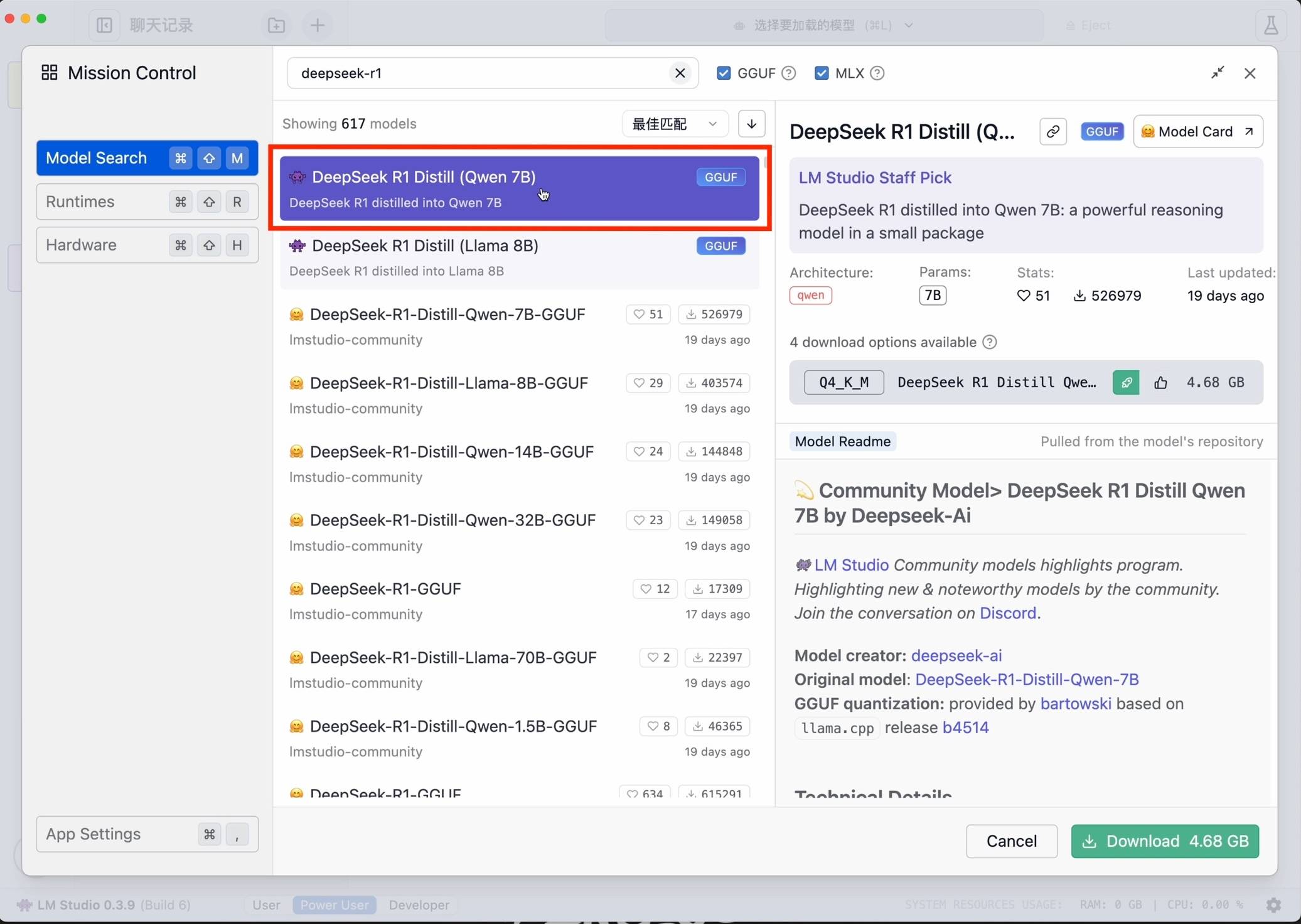
Recherchez ensuite deepseek-r1 et sélectionnez la version appropriée à télécharger. À titre d'exemple, j'ai choisi le petit modèle 7B distillé à partir du modèle Ali Qwen comme base.
Une fois la configuration terminée, elle peut être démarrée en un seul clic.
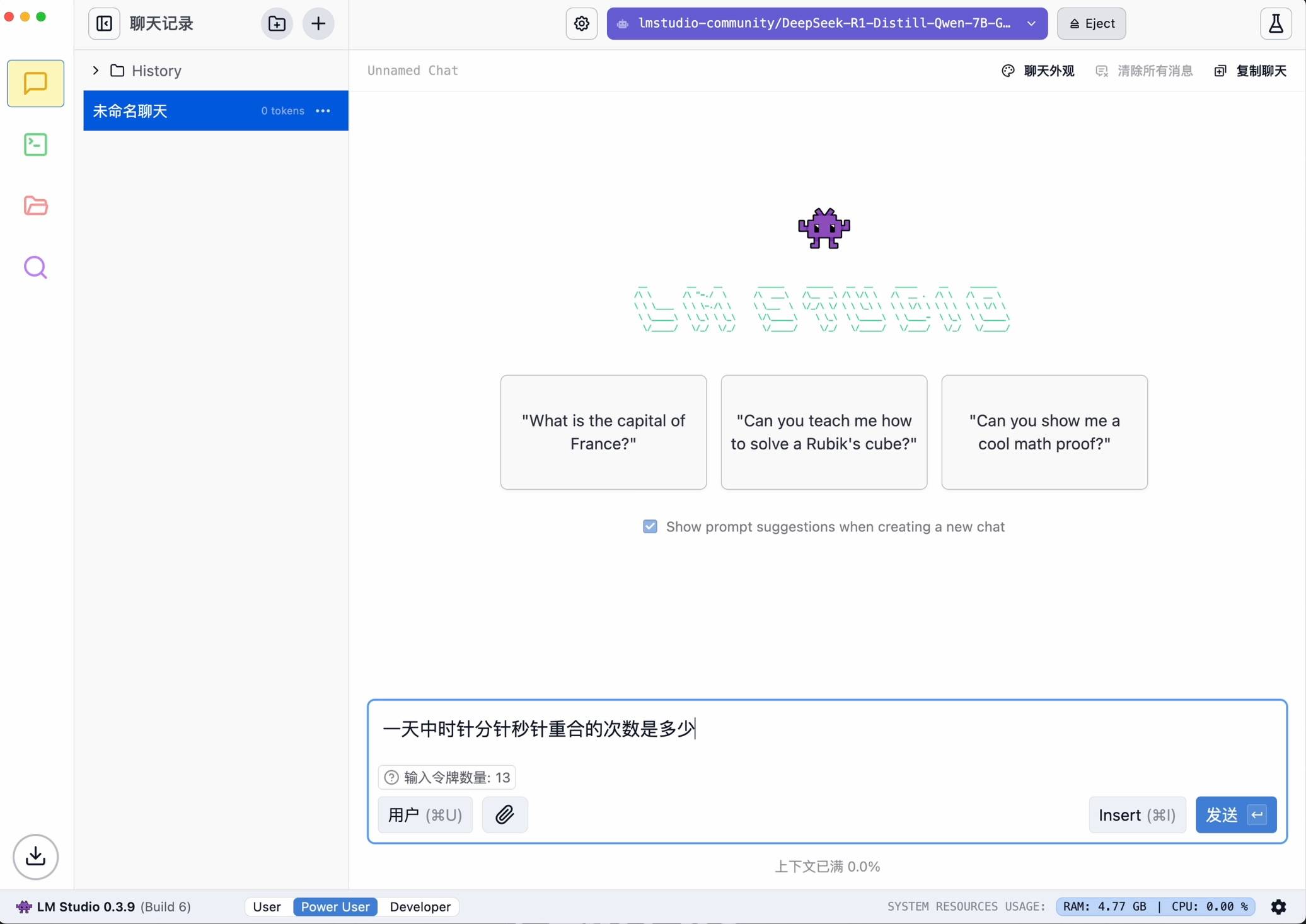
L'avantage d'utiliser LM Studio est qu'il ne nécessite pas de codage et possède une interface conviviale, mais il nécessite des performances élevées lors de l'exécution de grands modèles, il est donc plus adapté aux novices pour utiliser les fonctions de base.
Ollama
Bien entendu, nous avons également préparé des plans avancés pour les utilisateurs qui recherchent une expérience plus approfondie.
Commencez par obtenir et installer Ollama à partir du site officiel (ollama.com).
Après le démarrage, ouvrez l'outil de ligne de commande. Les utilisateurs Mac utilisent le clavier Commande+Espace pour ouvrir l'outil « Terminal ». Les utilisateurs Windows utilisent le clavier pour exécuter Win+R et saisissent cmd pour ouvrir l'outil « Invite de commandes ».
Entrez la commande de code (ollama run deepseek-r1:7b) dans la fenêtre pour lancer le téléchargement. Veuillez faire attention à la saisie du statut en anglais, vérifier les espaces et les tirets et saisir le nom de la version requis après les deux points.

Une fois la configuration terminée, vous pouvez démarrer une conversation dans la fenêtre de ligne de commande.
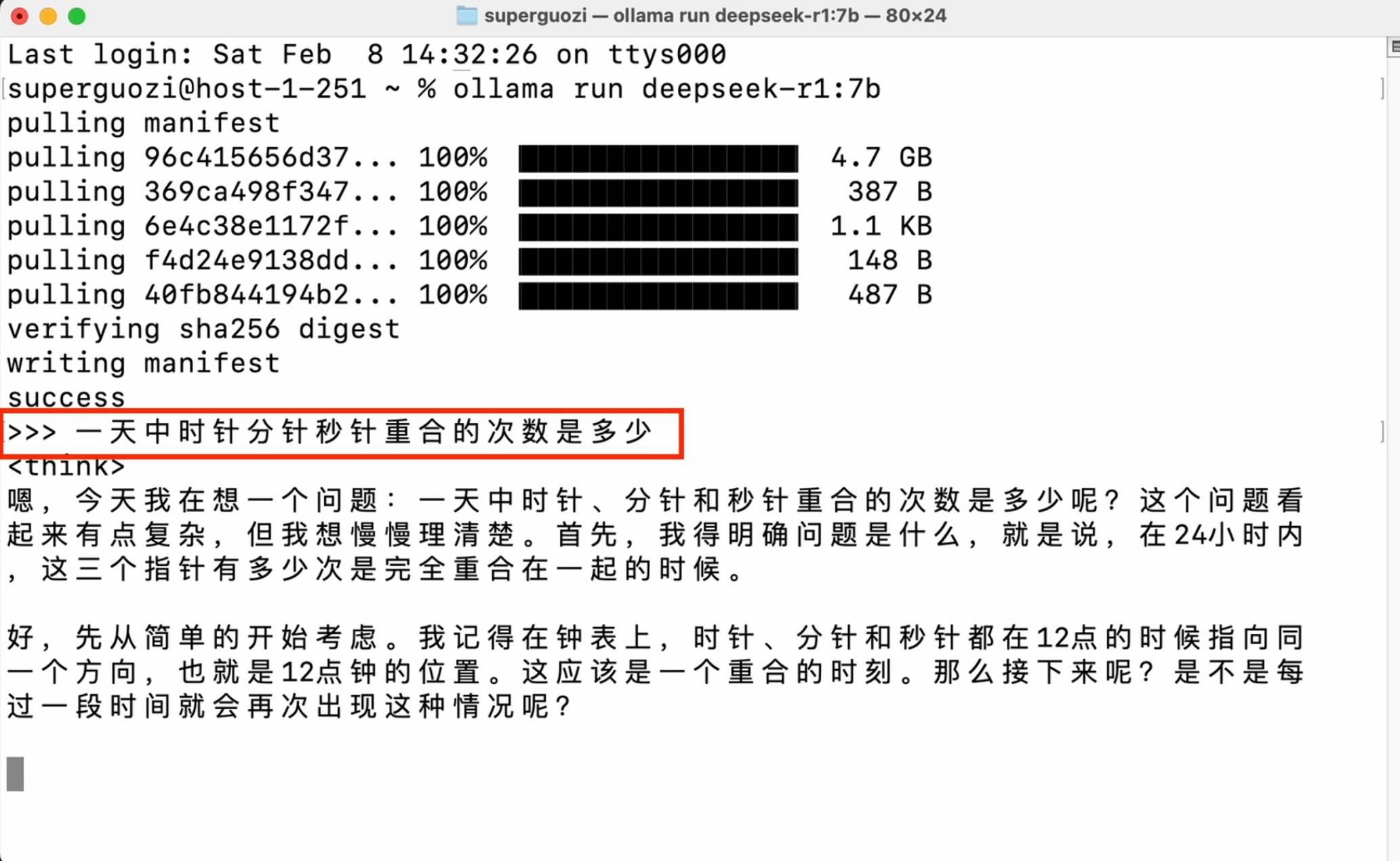
Cette méthode a des exigences de performances très faibles, mais nécessite une familiarité avec les opérations en ligne de commande, et la compatibilité du modèle est également limitée. Elle est plus adaptée aux développeurs avancés pour implémenter des opérations avancées.
Si vous souhaitez une interface interactive plus esthétique, vous pouvez aussi bien installer le plug-in dans le navigateur Chrome, rechercher et installer PageAssist.
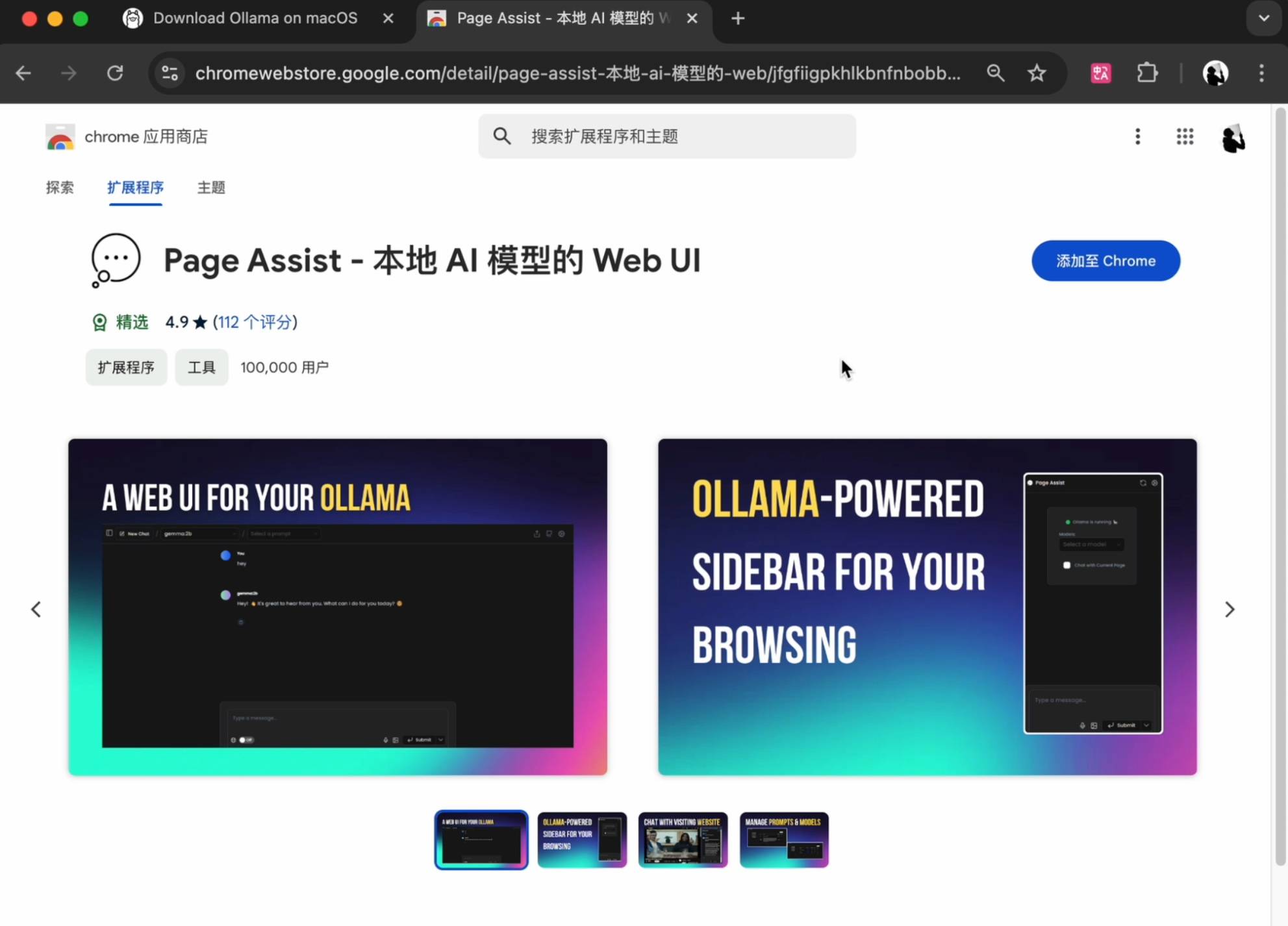
Sélectionnez un modèle installé localement pour commencer.
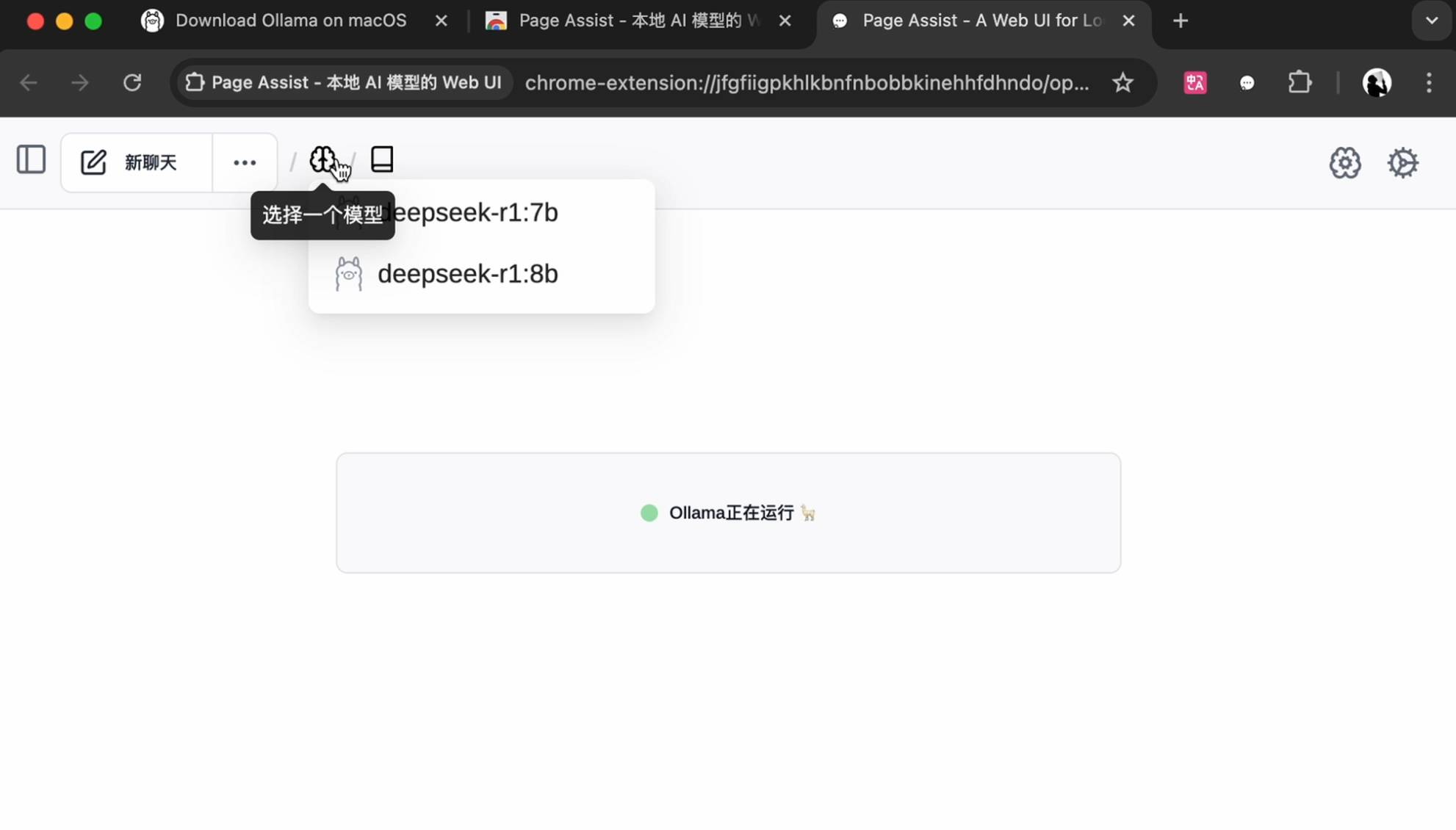
Modifiez la langue dans les paramètres dans le coin supérieur droit, sélectionnez le modèle sur la page d'accueil pour démarrer la conversation et prenez en charge les recherches de base sur Internet, et le gameplay est plus diversifié.
Si tu peux courir, tu peux courir, mais…
Nous avons utilisé LM Studio pour cette expérience.
Grâce à ses excellentes capacités d'optimisation, LM Studio permet aux modèles de s'exécuter efficacement sur du matériel grand public. Par exemple, LM Studio prend en charge la technologie de déchargement GPU, qui peut charger le modèle dans le GPU par blocs pour obtenir une accélération lorsque la mémoire vidéo est limitée.
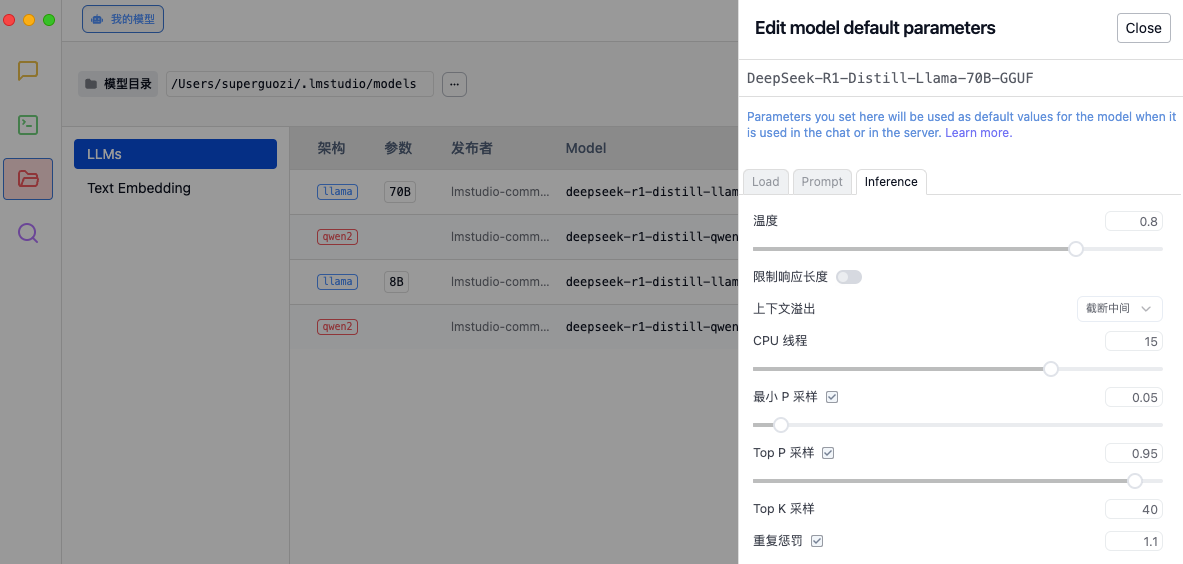
Tout comme le réglage d'une voiture de course, chaque paramètre affectera la performance finale. Avant d'en faire l'expérience, il est recommandé d'ajuster les paramètres d'inférence en fonction des besoins dans les paramètres de LM Studio pour optimiser la qualité de génération du modèle et l'allocation des ressources de calcul.
- Température : contrôle le caractère aléatoire du texte généré.
- Gestion des débordements de contexte : détermine comment gérer les entrées trop longues.
- Thread CPU : affecte la vitesse de génération et l’utilisation des ressources.
- Stratégie d'échantillonnage : garantir la rationalité et la diversité du texte généré grâce à de multiples méthodes d'échantillonnage et mécanismes de pénalité.
Daya Guo, chercheur chez DeepSeek, a partagé son guide de réglage interne sur la plate-forme X. La longueur maximale de génération est verrouillée à 32 768 jetons, la valeur de température est maintenue à 0,6 et la valeur top-p est fixée à 0,95. Chaque test génère 64 échantillons de réponses.
Les recommandations de configuration détaillées sont les suivantes :
1. Réglez la température entre 0,5 et 0,7 (le réglage recommandé est de 0,6) pour empêcher le modèle de produire un contenu répétitif ou incohérent sans fin.
2. Évitez d'ajouter une invite système, toutes les instructions doivent être incluses dans l'invite utilisateur.
3. Pour les questions mathématiques, il est recommandé d'inclure des instructions dans l'invite, par exemple : "Veuillez raisonner étape par étape et mettre la réponse finale dans boxed{}."
4. Lors de l'évaluation des performances du modèle, il est recommandé d'effectuer plusieurs tests et de faire la moyenne des résultats.
5. De plus, nous avons remarqué que le modèle de la série DeepSeek-R1 peut contourner le mode réflexion (c'est-à-dire la sortie "nn") lors de la réponse à certaines requêtes, ce qui peut affecter les performances du modèle. Pour garantir que le modèle effectue une inférence suffisante, nous vous recommandons de forcer le modèle à commencer sa réponse par « n » au début de chaque sortie.
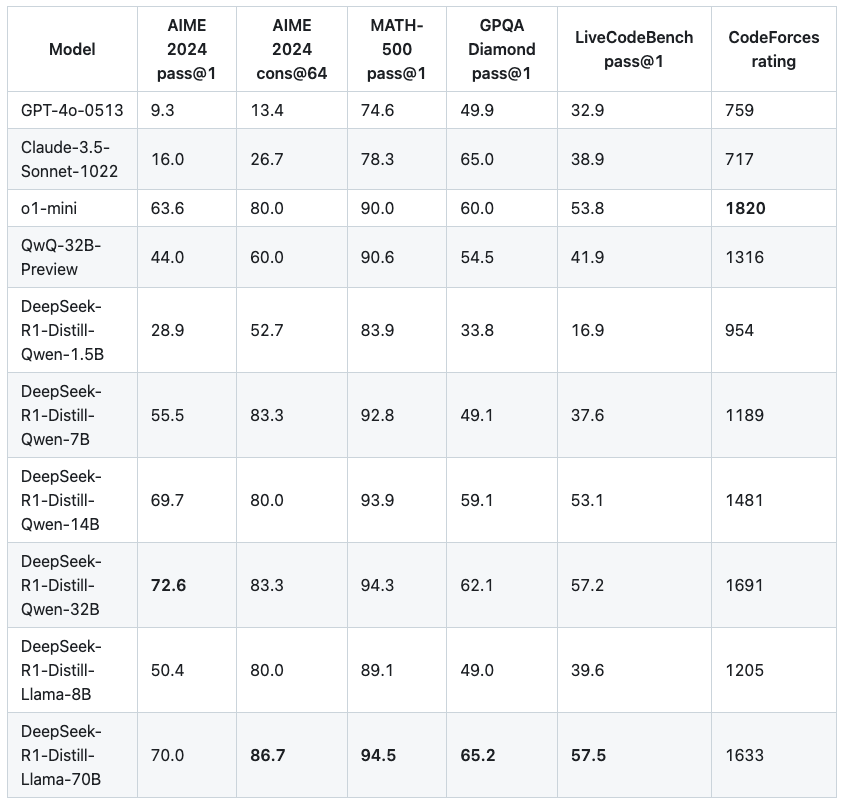
▲Évaluation et comparaison du modèle de version distillée donnée par le responsable de DeepSeek
Un plus grand nombre de paramètres n'apporte pas nécessairement de meilleurs résultats. Parmi les petits modèles que nous avons expérimentés, l'écart de force global entre les modèles avec des quantités de paramètres adjacentes n'est pas aussi hiérarchique. Nous avons également effectué quelques tests simples.
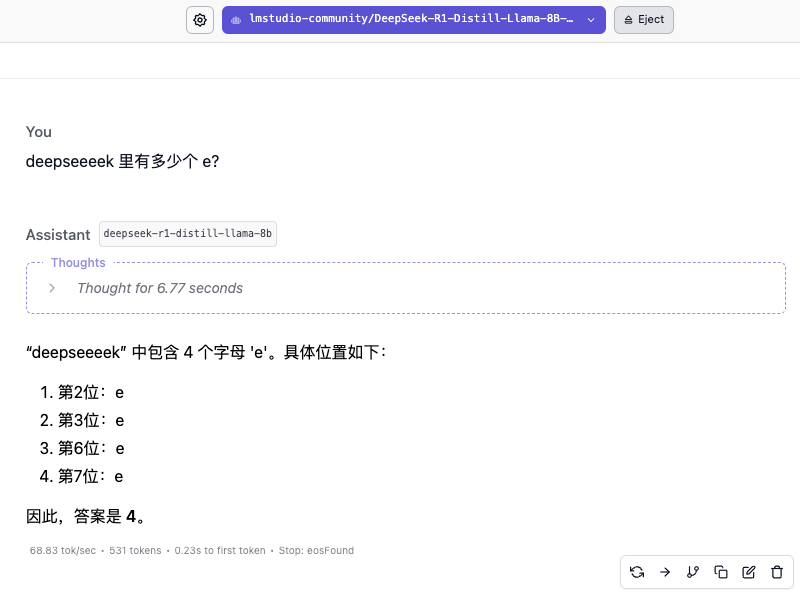

"Combien y a-t-il de e dans deekseeeek ?"
La vitesse de réponse du modèle 8B est très rapide, atteignant essentiellement 60 jetons/s, mais répondre rapidement ne signifie pas que la réponse est correcte. Une légère différence peut faire une énorme différence. Le processus de réflexion montre que le modèle ressemble davantage à une réponse basée sur les mots « DeepSeek » de la base de connaissances.

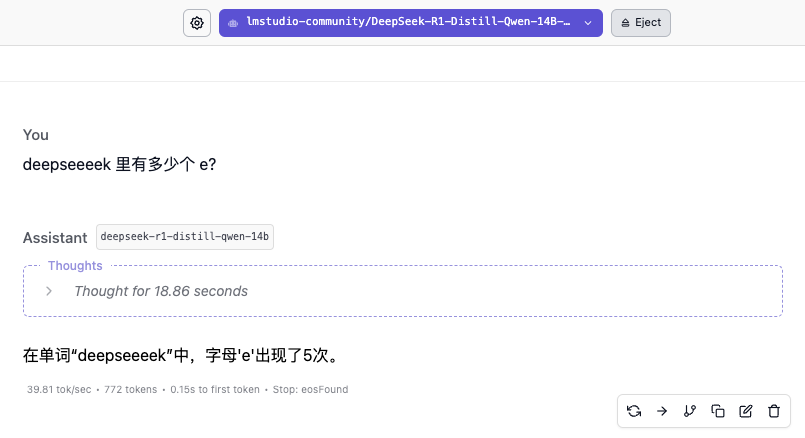
Le modèle 14B n’a pas non plus donné la bonne réponse. Il a fallu attendre l’apparition du modèle 32B pour que l’on ait enfin vu une réponse fiable. Le modèle 70B a montré un raisonnement plus minutieux mais a également donné de mauvaises réponses.
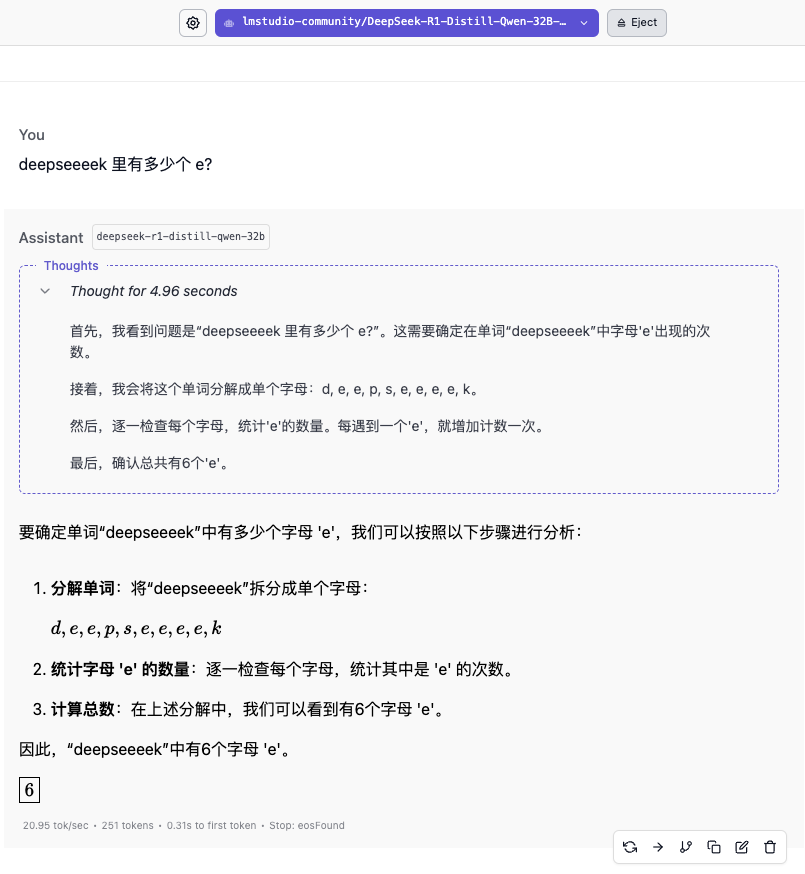
En termes de qualité des réponses à cette question, 32B et 70B ont chacun leurs propres mérites. 32B a un contrôle plus parfait sur les détails des scènes de script, tandis que 70B a livré une feuille de réponses avec des personnages complets et une intrigue complète.

"Quelqu'un prend un avion quelque part dans l'hémisphère nord et parcourt 2 000 kilomètres plein est, plein nord, plein ouest et plein sud. Au final, peut-il revenir au même endroit ?"
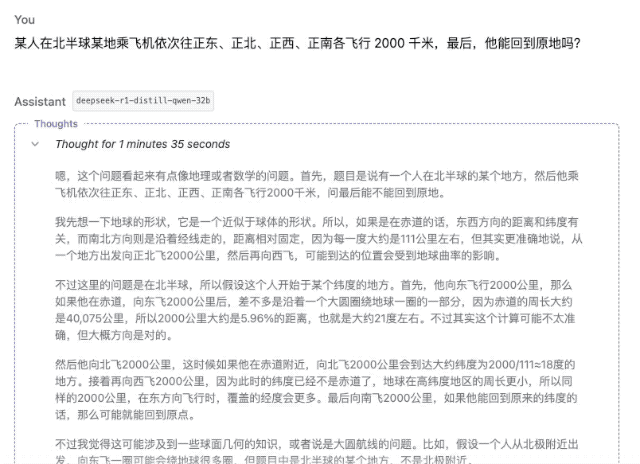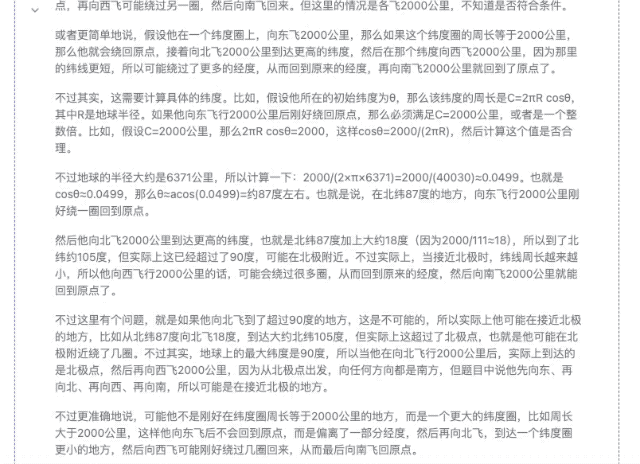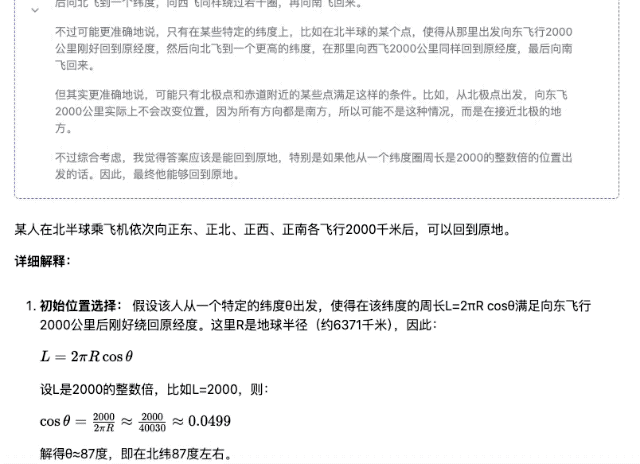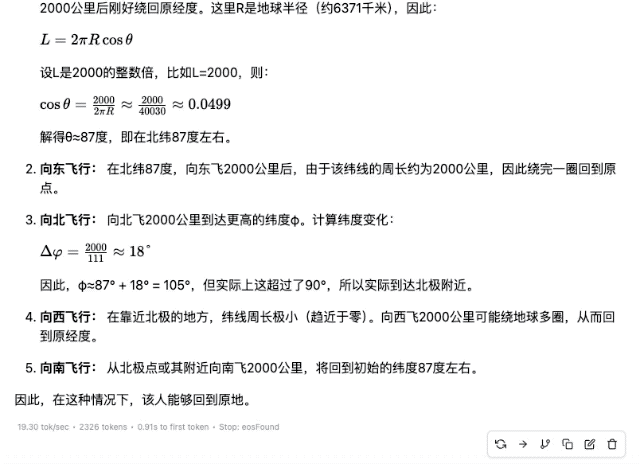
▲ DeepSeek-R1-Distill-Qwen-32B
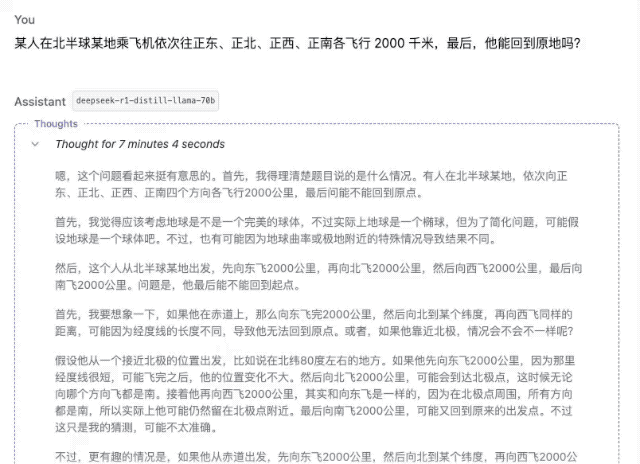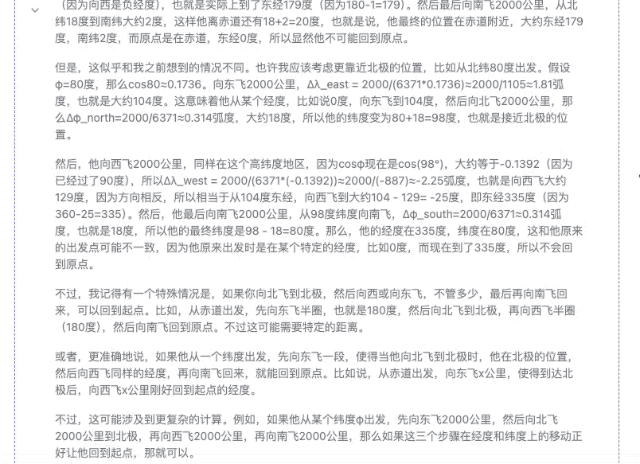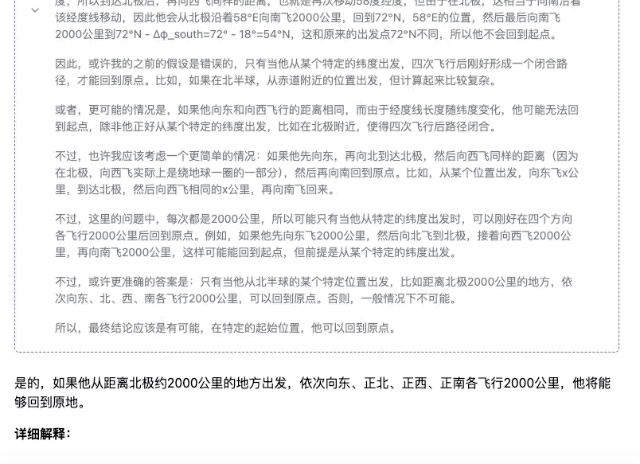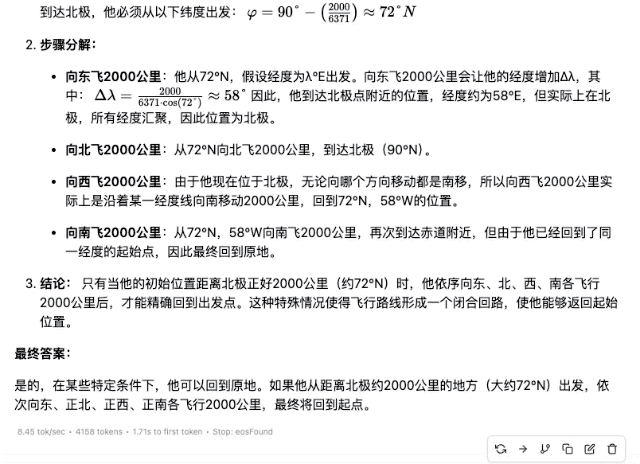
▲DeepSeek-R1-Distill-Llama-70B
Bien sûr, parmi ces modèles, plus les paramètres sont petits, plus la précision de la réponse est faible. Même si le processus de réflexion est fluide, des erreurs ultérieures seront commises en raison d'un manque de fermeté. Dans le domaine des calculs mathématiques, la différence de force entre les modèles de différentes ampleurs sera plus évidente.
Le déploiement local présente trois avantages majeurs : les données sensibles n'ont pas besoin d'être téléchargées sur le cloud ; elles peuvent être utilisées sans problème même si le réseau est déconnecté ; et les frais d'appel d'API sont supprimés, ce qui rend les tâches de texte long plus économiques.
Mais ne pas prendre en charge Internet a aussi ses inconvénients. Si vous ne lui fournissez pas de « données » et ne mettez pas à jour la base de connaissances en temps opportun, son niveau de cognition des informations stagnera également. Par exemple, si la base de connaissances s’étend jusqu’en 2024, elle ne pourra pas répondre à vos dernières actualités IA.
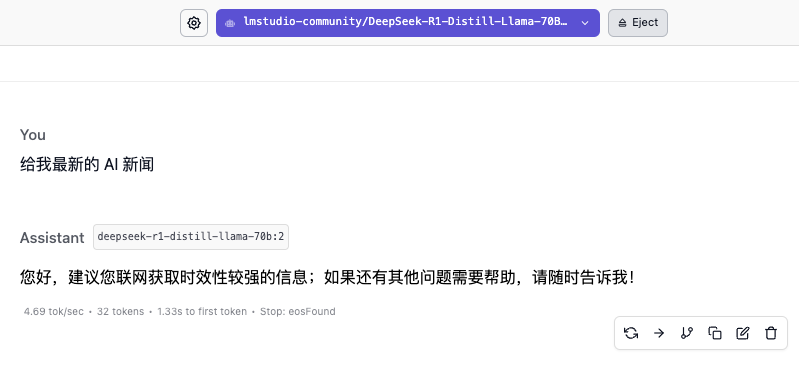
La fonction la plus couramment utilisée du déploiement local consiste à créer votre propre base de connaissances. La méthode consiste à ajouter une étape de déploiement liée à Anything LLM après l'installation de LM Studio.
Compte tenu de l'effet et de l'applicabilité, nous avons utilisé le modèle 32B comme modèle de liaison, et les résultats ont montré que l'effet était également très général. Le plus grand défi provenait de la limitation de la fenêtre contextuelle.
J'ai saisi un article de seulement 4 000 mots et un article d'environ 1 000 mots en séquence. La réponse du premier était encore très confuse, tandis que le second était compétent. Cependant, c'était un peu inutile de traiter des articles d'environ 1 000 mots, donc c'était bien comme un jouet, mais la productivité n'était guère intéressante.

Il faut également souligner que d'une part, il est extrêmement difficile d'ouvrir la bouche de ces quatre modèles. D'autre part, nous vous déconseillons d'essayer de « jailbreaker ». Bien qu'il existe de nombreux nouveaux modèles de versions réputés faciles à « jailbreaker » qui circulent sur Internet, pour des raisons de sécurité et d'éthique, nous ne recommandons pas un déploiement aléatoire.
Cependant, maintenant que nous avons atteint ce point, autant suivre le principe de tout savoir et essayer de télécharger et de déployer quelques petits modèles diffusés via des canaux formels.
En plus du déploiement local de petits modèles de distillation R1, existe-t-il un mauvais package pour la version R1 à sang pur ?
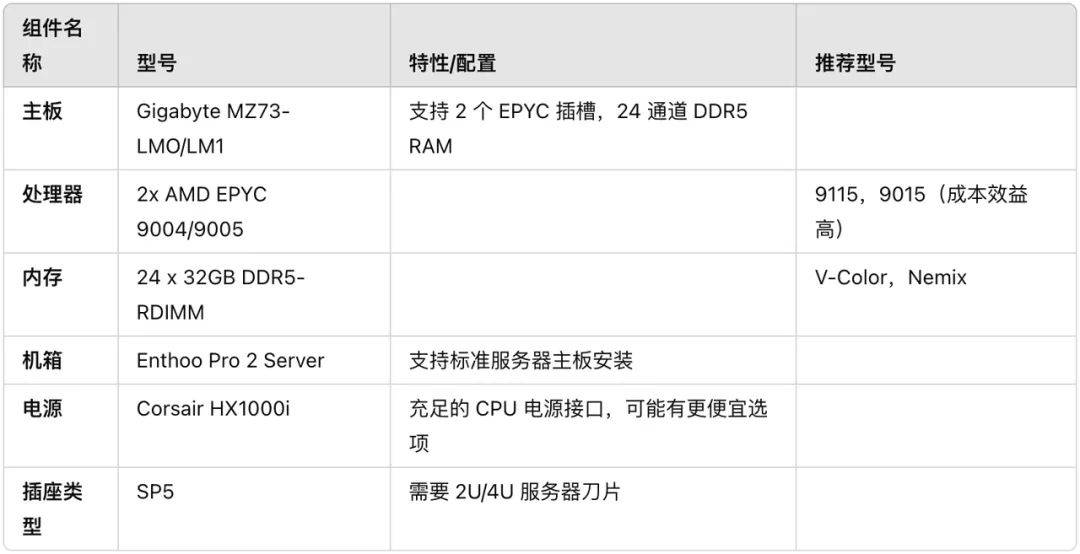
Matthew Carrigan, ingénieur chez Hugging Face, a récemment présenté une configuration matérielle et logicielle exécutant le modèle DeepSeek-R1 complet, la quantification Q8 et aucune distillation sur la plate-forme X, qui coûte environ 6 000 $.
Ci-joint le lien de configuration complet :
https://x.com/carrigmat/status/1884244369907278106
Plus près de chez nous, avons-nous vraiment besoin de déployer localement une version distillée de DeepSeek R1 ?
Ma suggestion n'est pas de considérer ces petits modèles distillés R1 comme des Tesla. Au mieux, ils ressemblent davantage à Wuling Hongguang. Ils peuvent courir, mais leurs performances sont très différentes, ou il leur manque des bras et des jambes.
D’après l’expérience du déploiement local des capacités de base de connaissances personnalisées les plus couramment utilisées, l’effet n’est pas satisfaisant. Lorsqu'il est confronté à des problèmes spécifiques, il ne peut pas « découvrir avec précision quel est le problème » ou simplement l'inventer, et son exactitude est inquiétante.
Pour la grande majorité des utilisateurs, la meilleure solution consiste à utiliser la version officielle ou à utiliser une plate-forme tierce. Cela ne nécessite pas de coûts matériels coûteux ni de soucis de performances limitées.
Même après avoir longtemps lutté, vous constaterez qu'au lieu d'investir beaucoup de temps, d'énergie et d'argent pour déployer ces petits modèles localement, il vaut mieux prendre un bon repas après avoir quitté le travail.
Pour les utilisateurs d'entreprise, les développeurs ou les utilisateurs ayant des besoins particuliers en matière de confidentialité des données, le déploiement local reste une option à considérer, mais seulement si vous comprenez pourquoi vous en avez besoin et ses diverses limites.
Vous trouverez ci-joint les questions et réponses de Xiaobai :
- Q : Puis-je déployer DeepSeek sur un ordinateur ordinaire ?
Réponse : La version complète de DeepSeek a des exigences informatiques plus élevées. Cependant, si vous souhaitez simplement l'utiliser pour des opérations simples, vous pouvez choisir quelques petits modèles de distillation, mais vous devez quand même faire ce que vous pouvez. - Q : Quelle est la version distillée de DeepSeek R1 ?
Réponse : Le modèle distillé est une version « simplifiée » avec des exigences matérielles inférieures et une vitesse d'exécution plus rapide. - Q : Puis-je utiliser DeepSeek sans Internet ?
R : Si vous choisissez de déployer DeepSeek localement, vous pouvez l'utiliser sans Internet. Si vous l'utilisez via le cloud ou une plateforme tierce, vous aurez besoin d'une connexion Internet pour y accéder. - Q : Mes données personnelles sont-elles en sécurité lorsque j'utilise DeepSeek ?
Réponse : Si vous choisissez de déployer DeepSeek localement, vos données ne seront pas téléchargées vers le cloud, qui est plus sécurisé. Si vous utilisez la version en ligne, assurez-vous de choisir une plateforme de services digne de confiance pour protéger la vie privée.
Auteur : Mo Chongyu, Lin
# Bienvenue pour suivre le compte public officiel WeChat d'Aifaner : Aifaner (ID WeChat : ifanr). Un contenu plus passionnant vous sera fourni dès que possible.
Ai Faner | Lien original · Voir les commentaires · Sina Weibo