
Personne ne sait exactement comment fonctionne la mise en cache dynamique du M3, mais j’ai une théorie

Lors de l'événement « Scary Fast » d'Apple , une fonctionnalité a attiré mon attention comme aucune autre : la mise en cache dynamique. Probablement comme la plupart des gens qui regardaient la présentation, j'ai eu une réaction : « Comment l'allocation de mémoire augmente-t-elle les performances ?
Apple a basé ses débuts sur la nouvelle puce M3 autour d'une fonctionnalité « fondamentale » qu'il appelle Dynamic Caching pour le GPU. L'explication simplifiée d'Apple ne précise pas exactement ce que fait la mise en cache dynamique, et encore moins comment elle améliore les performances du GPU sur le M3.
J'ai approfondi les architectures GPU typiques et envoyé quelques questions directes pour savoir ce qu'est exactement la mise en cache dynamique. Voici ma meilleure compréhension de ce qui est sans aucun doute la fonctionnalité la plus dense techniquement qu’Apple ait jamais proposée à une marque.
Qu’est-ce que la mise en cache dynamique exactement ?

La mise en cache dynamique est une fonctionnalité qui permet aux puces M3 d'utiliser uniquement la quantité précise de mémoire dont une tâche particulière a besoin. Voici comment Apple le décrit dans le communiqué de presse officiel : « La mise en cache dynamique, contrairement aux GPU traditionnels, alloue l'utilisation de la mémoire locale dans le matériel en temps réel. Avec Dynamic Caching, seule la quantité exacte de mémoire nécessaire est utilisée pour chaque tâche. Il s’agit d’une première dans l’industrie, transparente pour les développeurs et la pierre angulaire de la nouvelle architecture GPU. Cela augmente considérablement l’utilisation moyenne du GPU, ce qui augmente considérablement les performances des applications et des jeux professionnels les plus exigeants.
À la manière typique d'Apple, de nombreux aspects techniques sont intentionnellement obscurcis pour se concentrer sur le résultat. Il y en a juste assez pour comprendre l'essentiel sans dévoiler la sauce secrète ni confondre le public avec le jargon technique. Mais le point général à retenir semble être que la mise en cache dynamique permet au GPU d'avoir une allocation de mémoire plus efficace. Assez simple, non ? Eh bien, on ne sait toujours pas exactement comment l'allocation de mémoire « augmente l'utilisation moyenne » ou « augmente considérablement les performances ».
Pour tenter ne serait-ce que de comprendre la mise en cache dynamique, nous devons prendre du recul pour examiner le fonctionnement des GPU. Contrairement aux processeurs, les GPU excellent dans la gestion de charges de travail massives en parallèle. Ces charges de travail sont appelées shaders, qui sont les programmes exécutés par le GPU. Pour utiliser efficacement un GPU, les programmes doivent exécuter une tonne de shaders à la fois. Vous souhaitez utiliser autant de cœurs disponibles que possible.
Cela conduit à un effet que Nvidia appelle la « queue ». Une charge de shaders s'exécute en même temps, puis il y a une baisse d'utilisation tandis que davantage de shaders sont envoyés pour être exécutés sur des threads (ou plus précisément, des blocs de threads sur un GPU). Cet effet s'est reflété dans la présentation d'Apple lorsqu'il a expliqué la mise en cache dynamique, car l'utilisation du GPU a atteint un pic avant de toucher le fond.
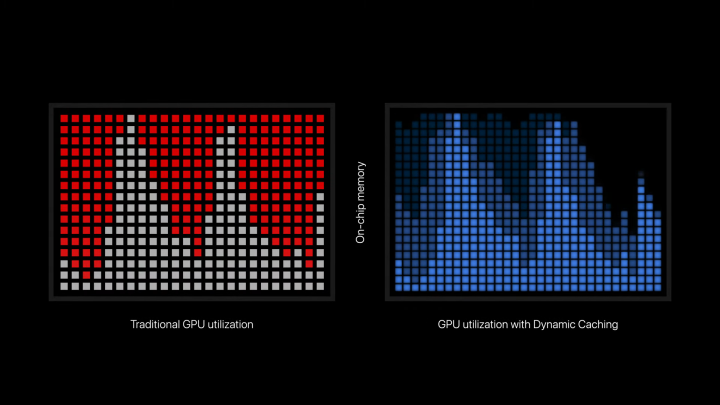
Comment cela joue-t-il dans la mémoire ? Les fonctions de votre GPU lisent les instructions de la mémoire et écrivent la sortie de la fonction dans la mémoire. De nombreuses fonctions devront également accéder à la mémoire plusieurs fois lors de leur exécution. Contrairement à un CPU où la latence de la mémoire via la RAM et le cache est extrêmement importante en raison du faible niveau de fonctions parallèles, la latence de la mémoire sur un GPU est plus facile à masquer. Ce sont des processeurs hautement parallèles, donc si certaines fonctions fouillent en mémoire, d'autres peuvent s'exécuter.
Cela fonctionne lorsque tous les shaders sont faciles à exécuter, mais que les charges de travail exigeantes auront des shaders très complexes. Lorsque l'exécution de ces shaders est planifiée, la mémoire nécessaire à leur exécution sera allouée, même si elle n'est pas nécessaire. Le GPU divise une grande partie de ses ressources en une seule tâche complexe, même si ces ressources seront gaspillées. Il semble que la mise en cache dynamique soit la tentative d'Apple d'utiliser plus efficacement les ressources disponibles sur le GPU, garantissant que ces tâches complexes ne prennent que ce dont elles ont besoin.
Cela devrait, en théorie, augmenter l'utilisation moyenne du GPU en permettant l'exécution simultanée d'un plus grand nombre de tâches, plutôt que d'avoir un ensemble plus restreint de tâches exigeantes engloutissant toutes les ressources disponibles pour le GPU. L'explication d'Apple se concentre d'abord sur la mémoire, donnant l'impression que l'allocation de mémoire à elle seule augmente les performances. D'après ma compréhension, il semble qu'une allocation efficace permette à davantage de shaders de s'exécuter en même temps, ce qui entraînerait alors une augmentation de l'utilisation et des performances.
Utilisé ou alloué
Un aspect majeur qui est essentiel pour comprendre ma tentative d’explication de la mise en cache dynamique est la manière dont les shaders se branchent. Les programmes exécutés par votre GPU ne sont pas toujours statiques. Ils peuvent changer en fonction de différentes conditions, ce qui est particulièrement vrai dans les shaders volumineux et complexes comme ceux requis pour le lancer de rayons. Ces shaders conditionnels doivent allouer des ressources pour le pire scénario possible, ce qui signifie que certaines ressources pourraient être gaspillées.
Voici comment Unity explique les shaders de branchement dynamique dans sa documentation : « Pour tout type de branchement dynamique, le GPU doit allouer de l'espace de registre pour le pire des cas. Si une branche est beaucoup plus coûteuse que l’autre, cela signifie que le GPU gaspille de l’espace de registre. Cela peut conduire à moins d’invocations du programme shader en parallèle, ce qui réduit les performances.
Il semble qu'Apple cible ce type de branchement avec la mise en cache dynamique, permettant au GPU d'utiliser uniquement les ressources dont il a besoin plutôt que de les gaspiller. Il est possible que la fonctionnalité ait des implications ailleurs, mais on ne sait pas exactement où et quand la mise en cache dynamique entre en jeu pendant qu'un GPU exécute ses tâches.
Encore une boîte noire

Bien sûr, je dois noter que tout cela n’est que ma compréhension, bricolée à partir du fonctionnement traditionnel des GPU et de ce qu’Apple a officiellement déclaré. Apple pourrait éventuellement publier plus d'informations sur la façon dont tout cela fonctionne, mais en fin de compte, les détails techniques de la mise en cache dynamique n'ont pas d'importance si Apple est effectivement en mesure d'améliorer l'utilisation et les performances du GPU.
En fin de compte, Dynamic Caching est un terme commercialisable pour désigner une fonctionnalité profondément ancrée dans l’architecture d’un GPU. Essayer de comprendre cela sans être quelqu'un qui conçoit des GPU conduira inévitablement à des idées fausses et à des explications réductrices. En théorie, Apple aurait pu simplement supprimer l’image de marque et laisser l’architecture parler d’elle-même.
Si vous cherchiez un aperçu plus approfondi de ce que la mise en cache dynamique pourrait faire dans le GPU du M3, vous avez maintenant une explication possible. Ce qui est important, c'est la performance du produit final, et nous n'aurons pas longtemps à attendre que les premiers appareils M3 d'Apple soient disponibles au public pour que nous puissions tous le découvrir. Mais d'après les performances et les démos que nous avons vues jusqu'à présent, cela semble certainement prometteur.