
« Prendre de l’avance » sur GPT-5 ! Google lance le package d’IA le plus puissant, avec l’abonnement d’IA le plus cher jamais proposé, au prix de 1 800 yuans par mois

La veille de la Google I/O de l'année dernière, OpenAI a lancé GPT-4o.
Les situations offensives et défensives sont différentes cette année.
Il y a quelques jours, OpenAI a révélé que GPT-5 serait tout-en-un, intégrant divers produits. Tout à l'heure, Google a mis en œuvre cette idée lors de la conférence I/O et a directement sorti son groupe familial d'IA le plus puissant de tous les temps.
Depuis la sortie des modèles Gemini 2.5 Pro et Flash, jusqu'au mode AI, en passant par Veo 3, Imagen 4 et les kits AI pour développeurs et créateurs, Google a presque compressé le chemin du modèle au produit en une seule conférence de presse.
Pour être plus précis, les scénarios d'application d'IA les plus en vogue du moment ont été « pré-enterrés » par Google dans ses interfaces de produits, ce qui fait comprendre aux gens qu'il est toujours l'un des géants mondiaux de l'IA avec la plus grande force d'ingénierie et les capacités d'intégration écologique.
Il n’est pas étonnant que de nombreux internautes aient plaisanté en disant qu’après une conférence de presse de près de deux heures, un grand nombre de start-ups mourraient aux mains de Google.
Il n'est cependant pas difficile de constater que certaines fonctionnalités de la conférence de presse sont encore au stade de la « bande-annonce » et des tests à petite échelle, et qu'elles sont peut-être encore loin d'être véritablement mises en œuvre.

Aidez-moi à « acheter des billets + trouver des sièges + remplir des formulaires » en une seule fois, le nouveau volume de recherche de l'IA de Google devient fou
L’IA réécrit la logique sous-jacente de la recherche.
Lors de la conférence I/O de l'année dernière, Google a lancé la fonctionnalité AI Overviews, qui compte désormais plus de 1,5 milliard d'utilisateurs actifs par mois.
L’IA générative a progressivement changé la façon dont les gens effectuent des recherches, mais elle implique que nous ne nous contentons plus de saisir des questions simples dans le champ de recherche, mais que nous posons plutôt des questions plus complexes, plus longues et plus multimodales.
Aujourd'hui, Google a une fois de plus intensifié ses efforts pour intégrer la recherche et l'IA, en lançant une expérience de recherche IA de bout en bout – AI Mode.
Comme l'a présenté le PDG de Google, Sundar Pichai, il s'agit du formulaire de recherche d'IA le plus puissant jamais développé par Google. Il dispose non seulement de capacités de raisonnement et de compréhension multimodale plus avancées, mais prend également en charge une exploration approfondie via des questions contextuelles et des liens Web.

Par exemple, lorsqu'un utilisateur est confronté à une question de recherche qui nécessite une interprétation complexe, le mode IA peut activer le mécanisme de « recherche approfondie », raisonner entre différentes informations et générer un rapport de citation de niveau expert en quelques minutes, vous faisant ainsi gagner des heures de recherche.
Dans le même temps, Google a également intégré les capacités multimodales du projet Astra dans la recherche pour améliorer encore l'interactivité en temps réel de la recherche. Avec la fonction Search Live, les utilisateurs peuvent simplement allumer leur caméra pour poser des questions et obtenir des commentaires en temps réel.
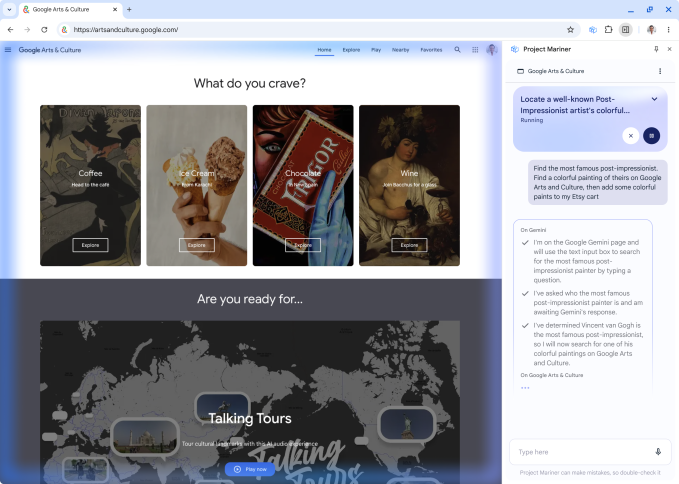
Cette année est la première année d'Agent, et Google a également lancé avec réflexion la fonctionnalité Project Mariner Agent pour aider les utilisateurs à effectuer leurs tâches plus efficacement.
Par exemple, avec une seule phrase, « Aidez-moi à trouver deux billets abordables pour le match de ce samedi, situé au niveau inférieur », le mode IA peut rechercher automatiquement des options sur plusieurs plateformes de billetterie, comparer les prix et l'inventaire en temps réel et effectuer des opérations fastidieuses telles que le remplissage de formulaires, améliorant ainsi considérablement l'efficacité.
Alimenté par le modèle Gemini et le Google Shopping Graph, le mode Google AI peut vous aider à affiner vos produits et vous inspirer. Si vous voulez voir à quoi ressemblent les vêtements sur vous, téléchargez simplement une photo de vous pour essayer des vêtements virtuellement.
De plus, le mode IA dispose également de puissantes capacités de personnalisation. Il peut fournir des suggestions personnalisées en fonction des préférences contextuelles de l'utilisateur et générer des graphiques et des résultats de visualisation, en particulier dans les recherches sportives et financières.
Cette fonctionnalité est désormais entièrement lancée aux États-Unis et sera étendue à davantage de régions à l’avenir.
En étant capable d'écrire du code et d'enregistrer des jetons, Gemini 2.5 obtient le personnage de « maître étudiant »
En termes de capacités du modèle, Google a publié la version I/O de Gemini 2.5 Pro, qui a dominé les classements.
Désormais, Gemini 2.5 Pro introduit un mode d'amélioration de l'inférence appelé « Deep Think ». Cette fonctionnalité prend en compte plusieurs hypothèses avant de générer une réponse, offrant ainsi une compréhension plus approfondie du contexte de la question.

2.5 Pro Deep Think s'est classé premier aux Olympiades mathématiques des États-Unis 2025 (USAMO) et à LiveCodeBench (benchmark de programmation), et a obtenu un score de 84,0 % au MMMU (test de raisonnement multimodal).
Google a toutefois déclaré qu'il consacrerait plus de temps à la réalisation d'évaluations de sécurité de pointe et demanderait des conseils supplémentaires aux experts en sécurité. Dans un premier temps, la fonctionnalité Deep Think sera actuellement ouverte à un petit nombre de testeurs via l’API Gemini.
Le Gemini 2.5 Flash, axé sur l'efficacité, a également été mis à niveau.
La nouvelle version 2.5 de Flash présente des améliorations dans des critères clés tels que le raisonnement, la multimodalité, le code et le contexte long, tout en étant plus efficace, avec 20 à 30 % de jetons en moins utilisés dans l'évaluation.
Flash 2.5 est désormais disponible pour tous dans l'application Gemini et sera généralement publié début juin pour les développeurs via Google AI Studio et pour les entreprises via Vertex AI.
En termes d'expérience de développement, 2.5 Pro et 2.5 Flash introduiront la fonction « Résumé des pensées » dans Gemini API et Vertex AI, qui peut présenter le chemin de raisonnement du modèle de manière structurée avec des titres, des informations clés et des outils d'appel.
Les développeurs en bénéficieront également. Google a annoncé qu'il prendrait officiellement en charge les outils MCP dans l'API et le SDK Gemini, permettant aux développeurs d'accéder facilement à davantage d'outils open source et d'écosystèmes de plug-ins.
La musique, les films et les images sont tous disponibles en ligne. Google a fait de l'IA un succès
Lors de cette conférence, Google a présenté une nouvelle génération de modèles d'images et de vidéos : Veo 3 et Imagen 4.
Contrairement à la génération vidéo traditionnelle, Veo 3 est un modèle de génération vidéo qui prend en charge l'audio. Il peut simuler la circulation, les chants d'oiseaux et même les conversations des personnages dans les scènes de rue urbaines, améliorant considérablement le sentiment d'immersion.
Le modèle génère non seulement des vidéos basées sur des invites de texte et d'image, mais synchronise également avec précision l'environnement physique avec la synchronisation labiale, améliorant considérablement le réalisme de la création vidéo.
Veo 3 est actuellement disponible pour les abonnés Ultra sur l'application Gemini et la plateforme Flow, et est pris en charge pour les utilisateurs d'entreprise sur la plateforme Vertex AI.

Le Flow mentionné ci-dessus est un outil de création de films IA créé par Google pour les créateurs.
Les utilisateurs décrivent simplement les scènes de films en langage naturel pour gérer les acteurs, les lieux, les accessoires et le style, générant automatiquement des segments narratifs. Flow est désormais disponible pour les utilisateurs de Gemini Pro et Ultra aux États-Unis, avec un déploiement mondial en cours.
En termes de génération d'images, la nouvelle version d'Imagen 4 a amélioré la précision et la vitesse, et peut afficher de manière réaliste des tissus, des gouttelettes d'eau et des poils d'animaux en détail, tout en étant capable de générer des styles plus abstraits.
Il prend en charge la résolution 2K et plusieurs rapports hauteur/largeur, et est considérablement optimisé en termes de composition et d'orthographe, ce qui le rend adapté à la création de cartes de vœux, d'affiches et même de bandes dessinées.
Imagen 4 est disponible aujourd’hui dans Gemini, Whisk, Vertex AI et dans Slides, Vids et Docs de Workspace. Il est rapporté qu'une version dix fois plus rapide sera lancée à l'avenir.

En termes de création musicale, Google a élargi l'accès au Music AI Sandbox propulsé par Lyria 2 et a lancé le modèle de génération de musique interactive Lyria RealTime. Le modèle est désormais disponible pour les développeurs via l'API et AI Studio.
Considérant que le contenu généré par Veo 3, Imagen 4 et Lyria 2 continuera à porter le filigrane SynthID, Google a publié un nouveau détecteur SynthID.
Les utilisateurs n'ont qu'à télécharger des fichiers pour identifier s'ils contiennent des filigranes SynthID, qui sont utilisés pour lutter contre la contrefaçon et retracer la source du contenu de l'IA.
Google veut créer un « modèle mondial » qui peut même vous aider à accomplir des tâches ?
Google espère faire de Gemini un « modèle mondial » capable de planifier, de comprendre et de simuler tous les aspects du monde réel.
Le PDG de Google DeepMind, Demis Hassabis, a déclaré que cette direction est l'un des concepts fondamentaux du projet Astra.

Au cours de l’année écoulée, Google a progressivement intégré la compréhension vidéo, le partage d’écran, les fonctions de mémoire, etc. dans Gemini Live. Désormais, la nouvelle sortie vocale de Gemini a été ajoutée avec un son natif, qui est plus naturel ; Les capacités de mémoire et d'utilisation de l'ordinateur sont également améliorées simultanément.
En outre, Google étudie également comment utiliser les capacités des agents pour aider les utilisateurs à gérer le multitâche.
Le projet Mariner en fait partie et peut réaliser jusqu'à dix tâches simultanément, telles que la recherche d'informations, la réservation, les achats et la recherche. Il est désormais disponible pour les utilisateurs d'Ultra aux États-Unis et sera bientôt intégré à l'API Gemini et à d'autres produits de base.
Un grand nombre de nouvelles fonctionnalités d’IA sont publiées. Une véritable fonctionnalité révolutionnaire va-t-elle émerger ?
NotebookLM a officiellement annoncé hier qu'elle était devenue l'application de productivité n° 2 et l'application globale n° 9 de l'App Store dans les 24 heures suivant son lancement.
En tant qu'exploration importante de Google dans les outils de prise de notes d'IA, NotebookLM fournit des fonctions telles que l'aperçu audio et la cartographie mentale.
Parmi eux, les aperçus audio prennent actuellement en charge plus de 80 langues, et cette semaine, Google a également annoncé qu'il introduirait une plus grande personnalisation de cette fonctionnalité. Les utilisateurs peuvent choisir la longueur du résumé en fonction de leurs besoins, qu'il s'agisse d'une navigation rapide ou d'une lecture approfondie.
Cette fonctionnalité sera d’abord disponible en anglais et sera étendue à d’autres langues ultérieurement.
Dans le même temps, Google répond également aux demandes des utilisateurs en matière de présentation visuelle et ajoutera bientôt une fonction d'aperçu vidéo à NotebookLM. Les utilisateurs peuvent convertir le contenu des notes en vidéos éducatives en un seul clic, transmettant ainsi des informations de manière plus intuitive.

Dans le domaine de la programmation de l'IA, Google a également apporté les dernières avancées de Jules.
Cet assistant de codage autonome, initialement apparu dans Google Labs, peut comprendre le code et effectuer de manière autonome des tâches de développement telles que l'écriture de tests, la création de fonctions et la correction de bugs. Il est désormais officiellement entré dans la phase de test bêta publique.

De plus, Google a lancé un nouveau service d’abonnement, Google AI Ultra.
Le plan offre aux utilisateurs professionnels un accès illimité aux modèles les plus puissants et aux fonctionnalités avancées de Google. Il convient aux professionnels tels que les cinéastes, les développeurs, les créatifs, etc., avec un abonnement mensuel de 249,99 USD.
Le programme est actuellement disponible aux États-Unis et sera bientôt étendu à d’autres pays.

En fait, l’IA ne manque pas de modèles ou de fonctions aujourd’hui. Ce qui est vraiment rare, c’est un « produit phare » qui peut être intégré dans la vie quotidienne et pénétrer véritablement l’esprit des utilisateurs grand public.
Google comprend certainement cela et travaille dur pour trouver la réponse.
Nous pouvons donc constater que lors de cette conférence de presse, Google a presque tout fait et tout mentionné : du texte, des images, des vidéos, de la musique, jusqu'à la recherche, les agents et les outils créatifs.
Les cartes ont été révélées et la technologie est en place. Désormais, tout ce dont Google a besoin, c’est d’une action qui répondra véritablement aux points sensibles des utilisateurs.
#Bienvenue pour suivre le compte public officiel WeChat d'iFanr : iFanr (ID WeChat : ifanr), où du contenu plus passionnant vous sera présenté dès que possible.