
Tout à l’heure, Huang Renxun a dévoilé la puce IA de bombe nucléaire de troisième génération ! Un superordinateur personnel effectue 1 000 000 milliards d’opérations par seconde, DeepSeek devient le plus grand gagnant

La conférence Nvidia GTC est devenue le Super Bowl de l'industrie de l'IA. Il n'y a pas de script ni de téléprompteur, et Huang Renxun s'est retrouvé coincé sur le câble à mi-chemin. Au contraire, c'est la partie la plus humaine de cette conférence sur l'IA à haute concentration. C'est déjà très rare dans les conférences technologiques d'aujourd'hui qui sont essentiellement répétées ou enregistrées à l'avance.

Tout à l'heure, Huang Renxun a de nouveau publié une nouvelle génération de puces d'IA de niveau bombe nucléaire, mais il y a aussi un protagoniste caché dans cette conférence : DeepSeek.
En raison des améliorations apportées à l'IA des agents (Agentic AI) et aux capacités de raisonnement, la quantité de calcul requise est désormais au moins 100 fois supérieure à celle estimée à la même époque l'année dernière.
L’impact du raisonnement coût-efficacité sur l’industrie de l’IA, plutôt que la simple accumulation de puissance de calcul, est devenu le fil conducteur de cette conférence. NVIDIA veut devenir une usine d’IA, permettant à l’IA d’apprendre et de raisonner à une vitesse supérieure à celle des humains.
Le raisonnement est essentiellement qu’une usine produit des jetons et que la valeur de l’usine dépend de sa capacité à générer des revenus et des bénéfices. L’usine devait donc être construite avec une extrême efficacité.
La nouvelle « bombe nucléaire » NVIDIA que Jen-Hsun Huang a sortie nous dit également que la future concurrence en matière d'intelligence artificielle ne réside pas dans le modèle qui est le plus grand, mais dans celui qui présente le coût de raisonnement le plus bas et l'efficacité du raisonnement la plus élevée.
En plus de la nouvelle puce Blackwell, il existe également deux « True AI PC »
La nouvelle puce Blackwell porte le nom de code « Ultra », qui est la puce GB300 AI. Elle succède à la « puce AI la plus puissante du monde » B200 de l'année dernière et réalise une fois de plus une percée en termes de performances.
Blackwell Ultra inclura la solution à l'échelle rack NVIDIA GB300 NVL72, ainsi que le système NVIDIA HGX B300 NVL16.

Le Blackwell Ultra GB300 NVL72 sortira au second semestre de cette année. Les détails des paramètres sont les suivants :
- 1.1 Inférence EF FP4 : lors de l'exécution de tâches d'inférence de précision FP4, elle peut atteindre 1,1 ExaFLOPS (exaFLOPS).
- Formation EF FP8 de 0,36 : les performances sont de 1,2 ExaFLOPS lors de l'exécution de tâches de formation avec la précision FP8.
- 1,5X GB300 NVL72 : par rapport au GB200 NVL72, les performances sont 1,5 fois.
- 20 To HBM3 : Équipé de 20 To de mémoire HBM, soit 1,5 fois celle de la génération précédente
- 40 To de mémoire rapide : Il dispose de 40 To de mémoire rapide, soit 1,5 fois celle de la génération précédente.
- 14,4 To/s CX8 : prend en charge CX8, avec une bande passante de 14,4 To/s, soit 2 fois celle de la génération précédente.
Une seule puce Blackwell Ultra offrira les mêmes performances d'IA de 20 pétaflops (pétaflops) que son prédécesseur, mais avec plus de 288 Go de mémoire HBM3e.
Si le H100 est plus adapté à la formation de modèles à grande échelle et que le B200 fonctionne bien dans les tâches d'inférence, alors le B300 est une plate-forme multifonctionnelle capable de gérer l'inférence pré-formation, post-formation et IA.

NVIDIA a également spécifiquement souligné que Blackwell Ultra convient également aux agents d'IA et à « l'IA physique » utilisés pour former des robots et des véhicules autonomes.
Pour améliorer encore les performances du système, Blackwell Ultra sera également intégré aux plates-formes NVIDIA Spectrum-X Ethernet et NVIDIA Quantum-X800 InfiniBand pour fournir 800 Gb/s de débit quantitatif pour chaque GPU du système, aidant ainsi les usines d'IA et les centres de données cloud à traiter plus rapidement les modèles d'inférence d'IA.
En plus du rack NVL72, Nvidia a également lancé le DGX Station, un ordinateur de bureau contenant une seule puce GB300 Blackwell Ultra. En plus du Blackwell Ultra, cet hôte sera également équipé de 784 Go de la même mémoire système, d'un réseau NVIDIA ConnectX-8 SuperNIC intégré à 800 Gbit/s et peut prendre en charge 20 pétaflops de performances d'IA.

Le projet « mini-hôte » DIGITS précédemment présenté au CES 2025 est également officiellement nommé DGX Spark. Il est équipé de la super puce GB10 Grace Blackwell spécialement optimisée pour les ordinateurs de bureau. Elle peut fournir jusqu'à 1 000 000 milliards d'opérations informatiques d'IA par seconde et est utilisée pour le réglage et le raisonnement des derniers modèles de raisonnement d'IA, notamment le modèle de base mondial NVIDIA Cosmos Reason et le modèle de base du robot NVIDIA GR00T N1.
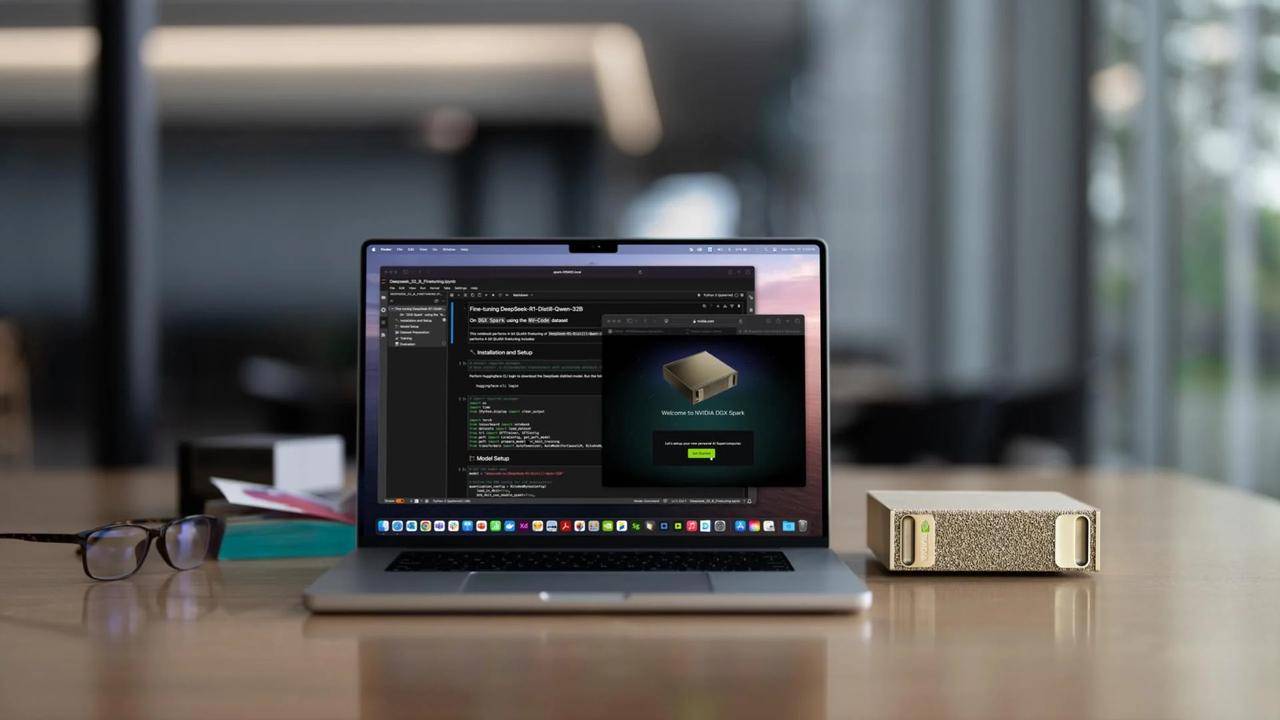
Huang Renxun a déclaré qu'avec DGX Station et DGX Spark, les utilisateurs peuvent exécuter de grands modèles localement ou les déployer sur d'autres cloud accélérés ou sur une infrastructure de centre de données telle que NVIDIA DGX Cloud.
C'est l'ordinateur de l'ère de l'IA.
Le système DGX Spark est disponible en précommande dès maintenant, tandis que la DGX Station devrait être lancée plus tard cette année auprès de partenaires tels que ASUS, Dell, HP et plus encore.
La puce IA de nouvelle génération Rubin est officiellement annoncée et sera lancée au second semestre 2026.
NVIDIA a toujours donné à son architecture le nom de scientifiques, et cette méthode de dénomination fait désormais partie de la culture de NVIDIA. Cette fois, NVIDIA a poursuivi cette pratique et a baptisé sa plate-forme de puces IA de nouvelle génération « Vera Rubin » en hommage à la célèbre astronome américaine Vera Rubin.
Huang Renxun a déclaré que les performances de Rubin seront 900 fois supérieures à celles de Hopper, tandis que Blackwell a réalisé une amélioration de 68 fois par rapport à Hopper.
Parmi eux, Vera Rubin NVL144 devrait sortir au second semestre 2026. Les informations sur les paramètres enregistrent le flux et ne lisent pas la version :
- 3.6 Inférence EF FP4 : lors de l'exécution de tâches d'inférence de précision FP4, elle peut atteindre 3,6 ExaFLOPS (exaFLOPS).
- 1.2 Formation EF FP8 : lors de l'exécution de tâches de formation avec la précision FP8, les performances sont de 1,2 ExaFLOPS.
- 3,3X GB300 NVL72 : par rapport au GB300 NVL72, les performances sont améliorées de 3,3 fois.
- 13 To/s HBM4 : Équipé du HBM4, la bande passante est de 13 To/s.
- 75 To de mémoire rapide : Il dispose de 75 To de mémoire rapide, soit 1,6 fois celle de la génération précédente.
- 260 To/s NVLink6 : prend en charge NVLink 6 avec une bande passante de 260 To/s, soit 2 fois celle de la génération précédente.
- 28,8 To/s CX9 : Prend en charge CX9 avec une bande passante de 28,8 To/s, soit 2 fois celle de la génération précédente.

La version standard de Rubin sera équipée de HBM4, qui offre des performances considérablement améliorées par rapport à la puce Hopper H100 actuelle.
Rubin a présenté un successeur nommé Grace CPU – Veru, qui contient 88 cœurs Arm personnalisés, chaque cœur prend en charge 176 threads et atteint une connexion à bande passante élevée de 1,8 To/s via NVLink-C2C.
Nvidia affirme que la conception personnalisée de Vera sera deux fois plus rapide que le processeur utilisé dans la puce Grace Blackwell de l'année dernière.
Lorsqu'elle est associée à un processeur Vera, la puissance de calcul de Rubin peut atteindre 50 pétaflops dans les tâches d'inférence, soit plus du double des 20 pétaflops de Blackwell. De plus, Rubin prend également en charge la mémoire HBM4 jusqu'à 288 Go, ce qui est également l'une des spécifications principales auxquelles les développeurs d'IA prêtent attention.

En fait, Rubin se compose de deux GPU, et ce concept de conception est similaire au GPU Blackwell actuellement sur le marché – ce dernier fonctionne également en assemblant deux puces indépendantes en un tout.
À partir de Rubin, Nvidia ne fera plus référence aux composants multi-GPU comme à un seul GPU comme c'était le cas avec Blackwell, mais les comptera plus précisément en fonction du nombre réel de puces GPU.
La technologie d'interconnexion a également été mise à niveau. Rubin est équipé d'un NVLink de sixième génération et d'une carte réseau CX9 prenant en charge 1 600 Gb/s, ce qui peut accélérer la transmission des données et améliorer la connectivité.
En plus de la version standard de Rubin, Nvidia prévoit également de lancer une version Ultra de Rubin.

Rubin Ultra NVL576 sera lancé au second semestre 2027. Les détails des paramètres sont les suivants :
- 15 Inférence EF FP4 : les performances atteignent 15 ExaFLOPS lors de l'exécution de tâches d'inférence avec la précision FP4.
- 5 Formation EF FP8 : exécution de 5 ExaFLOPS lors de l'exécution de tâches de formation avec une précision FP8.
- 14X GB300 NVL72 : par rapport au GB300 NVL72, les performances sont améliorées de 14 fois.
- 4,6 PB/s HBM4e : Équipé de la mémoire HBM4e, la bande passante est de 4,6 PB/s.
- 365 To de mémoire rapide : Le système dispose de 365 To de mémoire rapide, soit 8 fois celle de la génération précédente.
- 1,5 PB/s NVLink7 : prend en charge NVLink 7 avec une bande passante de 1,5 PB/s, 12 fois celle de la génération précédente.
- 115,2 To/s CX9 : Prend en charge CX9 avec une bande passante de 115,2 To/s, soit 8 fois celle de la génération précédente.
En termes de configuration matérielle, le système Veras de Rubin Ultra poursuit la conception de 88 cœurs Arm personnalisés, chaque cœur prend en charge 176 threads et fournit une bande passante de 1,8 To/s via NVLink-C2C.
En termes de GPU, Rubin Ultra intègre quatre GPU de taille réticule. Chaque GPU fournit 100 pétaflops de puissance de calcul FP4 et est équipé de 1 To de mémoire HBM4e, atteignant de nouveaux sommets en termes de performances et de capacité de mémoire.
Afin de maintenir une position solide face à une concurrence en évolution rapide sur le marché, le rythme de sortie des produits NVIDIA a été raccourci à une fois par an. Lors de la conférence de presse, Huang a également annoncé officiellement le nom de la puce IA de nouvelle génération : le physicien Feynman.
À mesure que la taille des usines d’IA continue de croître, l’importance de l’infrastructure réseau devient de plus en plus importante.
À cette fin, NVIDIA a lancé Spectrum-X  et les commutateurs de réseau optique en silicium Quantum-X, conçus pour aider les usines d'IA à connecter des millions de GPU sur tous les sites tout en réduisant considérablement la consommation d'énergie et les coûts d'exploitation.
et les commutateurs de réseau optique en silicium Quantum-X, conçus pour aider les usines d'IA à connecter des millions de GPU sur tous les sites tout en réduisant considérablement la consommation d'énergie et les coûts d'exploitation.

Les commutateurs Spectrum-X Photonics sont disponibles dans une variété de configurations, notamment :
- Configuration à 128 ports 800 Gb/s ou 512 ports 200 Gb/s, avec une bande passante totale de 100 Tb/s
- Configuration 512 ports 800 Gb/s ou 2 048 ports 200 Gb/s, le débit total atteint 400 Tb/s
Le commutateur Quantum-X Photonics qui l'accompagne est basé sur la technologie SerDes 200 Gb/s, fournit des connexions InfiniBand 800 Gb/s à 144 ports et utilise une conception de refroidissement liquide pour refroidir efficacement les composants photoniques au silicium intégrés.
Les commutateurs Quantum-X Photonics offrent une vitesse 2x et une évolutivité 5x pour l'architecture informatique IA par rapport aux produits de la génération précédente.
Les commutateurs Quantum-X Photonics InfiniBand devraient être disponibles plus tard cette année, tandis que les commutateurs Ethernet Spectrum-X Photonics devraient être lancés en 2026.
Avec le développement rapide de l’IA, la demande de bande passante, de faible latence et de haute efficacité énergétique dans les centres de données a également considérablement augmenté.
Les commutateurs NVIDIA Spectrum-X Photonics utilisent une technologie d'intégration photonique appelée CPO. Son cœur est de mettre le moteur optique (c'est-à-dire une puce capable de traiter les signaux optiques) et les puces électroniques ordinaires (telles que les puces de commutation ou les puces ASIC) dans le même boîtier.
Les avantages de cette technique sont nombreux :
- Efficacité de transmission plus élevée : la distance étant raccourcie, le signal est transmis plus rapidement.
- Consommation d'énergie réduite : la distance est plus courte et moins d'énergie est nécessaire pour transmettre les signaux.
- Taille plus petite : en intégrant des composants optiques et électriques, la taille globale devient plus petite et l'utilisation de l'espace est plus élevée.
Dynamo, le « système d'exploitation » de l'usine à IA
Il n’y aura plus de centres de données à l’avenir, seulement des usines d’IA.
Huang Renxun a déclaré qu'à l'avenir, lorsque chaque industrie et chaque entreprise aura une usine, il y aura deux usines : l'une est l'usine où elles produisent réellement, et l'autre est l'usine d'IA, et Dynamo est un système d'exploitation spécialement conçu pour « l'usine d'IA ».
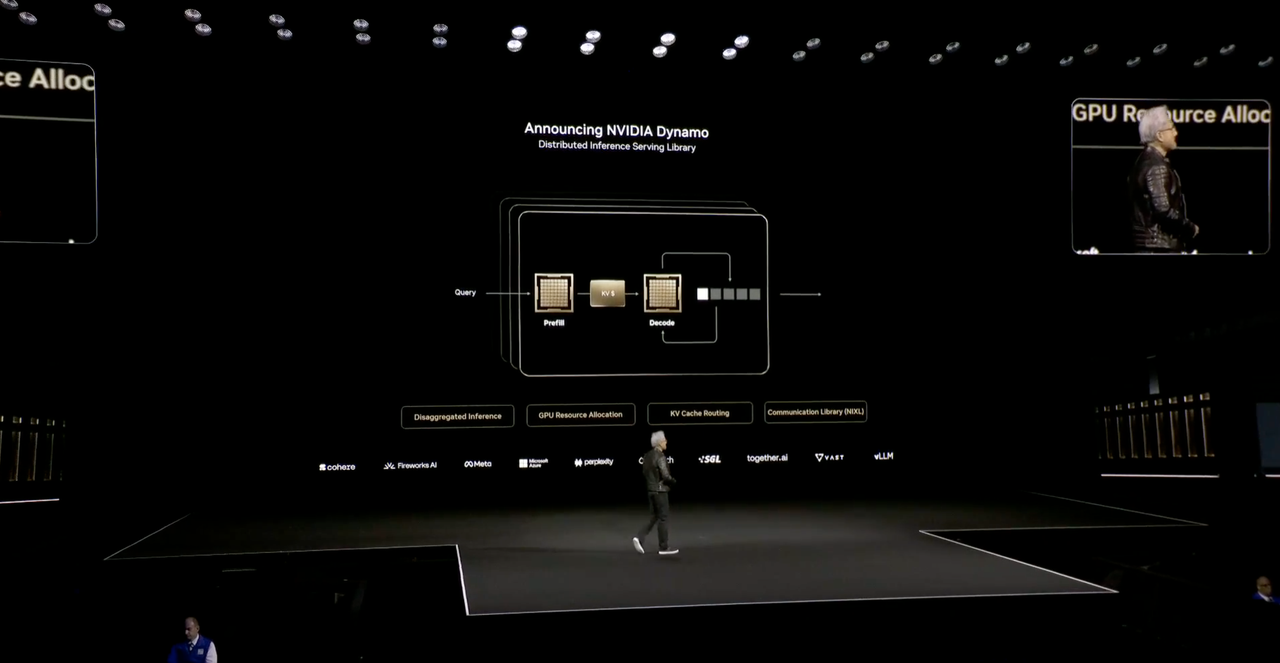
Dynamo est une bibliothèque de services de raisonnement distribué qui fournit des solutions open source pour les problèmes nécessitant des jetons mais ne parvenant pas à obtenir suffisamment de jetons.
En termes simples, Dynamo présente quatre avantages :
- Moteur de planification GPU, planifie dynamiquement les ressources GPU pour s'adapter aux besoins des utilisateurs
- Le routeur intelligent réduit le recalcul GPU des requêtes répétées et qui se chevauchent, libérant ainsi davantage de puissance de calcul pour gérer les nouvelles requêtes entrantes.
- Bibliothèque de communication à faible latence pour accélérer la transmission des données
- Gestionnaire de mémoire, intelligence pour les données d'inférence dans les périphériques de mémoire et de stockage à faible coût
Les robots humanoïdes ne seront jamais absents de leur apparition
Les robots humanoïdes sont une fois de plus devenus la finale de la conférence GTC. Cette fois, NVIDIA a présenté Isaac GR00T N1, le premier modèle fonctionnel de robot humanoïde open source au monde.

Huang Renxun a déclaré que l'ère de la robotique générale est arrivée. Avec l'aide du cadre de génération de données et d'apprentissage robot du noyau Isaac GR00T N1, les développeurs de robots du monde entier entreront dans la prochaine frontière de l'ère de l'IA.
Ce modèle utilise une architecture « double système » pour imiter les principes cognitifs humains :
- Système 1 : un modèle d'action à réflexion rapide qui imite les réactions ou l'intuition humaines
- Système 2 : Un modèle de réflexion lente pour une prise de décision réfléchie.
Avec le support du modèle de langage visuel, le Système 2 raisonne sur l'environnement et les instructions, puis planifie les actions. Le Système 1 convertit ces plans en actions du robot.
Le modèle de base du GR00T N1 est pré-entraîné à l'aide d'un raisonnement et de compétences généralisées de type humain, et les développeurs peuvent effectuer un post-entraînement avec des données réelles ou synthétiques pour répondre à des besoins spécifiques : qu'il soit capable d'effectuer des tâches spécifiques dans l'usine ou d'effectuer de manière autonome des tâches ménagères à la maison.
Huang a également annoncé Newton, un moteur physique open source développé en partenariat avec Google DeepMind et Disney Research.

Un robot équipé de la plate-forme Newton est également apparu sur scène. Huang l'a appelé « Bleu ». Il ressemblait au robot BDX de « Star Wars » et pouvait interagir avec Huang en utilisant la voix et le mouvement.
Avec 8 GPU, la vitesse d'inférence de DeepSeek-R1 est la plus rapide au monde
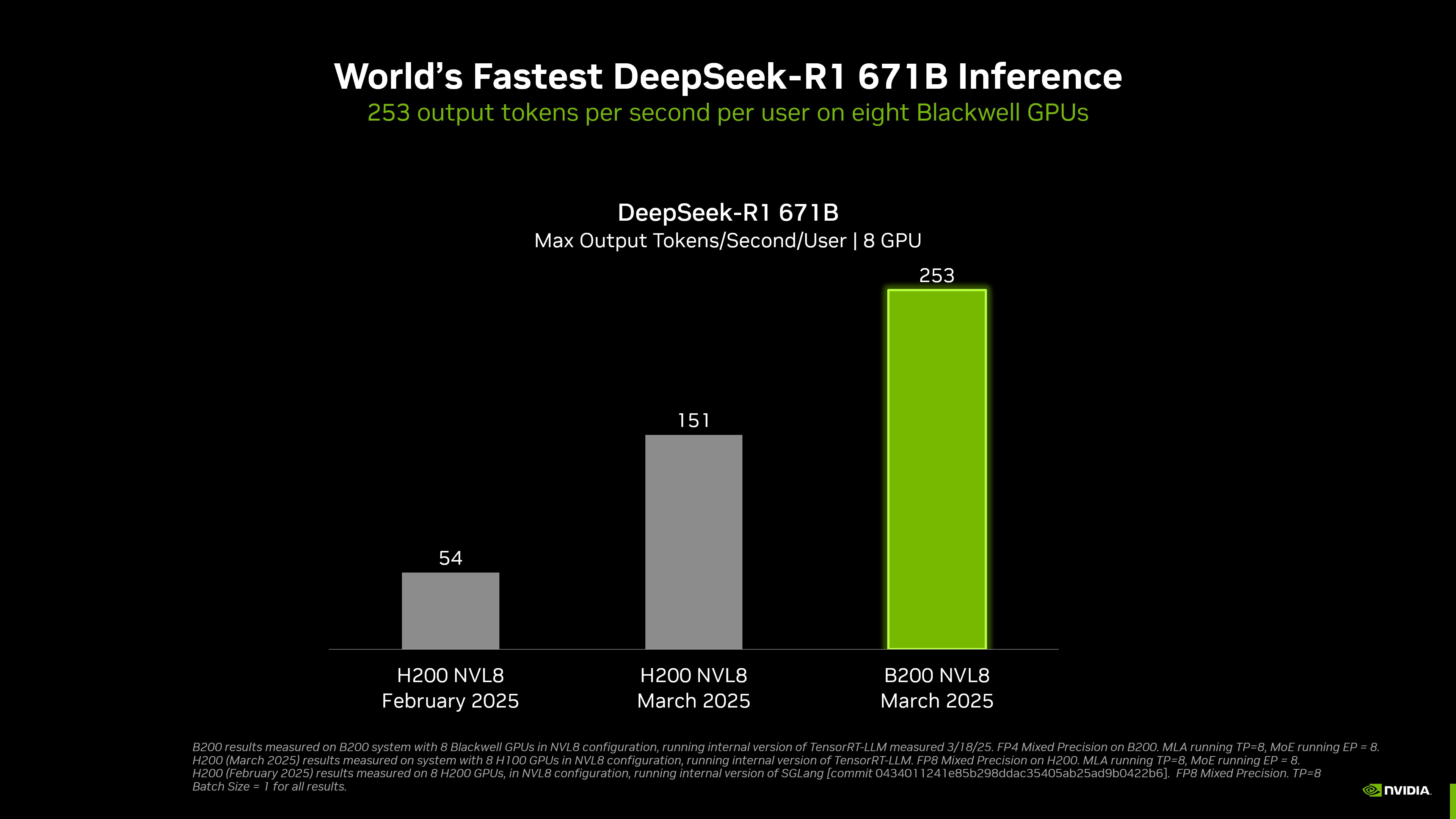
NVIDIA a réalisé l'inférence DeepSeek-R1 la plus rapide au monde.
Selon le site officiel, un système DGX équipé de 8 GPU Blackwell peut atteindre une vitesse de plus de 250 jetons par seconde et par utilisateur lors de l'exécution du modèle DeepSeek-R1 à 671 milliards de paramètres, ou atteindre un débit maximum de plus de 30 000 jetons par seconde.
Grâce à la combinaison du matériel et des logiciels, le débit de NVIDIA sur le modèle DeepSeek-R1 671B a été multiplié par environ 36 depuis janvier de cette année, et le rapport coût-efficacité par jeton a augmenté d'environ 32 fois.
Afin d'atteindre cet objectif, l'écosystème d'inférence complet de NVIDIA a été profondément optimisé pour l'architecture Blackwell. Il intègre non seulement des outils avancés tels que TensorRT-LLM et TensorRT Model Optimizer, mais prend également en charge de manière transparente les frameworks grand public tels que PyTorch, JAX et TensorFlow.
Sur des modèles tels que DeepSeek-R1, Llama 3.1 405B et Llama 3.3 70B, la plateforme DGX B200 avec une précision FP4 améliore le débit d'inférence de plus de 3 fois par rapport à la plateforme DGX H200.
Il convient de noter que le discours d'ouverture de cette conférence ne mentionnait pas l'informatique quantique, mais NVIDIA a spécialement organisé une journée quantique lors de cette conférence GTC et a invité les PDG de nombreuses sociétés d'informatique quantique populaires à y assister.
Il faut savoir que l'affirmation de Huang Renxun au début de l'année selon laquelle « l'informatique quantique mettra 20 ans pour être pratique » est toujours dans mes oreilles.
Derrière le changement de ton, elle est indissociable de la puce quantique topologique Majorana 1 de Microsoft, qui a mis 17 ans à développer et réaliser l'intégration de 8 qubits topologiques. Elle est également indissociable de la puce quantique de Google qui prétend accomplir une tâche qu'un ordinateur classique met 10^25 ans à traiter en 5 minutes, favorisant l'engouement pour l'informatique quantique.

La puce est sans aucun doute le point culminant, mais les débuts de certains logiciels méritent également l'attention.
Marc Andreessen, un célèbre investisseur de la Silicon Valley, a un jour affirmé que les logiciels dévoraient le monde. La logique fondamentale est que les logiciels sont en train de devenir l'infrastructure qui contrôle le monde physique grâce à la virtualisation, à l'abstraction et à la standardisation.
Non content d'être un « vendeur de pelles », NVIDIA a pour ambition de créer un « système d'exploitation de productivité » à l'ère de l'IA. De la conduite intelligente des voitures aux usines jumelles numériques dans l'industrie manufacturière, les cas présentés tout au long de la conférence sont des expressions concrètes de la conversion de la puissance de calcul des GPU en productivité industrielle.
En fait, qu'il s'agisse de la dernière puce de bombe nucléaire dévoilée lors de la conférence de presse ou de l'informatique quantique pariant sur l'avenir, les idées de Huang Renxun et la présentation du développement futur de l'IA lors de cette conférence de presse sont plus intéressantes que les paramètres techniques et indicateurs de performance actuels.

En introduisant la comparaison entre l'architecture Blackwell et Hopper, Huang Renxun n'a pas non plus oublié d'utiliser l'humour.
Il a utilisé comme exemple les données comparatives d'une usine de 100 MW, soulignant que l'architecture Hopper nécessite 45 000 puces et 400 racks, tandis que l'architecture Blackwell réduit considérablement les exigences matérielles grâce à une efficacité plus élevée.
Par conséquent, le résumé classique de Huang Renxun a été à nouveau rejeté : « plus vous achetez, plus vous économisez » (plus vous achetez, plus vous économisez). » Puis le sujet a changé et il a ajouté : « plus vous achetez, plus vous gagnez » (plus vous achetez, plus vous gagnez).
Alors que le domaine de l'IA passe de la formation au raisonnement, NVIDIA doit prouver que son écosystème logiciel et matériel est irremplaçable dans les scénarios de raisonnement.
D’une part, des géants tels que Meta et Google développent des puces d’IA auto-développées, ce qui pourrait détourner la demande du marché des GPU.
D'un autre côté, le lancement opportun des dernières puces IA de NVIDIA répond à l'impact des modèles open source tels que DeepSeek sur la demande de GPU et démontre des avantages technologiques dans le domaine du raisonnement. Il s'agit également de se prémunir contre les inquiétudes du marché concernant la demande croissante de formation.
Nvidia, dont la valorisation est récemment tombée à son plus bas niveau depuis 10 ans, a plus que jamais besoin d’une victoire substantielle.
# Bienvenue pour suivre le compte public officiel WeChat d'Aifaner : Aifaner (ID WeChat : ifanr). Un contenu plus passionnant vous sera fourni dès que possible.
Ai Faner | Lien original · Voir les commentaires · Sina Weibo