
Tout à l’heure, OpenAI a publié trois nouveaux modèles en une seule fois ! J’ai également créé un nouveau site internet à cet effet
Tout à l'heure, OpenAI a annoncé le lancement d'une nouvelle génération de modèles audio dans son API, comprenant des fonctions de synthèse vocale et de synthèse vocale, permettant aux développeurs de créer facilement de puissants agents vocaux.
Les principaux points forts du nouveau produit sont résumés ci-dessous
- gpt-4o-transcribe (parole en texte) : réduction significative du taux d'erreur de mots (WER), surpassant les modèles Whisper existants sur plusieurs benchmarks
- gpt-4o-mini-transcribe (parole en texte) : une version simplifiée de gpt-4o-transcribe, plus rapide et plus efficace
- gpt-4o-mini-tts (text-to-speech) : prenant en charge la « maniabilité » pour la première fois, les développeurs peuvent non seulement spécifier « quoi dire », mais également contrôler « comment le dire »
Selon OpenAI, le nouveau gpt-4o-transcribe a été formé depuis longtemps à l'aide d'ensembles de données audio diversifiés et de haute qualité, qui peuvent mieux capturer les nuances de la parole, réduire les erreurs de reconnaissance et améliorer considérablement la fiabilité de la transcription.
Par conséquent, gpt-4o-transcribe est plus adapté à la gestion de scénarios difficiles tels que des accents divers, des environnements bruyants et des vitesses de parole changeantes, tels que les centres d'appels clients, les transcriptions de réunions et d'autres domaines.
gpt-4o-mini-transcribe est basé sur l'architecture GPT-4o-mini et transfère les capacités des grands modèles grâce à la technologie de distillation des connaissances. Bien que le WER (le plus bas soit le mieux) soit légèrement supérieur à celui de la version complète, il est toujours meilleur que le modèle Whisper original et convient mieux aux scénarios d'application avec des ressources limitées mais nécessitant toujours une reconnaissance vocale de haute qualité.
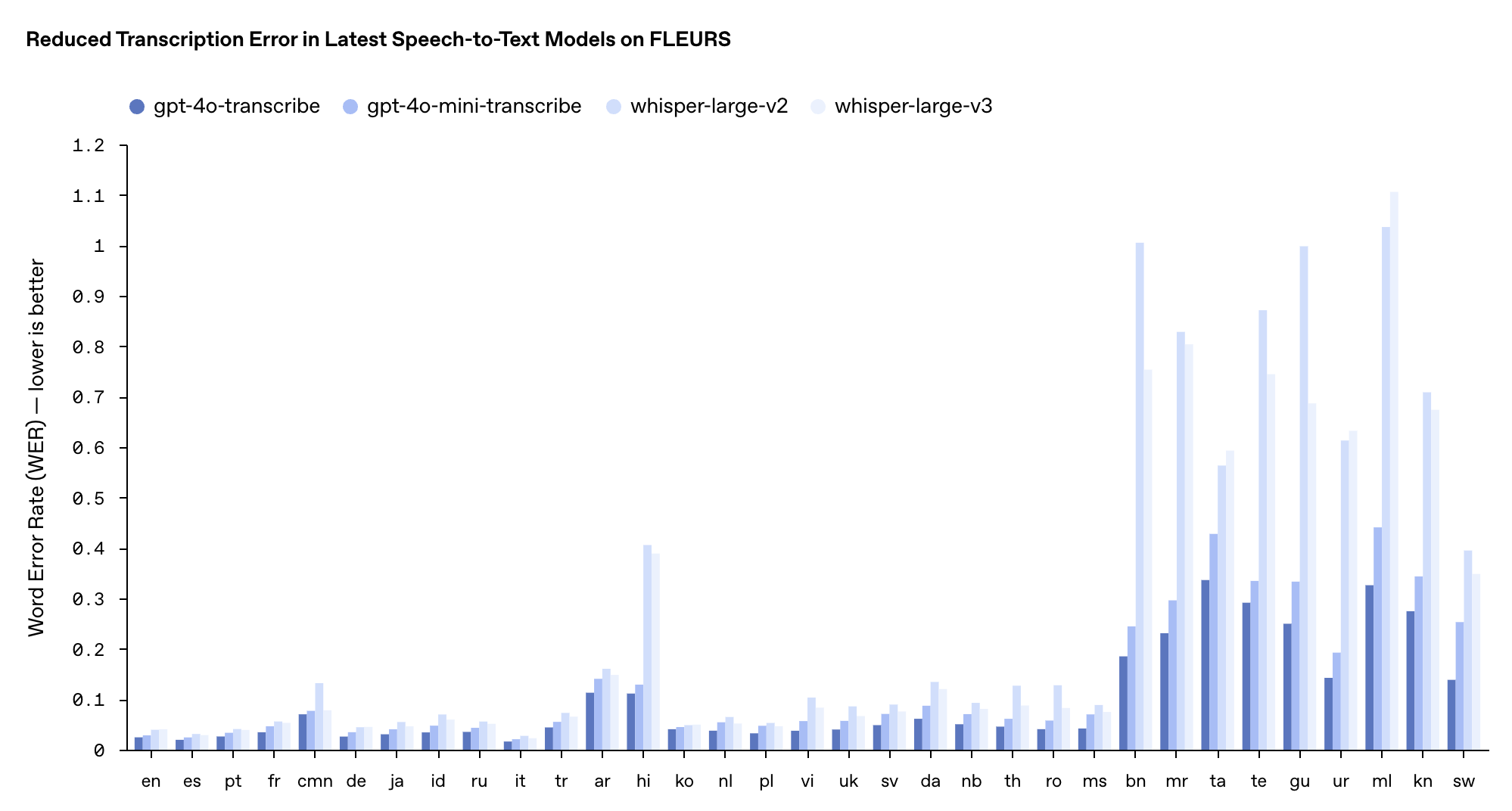
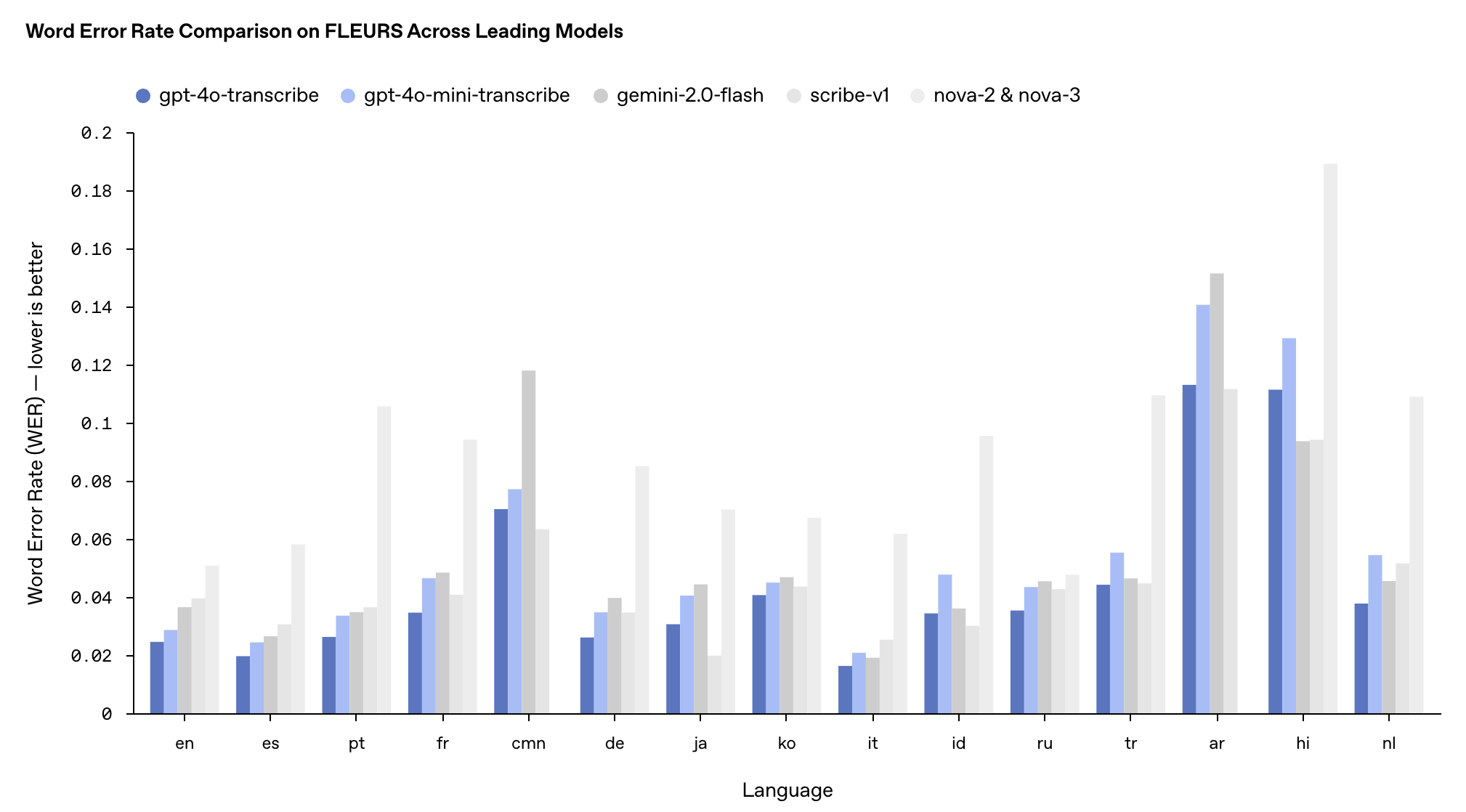
Les performances de ces deux modèles dans le test de référence multilingue FLEURS ont surpassé les modèles Whisper v2 et v3 existants, notamment en anglais, en espagnol et dans d'autres langues.
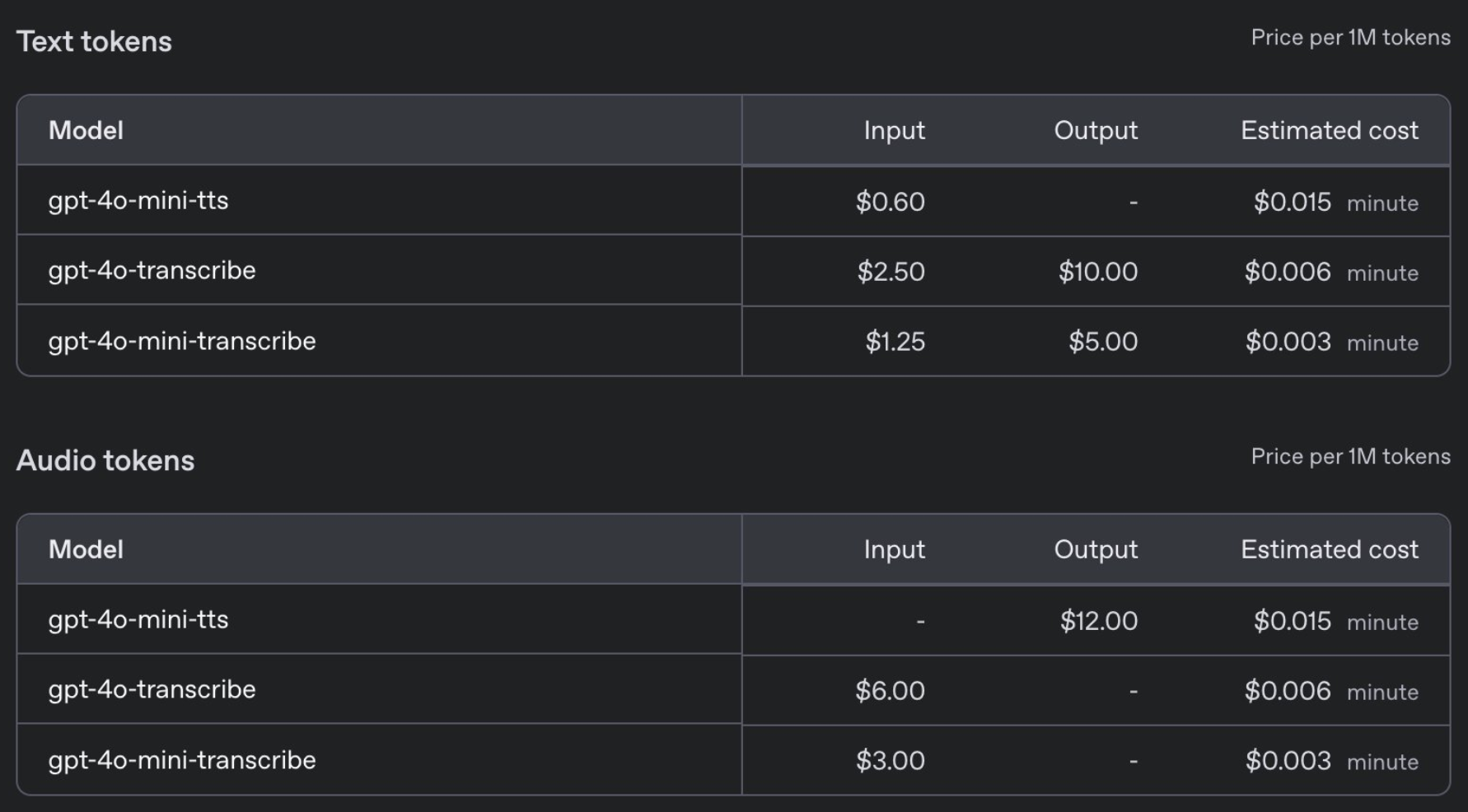
En termes de prix, GPT-4o-transcribe est au même prix que le modèle Whisper précédent, à 0,006 $ par minute, tandis que GPT-4o-mini-transcribe coûte la moitié du prix, à 0,003 $ par minute.
Dans le même temps, OpenAI a également publié un nouveau modèle de synthèse vocale gpt-4o-mini-tts. Pour la première fois, les développeurs peuvent non seulement spécifier quoi dire, mais aussi contrôler comment le dire.
Plus précisément, les développeurs peuvent prédéfinir une variété de styles de voix, tels que « Calme », « Surfeur », « Professionnel », « Chevalier médiéval », etc. Il peut également ajuster le style de voix en fonction d'instructions, telles que « Parlez comme un agent du service client compatissant ». Le prix est abordable à seulement 0,015 $ par minute.
La sécurité ne peut pas être prise à la légère, et OpenAI indique que gpt-4o-mini-tts sera surveillé en permanence pour garantir que sa sortie est cohérente avec le style de synthèse prédéfini.
Derrière ces avancées technologiques se cachent de nombreuses innovations d’OpenAI :
- Le nouveau modèle audio est construit sur l'architecture GPT-4o et GPT-4o-mini et est pré-entraîné à l'aide de véritables ensembles de données audio.
- Appliquez la méthode de distillation des connaissances à partir d'ensembles de données distillés créés par la méthode d'auto-jeu pour réaliser le transfert de connaissances des grands modèles vers les petits modèles.
- L’intégration de l’apprentissage par renforcement (RL) dans la technologie parole-texte peut améliorer considérablement la précision de la transcription et réduire les phénomènes « d’illusion ».
Lors de la diffusion en direct tôt le matin, OpenAI nous a montré un cas d'application d'Agent, consultant en mode IA.
Lorsque l'utilisateur a demandé « Quelle est ma dernière commande ? », le système a répondu sans problème : les shorts Patagonia commandés par l'utilisateur le 9 février ont été expédiés et le numéro de commande « AD 507 » a été fourni avec précision dans la question complémentaire.
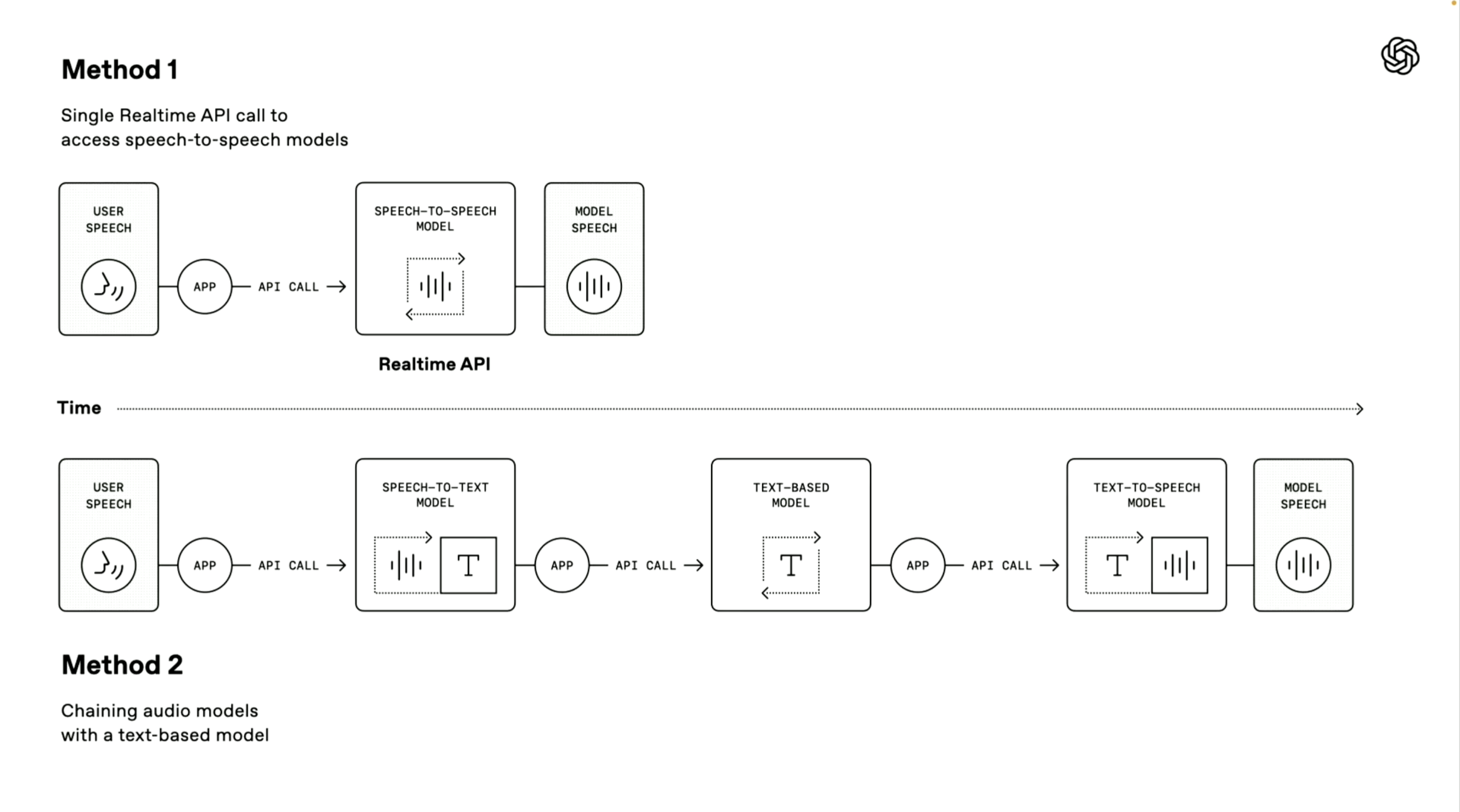
Il convient de mentionner que le démonstrateur OpenAI a également introduit deux voies techniques pour créer un agent vocal. Le premier « modèle parole-parole » utilise une méthode de traitement direct de bout en bout.
Le système peut recevoir directement les entrées vocales de l'utilisateur et générer des réponses vocales sans étapes de conversion intermédiaires. Cette méthode a une vitesse de traitement plus rapide et a été appliquée dans le mode vocal avancé et les services API en temps réel de ChatGPT. Elle est très adaptée aux scénarios nécessitant une vitesse de réponse extrêmement élevée.
La deuxième « méthode de la chaîne » est au centre de cette conférence.
Il décompose l'ensemble du processus de traitement en trois liens indépendants : d'abord, un modèle de synthèse vocale est utilisé pour convertir la parole de l'utilisateur en texte, puis un modèle de langage étendu (LLM) traite le contenu du texte et génère le texte de la réponse, et enfin, un modèle de synthèse vocale est utilisé pour convertir la réponse en sortie vocale naturelle.
Les avantages de cette méthode sont une conception modulaire, chaque composant peut être optimisé indépendamment ; les résultats du traitement sont plus stables, car la technologie de traitement de texte est généralement plus mature que le traitement audio direct ; et le seuil de développement est plus bas, les développeurs peuvent rapidement ajouter des fonctions vocales basées sur les systèmes de texte existants.
OpenAI apporte également plusieurs améliorations à ces systèmes d'interaction vocale :
- Prend en charge le streaming vocal pour une entrée et une sortie audio continues
- La fonction intégrée de suppression du bruit améliore la clarté de la parole.
- Détection sémantique de l'activité vocale, capable d'identifier quand un utilisateur a fini de parler
- Fournir des outils d'interface utilisateur de suivi pour aider les développeurs à déboguer les agents vocaux
Actuellement, ces nouveaux modèles audio sont disponibles pour les développeurs du monde entier.
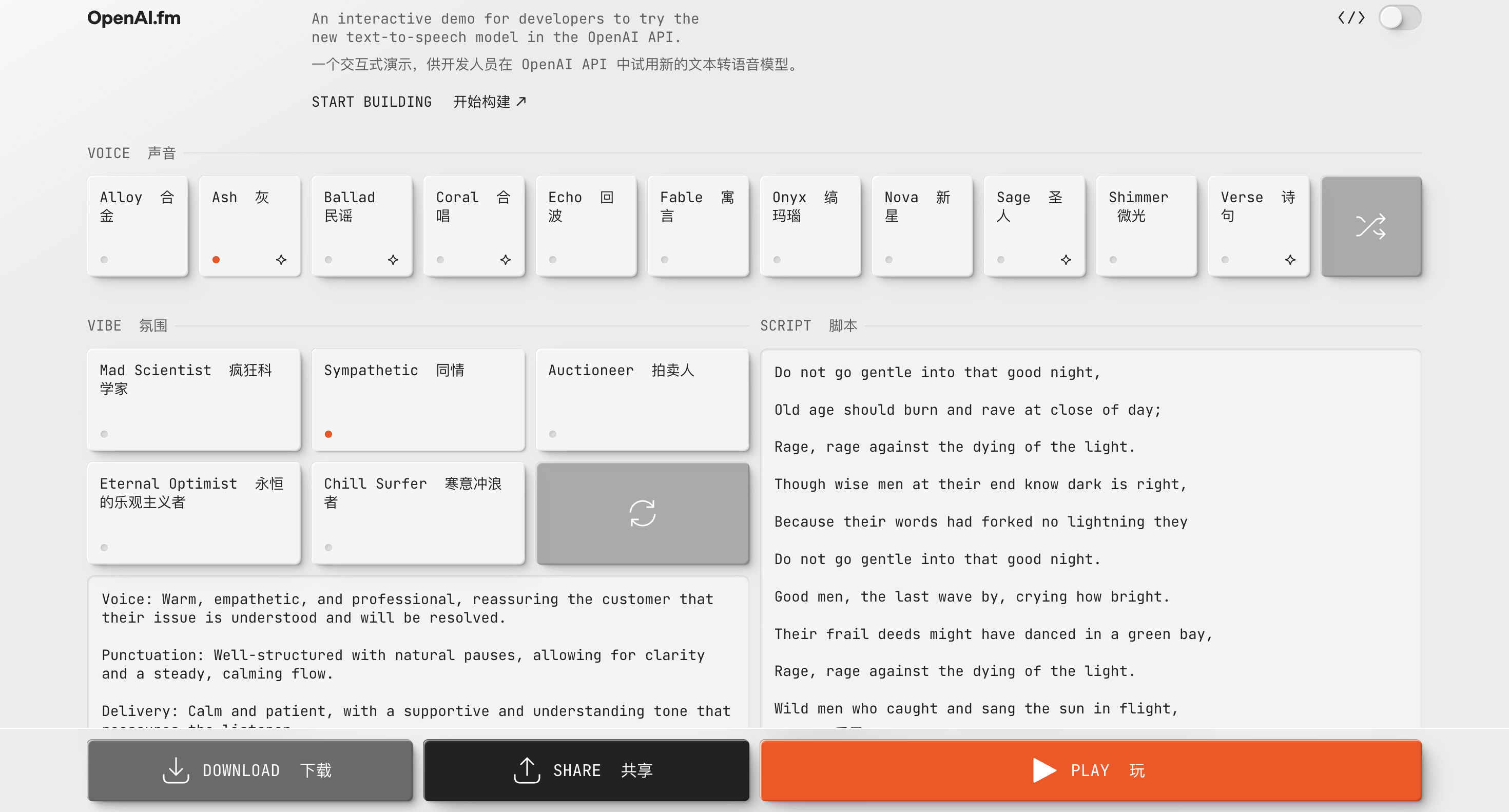
Vous pouvez également découvrir et créer de l'audio lié à gpt-4o-mini-tts sur http://OpenAI.fm. Ce site Web de démonstration est entièrement fonctionnel. Le coin inférieur gauche est le modèle prédéfini officiel, qui comprend principalement des paramètres tels que la personnalité, le ton, le dialecte et la prononciation.
Nous avons également testé un virelangue d'environ huit cents pionniers qui remontaient le versant nord Emmm, la version chinoise était juste médiocre. Quant à l'effet anglais, l'écouter réciter de la poésie ressemble beaucoup à une vraie personne, mais comparé au Hume AI ou Sesame auparavant populaire, il n'est toujours pas aussi bon que "audible à l'oreille humaine".
De plus, OpenAI a lancé l'intégration avec le SDK Agents pour simplifier davantage le processus de développement.
Il convient de mentionner qu'OpenAI a également organisé un concours de diffusion. Les utilisateurs peuvent créer de l'audio sur http://OpenAI.fm, puis utiliser le bouton « Partager » sur OpenAI.fm pour générer un lien, puis partager le lien sur la plateforme X.
Les trois candidats les plus créatifs recevront chacun une édition limitée Teenage Engineering OB-4. Il est recommandé que la durée audio soit contrôlée à environ 30 secondes, et vous pouvez faire preuve de créativité dans la voix, l'expression, la prononciation ou les changements dans l'intonation du script.

En fait, la tendance de l'IA évolue également discrètement cette année. En plus de toujours mettre l'accent sur le QI, il existe également une tendance supplémentaire consistant à mettre l'accent sur l'émotion.
Les arguments de vente de GPT-4.5 et Grok 3 sont l'intelligence émotionnelle, une écriture plus créative et des réponses plus personnalisées, tandis que le robot froid (Zhiyuan Robot) met également l'accent sur le fait d'être plus anthropomorphique et se concentre sur une valeur émotionnelle.
Parce qu'il touche directement le mode de communication le plus instinctif des êtres humains, le champ vocal a fait des efforts encore plus importants dans ce domaine.
Sesame AI, qui est récemment devenue populaire dans la Silicon Valley, peut détecter les émotions des utilisateurs en temps réel et générer des réponses émotionnellement résonnantes, capturant rapidement le cœur d'un grand nombre d'utilisateurs. Yann Lecun, lauréat du prix Turing, a également souligné récemment que l'IA du futur doit être empreinte d'émotions.
Qu'il s'agisse du nouveau modèle vocal publié aujourd'hui par OpenAI ou du Meta Llama 4, qui sortira bientôt, tous deux se rapprochent intentionnellement du dialogue vocal natif, essayant de se rapprocher des utilisateurs grâce à des interactions émotionnelles plus naturelles et s'appuyant sur le « contact humain » pour attirer les fans.
L’IA doit-elle être humaine ? Pendant longtemps. Les chatbots sont souvent définis comme des outils sans émotion, et ils vous rappelleront également lors de la conversation qu’il s’agit d’un modèle sans âme. Cependant, nous pouvons souvent en interpréter la valeur émotionnelle, et même établir inconsciemment des liens émotionnels avec elle.
Peut-être que l’humain a un désir inné d’être compris et accompagné, même si cette compréhension vient d’une machine.
# Bienvenue pour suivre le compte public officiel WeChat d'Aifaner : Aifaner (ID WeChat : ifanr). Un contenu plus passionnant vous sera fourni dès que possible.
Ai Faner | Lien original · Voir les commentaires · Sina Weibo