
Vous pouvez exécuter ChatGPT avec 2 Go de mémoire ! Ce « petit canon en acier » produit dans le pays permettra aux OV de Huawei de surmonter le goulot d’étranglement de leur expérience en matière d’IA.

Dans cette vague d'IA, Wall-Facing Intelligence est l'un des rares fabricants de modèles à grande tête en Chine à choisir le modèle All In end-to-side.
Depuis que Wallface Intelligence a publié le petit canon en acier 1.0 haute performance en février, il a été mis à niveau de manière itérative au cours des mois successifs, parmi lesquels le modèle open source MiniCPM-Llama3-V 2.5, lancé par la suite, a été plagié par l'équipe d'IA de Stanford en raison de sa solidité. force.
En avril, Zeng Guoyang, directeur technique de Wallface Intelligence, a également prédit que les modèles de niveau GPT-3.5 pourront fonctionner sur des appareils mobiles d'ici un ou deux ans.
La bonne nouvelle est que vous n'avez pas à attendre encore un ou deux ans, car le MiniCPM 3.0 publié aujourd'hui a atteint le niveau fixé lors de la sortie de la première génération de petits canons en acier : permettre aux modèles de niveau GPT-3.5 de fonctionner sur l'appareil au cours de cette année.

Avec seulement 4B de paramètres, les performances du MiniCPM 3.0 dépassent celles du GPT-3.5. MiniCPM 3.0 marque également l'arrivée du moment « ChatGPT côté appareil ».
Pour faire simple, le lancement de MiniCPM 3.0 signifie que les utilisateurs pourront à l'avenir bénéficier de services d'IA locaux rapides, sécurisés et riches en fonctionnalités sans recourir au traitement cloud, et obtenir une expérience d'interaction intelligente plus fluide et plus privée.
À en juger par les tests de référence partagés par le responsable, MiniCPM 3.0 est le meilleur des tests de référence axés sur la maîtrise du chinois tels que CMMLU et CEVAL, écrasant facilement des modèles tels que Phi-3.5 et GPT-3.5.
Même face aux grands modèles nationaux exceptionnels tels que 8B et 9B, les performances du MiniCPM 3.0 restent exceptionnelles.
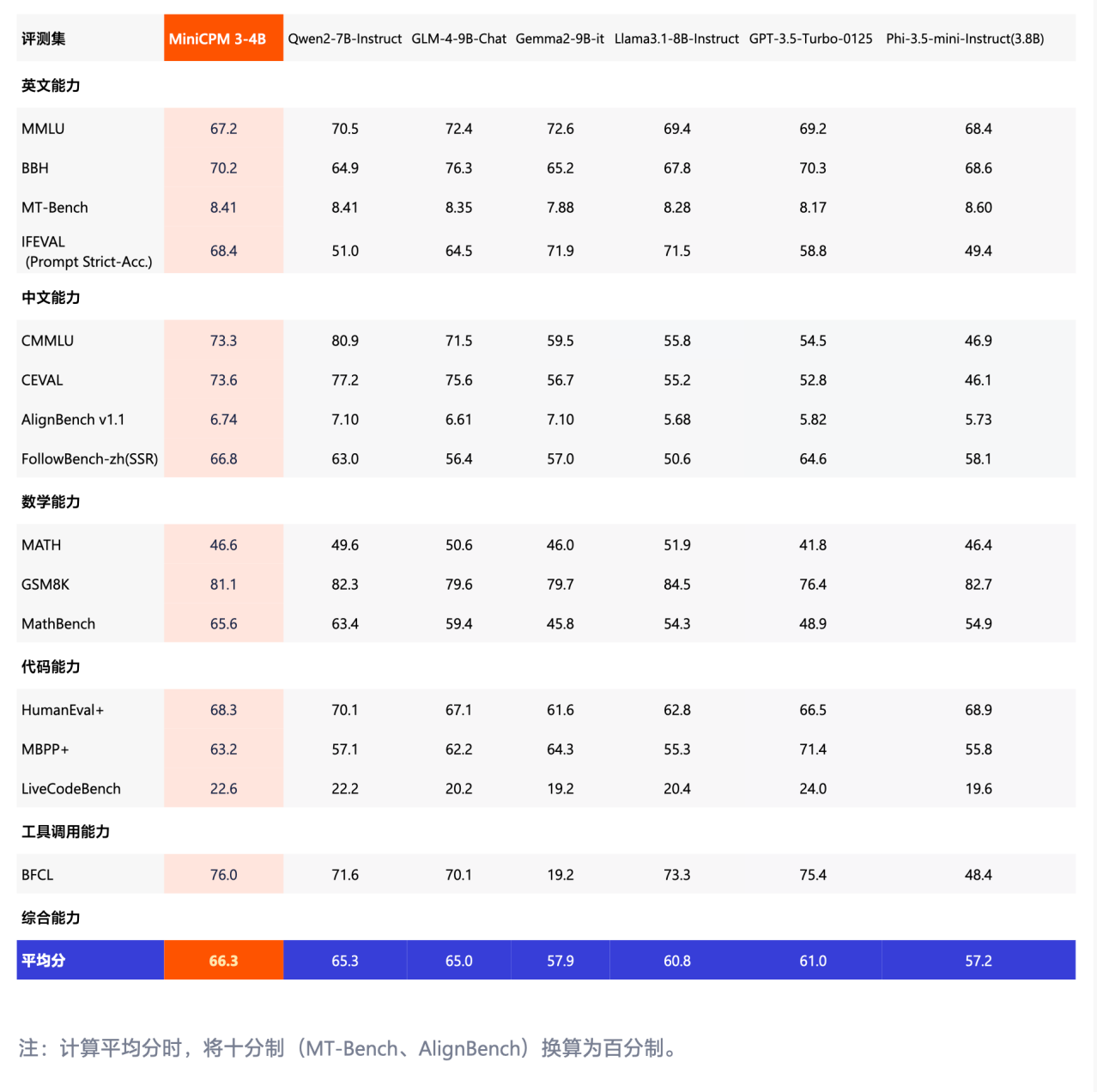
Résumons brièvement les fonctionnalités de MiniCPM 3.0 :
- Texte illimité, les performances de la liste surpassent Kimi
- L'appel de fonction le plus puissant du côté final, avec des performances comparables à GPT-4o
- Ensemble de plug-ins RAG trois pièces super puissant, recherche en chinois, langues croisées en chinois et en anglais en premier
Texte illimité, performances au-delà de Kimi
Petit mais puissant, petit mais complet, tels sont peut-être les adjectifs les plus appropriés pour MiniCPM 3.0.
La longueur du contexte est une caractéristique importante qui mesure les capacités de base des grands modèles. Une longueur de contexte plus longue signifie que le modèle peut stocker et rappeler plus d'informations, l'aidant ainsi à comprendre et à générer un langage avec plus de précision.
Par exemple, un contexte plus long pourrait permettre à un outil d’écriture d’IA de fournir des suggestions plus pertinentes basées sur ce que l’utilisateur a précédemment écrit, ou de créer des histoires plus complexes et plus engageantes basées sur des informations plus contextuelles.
À cette fin, Face Wall a proposé la technologie de traitement de trames d’articles longs LLMxMapReduce.
Il s'agit d'un moyen d'obtenir un texte infiniment long en découpant un contexte long en plusieurs fragments, permettant au modèle de le traiter en parallèle, d'extraire les informations clés de différents fragments et de résumer la réponse finale.

Il est rapporté que cette technologie améliore généralement la capacité du modèle à traiter des textes longs, et lorsque le texte continue de s'allonger, elle maintient toujours des performances stables et réduit la perte de score du texte long à mesure qu'il s'allonge.
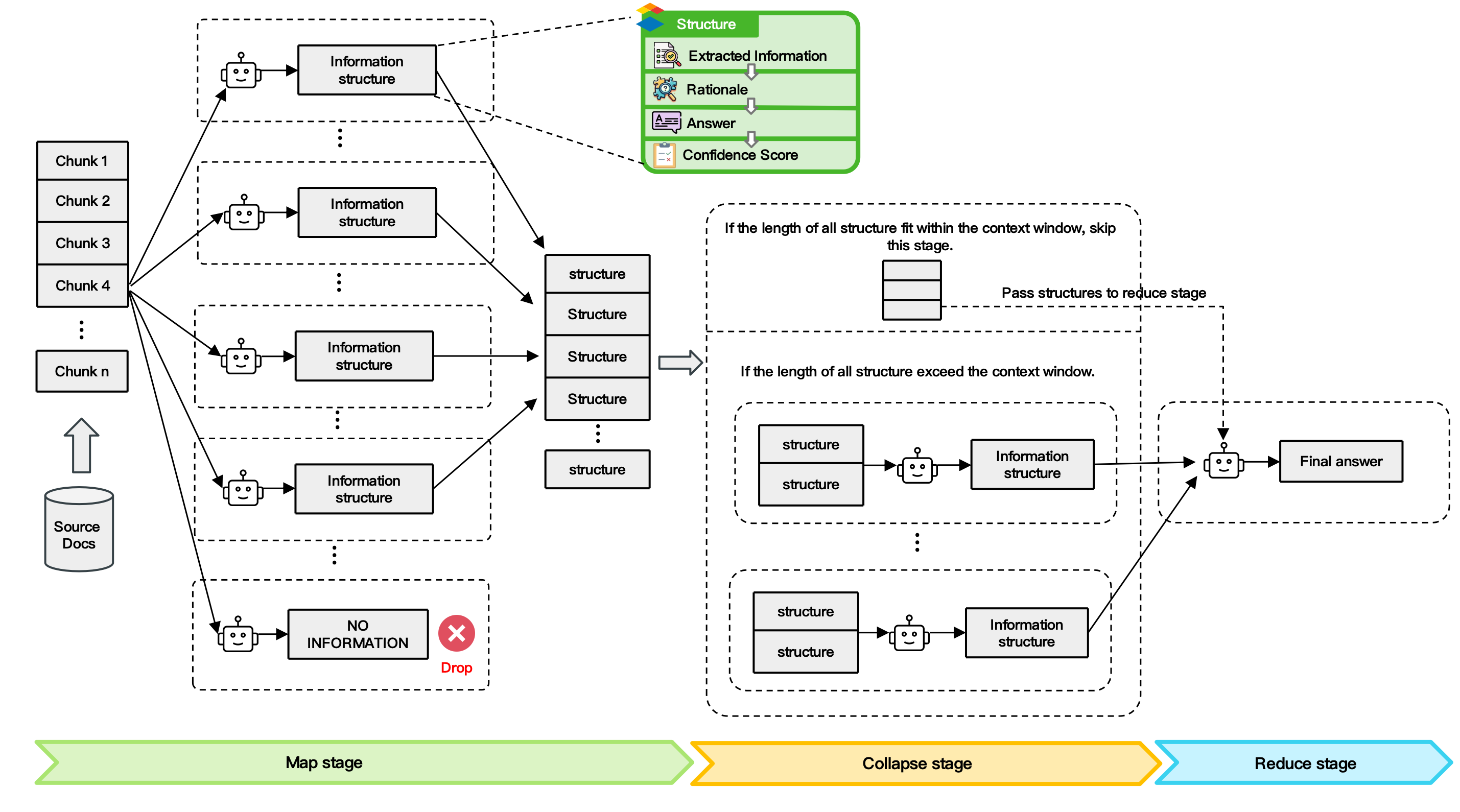
▲ Schéma du cadre technique LLMxMapReduce
De 32 Ko à 512 Ko, MiniCPM 3.0 peut briser les limitations de la mémoire des grands modèles et étendre la longueur du contexte de manière infinie et stable. Selon les termes du site officiel, c'est « aussi longtemps que vous le souhaitez ».
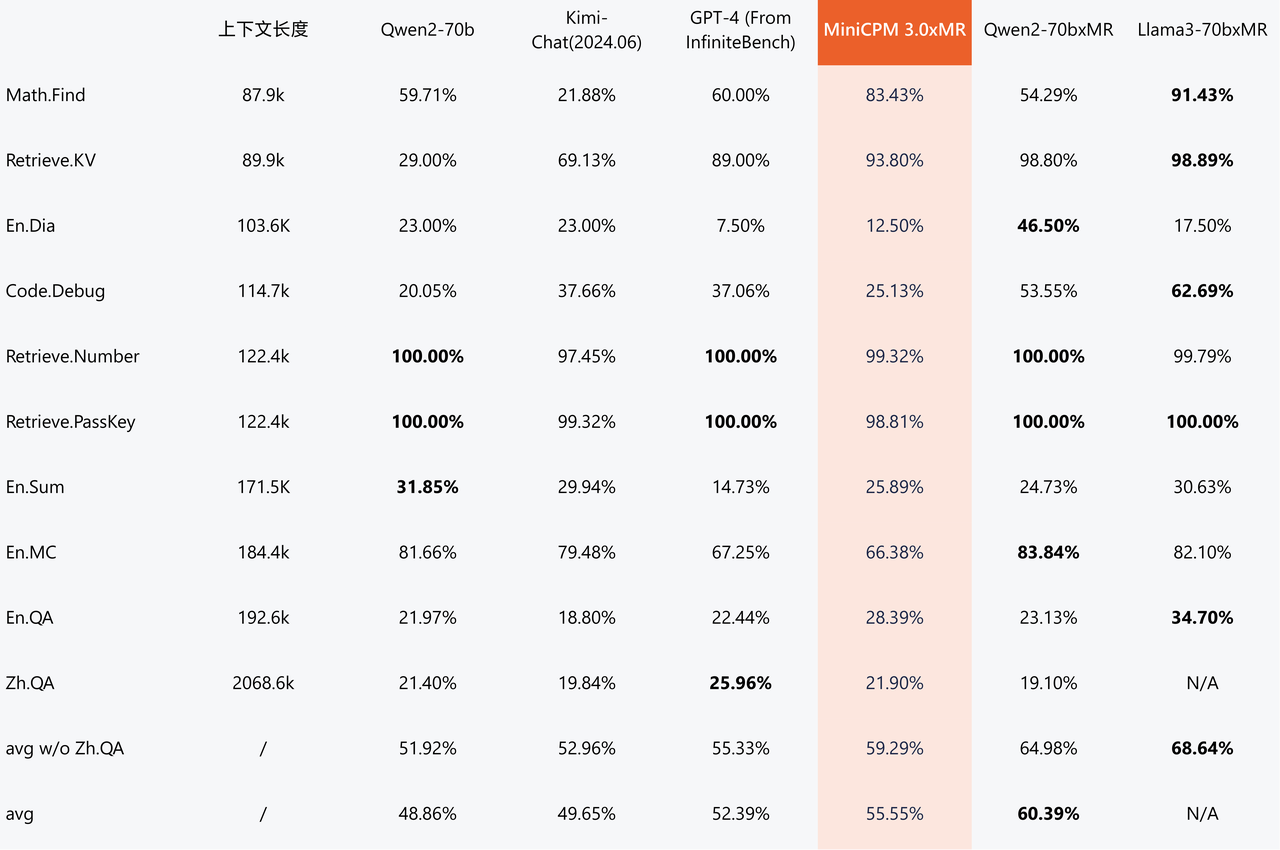
À en juger par les résultats des tests de référence InfiniteBench sur le texte long de grands modèles, à mesure que la longueur du texte augmente, l'avantage en termes de performances du MiniCPM 3.0 avec les paramètres 4B devient de plus en plus évident.
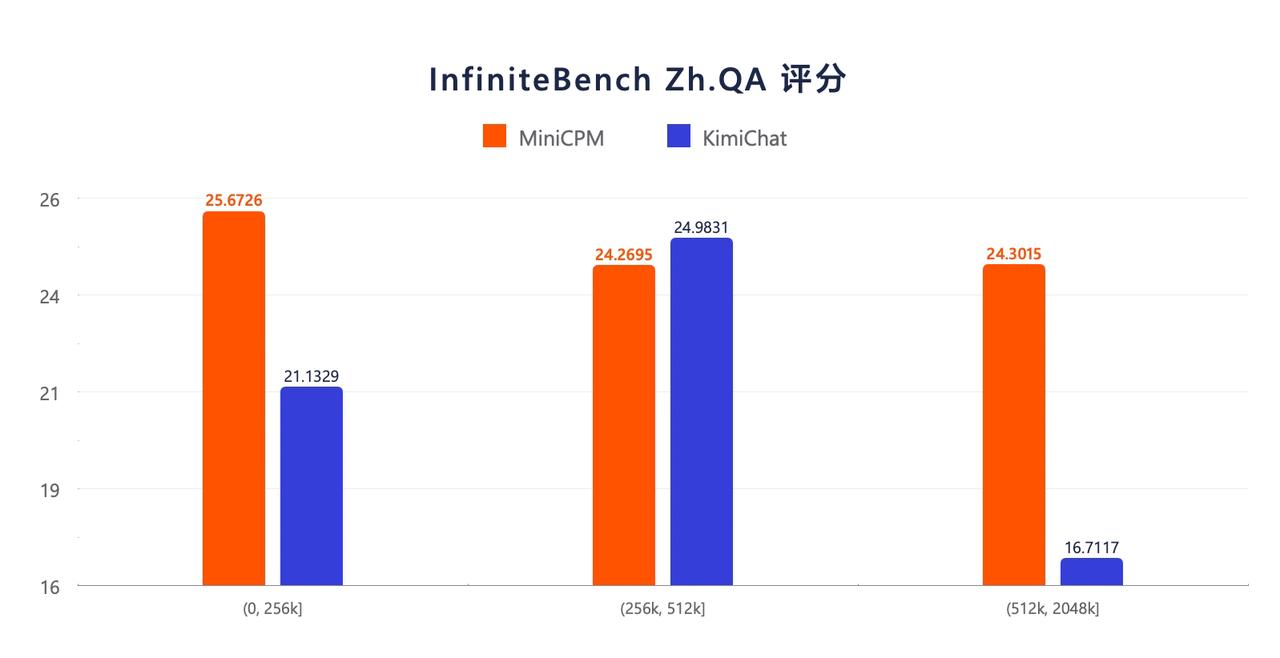
Les résultats de l'évaluation d'InfiniteBench Zh.QA montrent que les performances globales de MiniCPM 3.0 avec les paramètres 4B sont meilleures que celles de Kimi, montrant une stabilité relativement plus forte sur les textes plus longs.
L'appel de fonction le plus puissant du côté final, avec des performances comparables à GPT-4o
Dans des entretiens avec l'APPSO et d'autres médias, Zeng Guoyang a également déclaré que MiniCPM 3.0 a amélioré certaines fonctionnalités qui préoccupent les utilisateurs, telles que l'ajout d'appels de fonctions d'invite système complète et de capacités d'interprétation de code.
Parmi eux, Function Calling peut convertir la sémantique d'entrée floue de l'utilisateur en instructions structurées que la machine peut comprendre et exécuter avec précision, et permettre aux grands modèles de se connecter à des outils et systèmes externes.
Plus précisément, l'appel vocal d'applications telles que le calendrier, la météo, la messagerie électronique, le navigateur, etc. ou de bases de données locales telles que des albums photo et des fichiers sur le téléphone mobile ouvre des possibilités illimitées pour les applications d'agent du terminal et rend l'interaction homme-machine plus naturelle et plus pratique. .
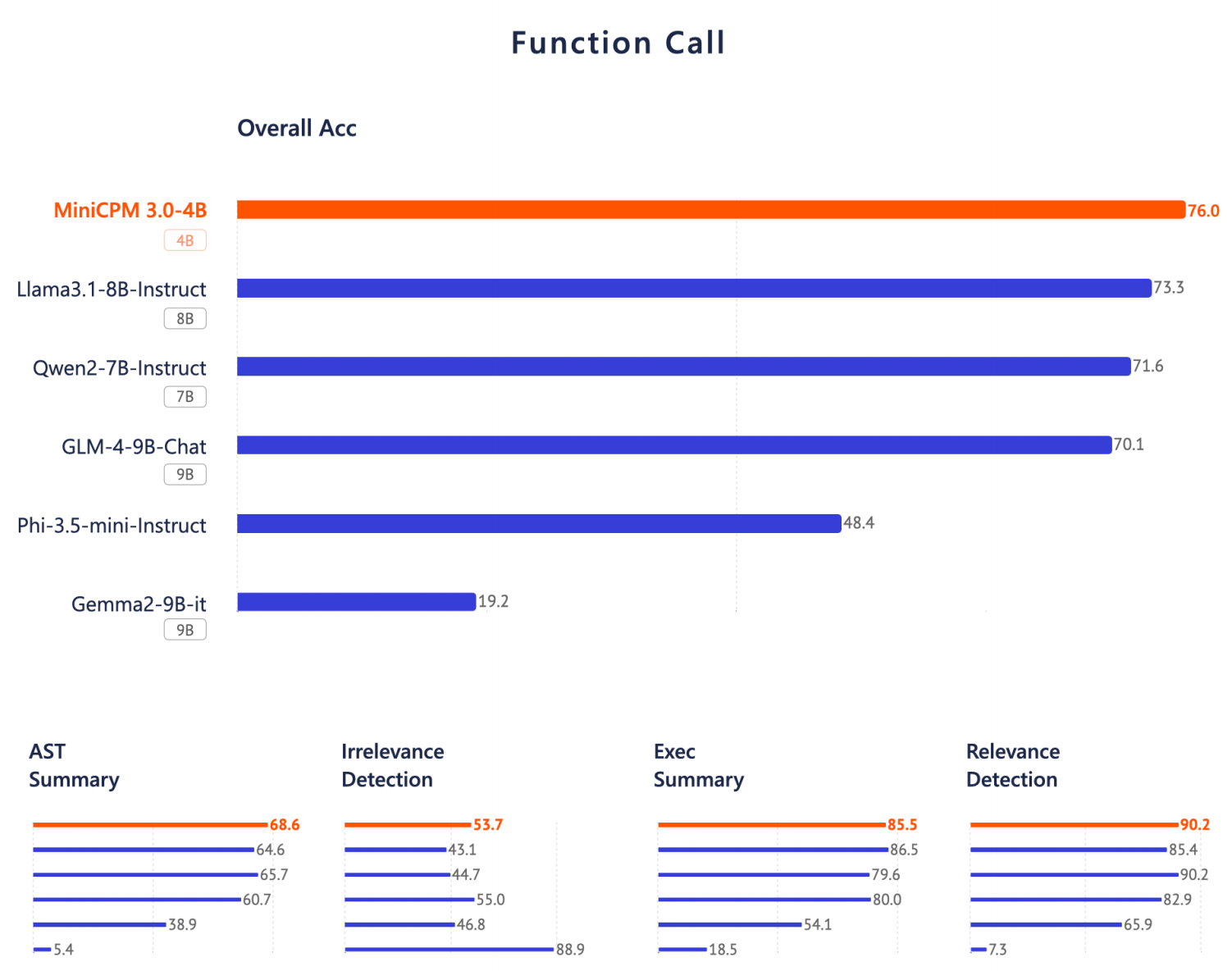
Selon les rapports, MiniCPM 3.0 prétend avoir les performances d'appel de fonction les plus élevées du côté des appareils. Sur la liste du classement des appels de fonctions de Berkeley, ses performances sont proches de GPT-4o et dépassent Llama 3.1-8B, Qwen-2-7B et. GLM-4-9B et bien d'autres modèles.
Zeng Guoyang a déclaré que les modèles open source existants ne couvrent pas entièrement ces capacités. Habituellement, seuls certains grands modèles cloud peuvent couvrir entièrement ces capacités. Désormais, MiniCPM 3.0 implémente également certaines fonctions correspondantes.
Prenez par exemple RAG (Retrieval Augmented Generation), une technologie qui combine la récupération d'informations (IR) et la génération de langage naturel (NLG).
Il guide le processus de génération de texte en récupérant des informations pertinentes dans des bibliothèques de documents à grande échelle, ce qui peut améliorer la précision et la fiabilité du modèle dans des tâches telles que répondre à des questions et générer du texte, et réduire le problème d'hallucination des grands modèles.
Pour les secteurs verticaux tels que le droit et la médecine qui s'appuient sur des bases de connaissances professionnelles et ont une tolérance extrêmement faible aux illusions des grands modèles, le grand modèle + RAG est particulièrement pratique dans l'industrie.
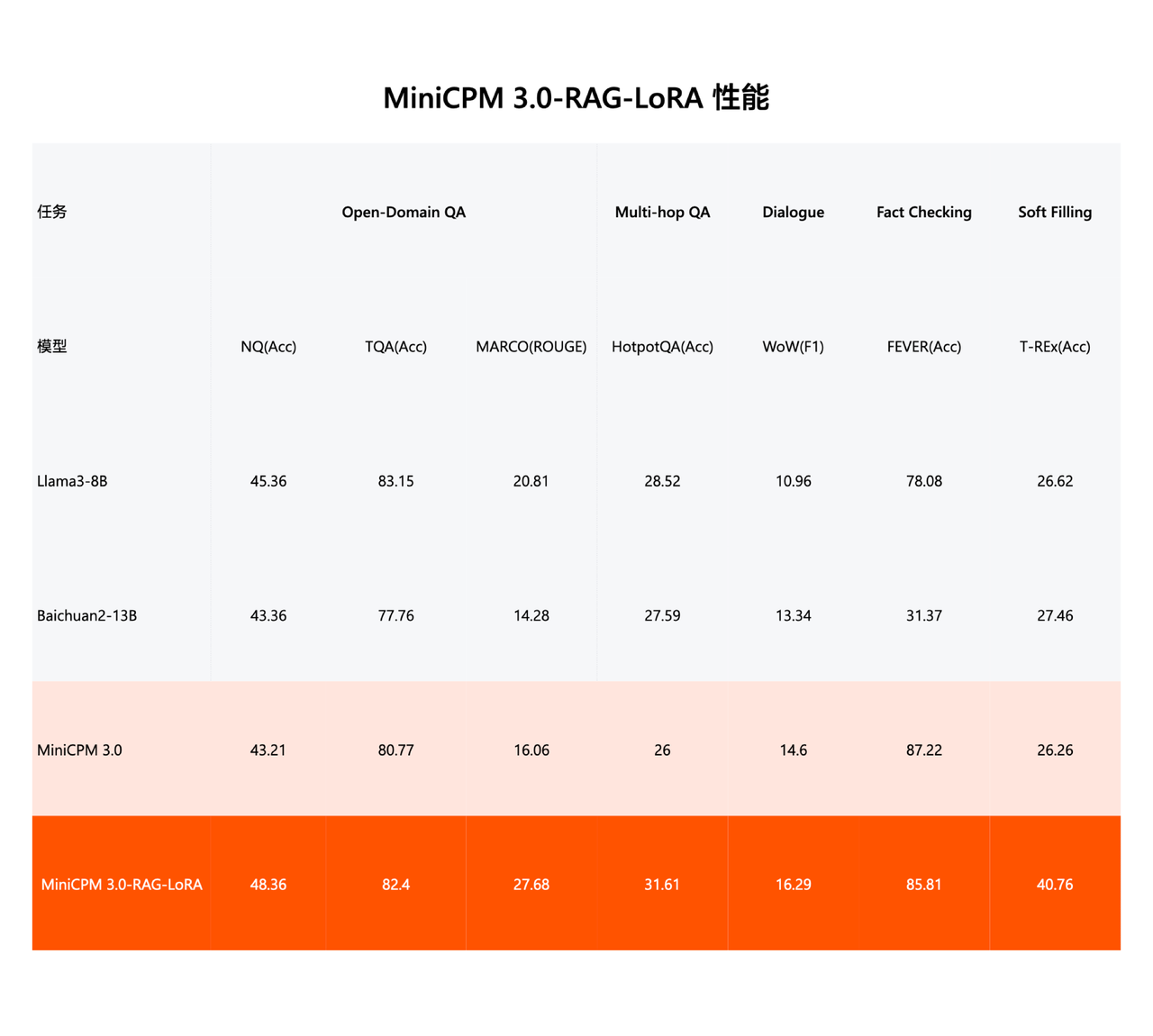
MiniCPM 3.0 a lancé l'ensemble de trois pièces RAG en une seule fois : modèle de récupération, modèle de réorganisation et plug-in LoRA pour les scénarios RAG.
MiniCPM-Embedding (modèle de récupération) a atteint les performances SOTA dans la récupération multilingue en chinois et en anglais, se classant premier en chinois et treizième en anglais sur la liste de récupération MTEB qui évalue les capacités d'intégration de texte du modèle.
MiniCPM-Reranker (modèle de reclassement) a atteint les performances SOTA dans les tests multilingues en chinois, anglais et chinois-anglais.
Après la formation LoRA pour les scénarios RAG, MiniCPM 3.0-RAG-LoRA fonctionne bien en matière de réponse aux questions en domaine ouvert (NQ, TQA, MARCO), de réponse aux questions multi-sauts (HotpotQA), de dialogue (WoW), de vérification des faits (FEVER) et de remplissage d'informations. (T-REx) et d'autres tâches de performance, surpassant les modèles leaders de l'industrie tels que Llama3-8B et Baichuan2-13B.
L'application modèle est implémentée, exécutez-la d'abord puis parlez-en
Dans une interview avec l'APPSO et d'autres médias, Li Dahai, PDG de Wall-Facing Intelligence, a mentionné que pouvoir exécuter et créer des applications de manière vraiment fluide sont deux concepts différents.
Le MiniCPM 3.0 optimisé a des besoins en ressources très faibles pour les appareils finaux. Après quantification, il ne nécessite que 2,2 Go de mémoire. L'inférence côté iPad peut également atteindre 18 à 20 jetons/s.
Pour les appareils mobiles comme l'iPad, être capable de traiter 18 à 20 jetons par seconde signifie déjà que le modèle peut traiter la saisie en langage naturel en temps réel.
Par exemple, dans les applications de reconnaissance vocale ou de traduction en temps réel, les utilisateurs ne connaîtront pratiquement pas de retards évidents et bénéficieront d'une expérience interactive relativement fluide.
De plus, par rapport aux modèles cloud, les modèles de la série MiniCPM en tant que modèles finaux présentent également naturellement des avantages locaux tels qu'un réseau faible, une facilité d'utilisation en cas de déconnexion, une latence ultra-faible, ainsi que la confidentialité et la sécurité des données.

Lorsque vous voyagez près de Gongga Snow Mountain, si vous souhaitez connaître la meilleure position pour profiter de la « Montagne Rizhao Jinshan », si votre réseau n'est pas bon, vous pouvez demander à MiniCPM 3.0.
Ou, si vous êtes un nouveau venu pour « prendre la mer », debout sur une côte accidentée, mais que vous souhaitez rentrer chez vous avec un chargement complet, autant suivre les suggestions données par MiniCPM 3.0. Lorsque vous regardez le ciel nocturne et avez l'idée de capturer des traînées d'étoiles, MiniCPM 3.0 peut également vous indiquer les détails de la prise de vue.
Derrière les progrès rapides de la série de petits canons en acier MiniCPM se cache le premier principe cohérent des grands modèles efficaces.
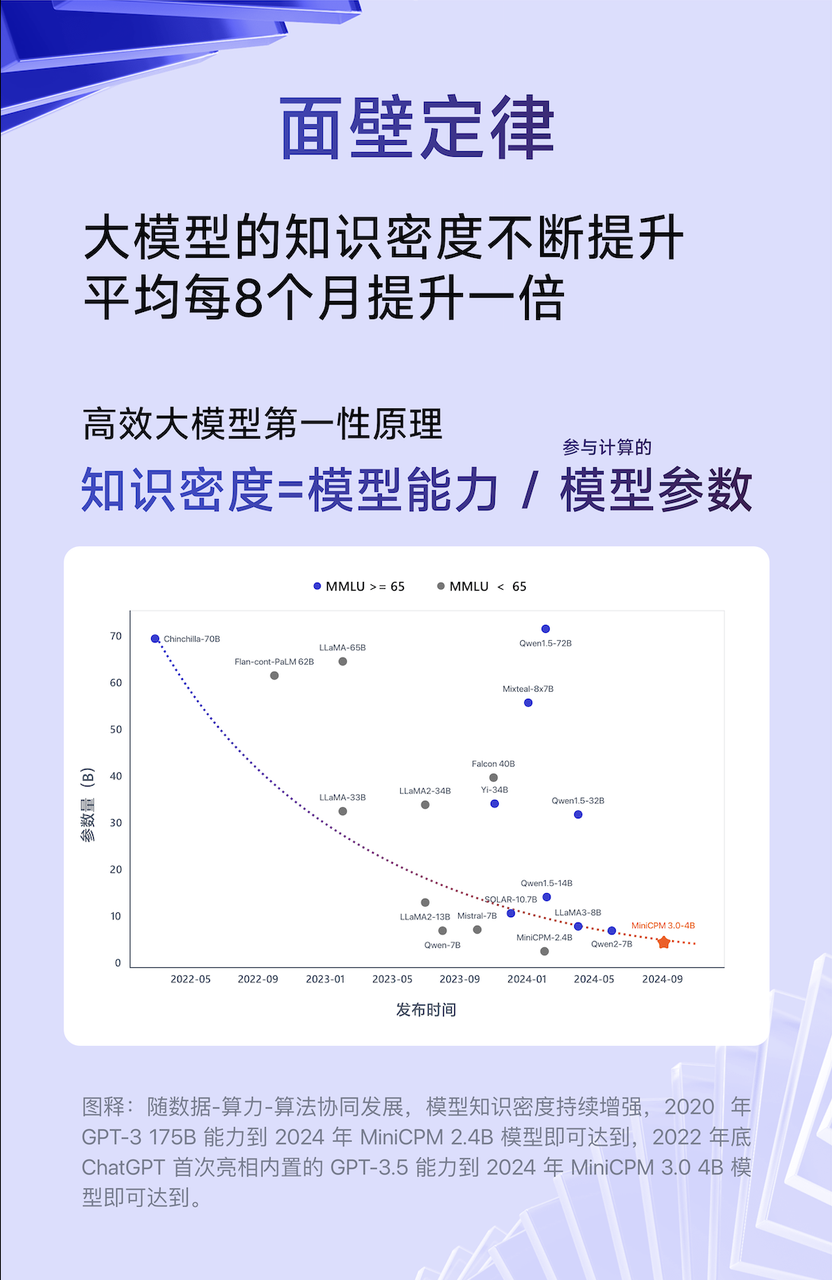
Liu Zhiyuan, scientifique en chef de Wall-Facing Intelligence, a un jour proposé une « loi de Moore » à l'ère des grands modèles, c'est-à-dire que la densité de connaissances des grands modèles doublera en moyenne tous les huit mois.
Densité des connaissances = capacité du modèle/paramètres du modèle impliqués dans le calcul
Plus précisément, à mesure que la densité des connaissances du modèle continue d'augmenter, la capacité 175B de GPT-3 en 2020 sera atteinte par le modèle MiniCPM 2.4B en 2024, et le GPT-3.5 intégré de ChatGPT fera ses débuts à la fin de 2022, qui sera atteint par le modèle MiniCPM 3.0 en 2024. .

Sur cette base, si MiniCPM poursuit la performance finale ultime, alors MiniCPM-V poursuit la performance ultime en matière d'innovation multimodale. Le progrès du petit canon en acier face au mur n'est pas un progrès unilatéral, mais l'avancement simultané de la fin. -deux phares latéraux.
Après un ou deux ans d'exploration technique, les grands modèles d'IA entrent progressivement dans le domaine des applications pratiques en eaux profondes.
Li Dahai estime que les grands modèles ont deux valeurs générales : la valeur dans un sens est de moderniser l'ancien monde et la valeur dans le second sens est de découvrir le nouveau monde.
Par exemple, l'intégration par Apple du service ChatGPT dans Apple Intelligence est un exemple typique.
Il en va de même pour le modèle côté appareil. Dans des scénarios tels que les téléphones mobiles, les voitures et les PC, la chose la plus appropriée à faire est de bien servir les fabricants de terminaux, puis de laisser les fabricants de terminaux utiliser le modèle côté appareil pour changer toute l’expérience au niveau du système.
Cependant, lors du saut passionnant de la technologie au produit, les fabricants doivent également investir beaucoup de temps dans l’intégration des besoins des utilisateurs et de la technologie.
Comme l'a dit Li Dahai, bien que l'Internet mobile existe depuis l'avènement de l'iPhone, la véritable croissance à grande échelle et les applications éprouvées n'ont commencé à émerger que quelques années plus tard.

En fait, l’intelligence appliquée aux murs explore des scénarios d’application pratiques.
Auparavant, le modèle d'extrémité MiniCPM orienté vers le mur fonctionnait sur des PC, des tablettes, des téléphones mobiles et d'autres domaines.
Il n'y a pas si longtemps, Wall-Facing Intelligence a également uni ses forces au WAIC pour accélérer l'évolution des robots et créer une solution pionnière pour une « intelligence incarnée » complète. Il s'agit également de la première démonstration dans l'industrie d'un modèle final efficace fonctionnant sur un robot humanoïde. pour comprendre, raisonner et interagir avec le monde physique. Système intelligent interactif.
Li Dahai a également révélé à l'APPSO et à d'autres médias que les produits équipés de modèles intelligents bout à côté muraux devraient être lancés avant la fin de l'année.
En bref, l’intelligence murale continue de placer les grands modèles à haute efficacité et haute performance au plus près des utilisateurs, permettant ainsi d’utiliser les capacités des grands modèles à volonté comme l’électricité, omniprésente, omniprésente et sûre.
Dans ce processus, davantage de personnes peuvent profiter le plus rapidement possible de la valeur et de la fonction des grands modèles.
Adresse open source MiniCPM 3.0 :
GitHub :  https://github.com/OpenBMB/MiniCPM
https://github.com/OpenBMB/MiniCPM
Visage câlin : https://huggingface.co/openbmb/MiniCPM3-4B
# Bienvenue pour suivre le compte public officiel WeChat d'Aifaner : Aifaner (ID WeChat : ifanr). Un contenu plus passionnant vous sera fourni dès que possible.
Ai Faner | Lien original · Voir les commentaires · Sina Weibo