
J’ai fait l’expérience d’Internet en 2046 à l’avance et c’était terrible


En tant que citoyens d'Internet, nous consommons chaque jour du contenu tout en produisant du contenu. Savez-vous combien de données Internet génère chaque jour ?
Selon les statistiques de la société de traitement de données en nuage Domo, la quantité de données générées chaque jour en 2020 atteindra environ 1,145 billion de Mo. Si toutes ces données sont stockées sur des disques durs, plus d'un million de disques durs de 1 To peuvent être remplis chaque jour.
Internet est comme un océan insondable, avec de nouvelles « marées » qui affluent chaque jour, mais ce que peu de gens remarquent, c'est que la vitesse de disparition des données Internet n'est pas beaucoup plus lente que cela.
La fermeture d'un site de blog, la défaillance d'un fournisseur de serveur, ou une intrusion malveillante par un pirate informatique peuvent faire disparaître complètement dans le monde certaines données Internet, qui peuvent inclure des photos de souvenirs précieux et des documents historiques clés. , avec la disparition de les données originales, celles-ci seront oubliées par l'humanité pour toujours.

Afin de préserver au maximum cette civilisation composée de personnages, une bibliothèque numérique à but non lucratif appelée Internet Archive aux États-Unis a collecté un grand nombre de pages Web, de vidéos, d'audios, de logiciels et de livres électroniques.
Depuis 1996, Internet Archive utilise des robots d'indexation pour explorer et archiver un grand nombre de pages Web. Jusqu'à présent, il y a eu plus de 351 milliards de pages Web, qui s'appelle le projet "Time Machine" (Wayback Machine).
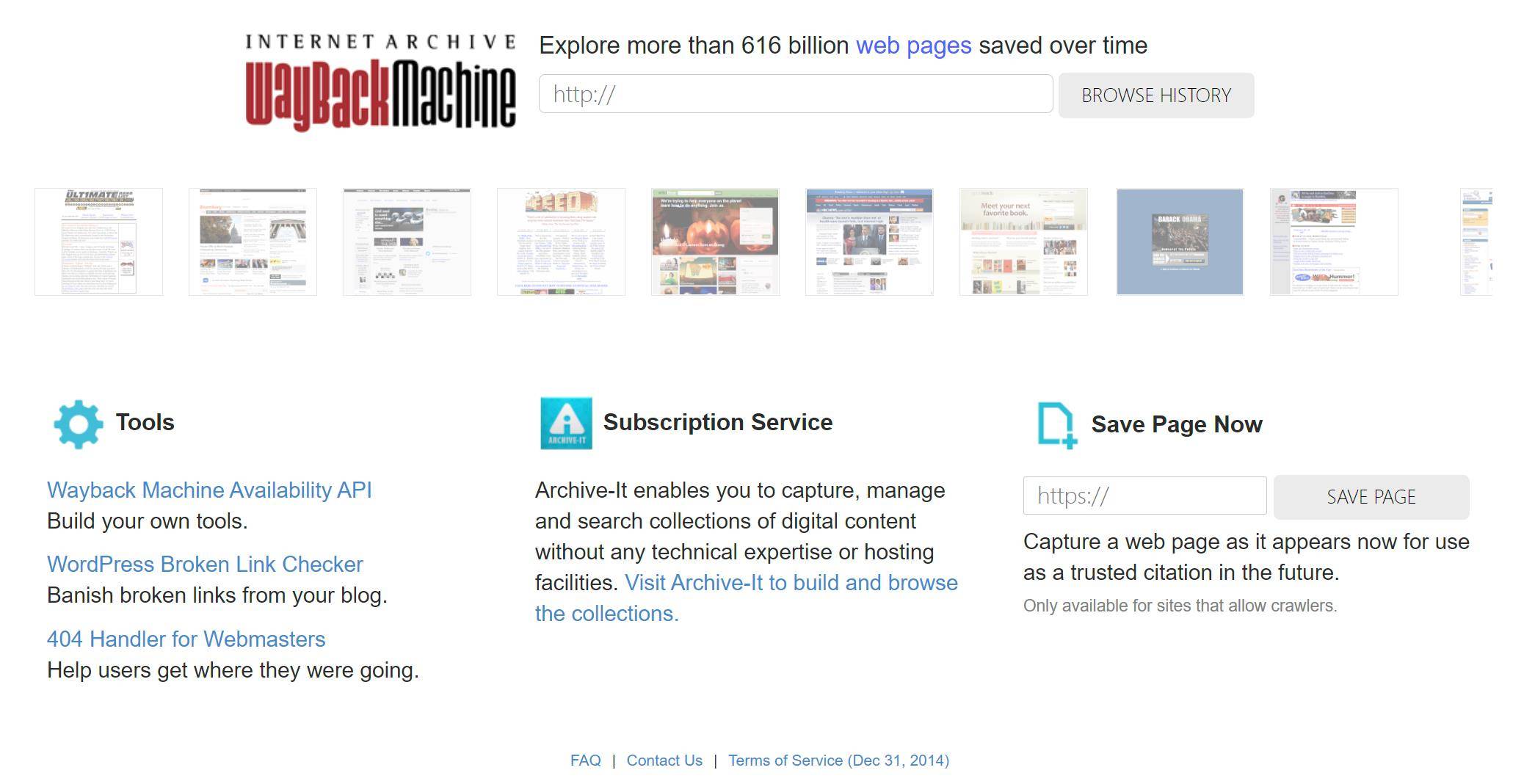
La page de "Time Machine" est très simple, avec un seul champ de saisie et un seul bouton de recherche, un peu à la manière des moteurs de recherche comme Google. Entrez le site Web que vous souhaitez « revenir dans le passé » dans le champ de saisie, sélectionnez la date que vous souhaitez parcourir et vous pouvez afficher les captures d'écran de la page Web qui a été enregistrée ce jour-là.
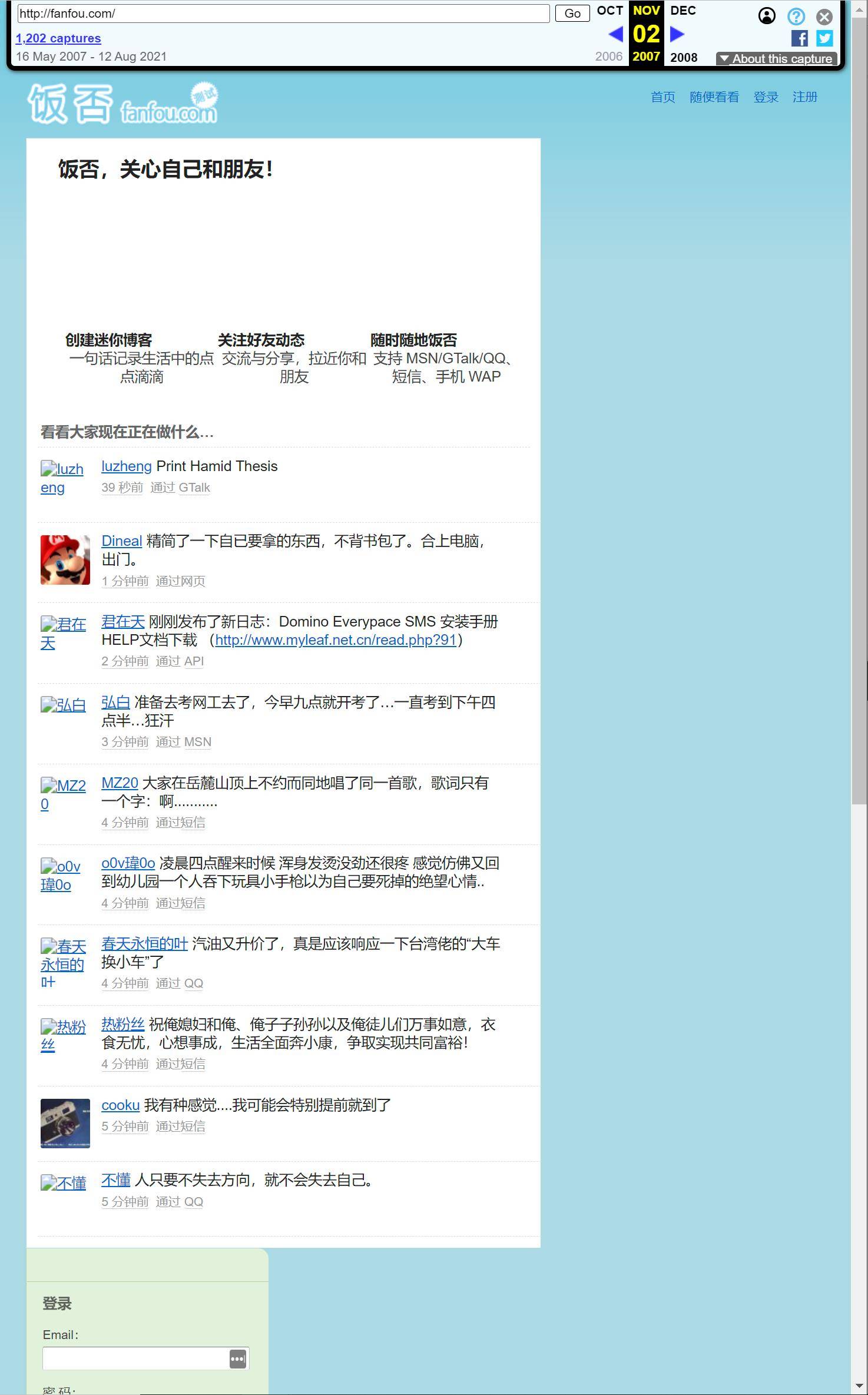
Fanfuku le 2 novembre 2007
Même pour certains sites Web qui ont depuis longtemps cessé d'exister à cause d'une mauvaise gestion et d'autres raisons, vous êtes très susceptible de trouver une sauvegarde historique dans la "machine à remonter le temps". C'est aussi l'une des idées de l'Internet Archive : protéger les Informations Internet.
2021 est exactement le 25e anniversaire de la naissance de l'Internet Archive. Il a enregistré près d'un quart de siècle d'histoire d'Internet. Afin de commémorer ce nœud spécial, l'Internet Archive a fait quelques "rénovations" à leurs machines à remonter le temps. temps Ils veulent non seulement enregistrer l'histoire, mais aussi vous ramener « vers le futur ».
Internet sera-t-il encore bon en 2046 ?
Le nouveau projet de l'Internet Archive s'appelle Wayforward Machine, qui est aussi une machine à remonter le temps, mais son rôle est de vous faire voyager dans le futur, l'heure est 2046.
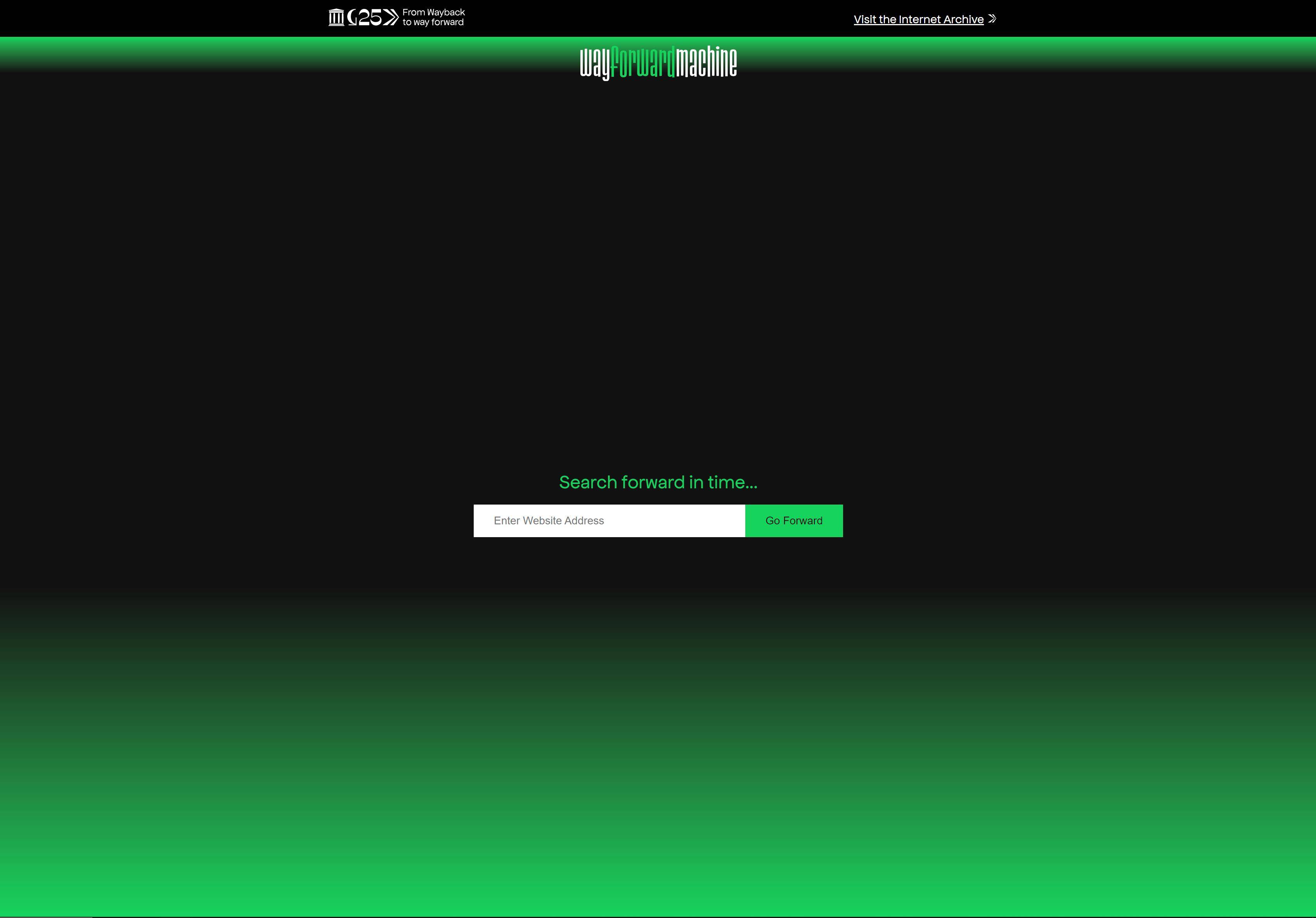
La page de "Future Time Machine" conserve le style concis de "Time Machine", et le schéma de couleurs noir et vert de la matrice y ajoute un petit sens futuriste de la technologie geeks.
Entrez l'URL dans la barre d'adresse au milieu, et vous pouvez voir à l'avance à quoi cela ressemble en 2046. Avec un peu d'humeur nerveuse et excitée, j'ai tapé www.Apple.com pour voir si l'iPhone 38 utilise 65W. .

Après avoir attendu patiemment, ce saut de 25 ans a finalement été accompli.Cependant, la première chose que j'ai vue n'était pas le logo noir et blanc familier, mais un "avertissement" sérieux qui m'obligeait à soumettre des informations personnelles avant de naviguer.

Après avoir suivi le guide et rempli une série d'informations personnelles telles que le nom, l'adresse, le numéro de téléphone portable, l'âge, le sexe, etc., je n'arrive toujours pas à accéder au site Web pour visualiser l'iPhone 38, et les choses sont devenues étranges : l'information demandé par le site Web devient de plus en plus privé, codé à partir du code postal. À mon poids, ma taille et d'autres informations physiologiques, et je ne peux pas le remplir.
J'ai essayé de parcourir le site officiel de Nintendo en 2046 pour voir si le mini écran LED 4K était utilisé dans le nouveau Switch, mais j'ai également été bloqué.

Le site Web me rappelle que je dois effectuer une authentification biométrique, et "humanisé", il fournit à la fois une authentification par rétine et par empreinte digitale.
Ce qui est plus "excessif", c'est que si j'accepte l'authentification, j'accepterai par défaut que les annonceurs poussent des publicités personnalisées en fonction de mes données biologiques.
Bien sûr, rien de tout cela ne s'est réellement produit. La "Future Time Machine" n'analysera pas vos informations biologiques, n'enregistrera pas vos données privées, ni ne simulera vraiment une page Web en 2046. C'est tout Internet. Un art de la performance- comme une farce planifiée par les archives.
Quelle que soit l'URL que vous entrez dans la "Future Time Machine", elle vous bloquera avec diverses fenêtres contextuelles, et ces "obstacles réseau" sont en fait l'avenir d'Internet que l'Internet Archive considère.

Lorsqu'en 2046, vous voulez aller sur un site Web musical pour trouver "Cultivation of Love" que vous avez écouté dans votre enfance, vous constaterez peut-être que le site Web a été fermé dès 2029, et des centaines de milliers d'histoires de commentaires sentimentaux qui ont été suivra tard dans la nuit.
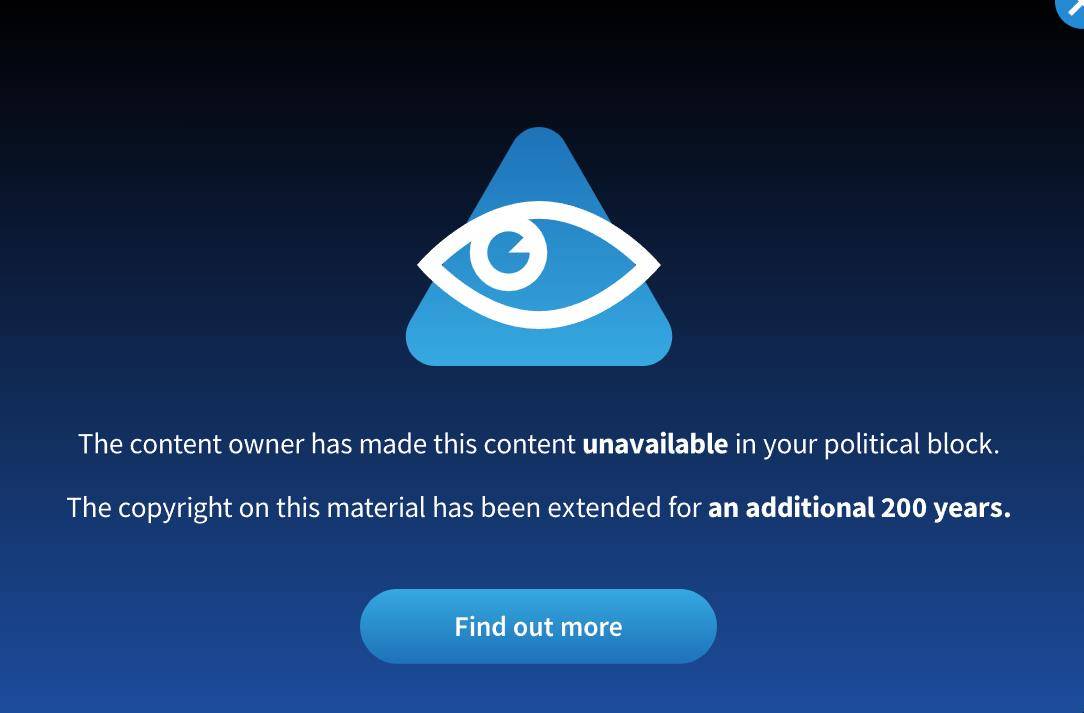
Ou lorsque vous accédez à certains sites de blogs et que vous souhaitez afficher des informations, vous pouvez rencontrer le propriétaire du site bloquant la navigation publique et étendant la protection du droit d'auteur de son contenu pendant 200 ans.
L'imagination de l'Internet Archive sur Internet en 2046 est pleine de couleurs dystopiques. Certaines de ses spéculations sont inévitablement audacieuses et radicales. Cependant, il est incontestable qu'Internet passe lentement de son statut d'origine " gratuit " et " ouvert " à fermé.

Photo de : L'Atlantique
Le problème des mauvais liens est une raison importante pour la fermeture de l'information. En juin de cette année, l'Atlantic Monthly a publié un article intitulé " Internet est en train de pourrir ". L'auteur Jonathan Zittrain et ses collègues ont effectué une série de recherches sur la question de l'échec des liens Web depuis 2014.
Prenons l'exemple de la revue universitaire faisant autorité "Harvard Law Review", 75% de ses liens de citation sont invalides depuis longtemps, ce qui signifie que si le problème des mauvais liens continue de se développer, les gens rencontreront de facto une chaîne de responsabilité dans un proche avenir. Le dilemme de l'effondrement total – personne ne peut distinguer la vérité de la vérité, car personne ne connaît la vérité.
De plus, la censure croissante des données personnelles et la publication de réglementations ont également rendu Internet Archive pessimiste quant à l'avenir d'Internet.

Pour cette raison, il prédit la chronologie des événements majeurs qui pourraient se produire sur Internet au cours des prochaines années 25. Par exemple, une loi sévère sur le droit d'auteur numérique sera adoptée en 2024 pour sévir contre le savoir libre, les trois plus grands éditeurs mondiaux fusionneront monopoliser les médias numériques en 2034, et les archives Internet en 2046. Le musée sera contraint de passer à des activités clandestines.
Et son projet « Time Machine » sera contraint de s'arrêter dès 2025. En effet, l'Internet Archive a déjà reçu des poursuites de quatre éditeurs.
Enregistrer méticuleusement l'histoire et partager les connaissances, c'est combattre l'avenir
Grâce à la "machine à remonter le temps", vous pouvez trouver de nombreuses choses intéressantes et significatives.
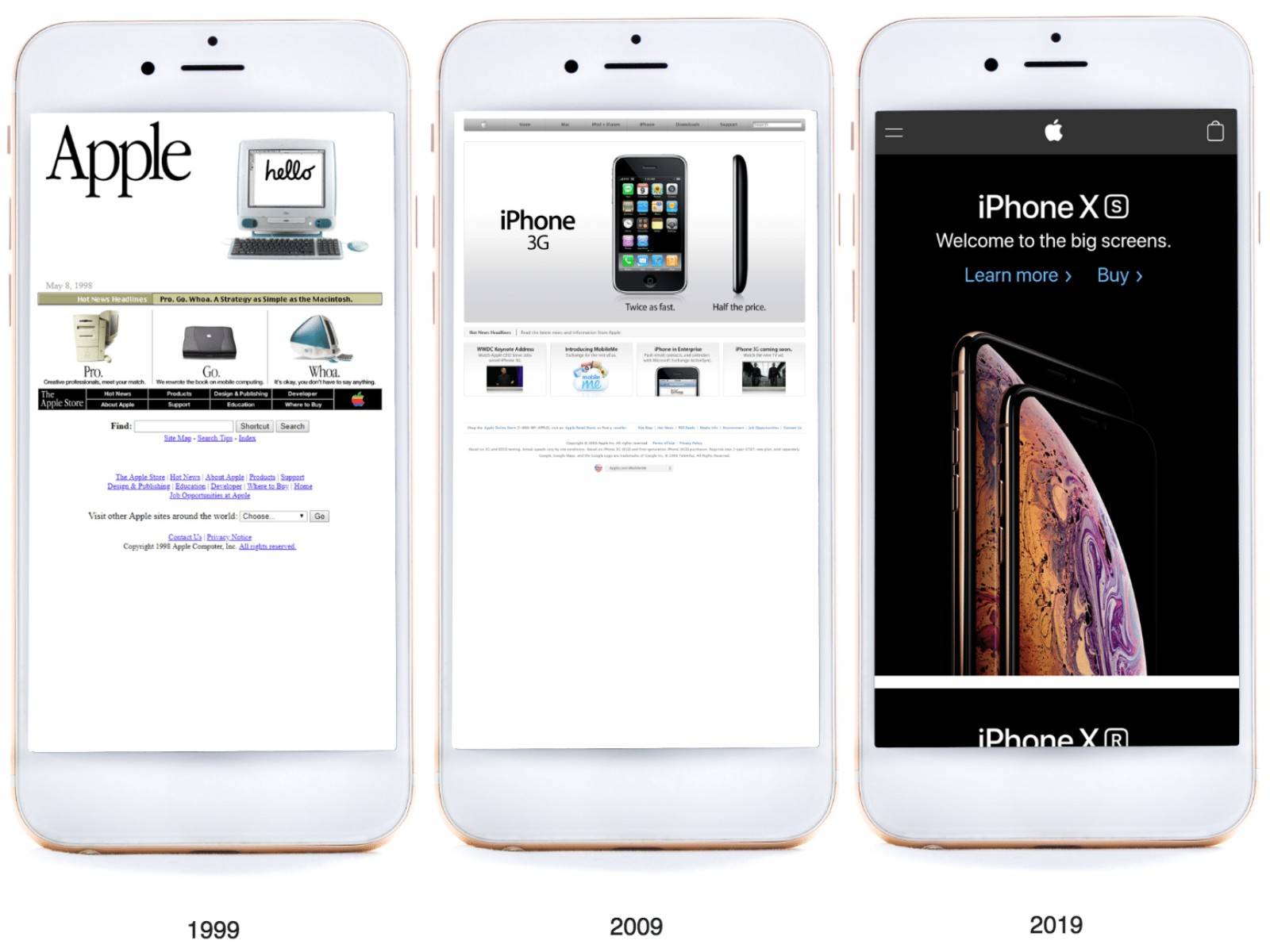
Par exemple, vous pouvez voir comment le site officiel d'Apple est passé de « vilain petit canard » à « cygne blanc » étape par étape.
Il enregistre non seulement les changements de conception du site Web, mais aussi les changements d'une époque.Cependant, en raison de son ouverture gratuite du contenu numérique aux personnes, Internet Archive se heurte à de plus en plus d'éditeurs.

L'Internet Archive n'est pas le seul sur la voie du savoir ouvert : un autre site de savoir controversé, Sci-Hub, a également fêté son dixième anniversaire cette année.
Sci-Hub est presque un secret bien connu mais indicible dans le cercle de la recherche scientifique : vous pouvez contourner le paywall et télécharger presque tous les articles scientifiques que vous souhaitez lire gratuitement, sans inscription ni abonnement.
Son but est de favoriser l'ouverture et la diffusion des connaissances, mais d'un point de vue commercial, ce genre de comportement est contrefaisant.

▲ Image de : Futurisme
La fondatrice de Sci-Hub, Alexandra Elbakin, a été poursuivie en justice par le géant de l'édition universitaire Elsevier en 2017, exigeant des dommages et intérêts de 15 millions de dollars, mais ce comportement n'a pas été soutenu par les chercheurs.
Certaines personnes disent que les archives Internet, Sci-Hub, EEF et d'autres sites Web sont des rebelles à l'ère du droit d'auteur et un étranger dans le monde d'Internet dominé par les capitaux. D'autres disent qu'ils sont les derniers gardiens de l'étincelle Internet.

▲ Brewster Kahle, fondateur de l'Internet Archive Photo de : The New York Times
Personne ne sait quand ils cesseront d'affronter la ligne rouge légale, mais leurs fondateurs ont lancé le même signal dans différentes interviews : ils s'y tiendront jusqu'à ce que personne ne la soutienne.
Au final, certains amis se demanderont peut-être pourquoi la "Future Time Machine" a choisi l'année 2046. A-t-elle été influencée par le réalisateur Wong Kar Wai ?
En fait, c'est uniquement parce qu'en 2046, l'Internet Archive vient d'enregistrer l'histoire d'Internet pendant un demi-siècle – si Internet existe encore à cette époque.
![]()
#Bienvenue pour suivre le compte officiel WeChat d'Aifaner : Aifaner (WeChat ID : ifanr), un contenu plus passionnant vous sera fourni dès que possible.
Ai Faner | Lien original · Voir les commentaires · Sina Weibo