
170 000 livres piratés sont le secret pour que les « ChatGPT » deviennent intelligents

Le "Real Hammer" est enfin là.
En juillet de cette année, OpenAI et Meta ont été poursuivis en justice par trois écrivains américains Sarah Silverman, Christopher Golden et Richard Kadrey, affirmant que les deux sociétés utilisaient leurs livres comme matériel pour former de grands modèles sans le consentement de l'auteur.

▲ Actrice, auteure Sarah Silverman et son autobiographie, photo de Vulture
preuve?
Dans l'affaire OpenAI, après que les plaignants aient saisi des mots d'invite, ChatGPT a pu résumer le contenu de leurs livres.
Dans le cas de Meta, il est écrit dans l'article du grand modèle Meta LLaMA que ses données de formation incluent un matériel appelé "ThePile" organisé par EleutherAI.
"ThePile" comprend également un ensemble de données appelé "Books3", dont le contenu est exactement celui de Bibliotik, une bibliothèque de ressources de livres piratés en ligne.
On voit que les preuves présentées par le plaignant à cette époque étaient relativement « indirectes ».
Jusqu'à présent, l'auteur et programmeur Alex Reisner a officiellement révélé quels livres d'auteurs avaient été volés derrière le grand modèle de Meta.
Ce qui est surprenant, c'est que ces « preuves » ont été mises à la surface tout le temps, mais elles n'ont pas été découvertes. Pourquoi ?
Même les créateurs des documents contrefaits ont toujours insisté sur le fait qu'il s'agissait d'une chose « juste ».
170 000 livres piratés

▲ Photo d' Intéressant Engineering
Le « grand projet » d'Alex Reisner est né de la curiosité :
En tant qu'écrivain et programmeur informatique, j'ai toujours été curieux de savoir sur quels types de livres les systèmes d'IA générative sont formés.
Cet été, Reisner a commencé à chercher des réponses dans des communautés telles que GitHub et Hugging Face, et a finalement trouvé l'ensemble de données open source « ThePile » que nous avons mentionné ci-dessus.
Cependant, télécharger sur « ThePile » ne signifie pas que vous pouvez savoir quels livres se trouvent dans « Books3 ».
Tout d'abord, comme "ThePile" a 800 Go, il est trop gros pour que les éditeurs de texte ordinaires puissent le lire. Reisner a écrit une série de programmes pour pouvoir extraire les informations de "Books3".

▲ Image d' Unsplash
De manière inattendue, dans les informations extraites, il n'y a aucune donnée avec des balises telles que « titre du livre » et « nom de l'auteur », et tout n'est que du « texte ».
Ainsi, Reisner a écrit un autre programme pour extraire le numéro ISBN (International Standard Book Number) dans les données et a comparé les données avec d'autres bases de données de livres en ligne pour identifier les livres spécifiques inclus dans « Books3 ».
Au final, cette étape a trouvé 190 000 codes ISBN, identifié 170 000 titres de livres correspondants (le nombre réel de livres peut être légèrement inférieur à ce nombre, car il existe différentes éditions du même livre), et 20 000 autres codes n'ont pas pu être trouvés. titre du livre correspondant.
Environ un tiers de ces livres sont de la fiction et les deux tiers sont de la non-fiction, provenant d'éditeurs petits et grands.
Oui, ces livres identifiés incluent également les livres des trois écrivains qui ont poursuivi OpenAI et Meta au début de l'article, on peut donc dire que le LLaMA de Meta a utilisé des livres piratés comme matériel de formation comme preuve très directe.
De plus, on peut également voir Elena Ferrante, auteur de "My Brilliant Girlfriend", Margaret Atwood, auteur de "The Handmaid's Tale", Stephen King, Haruki Murakami, célèbres aliments et boissons. De nombreuses œuvres de l'auteur Michael Pollan, auteur du thriller James Patterson. , et d'autres.

▲ Margaret Atwood et plus de 8 000 écrivains ont également écrit une lettre commune exigeant que les sociétés d'IA obtiennent l'autorisation des écrivains avant de pouvoir utiliser des livres comme matériel de formation.
En plus des livres d'auteurs célèbres, Reisner a également trouvé 102 romans pulp de Ron Hubbard, le fondateur de la Scientologie, et 90 livres du livre de John F. Arthur, ainsi que plusieurs ouvrages d'Erich von Daniken, un partisan de la « théorie de la création extraterrestre ». ".
Reisner a souligné dans l'article "Atlantic Monthly" que bien que l'ensemble de données "Books3" ne soit pas bien connu en dehors de la communauté de l'IA, il est très populaire dans le cercle. "Il peut être téléchargé, mais il est un peu difficile à trouver. . Si vous souhaitez parcourir et analyser, c'est tout aussi difficile."
C'est la première fois que Reisner consacre autant de temps à l'écriture d'un programme pour analyser la comparaison, et rédige également soigneusement un article et le publie dans les médias.
Dans le même temps, le cercle de l'IA a également un maintien tacite de "Books3", car, selon les mots du créateur de "Books3", il s'agit d'une ressource importante pour garantir que le développement de l'IA générative ne sera pas monopolisé. par les grandes entreprises.
"Voleur de Feu" ou "Voleur" ?

▲L'image provient de "The Atlantic Monthly"
Ce serait en effet mieux si nous n'avions pas besoin de quelque chose comme Books3.
Mais le fait est que sans Books3, seul OpenAI peut faire ce qu'il fait.
Le développeur indépendant Shawn Presser, le créateur de "Books3", a déclaré à Reisner.
Presser a commencé à créer Books3 pour fournir des « données de formation de niveau OpenAI » à tous les développeurs.
En 2020, Presser a téléchargé une copie de Bibliotik et réécrit un programme écrit par le hacker Aaron Swartz il y a plus de dix ans pour convertir tous les livres au format ePub en texte brut, un format plus adapté aux grands modèles.
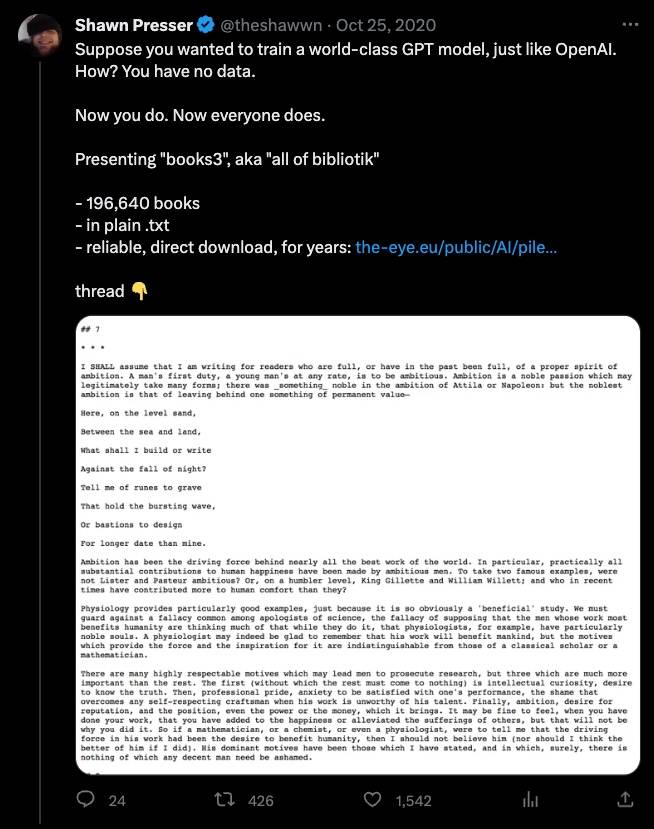
Quant au manque d'informations sur les droits d'auteur pour certains livres de l'ensemble de données, Presser a déclaré qu'il s'agissait d'un résultat inattendu de la conversion, et non intentionnel.
Le nom « Books3 » fait également écho aux « Books1 » et « Books2 » évoqués par OpenAI.
En 2020, l'article d'OpenAI a souligné que les données de formation de GPT-3 comprennent deux collections de données de livres sur Internet.
De par leur taille, les gens pensent que les données « Books1 » d'OpenAI proviennent du « Projet Gutenberg » – un projet spécialisé dans la collecte de ressources littéraires dont les droits d'auteur ont expiré.
Le contenu de "Books2" est inconnu, et certaines personnes ont deviné, d'après sa taille, qu'il est similaire aux données de Bibliotik ou de la bibliothèque piratée en ligne de Libgen.
Bien entendu, en plus des données du livre, GPT-3 utilisait également d'autres données à l'époque, telles que Wikipédia et d'autres informations textuelles récupérées sur Internet.
C'est pourquoi « ThePile » intégré par EleutherAI contient également de nombreuses autres données, telles que Wikipédia, des sous-titres de vidéos YouTube, des documents et des raccourcis du Parlement européen, etc.
Néanmoins, la qualité des textes des livres semble toujours importante en comparaison.
Meta a déclaré que le modèle original à grande échelle LlaMA-65B ne fonctionnait pas bien, principalement parce qu'il "utilisait un nombre limité de livres et d'articles universitaires".
L'article du MIT-Cornell souligne également que les livres « ont l'effet positif le plus important sur les performances en aval » dans les données d'entraînement de grands modèles.
Nous verrons donc "ThePile" et "Books3" dans les données d'entraînement LlaMA 2 lancées plus tard par Meta.

▲ Photo de CNN
C'est pourquoi Presser a été indigné lorsque Books3 a été récemment supprimé après une plainte déposée par le groupe anti-piratage danois Rights Alliance .
Selon lui, toutes les grandes entreprises à but lucratif utilisent le contenu contrefait pour entraîner leurs propres grands modèles en privé, mais comme elles ne divulguent pas leurs données d'entraînement, personne ne peut les poursuivre en justice.
Cependant, Books3 a été retiré des étagères précisément parce qu'il souhaitait rendre le grand modèle plus ouvert et transparent et divulguer activement la source des données.
Presser souligne que nous ne pouvons pas laisser les grandes entreprises aux poches profondes monopoliser cette technologie importante qui remodèle notre culture, mais laisser à chacun les ressources nécessaires pour construire ses propres grands modèles :
Mon objectif est de rendre (construire ces grands modèles) accessible à tous.
À moins que l'auteur du livre n'ait un moyen de mettre ChatGPT hors ligne ou de le poursuivre en justice pour le fermer, il est absolument nécessaire que vous et moi puissions créer notre propre ChatGPT.
Tout comme dans les années 90, il est important de garantir que chacun puisse créer son propre site Internet.
Quant à poursuivre ChatGPT hors ligne, ce n’est pas impossible.
Tout le monde poursuit les géants de l'IA

▲ OpenAI n'est plus "Open" et n'est pas transparent. L'image vient de Politico
Le procès intenté par l'écrivain vedette attire peut-être davantage l'attention, mais ce sont les médias d'information traditionnels qui ont le potentiel de poursuivre ChatGPT pour « remake ».
La semaine dernière, NPR a rapporté que le New York Times envisageait de poursuivre OpenAI en justice, citant des personnes proches du dossier.
Depuis quelques semaines, le New York Times négocie un accord de licence avec OpenAI. Cependant, les négociations ne semblaient pas bien se dérouler, à tel point que le New York Times a commencé à envisager de poursuivre OpenAI pour violation du droit d'auteur.
Selon le rapport, la loi fédérale sur le droit d'auteur prévoit que les contrevenants peuvent être condamnés à une amende allant jusqu'à 150 000 dollars pour chaque infraction "intentionnelle". Combinée au nombre d'articles du New York Times, cette somme "peut être fatale à une entreprise".
De plus, si le juge décide qu'OpenAI a pris illégalement l'article du New York Times pour former un grand modèle, le tribunal peut également ordonner à OpenAI de détruire l'ensemble de données ChatGPT, l'obligeant à se recycler et à créer ChatGPT uniquement avec des travaux autorisés.

▲ Photo de BrookField
Que le plaignant soit le New York Times ou un auteur de livres, le succès de ces poursuites (ou poursuites potentielles) dépendra de la capacité des géants de l'IA à décrire l'utilisation de ces informations comme une « utilisation équitable », c'est-à-dire sous certaines conditions. Dans certaines circonstances, l’utilisation non autorisée de certaines œuvres peut être autorisée, comme l’enseignement, les commentaires, la recherche et les reportages.
Il y a deux arguments en faveur du « fair use » :
- Les IA génératives ne reproduisent pas elles-mêmes les livres sur lesquels elles ont été formées, mais créent de nouveaux contenus ;
- Ces nouveaux contenus ne nuiront pas au marché de l’œuvre originale.
Jason Schultz, directeur de la Technology Law and Policy Clinic de l'Université de New York, affirme que l'argument est fort lorsqu'il s'agit de vol de livres.
Mais les avocats du New York Times ont insisté sur le fait que l'utilisation de l'article de journal par OpenAI ne constituait pas une « utilisation équitable ».
Si les utilisateurs peuvent obtenir des descriptions des événements d'actualité mentionnés dans les articles via des chatbots IA, ils ne pourront plus lire les articles, cela peut donc devenir un substitut aux articles d'actualité et affecter le marché d'origine.
Le blogueur juridique Fan Baile a souligné que la loi sur la propriété intellectuelle n'est pas statique, mais que son essence est ferme : faire prospérer le marché créatif.
Si même une entreprise d’IA évaluée à des dizaines de milliards de dollars pouvait utiliser gratuitement les œuvres que les écrivains ont passé des années à créer sans payer un seul droit d’auteur, et même voler ces livres pour former des outils destinés à remplacer les écrivains, ce serait un gros problème. C'est sans aucun doute un coup fatal pour les créateurs.
Le problème de « l’injustice des données » évoqué par Presser ne devrait pas être une excuse pour violer les droits des créateurs.
Les questions de droits d’auteur seront en fin de compte l’un des facteurs clés pour déterminer jusqu’où l’IA peut aller.
Selon Daniel Gervais, codirecteur du programme de propriété intellectuelle à l'Université Vanderbilt :
La loi sur le droit d’auteur est une épée qui pèse sur les entreprises d’IA, et à moins qu’elles ne trouvent comment négocier une solution, cette épée pèsera sur elles pendant des années.
Tout cela n’est que le début d’une nouvelle phase.

Enfin, nous avons réglé certaines des poursuites en cours pour contrefaçon de sociétés d'IA à titre de référence. 

#Bienvenue pour suivre le compte public WeChat officiel d'Aifaner : Aifaner (WeChat ID : ifanr), un contenu plus excitant vous sera présenté dès que possible.
Ai Faner | Lien original · Voir les commentaires · Sina Weibo