
Le guide le plus complet ! OpenAI publie le guide d’utilisation de GPT-4, toutes les informations utiles sont ici

Depuis sa naissance, ChatGPT a été promu sur l'autel de l'IA générative par d'innombrables personnes grâce à son innovation qui fait date.
Nous attendons toujours de lui qu'il comprenne précisément nos intentions, mais nous constatons souvent que ses réponses ou ses créations ne correspondent pas à 100% à nos attentes. Cet écart peut provenir de nos attentes excessives en matière de performances du modèle ou de notre incapacité à trouver le canal de communication le plus efficace lors de son utilisation.
Tout comme les explorateurs ont besoin de temps pour s'adapter à un nouveau terrain, notre interaction avec ChatGPT nécessite également de la patience et des compétences. Auparavant, OpenAI a officiellement publié le guide d'utilisation de GPT-4, Prompt Engineering, qui a enregistré six stratégies pour contrôler GPT-4.
Je pense qu'avec cela, votre communication avec ChatGPT sera plus fluide à l'avenir.
Résumons brièvement ces six stratégies :
- Écrivez des instructions claires
- Fournir un texte de référence
- Divisez les tâches complexes en sous-tâches plus simples
- Donnez au modèle le temps de « réfléchir »
- Utiliser des outils externes
- Tester systématiquement les changements
Écrivez des instructions claires
Décrire des informations détaillées
ChatGPT ne peut pas juger nos pensées implicites, nous devons donc vous informer le plus clairement possible de vos exigences, comme la longueur de la réponse, le niveau de rédaction, le format de sortie, etc.
Moins nous laissons ChatGPT deviner et déduire nos intentions, plus il est probable que le résultat réponde à nos exigences. Par exemple, lorsque nous lui demandons d'écrire un article de psychologie, les mots d'invite donnés devraient ressembler à ceci : 
S'il vous plaît, aidez-moi à rédiger un article de psychologie sur "Les causes et le traitement de la dépression". Exigences : Je dois rechercher la littérature pertinente et je ne peux pas plagier ou plagier ; Je dois suivre le format de l'article académique, y compris le résumé, l'introduction, le corps, la conclusion, etc. .; Le nombre de mots est de 2 000 mots ou plus.

Laissez le modèle jouer un rôle
Il existe des spécialisations dans l'industrie, et le modèle désigné joue un rôle spécialisé, et le contenu qu'il produit apparaîtra plus professionnel.
Par exemple : incarnez un romancier policier et utilisez un raisonnement à la Conan pour décrire une affaire de meurtre bizarre. Exigences : un traitement anonyme est requis, le nombre de mots est supérieur à 1 000 mots et l'intrigue comporte des hauts et des bas.
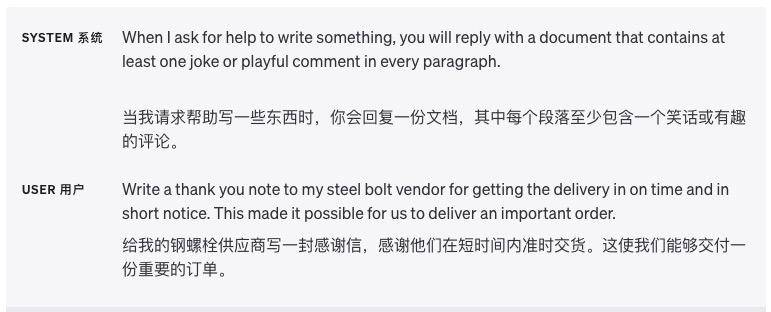
Utilisez des délimiteurs pour diviser clairement les différentes sections
Les délimiteurs tels que les guillemets triples, les balises XML et les titres de section peuvent aider à diviser les sections de texte qui doivent être traitées différemment et aider le modèle à mieux lever l'ambiguïté.

Préciser les étapes requises pour terminer la tâche
Diviser certaines tâches en une série d'étapes clairement définies facilite l'exécution de ces étapes par le modèle.

Fournir des exemples
Il est souvent plus efficace de fournir une explication générale qui s'applique à tous les exemples plutôt que de démontrer par exemple, mais dans certains cas, il peut être plus facile de fournir des exemples.
Par exemple, si je dis au modèle que pour apprendre à nager, il suffit de donner des coups de pied dans les jambes et de balancer les bras, c'est une affirmation générale. Et si je montre au modèle une vidéo de natation, montrant les mouvements spécifiques de coups de pied et de balancement des bras, cela est expliqué à travers des exemples.
Spécifier la longueur de sortie
Nous pouvons indiquer au modèle la longueur que nous souhaitons que le résultat qu'il génère dure, et cette longueur peut être comptée en termes de mots, de phrases, de paragraphes, de puces, etc.
Limité par le mécanisme interne du modèle et la complexité du langage, il est préférable de le diviser en paragraphes et en points clés, afin que l'effet soit meilleur.
Fournir un texte de référence
Demandez au modèle de répondre en utilisant le texte de référence
Si nous disposons de plus d'informations de référence, nous pouvons les « transmettre » au modèle et laisser le modèle utiliser les informations fournies pour répondre.

Demandez au modèle de citer le texte de référence pour répondre
Si l'entrée contient déjà des documents de connaissances pertinents, les utilisateurs peuvent directement demander au modèle d'ajouter des références à ses réponses en citant des passages du document, minimisant ainsi la possibilité que le modèle dise des bêtises.
Dans ce cas, les citations dans la sortie peuvent également être vérifiées par programme en faisant correspondre les chaînes dans le document fourni pour confirmer l'exactitude de la citation.

Divisez les tâches complexes en sous-tâches plus simples
Utiliser la classification d'intention pour identifier les instructions les plus pertinentes pour les requêtes des utilisateurs
Lorsque nous traitons de tâches qui nécessitent de nombreuses opérations différentes, nous pouvons utiliser une approche plus intelligente. Tout d’abord, divisez le problème en différents types et voyez quelles opérations chaque type nécessite. C'est comme si lorsque nous organisons des choses, nous mettions d'abord des choses similaires ensemble.
Ensuite, nous pouvons définir des opérations standards pour chaque type, tout comme l'étiquetage de chaque type de chose. De cette manière, certaines étapes communes peuvent être définies à l'avance, comme la recherche, la comparaison, la compréhension, etc.
Cette méthode de traitement peut être avancée couche par couche et si nous souhaitons poser des questions plus spécifiques, nous pouvons l'affiner davantage en fonction des opérations précédentes.
L'avantage est que chaque fois que vous répondez à une question utilisateur, vous n'avez qu'à effectuer les opérations requises pour l'étape en cours, plutôt que d'effectuer l'intégralité de la tâche en une seule fois. Non seulement cela réduit le risque d’erreur, mais cela permet également de gagner du temps, car accomplir l’ensemble de la tâche en même temps peut s’avérer coûteux.

Pour les scénarios d'application qui doivent gérer de longues conversations, résumez ou filtrez les conversations précédentes
Lorsque le modèle traite le dialogue, il est limité par la longueur de contexte fixe et ne peut pas mémoriser tout l'historique du dialogue.
Une façon de résoudre ce problème consiste à résumer la conversation précédente. Lorsque la longueur de la conversation d'entrée atteint une certaine limite, le système peut résumer automatiquement le contenu de la conversation précédente et afficher une partie des informations sous forme de résumé, ou il peut le faire. En cours, le contenu du chat précédent est discrètement résumé en arrière-plan.
Une autre solution consiste à sélectionner dynamiquement les parties de la conversation les plus pertinentes par rapport au problème actuel tout en y travaillant. Cette approche implique une stratégie appelée « récupération efficace des connaissances à l'aide d'une recherche basée sur l'intégration ».
Pour faire simple, il s’agit de retrouver les parties pertinentes de la conversation précédente en fonction du contenu de la question actuelle. Cela permet une utilisation plus efficace des informations précédentes et rend la conversation plus ciblée.
Résumer de longs documents de manière segmentaire et créer de manière récursive un résumé complet
Étant donné que le modèle ne peut mémoriser que des informations limitées, il ne peut pas être directement utilisé pour résumer des textes très longs. Afin de résumer de longs documents, nous pouvons utiliser une méthode de synthèse étape par étape.
Tout comme lorsque nous lisons un livre, nous pouvons résumer chaque section en posant des questions chapitre après chapitre. Les résumés de chaque section peuvent être enchaînés pour former un résumé de l’ensemble du document. Ce processus peut être récursif couche par couche jusqu'à ce que l'ensemble du document soit résumé.
Si vous avez besoin de comprendre ce qui suit, vous devrez peut-être utiliser les informations précédentes. Un autre conseil utile dans ce cas est de regarder le résumé avant de lire jusqu'à un certain point et d'avoir une idée de ce dont il s'agit.
Donnez au modèle le temps de « réfléchir »
Demandez au modèle de proposer sa propre solution avant de tirer des conclusions hâtives
Dans le passé, nous pouvions directement demander au modèle d'examiner la réponse de l'élève, puis lui demander si la réponse est correcte. Cependant, parfois la réponse de l'élève est fausse. Si l'on demande directement au modèle de juger la réponse de l'élève, il peut ne pas être exact.
Afin de rendre le modèle plus précis, nous pouvons d'abord laisser le modèle résoudre ce problème mathématique par lui-même et calculer d'abord sa propre réponse. Laissez ensuite le modèle comparer les réponses de l'élève avec ses propres réponses.
En laissant d'abord le modèle faire les calculs tout seul, il lui sera plus facile de déterminer si la réponse de l'élève est correcte. Si la réponse de l'élève est différente de la propre réponse du modèle, il saura que l'élève a mal répondu. Cela permet au modèle de commencer à réfléchir à partir de la première étape la plus élémentaire, plutôt que de juger directement la réponse de l'élève, ce qui peut améliorer la précision du jugement du modèle.

Utilisez un monologue intérieur pour masquer le processus de raisonnement du modèle
Parfois, lorsqu’il répond à une question spécifique, il est important que le modèle raisonne sur le problème en détail. Toutefois, pour certains scénarios d'application, le processus d'inférence du modèle peut ne pas convenir au partage avec les utilisateurs.
Pour résoudre ce problème, il existe une stratégie appelée monologue interne. L'idée de cette stratégie est de demander au modèle d'organiser une partie de la sortie que l'utilisateur ne souhaite pas voir sous une forme structurée, puis d'en afficher seulement une partie, pas la totalité, lorsqu'elle est présentée à l'utilisateur.
Par exemple, supposons que nous enseignons un certain sujet et que nous devions répondre aux questions des étudiants. Si nous expliquons directement aux étudiants toutes les idées de raisonnement du modèle, les étudiants n'auront pas à y réfléchir eux-mêmes.
Par conséquent, nous pouvons utiliser la stratégie du « monologue intérieur » : laissez d'abord le modèle réfléchir au problème complètement par lui-même, réfléchissez à toutes les idées de solution, puis sélectionnez seulement une petite partie des idées du modèle et expliquez-les aux étudiants dans un langage simple.
Ou nous pouvons concevoir une série de questions : laissez d'abord le modèle réfléchir à la solution entière par lui-même, sans permettre aux étudiants de répondre, puis posez aux étudiants une question simple similaire basée sur les idées du modèle. Une fois que les étudiants ont répondu, laissez le modèle juger si les réponses des élèves sont correctes ou fausses.
Enfin, le modèle utilise un langage facile à comprendre pour expliquer aux étudiants les idées de solutions correctes. Cela entraîne non seulement la capacité de raisonnement du modèle, mais permet également aux étudiants de penser par eux-mêmes sans leur donner directement toutes les réponses.

Demandez au modèle s'il a manqué quelque chose lors de la passe précédente
Supposons que nous demandions au modèle de trouver des phrases liées à une certaine question à partir d'un fichier volumineux, et que le modèle nous dira une phrase à la fois.
Mais parfois, le modèle fait une erreur de jugement et s'arrête alors qu'il devrait continuer à chercher des phrases associées, ce qui entraîne l'omission de phrases associées qui ne nous sont pas communiquées plus tard.
À ce stade, nous pouvons rappeler au modèle « Y a-t-il d'autres phrases associées ? », puis il continuera à interroger les phrases associées, afin que le modèle puisse trouver des informations plus complètes.
Utiliser des outils externes
Récupération efficace des connaissances grâce à la recherche basée sur l'intégration
Si nous ajoutons des informations externes aux entrées du modèle, celui-ci peut répondre aux questions de manière plus intelligente. Par exemple, si un utilisateur pose une question sur un certain film, nous pouvons saisir des informations importantes sur le film (telles que les acteurs, les réalisateurs, etc.) dans le modèle afin que celui-ci puisse donner des réponses plus intelligentes.
L'intégration de texte est un vecteur qui mesure la relation entre les textes. Les vecteurs de texte similaires ou associés sont plus proches, tandis que les vecteurs de texte non liés sont relativement éloignés, ce qui signifie que nous pouvons tirer parti des intégrations pour une récupération efficace des connaissances.
Plus précisément, nous pouvons découper le corpus de texte en morceaux et intégrer et stocker chaque morceau. Nous pouvons ensuite intégrer une requête donnée et trouver le morceau de texte intégré le plus pertinent dans le corpus (c'est-à-dire le morceau de texte le plus proche de la requête dans l'espace d'intégration) via la recherche vectorielle.
Utilisez l'exécution de code pour des calculs plus précis ou pour appeler des API externes
Les modèles de langage ne sont pas toujours capables d’effectuer avec précision des opérations mathématiques complexes ou des calculs qui prennent beaucoup de temps. Dans ce cas, nous pouvons demander au modèle d’écrire du code pour terminer la tâche, plutôt que de le laisser effectuer les calculs tout seul.
Plus précisément, nous pouvons demander au modèle d'écrire le code qui doit être exécuté dans un certain format, par exemple en l'entourant de triples backticks. Lorsque le code génère des résultats, nous pouvons les extraire et les exécuter.
Enfin, si vous le souhaitez, la sortie d'un moteur d'exécution de code (tel que l'interpréteur Python) peut être utilisée comme entrée pour la question suivante du modèle. Cela permet d'effectuer plus efficacement les tâches qui nécessitent des calculs.

Un autre bon exemple d’utilisation de l’exécution de code est l’utilisation d’API externes (Application Programming Interfaces). Si nous expliquons au modèle comment utiliser correctement une API, il peut écrire du code qui appelle cette API.
Nous pouvons fournir au modèle de la documentation ou des exemples de code montrant comment utiliser l'API, afin que le modèle puisse être guidé pour apprendre à utiliser l'API. En termes simples, en fournissant au modèle des conseils sur l'API, il peut créer du code pour réaliser plus de fonctions.

Avertissement : L'exécution du code généré par un modèle est intrinsèquement dangereuse et toute application tentant de le faire doit prendre des précautions. En particulier, des environnements d’exécution de code en bac à sable sont nécessaires pour limiter les dommages potentiels que peut causer un code non fiable.
Laissez le modèle fournir des fonctionnalités spécifiques
Nous pouvons lui transmettre une liste décrivant les fonctionnalités via une requête API. De cette manière, le modèle est capable de générer des paramètres de fonction basés sur le modèle fourni. Les paramètres de fonction générés sont renvoyés au format JSON, que nous utilisons ensuite pour effectuer l'appel de fonction.
Ensuite, une boucle peut être implémentée en renvoyant la sortie de l'appel de fonction au modèle dans la requête suivante. C'est la méthode recommandée pour appeler des fonctions externes à l'aide du modèle OpenAI.
Tester systématiquement les changements
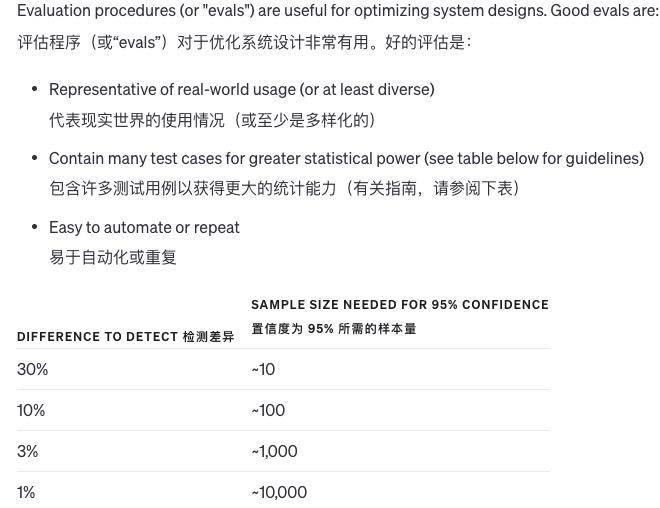
Lorsque nous apportons des modifications à un système, il est difficile de juger si les changements sont bons ou mauvais. En raison du peu d’exemples, il est difficile de déterminer si les résultats se sont réellement améliorés ou s’il s’agit simplement d’une question de chance. Parfois, une modification est bonne dans certaines situations et mauvaise dans d’autres.
Alors, comment évaluer la qualité du résultat du système ? S’il n’existe qu’une seule réponse standard à une question, l’ordinateur peut déterminer automatiquement si elle est bonne ou fausse. S’il n’existe pas de réponse standard, d’autres modèles peuvent être utilisés pour juger de la qualité.
De plus, nous pouvons également laisser les humains évaluer la qualité subjective, ou combiner l'évaluation informatique et humaine. Lorsque la réponse à la question est très longue et que la qualité des différentes réponses ne diffère pas beaucoup, alors le modèle peut évaluer la qualité par lui-même. .
Bien entendu, à mesure que les modèles deviennent plus avancés, de plus en plus de contenus peuvent être évalués automatiquement et de moins en moins d'évaluation manuelle sont nécessaires. Il est très difficile d'améliorer le système d'évaluation et la combinaison des ordinateurs et de l'intelligence artificielle est la meilleure méthode.
Évaluer les résultats du modèle par rapport aux réponses de référence
Supposons que nous soyons confrontés à un problème et que nous ayons besoin d'une réponse. Nous connaissons déjà la bonne réponse à cette question, basée sur certains faits. Par exemple, à la question « Pourquoi le ciel est-il bleu ? » La bonne réponse pourrait être « Parce que lorsque la lumière du soleil traverse l’atmosphère, la lumière dans la bande de lumière bleue passe mieux que les autres couleurs. »
Cette réponse est basée sur les faits suivants :
La lumière du soleil contient différentes couleurs (bandes lumineuses)
La bande de lumière bleue a moins de perte lors du passage dans l'atmosphère
Une fois que nous avons la question et la bonne réponse, nous pouvons utiliser un modèle (tel qu'un modèle d'apprentissage automatique) pour juger de l'importance de chaque fait dans la réponse à la bonne réponse.
Par exemple, le modèle détermine que le fait que « la lumière du soleil contient différentes couleurs » dans la réponse est très important pour l'exactitude de la réponse. Le fait que « la bande de lumière bleue a moins de perte » est également important pour la réponse. De cette façon, nous pouvons savoir de quels faits clés connus dépend la réponse à cette question.

Dans le processus de communication homme-machine avec ChatGPT, les mots d'invite semblent simples, mais ils constituent l'existence la plus critique. À l'ère numérique, les mots d'invite sont le point de départ de la division des exigences. En concevant des mots d'invite intelligents, nous pouvons diviser l'ensemble tâche divisée en une série d’étapes concises.
Une telle décomposition aide non seulement le modèle à mieux comprendre l'intention de l'utilisateur, mais fournit également à l'utilisateur un chemin de fonctionnement plus clair, tout comme un indice pour nous guider étape par étape pour découvrir la réponse au problème.
Vos et mes besoins sont comme une rivière en crue, et le mot d'invite est comme une écluse qui régule la direction du flux. Il joue le rôle de plaque tournante, reliant la pensée de l'utilisateur et la compréhension de la machine. Il n'est pas exagéré de dire qu'un bon mot d'invite n'est pas seulement un aperçu de la compréhension profonde de l'utilisateur, mais aussi une compréhension tacite de la communication homme-machine.
Bien sûr, si vous souhaitez vraiment maîtriser les compétences nécessaires à l'utilisation de mots rapides, il ne suffit pas de compter uniquement sur l'ingénierie Prompt, mais le guide d'utilisation officiel d'OpenAI nous fournit toujours de précieuses indications d'introduction.
# Bienvenue pour suivre le compte public officiel WeChat d'aifaner : aifaner (ID WeChat : ifanr). Un contenu plus passionnant vous sera fourni dès que possible.
Ai Faner | Lien original · Voir les commentaires · Sina Weibo