
AGI arrive vite ! Le modèle multimodal de l’Assemblée populaire nationale réalise pour la première fois une mise à jour indépendante, et la génération de photos et de vidéos dépasse celle de Sora.

L’AGI (intelligence générale artificielle) est le Saint Graal de toute l’industrie de l’IA.
L'année dernière, l'ancien scientifique en chef d'OpenAI, Ilya Sutskeve, a exprimé son point de vue : "Tant que nous pouvons très bien prédire le prochain jeton, nous pouvons aider les humains à atteindre l'AGI."
Geoffrey Hinton, lauréat du Turing Award, connu comme le père de l'apprentissage profond, et Sam Altman, PDG d'OpenAI, pensent tous deux que l'AGI arrivera d'ici dix ans, voire plus tôt.
L’AGI n’est pas la fin, mais un nouveau point de départ dans l’histoire du développement humain. Il y a de nombreux éléments à prendre en compte sur la voie de l'AGI, et l'industrie chinoise de l'IA est également une force qui ne peut être ignorée.
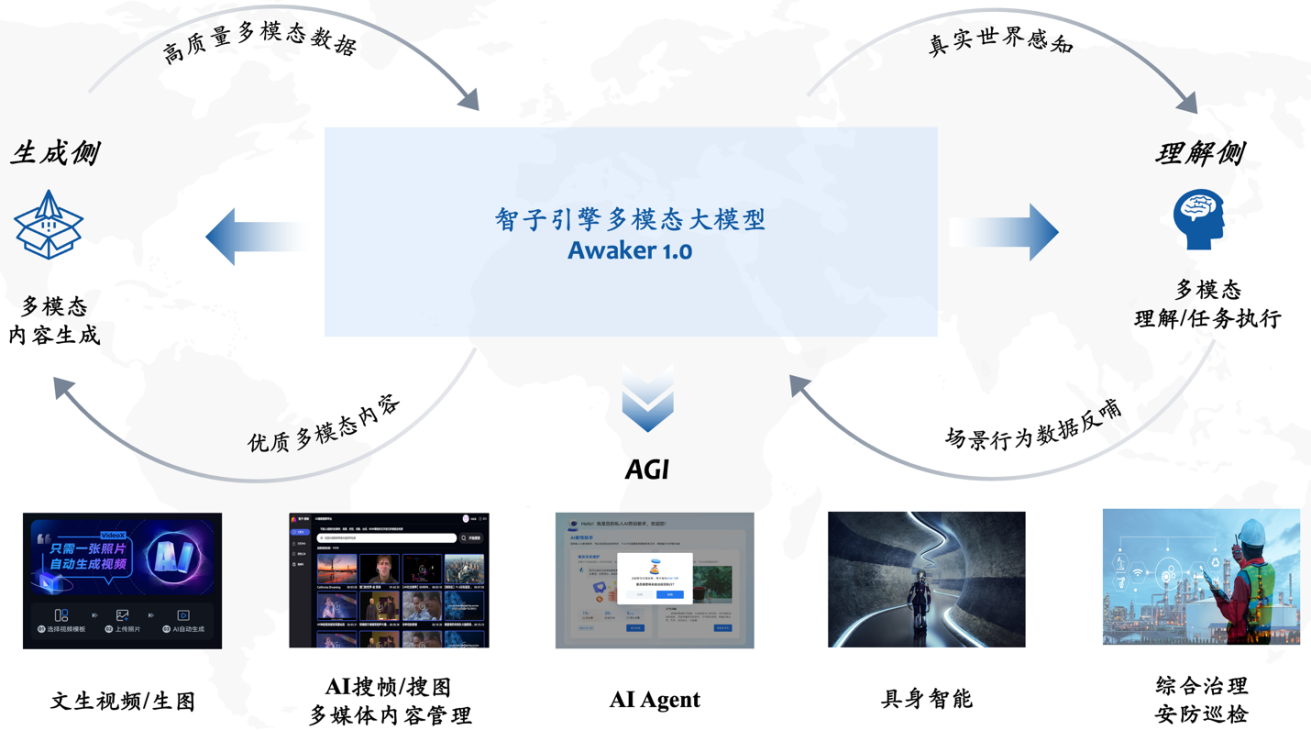
Lors du Forum parallèle général sur l'intelligence artificielle du Forum Zhongguancun qui s'est tenu le 27 avril, Sophon Engine, une startup affiliée à l'Université Renmin de Chine, a lancé en grande pompe un nouveau grand modèle multimodal Awaker 1.0, franchissant une étape cruciale vers l'AGI.
Par rapport au modèle de séquence ChatImg de la génération précédente du moteur Sophon, Awaker 1.0 adopte une nouvelle architecture MOE et dispose de capacités de mise à jour indépendantes. Il s'agit du premier grand modèle multimodal de l'industrie à réaliser une « véritable » mise à jour indépendante . En termes de génération visuelle, Awaker 1.0 utilise une base de génération vidéo VDT entièrement développée par lui-même, qui obtient de meilleurs résultats que Sora dans la génération photo-vidéo, brisant ainsi la difficulté du « dernier kilomètre » de l'atterrissage de grands modèles.

Modèle de base MOE d'Awaker
Du côté de la compréhension, le modèle de base d'Awaker 1.0 résout principalement le problème des conflits graves dans la pré-formation multimodale et multitâche. Bénéficiant de l'architecture MOE multitâche soigneusement conçue, le modèle de base d'Awaker 1.0 peut non seulement hériter des capacités de base du grand modèle multimodal de génération précédente du moteur Sophon, ChatImg, mais également apprendre les capacités uniques requises pour chaque tâche multimodale. . Par rapport au grand modèle multimodal ChatImg de la génération précédente, les capacités du modèle de base d'Awaker 1.0 ont été considérablement améliorées dans plusieurs tâches.
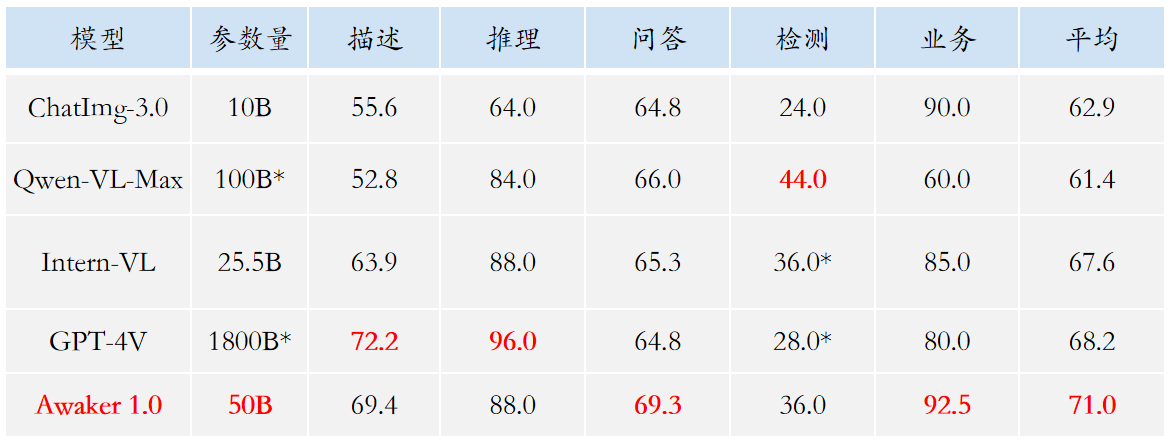
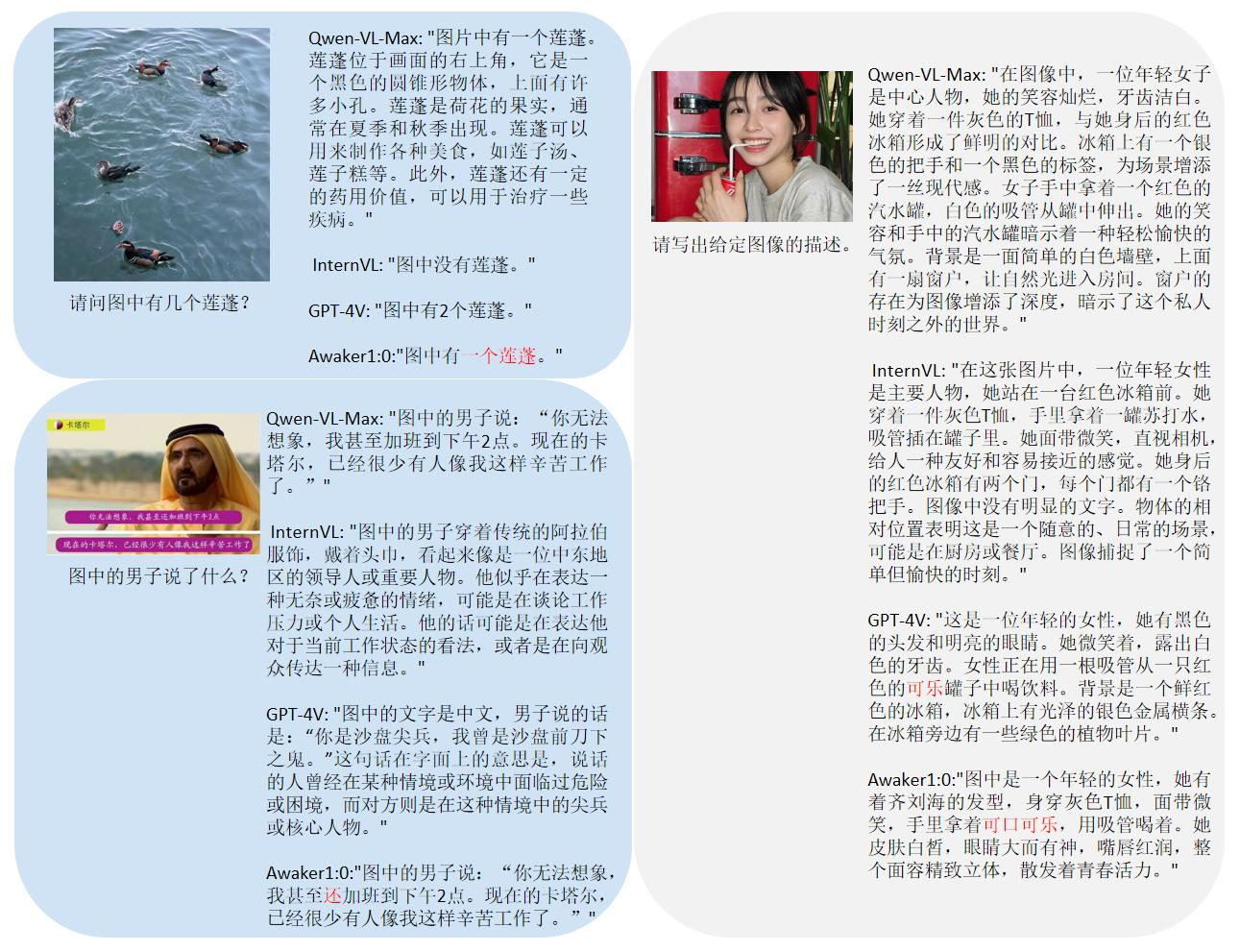
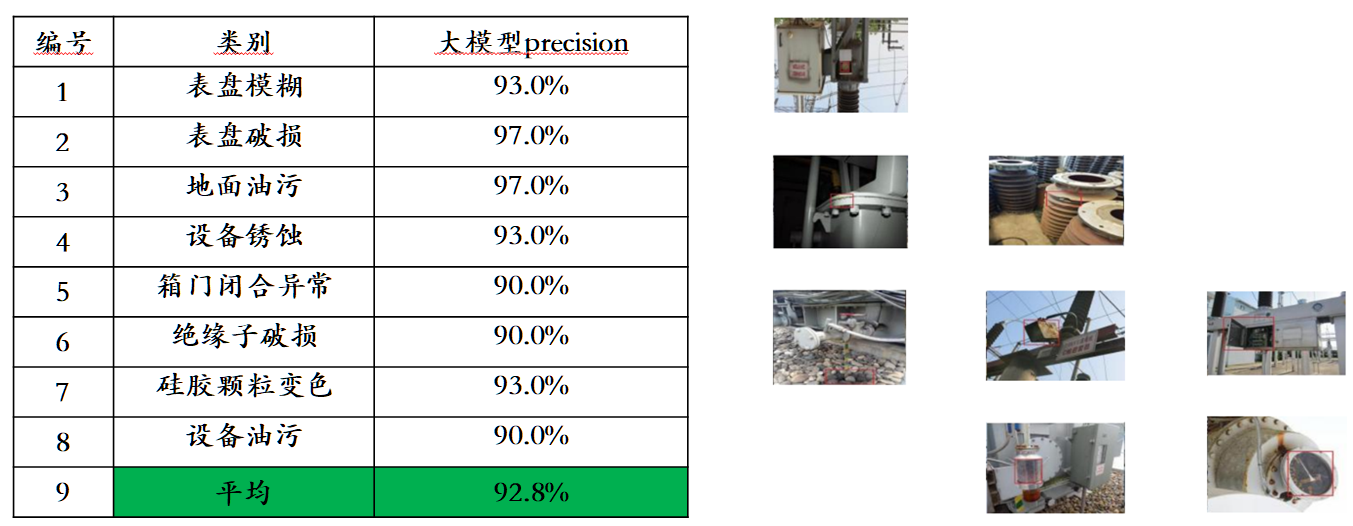
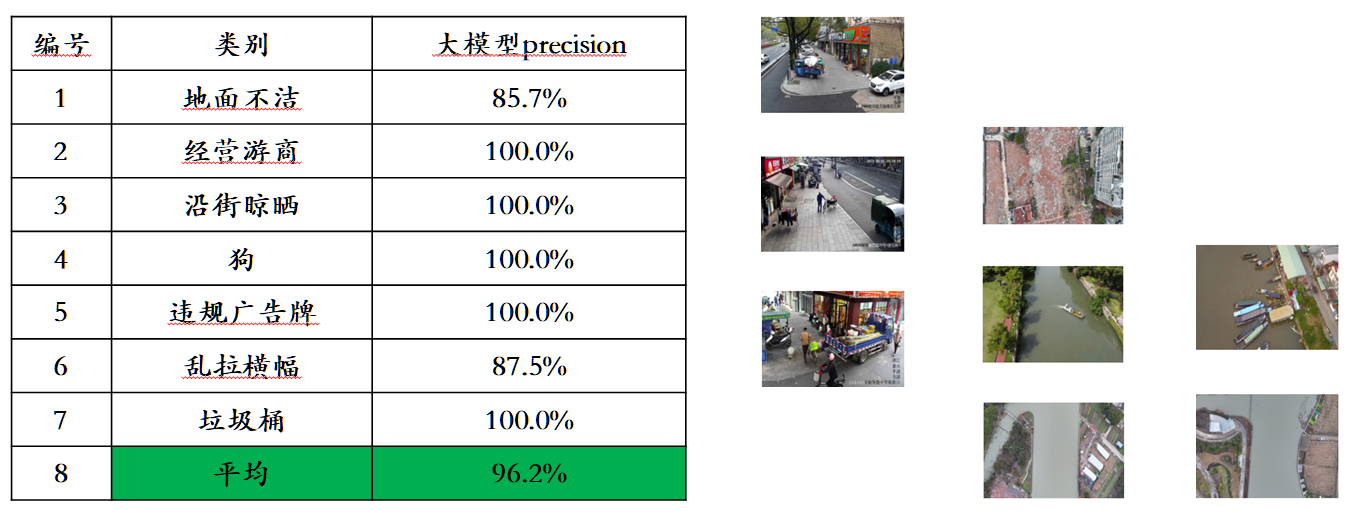
Compte tenu du problème de fuite de données d'évaluation dans les listes d'évaluation multimodales traditionnelles, Sophon Engine a divulgué une norme stricte pour créer son propre ensemble d'évaluation, dans lequel la plupart des images de test proviennent d'albums personnels de téléphones portables. Dans cet ensemble d'évaluation multimodale, il effectue une évaluation manuelle équitable sur Awaker 1.0 et les trois grands modèles multimodaux les plus avancés au pays et à l'étranger. Les résultats détaillés de l'évaluation sont présentés dans le tableau ci-dessous. Notez que GPT-4V et Intern-VL ne prennent pas directement en charge les tâches de détection. Leurs résultats de détection sont obtenus en exigeant que le modèle utilise un langage pour décrire l'orientation de l'objet.
Awaker+ Intelligence Incarnée : Vers l’AGI
La combinaison de grands modèles multimodaux et d’intelligence incorporée est très naturelle, car les capacités de compréhension visuelle des grands modèles multimodaux peuvent être naturellement combinées avec des caméras intelligentes incorporées. Dans le domaine de l'intelligence artificielle, « grand modèle multimodal + intelligence incorporée » est même considéré comme une voie réalisable pour parvenir à l'intelligence artificielle générale (AGI).
D'une part, les gens s'attendent à ce que l'intelligence incorporée soit adaptable, c'est-à-dire que l'agent peut s'adapter à des environnements d'application changeants grâce à un apprentissage continu. Il peut non seulement faire de mieux en mieux sur des tâches multimodales connues, mais aussi s'adapter rapidement à des tâches multimodales inconnues. -tâches modales. D’un autre côté, les gens s’attendent également à ce que l’intelligence incarnée soit véritablement créative, en espérant qu’elle puisse découvrir de nouvelles stratégies et solutions et explorer les limites des capacités de l’intelligence artificielle grâce à l’exploration autonome de l’environnement. En utilisant de grands modèles multimodaux comme « cerveaux » de l’intelligence incarnée, il est possible d’améliorer considérablement l’adaptabilité et la créativité de l’intelligence incarnée, approchant ainsi éventuellement le seuil de l’AGI (ou même atteignant l’AGI).
Cependant, les grands modèles multimodaux existants présentent deux problèmes évidents : premièrement, le cycle de mise à jour itérative du modèle est long, nécessitant beaucoup d'investissements humains et financiers. Deuxièmement, les données de formation du modèle sont toutes dérivées de données existantes ; , et le modèle incapable d'acquérir continuellement de grandes quantités de nouvelles connaissances. Bien que de nouvelles connaissances continues puissent également être injectées via RAG et un contexte long, le grand modèle multimodal lui-même n'apprend pas ces nouvelles connaissances, et ces deux méthodes de remédiation entraîneront également des problèmes supplémentaires. En bref, les grands modèles multimodaux actuels ne sont pas très adaptables aux scénarios d'application réels, encore moins créatifs, ce qui entraîne diverses difficultés lors de leur mise en œuvre dans l'industrie.
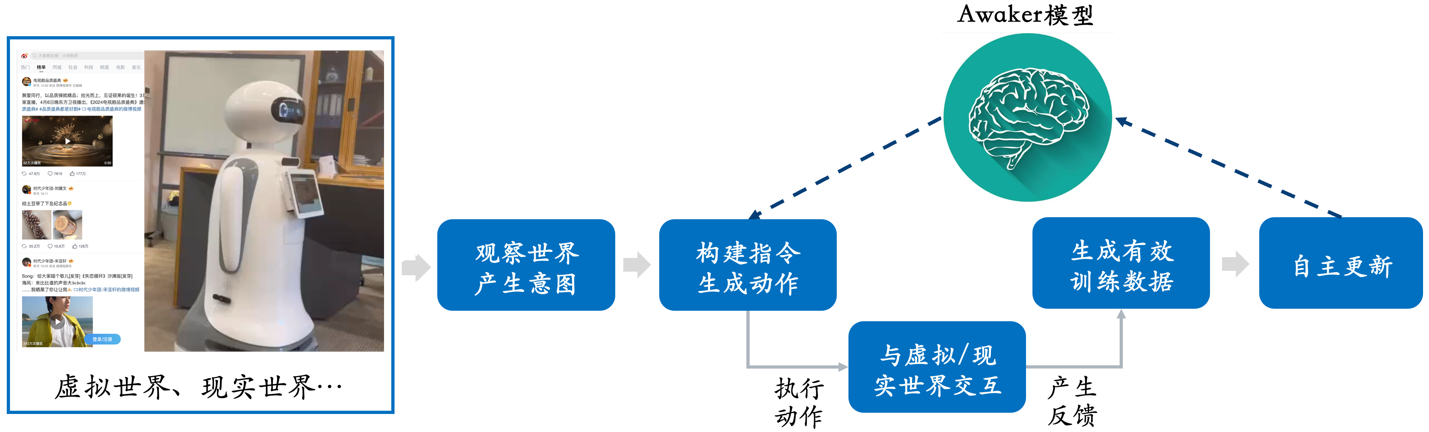
Awaker 1.0 publié cette fois par Sophon Engine est le premier grand modèle multimodal au monde doté d'un mécanisme de mise à jour autonome, qui peut être utilisé comme « cerveau » de l'intelligence incarnée. Le mécanisme de mise à jour autonome d'Awaker 1.0 comprend trois technologies clés : la génération active de données, la réflexion et l'évaluation du modèle et la mise à jour continue du modèle .
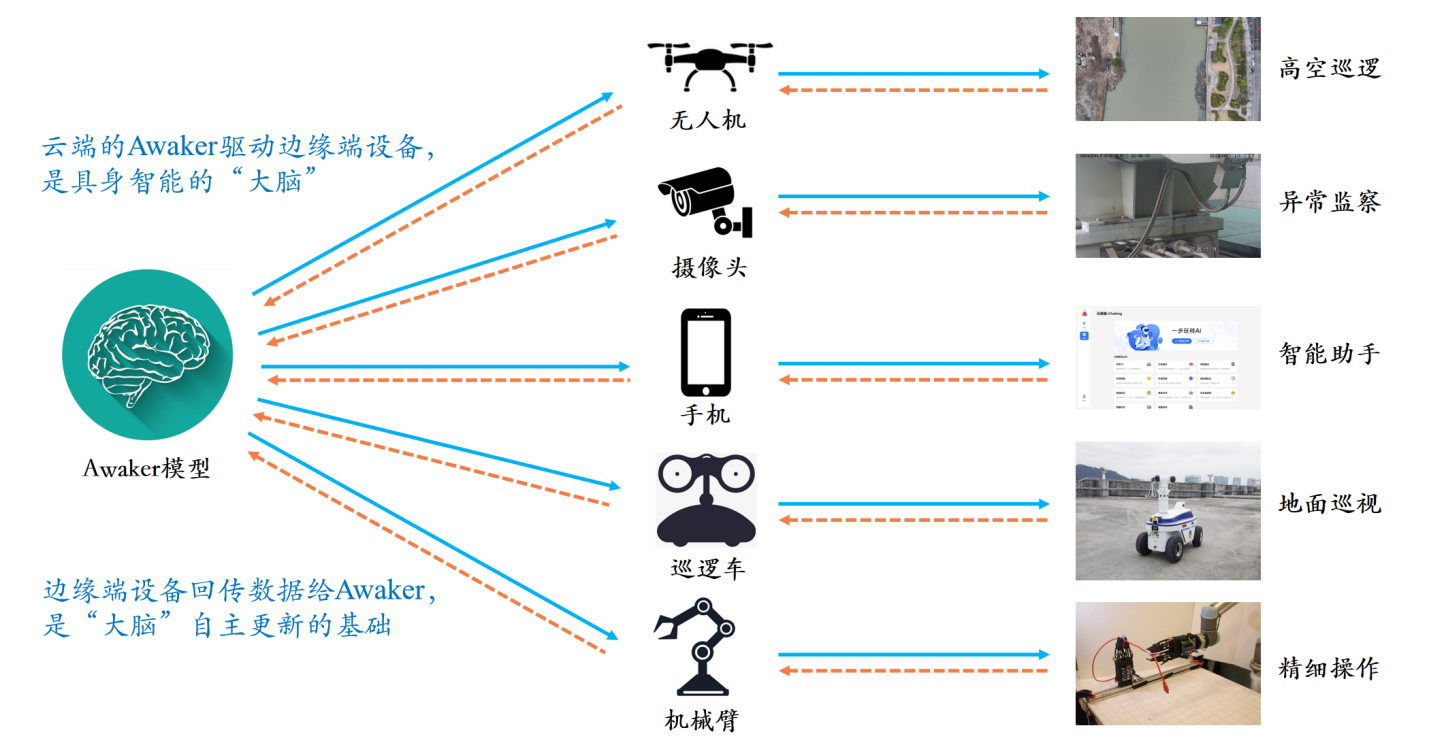
Différent de tous les autres grands modèles multimodaux, Awaker 1.0 est « live » et ses paramètres peuvent être continuellement mis à jour en temps réel. Comme le montre le diagramme de cadre ci-dessus, Awaker 1.0 peut être combiné avec divers appareils intelligents, observer le monde à travers des appareils intelligents, générer des intentions d'action et construire automatiquement des instructions pour contrôler les appareils intelligents afin d'effectuer diverses actions. Les appareils intelligents généreront automatiquement divers retours après avoir effectué diverses actions. Awaker 1.0 peut obtenir des données d'entraînement efficaces à partir de ces actions et retours pour une mise à jour automatique continue et renforcer continuellement les différentes capacités du modèle.
En prenant comme exemple l'injection de nouvelles connaissances, Awaker 1.0 peut apprendre en permanence les dernières informations sur Internet et répondre à diverses questions complexes basées sur les informations d'actualité nouvellement apprises. Différent des méthodes traditionnelles de RAG et de contexte long, Awaker 1.0 permet véritablement d'apprendre de nouvelles connaissances et de les « mémoriser » sur les paramètres du modèle.

Comme le montre l'exemple ci-dessus, pendant trois jours consécutifs d'auto-mise à jour, Awaker 1.0 a été capable d'apprendre chaque jour les informations d'actualité du jour et de prononcer avec précision les informations correspondantes en répondant aux questions. Dans le même temps, Awaker 1.0 n'oubliera pas les connaissances acquises pendant le processus d'apprentissage continu. Par exemple, les connaissances de Zhijie S7 sont toujours mémorisées ou comprises par Awaker 1.0 après 2 jours.
Awaker 1.0 peut également être combiné avec divers appareils intelligents pour réaliser une collaboration à la pointe du cloud. Awaker 1.0 est déployé dans le cloud en tant que « cerveau » pour contrôler divers appareils intelligents de pointe afin d'effectuer diverses tâches. Les commentaires obtenus lorsque l'appareil intelligent Edge effectue diverses tâches seront transmis en continu à Awaker 1.0, lui permettant d'obtenir en permanence des données d'entraînement et de se mettre à jour en permanence.
Simulateur du monde réel : VDT
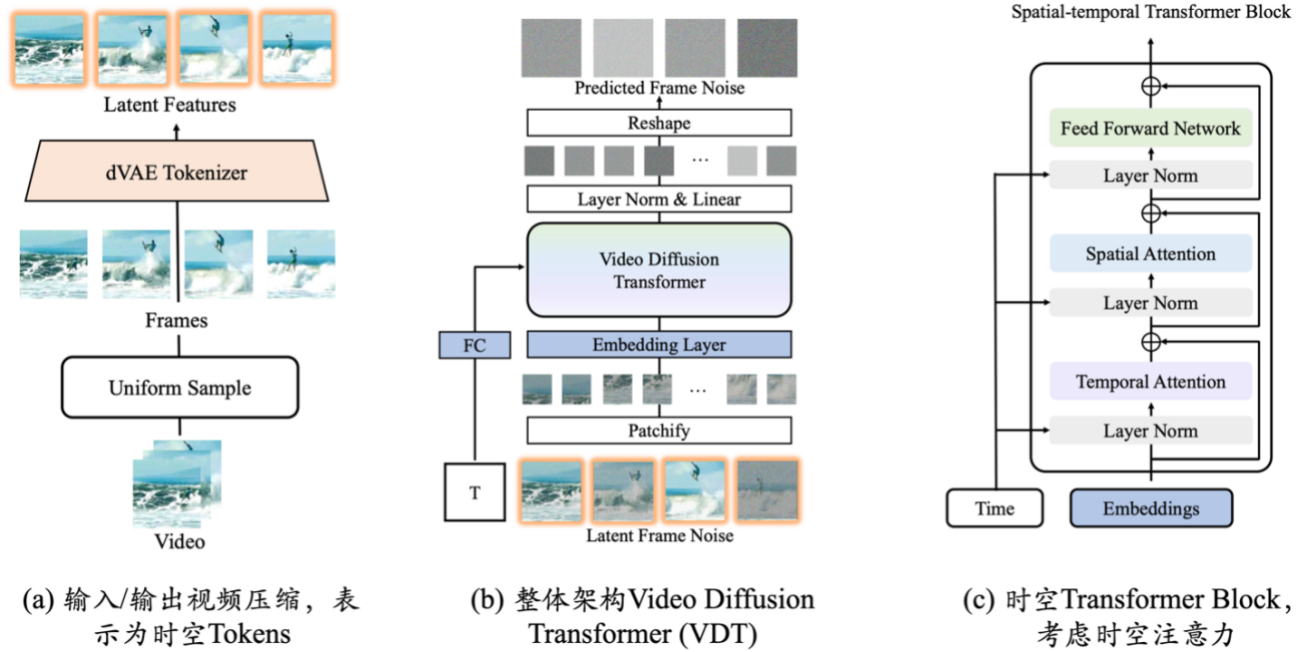
Les innovations de la base de génération vidéo VDT incluent principalement les aspects suivants :
- L'application de la technologie Transformer à la génération vidéo basée sur la diffusion démontre le grand potentiel de Transformer dans le domaine de la génération vidéo. L'avantage du VDT réside dans son excellente capacité de capture en fonction du temps, permettant la génération d'images vidéo temporellement cohérentes, notamment la simulation de la dynamique physique d'objets tridimensionnels au fil du temps.
- Un mécanisme unifié de modélisation de masque spatio-temporel est proposé pour permettre à VDT de gérer une variété de tâches de génération vidéo, réalisant ainsi la large application de cette technologie. Les méthodes flexibles de traitement de l'information conditionnelle de VDT, telles que le simple épissage de l'espace de jetons, unifient efficacement les informations de différentes longueurs et modalités. Dans le même temps, en se combinant avec le mécanisme de modélisation de masque spatio-temporel, VDT est devenu un outil de diffusion vidéo universel, qui peut être appliqué à la génération inconditionnelle, à la prédiction d'images vidéo ultérieures, à l'interpolation d'images, aux vidéos génératrices d'images et aux images vidéo sans modifier le structure du modèle. Achèvement et autres tâches de génération vidéo.
L'équipe du moteur Sophon s'est concentrée sur l'exploration de la simulation de lois physiques simples par VDT et a formé VDT sur l'ensemble de données Physion. Dans l’exemple suivant, nous avons constaté que VDT simulait avec succès des processus physiques, tels que la balle se déplaçant le long d’une trajectoire parabolique et la balle roulant sur un avion et entrant en collision avec d’autres objets. Dans le même temps, le deuxième exemple de la ligne 2 montre également que VDT a capturé la vitesse et l'élan de la balle, car la balle n'a finalement pas renversé le pilier en raison d'une force d'impact insuffisante. Cela prouve que l'architecture Transformer peut apprendre certaines lois physiques.

Ils ont également mené une exploration approfondie de la tâche de génération de photos et de vidéos. Cette tâche impose des exigences très élevées en matière de qualité de génération vidéo, car nous sommes naturellement plus sensibles aux changements dynamiques des visages et des personnages. Compte tenu de la particularité de cette tâche, les chercheurs doivent combiner VDT (ou Sora) et génération contrôlable pour relever les défis de la génération photo vidéo. À l'heure actuelle, le moteur Sophon a dépassé la plupart des technologies clés de génération de photo-vidéo et a atteint une meilleure qualité de génération de photo-vidéo que Sora. Le moteur Sophon continuera d’optimiser l’algorithme de génération contrôlable de portraits et explore également activement sa commercialisation. À l'heure actuelle, un scénario d'atterrissage commercial confirmé a été trouvé, et il devrait résoudre dans un avenir proche la difficulté d'atterrir de grands modèles dans le « dernier kilomètre ».
À l’avenir, un écran de visualisation plus polyvalent deviendra un outil puissant pour résoudre le problème des sources de données multimodales de grands modèles. Grâce à la génération vidéo, VDT sera capable de simuler le monde réel, d'améliorer encore l'efficacité de la production de données visuelles et de fournir une assistance pour la mise à jour indépendante du grand modèle multimodal Awaker.
Conclusion
Awaker 1.0 est une étape clé pour l'équipe du moteur Sophon pour avancer vers l'objectif ultime de « réaliser AGI ». Sophon Engine a déclaré à l'APPSO que l'équipe estime que l'auto-exploration, l'auto-réflexion et d'autres capacités d'apprentissage autonome de l'IA sont des critères d'évaluation importants du niveau d'intelligence, et sont tout aussi importants que l'augmentation continue de l'échelle des paramètres (loi d'échelle).
Awaker 1.0 a mis en œuvre des cadres techniques clés tels que « la génération active de données, la réflexion et l'évaluation du modèle et la mise à jour continue du modèle », réalisant des avancées tant du côté de la compréhension que du côté de la génération. Il devrait accélérer le développement du grand multimodal. modéliser l'industrie et finalement permettre aux humains de réaliser l'AGI.
# Bienvenue pour suivre le compte public officiel WeChat d'aifaner : aifaner (ID WeChat : ifanr). Un contenu plus passionnant vous sera fourni dès que possible.
Ai Faner | Lien original · Voir les commentaires · Sina Weibo