
Comment trier des fichiers texte sous Linux à l’aide de la commande sort
Linux vous fournit plusieurs utilitaires que vous pouvez utiliser pour traiter des fichiers texte. Que vous souhaitiez supprimer les données en double ou trier le contenu dans un fichier, les outils de ligne de commande Linux ont tout ce dont vous avez besoin.
Cet article montrera la commande de tri et comment vous pouvez l'utiliser pour trier le contenu dans un fichier texte et l'organiser en conséquence.
Quelle est la commande de tri ?
Comme mentionné ci-dessus, la commande de tri aide un utilisateur à organiser le contenu d'un fichier texte dans un ordre particulier. Plusieurs options sont disponibles qui vous permettent de trier le dossier selon votre souhait. Il s'agit d'un programme Linux standard qui peut trier un fichier texte par ordre alphabétique, numérique, par colonne, etc., dans l'ordre normal ou inverse.
D'autres fonctionnalités de la commande incluent l'ignorance de la casse des caractères lors du tri, le tri d'un fichier par mois, l'ignorance des blancs dans un fichier et le tri aléatoire. En utilisant le tri, vous pouvez également vérifier si un fichier est déjà trié ou non.
Comment utiliser le tri sous Linux
Bien que le tri contienne plusieurs méthodes et indicateurs que vous pouvez utiliser, il reste facile à apprendre.
Syntaxe de base
La syntaxe de base de l'utilisation de sort est :
sort filename…où filename est le chemin absolu ou relatif du fichier texte que vous souhaitez trier.
Par défaut, le tri organisera le contenu selon les critères suivants :
- Les lignes commençant par des caractères numériques ont la priorité la plus élevée.
- La commande va trier les lignes par ordre alphabétique, après avoir trié les lignes commençant par des nombres.
- Les lignes commençant par des caractères minuscules précèdent les lignes commençant par le même caractère en majuscule.
Considérez un fichier texte nommé textfile.txt contenant les informations suivantes :
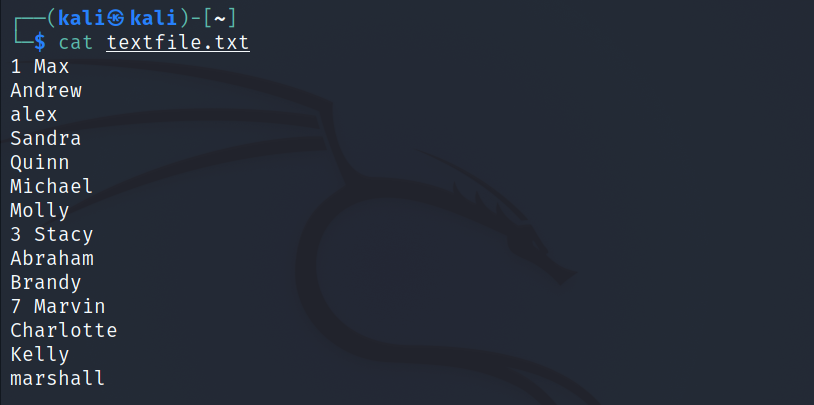
Pour trier le fichier à l'aide de la configuration par défaut :
sort textfile.txtProduction:

Créer un nouveau fichier de sortie
La commande sort ne modifie pas le contenu du fichier. Il envoie simplement le contenu trié à la sortie standard. Cependant, cela ne signifie pas que le tri ne peut pas créer un nouveau fichier. Vous pouvez utiliser l'indicateur -o pour spécifier le nom du fichier trié et tri créera automatiquement le fichier pour vous et ajoutera le contenu.
sort -o sortedfile filename…où sortedfile est le nom du fichier de sortie et filename est le fichier d'origine qui doit être trié.
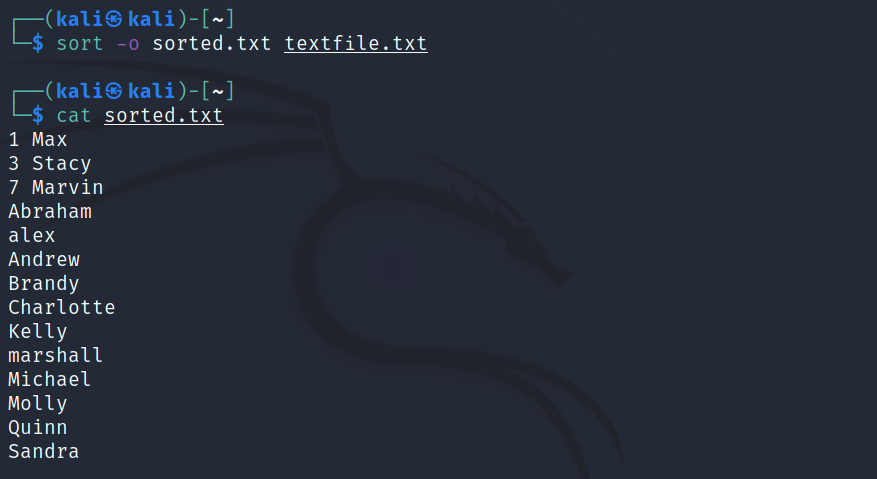
Pour trier textfile.txt et créer un nouveau fichier de sortie pour le contenu :
sort -o sorted.txt textfile.txtProduction:
Trier plusieurs fichiers
Pour trier plusieurs fichiers à la fois, transmettez simplement les noms de fichiers séparés par le caractère Espace .
sort textfile.txt textfile2.txtProduction:
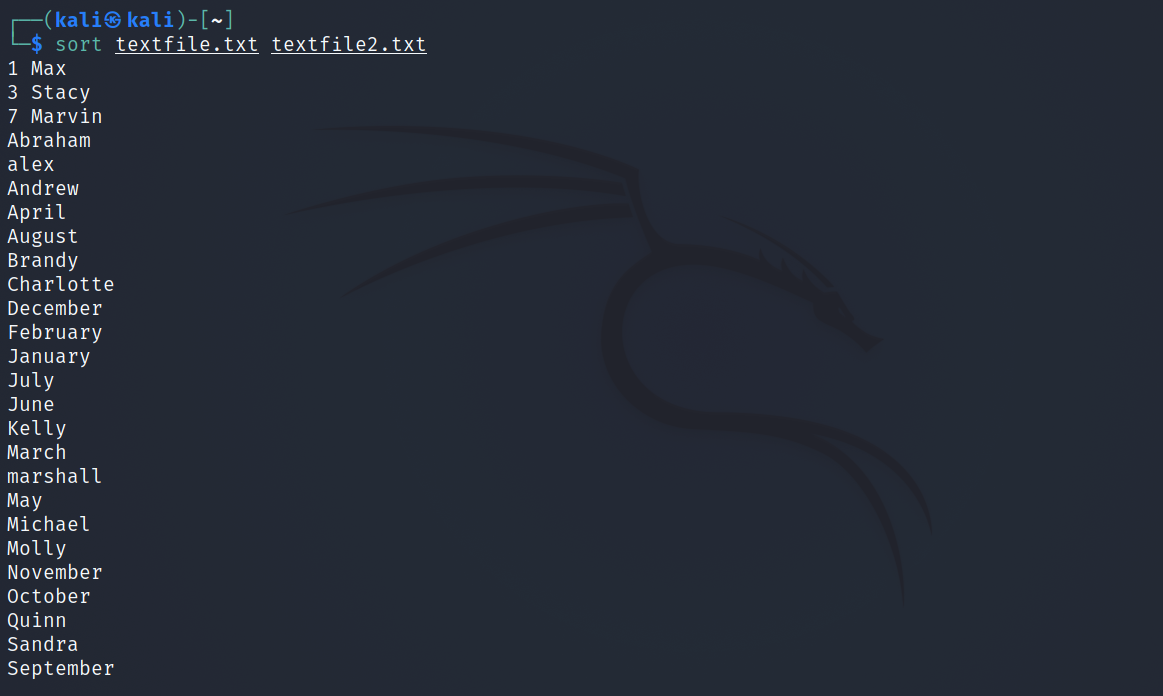
Notez que sort fusionnera la sortie des fichiers et les affichera ensemble dans le terminal.
Trier un fichier à l'envers
Si vous souhaitez inverser la disposition du contenu, utilisez l'indicateur -r avec la commande par défaut. Le -r dans la commande suivante signifie Reverse .
sort -r textfile.txtProduction:

Trier un fichier numériquement
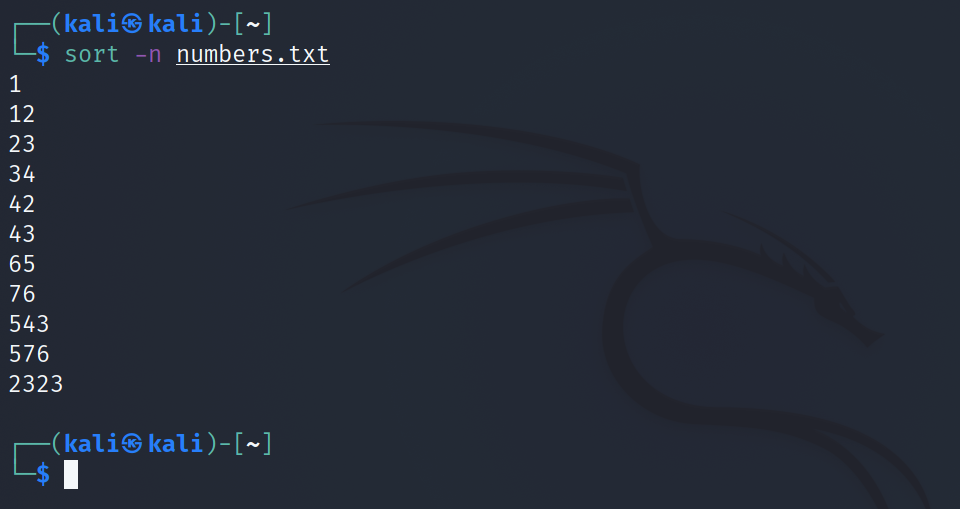
Pour trier un fichier contenant des données numériques, utilisez l'indicateur -n avec la commande. Par défaut, le tri organisera les données dans l'ordre croissant.
sort -n numbers.txtProduction:
Si vous souhaitez trier par ordre décroissant, inversez l'arrangement à l'aide de l'option -r avec l'indicateur -n dans la commande.
sort -rn numbers.txtProduction:

Ignorer la casse des caractères lors du tri
Par défaut, le tri prend en compte la casse des caractères du contenu. Les lignes commençant par des caractères minuscules précèdent les lignes commençant par la version majuscule du même caractère. Par exemple, « c'est un garçon » précédera « c'est un garçon ».
Si vous souhaitez que le tri ignore la casse des caractères, spécifiez l' indicateur -f ou –ignore-case comme suit :
sort -f textfile.txt
sort --ignore-case textfile.txtProduction:

Trier un fichier en fonction du mois
À l'aide de l'indicateur -M , vous pouvez modifier l'ordre du contenu d'un fichier en fonction des noms de mois.
sort -M textfile2.txtProduction:

Ignorer les blancs de début
Parfois, le fichier que vous souhaitez trier peut contenir des espaces ou des tabulations. Pour ignorer ces caractères vides, utilisez l'indicateur -b .
sort -b fileblanks.txtProduction:
Trier un fichier selon une colonne
Si vous avez un fichier texte avec des données organisées dans des colonnes séparées, vous pouvez trier le fichier en fonction du contenu d'une colonne. Tout ce que vous avez à faire est de passer le numéro de colonne avec l'indicateur -k .
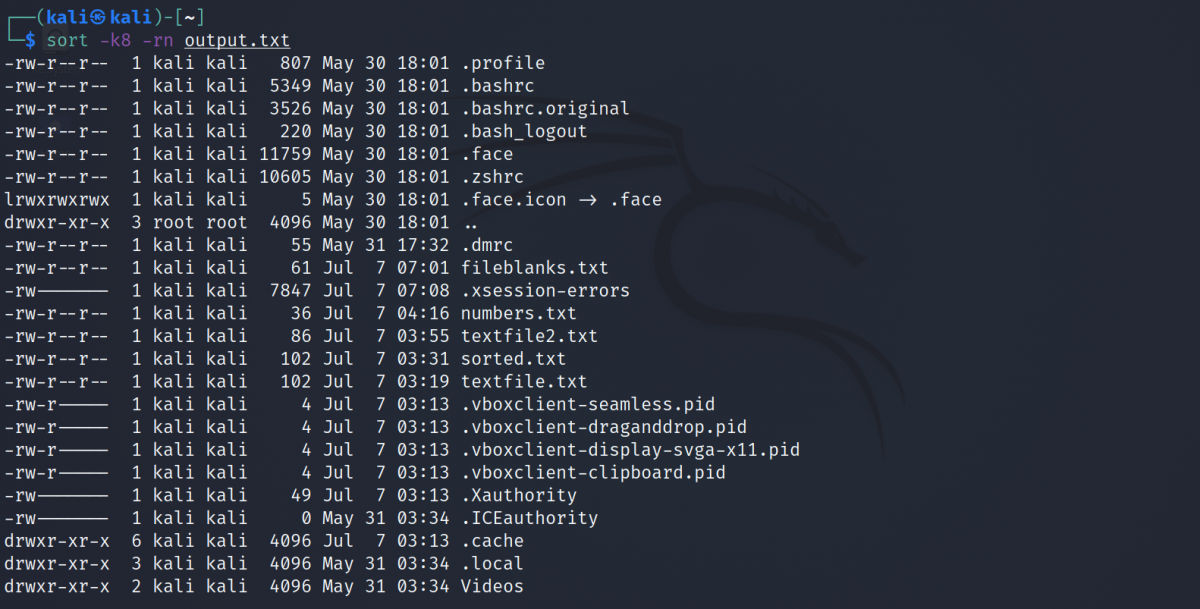
Considérons un fichier texte contenant des informations de fichier avec différentes colonnes. Pour trier un fichier nommé output.txt selon la huitième colonne :
sort -k8 -rn output.txtProduction:
Tri des tuyaux avec d'autres commandes
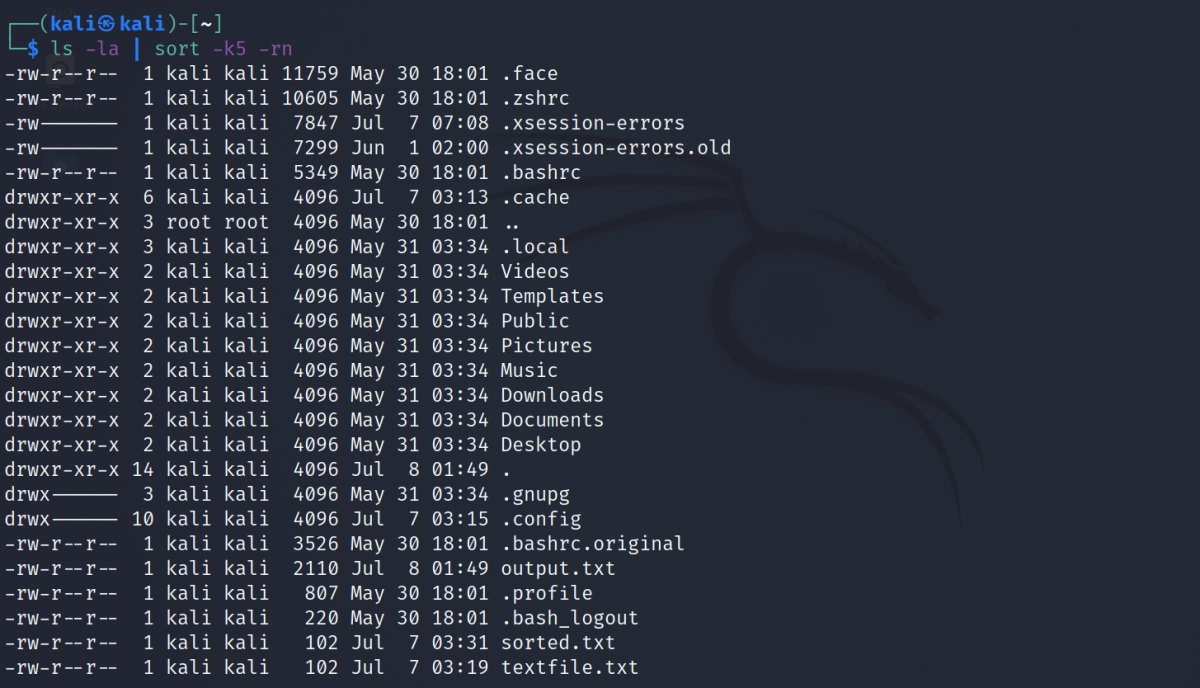
Vous pouvez même utiliser sort avec d'autres commandes Linux pour modifier la disposition de la sortie. Par exemple, pour trier la sortie de la commande ls en fonction de la taille des fichiers :
ls -la | sort -k5 -rnProduction:
Trier un fichier au hasard
Vous pouvez utiliser l'indicateur -R si vous souhaitez randomiser l'ordre des lignes dans un fichier texte. Considérez le fichier textfile.txt :

sort -R textfile.txtProduction:

Trier les numéros de version dans un fichier
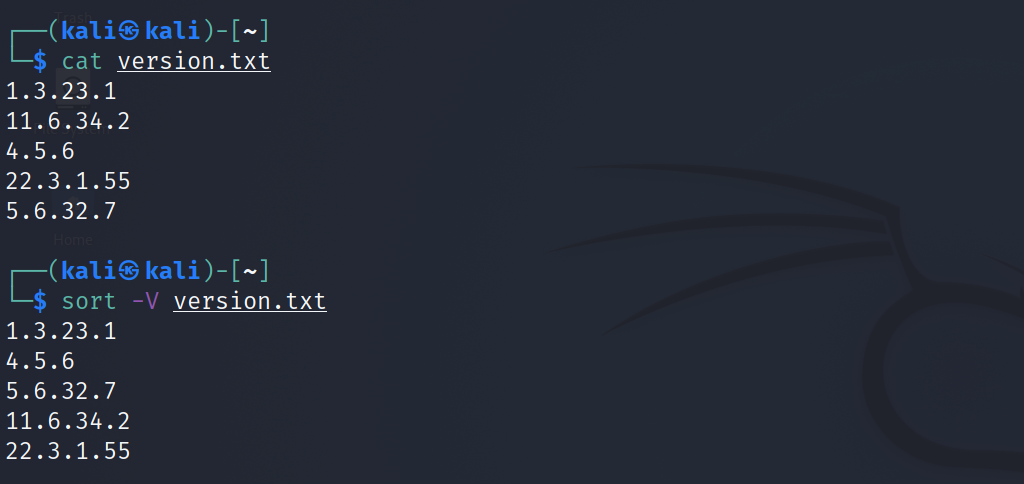
Si vous avez un fichier texte contenant des informations de version associées à un package, vous pouvez trier son contenu à l'aide de l'indicateur -V ou –version-sort .
sort -V version.txt
sort --version-sort version.txtProduction:
Vérifier si un fichier est trié
L'indicateur -c vous aidera à identifier les fichiers déjà triés selon les options spécifiées. Si le contenu du fichier est correctement trié, le tri n'affichera aucune sortie.
Pour vérifier si le fichier textfile.txt est trié :
sort -c textfile.txtMaintenant, trions le fichier et enregistrons sa sortie dans un nouveau fichier nommé sorted.txt . A l'émission de la commande suivante :
sort -c sorted.txtProduction:

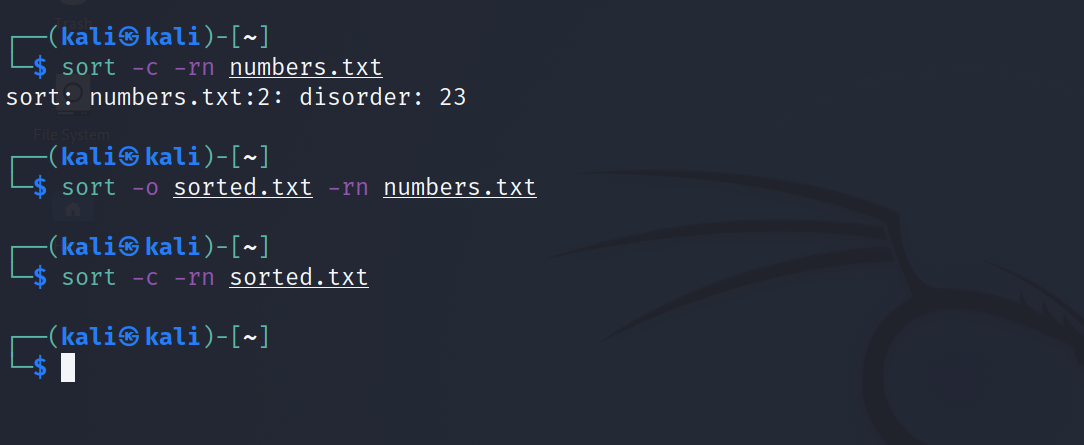
Vous pouvez également spécifier différents indicateurs pour vérifier l'agencement du fichier selon des critères particuliers. Par exemple, pour vérifier si le fichier number.txt est trié par ordre décroissant :
sort -c -rn numbers.txtVous verrez une sortie indiquant que le fichier n'est pas trié correctement. Trions le fichier et vérifions si le nouveau fichier réussit le test.
sort -o sorted.txt -rn numbers.txt
sort -c -rn sorted.txtProduction:
Trier le fichier et supprimer les doublons
Le fichier sur lequel vous travaillez peut contenir des données en double. Bien que vous puissiez utiliser la commande uniq pour supprimer ces informations du fichier, le tri peut effectuer cette tâche pour vous. L'indicateur -u ou –unique est ce dont vous avez besoin.
Considérons un fichier nommé duplicate.txt :
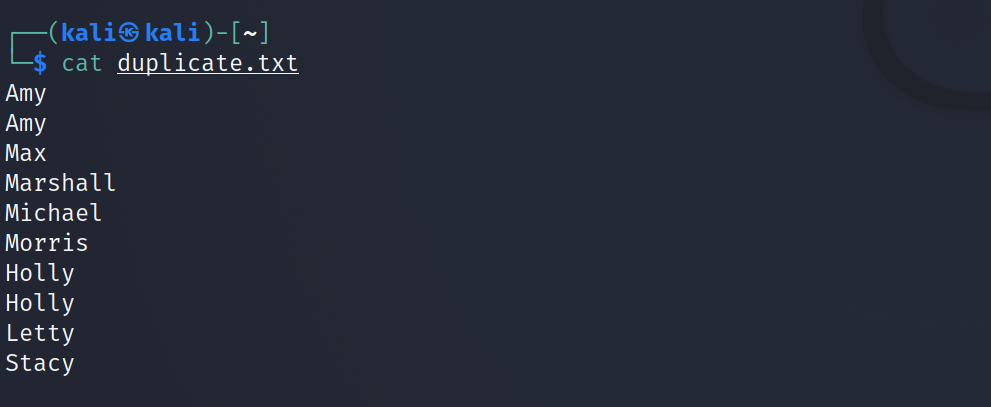
Pour trier le fichier et supprimer les données répétées :
sort -u duplicate.txtProduction:
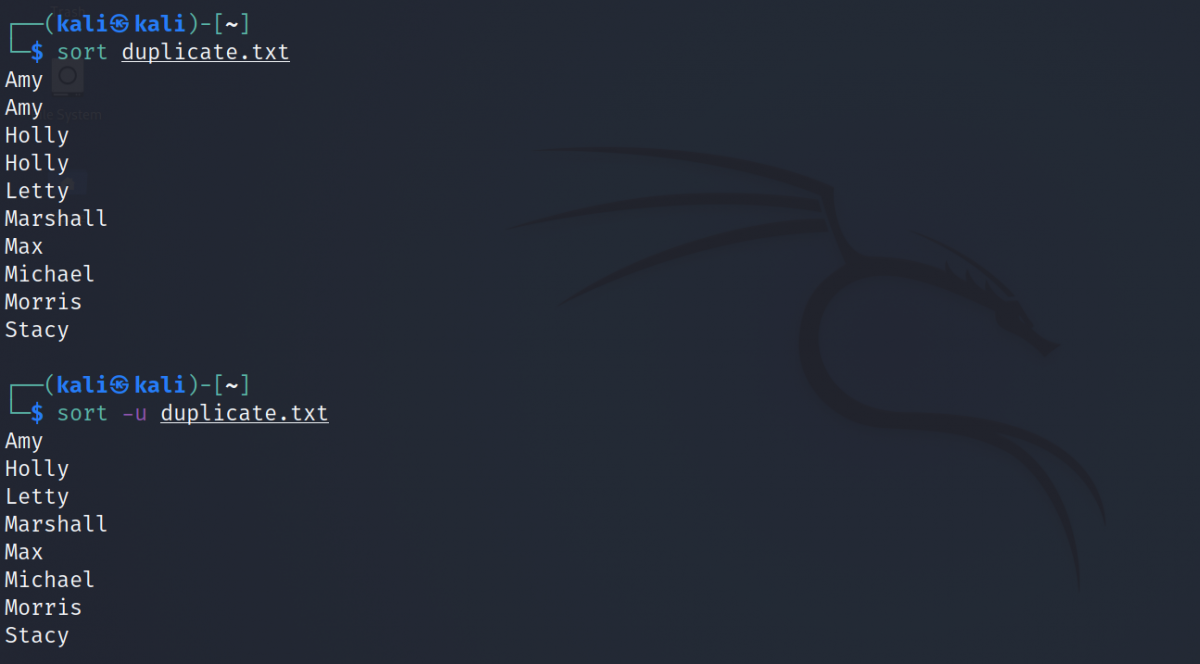
Vous pouvez voir que lorsque vous utilisez l'indicateur -u , sort affiche uniquement des lignes distinctes et les organise selon les critères spécifiés.
Travailler avec des fichiers texte sous Linux
Bien que la puissance des éditeurs de texte en ligne de commande soit incomparable, vous pouvez toujours opter pour un éditeur graphique tel que gedit pour modifier facilement le contenu d'un fichier texte. En outre, c'est un meilleur choix pour ceux qui débutent avec Linux et ne peuvent pas gérer le terminal.
La meilleure façon de commencer avec la ligne de commande, et Linux en général, est de commencer par pratiquer les commandes de base. Après avoir couvert les utilitaires fondamentaux, avancer progressivement vers des commandes plus complexes est probablement la meilleure approche.