
Comment trouver des données en double dans un fichier texte Linux avec uniq
Avez-vous déjà rencontré des fichiers texte avec des lignes répétées et des mots en double? Peut-être que vous travaillez régulièrement avec la sortie de commande et que vous souhaitez les filtrer pour des chaînes distinctes. En ce qui concerne les fichiers texte et la suppression des données redondantes sous Linux, la commande uniq est votre meilleur pari.
Dans cet article, nous aborderons en détail la commande uniq, ainsi qu'un guide détaillé sur la façon d'utiliser la commande pour supprimer les lignes en double d'un fichier texte.
Qu'est-ce que la commande uniq?
La commande uniq sous Linux est utilisée pour afficher des lignes identiques dans un fichier texte. Cette commande peut être utile si vous souhaitez supprimer des mots ou des chaînes en double d'un fichier texte. Étant donné que la commande uniq correspond aux lignes adjacentes pour rechercher des copies redondantes, elle ne fonctionne qu'avec des fichiers texte triés.
Heureusement, vous pouvez diriger la commande de tri avec uniq pour organiser le fichier texte d'une manière compatible avec la commande. Outre l'affichage de lignes répétées, la commande uniq peut également compter l'occurrence de lignes en double dans un fichier texte.
Comment utiliser la commande uniq
Il existe différentes options et indicateurs que vous pouvez utiliser avec uniq. Certains d'entre eux sont basiques et effectuent des opérations simples telles que l'impression de lignes répétées, tandis que d'autres sont destinés aux utilisateurs avancés qui travaillent fréquemment avec des fichiers texte sous Linux.
Syntaxe de base
La syntaxe de base de la commande uniq est:
uniq option input output… où option est l'indicateur utilisé pour invoquer des méthodes spécifiques de la commande, input est le fichier texte à traiter et output est le chemin du fichier qui stockera la sortie.
L'argument de sortie est facultatif et peut être ignoré. Si un utilisateur ne spécifie pas le fichier d'entrée, uniq prend les données de la sortie standard comme entrée. Cela permet à un utilisateur de diriger uniq avec d' autres commandes Linux .
Exemple de fichier texte
Nous utiliserons le fichier texte duplicate.txt comme entrée pour la commande.
127.0.0.1 TCP
127.0.0.1 UDP
Do catch this
DO CATCH THIS
Don't match this
Don't catch this
This is a text file.
This is a text file.
THIS IS A TEXT FILE.
Unique lines are really rare.
Notez que nous avons déjà trié ce fichier texte à l'aide de la commande sort . Si vous travaillez avec un autre fichier texte, vous pouvez le trier à l'aide de la commande suivante:
sort filename.txt > sorted.txtSupprimer les lignes en double
L'utilisation la plus élémentaire d'uniq consiste à supprimer les chaînes répétées de l'entrée et à imprimer une sortie unique.
uniq duplicate.txtProduction:
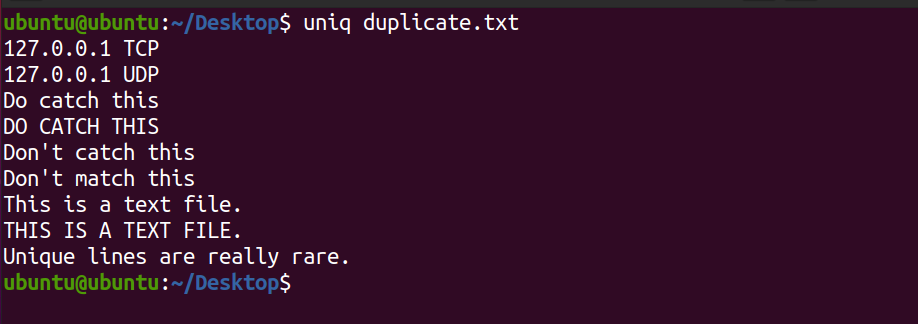
Notez que le système n'affiche pas la deuxième occurrence de la ligne Ceci est un fichier texte . En outre, la commande susmentionnée imprime uniquement les lignes uniques du fichier et n'affecte pas le contenu du fichier texte d'origine.
Compter les lignes répétées
Pour afficher le nombre de lignes répétées dans un fichier texte, utilisez l'indicateur -c avec la commande par défaut.
uniq -c duplicate.txtProduction:
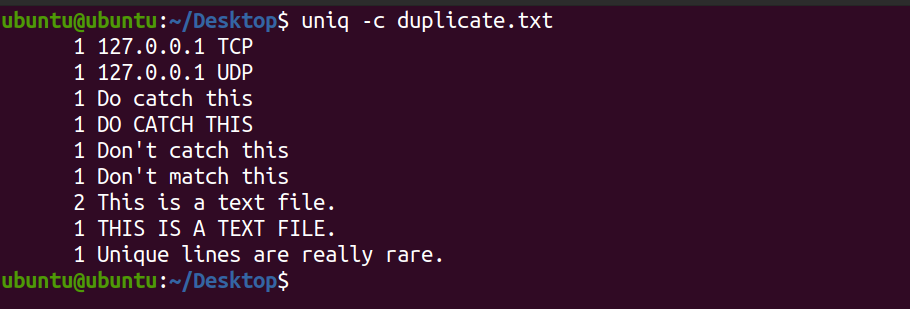
Le système affiche le nombre de chaque ligne qui existe dans le fichier texte. Vous pouvez voir que la ligne Ceci est un fichier texte apparaît deux fois dans le fichier. Par défaut, la commande uniq est sensible à la casse.
Imprimer uniquement les lignes répétées
Pour imprimer uniquement les lignes dupliquées du fichier texte, utilisez l'indicateur -D . Le -D signifie Duplicate .
uniq -D duplicate.txtLe système affichera la sortie comme suit.
This is a text file.
This is a text file.Ignorer les champs lors de la vérification des doublons
Si vous souhaitez ignorer un certain nombre de champs tout en faisant correspondre les chaînes, vous pouvez utiliser l'indicateur -f avec la commande. Le -f signifie Field .
Considérez le fichier texte suivant fields.txt .
192.168.0.1 TCP
127.0.0.1 TCP
354.231.1.1 TCP
Linux FS
Windows FS
macOS FSPour ignorer le premier champ:
uniq -f 1 fields.txtProduction:
192.168.0.1 TCP
Linux FSLa commande susmentionnée a ignoré le premier champ (les adresses IP et les noms de système d'exploitation) et correspond au deuxième mot (TCP et FS). Ensuite, il a affiché la première occurrence de chaque correspondance en tant que sortie.
Ignorer les caractères lors de la comparaison
Comme pour sauter des champs, vous pouvez également sauter des caractères. L'indicateur -s vous permet de spécifier le nombre de caractères à ignorer tout en faisant correspondre les lignes en double. Cette fonctionnalité est utile lorsque les données avec lesquelles vous travaillez se présentent sous la forme d'une liste comme suit:
1. First
2. Second
3. Second
4. Second
5. Third
6. Third
7. Fourth
8. FifthPour ignorer les deux premiers caractères (la numérotation des listes) dans le fichier list.txt :
uniq -s 2 list.txtProduction:
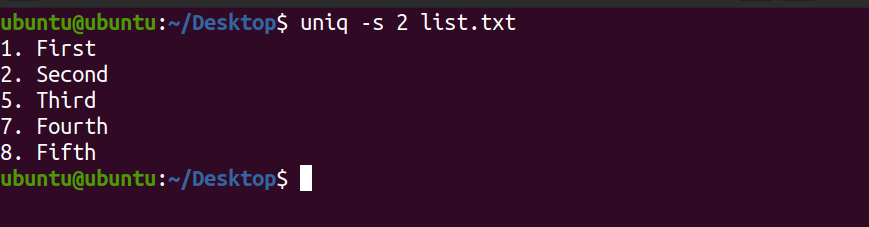
Dans la sortie ci-dessus, les deux premiers caractères ont été ignorés et les autres ont été mis en correspondance pour des lignes uniques.
Vérifier les N premiers caractères pour les doublons
L'indicateur -w vous permet de vérifier uniquement un nombre fixe de caractères pour les doublons. Par example:
uniq -w 2 duplicate.txtLa commande susmentionnée ne correspondra qu'aux deux premiers caractères et imprimera des lignes uniques le cas échéant.
Production:
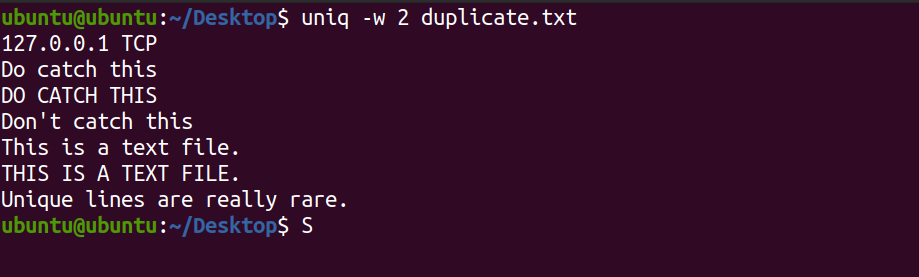
Supprimer la sensibilité à la casse
Comme mentionné ci-dessus, uniq est sensible à la casse tout en faisant correspondre les lignes d'un fichier. Pour ignorer la casse des caractères, utilisez l'option -i avec la commande.
uniq -i duplicate.txtVous verrez la sortie suivante.
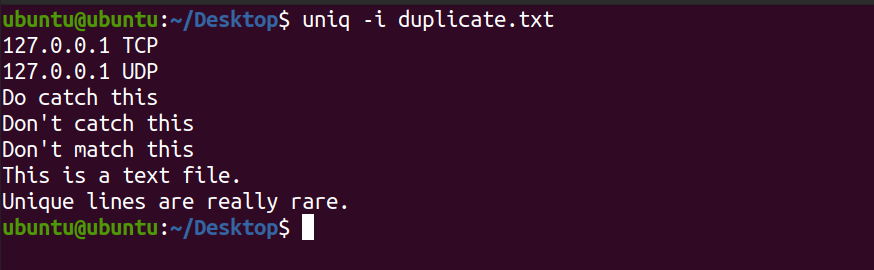
Remarquez dans la sortie ci-dessus, uniq n'affiche pas les lignes DO CATCH THIS et THIS IS A TEXT FILE .
Envoyer la sortie vers un fichier
Pour envoyer la sortie de la commande uniq vers un fichier, vous pouvez utiliser le caractère de redirection de sortie ( > ) comme suit:
uniq -i duplicate.txt > otherfile.txtLors de l'envoi d'une sortie vers un fichier texte, le système n'affiche pas la sortie de la commande. Vous pouvez vérifier le contenu du nouveau fichier à l'aide de la commande cat .
cat otherfile.txtVous pouvez également utiliser d'autres méthodes pour envoyer la sortie de ligne de commande à un fichier sous Linux .
Analyse de données dupliquées avec uniq
La plupart du temps, lors de la gestion des serveurs Linux, vous travaillerez soit sur le terminal, soit vous éditerez des fichiers texte. Par conséquent, savoir comment supprimer les copies redondantes de lignes dans un fichier texte peut être un grand atout pour vos compétences Linux.
Travailler avec des fichiers texte peut être frustrant si vous ne savez pas comment filtrer et trier le texte dans un fichier. Pour faciliter votre travail, Linux dispose de plusieurs commandes d'édition de texte telles que sed et awk qui vous permettent de travailler efficacement avec des fichiers texte et des sorties de ligne de commande.