
J’ai utilisé la nouvelle fonction de ChatGPT pour éditer une image et l’envoyer à Moments, mais tous les messages privés m’ont demandé comment je faisais ?
Lorsque OpenAI a publié la nouvelle génération de fonctions de graphe vincentien tôt ce matin, tout le monde n'était pas très clair sur sa force. Ils pensaient qu'il suivait Gemini et apportait des mises à niveau tardives.
GPT n'a rien dit, mais a simplement choqué le public avec ses cas d'utilisation.

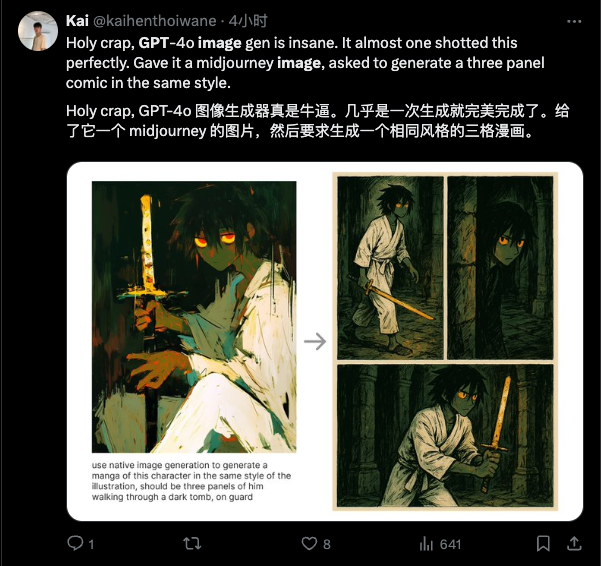
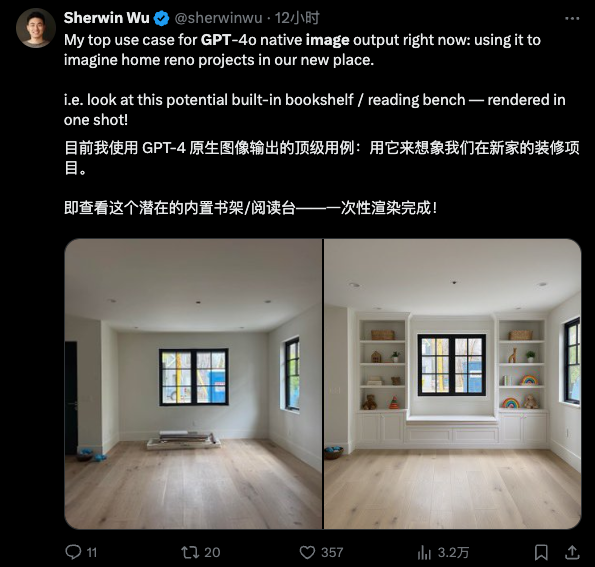
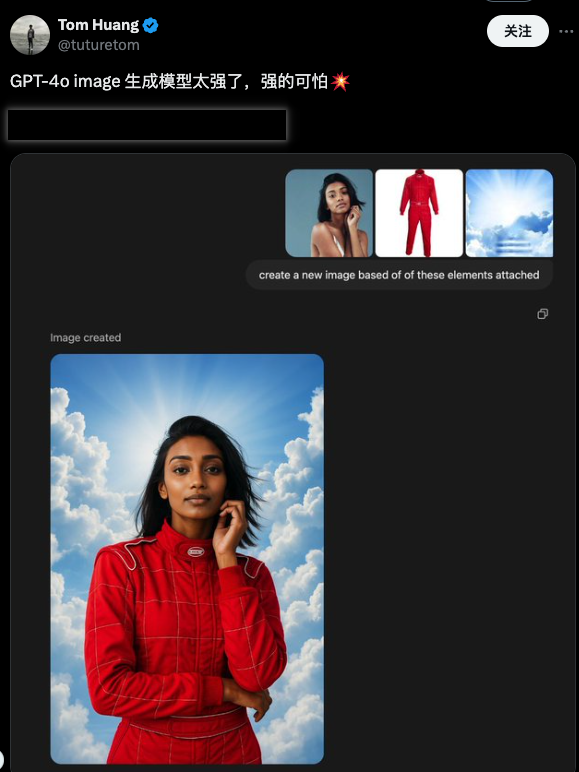
Dans sa dernière itération, OpenAI apporte une conformité révolutionnaire aux instructions et des performances constantes à la fonctionnalité des graphiques vincentiens. Avec l'invite textuelle la plus simple, vous pouvez obtenir un réglage précis des détails de l'image – toutes les modifications doivent uniquement être effectuées au cours de la session , sans aucune opération supplémentaire telle que des boutons ou des pinceaux.
La magie ne nécessite pas de pinceaux, seulement des sorts
Semblable à Gemini, cette mise à jour d'OpenAI ne se concentre pas sur le réalisme et la complexité des images, mais sur la conformité et la cohérence des instructions, et cela dans le cadre de l'utilisation uniquement d'instructions en langage naturel.
Examinons d’abord une série de photos culinaires d’entrée de gamme. L’invite est également très simple : générer une image de café et de pain.

Plus tard, sur la base de la photo originale, j'ai demandé à la changer en café glacé et confiture à tartiner.

À l’exception de l’anse de la tasse, j’ai ajouté ce qui devait l’être et laissé de côté ce qui devait l’être, et les instructions ont été très bien suivies.
Les images impliquant des portraits ont également des performances stables.

Si vous regardez attentivement, il y a encore quelques petits changements, mais les mouvements du corps humain, les plis des vêtements et les expressions les plus critiques sont tous impeccables.
Lors de la création de cet ensemble d'images, j'ai rencontré un contrôle des risques liés au contenu et j'ai reçu une erreur indiquant qu'il ne répondait pas aux exigences du règlement. Cependant, il comprenait l'intention de la directive originale et des modifications proposées.

Ce dernier est aussi celui qui a l’effet le meilleur et le plus naturel.
Les tâches avec un contenu d’écran simple sont naturellement faciles à comprendre, mais qu’en est-il des tâches plus complexes ?
Lors du test photo précédent de Gemini, nous avons produit une scène de rue en ville et l'effet était incroyable. Jetez un œil à nouveau :

La même invite a été exécutée sur ChatGPT, mais l'effet d'image était légèrement pire, surtout la nuit, où les détails de la foule étaient presque invisibles.

Bien entendu, ce problème concerne davantage les différences esthétiques. Il n’y a aucun problème pour identifier les éléments clés. Il peut même capturer de petits détails tels que « Tsutaya Bookstore », et la génération de polices est également assez stable.
En plus de le générer directement avec du texte, vous pouvez également télécharger des images pour les modifier – voici l'épisode le plus choquant.
Après avoir téléchargé le logo APPSO au format png, la première étape consiste simplement à le changer en 3D.

L'effet est correct, la direction de l'ombre est incohérente, mais elle correspond à la lumière elle-même. Ensuite, effectuez quelques ajustements.

Choquant! Les invites pour ces deux ajustements ne comportent qu'une vingtaine de mots.

(Même les produits numériques par défaut proviennent d'Apple, et certains attributs non mentionnés sont en réalité cachés.)
Le réglage ultérieur aux petits angles est également très précis.

▲ Invite : Ajustez l'angle pour que le logo rouge devienne frontal, tandis que le reste reste inchangé
Le réglage détaillé est un très gros point fort de cette mise à jour, qui peut associer avec précision les instructions aux détails correspondants pour effectuer des modifications locales précises.

▲ Invite : ajustez l'angle, l'objectif prend des photos depuis l'avant droit, la lumière globale diminue, un faisceau de lumière intense éclaire une partie de la machine depuis la droite, avec des grains de café à côté.
Les instructions incluent des contenus clés tels que les effets d'éclairage, les angles de caméra et les ajouts d'éléments. Le modèle peut être identifié avec précision et ajusté globalement. Je suis fatigué de parler des quatre mots à changer.
La chose la plus surprenante de cette mise à jour devrait être la possibilité de basculer rapidement entre les images brutes et le texte brut au cours de la même session.
Par exemple, dans l'image ci-dessous, la première instruction consiste à générer un guide d'emballage cadeau.

La première chose qui a été donnée était une version illustrée et textuelle – ce qui n’est pas une erreur. Je n'ai pas précisé si je souhaitais faire une version image et texte ou une version texte. Les instructions étaient très vagues.
Après avoir généré la version texte, ChatGPT a demandé de manière proactive s'il souhaitait créer une version graphique. Après avoir reçu une réponse de confirmation, il a fourni une version graphique.

Cela signifie que la réponse précise du modèle ne se reflète pas seulement dans la compréhension d'une seule instruction, mais également dans la compréhension des intentions potentielles de l'utilisateur et dans la « réflexion d'un pas de plus » que l'utilisateur .
En fait, c’est également la capacité démontrée par Deep Research lors de sa sortie précédente. La recherche approfondie d'OpenAI est l'un des rares modèles qui demande activement aux utilisateurs de clarifier les détails de l'exécution des tâches.
Des fonctionnalités similaires ont été migrées cette fois vers les images brutes. En termes d’expérience utilisateur, ils sont plus intuitifs et perceptibles que ceux de Deep Research.
Par exemple, il peut être utilisé pour rédiger des notifications et des instructions quotidiennes, avec des images et des textes au même endroit.
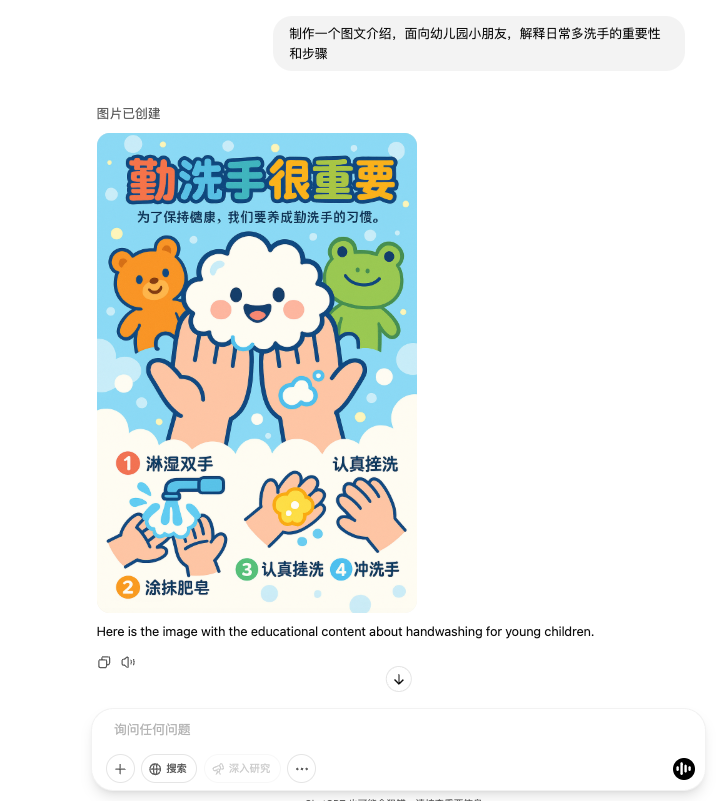
Dans l’ensemble, la chose la plus étonnante cette fois doit être la synchronisation de la cohérence et du suivi des instructions.
Comme d'habitude, chaque avis devrait comporter des "guides d'utilisation" – je n'ai vraiment trouvé aucune précaution cette fois-ci. Tout ce que vous avez à faire est de suivre vos propres idées, d'appuyer sur le clavier et de saisir du texte. Il n'y a pas de « trucs » ou de « trucs ».
La cohérence de la création et de la modification des dessins via les invites est un problème très critique dans le dessin de Vincent. Cela est lié à la fois aux capacités du modèle et aux capacités d’ingénierie. Avant que le respect et la cohérence des instructions ne fassent de tels progrès, le problème était principalement résolu par des incitations, et la pression était du côté de l'utilisateur .
Par conséquent, il existe divers modèles d'invite et stratégies pour vous apprendre à « gérer les modèles ». Mais ce n’est pas l’état dans lequel devrait se trouver l’interaction en langage naturel. Lorsque le modèle fait face à des personnes, il n’accepte que les instructions les plus directes de l’utilisateur – laissant les gens apprendre d’abord à rédiger des invites, ce qui est vraiment décourageant.
Les récentes mises à jour de Gemini et d'OpenAI ont rendu la piste de génération de photos, devenue moins populaire, redevenue vivante. Ils montrent également la même chose en commun : l'époque où certains produits de modification d'image augmentent la contrôlabilité des images brutes en ajoutant des boutons et des entrées pour lutter contre l'illusion des modèles est révolue.
Le problème de cohérence résout non seulement le problème de la génération d'images, mais également les problèmes mineurs liés au processus « d'utilisation de la fonction de génération d'images ». Dans un sens, il s’agit également d’une optimisation au niveau de l’ingénierie.
La modification et la génération peuvent toutes être réalisées en utilisant la compréhension précise du modèle des instructions textuelles – à ce niveau, « le modèle est le produit » est toujours vrai.
# Bienvenue pour suivre le compte public officiel WeChat d'aifaner : aifaner (WeChat ID : ifanr). Un contenu plus passionnant vous sera fourni dès que possible.
Ai Faner | Lien original · Voir les commentaires · Sina Weibo