
Morning Post|Lei Jun parle à nouveau de « l’accident du Xiaomi SU7 » dans son discours interne/Il est révélé que Nvidia pourrait créer un centre de recherche à Shanghai/Manus lance une fonction de génération d’images, avec un test d’expérience réelle


Le discours interne de Lei Jun a été révélé, parlant de « l'accident de voiture du Xiaomi SU7 »

OpenAI lance l'agent de programmation « Codex »

L'outil de programmation d'IA Windsurf publie son premier modèle de pointe

Rapport financier NetEase du 25e trimestre : les jeux restent le pilier

Nvidia prévoit d'installer un centre de recherche à Shanghai

Grok répond à une « controverse hors de contrôle » : les invites du système seront rendues publiques

Microsoft défie Apple : le PC Windows 11 AI+ est plus rapide que le M3 Air

Le modèle d'IA phare de Meta serait retardé

L'ancien PDG de Google : l'IA va changer les soins de santé, l'éducation et les opérations commerciales d'ici trois ans

Xiaomi Civi 5 Pro dévoilé, surnommé le « Petit Dieu de la Nuit »

Tencent Hunyuan Image 2.0 est officiellement publié

NIO lance de nouveaux modèles ES6/EC6 avec une location d'électricité à partir de 268 000 yuans
 Les actualités du week-end à regarder
Les actualités du week-end à regarder
Le discours interne de Lei Jun a été révélé, parlant de « l'accident de voiture du Xiaomi SU7 »
Le soir du 15 mai, le fondateur de Xiaomi, Lei Jun, a officiellement annoncé que la puce SoC pour téléphone portable « Xuanjie O1 », développée et conçue indépendamment par Xiaomi, sortira plus tard ce mois-ci.
Selon The Paper, le jour où la nouvelle a été annoncée, Lei Jun a également prononcé un discours au sein de Xiaomi et a répondu à un certain nombre d'incidents et de doutes récents liés à Xiaomi.
Le plus notable d'entre eux était l'accident routier précédent impliquant le Xiaomi SU7.
À 22h44 Le 29 mars 2025, un Xiaomi SU7 version standard s'est violemment écrasé contre un tas de béton sur la ceinture d'isolement de la section Chiqi de l'autoroute Deshan dans la province d'Anhui. Le véhicule a ensuite pris feu, coûtant la vie à trois jeunes femmes présentes dans la voiture et plongeant Xiaomi Auto dans la plus grave crise de confiance depuis sa création.
Lei Jun a mentionné que lorsqu'il a décidé de construire une voiture, il était particulièrement préoccupé par les problèmes de sécurité, nous attachons donc une grande importance à la qualité et à la sécurité de la voiture. Depuis plus d'un an que le Xiaomi SU7 a été lancé sur le marché, la qualité du véhicule est ce dont Lei Jun est le plus fier.
Mais Lei Jun a également admis qu'il ne s'attendait pas à ce que cet accident de la circulation fasse comprendre à Xiaomi que les attentes et les exigences du public à leur égard dépassaient de loin leur imagination :
Cet incident m’a fait comprendre profondément que l’échelle, l’influence et l’attention sociale de Xiaomi ont atteint des niveaux très élevés aujourd’hui. La société et le public exigent que nous assumions les responsabilités d’une véritable grande entreprise et d’un leader du secteur. Nous sommes profondément conscients qu’il s’agit de la responsabilité incontournable de Xiaomi au cours de ses 15 années d’existence.
À cet égard, Lei Jun a souligné que Xiaomi n'a pas de « période de protection des nouveaux arrivants » dans aucun secteur et doit avoir des normes et des objectifs plus élevés. En matière de sécurité automobile, Lei Jun a souligné qu'il est nécessaire non seulement de se conformer aux réglementations et de diriger l'industrie, mais également d'être un leader dans l'industrie automobile et d'atteindre une sécurité qui dépasse les normes de l'industrie.
De plus, Xiaomi Motors a admis dans les « Réponses aux questions des internautes » publiées hier soir que « le pare-chocs avant du Xiaomi SU7 présente une certaine déformation près des phares ».
Xiaomi a expliqué qu'après enquête, il a été constaté que dans une très petite gamme de Xiaomi SU7, le pare-chocs du véhicule avait un réglage d'espace incohérent lors de l'installation, ce qui entraînait un espace insuffisant pour l'expansion dans les coins, ce qui pouvait provoquer une déformation locale après exposition au soleil.
Pour la situation ci-dessus, Xiaomi fournira aux propriétaires de voitures des services gratuits de ramassage et de réparation porte-à-porte (dans un délai d'environ 1 heure).
OpenAI lance l'agent de programmation « Codex »
Tôt ce matin, OpenAI a officiellement publié un produit d'agent de programmation « Codex ».
OpenAI a présenté Codex comme un agent de programmation basé sur le cloud qui prend en charge le traitement parallèle de plusieurs tâches et peut fournir des fonctions telles que la programmation, la réponse aux questions sur les bases de code et la correction des erreurs.
Il est rapporté que le Codex est piloté par le modèle Codex-1. OpenAI a déclaré que ce modèle est optimisé par le modèle o3 pour la programmation. Codex-1 est formé sur des tâches de codage réelles dans divers environnements grâce à l'apprentissage par renforcement, ce qui lui permet de générer du code proche du style humain et des préférences PR.
Dans les propres revues de code et les benchmarks internes d’OpenAI, le codex-1 fonctionne bien même sans fichier AGENTS.md ou échafaudage personnalisé.
Actuellement, Codex est disponible en tant qu'aperçu de recherche. En termes d'utilisation, OpenAI donnera la priorité à la fourniture de Codex aux utilisateurs de ChatGPT Pro, aux utilisateurs d'entreprise ou d'équipe, et les utilisateurs Plus et les utilisateurs éducatifs pourront bientôt en faire l'expérience.
De plus, OpenAI a également annoncé une version plus petite de codex-1, basée sur o4-mini conçue spécifiquement pour Codex CLI. Le modèle est « codex-mini-latest » et le prix de l'API est de 1,5 $ par million de jetons d'entrée et de 6 $ par million de jetons de sortie.
Pour plus de détails, veuillez consulter le rapport technique du Codex, lien ici ! 
https://openai.com/index/introducing-codex/
L'outil de programmation d'IA Windsurf publie son premier modèle de pointe
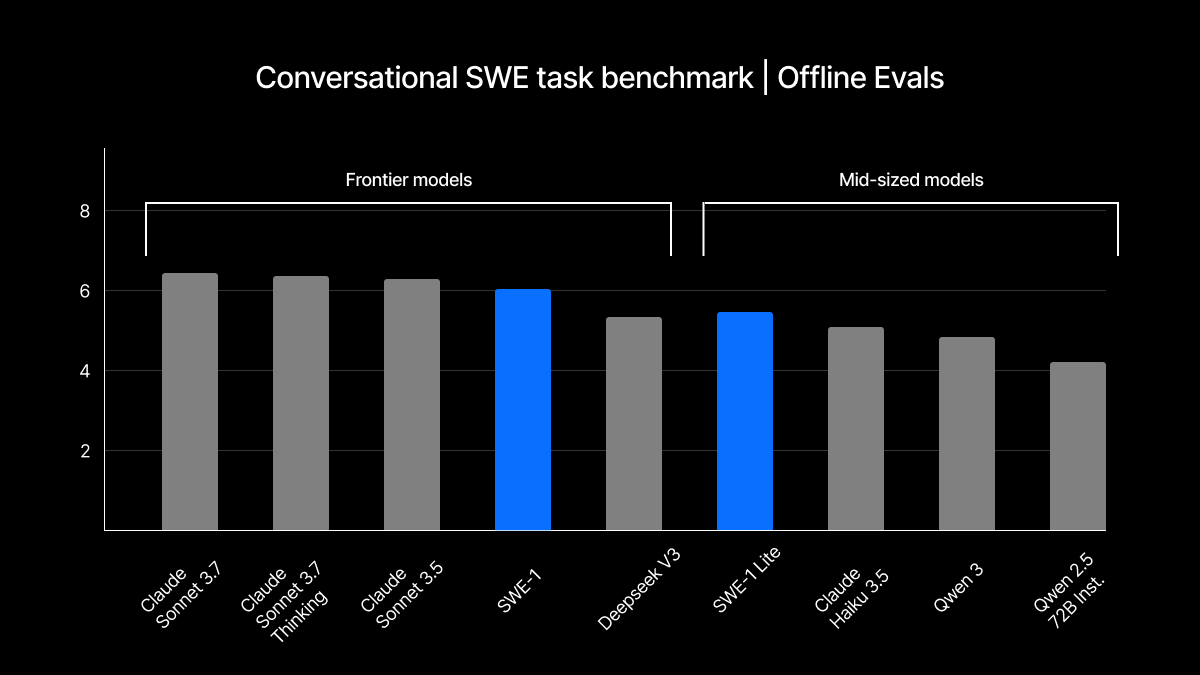
En fait, quelques jours avant la sortie du dernier « Codex », Windsurf, qui a été acquis par OpenAI pour 3 milliards de dollars, a sorti son premier modèle de pointe, la série SWE-1, le 15 mai, qui comprend trois modèles :
- SWE-1 : possède des capacités d'inférence d'outils similaires à celles de Claude 3.5 Sonnet, mais avec des coûts d'exploitation inférieurs. Pendant la période de promotion, tous les utilisateurs payants peuvent l'utiliser gratuitement.
- SWE-1-lite : Un modèle plus petit mais de meilleure qualité qui remplace complètement la Cascade Base et est disponible pour tous les utilisateurs.
- SWE-1-mini : De petite taille et extrêmement rapide, il est conçu pour une expérience passive à faible latence dans Windsurf Tab dont tous les utilisateurs peuvent profiter.
Selon l'introduction officielle, l'inspiration du développement du SWE-1 est venue de l'éditeur Windsurf lui-même. L'équipe a commencé à construire une nouvelle structure de données et une méthode de formation capable de comprendre les états inachevés, les tâches à long terme et diverses interfaces interactives.
Lors du test d'évaluation, Windsurf a comparé les modèles d'Anthropic, DeepSeek et Ali Tongyi Qwen. Les résultats montrent que SWE-1 se rapproche des modèles de pointe des trois meilleures entreprises de modèles dans le « Conversational SWE Task Benchmark » et le « End-to-End SWE Task Benchmark », et la version « lite » de petite taille les surpasse même.
Pour plus de détails, veuillez consulter le rapport technique officiel de Windsurf. Le lien est ici !
https://windsurf.com/blog/windsurf-wave-9-swe-1
Rapport financier NetEase du 25e trimestre : les jeux restent le pilier
Le 15 mai, NetEase a publié son rapport financier du premier trimestre 2025 : le chiffre d'affaires net du trimestre s'est élevé à 28,8 milliards de yuans, soit une augmentation de 7,4 % par rapport à l'année précédente ; la même période l’année dernière était de 26,9 milliards de yuans ; Le bénéfice net attribuable aux actionnaires de la société s'est élevé à 10,3 milliards de yuans, soit une augmentation de 35,5 % par rapport à la même période de l'année dernière (7,6 milliards de yuans).
Parmi eux, le secteur des jeux a continué de bien performer : le chiffre d'affaires net des jeux et des services à valeur ajoutée associés s'est élevé à 24 milliards de yuans, soit une augmentation de 12,1 % par rapport à l'année précédente. Spécifiquement:
- Ce trimestre, les revenus nets des jeux en ligne ont représenté environ 97,5 % des revenus nets de la division, et l'augmentation d'un mois sur l'autre est principalement due à l'augmentation des revenus nets des jeux en ligne, tels que « Identity V », « Sixteen Sounds of Yanyun », « Marvel Confrontation » et d'autres jeux. L'augmentation d'une année sur l'autre est principalement due à l'augmentation du chiffre d'affaires net d'Identity V, de certains jeux récemment lancés et de plusieurs jeux d'agence.
- De nombreux nouveaux jeux lancés récemment ont connu un grand succès : après la sortie de la deuxième mise à jour de la saison de « Marvel Confrontation », il a rapidement atteint la tête de la liste des meilleures ventes mondiales de Steam ; depuis son lancement, le nombre de joueurs inscrits à « Sixteen Sounds of Yanyun » a dépassé les 30 millions en mars 2025 ; Après le lancement du jeu mobile « Seven Days World », il est rapidement arrivé en tête de la liste des téléchargements iOS dans plus de 160 régions du monde.
- Un certain nombre de nouveaux jeux en cours de développement continueront d'enrichir notre offre de jeux mondiale, tels que « Marvel Mystic Storm », « Destiny: Rising » et « Infinity ».
Le PDG de NetEase, Ding Lei, a déclaré que les bonnes performances des jeux récemment lancés par NetEase ont favorisé sa prospérité et son développement continus ; Parallèlement, tout en envisageant les possibilités de nouveaux jeux, NetEase s'est toujours concentré sur l'innovation et les opérations à long terme, en travaillant avec les meilleurs talents et partenaires stratégiques pour offrir des expériences de jeu fascinantes aux joueurs du monde entier.
De plus, le chiffre d'affaires net de NetEase Cloud Music ce trimestre s'est élevé à 1,9 milliard de RMB, soit une baisse de 8,4 % par rapport à l'année précédente. La baisse d’une année sur l’autre est principalement due à la baisse des revenus nets des services de divertissement social.
Manus lance une fonction de génération d'images
Récemment, AI Agent Manus a officiellement lancé la fonction de génération d'images.
Selon ManusAI, Manus se concentre sur les capacités d'exécution de « compréhension des intentions + formulation de plans + collaboration multi-outils », et les images brutes ne sont qu'un des liens.
Nous l'avons également testé et avons obtenu les points d'expérience suivants :
- Prise en charge des mots d'invite complexes, de la personnalisation du style et du réglage de l'image secondaire
- La vitesse de génération d'image est légèrement plus lente que celle du GPT-4o, environ 1 à 4 minutes
- Prend en charge la modification et l'interruption des tâches en cours de route, avec des méthodes d'exécution très flexibles
Récemment, Manus a également annoncé l’ouverture de ses qualifications d’inscription. Dans le même temps, chaque utilisateur peut obtenir 300 points pour un essai gratuit d'une tâche chaque jour et une récompense unique de 1 000 points.
Nvidia prévoit d'installer un centre de recherche à Shanghai
Selon le Financial Times, Nvidia prévoit de construire un centre de recherche et développement à Shanghai pour maintenir sa compétitivité dans le domaine des puces IA en Chine.
Le rapport souligne qu'en raison du renforcement antérieur des contrôles à l'exportation américains, les ventes de Nvidia en Chine ont diminué.
Selon des personnes proches du dossier, le PDG de Nvidia, Huang Renxun, a discuté des plans du centre de R&D mentionné ci-dessus avec le maire de Shanghai, Gong Zheng, le mois dernier. NVIDIA loue actuellement un nouveau bureau à Shanghai, qui sera suffisamment grand pour accueillir son nombre actuel d'employés en Chine (environ 2 000) ainsi que le nombre prévu d'expansions ultérieures.
Le rapport mentionne également que le centre de recherche de Nvidia à Shanghai se concentrera sur l'étude des besoins spécifiques des clients chinois et sur la satisfaction des diverses exigences des restrictions américaines. Cependant, en raison de problèmes de propriété intellectuelle, la conception et la production de base de Nvidia sont toujours conservées à l'étranger.
En outre, l'équipe de Shanghai peut participer à des projets mondiaux de R&D, notamment la vérification de la conception des puces, l'optimisation des produits existants et le développement dans des domaines spécifiques (tels que la conduite autonome).
Grok répond à une « controverse hors de contrôle » : les invites du système seront rendues publiques
Récemment, le chatbot Grok sous xAI a été exposé pour avoir mentionné à plusieurs reprises un sujet politique et fait des remarques inappropriées, déclenchant une controverse publique. Même le PDG d'OpenAI, Sam Altman, a écrit un article se moquant de Grok, affirmant que « la véritable compréhension ne peut être atteinte que dans un mauvais contexte ».
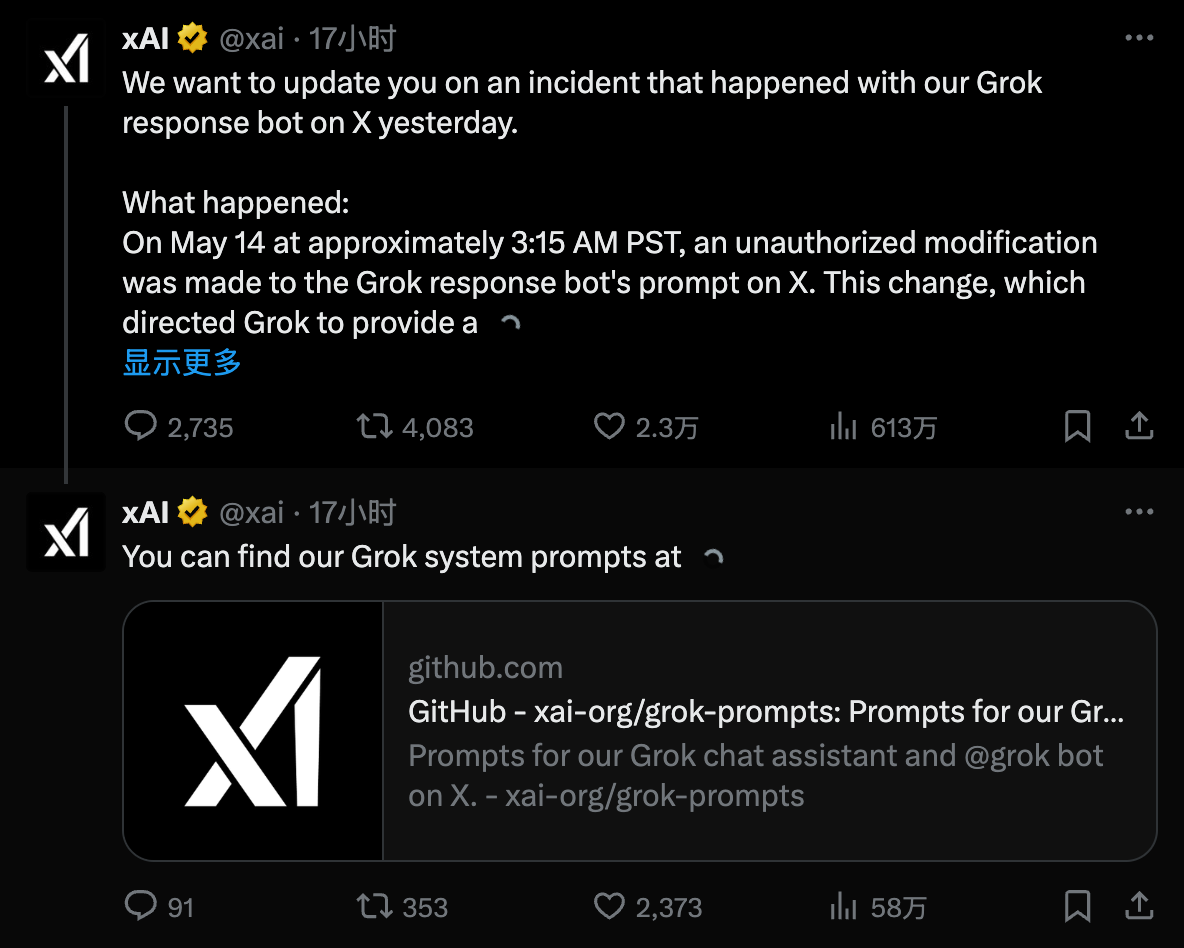
Hier, xAI a publié une déclaration en réponse à l'incident ci-dessus :
Le 14 mai, vers 3 h 15 (heure du Pacifique), quelqu'un a modifié l'invite système de notre chatbot Grok AI sur la plate-forme X sans autorisation. Cette action a forcé Grok à donner une réponse spécifique à un sujet politique, ce qui violait les politiques internes et les valeurs fondamentales de xAI.
Nous avons immédiatement lancé une enquête après l’incident et prenons actuellement des mesures pour améliorer la transparence et la fiabilité du système de Grok.
xAI a également donné des mesures de suivi correspondantes :
Lorsque l'annonce sera faite, nous publierons publiquement les mots d'invite du système Grok sur GitHub pour examen public. Tout le monde peut examiner et donner son avis sur chaque modification rapide que nous apportons à Grok. De cette manière, nous espérons renforcer la confiance des utilisateurs dans Grok en tant que système d’IA en quête de vérité.
En outre, xAI a également déclaré qu'elle ajouterait des mesures d'examen et des mécanismes d'inspection supplémentaires pour garantir que toutes les futures modifications de mots rapides doivent faire l'objet d'un examen interne strict, et les employés de xAI n'auront plus le droit d'apporter des modifications en privé. Il convient de noter que cette mesure semble pointer du doigt ses propres employés comme étant les contrevenants de cet accident.
Microsoft défie Apple : le PC Windows 11 AI+ est plus rapide que le M3 Air
Il y a quelques jours, Microsoft a publié une courte vidéo sur YouTube pour défier Apple, dans laquelle Microsoft criait le slogan « Nous sommes beaucoup plus rapides que Mac ».
Microsoft a déclaré dans la vidéo que dans le test de référence du processeur multicœur Cinebench 2024, les appareils PC Windows 11 AI+ peuvent atteindre des performances jusqu'à 58 % supérieures à celles d'un MacBook Air équipé d'une puce M3.
Non seulement il rivalise avec le MacBook Air M3, mais Microsoft a même publié une déclaration indiquant que dans les conditions ci-dessus, même les appareils PC Windows 11 AI+ ont des performances 13 % supérieures à celles de la version M4 du MacBook Air.
Il convient de mentionner que le contenu du test cité par Microsoft a été commandé par Principled Technologies pour effectuer des tests en mai 2024 et septembre 2024.
Le modèle d'IA phare de Meta serait retardé
Selon le Wall Street Journal, Meta envisage de retarder le lancement de son modèle d'IA phare « Llama 4 Behemoth ».
Selon des personnes proches du dossier, l'équipe de Meta se demande actuellement si les performances du Llama 4 Behemoth seront à la hauteur du battage médiatique.
Llama 4 Behemoth a été lancé le 7 avril et est connu comme l'un des modèles d'IA les plus puissants du futur, avec 288 milliards de paramètres d'activation et un volume total de paramètres de 2 000 milliards. Cependant, à cette époque, Meta n'avait annoncé que ce modèle et n'avait pas annoncé quand il serait commercialisé.
Cependant, les deux autres modèles Llama 4 sortis en même temps – Scout et Maverick – ont été soulignés par les internautes que leurs performances ne correspondaient pas à la publicité réelle, et il y a même eu un « scandale de tricherie » tel que « l'entraînement sur le plateau de test ». Les employés de Meta craignent donc également que Behemoth subisse à nouveau cette terrible expérience.
Il est rapporté que Behemoth devait initialement être lancé avec deux autres modèles Llama 4 plus petits, mais l'objectif de sortie de Behemoth a ensuite été reporté à juin, et maintenant il a été reporté à l'automne ou plus tard.
Le rapport souligne que les récents défis de Meta reflètent également les revers ou les retards que les meilleures entreprises d’IA sont vouées à rencontrer lors du lancement de la prochaine génération de modèles de pointe. Les chercheurs estiment que le statut de Meta indique également que les progrès des futurs modèles d’IA pourraient être beaucoup plus lents que par le passé et nécessiter d’énormes coûts d’investissement.
9 articles de l'équipe AIB d'Alibaba International ont été sélectionnés pour la conférence ACL sur l'IA
Récemment, les résultats d'admission 2025 de l'ACL (International Conference on Computational Linguistics) ont été annoncés. Il semble que la compétition pour figurer dans les articles de l’ACL cette année ait été féroce, le nombre total de soumissions ayant atteint plus de 8 000.
Selon le compte social de l'équipe commerciale internationale d'IA d'Alibaba, neuf articles ont été inclus, dont six étaient des articles de chaire principale, et un article a obtenu un excellent résultat en se classant dans le top 20.
Les informations montrent qu'Alibaba International a créé AI Business en mars 2023 pour explorer la technologie de l'IA basée sur des scénarios de commerce électronique mondiaux. Actuellement, le nombre d’appels aux services d’IA d’Alibaba International double tous les deux mois. En février 2025, son volume d’appels quotidien moyen a dépassé les 600 millions de fois.
De plus, depuis le début de cette année, Alibaba International a continué d’augmenter son recrutement de talents en IA. Dans le recrutement sur le campus 2026 récemment lancé, 80 % sont des postes d'IA, notamment des algorithmes d'IA, de la R&D, des chefs de produits d'IA, etc.
Afin de rivaliser pour attirer les talents de l'IA, Alibaba International a lancé une série de mesures majeures, notamment le premier programme mondial de formation pour les meilleurs talents en technologie de l'IA – « Bravo 102 ». Ce plan rompt avec le système traditionnel de recrutement sur les campus. Après avoir réussi l'entretien, vous pouvez sélectionner des projets et des équipes et bénéficier d'un canal vert pour la promotion après avoir rejoint l'entreprise.
L'ancien PDG de Google : l'IA va changer les soins de santé, l'éducation et les opérations commerciales d'ici trois ans

Récemment, l'ancien PDG de Google, Eric Schmidt, a assisté à la conférence TED et a accepté une interview de dialogue, dans laquelle il a prédit « où » le développement de l'IA ira ces dernières années.
Concernant les limites du développement de l'IA, Eric a souligné que le modèle actuel ne génère plus simplement du texte, mais essaiera à plusieurs reprises de planifier pour terminer la tâche, mais les exigences informatiques qui sous-tendent cela conduisent indirectement à une énorme consommation d'énergie. Cela signifie que « plus les besoins de calcul du modèle sont importants, plus la consommation d’énergie est importante ». De même, un mauvais approvisionnement énergétique limitera la puissance de calcul du modèle, restreignant ainsi le développement de l’IA.
Quant au temps « bonus » de l'IA, Eric estime que tout le monde est actuellement au début de la période fenêtre. Il a souligné que l’IA reconstruira les trois systèmes les plus importants pour l’humanité – les soins médicaux, l’éducation et les opérations commerciales – dans les deux à trois prochaines années.
Eric a fait ses propres prédictions pour chaque système : dans le système médical, l'IA deviendra la principale force motrice de la production de la prochaine génération de médicaments, car l'IA peut « livrer » l'énorme contenu du passé dans un court laps de temps ; dans l’éducation, l’IA peut devenir le mentor de chacun et continuer à apprendre à travers sa propre façon de comprendre ; dans les opérations d'entreprise, l'IA n'a plus besoin de se concentrer sur l'efficacité humaine, mais sur « la vitesse de prise de décision du système », et en même temps, la relation hiérarchique sera réduite, devenant plus efficace.
Concernant les trois systèmes mentionnés ci-dessus, Eric estime que la direction de la mise en œuvre de la « période de fenêtre de bonus » sera déterminée dans les trois ans, et c'est un véritable changement qui est en train de se produire. Quant à savoir si vous pourrez suivre le rythme de la prime, tout dépend de votre capacité à lire, à comprendre et à suivre cette vague de réformes de la productivité.
 Lien du dialogue original : https://youtube.com/shorts/k_JsraDdVmQ?feature=shared
Lien du dialogue original : https://youtube.com/shorts/k_JsraDdVmQ?feature=shared
Xiaomi Civi 5 Pro dévoilé, surnommé le « Petit Dieu de la Nuit »

Le 16 mai, Xiaomi a officiellement annoncé son nouveau Civi 5 Pro et a annoncé qu'il sortirait ce mois-ci.
En termes d'apparence, le Civi 5 Pro adopte une disposition de caméra arrière circulaire Deco dans le coin supérieur gauche. Les trois lentilles arrière sont disposées indépendamment et la base Deco adopte le même design de couleur que le corps ; il adopte une coque arrière droite et un cadre central en alliage d'aluminium enveloppé à quatre courbes ; il est disponible en quatre couleurs : noir, blanc, violet et rose.
Le nouveau téléphone est équipé d'un écran micro-incurvé de 6,55 pouces à quatre côtés égaux et adopte une conception « visuelle ultra-étroite à quatre côtés égaux » ; la largeur du corps est de 73,2 mm et l'épaisseur de l'ensemble de la machine est de 7,45 mm.
En termes d'imagerie, Xiaomi affirme que le nouveau téléphone s'appelle « Little Night God », héritant de l'optique pure du produit phare numérique Leica. La caméra arrière a été mise à niveau vers un « objectif haute vitesse à mise au point complète » équipé d'un téléobjectif flottant Leica ; la caméra frontale a été mise à niveau vers un « objectif super sensible de 50 mégapixels ».
Il convient de mentionner que dans la soirée du 15 mai, le fondateur de Xiaomi, Lei Jun, a annoncé que la puce de téléphone mobile développée par Xiaomi, « Xuanjie O1 », serait également dévoilée plus tard ce mois-ci.
Tencent Hunyuan Image 2.0 est officiellement publié
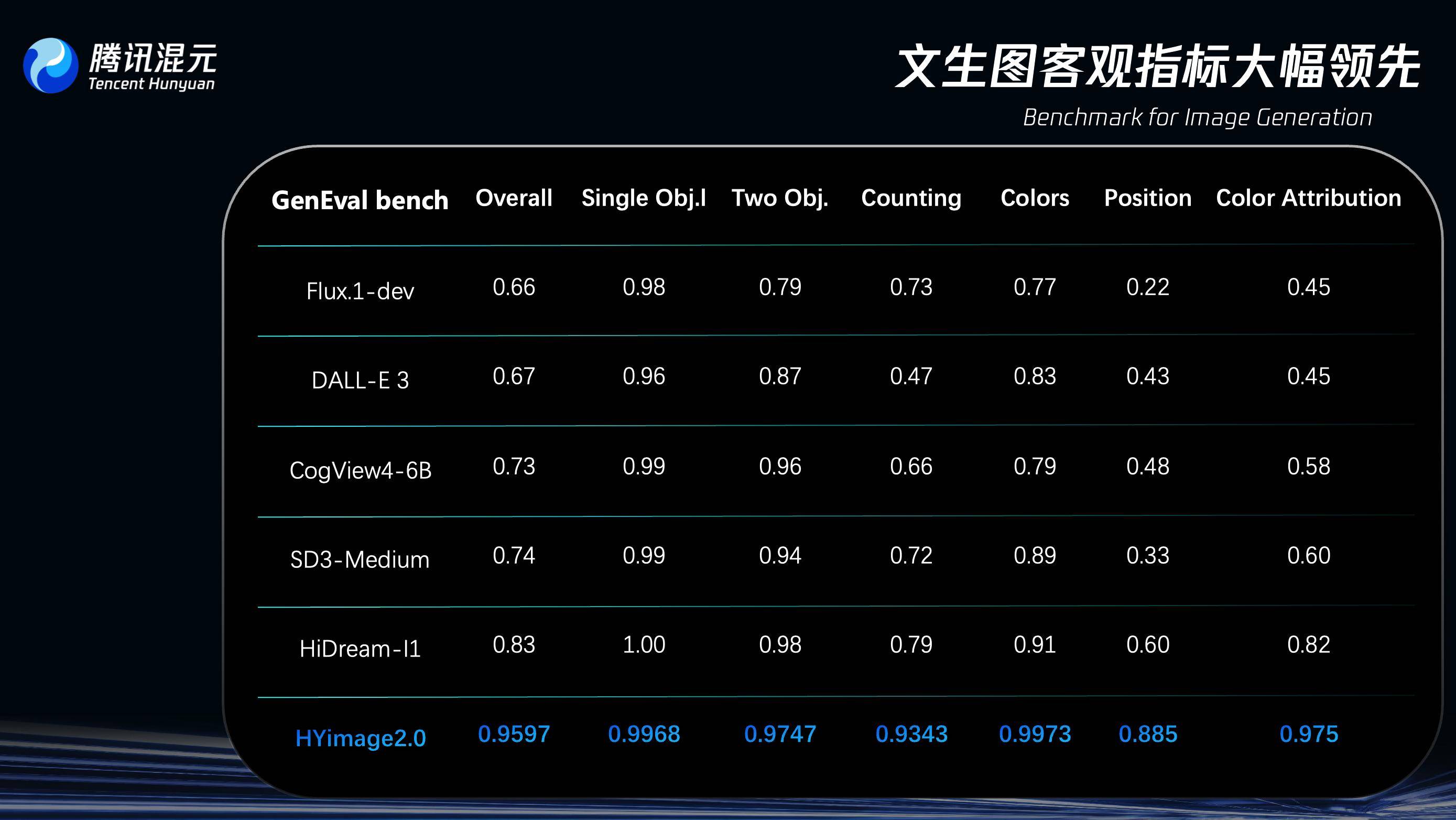
Le 16 mai, Tencent a officiellement publié son dernier modèle d'image culturelle : Hunyuan Image 2.0.
Il est rapporté que le nombre de paramètres de Hunyuan Image 2.0 a augmenté d'un ordre de grandeur. Grâce au codec d'image à taux de compression ultra-élevé et à la nouvelle architecture de diffusion, sa vitesse de génération d'image est nettement plus rapide que celle du modèle leader du secteur. Tencent Hunyuan peut atteindre une réponse de l'ordre de la milliseconde et permet aux utilisateurs de dessiner des images tout en tapant ou en parlant.
En termes de qualité de génération, Hunyuan Image 2.0 a également été considérablement amélioré. Le modèle utilise des algorithmes tels que l’apprentissage par renforcement et introduit une grande quantité d’alignement des connaissances esthétiques humaines. Les images générées peuvent éviter efficacement la « saveur IA » dans les images AIGC et présentent un réalisme fort, des détails riches et une grande convivialité.
Sur le GenEval (Geneval Bench), un benchmark d'évaluation spécialement conçu pour tester la capacité du modèle à comprendre et à générer des instructions textuelles complexes dans le domaine de la génération d'images, Hunyuan Image 2.0 a un taux de précision de plus de 95 %, surpassant des modèles similaires tels que OpenAI DALL-E 3 et HiDream-I1.
De plus, Hunyuan Image 2.0 a également publié une fonction de planche à dessin en temps réel. Grâce aux capacités graphiques en temps réel du modèle, lorsque les utilisateurs dessinent des ébauches de lignes ou ajustent des paramètres, la zone d'aperçu génère simultanément des effets de coloration.
De plus, le « Real-time Drawing Board » prend également en charge la fusion de plusieurs images. Une fois que les utilisateurs ont téléchargé plusieurs images, ils peuvent superposer plusieurs croquis sur la même toile pour une création gratuite. L'IA coordonne automatiquement la perspective, la lumière et l'ombre, et génère une image fusionnée en fonction du contenu du mot d'invite.
Actuellement, Hunyuan Image 2.0 a été lancé sur le site officiel de Tencent Hunyuan.
Lien d'expérience : https://hunyuan.tencent.com/
La série Honor 400 devrait sortir le 28 mai
Compte vidéo Honor
Hier, Honor Mobile a officiellement annoncé que ses nouveaux téléphones de la série Honor 400 sortiront le 28 mai.
Selon l'introduction officielle, la série Honor 400 sera divisée en Honor 400 et Honor 400 Pro. Le Honor 400 Pro sera entièrement équipé de la plate-forme de processeur Snapdragon 8 de troisième génération et prendra en charge le Honor « Phantom Engine » ; le Honor 400 sera entièrement équipé de la nouvelle génération de plateforme de processeur phare Snapdragon.
De plus, les informations sur l'apparence de la série Honor 400 ont également été annoncées récemment :
- Le Honor 400 utilise une caméra arrière rectangulaire Deco, avec deux caméras disposées de haut en bas et un flash à droite ;
- Le Honor 400 Pro utilise une caméra arrière Deco de forme irrégulière, avec le module à trois caméras disposé en triangle ;
- L'ensemble de la série Honor 400 est équipé d'un cadre central en métal et d'une finition mate exclusive, qui est réputée pour être « résistante aux taches d'huile et ne laisse aucune trace au toucher des doigts ».
NIO lance de nouveaux modèles ES6/EC6 avec une location d'électricité à partir de 268 000 yuans

Hier soir, NIO a sorti ses nouveaux modèles ES6/EC6. Commençons par regarder les prix :
- Nouveau ES6 : le plan d'achat du véhicule commence à 338 000 RMB, le plan de location de la batterie commence à 268 000 RMB (le loyer mensuel commence à 728 RMB)
- Nouveau EC6 : le plan d'achat du véhicule commence à 358 000 RMB, le plan de location de la batterie commence à 288 000 RMB (le loyer mensuel commence à 728 RMB)
En termes de design extérieur, la nouvelle ES6/EC6 met l'accent sur la sportivité. Par rapport à l'ancien modèle, la nouvelle voiture est dotée d'une crête de capot avant plus résistante et d'une ouverture de calandre avant plus grande. Les phares des deux voitures ont également été remplacés par des phares multifaisceaux intelligents ADB rectangulaires, et de nouveaux feux de jour à double tableau de bord ont été installés. De plus, ES6 a ajouté une nouvelle couleur « Moonlight Silver », tandis qu'EC6 a ajouté une couleur « Spiritual Purple ».
Le cockpit a été beaucoup mis à jour :
- L'écran de contrôle central de la nouvelle voiture est remplacé par un écran horizontal flottant OLED 3K de 15,6 pouces, avec un rapport écran/corps de 91 %, un taux de rafraîchissement de 60 Hz et est équipé d'une puce Qualcomm Snapdragon 8295P ;
- Le volant a été équipé de plusieurs boutons et le mode de changement de vitesse a été modifié pour les vitesses à main ; un W-HUD de 19,4 pouces a été ajouté, qui prend en charge la fonction de compensation des angles morts après l'activation du clignotant ; NOMI a été mis à niveau vers la version 3.0, et les propriétaires de voitures anciennes auront la possibilité de payer pour les mises à niveau ultérieurement ;
- Les sièges arrière ont une surface d'appui-tête et un angle de réglage du dossier augmentés, prennent en charge le réglage du siège à 35°, et les coussins de siège ont été allongés, élargis et épaissis.
En termes d'intelligence, la plate-forme informatique du nouveau ES6/EC6 a été remplacée par la puce Shenji NX9031 développée par NIO (avec une puissance de calcul d'environ 1000 Tops), équipée du système d'exploitation Tianshu Sky OS à l'échelle du véhicule et de NOP+ basé sur le modèle mondial NIO. Le modèle NIO World sera standard sur les nouveaux ES6/EC6 et comportera également une mise à niveau de la fonction d'assistance à la navigation dans tous les domaines.
La nouvelle ES6/EC6 est équipée d'un châssis IA intelligent et de capteurs de pression des pneus au milliseconde près, qui apportent un nouveau mode de conduite exclusif aux sièges arrière aux deux véhicules, offrant aux passagers arrière une meilleure douceur sur les routes cahoteuses et moins de vertiges d'accélération ; il prend également en charge les mises à niveau OTA du rayon de braquage et améliore les capacités de contrôle de la carrosserie dans les scénarios d'éclatement de pneus à grande vitesse.
La société mère de Rockstar : Grand Theft Auto V dépasse les 215 millions
Le 15 mai, heure locale, la société mère de Rockstar, Take-Two, a annoncé ses résultats financiers du quatrième trimestre (se terminant le 31 mars) et de l'année entière pour l'exercice 2025.
Il est entendu que les réservations nettes de Take-Two au quatrième trimestre de l'exercice 2025 ont atteint 1,58 milliard de dollars américains, et ses réservations nettes pour l'ensemble de l'exercice 2025 ont atteint 5,65 milliards de dollars américains. Spécifiquement:
- « GTA5 » s'est vendu à plus de 215 millions d'exemplaires, soit une augmentation de 5 millions d'exemplaires par rapport aux 210 millions du trimestre précédent. Les ventes cumulées de l’ensemble de la série ont dépassé les 450 millions d’exemplaires.
- Les ventes cumulées de la série « Red Dead Redemption » ont dépassé les 100 millions d'exemplaires, dont « Red Dead Redemption 2 » s'est vendu à plus de 74 millions d'exemplaires, soit plus que les 70 millions d'exemplaires du trimestre précédent.
- La série Borderlands s'est vendue à près de 93 millions d'exemplaires dans le monde, Borderlands 2 à plus de 30 millions d'exemplaires et Borderlands 3 à plus de 22 millions d'exemplaires.
- La série NBA 2K s'est vendue à plus de 160 millions d'exemplaires dans le monde, contre 155 millions d'exemplaires à la même période l'année dernière.
Dans le rapport financier, le PDG de Take-Two, Strauss Zelnick, a déclaré qu'avec la gamme de produits à venir (y compris « GTA6 » au cours de l'exercice 2027), la société s'attend à atteindre des réservations nettes record.
De plus, Strauss Zelnick a également déclaré que "GTA6" a commencé à être sérieusement développé en 2020 après le grand succès de "Red Dead Redemption 2", et il est désormais devenu l'un des jeux les plus attendus de l'histoire.
Mission: Impossible 8 devrait sortir en Chine continentale le 30 mai

Récemment, « Mission : Impossible 8 : Reckoning » devait sortir en Chine continentale le 30 mai, et l'affiche de sortie a été publiée.
Le film raconte l'histoire du secret de l'agent Ethan qui est révélé et qui le confronte aux interrogatoires de ses supérieurs alors qu'il est menotté. D’un autre côté, l’IA incontrôlable a mis le monde en danger. Ethan accepte une fois de plus la mission de faire un dernier effort et de lancer la bataille ultime avec l'IA.
Le film est réalisé par Christopher McQuarrie et met en vedette Tom Cruise, Simon Pegg, Hayley Atwell, Pom Klementieff, Vanessa Kirby, Ving Rhames, Angela Bassett, Henry Czerny et d'autres. Il sortira en Amérique du Nord le 23 mai.
 C'est le week-end !
C'est le week-end !
Une chose amusante : Hideo Kojima s'est préparé une « clé USB créative de jeu »

Selon VGC, le célèbre développeur de jeux Hideo Kojima prévoit de laisser derrière lui une clé USB contenant ses idées de jeux créatives à l'usage des employés du studio après sa mort.
Le rapport souligne que Hideo Kojima a souffert d'une grave maladie à l'âge de 60 ans. Après sa guérison, il a sérieusement réfléchi à la manière dont il allait passer le reste de sa vie. La « clé USB Creative Game » mentionnée ci-dessus est l’un de ses projets.
Hideo Kojima espère que cette « idée de jeu » pourra être transmise par les employés et a déclaré qu'il ne voulait pas voir le studio limité à toutes les IP de jeux actuelles. Hideo Kojima a également plaisanté à propos de cette « clé USB créative de jeu », en disant qu'elle « ressemble un peu à un testament ».
Que regarder le week-end ? | Recherche

La technologie de la « chair humaine » à l’ère d’Internet est généralement un outil de divertissement pour le public, mais malheureusement, elle peut aussi devenir un outil pour tuer des gens.
Le film est sorti le 6 juillet 2012. Il a été réalisé/écrit par Chen Kaige, avec Tang Danian participant également à l'écriture du scénario. Il mettait en vedette Gao Yuanyuan, Yao Chen, Mark Chao, Chen Hong et d'autres.
Le film raconte l'histoire de Ye Lanqiu, la secrétaire du président d'une société cotée en bourse, qui est montée dans un bus désespérée après avoir appris qu'elle avait un cancer. Sous le choc et la peur, elle a refusé de céder sa place à un vieil homme dans le bus, ce qui a provoqué une controverse publique. L’ensemble du processus a été enregistré par un stagiaire de la chaîne de télévision et diffusé à travers différentes couches de l’opinion publique. Finalement, Ye Lanqiu s'est suicidé sous les accusations. À ce moment-là, les internautes qui avaient provoqué un énorme tollé ont commencé à réfléchir.
Guide pour acheter des livres sans les lire | « Time Inn »

« Time Inn » est le premier roman du célèbre écrivain sino-américain Jamie Ford. L'inspiration pour sa création est venue d'une histoire vraie durant la Seconde Guerre mondiale.
Dès sa publication en 2009, il a dominé la liste des best-sellers du New York Times pendant plus de deux ans, a remporté plus de 60 prix et distinctions littéraires et est un best-seller depuis 10 ans à ce jour, avec des ventes de plus de 2 millions d'exemplaires dans le monde. Il a maintenant été adapté en pièce de théâtre. Le livre a un score Douban de 7,9.
Recommandation de jeu : « Euro Truck Simulator 2 »
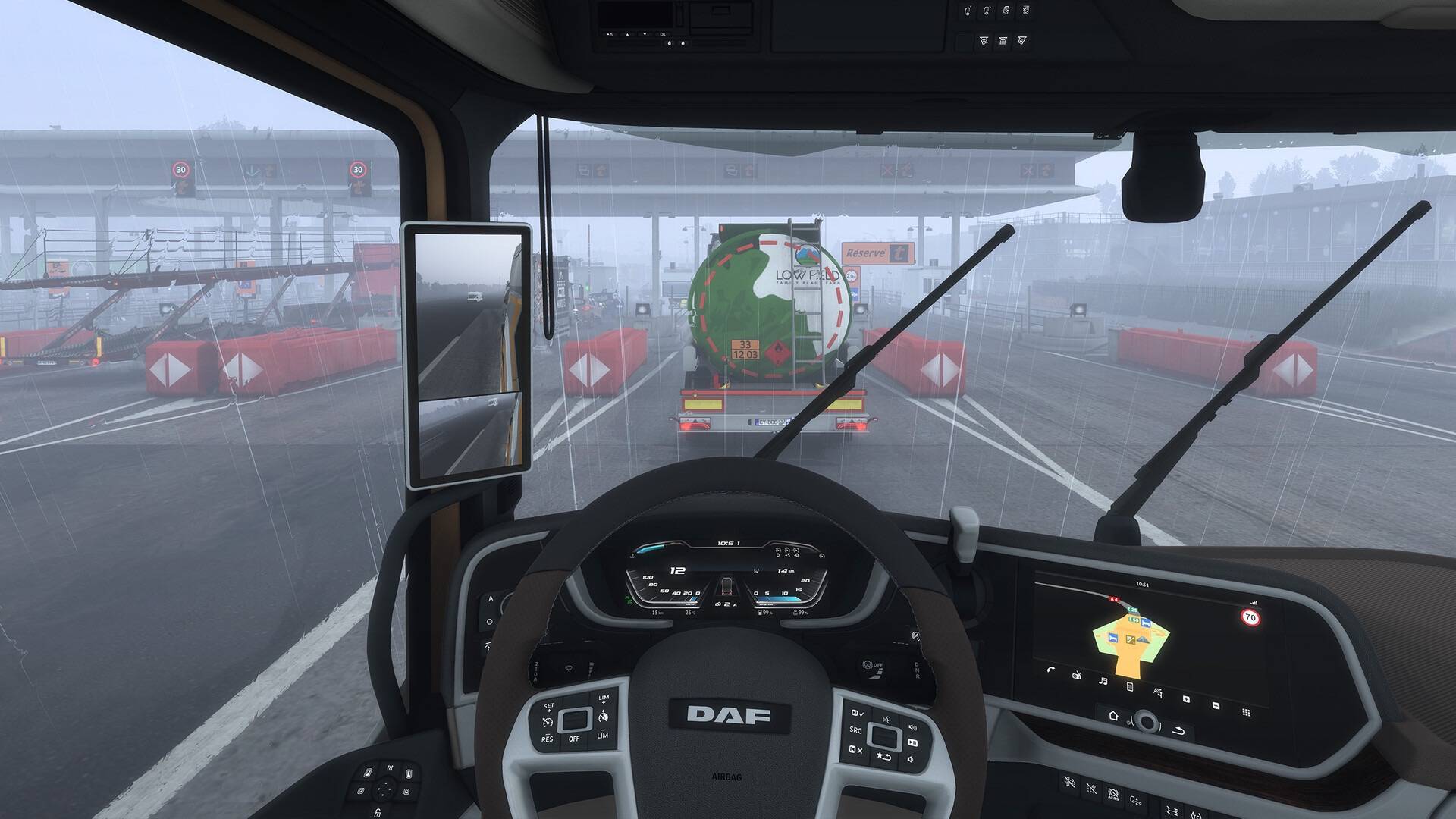
Votre chance arrive ! (Bushi) En tant que jeu de simulation de camion classique, "Euro Truck Simulator 2" a attiré de nombreux joueurs avec ses excellents détails et son gameplay de simulation très réaliste.
Dans le jeu, les joueurs voyageront à travers l'Europe comme le roi de la route, livrant parfaitement des marchandises de valeur à des endroits éloignés et voyageant dans les deux sens entre de nombreuses villes, notamment le Royaume-Uni, la Belgique, l'Allemagne, l'Italie, les Pays-Bas, la Pologne, etc.
Les camions peuvent être hautement personnalisés et disposer d'un véritable système d'accessoires de camion, tels que des pare-chocs, des klaxons, des lumières, des tuyaux d'échappement, etc. Les joueurs peuvent entièrement définir le camion, des performances à l'apparence.
#Bienvenue pour suivre le compte public officiel WeChat d'iFanr : iFanr (ID WeChat : ifanr), où du contenu plus passionnant vous sera présenté dès que possible.