
Révélant le modèle de génération vidéo le plus puissant Sora, comment OpenAI réalise-t-il une prise de vue en une minute ?

Tôt ce matin, OpenAI a sorti l'outil de génération vidéo d'IA Sora de son « arsenal de munitions », occupant instantanément les gros titres de l'actualité.
Même Musk, qui a toujours été en désaccord avec OpenAI, est prêt à admettre le pouvoir de Sora et à en faire l'éloge : « Dans les prochaines années, les humains créeront des œuvres exceptionnelles avec l'aide de la puissance de l'IA. »
La puissance de Sora réside dans sa capacité à générer des vidéos cohérentes et fluides d'une durée maximale de 60 secondes, basées sur des descriptions textuelles, qui contiennent des scènes délicates et complexes, des expressions de personnages vives et des mouvements de caméra complexes.
Par rapport à d'autres vidéos qui ne peuvent générer que des vidéos aussi courtes que des chiffres, la durée d'une minute de Sora a sans aucun doute pour effet de renverser la situation.
Plus important encore, Sora a montré le meilleur niveau en termes d'authenticité vidéo, de longueur, de stabilité, de cohérence, de résolution ou de compréhension du texte. Profitons d’abord des clips vidéo de démonstration officiellement publiés.
Invite : La belle ville enneigée de Tokyo est animée. La caméra se déplace dans les rues animées de la ville, suivant plusieurs personnes profitant du beau temps enneigé et faisant leurs achats dans les stands à proximité. De magnifiques pétales de sakura volent dans le vent avec des flocons de neige.
Dans cette vidéo, un couple est vu du point de vue d'un drone marchant dans une rue animée de la ville, avec de magnifiques pétales de fleurs de cerisier dansant dans les airs accompagnés de flocons de neige.
Alors que d'autres outils ont encore du mal à maintenir un seul objectif stable, Sora a réussi à commuter en douceur plusieurs objectifs, et la cohérence du changement d'objectif et la cohérence des objets sont loin devant, ce qui constitue un véritable coup dur pour la réduction de dimensionnalité. 

▲De @gabor
Dans le passé, le tournage d'une telle vidéo aurait pu nécessiter beaucoup de temps et d'énergie dans une série de tâches fastidieuses telles que la création du scénario et la conception des plans. Maintenant, avec juste une simple description textuelle, Sora peut complètement générer une si grande scène, et les pratiquants concernés ont peut-être commencé à trembler.
L'internaute @debarghya_das a créé cette bande-annonce de plus de 20 secondes en 15 minutes en utilisant le montage OpenAI Sora, la voix de David Attenborough sur Eleven Labs et quelques échantillons de musique naturelle de Youtube sur iMovie.

Comment Sora obtient-il ses puissants effets ?
OpenAI a également publié un rapport technique détaillé sur Sora, présentant les principes techniques et les applications qui le sous-tendent.
Alors, comment Sora a-t-il réalisé cette percée ? Inspiré par l'expérience pratique réussie de LLM, OpenAI introduit des codes d'intégration de correctifs visuels (patchs), une représentation visuelle des données hautement évolutive et efficace qui peut considérablement améliorer la capacité des modèles génératifs à gérer diverses données vidéo et image.

Dans un espace de grande dimension, OpenAI compresse d'abord les données vidéo dans un espace latent de basse dimension, puis les décompose en intégrations spatio-temporelles, convertissant ainsi la vidéo en une série de blocs d'encodage.
Ensuite, OpenAI a formé un réseau spécialement conçu pour réduire la dimensionnalité des données visuelles. Le réseau prend une vidéo brute en entrée et génère une représentation latente compressée dans le temps et dans l’espace. C'est dans cet espace latent compressé que Sora est formé et génère des vidéos au sein de cet espace.
De plus, OpenAI a formé un modèle de décodeur capable de restaurer ces représentations latentes en images vidéo au niveau des pixels.
En traitant l'entrée vidéo compressée, les chercheurs ont pu extraire une série de correctifs spatio-temporels, qui jouent un rôle similaire aux jetons de transformateur dans le modèle.
Grâce à une représentation basée sur des correctifs, Sora peut s'adapter à des vidéos et des images de différentes résolutions, durées et formats d'image. Lors de la génération d'un nouveau contenu vidéo, ces correctifs initialisés de manière aléatoire peuvent être disposés dans une grille en fonction de la taille requise. Contrôlez la taille et forme de votre vidéo finale.

Bien que le principe ci-dessus semble assez compliqué, en fait, la nouvelle technologie utilisée par OpenAI – code d'intégration de blocs visuels (appelé bloc visuel) – revient à organiser un ensemble de blocs de construction désorganisés dans une petite boîte. De cette façon, même s'il existe de nombreux blocs de construction, vous pouvez facilement trouver les blocs de construction dont vous avez besoin tant que vous trouvez cette petite boîte.
Étant donné que les données vidéo sont converties en petits carrés, lorsqu'OpenAI fournit à Sora une nouvelle tâche vidéo, ils extrairont d'abord quelques petits carrés contenant des informations temporelles et spatiales de la vidéo. Ces petits carrés sont ensuite confiés à Sora pour générer de nouvelles vidéos basées sur ces informations.
De cette façon, la vidéo peut être reconstituée comme un puzzle. L’avantage est que l’ordinateur peut apprendre et traiter plus rapidement différents types d’images et de vidéos.
À mesure que Sora était entraîné plus en profondeur, les chercheurs d’OpenAI ont également constaté que la qualité des échantillons s’améliorait considérablement à mesure que la quantité de calculs d’entraînement augmentait. OpenAI a constaté que l'entraînement directement sur la taille d'origine des données présente plusieurs avantages :
- Sora ne recadre pas le matériel lors de la formation, ce qui permet à Sora de créer du contenu directement en fonction du rapport hauteur/largeur natif des différents appareils.
- Une formation sur le rapport hauteur/largeur natif de la vidéo peut améliorer considérablement la qualité de composition et de mise en page de la vidéo.

De plus, Sora possède les fonctionnalités suivantes :
La formation d'un système de génération texte-vidéo nécessite un grand nombre de vidéos avec des légendes textuelles. OpenAI applique la technologie de réannotation introduite dans DALL·E 3 aux vidéos.
Semblable à DALL·E 3, OpenAI utilise GPT pour convertir les courtes invites de l'utilisateur en instructions plus détaillées, puis les envoie au modèle vidéo, permettant à Sora de générer des vidéos de haute qualité.
En plus de convertir du texte, Sora peut également accepter la saisie d'images ou de vidéos existantes. Cette fonctionnalité permet à Sora d'effectuer une variété de tâches d'édition d'images et de vidéos, telles que la création de vidéos en boucle transparente, l'ajout d'effets d'animation aux images statiques, l'extension de la durée de lecture des vidéos, etc.
Une image réaliste de nuages formant le mot « SORA ».


Dans une salle historique richement décorée, une énorme vague est sur le point de déferler. Les deux surfeurs ont profité de l’occasion et ont surfé de main de maître sur les vagues.


Sora peut modifier le style et l'environnement d'une vidéo sans aucun exemple préalable. Même deux vidéos avec des styles complètement différents peuvent être connectées en douceur.

Sora peut également générer des images. L'équipe de recherche crée des images de différentes tailles en disposant des blocs de bruit gaussien dans une grille spatiale avec une plage temporelle d'une seule image. La résolution maximale atteint 2048 × 2048.

Le véritable OpenAI a également franchement admis les limites actuelles de Sora, telles que son incapacité à simuler les effets physiques de scènes complexes et à comprendre certaines relations causales spécifiques. Par exemple, il ne peut pas simuler avec précision les interactions physiques de base comme le bris de verre.

▲Courir dans la direction opposée
Mais OpenAI croit fermement que les capacités actuelles de Sora montrent que l'expansion continue des modèles vidéo est une voie prometteuse vers le développement de simulateurs performants capables de simuler les mondes physique et numérique ainsi que les objets, les animaux et les humains qu'ils contiennent.
Les modèles mondiaux, la prochaine direction de l’IA ?
OpenAI a découvert que lorsqu'il est formé à grande échelle, Sora présente un ensemble convaincant de capacités émergentes qui peuvent, dans une certaine mesure, simuler des personnes, des animaux et des environnements du monde réel.
Ces capacités ne sont pas basées sur des préréglages spécifiques d'espace ou d'objets tridimensionnels, mais sont pilotées par des données à grande échelle.
- Cohérence dans l'espace tridimensionnel
Sora peut générer des vidéos avec des changements de perspective dynamiques. Lorsque la position et l'angle de la caméra changent, les personnages et les éléments de la scène de la vidéo peuvent se déplacer de manière cohérente dans l'espace tridimensionnel. - Continuité longue distance et persistance des objets Sora maintient la continuité vidéo sur de longues périodes, même lorsque des personnes, des animaux ou des objets sont masqués ou déplacés hors du cadre. De même, il peut afficher le même personnage plusieurs fois dans le même échantillon vidéo et garantir une apparence cohérente.
- Simulation du monde numérique
Sora peut également simuler des processus numériques, tels que des jeux vidéo, en mentionnant simplement les mots « Minecraft » pour activer ses capacités associées.
OpenAI considère Sora comme « la base de modèles capables de comprendre et de simuler le monde réel » et estime que ses capacités « constitueront une étape importante dans la réalisation de l’AGI ».
Concernant l'arrivée de Sora, Jim Fan, scientifique principal de NVIDIA, a déclaré :
Si vous pensez que Sora d'OpenAI est un outil d'expérimentation créative, comme DALL·E, vous voudrez peut-être reconsidérer votre décision.
Sora est en fait un moteur de simulation physique basé sur des données qui peut simuler des mondes réels ou fictifs. Ce simulateur apprend le rendu d'images complexes, le comportement physique « intuitif », les capacités de planification à long terme et la compréhension du niveau sémantique grâce aux calculs de débruitage et de gradient.
La base de cette capacité de modèle est le modèle universel mondial, qui est un système d'intelligence artificielle. Son objectif est de construire un module de réseau neuronal capable de mettre à jour l'état pour mémoriser et modéliser l'environnement.
Ce modèle est capable de prédire la prochaine observation possible en fonction des observations actuelles (telles que des images, des états, etc.) et des actions à venir. Il simule d'éventuels événements futurs dans l'environnement en apprenant les lois et le bon sens du monde.

En fait, le modèle mondial n'est pas un concept nouveau : dès décembre de l'année dernière, Runway, le leader de la génération de vidéos IA, a officiellement annoncé qu'il construirait un modèle mondial universel dans le but de créer une sorte de LLM différent. du LLM existant et peut être plus réaliste.Systèmes d'intelligence artificielle qui simulent le monde réel.
Plus précisément, l'idée centrale du modèle mondial est d'apprendre comment le monde fonctionne en mémorisant l'expérience historique, puis de prédire les événements qui pourraient se produire dans le futur. Par exemple, à partir d'une vidéo d'un objet qui tombe, le modèle peut prédire l'image suivante en fonction de l'image actuelle, apprenant ainsi les lois physiques du mouvement de l'objet.
Yann LeCun, lauréat du prix Turing, a également proposé un concept similaire et critiqué les grands modèles basés sur l'autorégression générative probabiliste, tels que GPT, estimant que de tels modèles ne peuvent pas résoudre le problème des hallucinations. LeCun et son équipe prédisent même que des modèles comme GPT pourraient devenir obsolètes d’ici cinq ans.
Les modèles mondiaux peuvent être considérés comme une direction de recherche dans le domaine de l’intelligence artificielle qui tente de créer une IA plus proche du niveau de l’intelligence humaine. En simulant et en apprenant à partir d’environnements et d’événements du monde réel, les modèles mondiaux ont le potentiel de conduire l’IA vers des niveaux plus élevés de capacités de simulation et de prédiction.
En février, Justine Moore, associée de la célèbre société de capital-risque a16z, a mené une analyse approfondie de la situation actuelle dans le domaine de la génération vidéo IA. Au cours des deux années qui se sont écoulées depuis que l’IA générative est progressivement devenue publique, le domaine de la génération vidéo d’IA a inauguré une scène prospère où une centaine de fleurs s’épanouissent et une centaine d’écoles de pensée s’affrontent.
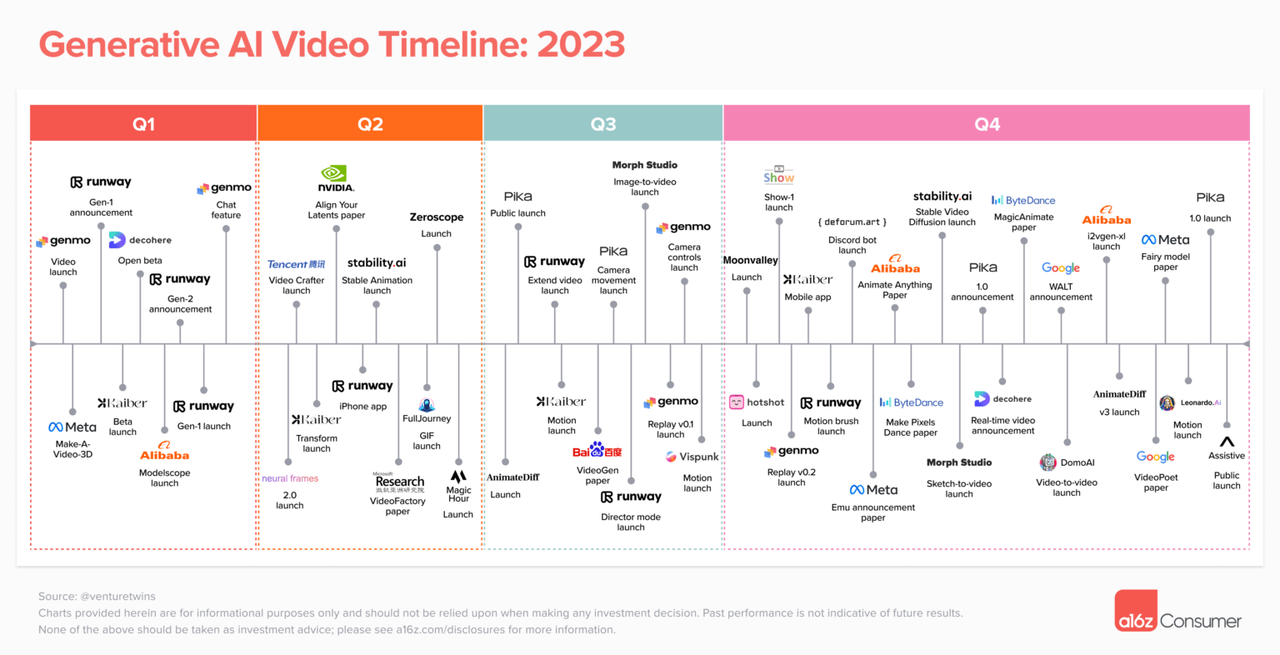
Avec l'ajout d'OpenAI Sora, le domaine de la génération vidéo IA fera d'énormes vagues, et les plates-formes grand public existantes telles que Runway, Pika et Stable Video Diffusion pourraient être affectées.
Dans le même temps, les règles du jeu pour les créateurs indépendants seront complètement modifiées : toute personne ayant de la créativité et des idées pourra utiliser Sora pour générer son propre contenu vidéo. L’abaissement du seuil de création signifie également que les créateurs indépendants entreront dans un âge d’or.
Comme indiqué dans « Le problème à trois corps », « Cela n'a pas d'importance. » Quelle que soit la situation concurrentielle actuelle, le domaine de la génération vidéo IA pourrait être bouleversé par les nouvelles technologies et innovations. Et l'entrée de Sora n'est que le début, loin d'être la fin.
# Bienvenue pour suivre le compte public officiel WeChat d'aifaner : aifaner (ID WeChat : ifanr). Un contenu plus passionnant vous sera fourni dès que possible.
Ai Faner | Lien original · Voir les commentaires · Sina Weibo