
DeepSeek fait pression pour la stratégie d’élargissement de Gemini, la fonction de recherche de ChatGPT est gratuite et ouverte et l’IA lance une guerre de partage des bénéfices

À la fin de l'année dernière, Google Deepmind a lancé le modèle Gemini 2.0 Flash pour l'ère des agents intelligents, entrant d'un pied dans l'ère 2.0. Après deux mois, la série de seaux familiaux Gemini 2.0 a finalement été officiellement lancée.
Catalysée par « l'effet poisson-chat » de DeepSeek, cette version est différente de l'habituelle. Elle améliore non seulement encore les performances, mais brandit également la bannière de la rentabilité de l'IA et adopte également des capacités multimodales.
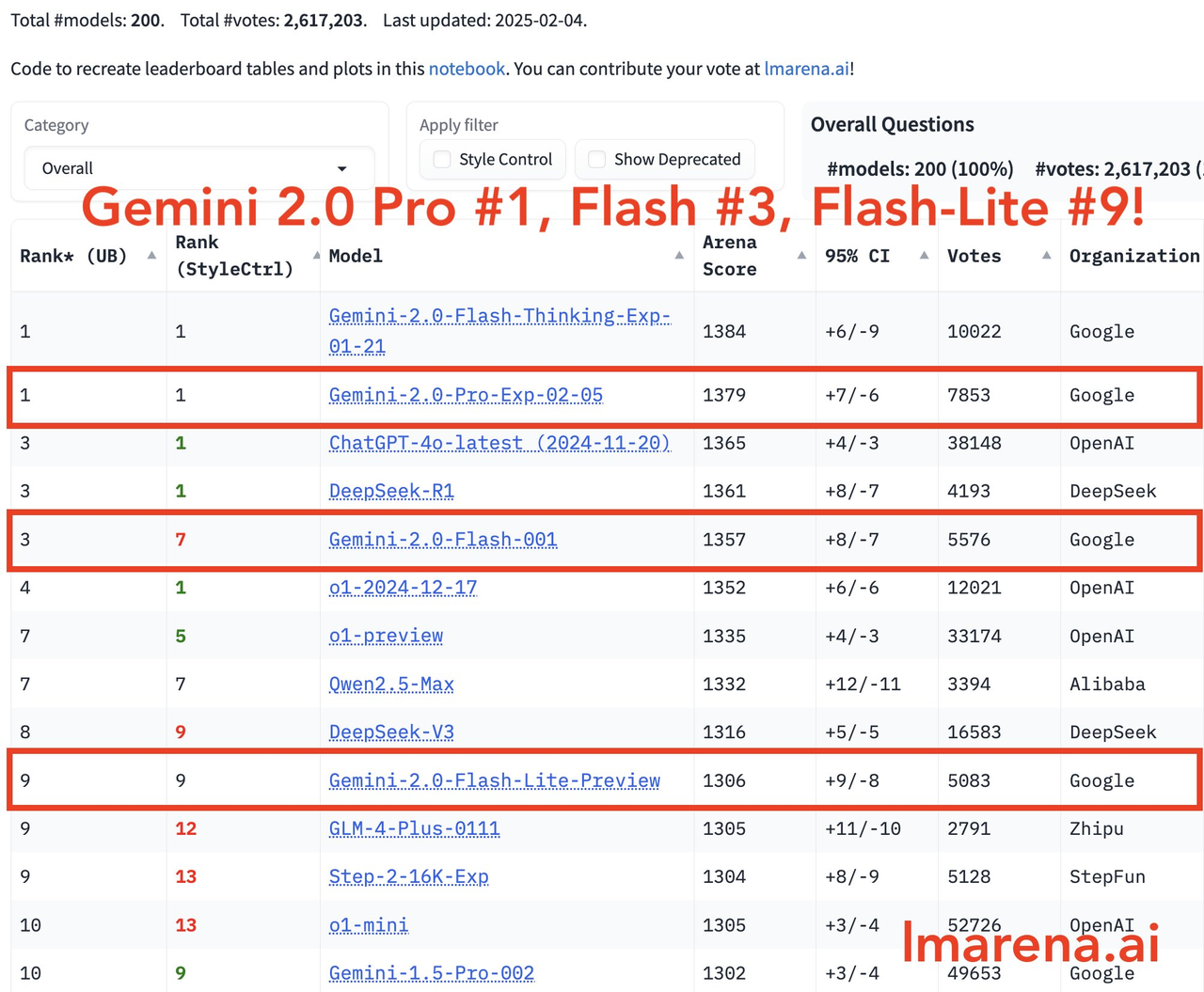
Dans le dernier domaine des grands modèles, Gemini-2.0-Pro se classe premier dans toutes les catégories, Gemini-2.0-Flash se classe troisième et Flash-lite se classe parmi les dix premiers en raison de son excellent rapport qualité/prix.
Demis Hassabis, PDG de Deepmind, a écrit :
Des progrès passionnants ! Nous nous efforçons de réduire les coûts tout en améliorant constamment la qualité. La série Gemini 2.0 est un modèle leader en termes de rapport prix/performance et de performances. Avec la version d’aujourd’hui, chacun peut profiter de son puissant raisonnement et de ses capacités multimodales, qui jettent également les bases de notre travail intelligent.
Les principales caractéristiques des modèles de la série Gemini 2.0 sont les suivantes :
- 2.0 Pro Experimental : se concentre sur les performances de codage et la capacité à gérer des invites complexes, et fonctionne bien en matière de compréhension des connaissances et de raisonnement logique.
- 2.0 Flash : fournit une interface API spécifiquement destinée aux développeurs pour prendre en charge la création rapide d'applications.
- 2.0 Flash-Lite : obtenez une meilleure rentabilité et une meilleure réactivité tout en conservant des performances élevées.
- 2.0 Flash Thinking Experimental : il est désormais disponible dans l'application Gemini pour que les utilisateurs puissent en faire l'expérience.
Que peut-on faire avec moins de 1$ ? Le nouveau modèle de Google peut sous-titrer 40 000 images
Plus précisément, la série Gemini 2.0 de modèles de godets familiaux a chacune ses propres caractéristiques.
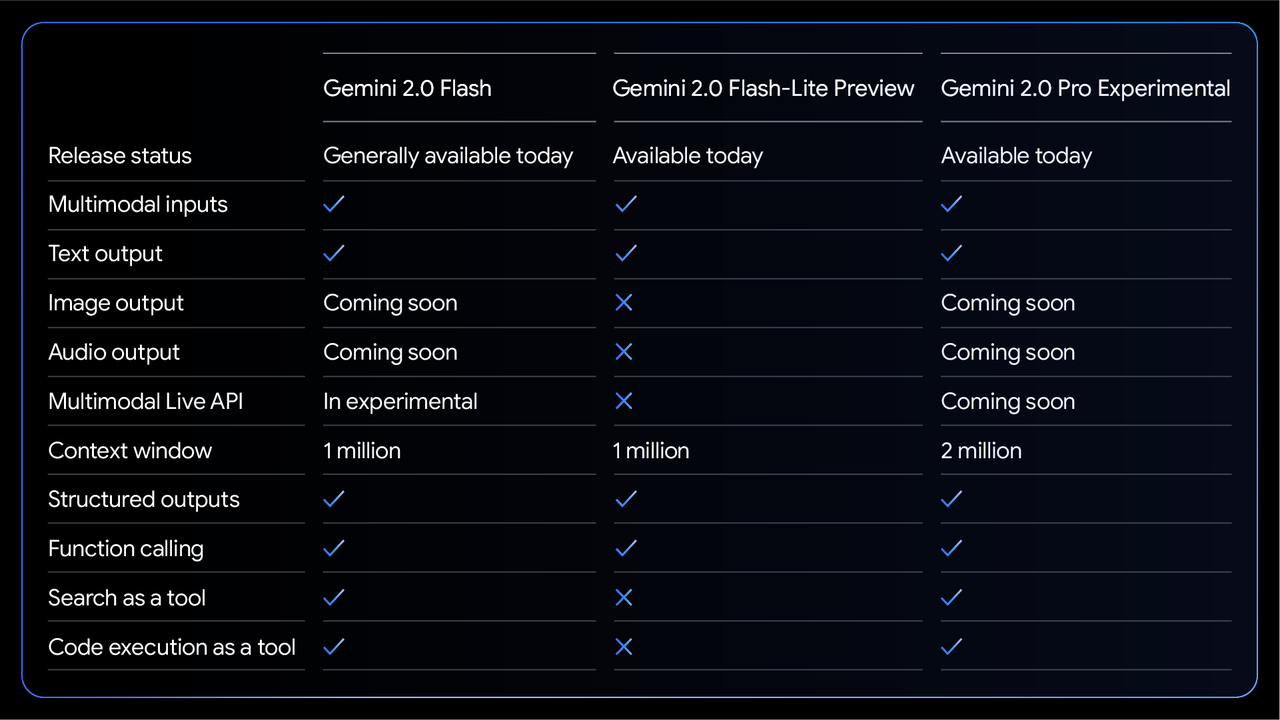
Parmi eux, Gemini 2.0 Flash, qui a été entièrement publié, prend en charge l'entrée multimodale et la sortie de texte, dispose d'une fenêtre contextuelle de 1 million de jetons et prend en charge la sortie structurée, l'appel de fonction, l'exécution de code et d'autres fonctions.
Il convient de noter que son API multimodale en temps réel est encore au stade « bêta » et que les fonctions de sortie d'image et audio seront également lancées ultérieurement.
Le plan tarifaire de ce modèle a également été déterminé, avec une entrée texte, image et vidéo facturant 0,10 $ par million de jetons et une entrée audio coûtant 0,70 $ (officiellement en vigueur à partir du 20 février). La sortie de texte coûte 0,40 $ par million de jetons.
Tous les types de frais de cache sont également maintenus à un niveau bas. La mise en cache texte/image/vidéo coûte 0,025 $ par million de jetons et la mise en cache audio coûte 0,175 $.
Sur cette base, Google a également lancé une « version allégée » plus rentable : Gemini 2.0 Flash-Lite.
Bien que ce modèle ait fait certains compromis en termes de fonctionnalités et ne prenne actuellement pas en charge les API multimodales en temps réel, les outils de recherche et l'exécution de code, il conserve une fenêtre contextuelle d'un million de jetons, ainsi que des fonctions de base telles que l'entrée multimodale, la sortie de texte et les appels de fonction.

Son prix est plus abordable, les entrées texte, image et vidéo ne coûtant que 0,075 $ par million de jetons, soit près d'un tiers moins cher que la version standard. L'entrée audio coûte également 0,075 $, la sortie texte est de 0,30 $, la mise en cache texte/image/vidéo n'est que de 0,01875 $ par million de jetons et la mise en cache audio est de 0,175 $.
À titre de comparaison, le modèle DeepSeek-V3 coûte désormais 0,014 $ par million de jetons lors de l'accès au cache. À partir du 8 février, son prix reviendra au niveau de 0,07 $ par million de jetons. Cet ajustement pourrait également être l’un des facteurs importants qui ont incité Google à formuler sa stratégie de tarification actuelle.

Selon Google, le coût d'utilisation de ce modèle pour générer des légendes pour 40 000 images uniques est inférieur à 1 $.
Au sommet de la gamme de produits se trouve la version Gemini 2.0 Pro Experimental. Ce modèle dispose d'une grande fenêtre contextuelle de 2 millions de jetons, ce qui équivaut à traiter environ 1,5 million de mots à la fois, ce qui est plus que suffisant pour digérer l'intégralité des sept livres de la série « Harry Potter » en même temps.
Sur le plan fonctionnel, il s'agit également du lecteur le plus polyvalent, prenant non seulement en charge la saisie multimodale et la sortie de texte, mais disposant également de fonctionnalités complètes telles que la sortie structurée, l'appel de fonctions, les outils de recherche et l'exécution de code.
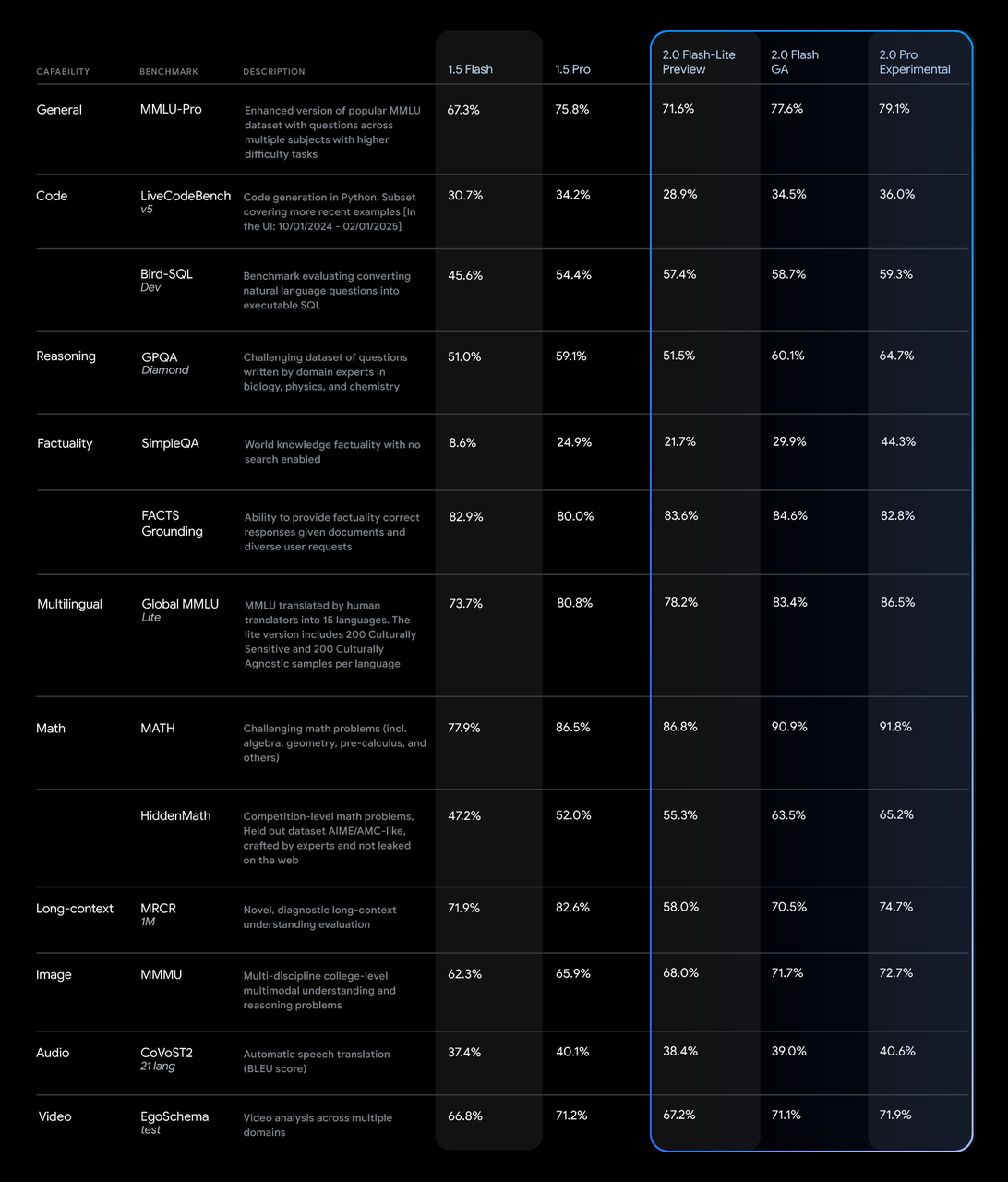
En termes de tests de performances, la série Gemini 2.0 fonctionne bien.
Dans le test MMLU-Pro, le 2.0 Pro Experimental était en tête avec un score de 79,1 %, tandis que le 2.0 Flash Lite Preview et le 2.0 Flash GA ont obtenu respectivement 71,6 % et 77,6 %.
En termes de génération de code, de mathématiques et de capacité multilingue, 2.0 Pro Experimental a également obtenu de bons résultats, notamment en mathématiques (91,8 %) et en capacité multilingue (86,5 %).
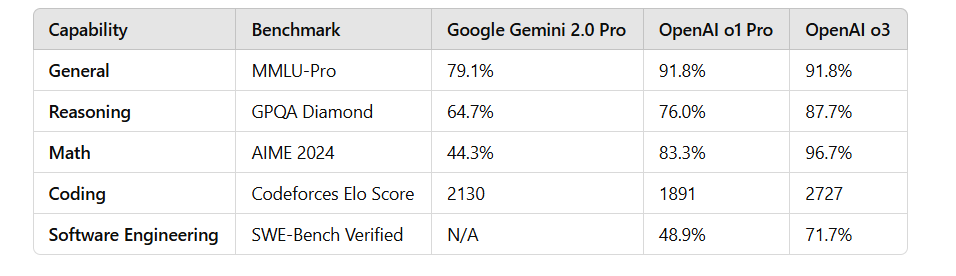
Malheureusement, même la version expérimentale Gemini 2.0 Pro la plus puissante est loin derrière le modèle OpenAI o3 et n'a pas réalisé le « dépassement de virage » attendu par le monde extérieur.
Cependant, certains internautes estiment que, puisque Gemini 2.0 Pro n'est pas un modèle CoT typique, la comparaison actuelle des performances n'est peut-être pas tout à fait raisonnable.
Les principaux avantages de ces modèles sont leur réactivité rapide et leur faible coût, ce qui les rend particulièrement adaptés à des tâches spécifiques telles que la reconnaissance ou la classification d'entités nommées. Avec le lancement prochain de nouvelles fonctionnalités telles que la génération d'images et la synthèse vocale, les scénarios d'application de la série Gemini 2.0 seront encore élargis.
Ces nouveaux modèles sont désormais disponibles pour les développeurs de Google AI Studio et de la plateforme Vertex AI, ainsi que pour les utilisateurs expérimentés de Gemini sur leurs appareils.
Bataille de serpents, balle sautante, Gemini 2.0 peut toujours jouer comme ça
Qui a dit que l’IA ne pouvait donner que des réponses sèches ? Avec le lancement de Gemini 2.0 Family Bucket, les internautes ont hâte de jouer de nouveaux tours.
Par exemple, vous voulez voir un combat de serpents ? Laissez Gemini 2.0 concevoir un jeu Snake en utilisant du code.

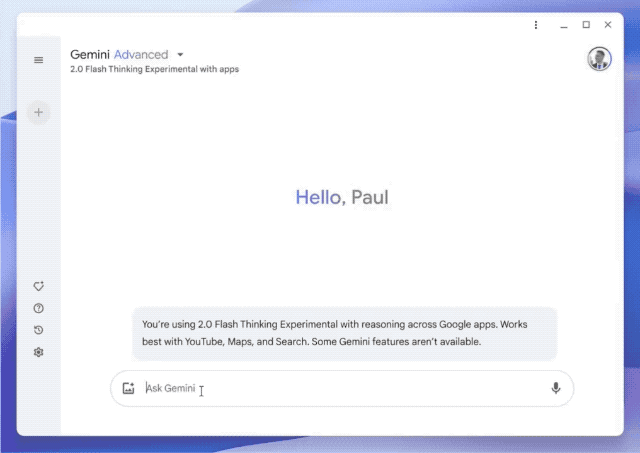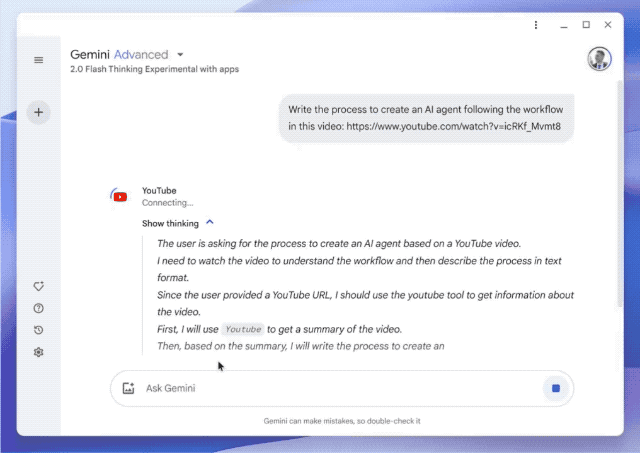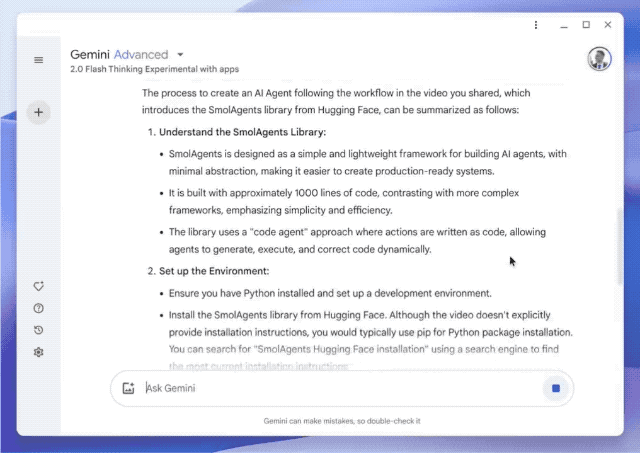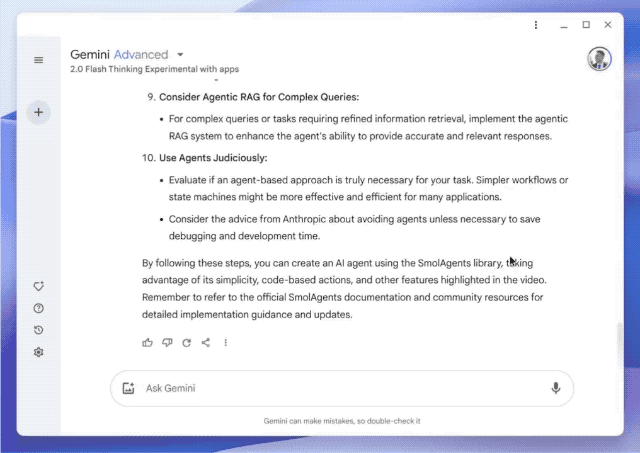
Or, le modèle Gemini Flash Thinking est le premier modèle d'inférence à avoir accès à YouTube, et il prend également en charge les fonctions de recherche et de carte Google.
En termes de rendu d'image, un développeur a demandé au modèle d'écrire un script utilisant p5.js, qui générait une scène tridimensionnelle contenant 100 boules jaunes rebondissantes dynamiques. De plus, les boules jaunes à l’intérieur de la sphère doivent pouvoir entrer en collision correctement, la sphère doit tourner lentement et toujours rester à l’intérieur de la sphère.
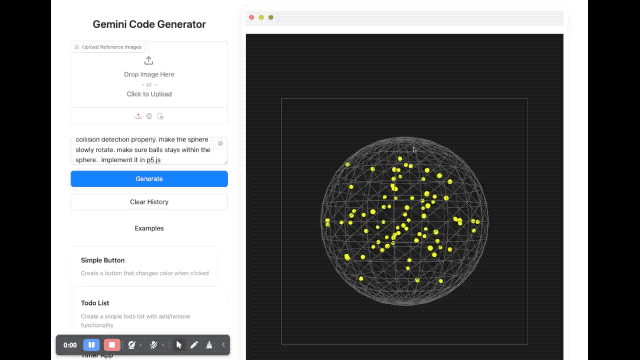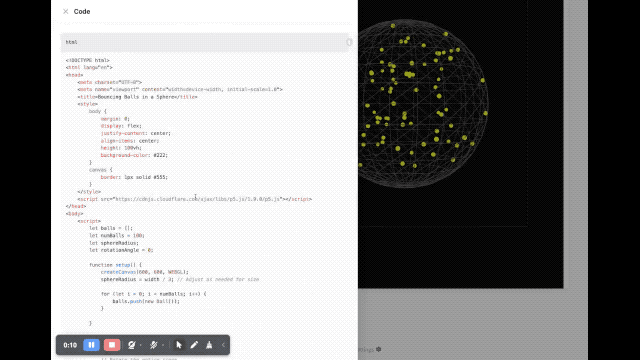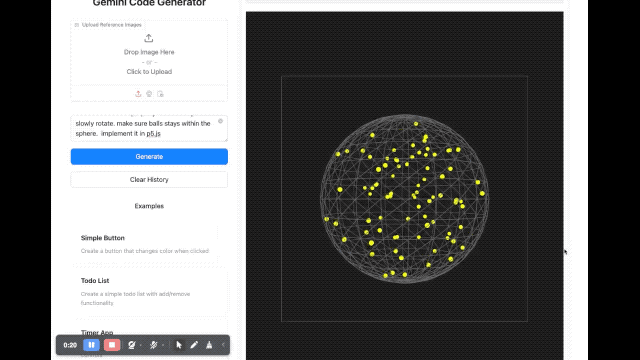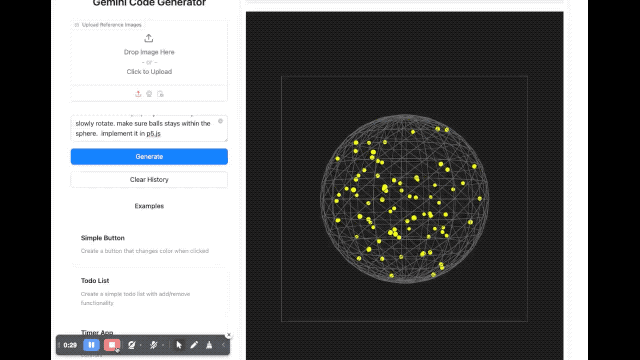
Nous avons également brièvement expérimenté plusieurs nouveaux modèles sortis cette fois dans le studio Google AI. La vitesse de réponse de ces nouveaux modèles est assez rapide Quant à l’effet, euh, c’est vraiment difficile à évaluer.
Pendant que Gemini montre ses muscles, OpenAI, qui est souvent un tireur d'élite, continue également à déployer ses efforts.
Aujourd'hui, OpenAI a annoncé tôt le matin que la fonction Deep Research était entièrement ouverte à tous les utilisateurs Pro, y compris le Royaume-Uni, l'UE, la Norvège, l'Islande, le Liechtenstein, la Suisse et d'autres régions. De plus, les utilisateurs versent des larmes d’envie.
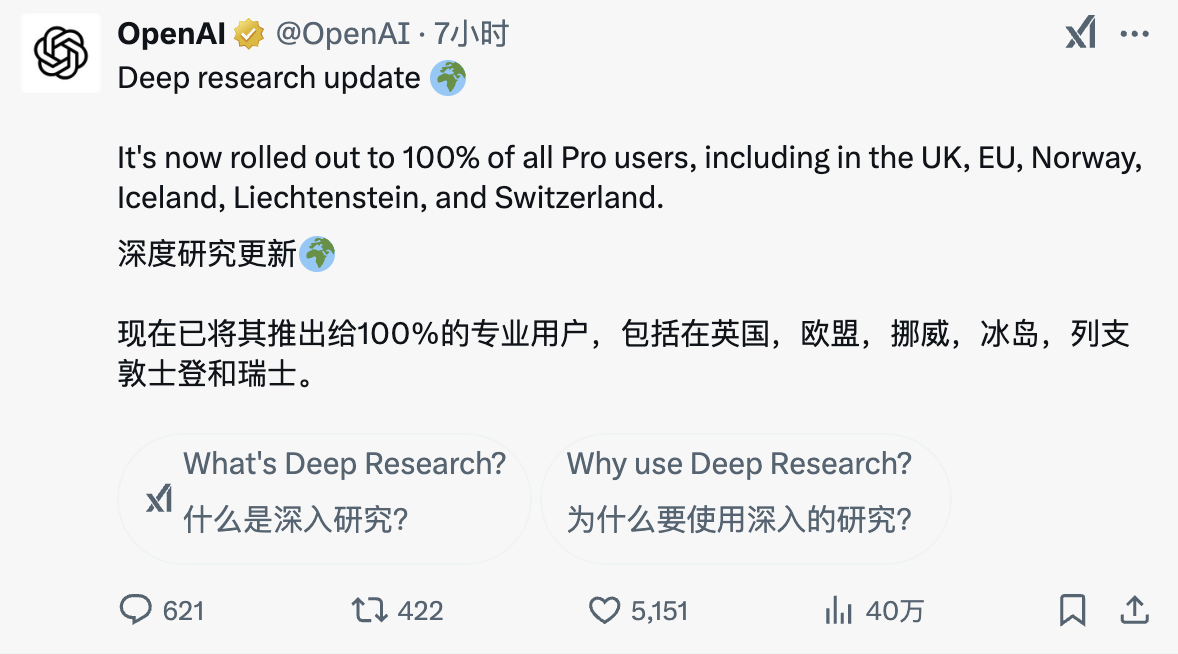
De plus, la fonction de recherche de ChatGPT est désormais ouverte à tous les utilisateurs et peut être utilisée sans inscription, abaissant encore le seuil d'utilisation.
Cependant, avant de regrouper le modèle, vous pourriez aussi bien regrouper d'abord le nom du modèle AI. Qu'il s'agisse de la série Gemini ou de la série GPT/o d'OpenAI, à mesure que les nouveaux modèles se succèdent, les différents numéros de version et règles de dénomination sont également éblouissants.
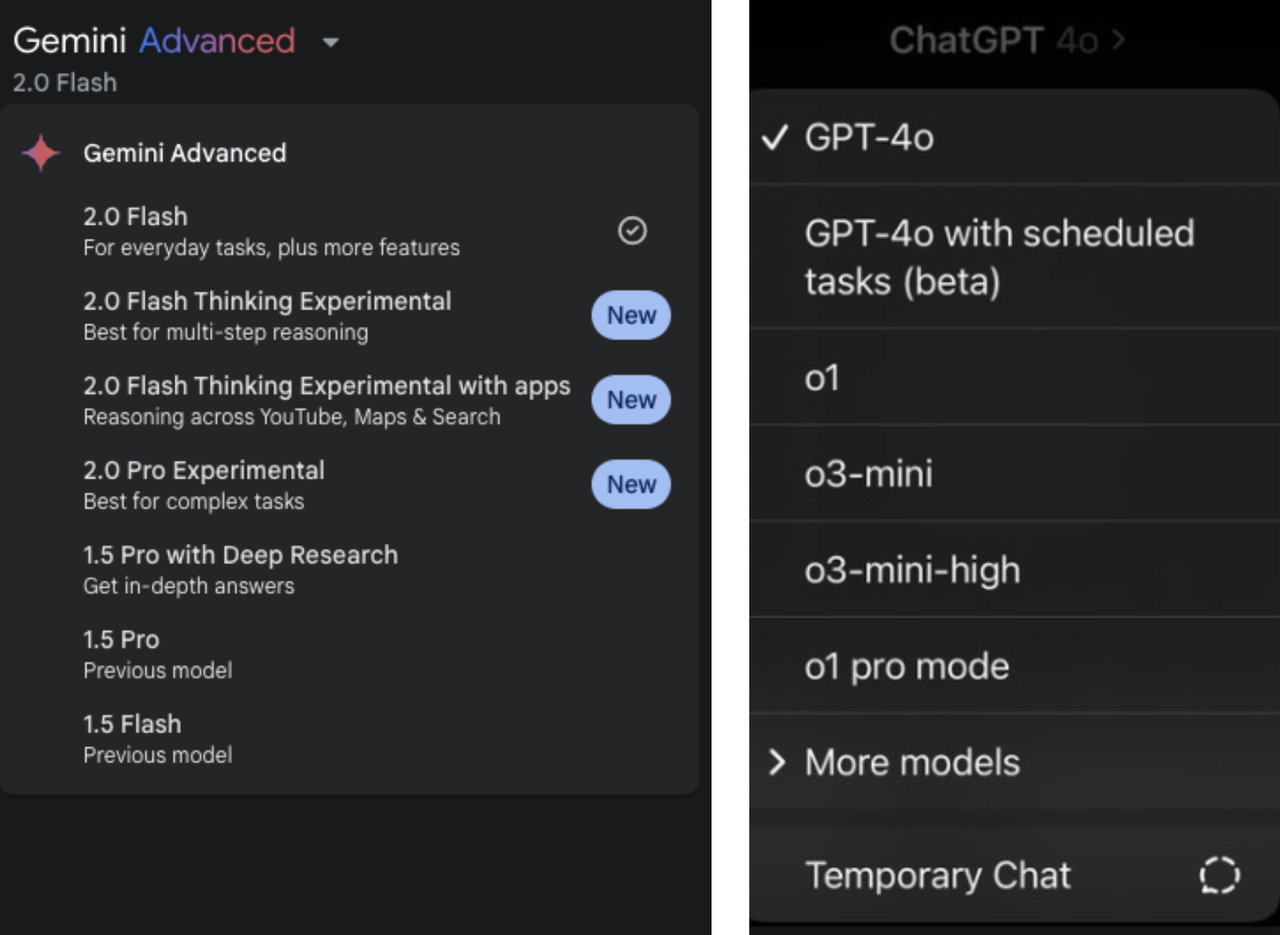
L'année dernière, lorsque Sam Altman, PDG d'OpenAI, a été interrogé sur la stratégie de dénomination des produits de l'entreprise, il a également admis que c'était un vrai casse-tête.
Le PDG d'Anthropic, Amodei, a déclaré un jour que même si la méthode de dénomination de Claude semblait bonne au début, avec l'itération et la mise à jour rapides du modèle, le système de dénomination encore utilisé s'est également étendu.
Il a souligné qu'aucune entreprise d'IA n'a vraiment « résolu le problème de dénomination » à l'heure actuelle et que tout le monde travaille dur pour trouver des méthodes de dénomination plus simples et plus claires. Il s’agit peut-être également d’un rare consensus parmi les géants de l’IA.
# Bienvenue pour suivre le compte public officiel WeChat d'aifaner : aifaner (ID WeChat : ifanr). Un contenu plus passionnant vous sera fourni dès que possible.
Ai Faner | Lien original · Voir les commentaires · Sina Weibo