
Entretien avec l’équipe Ideal Assisted Driving : Comment la conduite assistée est passée du statut de « singe » à celui d’« humain »

L'année dernière à la même époque, iFanr et Dongchehui ont discuté avec l'équipe Ideal Assisted Driving du centre de recherche et développement Ideal Beijing. À cette époque, la nouvelle architecture technologique d'Ideal Assisted Driving, « modèle de langage visuel de bout en bout + VLM », était sur le point d'être déployée dans les véhicules. L'équipe Ideal Assisted Driving déclarait alors :
Le cadre théorique derrière le « modèle de langage visuel de bout en bout + VLM » est la « réponse ultime » à la conduite autonome.
Avec la transition de l'architecture technique « modèle de langage visuel de bout en bout + VLM » vers VLA (Vision-Language-Action, modèle d'action du langage visuel), nous nous rapprochons un peu plus de la « réponse ultime ».
Selon Li Xiang et l'équipe de conduite assistée Ideal, il s'agit d'une étape clé dans l'évolution des capacités de conduite assistée d'Ideal, du stade « singe » au stade « humain ». Nous avons également visité aujourd'hui le centre de R&D d'Ideal à Pékin pour poursuivre les échanges avec l'équipe de conduite assistée Ideal sur les nouvelles tendances dans ce domaine.

▲ Lang Xianpeng, vice-président principal de la R&D sur la conduite autonome chez Ideal Auto
En matière de conduite assistée, quelle est la différence entre les singes et les humains ?
Avant que la solution de conduite assistée d'Ideal ne passe au modèle de langage visuel « de bout en bout + VLM » l'année dernière, elle adoptait l'architecture technique standard du secteur « Perception – Planification – Contrôle ». Cette architecture repose sur l'écriture par les ingénieurs de règles adaptées pour guider le contrôle du véhicule en fonction de diverses conditions de circulation réelles, mais il est difficile de couvrir toutes les situations réelles.

Nous sommes dans l'ère mécanique de la conduite assistée. Celle-ci ne peut gérer que des situations soumises à des règles spécifiques et n'a aucune capacité de réflexion ni d'apprentissage.
Le « modèle de langage visuel de bout en bout + VLM » marque l'avènement de l'« ère du singe » en matière de conduite assistée. Comparés aux machines, les singes sont plus intelligents et possèdent une certaine capacité d'imitation et d'apprentissage. Bien sûr, ils sont aussi plus actifs et désobéissants.
L'essence du modèle de langage visuel « de bout en bout + VLM » repose sur l'apprentissage par imitation, qui s'appuie sur de nombreuses données de conduite humaine pour l'apprentissage. La quantité et la qualité de ces données déterminent les performances. De plus, pour des raisons de sécurité, dans cette architecture, le modèle de langage visuel VLM, responsable des scénarios complexes, ne participe pas au contrôle du véhicule ; il se limite à la prise de décision et au guidage de trajectoire.

VLA (Vision-Language-Action) est « l'ère humaine » de la conduite assistée, possédant la capacité de « penser, communiquer, se souvenir et s'améliorer ».
Les singes ont subi une longue transformation pour devenir humains. En théorie, l'apprentissage par imitation du modèle de langage visuel de bout en bout + VLM permet également d'apprendre la quasi-totalité des données de conduite humaine sur une longue période et de se comporter presque comme un humain.
Mais le prix, c'est le « temps ».
Lang Xianpeng, vice-président senior de la R&D sur la conduite autonome chez Ideal Auto, a déclaré :
L'année dernière, notre kilométrage moyen de prise en charge (MPI) de bout en bout était d'environ dix kilomètres dans la première version, en juillet dernier. Nous le trouvions plutôt bon à l'époque, car notre version sans carte était en développement depuis longtemps, et le MPI complet (autoroute + ville) n'était que d'environ dix kilomètres.
De 1 à 2 millions de clips (clips vidéo utilisés pour la formation complète à la conduite assistée), puis à 10 millions de clips, à mesure que le volume de données augmentait, l'IPM a atteint 100 kilomètres au début de l'année. En sept mois, l'IPM a décuplé, en moyenne plusieurs fois par mois.
Mais après avoir atteint 10 millions de clips, nous avons découvert un problème : augmenter simplement la quantité de données était inutile ; la quantité de données précieuses diminuait. C'est comme un examen : en cas d'échec, prendre un crédit aléatoire peut améliorer très rapidement votre score. Mais avec 80 ou 90 points, il est très difficile d'améliorer même de 5 ou 10 points.
À ce stade, nous avons utilisé le super-alignement pour forcer le modèle à produire des résultats conformes aux attentes humaines. Nous avons également sélectionné certaines données et les avons complétées par un super-alignement afin d'améliorer encore les capacités du modèle. Cette approche a eu un certain effet, mais il nous a fallu environ cinq mois, de mars à fin juillet de cette année, pour obtenir une amélioration d'environ deux fois les performances du modèle.
C'est le premier problème rencontré par l'architecture technique « modèle de langage visuel de bout en bout + VLM » après ses progrès rapides : plus le temps passe, plus les données utiles se raréfient, et plus l'amélioration des performances du modèle est lente.

Le problème fondamental a également été mis en lumière. Lang Xianpeng a déclaré :
Fondamentalement, l'apprentissage par imitation de bout en bout actuel manque de capacités de raisonnement logique profond. C'est comme un singe conduisant une voiture. Donnez-lui des bananes, et il se comportera peut-être comme vous le souhaitez, mais il ignorera pourquoi. Il viendra peut-être à vous lorsqu'on frappe un gong, ou dansera lorsqu'on joue du tambour, mais il ignorera pourquoi.
Par conséquent, l'architecture de bout en bout ne permet pas une réflexion approfondie. Il s'agit tout au plus d'une réponse au stress. Autrement dit, étant donné une entrée, le modèle produit une sortie. Il n'y a aucune logique profonde derrière cela.
C'est pourquoi nous ajoutons un modèle de langage visuel (MLV) au grand modèle de bout en bout. Ce modèle possède des capacités de compréhension et de réflexion plus avancées, permettant une meilleure prise de décision. Cependant, ce modèle est lent à réfléchir et peu couplé au grand modèle de bout en bout. Par conséquent, ce dernier a souvent du mal à comprendre ou à accepter les décisions prises par le MLV.
À la même époque l’année dernière, l’équipe de conduite assistée idéale déclarait :
Deux tendances futures se dessinent. Premièrement, l'échelle des modèles va augmenter. Les Systèmes 1 et 2 sont actuellement deux modèles de bout en bout avec un VLM. Ces deux modèles pourraient être fusionnés. Actuellement, leur couplage est faible, mais il pourrait être renforcé à l'avenir. Deuxièmement, nous pouvons également tirer des enseignements de la tendance actuelle des grands modèles multimodaux. Ces modèles évoluent vers une multimodalité native, capable de gérer le langage, la parole, la vision et le lidar. C'est un aspect que nous étudierons à l'avenir.
La tendance est rapidement devenue réalité.
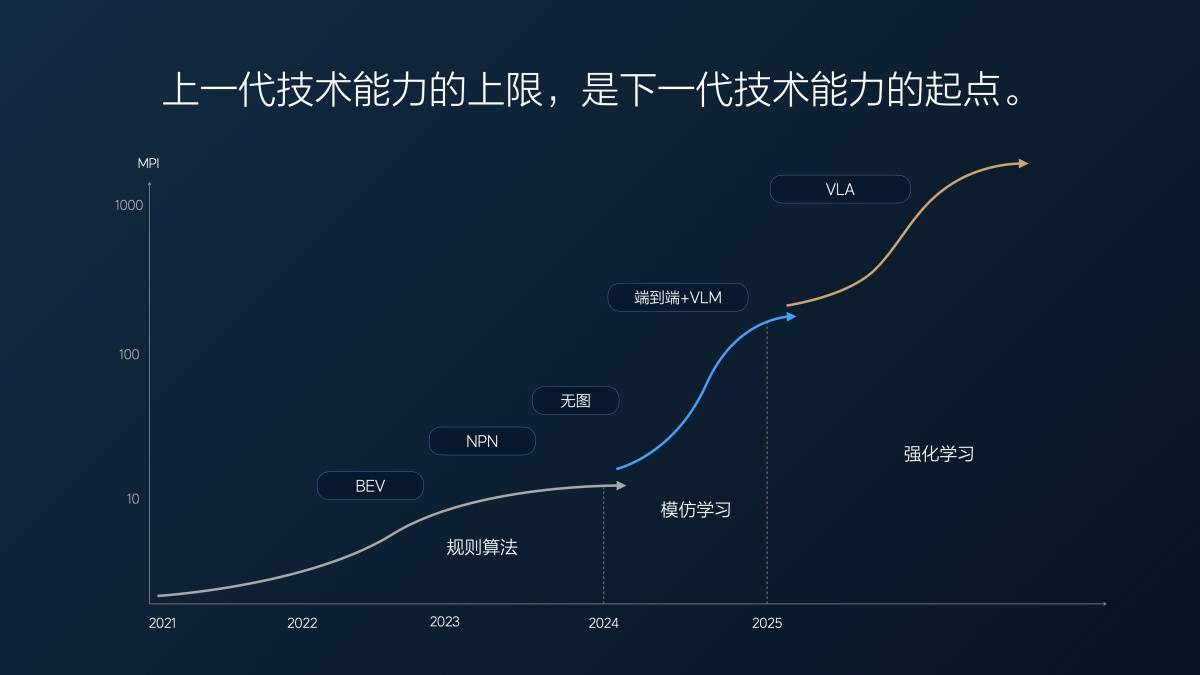
Lang Xianpeng a également expliqué les raisons du passage du end-to-end + VLM au VLA :
Lorsque nous travaillions de bout en bout l’année dernière, nous nous demandions constamment si cela était suffisant et, dans le cas contraire, ce que nous devions faire d’autre.
Nous avons mené des recherches préliminaires sur l'intelligence artificielle volatilisée (VLA). Ces recherches témoignent de notre compréhension du fait que l'intelligence artificielle n'est pas un apprentissage par imitation. Elle doit posséder des capacités de réflexion et de raisonnement comparables à celles des humains. Autrement dit, elle doit être capable de résoudre des situations qu'elle n'a jamais vues ou des scénarios inconnus. Certes, elle possède une certaine capacité de généralisation de bout en bout, mais cela ne suffit pas pour être considérée comme dotée de capacités de réflexion.
Tout comme un singe, il peut faire quelque chose que vous pensez dépasser votre imagination, mais il ne le fera pas toujours. Mais les humains sont différents. Ils peuvent évoluer et itérer ; nous devons donc développer notre intelligence artificielle en fonction de l'évolution de l'intelligence humaine. Nous sommes rapidement passés de la solution de bout en bout à la solution VLA.
VLA (Vision-Language-Action) est la tendance de pensée de l'année dernière et l'architecture technique qui est devenue une réalité aujourd'hui.
Bien que VLA et VLM ne diffèrent que par une seule lettre, leurs connotations sont très différentes.
La vision dans VLA fait référence à l'entrée de diverses informations de capteurs, y compris des informations de navigation, qui permettent au modèle de comprendre et de percevoir l'espace.
Le langage VLA fait référence à la capacité du modèle à résumer, traduire, compresser et encoder la compréhension spatiale perçue dans une expression linguistique, tout comme un humain.
L'action de VLA est le modèle générant une stratégie comportementale basée sur le langage de codage de la scène pour conduire la voiture.
La différence la plus intuitive réside dans la possibilité de contrôler la voiture grâce au langage. On peut ralentir ou accélérer la voiture, ou encore tourner à gauche ou à droite, en parlant. Cela est principalement dû au langage. Les instructions reçues par le grand modèle de commandes humaines sont également des instructions du modèle VLA, ce qui équivaut à connecter les personnes et les voitures.
De plus, il n'existe plus de barrière entre la vision et le comportement. La vitesse et l'efficacité de la transmission des informations visuelles à la transmission des comportements de contrôle du véhicule sont considérablement accélérées, et les problèmes de lenteur du VLM et de manque de compréhension de bout en bout sont résolus.
Une différence plus significative réside dans la capacité de la chaîne de pensée (CoT). Le modèle VLA a une fréquence d'inférence de 10 Hz, soit plus de trois fois plus rapide que le VLM. Il offre également une perception et une compréhension plus complètes de l'environnement, permettant un raisonnement plus rapide et plus rationnel et la prise de décisions stratégiques.
En plus des capacités de réflexion et de communication, VLA possède également une certaine capacité de mémoire, qui lui permet de se souvenir des préférences et des habitudes du propriétaire ; ainsi qu'une capacité d'apprentissage autonome assez forte.

▲ Ideal i8 est le premier modèle à utiliser la technologie Ideal VLA
Conduite assistée idéale « Flying Life »
Dans le monde réel, si les humains veulent devenir des conducteurs expérimentés, ils doivent d'abord s'inscrire dans une auto-école et obtenir un permis de conduire, puis mettre un « autocollant de stage » et prendre la route, conduisant sur de vraies routes pendant quelques années.
Il en va de même pour les formations à la conduite assistée antérieures, qui nécessitent non seulement des données de conduite réelles pour la formation, mais également un grand nombre de tests routiers dans le monde réel.
Dans certains romans, certains candidats talentueux peuvent devenir des maîtres d'arts martiaux avec des niveaux de compétence extrêmement élevés grâce à la lecture, comme « l'immortel à l'épée confucéenne » Xie Xuan dans « Le Chant de la jeunesse » et Xuanyuan Jingcheng dans « L'épéiste dans la neige ».
Cependant, dans les romans d'arts martiaux traditionnels, il n'y a que des personnages comme Wang Yuyan dans « Les Demi-Dieux et Demi-Diables » qui maîtrisent les classiques des arts martiaux mais n'ont aucune capacité de combat réelle.

▲ Images de « Speeding Life »
Bien sûr, il existe aussi des situations intermédiaires : dans le film de course « Speeding Life », le pilote de course démuni Zhang Chi reproduisait constamment dans son esprit les conditions de piste complexes de la région de Bayinbuluke, conduisait dans son esprit 20 fois par jour, simulait la conduite plus de 36 000 fois en 5 ans, puis lorsqu'il revenait sur la vraie piste, il devenait le champion.
Conduire virtuellement, s'améliorer constamment et surpasser vos meilleurs résultats passés, c'est « l'algorithme ».
Cependant, avant que Zhang Chi ne revienne sur la piste et ne redevienne le pilote champion, il avait déjà fait ses preuves sur cette piste à de nombreuses reprises et accumulé beaucoup d'expérience pratique de conduite.
Une vraie voiture et une vraie route, accumuler de l'expérience jusqu'à ce que vous compreniez toutes les conditions routières de cette piste, ce sont des « données ».

Lang Xianpeng a déclaré que pour développer un bon modèle VLA, quatre niveaux de capacités sont nécessaires : les données, les algorithmes, la puissance de calcul et les capacités d'ingénierie.
Ideal met depuis longtemps en avant l'abondance de ses données, leur qualité, sa base de données performante, ainsi que la précision de leur étiquetage et de leur exploration. Concernant les données, Ideal possède également une nouvelle compétence : la génération d'entraînements.

Le modèle mondial est utilisé pour reconstruire la scène, puis des scènes similaires sont générées à partir des données réelles reconstruites. Par exemple, il est idéal de reconstruire une scène ETC à grande vitesse dans le modèle mondial. Dans ce scénario, non seulement les conditions réelles d'origine peuvent être utilisées, comme un sol ensoleillé et sec en journée, mais aussi des scènes telles que de fortes chutes de neige en journée sur un sol glissant, et une pluie fine la nuit avec une visibilité réduite.
L'algorithme d'entraînement idéal pour les modèles VLA est également étroitement lié aux données générées. Lang Xianpeng explique :
Nous n'avons pas encore atteint le développement de bout en bout en 2023. Le kilométrage d'essai effectif des véhicules réels par an est d'environ 1,57 million de kilomètres et le coût par kilomètre est de 18 yuans.
Lorsque nous avons commencé à travailler sur des systèmes de bout en bout, une partie de notre travail était déjà réalisée en simulation. En 2024, nous avons parcouru environ 5 millions de kilomètres en simulation et plus d'un million de kilomètres en tests sur véhicules réels. Le coût moyen est tombé à moins de 5 yuans par kilomètre, ce qui représente toujours environ 30 millions de yuans. Cependant, avec ces mêmes 30 millions de yuans, nous avons pu tester 6 millions de kilomètres.
Au cours des six premiers mois de cette année (du 1er janvier au 30 juin), nous avons enregistré 40 millions de kilomètres de tests, dont seulement 20 000 sur des véhicules réels, couvrant des scénarios de base. Tous nos tests, y compris le Super Alignement et les fonctionnalités VLA actuelles que vous avez vues, sont réalisés par simulation. Le coût est de 0,5 centime par kilomètre, couvrant à peine les frais d'électricité et de serveur. De plus, la qualité des tests est élevée, tous les cas et scénarios étant entièrement répliqués et précis, garantissant des résultats précis. L'augmentation du kilométrage et l'amélioration de la qualité des tests ont stimulé l'efficacité de la R&D.
Beaucoup de gens se demandaient s'il était impossible de construire un VLA en six mois et même de tout tester. En réalité, nous avons effectué de nombreux tests.
Outre leur faible coût, les tests de simulation présentent l'avantage de reproduire parfaitement la scène. En conditions réelles, il est difficile de restituer une scène à 100 %. Pour le modèle VLA, la moindre différence dans la reproduction de la scène peut entraîner une énorme différence de performances de conduite.

En ce sens, la forme d'entraînement idéale du modèle VLA est quelque peu similaire au modèle du film « Speeding Life » où le protagoniste effectue en permanence une formation virtuelle basée sur une expérience de conduite réelle.
Bien entendu, l'entraînement du modèle VLA requiert également une puissance de calcul considérable. La puissance de calcul totale actuelle d'Ideal est de 13 EFLOPS, dont 3 EFLOPS dédiés à l'inférence et 10 EFLOPS à l'entraînement. Converti en cartes graphiques, cela équivaut à 20 000 GPU NVIDIA H20 pour l'entraînement et 30 000 GPU NVIDIA L20 pour l'inférence.

Questions et réponses clés
Q : La conduite assistée intelligente présente un « triangle impossible » : efficacité, confort et sécurité, qui sont mutuellement limités et peuvent être difficiles à atteindre simultanément à ce stade. À quel indicateur le VLA d'Ideal Auto accorde-t-il actuellement la priorité ? Vous venez d'évoquer le MPI. Pouvons-nous comprendre que l'objectif ultime d'Ideal Auto est d'améliorer la sécurité afin de réduire efficacement les prises de contrôle ?
Lang Xianpeng : L'IPM est l'un de nos indicateurs. L'APM, qui correspond au kilométrage avant accident, en est un autre. Un propriétaire idéal de voiture est victime d'un accident environ tous les 600 000 kilomètres de conduite humaine, tandis que les conducteurs utilisant la conduite assistée en subissent un tous les 3,5 à 4 millions de kilomètres. Nous continuerons d'améliorer ces données de kilométrage. Notre objectif est de multiplier l'APM par dix par rapport à la conduite humaine, soit dix fois plus sûre, et d'atteindre un taux d'accidents de 6 millions de kilomètres. Cependant, cet objectif ne pourra être atteint qu'après l'amélioration du modèle VLA.
Nous avons également analysé le MPI. Si certains risques pour la sécurité peuvent entraîner une prise de contrôle du conducteur, d'autres facteurs, comme un manque de confort lors d'un freinage brusque ou brutal, peuvent également entraîner une prise de contrôle du conducteur. Bien que les risques pour la sécurité ne soient pas systématiques, les utilisateurs peuvent hésiter à utiliser la conduite assistée si le confort de conduite n'est pas optimal. Parce que le MPA mesure la sécurité, en plus de la sécurité, nous avons mis l'accent sur l'amélioration du confort de conduite dans le MPI. Découvrez les fonctionnalités de conduite assistée de l'Ideal i8 et vous constaterez une amélioration significative du confort par rapport aux versions précédentes.
L'efficacité passe après la sécurité et le confort. Par exemple, si nous prenons la mauvaise route, même si cela entraîne une perte d'efficacité, nous ne la corrigerons pas immédiatement en adoptant des comportements dangereux. Nous devons néanmoins rechercher l'efficacité en nous basant sur la sécurité et le confort.

Q : Quelles sont les difficultés du modèle VLA ? Quelles sont les exigences pour les entreprises ? À quels défis une entreprise doit-elle faire face si elle souhaite mettre en œuvre le modèle VLA ?
Lang Xianpeng : De nombreuses personnes se demandent si les constructeurs automobiles peuvent ignorer l'algorithme de règles précédent et l'étape de bout en bout s'ils souhaitent développer un modèle VLA. Je pense que ce n'est pas possible.
Bien que les données, les algorithmes et d'autres aspects de VLA puissent différer des modèles précédents, ils reposent toujours sur des bases existantes. Sans une boucle fermée complète de données collectées auprès de véhicules réels, il n'existe aucune donnée pour entraîner le modèle mondial. Ideal Auto a pu implémenter le modèle VLA grâce à ses 1,2 milliard de points de données. Seule une compréhension approfondie de ces données permet de générer des données de meilleure qualité. Sans ces bases, il est impossible d'entraîner le modèle mondial et, deuxièmement, le type de données à générer est difficile à déterminer.
Dans le même temps, le soutien de la puissance de calcul de formation de base et de la puissance de calcul d'inférence nécessite beaucoup de fonds et de capacités techniques, qui ne peuvent être réalisés sans une accumulation préalable.
Q : Ideal effectue 20 000 kilomètres de tests réels cette année. Sur quoi se base-t-on pour réduire significativement le nombre de kilomètres de tests réels ?
Lang Xianpeng : Nous pensons que les tests en conditions réelles présentent de nombreux défis. Le coût est un problème, mais le plus important est l'impossibilité de reproduire exactement le scénario dans lequel le problème s'est produit lors de certains tests. De plus, les tests en conditions réelles sont inefficaces, car ils obligent les conducteurs à conduire le véhicule puis à le retester. Nos simulations actuelles rivalisent avec les tests en conditions réelles. Plus de 90 % des tests effectués sur la Super Edition actuelle et la version VLA de l'Ideal i8 sont simulés.
Depuis l'année dernière, nous utilisons des tests de simulation pour valider notre version complète. Convaincus de sa fiabilité et de son efficacité, nous avons remplacé les tests sur véhicules réels par ces tests. Si certains tests sont irremplaçables, comme les tests de durabilité du matériel, nous utilisons généralement des tests de simulation pour les tests de performances, et les résultats sont excellents.
Avec l'avènement de l'ère industrielle, les processus de réduction des coûts ont été remplacés par la mécanisation ; avec l'avènement de l'ère de l'information, Internet a remplacé une part importante du travail. Il en va de même à l'ère de la conduite autonome. Avec l'avènement de l'ère du « bout-en-bout », nous sommes passés à l'utilisation de l'IA pour la conduite autonome. Passant d'un grand nombre d'ingénieurs et de testeurs d'algorithmes à une approche axée sur les données, nous améliorons les capacités de conduite autonome grâce aux processus de données, aux plateformes de données et à l'itération des algorithmes. À l'ère des modèles automatisés virtualisés (VLA) à grande échelle, l'efficacité des tests est le facteur clé de l'amélioration des capacités. Pour atteindre une itération rapide, il est nécessaire d'éliminer les facteurs qui l'entravent. Si des interventions manuelles et sur des véhicules réels sont encore nécessaires, la vitesse sera réduite. Il ne s'agit pas nécessairement de remplacer les tests sur véhicules réels ; la technologie et l'approche nécessitent intrinsèquement le recours à des tests de simulation. Sans cela, nous ne pratiquons pas l'apprentissage par renforcement ni ne développons de modèles VLA.
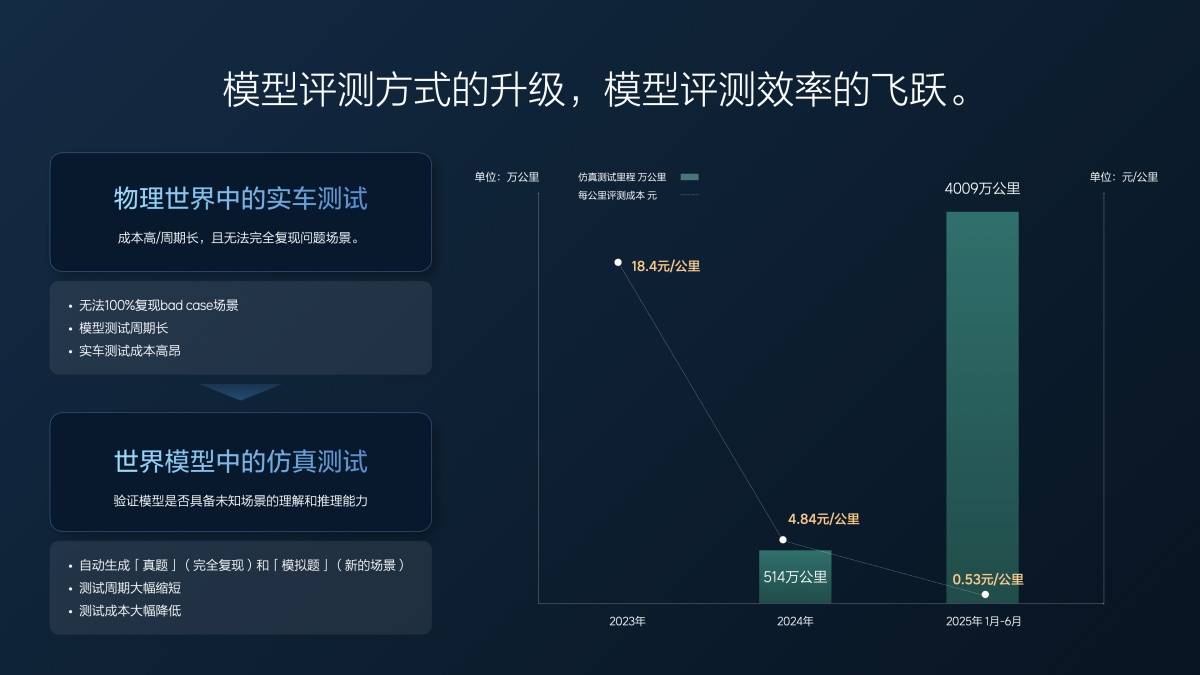
Q : VLA ne subvertit pas réellement le end-to-end + VLM, peut-on donc comprendre que VLA est une innovation qui tend à se concentrer sur les capacités d'ingénierie ?
Zhan Kun (expert senior en algorithmes, conduite autonome, Ideal Auto) : L'intelligence artificielle (VLA) est bien plus qu'une simple innovation technique. Si l'intelligence incarnée vous intéresse, vous remarquerez que cette tendance est portée par l'application de grands modèles au monde physique. Cela implique essentiellement le développement d'un algorithme VLA. Notre modèle VLA vise à appliquer les idées et les approches de l'intelligence incarnée au domaine de la conduite autonome. Nous avons été les premiers à le proposer et à le mettre en pratique. L'intelligence artificielle (VLA) est également de bout en bout, car elle repose essentiellement sur l'entrée de scène et la sortie de trajectoire, un concept similaire à celui de l'intelligence artificielle (VLA). Cependant, l'innovation algorithmique implique une réflexion supplémentaire. L'intelligence artificielle (VLA) de bout en bout peut être comprise comme de l'intelligence artificielle sans le langage. Le langage correspond à la pensée et à la compréhension. Nous avons intégré cette composante à l'intelligence artificielle (VLA), unifiant ainsi le paradigme robotique et faisant de la conduite autonome une catégorie de robotique. Il s'agit d'une innovation algorithmique, et pas seulement d'une innovation technique.
L'innovation technique constitue un défi majeur pour la conduite autonome. Le VLA est un modèle de grande envergure, et son déploiement sur des puces de pointe est extrêmement complexe. De nombreuses équipes ne considèrent pas nécessairement le VLA comme une mauvaise idée, mais plutôt comme un déploiement complexe. Sa mise en pratique est extrêmement complexe, surtout lorsque les puces de pointe manquent de puissance de calcul. Il est donc nécessaire de le déployer sur des puces à haute puissance de calcul. Il ne s'agit pas seulement d'innovation technique, mais d'une optimisation poussée du déploiement technique pour réussir.
Q : Lors du déploiement de grands modèles VLA embarqués, y aura-t-il un élagage ou une distillation du modèle ? Comment trouver un équilibre entre efficacité de l'inférence et performances du modèle ?
Zhan Kun : Nous avons soigneusement équilibré efficacité et rationalisation lors du déploiement. Notre modèle de base est un modèle propriétaire 8×0,4 B MoE (Mixture of Experts), unique dans le secteur. Après une analyse approfondie des puces NVIDIA, nous avons constaté que cette architecture était parfaitement adaptée. Elle offre une vitesse d'inférence élevée et une grande capacité de modélisation, ce qui lui permet de prendre en charge des modèles volumineux avec des scénarios et des capacités variés. C'était notre choix architectural.
De plus, nous avons distillé un modèle de grande envergure. Nous avons initialement entraîné un modèle cloud de 32 milliards de dollars, doté d'une vaste quantité de connaissances et de capacités de conduite. Nous avons distillé ses processus de réflexion et de raisonnement dans un modèle MoE de 3,2 milliards de dollars, et utilisé la technologie de diffusion en conjonction avec Vision et Action (un modèle de diffusion capable de générer des images, des vidéos, de l'audio, des trajectoires de mouvement et d'autres données. Plus précisément, dans le scénario VLA idéal, la diffusion est utilisée pour générer des trajectoires de conduite).
Nous avons réalisé de nombreuses optimisations grâce à cette approche. Plus précisément, nous avons également implémenté des optimisations techniques pour Diffusion. Plutôt que d'utiliser simplement Diffusion standard, nous avons mis en œuvre une compression d'inférence, qui peut être considérée comme une forme de distillation. Auparavant, Diffusion aurait nécessité 10 étapes d'inférence, mais la correspondance de flux n'en nécessite que deux. Cette compression est la raison fondamentale pour laquelle nous avons pu déployer VLA.

Q : VLA est-il une solution satisfaisante ? Combien de temps faudra-t-il pour atteindre ce que l'on appelle le « moment GPT » ?
Zhan Kun : Lorsqu'il a été dit précédemment que le modèle multimodal n'avait pas atteint le stade GPT, il s'agissait peut-être d'IA physique comme VLA, plutôt que de VLM. En réalité, VLM répond désormais pleinement à une norme très innovante, le « moment GPT ». Si l'on se concentre sur l'IA physique, le VLA actuel, notamment dans les domaines de la robotique et de l'intelligence incarnée, n'a peut-être pas atteint le stade GPT, car il ne dispose pas d'aussi bonnes capacités de généralisation.
Cependant, dans le domaine de la conduite autonome, le VLA résout un paradigme de conduite relativement unifié, et il est possible d'atteindre ainsi un « moment GPT ». Nous sommes également conscients que le VLA actuel est la première version, et la première à être produite en série dans l'industrie ; il comportera donc certainement des défauts.
Cette tentative majeure vise à explorer une nouvelle voie grâce à VLA. Elle comporte de nombreux domaines d'expérimentation et de nombreux points d'exploration à mettre en œuvre. Cela ne signifie pas que si nous ne parvenons pas à atteindre le « moment GPT », nous ne devons pas passer à la production de masse. De nombreux détails, notamment notre évaluation et notre simulation, permettent de vérifier la faisabilité de la production de masse et la capacité à offrir aux utilisateurs une expérience « meilleure, plus confortable et plus sûre ». Si ces trois points sont atteints, nous pourrons offrir une meilleure prestation aux utilisateurs.
Les « moments GPT » font davantage référence à une forte polyvalence et à une généralisation poussée. Dans ce processus, à mesure que nous étendrons la conduite autonome aux robots spatiaux ou à d'autres domaines intégrés, nous pourrions développer des capacités de généralisation plus fortes ou des capacités de coordination plus complètes. Après la mise en œuvre, nous migrerons progressivement vers les moments ChatGPT à mesure que « les données utilisateur s'accumulent, que les scénarios s'enrichissent, que la réflexion gagne en logique et que les interactions vocales se multiplient ».
Comme l'a dit le Dr Lang Bo (Dr Lang Xianpeng), si nous atteignons 1 000 MPI d'ici l'année prochaine, cela pourrait donner aux utilisateurs le sentiment que nous avons véritablement atteint un « moment GPT » pour VLA.
#Bienvenue pour suivre le compte public officiel WeChat d'iFaner : iFaner (ID WeChat : ifanr), où du contenu plus passionnant vous sera présenté dès que possible.