
Index de base de données : une introduction pour les débutants
« Index de base de données » fait référence à un type spécial de structure de données qui accélère la récupération d'enregistrements à partir d'une table de base de données. Les index de base de données vous permettent de localiser et d'accéder efficacement aux données d'une table de base de données sans avoir à rechercher chaque ligne à chaque fois qu'une requête de base de données est traitée.
Un index de base de données peut être assimilé à l'index d'un livre. Les index dans les bases de données vous dirigent vers l'enregistrement que vous recherchez dans la base de données, tout comme la page d'index d'un livre vous pointe vers le sujet ou le chapitre souhaité.
Cependant, bien que les index de base de données soient essentiels pour une recherche et un accès aux données rapides et efficaces, ils occupent des écritures et un espace mémoire supplémentaires.
Qu'est-ce qu'un indice ?
Les index de base de données sont des tables de recherche spéciales constituées de deux colonnes. La première colonne est la clé de recherche et la seconde est le pointeur de données. Les clés sont les valeurs que vous souhaitez rechercher et récupérer dans votre table de base de données, et le pointeur ou la référence stocke l'adresse du bloc de disque dans la base de données pour cette clé de recherche spécifique. Les champs clés sont triés de manière à accélérer l'opération de récupération des données pour toutes vos requêtes.
Pourquoi utiliser l'indexation de base de données ?
Je vais vous montrer les index de base de données de manière simplifiée ici. Supposons que vous ayez une table de base de données des huit employés travaillant dans une entreprise et que vous souhaitiez rechercher les informations pour la dernière entrée de la table. Maintenant, pour trouver l'entrée précédente, vous devez rechercher chaque ligne de la base de données.
Cependant, supposons que vous ayez trié le tableau par ordre alphabétique en fonction du prénom des employés. Ainsi, ici, les clés d'indexation sont basées sur la "colonne de nom". Dans ce cas, si vous recherchez la dernière entrée, « Zack », vous pouvez sauter au milieu du tableau et décider si notre entrée vient avant ou après la colonne.
Comme vous le savez, cela viendra après la rangée du milieu, et vous pouvez à nouveau diviser les rangées après la rangée du milieu en deux et faire une comparaison similaire. De cette façon, vous n'avez pas besoin de parcourir chaque ligne pour trouver la dernière entrée.
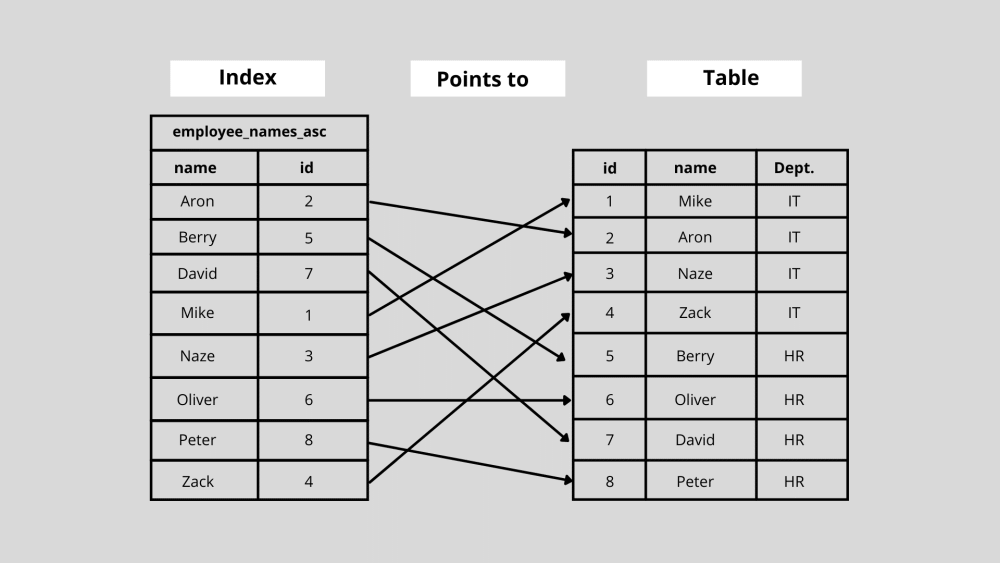
Si l'entreprise comptait 1 000 000 d'employés et que la dernière entrée était « Zack », vous devrez rechercher 50 000 lignes pour trouver son nom. Alors qu'avec l'indexation alphabétique, vous pouvez le faire en quelques étapes. Vous pouvez maintenant imaginer à quel point la recherche et l'accès aux données peuvent devenir plus rapides avec l'indexation des bases de données.
Différentes méthodes d'organisation des fichiers pour les index de base de données
L'indexation dépend fortement du mécanisme d'organisation des fichiers utilisé. En règle générale, il existe deux types de méthodes d'organisation de fichiers utilisées dans l'indexation de base de données pour stocker des données. Ils sont discutés ci-dessous :
1. Fichier d'index ordonné : Il s'agit de la méthode traditionnelle de stockage des données d'index. Dans cette méthode, les valeurs de clé sont triées dans un ordre particulier. Les données d'un fichier d'index ordonné peuvent être stockées de deux manières.
- Index clairsemé : Dans ce type d'indexation, une entrée d'index est créée pour chaque enregistrement.
- Index dense : dans l'indexation dense, une entrée d'index est créée pour certains enregistrements. Pour rechercher un enregistrement dans cette méthode, vous devez d'abord rechercher la valeur de clé de recherche la plus significative à partir des entrées d'index qui sont inférieures ou égales à la valeur de clé de recherche que vous recherchez.
2. Organisation du fichier de hachage : dans cette méthode d'organisation des fichiers, une fonction de hachage détermine l'emplacement ou le bloc de disque où un enregistrement est stocké.
Types d'indexation de base de données
Il existe généralement trois méthodes d'indexation de base de données. Elles sont:
- Indexation en cluster
- Indexation non clusterisée
- Indexation multi-niveaux
1. Indexation en cluster
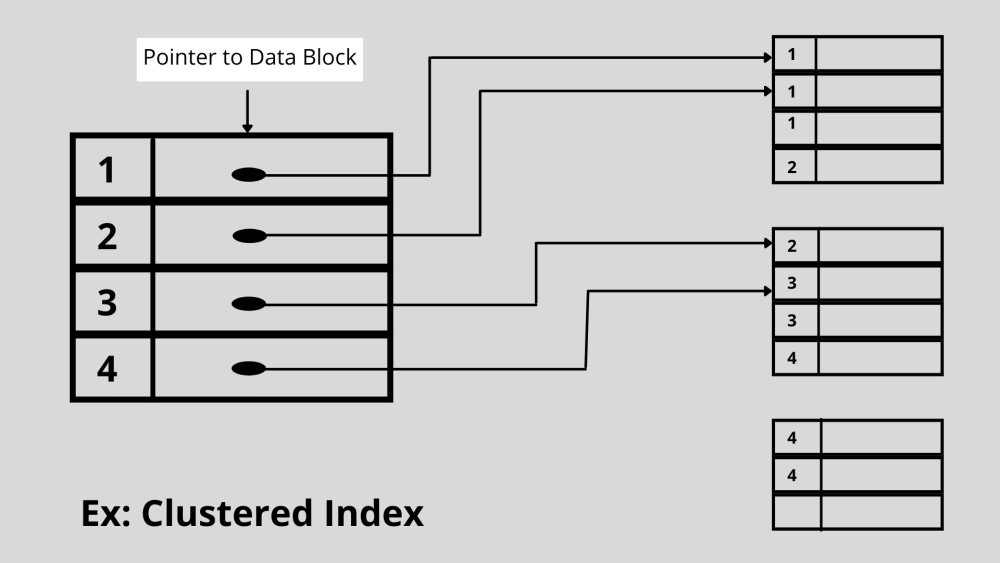
Dans l'indexation en cluster, un seul fichier peut stocker plus de deux enregistrements de données. Le système conserve les données réelles dans l'indexation en cluster plutôt que les pointeurs. La recherche est rentable avec l'indexation en cluster car elle stocke toutes les données associées au même endroit.
Un index de clustering utilise des fichiers de données ordonnés pour se définir. De plus, la jointure de plusieurs tables de base de données est très courante avec ce type d'indexation.
Il est également possible de créer un index basé sur des colonnes non primaires qui ne sont pas uniques pour chaque clé. Dans de telles occasions, il combine plusieurs colonnes pour former les valeurs de clé uniques pour les index clusterisés.
Ainsi, en bref, les index de clustering sont l'endroit où des types de données similaires sont regroupés et des index sont créés pour eux.
Exemple : Supposons qu'il existe une entreprise qui compte plus de 1 000 employés dans 10 départements différents. Dans ce cas, l'entreprise doit créer une indexation de clustering dans son SGBD pour indexer les employés qui travaillent dans le même service.
Chaque cluster avec des employés travaillant dans le même service sera défini comme un seul cluster, et les pointeurs de données dans les index feront référence au cluster comme une entité entière.
2. Indexation non groupée
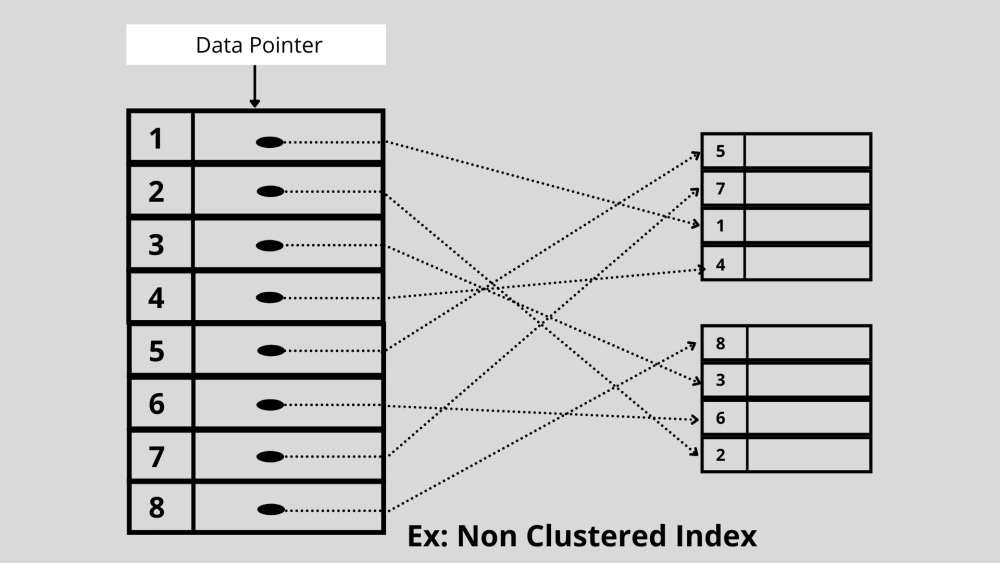
L'indexation non cluster fait référence à un type d'indexation dans lequel l'ordre des lignes d'index n'est pas le même que la façon dont les données d'origine sont physiquement stockées. Au lieu de cela, un index non cluster pointe vers le stockage de données dans la base de données.
Exemple : l' indexation non-cluster est similaire à un livre qui a une page de contenu ordonnée. Ici, le pointeur de données ou la référence est la page de contenu ordonnée qui est triée par ordre alphabétique, et les données réelles sont les informations sur les pages du livre. La page de contenu ne stocke pas les informations sur les pages du livre dans leur ordre.
3. Indexation multi-niveaux
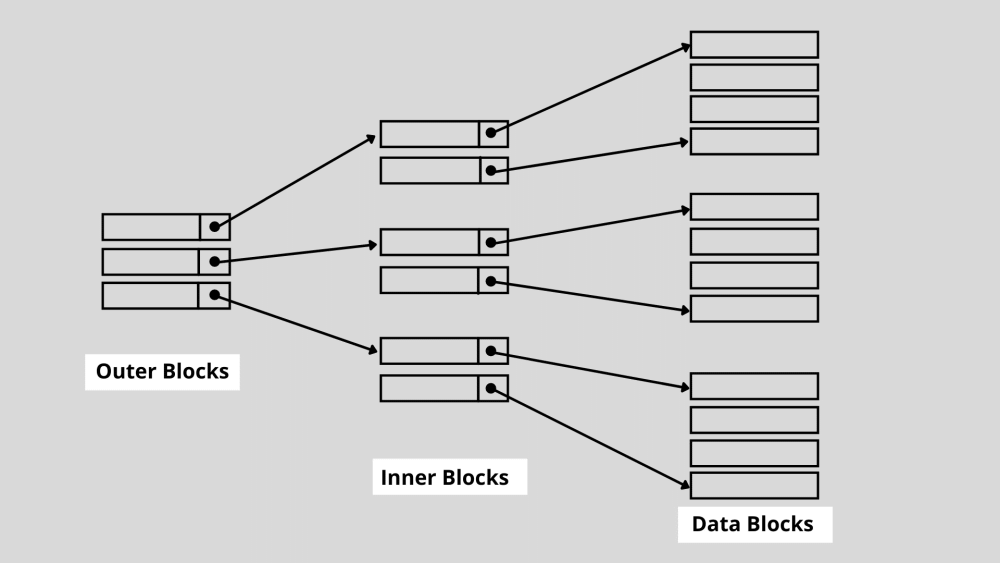
L'indexation à plusieurs niveaux est utilisée lorsque le nombre d'index est très élevé et qu'elle ne peut pas stocker l'index primaire dans la mémoire principale. Comme vous le savez peut-être, les index de base de données comprennent des clés de recherche et des pointeurs de données. Lorsque la taille de la base de données augmente, le nombre d'index augmente également.
Cependant, pour assurer une opération de recherche rapide, les enregistrements d'index doivent être conservés dans la mémoire. Si un index à un seul niveau est utilisé lorsque le numéro d'index est élevé, il est peu probable qu'il stocke cet index en mémoire en raison de sa taille et de ses accès multiples.
C'est là qu'intervient l'indexation multi-niveaux. Cette technique divise l'index à un niveau en plusieurs blocs plus petits. Après s'être cassé, le bloc de niveau externe devient si petit qu'il peut facilement être stocké dans la mémoire principale.
Qu'est-ce que la fragmentation d'index SQL ?
Lorsqu'un ordre des pages d'index ne correspond pas à l'ordre physique dans le fichier de données, la fragmentation de l'index SQL se produit. Initialement, tous les index SQL résident sans fragmentation, mais lorsque vous utilisez la base de données (Insérer/Supprimer/Modifier des données) à plusieurs reprises, cela peut provoquer une fragmentation.
Outre la fragmentation de la base de données, votre base de données peut également faire face à d'autres problèmes vitaux comme la corruption de la base de données. Cela peut entraîner une perte de données et un site Web endommagé. Si vous faites affaire avec votre site Web, cela peut être un coup fatal pour vous.