
La recherche IA pollue déjà Internet

Laissez les utilisateurs manger des pierres et mettre de la colle sur la pizza, et le renversement de la recherche Google AI est toujours au coin de la rue.
Perplexity, qui prétendait être subversif pour Google, a rencontré des problèmes juste après.
Par rapport à ChatGPT, la recherche IA peut se connecter à Internet, citer des sources et il est moins facile de dire des bêtises.
Mais que se passe-t-il si la source elle-même est un déchet ?
Recherche AI, faisant déjà référence à une autre recherche AI
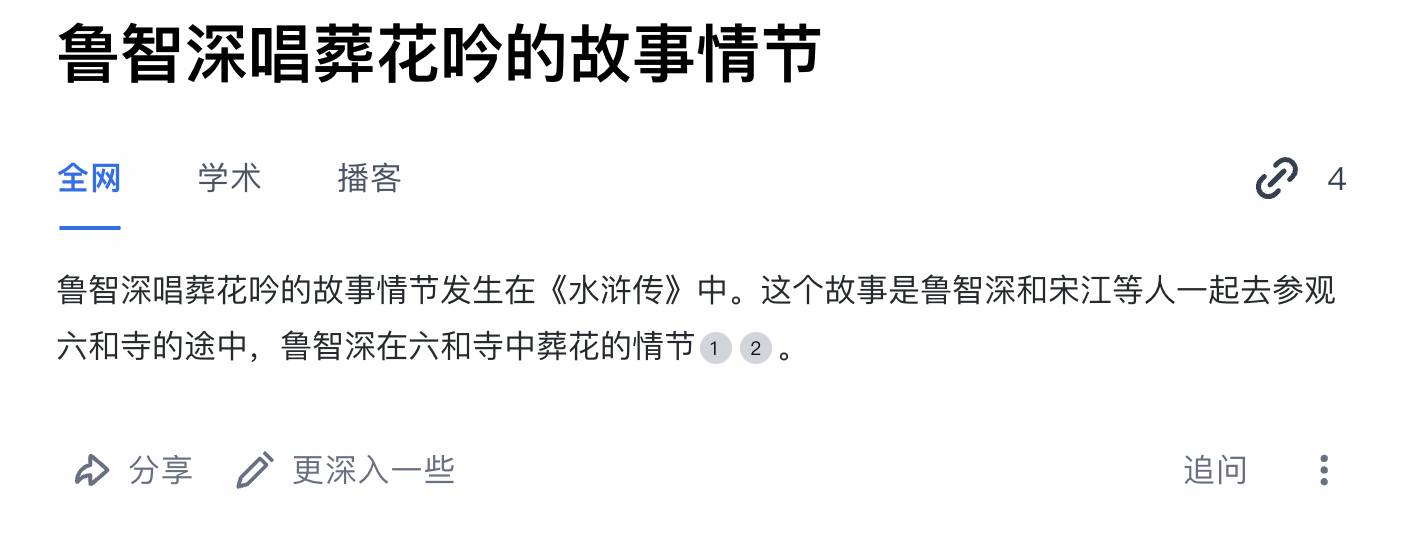
Beaucoup de gens ont entendu la blague sur "Lin Daiyu déracinant le saule pleureur". J'étais récemment en train de revoir Water Margin, et j'ai eu une idée et j'ai demandé à Perplexity en chinois : "Quelles sont les similitudes entre le personnage de Lin Daiyu et celui de Lu Zhishen ?"
La réponse était banale, mais un personnage inattendu est apparu dans la source citée : Byte Doubao, l'assistant IA appartenant à Douyin.
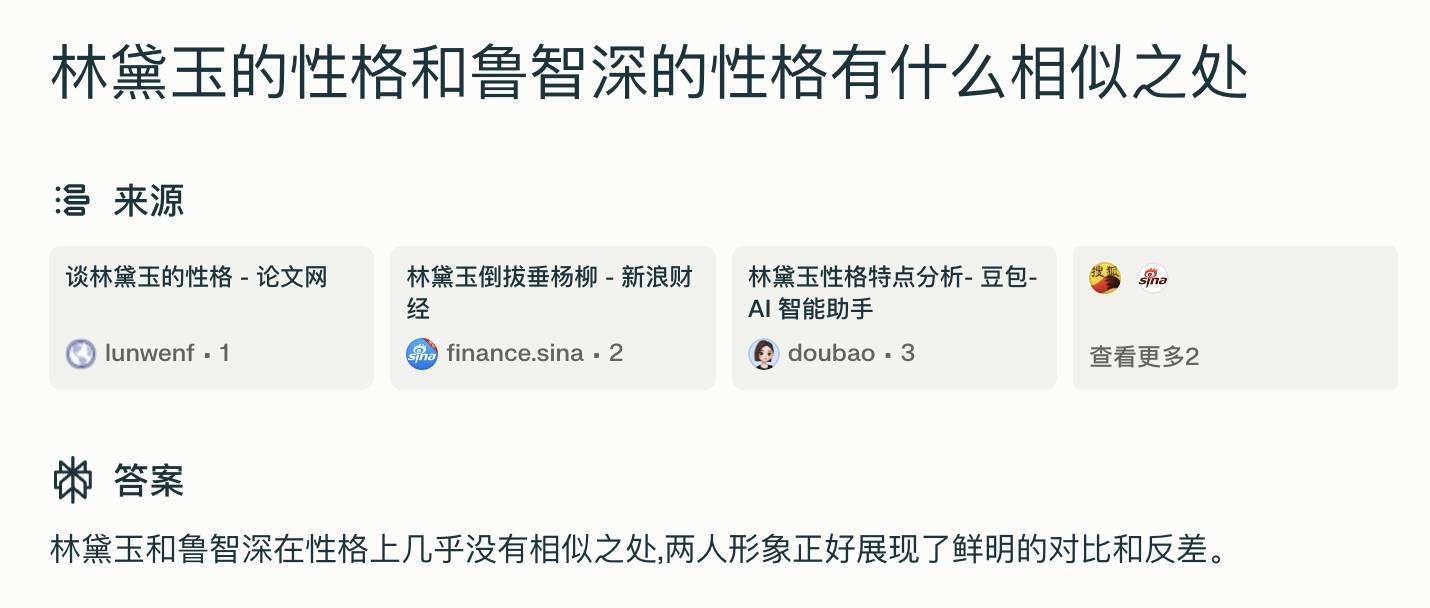
Est-ce une nouvelle forme de guerre commerciale ? Lorsque j'ai cliqué dessus, j'ai découvert que le contenu était l'historique des discussions entre l'utilisateur et Doubao, et que les réponses de l'IA étaient très efficaces contre les stéréotypes. Si la qualité est meilleure que le compte marketing, c'est tout. Écrire ainsi est un péché supplémentaire.
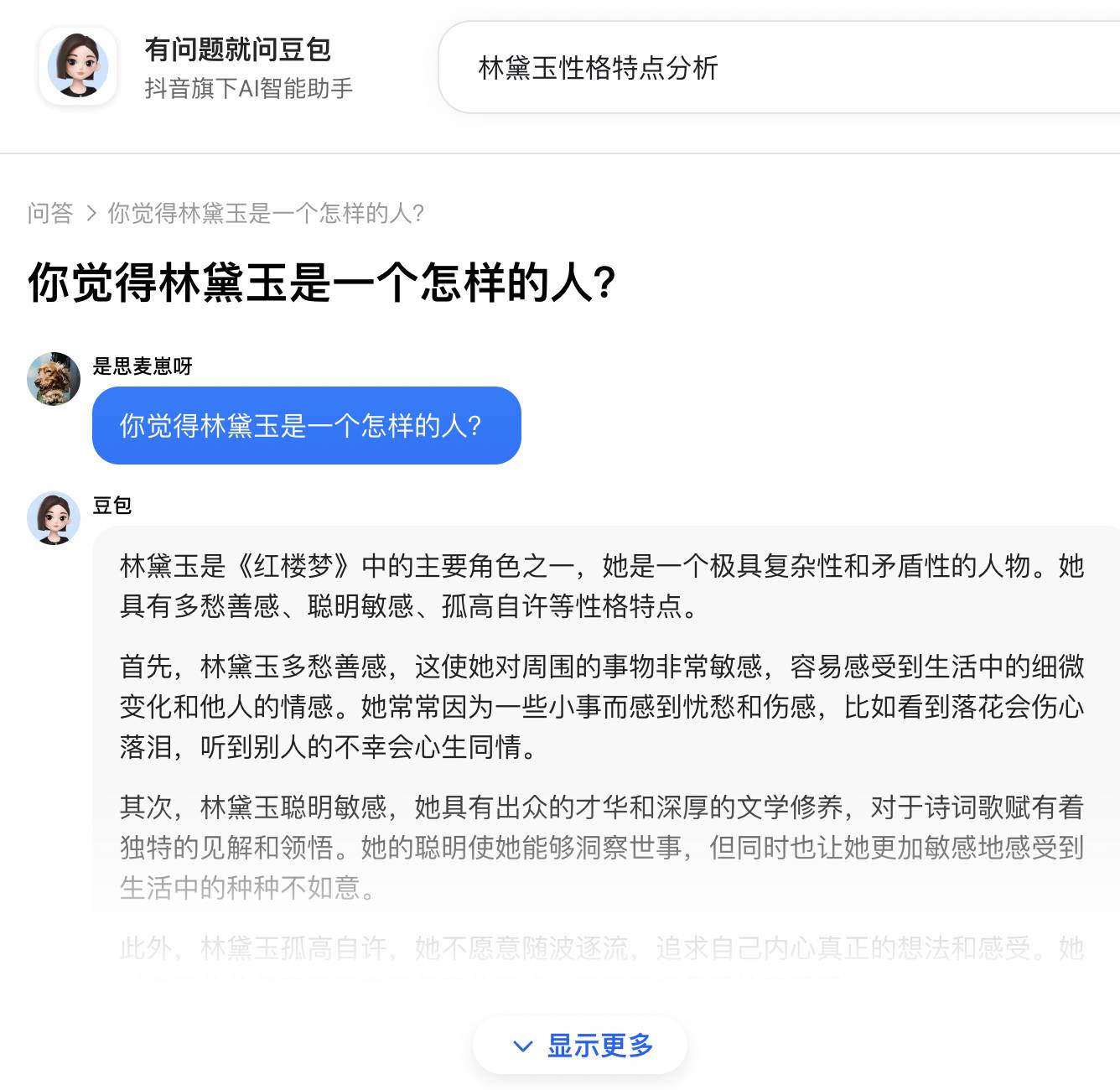
Lorsque j'ai directement recherché la même question sur Google, Doubao est revenu pour augmenter sa présence, et s'est classé deuxième. Ce n'était pas la même citation que Perplexity, mais quand j'ai cliqué dessus, c'était quand même une série d'absurdités commençant par "premier". " et deuxièmement".
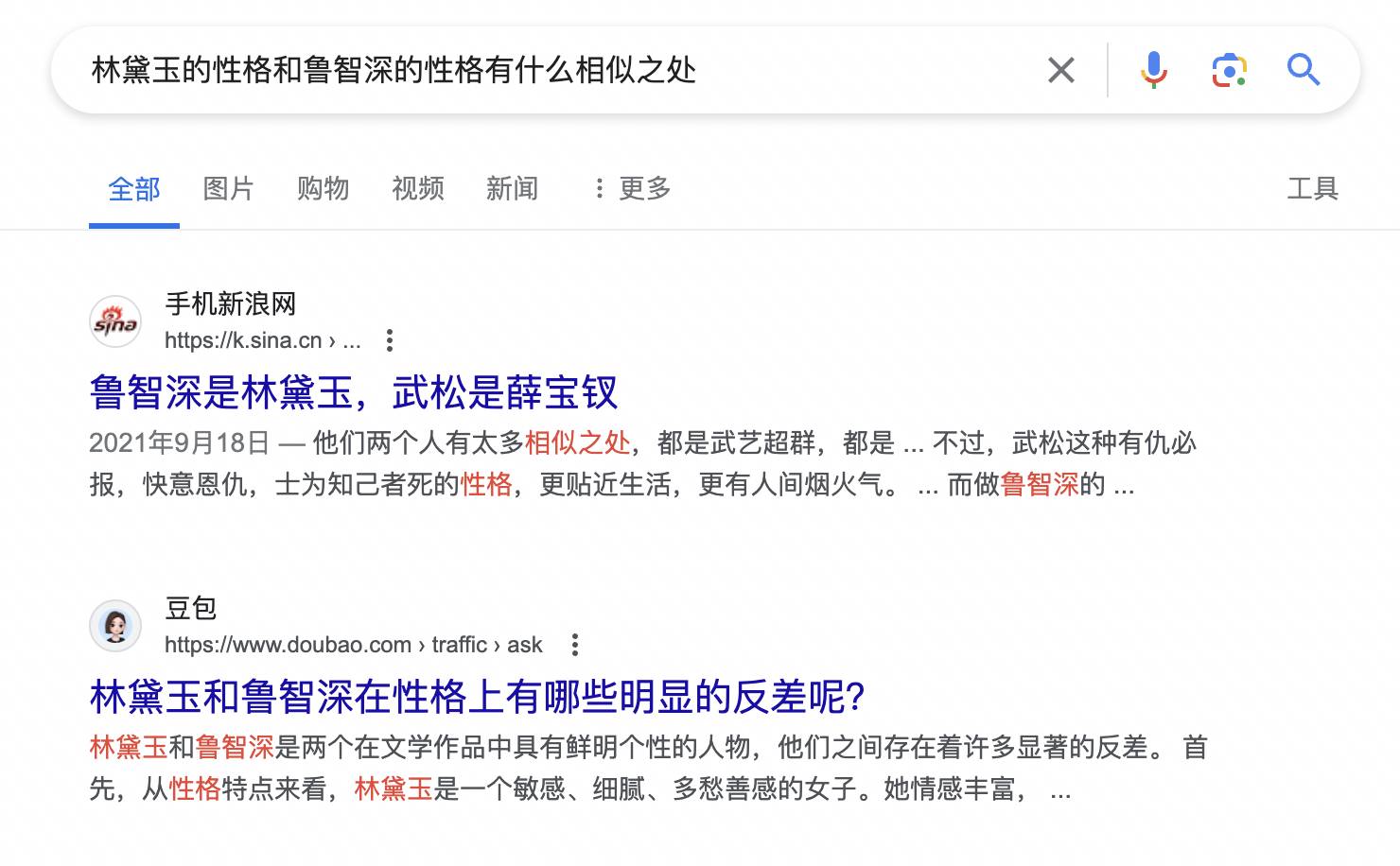
Comme indiqué précédemment par The Information, Perplexity utilise des API pour accéder aux données sur les classements de recherche Bing et Google, qui déterminent la pertinence, la qualité et l'autorité des pages Web.
En d’autres termes, si Beanbao est facile à rechercher sur Google, il peut être plus facile d’être cité par Perplexity. Cela rend les gens curieux : pourquoi les poufs peuvent-ils apparaître dans les moteurs de recherche ?
Lorsque je me suis connecté à la dernière version de la version Web de Doubao, la réponse est apparue. Elle cochait une option par défaut : autoriser l'inclusion du contenu partagé par les moteurs de recherche et son affichage sur la page de résultats de recherche.
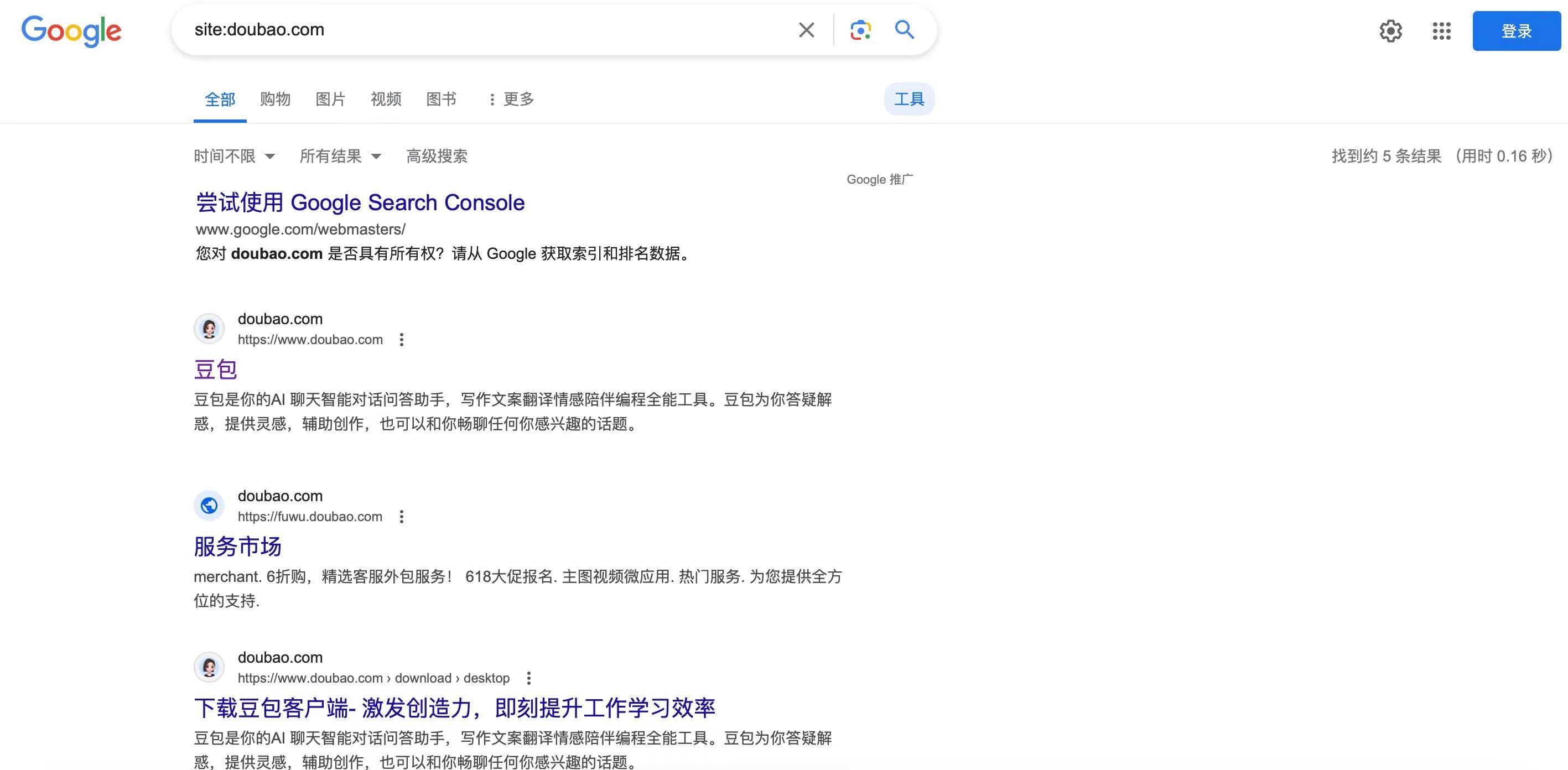
L'expérience ci-dessus a eu lieu le 31 mai à 14h. Le 1er juin à 19h00, Byte a répondu à Aifaner, affirmant que Doubao avait été mis à jour et que le contenu était partagé avec les moteurs de recherche. Il n'est pas vérifié par défaut, mais l'utilisateur choisit activement d'être exploré par les moteurs de recherche.
Dans le même temps, Byte a déclaré que certains contenus de questions-réponses recherchés et inclus étaient en fait du contenu de questions-réponses de haute qualité créé par une personne utilisant un compte virtuel, et non par un utilisateur réel. Il a été nettoyé maintenant. Lors d'une recherche sur Google, il n'y a que 5 résultats sur le site.
Doubao semble avoir créé un précédent en permettant l'indexation des enregistrements de discussions entre les utilisateurs et l'IA. Perplexity, Tiangong, Secret Tower et 360 AI peuvent tous partager l'historique des discussions sous forme de lien, mais il n'existe pas d'option similaire à Beanbao.
ChatGPT prend également en charge le partage de conversations avec des liens, mais promet qu'il ne sera utilisé que pour le partage entre individus et n'apparaîtra pas dans les résultats de recherche publics sur Internet.

Dans les premières années, les « fermes de contenu » volaient ou rassemblaient les articles d'autres personnes pour produire rapidement du contenu. Elles s'appuyaient sur des stratégies de référencement (optimisation des moteurs de recherche) telles que l'optimisation des mots clés et des mises à jour fréquentes pour occuper la première ligne des pages de recherche et gagner du trafic et frais de publicité.
À cette époque, les contributeurs de contenu étaient encore de vraies personnes, produisant plusieurs articles chaque jour, mais c'est maintenant au tour de l'IA, et les capacités de combat de copier, coller, nettoyer et produire en série ne sont pas au même niveau.
"Lin Daiyu a déraciné les saules pleureurs" et "Lu Zhishen a chanté la chanson des fleurs enterrées" ne sont pas des faits. Plus les gens le disaient, plus cela avait de poids, et c'est devenu un fait aux yeux de la recherche d'IA. étaient Zhihu, Douyin, des histoires avec des nez et des yeux inventés par les utilisateurs de Jianshu.
Si la source d’information devient l’IA, les résultats n’en seront que plus tragiques. Imaginez que davantage de contenu généré par l'IA soit inclus dans Google, que les recherches d'IA fassent référence aux classements de recherche de Google, et que ce qui soit finalement présenté aux utilisateurs, ce soient les résultats indésirables de l'IA superposés à l'IA.
Les êtres humains nourris ne peuvent que devenir plus perspicaces et distinguer les informations utiles des absurdités.
Recherche IA en 80 points
Pour être honnête, j'aime toujours les produits de recherche d'IA tels que Perplexity. Ils ont encore une fois amélioré ma productivité après ChatGPT.
Les humains posent des questions, les recherchent, les résument et les documentent. Il s'agit d'un flux de travail déjà mature. Nous payons moins mais sommes plus efficaces.
Dans la plupart des cas, les performances de la recherche IA sont plutôt bonnes. Une partie de la raison pour laquelle l'IA de Google a été annulée était qu'elle était impatiente de lancer des fonctionnalités et se concentrait uniquement sur l'augmentation du poids de Reddit dans les recherches, sans permettre à l'IA de réfléchir à la cohérence des résultats avec le bon sens.
Lorsque j'ai saisi le même problème qui a provoqué l'échec de la recherche Google AI dans Perplexity, les résultats étaient plus satisfaisants.
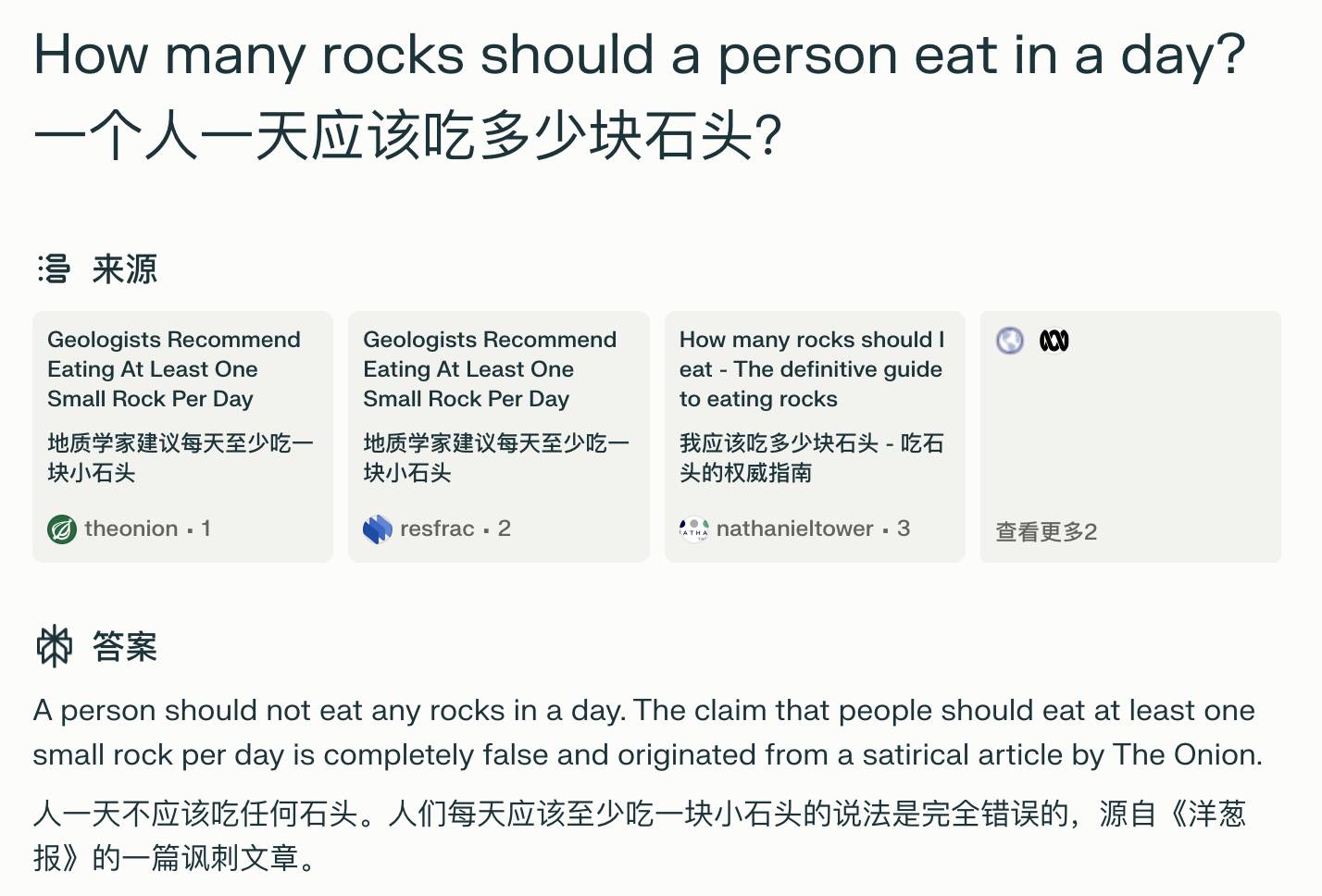
Concernant « combien de pierres les gens mangent-ils par jour ? », Perplexity peut trouver avec précision la source d'Onion News et expliquer que cela n'a aucun sens, contrairement à la recherche Google AI qui traite Onion News comme un standard.
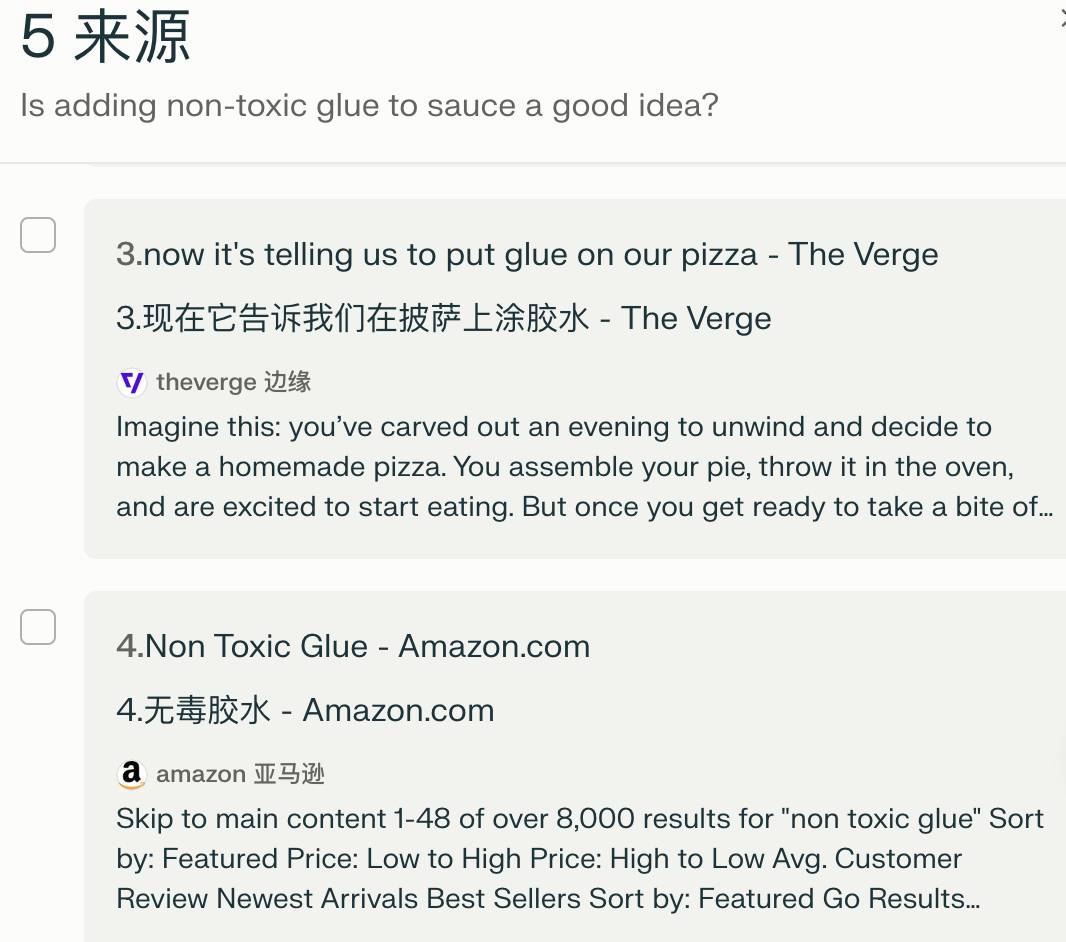
Il y a aussi "Que dois-je faire si le fromage à pizza glisse facilement?" Google AI a suggéré d'ajouter de la colle avant de chercher. Perplexity était évidemment plus intelligent et a d'abord donné quelques méthodes raisonnables. Après avoir demandé si de la colle pouvait être ajoutée, j'ai trouvé avec précision ce qui était trompeur. Recherche Google AI. Post Reddit, disant que c'était une blague.
Afin de rendre les résultats plus rigoureux, Perplexity s'est même rendu sur Amazon pour effectuer une recherche, affirmant qu'il n'avait trouvé qu'une variété de produits de colle non toxiques et n'a pas dit que ces colles pouvaient être utilisées pour l'alimentation.
Par rapport à Perplexity, Google n'est évidemment pas inférieur en termes de capacités de modèle, mais en termes d'ingénierie et de production ultérieures.
En principe, la recherche par IA consiste d'abord à rechercher puis à résumer. Par rapport aux robots de discussion qui ne sont pas connectés à Internet, il y a moins d'illusions. L'une des technologies de base est RAG (Retrieval Augmentation Generation).
RAG combine la recherche d'informations et les modèles génératifs. La recherche d'informations trouve des informations pertinentes à partir d'une vaste bibliothèque de documents basée sur les requêtes des utilisateurs ; les modèles génératifs utilisent ces documents récupérés comme contexte pour générer des réponses plus précises et détaillées.
La bibliothèque de documents ici peut être la bibliothèque d'index d'un moteur de recherche traditionnel, ou il peut s'agir d'une base de données propriétaire telle que la loi, ou de contenu généré par l'utilisateur tel que les médias sociaux.

Si une page Web est remplie de nombreux contenus générés par l’IA de mauvaise qualité, cela aura un impact négatif sur le RAG de la recherche par l’IA.
Ensuite, face au contenu agressif généré par l'IA, la seconde moitié de la recherche par l'IA pourrait consister à continuer à rivaliser avec les capacités d'ingénierie autres que les modèles, et à comparer la qualité des sources de données et des capacités de recherche, notamment si elle peut rechercher plus de pages Web et recherchez des pages Web faisant davantage autorité ou intégrez des informations exclusives telles que des rapports financiers.
La situation actuelle est que nous sommes progressivement devenus indissociables de la recherche par l'IA. Si la recherche traditionnelle basée sur des mots clés et l'ouverture manuelle des liens est de 40 points, le grand modèle facile à dire est de 60 points et la recherche par l'IA en réseau a a élevé la norme à 80 points. Même si vous ferez encore des erreurs, vous ne pourrez pas revenir en arrière après en avoir fait l'expérience, vous n'êtes donc pas obligé de le nier complètement.
Citant des sources de diverses manières, la guerre commerciale de la recherche par IA
En plus des pages Web courantes, les produits de recherche d’IA semblent avoir la même idée : fournir des sources d’informations multimodales.
360 AI peut trouver des vidéos, Secret Tower peut trouver des podcasts et des articles universitaires, et Perplexity peut rechercher Reddit et YouTube.
Mais la recherche IA consiste davantage à fournir une introduction. Si vous souhaitez un contenu plus détaillé, vous ne pouvez toujours pas être paresseux et aller à la source de l’information.

Dans le même temps, il existe un autre phénomène intéressant. Les applications lancent des fonctions de recherche intégrées sur l’IA, telles que le « Sousousu » de Xiaohongshu lors des tests internes et le « AI Question Book » de WeChat Reading pour explorer l’IA dans l’écosystème existant. En ce sens, ce sont également des produits de recherche IA.
▲ Photo de : Xiaohongshu@三水水
L'application Tencent Yuanbao, lancée il y a 2 jours, est basée sur le grand modèle Hunyuan et intègre des fonctions telles que la recherche AI, le résumé AI et l'écriture AI. Elle était encore plus prometteuse dès le début.
Parce qu'il dispose de ressources telles que la plateforme de compte public WeChat et la plateforme Tencent News, et que le compte public est une collection de contenu de haute qualité sur l'Internet chinois.
Par exemple, si vous saisissez un titre et recherchez un article de compte public spécifique, Tencent Yuanbao peut donner un meilleur résumé et recommander davantage d'articles de compte public. Au contraire, une IA telle que Doubao capture les canaux de distribution du contenu de compte public, et le résumé est relativement omis.
Combiné avec le fonctionnement de Doubao pour afficher le contenu de l'IA sur la page des résultats de recherche, il semble que nous ayons encore une fois rappelé la distribution de contenu de l'Internet mobile.
À l’ère de l’Internet mobile, contrairement à l’ère précédente des portails, les applications sont isolées les unes des autres et difficiles à explorer par les moteurs de recherche. Par exemple, si vous saisissez le titre d'un article de compte public, le moteur de recherche ne peut pas trouver le texte original et ne peut voir que le canal de distribution.
Dans le même temps, sur les moteurs de recherche traditionnels, il existe de nombreuses distractions telles que des publicités, et il y a aussi beaucoup de contenu de compte marketing de mauvaise qualité. Nous nous y sommes progressivement habitués. Pour les didacticiels système, rendez-vous à la Station B. posez des questions sur des sujets insignifiants de la vie quotidienne, utilisez Xiaohongshu et recherchez des articles sur WeChat.

Avec de plus en plus de produits de recherche IA et de contenus générés par l'IA, cette situation pourrait se reproduire à l'avenir : le contenu Web deviendra de plus en plus mixte, avec une augmentation de la quantité, tandis que le contenu de haute qualité restera fermé comme toujours, se transformant en une recherche IA verticale. fossé.
En plus des recherches d’IA multimodales vastes et complètes, de plus en plus d’excellentes recherches d’IA verticales pourraient émerger.
Par exemple, le moteur de recherche universitaire Consensus jouit d’une bonne réputation, de sources de haute qualité de plus de 200 millions d’articles et, combiné aux capacités d’analyse basées sur l’IA, la réponse citera toujours une certaine étude.
Demandez au consensus « L'exercice peut-il améliorer les capacités cognitives ? » Il ne s'est pas précipité pour tirer des conclusions, il a plutôt rédigé un résumé et présenté un tableau, au lieu d'y répondre comme une simple question de « si ».

Nous attendons de la recherche IA qu’elle fournisse plus rapidement un contenu meilleur, plus diversifié, plus visuel et plus personnalisé et qu’elle réponde à des questions plus complexes et spécifiques au cours du processus interactif de communication en langage humain.
Cependant, dans le même temps, le contenu et l’écologie de la recherche sont également détruits par l’IA, ce qui semble être une métaphore des deux côtés de l’IA.
À l’avenir, il y aura certainement de plus en plus de contenus générés par l’IA. Au milieu de la tension entre le pour et le contre, la question de savoir s’il est plus difficile ou plus facile de trouver des informations plus utiles reste ouverte. Le rêve de l’utiliser n’est pas encore devenu réalité. Si nous utilisons l’IA comme un outil et exerçons notre propre initiative subjective, les humains ne seront pas facilement tristes et déçus.
# Bienvenue pour suivre le compte public officiel WeChat d'aifaner : aifaner (ID WeChat : ifanr). Un contenu plus passionnant vous sera fourni dès que possible.
Ai Faner | Lien original · Voir les commentaires · Sina Weibo