
L’art de l’avatar est là, Apple lance une nouvelle technologie d’IA pour créer votre « avatar numérique » en 30 minutes

Alors qu’un certain nombre de géants de la technologie se livrent une concurrence féroce dans le domaine de l’IA générative, Apple, de son côté, semble un peu silencieux.
Aujourd'hui, Apple a publié un document de recherche sur l'IA générative, qui nous montre rarement sa dernière avancée dans ce domaine.
Cet article détaille une technologie d’IA générative appelée HUGS (Human Gaussian Splats). Bref, grâce à la bénédiction de cette technologie, on peut même créer un « avatar numérique » humain à travers une courte vidéo.
Plus près de chez nous, regardons l’effet de démonstration spécifique

Selon les responsables d'Apple, bien que la technologie de rendu basée sur les réseaux neuronaux ait permis d'améliorer considérablement la formation et la vitesse de rendu au fil des ans, cette technologie se concentre principalement sur la photogrammétrie de scènes statiques et est difficile à appliquer aux modèles humains flexibles en mouvement.
Afin de résoudre ce problème, le Centre de recherche sur l'apprentissage automatique d'Apple et l'Institut Max Planck pour les systèmes intelligents ont collaboré pour proposer un cadre d'IA appelé HUGS. Après la formation, HUGS peut automatiquement se séparer des vidéos en 30 minutes. Un arrière-plan statique et un environnement numérique entièrement dynamique avatar.
Comment ça se fait exactement ?
Leur idée principale est d'utiliser la distribution gaussienne tridimensionnelle (3DGS) pour représenter les personnes et les scènes. Vous pouvez comprendre la distribution gaussienne (GS) comme un corps tridimensionnel paramétré en forme de cloche avec une position centrale, une taille de volume et un angle de rotation.
Si nous plaçons plusieurs de ces corps tridimensionnels en forme de cloche à différents endroits d’une pièce, ajustons leurs positions, tailles et angles, et les combinons ensemble, nous pouvons reconstruire la structure de la pièce et les personnages de la scène. La distribution gaussienne est très rapide à entraîner et à restituer, ce qui constitue le plus grand avantage de cette méthode.
Le prochain problème auquel nous sommes confrontés est que la distribution gaussienne elle-même est relativement simple et qu’il est difficile de simuler avec précision la structure complexe du corps humain simplement en les empilant.

Par conséquent, ils ont d’abord utilisé un modèle de corps humain appelé SMPL, qui est un modèle de forme de corps humain relativement simple et couramment utilisé qui fournit un point de départ pour une distribution gaussienne qui ancre la forme et la posture de base du corps humain.
Bien que le modèle SMPL fournisse la forme de base du corps humain, il n'est pas très précis dans la gestion de certains détails, tels que les plis des vêtements, les coiffures, etc., et la distribution gaussienne peut s'écarter et modifier le modèle SMPL dans une certaine mesure.
De cette façon, ils peuvent ajuster le modèle de manière plus flexible, mieux capturer et simuler ces détails et donner à l'avatar numérique final une apparence plus réaliste.

La séparation n'est que la première étape, il faut aussi faire bouger le modèle humain construit. À cette fin, ils ont conçu un réseau de déformation spécial pour apprendre à contrôler le poids de mouvement de chaque distribution gaussienne (représentant la forme du corps humain et de la scène) sous différentes poses squelettiques, appelé poids LBS.
Ces poids indiquent au système comment la distribution gaussienne doit changer lorsque le squelette humain bouge pour simuler un mouvement réel.
De plus, ils ont non seulement arrêté de concevoir le réseau, mais ont également optimisé la distribution gaussienne de l'avatar numérique, la distribution gaussienne de la scène et le réseau de déformation en observant de véritables vidéos de mouvements humains. De cette façon, l’avatar numérique peut mieux s’adapter aux différentes scènes et actions, ce qui lui donne un aspect plus réel.
Par rapport aux méthodes traditionnelles, la vitesse d'entraînement de cette méthode est considérablement améliorée, au moins 100 fois plus rapide, et elle peut également restituer une vidéo haute définition à 60 images par seconde.

Plus important encore, cette nouvelle méthode permet d'obtenir un processus de formation plus efficace et un coût de calcul inférieur, ne nécessitant parfois que 50 à 100 images de données vidéo, ce qui équivaut à 24 images de vidéo en seulement 2 à 4 secondes.
Concernant la sortie de cette réalisation, les attitudes des internautes ont montré une tendance polarisée.
Le blogueur numérique @mmmryo s'est émerveillé devant la modélisation de la peau, des vêtements, des cheveux et d'autres détails par le modèle génératif, et a émis l'hypothèse que cette technologie serait probablement spécialement conçue pour l'iPhone ou le Vision Pro.
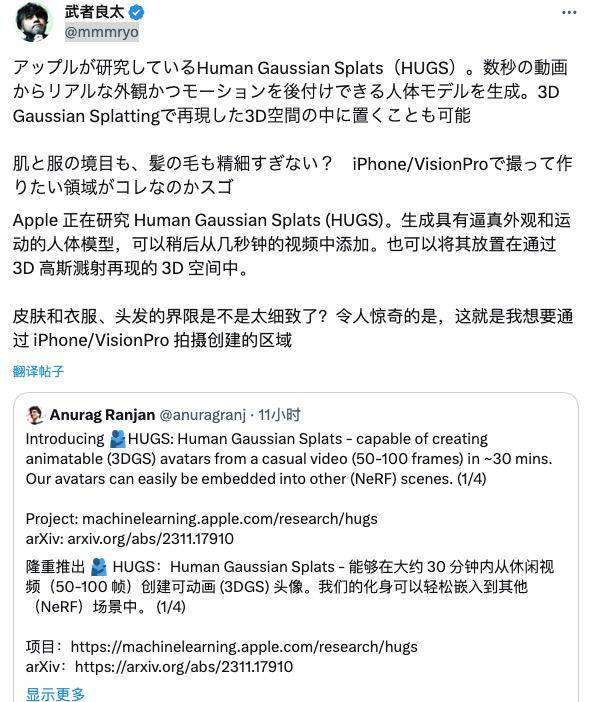
Le scientifique de Samsung, Kosta Derpani, est apparu dans la zone de commentaires du chercheur d'Apple Anurag Ranjan et a exprimé tous les éloges et l'affirmation de cette réalisation.

Cependant, certains internautes ne l'ont pas acheté. Par exemple, l'utilisateur X @EddyRobinson a remis en question l'effet réel généré.
Apple a annoncé qu'il publierait le code du modèle, mais au moment de mettre sous presse, cliquer sur le lien du code officiel fourni par Apple n'entraînera que "404".

Certains internautes ont lancé des discussions rationnelles :

Il convient de mentionner que l’auteur de cet article a un visage chinois familier.
L'auteur principal de l'article, Jen-Hao Rick Chang, est originaire de Taiwan, en Chine. Avant de rejoindre Apple en 2020, il a obtenu son doctorat au département ECE de l'Université Carnegie Mellon.
La carrière universitaire de Zhang Renhao est assez légendaire : à l'Université Carnegie Mellon, il a étudié auprès du professeur Vijayakumar Bhagavatula et du professeur Aswin Sankaranarayanan, tous deux maîtres dans le domaine du traitement d'images.

Après s'être consacré au domaine de l'apprentissage automatique pendant les trois premières années, par intérêt pour la recherche, Zhang Renhao a résolument changé d'orientation de recherche et a commencé à se plonger dans des domaines complètement différents de l'optique. Depuis lors, il a successivement travaillé chez SIGGRAPH dans le domaine de l'infographie et de la technologie interactive, ainsi que dans le domaine de l'apprentissage automatique ICML International. A publié de nombreux chefs-d'œuvre lors de conférences universitaires.
Cet article d'Apple est le dernier résultat de recherche qu'il a co-écrit. Enfin, l'adresse spécifique de l'article est indiquée. Des détails plus spécifiques peuvent être trouvés sur le lien ci-dessous. 
https://arxiv.org/abs/2311.17910
Il faut dire que le thème de la génération vidéo IA de cette année est tout simplement inhumain. L'émergence de Runway a introduit l'IA générative dans les salles sacrées du cinéma. "L'univers instantané" soutenu par la technologie Runway démontre la magie de la génération vidéo IA. vivement.

Ensuite, Pika 1.0 de Pika Lab a repris le « brevet » de la génération vidéo IA des mains des créateurs professionnels. Grâce à une saisie de texte plus simple, un montage vidéo facile à comprendre et une génération vidéo de meilleure qualité, chacun a la possibilité de devenir son propre réalisateur vidéo.
Que vous soyez professionnel ou amateur, vous pouvez également utiliser le générateur d'animation humaine MagicAnimate pour vous divertir. Saisissez simplement des photos de personnes selon des séquences d'action prédéterminées pour générer des vidéos dynamiques.
Le protagoniste en mouvement peut être votre selfie, votre animal de compagnie ou un tableau célèbre et familier. Tout peut être déplacé en utilisant votre imagination.

Bien sûr, ce qui est peut-être plus accrocheur est le modèle de génération vidéo VideoPoet lancé aujourd'hui par l'équipe Google, qui prend en charge diverses fonctions de génération vidéo et de génération audio, et peut même permettre à de grands modèles de guider la génération vidéo complète.
Non seulement il peut générer des vidéos de 10 secondes à la fois, mais VideoPoet peut également résoudre le problème actuel de l'incapacité de générer des vidéos avec de grands mouvements. C'est un outil polyvalent dans le domaine de la génération vidéo. Le seul inconvénient est peut-être que il "vit" sur le blog de Google.

Relativement parlant, la dernière réalisation d'Apple vise la technologie populaire actuelle similaire aux ancres d'IA. Une courte vidéo qui peut prendre moins de quelques secondes peut générer votre "avatar numérique". Voir n'est peut-être pas croire. Comment pouvons-nous le prouver à l'avenir ce « je, c'est moi » vaut peut-être la peine de s'inquiéter à nouveau.
Vision Pro sortira aux États-Unis l'année prochaine, et les résultats de recherche de cet article sont probablement un œuf de Pâques enterré d'avance.
# Bienvenue pour suivre le compte public officiel WeChat d'aifaner : aifaner (ID WeChat : ifanr). Un contenu plus passionnant vous sera fourni dès que possible.
Ai Faner | Lien original · Voir les commentaires · Sina Weibo