
Le code de vérification anti-humain aurait dû être tué il y a longtemps

"Je ne suis pas un robot" devrait aller de soi.
Mais avant que l'ordinateur ne reconnaisse que vous êtes humain, il vous sera peut-être demandé de cliquer sur des images contenant des feux de circulation ou des trottoirs.
Lorsque vous plissez les yeux près de l'écran, en vous demandant si un petit coin compte, vous savez que ce n'est pas si simple.
Ce genre de sensation difficile à prouver à soi-même, le voyageur de la Fête du Printemps qui s'est procuré des billets en 12306 en 2015 devrait y goûter.
Des années plus tard, le captcha en constante évolution vous oblige toujours à réfléchir à la question philosophique séculaire – qui suis-je ?
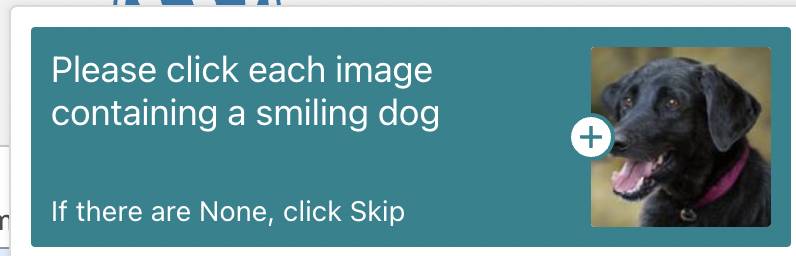
Un chien souriant, un cheval fait de nuages, c'est plus dur de prouver qu'on est un être humain
"Veuillez cliquer sur chaque image contenant un chien souriant."
Jared Bauman, fondateur d'une agence de marketing créatif, a récemment été déconcerté par CAPTCHA . Ce qu'il se demande, c'est si les chiens peuvent vraiment rire ? La plupart des chiens n'avaient l'air ni heureux ni tristes, certains grimaçants, d'autres bouche bée.
Le 2 août, on lui a demandé de trouver un "cheval fait de nuages" . Parmi les 9 photos, il y avait 2 éléphants faits de nuages. Il a malheureusement perdu le premier clic.

Jared Bauman s'est rendu compte d'un problème sérieux – trouver un feu de circulation, un bus ou une cheminée était obsolète, et le système de captcha s'est mis à définir le prochain niveau de défi.
Les captchas proviennent de hCaptcha, qui, selon les développeurs, est plus soucieux de la confidentialité que le système de captcha de Google, reCAPTCHA, ne collectant que le minimum de données personnelles nécessaires.
Et pourquoi le code de vérification devient de plus en plus difficile, nous devons encore commencer par ce qu'est le code de vérification et ce qu'est le système de code de vérification reCAPTCHA de Google.

CAPTCHA, le nom complet est "Distinguer automatiquement l'ordinateur et le test de Turing public humain".
Captcha est également considéré comme un test de Turing inversé car il utilise des ordinateurs pour tester les humains, et non les humains comme dans le test de Turing standard .
Captcha est conçu pour protéger les sites Web contre les robots nuisibles , y compris la diffusion de logiciels malveillants, la diffusion de faux comptes, la réalisation d'attaques DDoS, l'envoi de spam en masse, le vol d'informations sur les utilisateurs, etc. Ces robots sont essentiellement des lignes de code informatique qui s'exécutent automatiquement.
Captcha a été créé au début des années 2000 par quelques informaticiens de l'université Carnegie Mellon.
Le CAPTCHA original a pris la forme d'un texte déformé pour éviter la reconnaissance automatique par des programmes informatiques tels que la reconnaissance optique de caractères, plus que ce qui pouvait être déchiffré par les ordinateurs à l'époque, mais lisible par la plupart des humains.

Bientôt, les chercheurs ont réalisé que la technologie avait le potentiel de différencier les humains des robots, et ils ont développé la technologie reCAPTCHA qui permet aux utilisateurs de numériser des profils papier lorsqu'ils remplissent des codes captcha que les humains peuvent déchiffrer mieux que les ordinateurs Lettres tordues de la littérature ancienne.
A ce stade, l'utilisateur doit saisir deux mots, un vrai test avec une réponse claire, et un nouveau mot qui n'a pas encore été transcrit . En montrant le même mot plusieurs fois aux utilisateurs du monde entier, reCAPTCHA vérifie automatiquement que le mot a été correctement transcrit.

C'est comme un crowdfunding sur internet, demandant votre temps au lieu de votre argent. C'est la magie d'Internet. Avec le soutien de la technologie, pour créer du plaisir, vous pouvez utiliser un peu d'énergie de chacun pour vous rassembler naturellement dans une tour.
En 2009, Google a acquis reCAPTCHA et l'a utilisé pour numériser Google Books et les archives du New York Times. En 2011, Recaptcha avait numérisé l'intégralité des archives de Google Books, soit 13 millions d'articles du New York Times. En 2012, il traduisait environ 150 millions de mots par jour.
Pourquoi le code de vérification est-il de plus en plus difficile ?
Les humains sont plongés dans l'océan du savoir et les robots n'ont pas cessé d'apprendre.
En 2014, Google a publié un algorithme dédié au déchiffrement du captcha de texte déformé, et la technologie de l'intelligence artificielle a été capable de résoudre le texte déformé le plus difficile avec une précision de 99,8 % , alors que le taux de réussite humaine est de 33 %.
Les lettres tordues ont perdu leur objectif initial, et il est temps pour la prochaine génération de captcha.
En 2012, Google a lancé une version de reconnaissance d'image de reCAPTCHA qui comprenait des photos de Google Street View, permettant aux utilisateurs de transcrire des numéros de maison et d'autres signes.

Semblable à la numérisation de vieux livres au début, dans ce processus, Google a servi à plusieurs fins, non seulement pour se défendre contre les scripts malveillants, mais aussi pour améliorer sa propre intelligence artificielle.
En 2014, Google a déclaré : "Les équipes Street View et reCAPTCHA travaillent en étroite collaboration, et les deux continueront à s'améliorer pour rendre les cartes plus précises et utiles, et reCAPTCHA plus sûr et plus efficace." Rendre les cartes plus précises et utiles signifie que Google doit former des intelligence Meilleure reconnaissance des objets dans les images .
Alors, comment formez-vous l'intelligence artificielle? reCAPTCHA. Des centaines de millions d'utilisateurs ont construit des ensembles de données d'apprentissage automatique pour que les entreprises technologiques prouvent qu'ils sont humains.
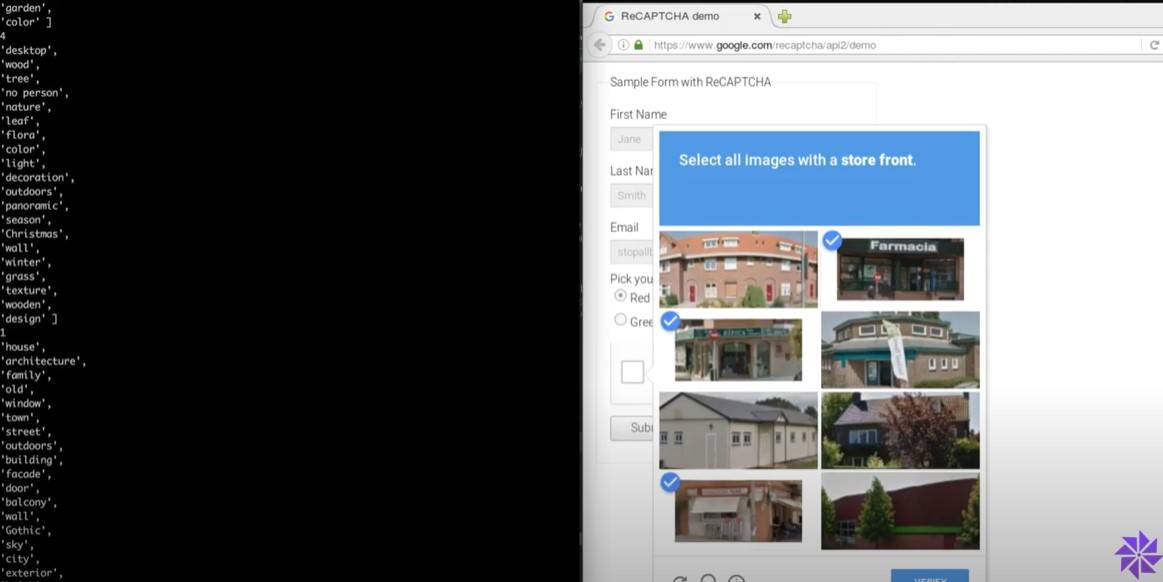
Il n'y a pas que Google qui progresse. En 2017, le développeur Francis Kim a mené une expérience dans laquelle il a construit un système en 40 lignes de Javascript pour tenter de passer le captcha d'image de reCAPTCHA en utilisant l'API de reconnaissance d'image du concurrent Google Clarifai. En conséquence, le script a réussi à trouver le magasin dans l'image.
En théorie, cela pourrait également être réalisé en utilisant la propre technologie de reconnaissance d'image de Google.
Le système CAPTCHA de Google a en fait deux objectifs : supprimer le comportement des scripts malveillants tout en entraînant l'intelligence artificielle avec du texte, des images, etc. Mais le fait est que l'intelligence artificielle de Google s'améliore de plus en plus, mais le script malveillant progresse également dans la bataille de l'esprit et du courage, et il devient de plus en plus difficile pour les utilisateurs de prouver qu'ils sont humains.
En 2014, le "No CAPTCHA reCAPTCHA" de Google est entré en scène, c'est-à-dire "Captcha sans code de vérification". L'interface est simple et conviviale, et il suffit de croire que "je ne suis pas un robot".
Google dit avoir lancé une nouvelle API qui observe le comportement des utilisateurs, collectant des données telles que le taux de mouvement du pointeur, l'adresse IP actuelle, l'utilisation ou non de plugins, la durée d'utilisation d'une page et le nombre de clics effectués, simplifiant radicalement l'expérience reCAPTCHA . Dans la plupart des cas, un simple clic confirme que l'utilisateur est un bot.
Cependant, le captcha n'a pas disparu. Sans doute même le captcha le plus ennuyeux de tous les temps.
Dans le cas où le moteur d'analyse des risques ne peut pas prédire si l'utilisateur est un humain ou non, Google fera ressortir le code de vérification et proposera plus de nouvelles façons de jouer, telles que celles basées sur le problème classique de marquage d'images de vision par ordinateur, laissez vous sélectionnez tous les éléments, y compris les chats ou les dindes Photo.
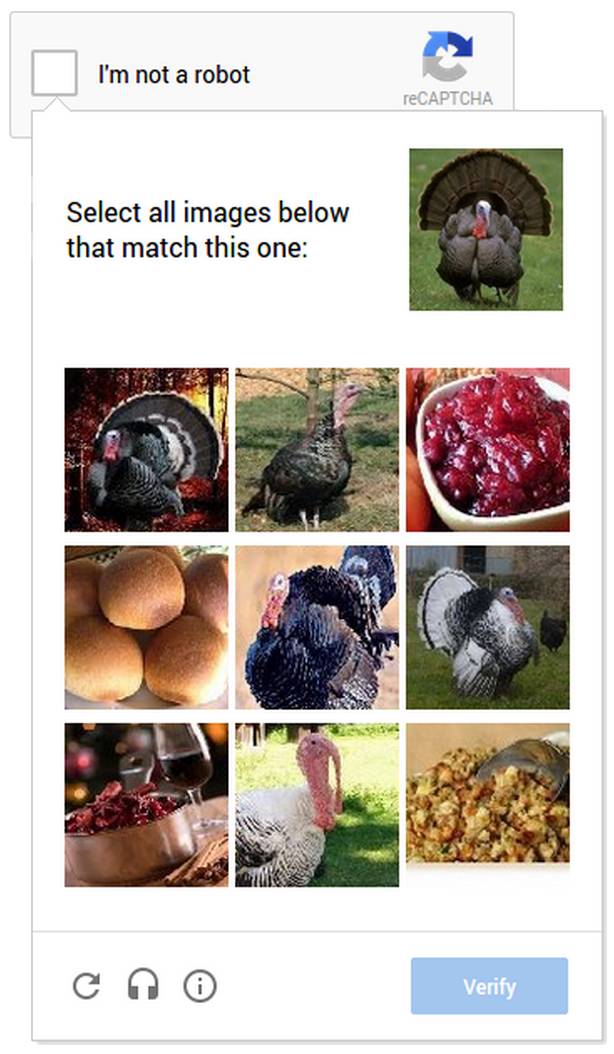
De plus, il existe des captcha de type jeu qui obligent l'utilisateur à faire pivoter un objet selon un angle spécifique ou à déplacer une pièce de puzzle en place.
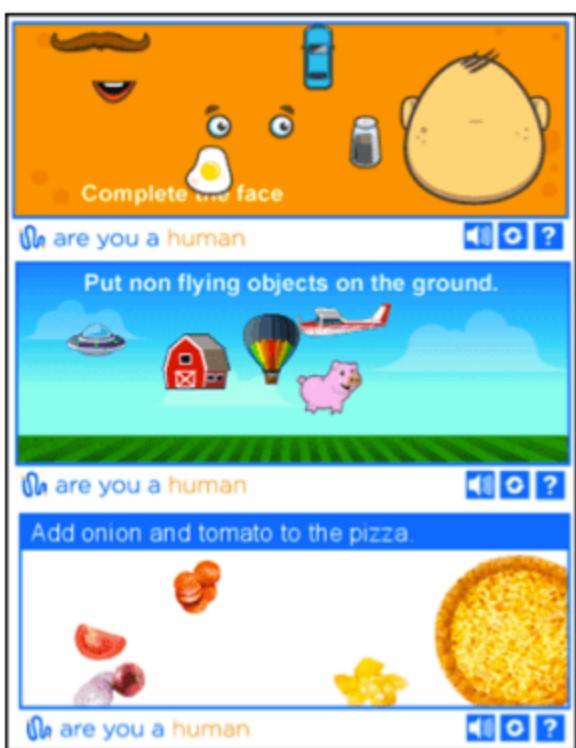
Les humains peuvent comprendre la logique des puzzles, mais les robots qui manquent d'instructions explicites peuvent être bloqués. Mais il est difficile de dire s'il sera maîtrisé à l'avenir.
Plus les machines apprennent, moins les humains ont d'avantages.
Le code de vérification peut-il être remplacé ?
Jason Polakis, professeur d'informatique à l'Université de l'Illinois à Chicago, a souligné que l'apprentissage automatique est désormais à égalité avec les humains dans les tâches de base de reconnaissance de texte, d'image et de parole, et "nous avons besoin d'alternatives".
De plus, avant le système captcha, l'expérience utilisateur et l'accessibilité sont fortement réduites. Le code de vérification n'est pas facile pour de nombreuses personnes, en particulier les personnes âgées et d'autres groupes ayant des troubles d'apprentissage .

Eileen Ridge, qui fournit des conseils techniques aux clients âgés, a déclaré qu'elle recevait souvent des appels de clients qui avaient du mal à faire la distinction entre les trottoirs peints et les passages pour piétons normaux, et craignaient beaucoup d'être exclus des comptes pour de mauvaises réponses, tout comme de nombreuses personnes âgées en Chine. Internet a la même attitude.
Un chien souriant, un cheval fait de nuages, peuvent être plus durs pour eux.
Le schéma de remplacement du code de vérification est également en développement continu.
Certains sites utilisent une forme de captcha invisible pour les utilisateurs humains, insérant des champs sur des écrans visibles uniquement par les robots, les incitant à remplir des formulaires et à prouver qu'ils ne sont pas humains.

Au cours des deux dernières années, Google a lancé un nouveau système de code de vérification, reCaptcha v3 , qui utilise la pensée inversée pour enregistrer automatiquement les caractéristiques de comportement des utilisateurs naviguant sur le site Web et noter les utilisateurs en fonction de ces enregistrements. Si le score de l'utilisateur est trop faible, il sera jugé comme un robot. . Sinon, les utilisateurs ne seront pas dérangés et l'expérience en ligne est très fluide. Mais cela peut impliquer des problèmes de confidentialité.
FastCompany rapporte que l'utilisation des cookies de Google par les utilisateurs est un facteur important dans la détermination des notes. Les utilisateurs obtiennent des scores plus élevés s'ils choisissent de laisser Google se souvenir de leurs informations de connexion, ne sont pas connectés à un compte Google ou utilisent un VPN ou un navigateur oignon sont souvent invités à être à haut risque.

Ghosemajumder, CTO de la société de détection de robots Shape Security, estime que les tests de code de vérification tels que les codes de vérification de jeu et les codes de vérification vidéo seront éventuellement piratés. Par rapport aux tests, il préfère "l'authentification continue", qui observe essentiellement le comportement de l'utilisateur et recherche des signes d'automatisation :
"Un vrai humain n'a pas un bon contrôle sur ses fonctions motrices, donc même s'il essaie très fort, il ne peut pas déplacer la souris de la même manière plusieurs fois au cours de multiples interactions."
En juin, Apple a annoncé lors de la Worldwide Developers Conference qu'il remplacerait les codes de vérification par des jetons d'accès privés .
Mot de passe ou biométrie pour déverrouiller le téléphone, ouvrir le navigateur, entrer sur le site avec précision… une série d'opérations suffisent pour "vérifier l'identité". Lorsque le système Apple vérifie que l'appareil et le compte Apple ID sont dans un état normal, le "jeton d'accès privé" peut être fourni à l'application ou au site Web qui nécessite un code de vérification.
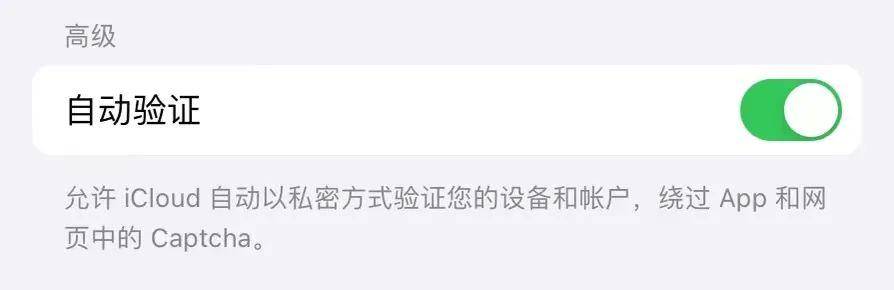
Des entreprises telles que Cloudflare et Ffast, qui assurent la gestion de la sécurité des sites Web, prennent déjà en charge les jetons d'accès privés, qui ne nécessitent plus de codes de vérification pour se connecter à leurs applications ou sites Web avec des appareils iOS 16. À l'heure actuelle, cette technologie est toujours promue et elle a besoin de plus de partisans pour se joindre afin d'être plus utile.
"Cela fera gagner beaucoup de temps à beaucoup de gens, et les utilisateurs aiment se sentir en confiance", a déclaré Tommy Pauly, ingénieur chez Apple.
Mais tant qu'il y aura des faux comptes, des spams, des messages harcelants, etc., nous avons toujours besoin d'une technologie qui sépare les utilisateurs humains des bots, et une certaine forme de technologie captcha existera toujours, se développant en parallèle avec l'intelligence artificielle.
À l'avenir, les systèmes captcha reconnaîtront probablement les humains non pas par notre capacité à surpasser les robots, mais par notre capacité à faire des erreurs. C'est-à-dire pour définir des tests plus difficiles, nous avons tendance à échouer et le robot donne la bonne réponse. Peut-être, alors que nous nous grattons la tête pour trouver toutes les balises de l'image, nous menons une lutte qui vainc l'homme.
Références:
1. https://auth0.com/blog/captcha-can-ruin-your-ux-here-s-how-to-use-it-right/
2. https://www.wired.com/story/smiling-dogs-horses-made-of-clouds-captcha-has-gone-too-far/
3. https://www.techradar.com/news/captcha-if-you-can-how-youve-been-training-ai-for-years-without-realising-it
4. https://www.theverge.com/2019/2/1/18205610/google-captcha-ai-robot-human-difficult-artificial-intelligence
#Bienvenue pour prêter attention au compte WeChat officiel d'Aifaner : Aifaner (WeChat : ifanr), un contenu plus excitant vous sera apporté dès que possible.
Love Faner | Lien d'origine · Voir les commentaires · Sina Weibo