
Le fondateur idéal, Li Xiang, s’exprime à nouveau : ne poursuivez pas Tesla FSD, votre professeur est DeepSeek

En mars de cette année, lors de la conférence NVIDIA Spring GTC 2025, Jia Peng, responsable de la recherche et du développement des technologies de conduite autonome chez Li Auto, a présenté sur scène sa dernière réalisation : le grand modèle MindVLA.
Il s'agit d'un modèle Vision-Langage-Action (VLA) avec 2,2 milliards de paramètres. Jia Peng a en outre déclaré avoir déployé avec succès le modèle sur la voiture. Idéalement, le modèle VLA constitue le moyen le plus efficace pour résoudre le problème de l’interaction entre l’IA et le monde physique.
Au cours de l’année écoulée, l’architecture de bout en bout est devenue un point névralgique technologique dans le domaine de la conduite intelligente, poussant les constructeurs automobiles à passer de la conception de règles modulaires traditionnelles aux systèmes intégrés. Les constructeurs automobiles qui dominaient autrefois en s'appuyant sur des règles et des algorithmes sont confrontés aux difficultés de la transformation, tandis que les retardataires ont saisi l'opportunité de dépasser dans les virages.
Idéal est l'un des représentants.
Ideal a fait des progrès rapides en matière de conduite intelligente l’année dernière. En juillet, elle a pris l'initiative de réaliser le NOA (Navigation Assisted Driving) national sans carte et a également lancé une architecture unique « de bout en bout (système rapide) + VLM (système lent) », qui a attiré une large attention dans l'industrie.

Ce soir, alors que la deuxième saison d'Ideal AI Talk avance, nous comprenons mieux ce que Li Xiang appelle la « société d'intelligence artificielle ».
C’est le « grand modèle du conducteur » et c’est aussi votre conducteur.
Li Xiang, PDG de Li Auto, a mentionné VLA pour la première fois lors de la première saison d'AI Talk avec Zhang Xiaojun, rédacteur en chef de Tencent News Technology, en décembre de l'année dernière. A cette époque, il dit :
Les camarades de classe idéaux et la conduite autonome sur lesquels nous travaillons sont en fait séparés selon les normes de l'industrie et n'en sont qu'à leurs débuts. Le Mind GPT que nous réalisons est en fait un grand modèle de langage ; En interne, la conduite autonome que nous pratiquons est appelée intelligence comportementale, mais comme la définit Li Feifei (professeur titulaire à Stanford et ancien scientifique en chef de Google), elle s'appelle intelligence spatiale. Ce n’est que lorsque vous le ferez réellement à grande échelle que vous saurez qu’un jour les deux seront définitivement liés. Nous l’appelons VLA (Vision Language Action Model) en interne.
Li Xiang pense que le modèle de base deviendra définitivement un VLA à un moment donné. La raison en est que les modèles linguistiques ne peuvent comprendre le monde tridimensionnel qu'à travers le langage et la cognition, ce qui n'est évidemment pas suffisant. "Il faut qu'il soit véritablement vectoriel, en utilisant la méthode de Diffusion (modèle de diffusion) et en utilisant la méthode générative (pour comprendre le monde)."
On peut dire que la naissance de VLA n'est pas seulement une tentative audacieuse de combiner profondément l'intelligence linguistique et l'intelligence spatiale, mais aussi une réinterprétation du concept de « voitures intelligentes » par Li Auto.

Li Xiang l'a défini plus en détail dans AI Talk de ce soir : "VLA est un grand modèle de pilote qui fonctionne comme un pilote humain." Ce n'est pas seulement une technologie, mais aussi un partenaire intelligent capable de communiquer naturellement avec les utilisateurs et de prendre des décisions de manière indépendante.
Alors, qu’est-ce qu’un VLA exactement ? Le noyau est en fait très simple : en intégrant la perception visuelle, la compréhension du langage naturel et les capacités de génération d'actions, le véhicule devient un « agent conducteur » capable de communiquer avec les gens et de prendre des décisions par lui-même.

▲ Lors de la navigation via ETC, le conducteur peut directement commander au système de prendre le canal manuel (conduite assistée)
Imaginez que vous êtes assis dans une voiture et que vous dites avec désinvolture : « Je suis un peu fatigué aujourd'hui, conduisez plus lentement. Le véhicule comprendra non seulement ce que vous voulez dire, mais il ajustera également la vitesse et choisira même un itinéraire plus fluide. Cette interaction naturelle et fluide est exactement ce que VLA souhaite réaliser. Li Xiang a révélé que toutes les instructions courtes sont traitées directement par la voiture, tandis que les instructions complexes sont analysées par le modèle de 3,2 milliards de paramètres du cloud pour garantir à la fois efficacité et intelligence.

Atteindre un tel objectif n’est pas facile. La particularité de VLA est qu’elle relie les trois dimensions de la vision, du langage et du mouvement. Derrière une simple commande de l'utilisateur, cela peut impliquer une perception en temps réel de l'environnement, une compréhension précise des intentions du langage et un ajustement rapide du comportement de conduite, trois éléments indispensables.
L’avantage de VLA est qu’il permet à ces trois éléments de travailler ensemble de manière transparente.
De la vision à la réalité, la recherche et le développement de VLA étaient un no man’s land. Li Xiang a dit franchement : « L'acquisition de données visuelles et de mouvement est la chose la plus difficile, et aucune entreprise ne peut les remplacer.
Pour comprendre le contexte technique de VLA, il faut regarder l’évolution de Li Auto en matière de conduite intelligente.
Li Xiang a déclaré que les premiers systèmes étaient intelligents « au niveau des insectes », avec seulement un million de paramètres, pilotés par des règles et des cartes de haute précision, et étaient impuissants face à des conditions routières complexes. Plus tard, l'architecture de bout en bout et le modèle de langage visuel ont permis à la technologie de passer au « niveau mammifère », en s'affranchissant de la dépendance aux cartes, et le NOA national sans carte est devenu une réalité.
En fait, cette étape a placé Li Auto à l'avant-garde de l'industrie, mais ils n'en sont évidemment pas satisfaits. Selon Li Xiang, l’émergence de VLA marque que la technologie de conduite intelligente de Li Auto est entrée dans une nouvelle étape de « l’intelligence humaine ».

Par rapport aux systèmes précédents, VLA peut non seulement percevoir le monde physique en 3D, mais également effectuer un raisonnement logique et même générer des comportements de conduite proches des niveaux humains.
Pour donner un exemple simple, supposons que vous disiez « trouver un endroit pour faire demi-tour » dans une rue encombrée. VLA n'exécutera pas l'instruction mécaniquement. Au lieu de cela, il combinera les conditions routières, la circulation et les règles de circulation pour trouver l’heure et le lieu les plus raisonnables pour effectuer le demi-tour.
Li Xiang a déclaré que VLA peut s'adapter rapidement à de nouveaux scénarios en générant des données. Même s'il est confronté pour la première fois à des travaux de construction de routes complexes, il peut optimiser la réponse en trois jours. Cette flexibilité et ce jugement sont les principaux atouts de VLA.
Le professeur idéal est DeepSeek
Le VLA est pris en charge par un système technique complexe et sophistiqué développé indépendamment par Li Auto. Ce système permet à la voiture non seulement de « comprendre » le monde, mais aussi de penser et d'agir comme un conducteur humain.
La première est la technologie de représentation gaussienne 3D, qui utilise de nombreux « points de Gauss » pour épeler un objet 3D. Chaque point contient sa propre position, couleur, taille et autres informations. Cette technologie utilise des données réelles massives pour former un puissant modèle de compréhension spatiale 3D grâce à un apprentissage auto-supervisé. Grâce à lui, VLA peut « comprendre » le monde qui l'entoure comme un être humain, sachant où se trouvent les obstacles et où se trouve la zone praticable.

▲Lorsque l'espace de stationnement mémoire est occupé, le système recherchera automatiquement d'autres espaces de stationnement. Vous pouvez également comprendre les instructions du conducteur et retrouver la « Zone C3 » grâce aux panneaux apposés sur le mur.
Vient ensuite l’architecture experte hybride (MoE), qui se compose de réseaux experts, de réseaux fermés et de combinateurs. Lorsque les paramètres du modèle dépassent 100 milliards de niveaux, la méthode traditionnelle impliquera tous les neurones dans chaque calcul, ce qui constitue un gaspillage de ressources. Le réseau fermé de l'architecture MoE fera appel à différents experts en fonction de différentes tâches pour garantir que les paramètres d'activation n'augmenteront pas de manière significative.
En parlant de cela, Li Xiang a également fait l'éloge de DeepSeek :
DeepSeek utilise les meilleures pratiques humaines… Lorsqu'ils ont créé DeepSeek V3, la V3 était en fait un MoE, un modèle 671B. Je pense que MoE est une très bonne architecture. Cela équivaut à rassembler un groupe d’experts, et chacun a une capacité d’expert.
Enfin, Ideal introduit un mécanisme d’attention clairsemée (Sparse Attention) à VLA. En termes humains, VLA ajustera automatiquement le poids de l'attention sur les domaines clés, améliorant ainsi l'efficacité du raisonnement de l'appareil.
Li Xiang a déclaré que pendant le processus de formation de ce nouveau modèle de base, les ingénieurs d'Ideal ont passé beaucoup de temps à trouver le meilleur rapport de données, intégrant une grande quantité de données 3D et de données graphiques liées à la conduite autonome, et réduisant la proportion de données culturelles et historiques.
De la perception à la prise de décision, VLA s’appuie sur la combinaison rapide et lente de la pensée humaine. Il peut rapidement produire des décisions d'action simples, comme éviter une situation d'urgence, et peut également effectuer une « réflexion lente » à travers des chaînes de réflexion courtes pour faire face à des scénarios plus complexes, comme planifier temporairement un itinéraire pour contourner la zone de construction. Afin d'améliorer encore les performances en temps réel, VLA introduit également une technologie de raisonnement spéculatif et de décodage parallèle pour exploiter pleinement la puissance de calcul de la puce intégrée afin de garantir que le processus de prise de décision est rapide et non chaotique.
Lors de la génération de comportements de conduite, VLA utilise le modèle de diffusion et l'apprentissage par renforcement basé sur le feedback humain (RLHF). Le modèle Diffusion est chargé de générer des trajectoires de conduite optimisées, tandis que le RLHF rapproche ces trajectoires des habitudes humaines, à la fois sûres et confortables. Par exemple, VLA ralentira automatiquement lors d'un virage ou laissera une distance de sécurité suffisante lors de la fusion. Ces détails reflètent tous un apprentissage approfondi du comportement de conduite humain.

Le modèle mondial est une autre technologie clé qui fournit idéalement un environnement virtuel de haute qualité pour l’apprentissage par renforcement via la reconstruction et la génération de scènes. Li Xiang a révélé que World Model avait réduit le coût de vérification de 170 000 à 180 000 yuans pour 10 000 kilomètres à 4 000 yuans. Il permet à VLA d'optimiser en permanence pendant la simulation et de gérer facilement des scénarios complexes.
En parlant de formation, le processus de croissance de VLA a été assez méthodique. L'ensemble du processus est divisé en trois étapes : pré-formation, post-formation et apprentissage par renforcement. "La pré-formation est comme l'apprentissage de connaissances, la post-formation est comme l'apprentissage de la conduite dans une auto-école et l'apprentissage intensif est comme une pratique sociale." » dit Li.
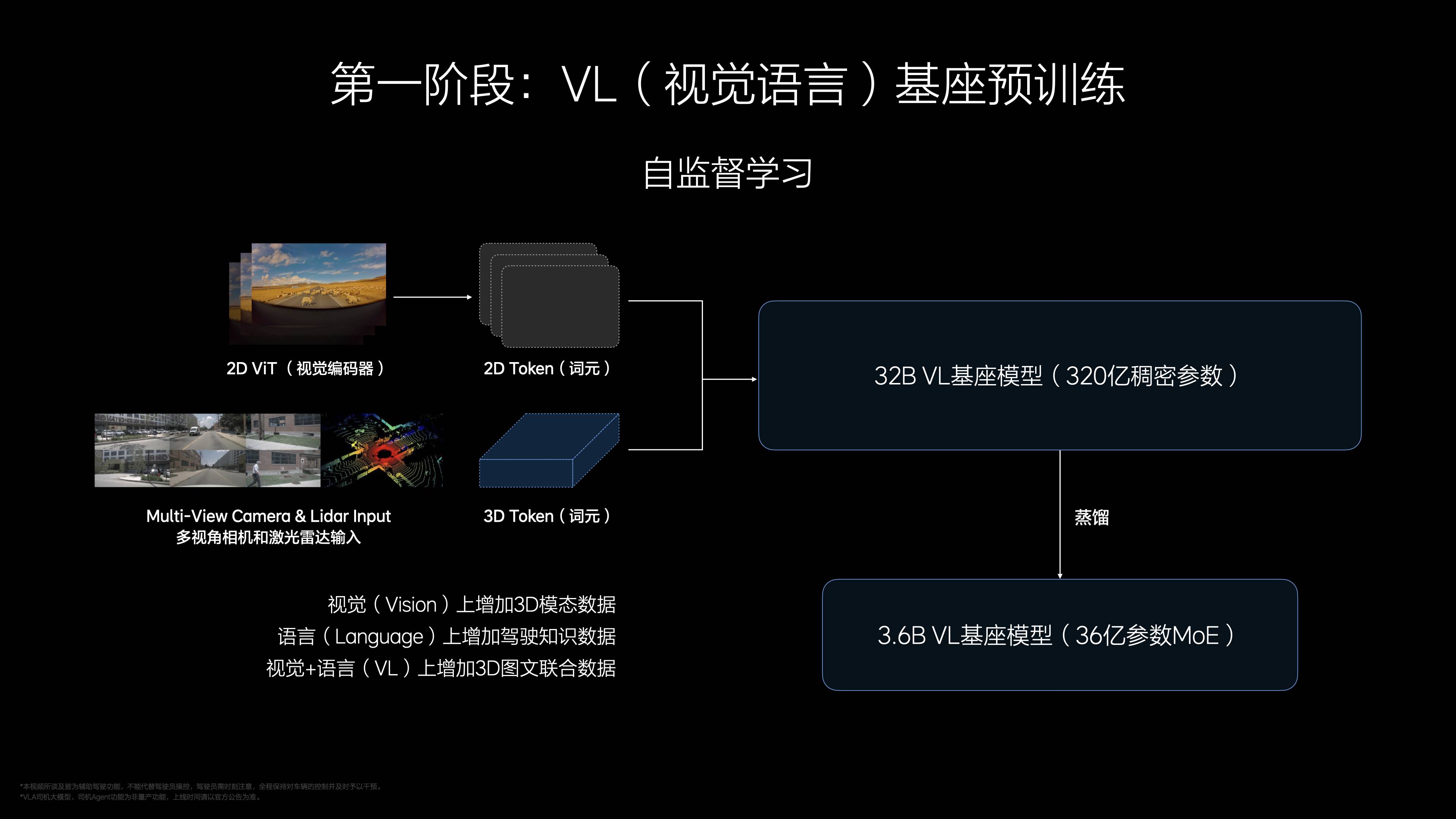
Au cours de la phase de pré-formation, Li Auto a créé un modèle de base de langage visuel pour VLA, rempli de riches données visuelles 3D, d'images 2D haute définition et d'un corpus lié à la conduite, afin qu'il puisse d'abord apprendre à « voir » et « écouter » ; Ensuite, un module d'action a été ajouté à la formation pour générer une trajectoire de conduite de 4 à 8 secondes, et le modèle a été distillé de 320 millions de paramètres à 400 millions.
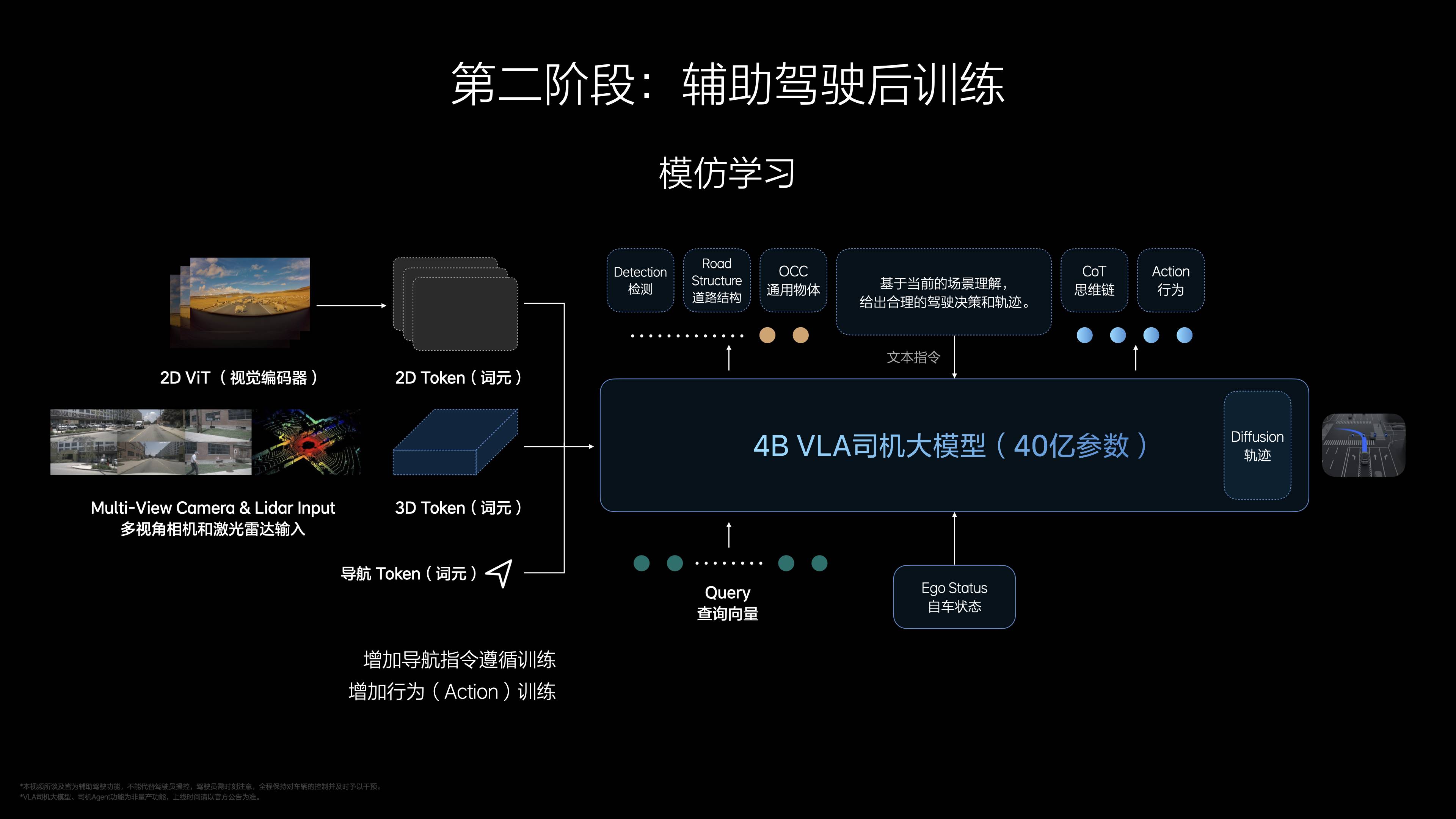
L'apprentissage par renforcement est divisé en deux étapes : utilisez d'abord le RLHF pour aligner les habitudes humaines, analyser les données de prise de contrôle et assurer la sécurité et le confort ; utilisez ensuite l'optimisation de l'apprentissage par renforcement pur pour que VLA « conduise mieux que les humains » en fonction de la valeur G (confort), des collisions et des commentaires sur les règles de circulation. Li Xiang a mentionné que cette étape est complétée dans le modèle mondial, simulant des scénarios de trafic réels, et que l'efficacité est bien supérieure à la vérification traditionnelle.
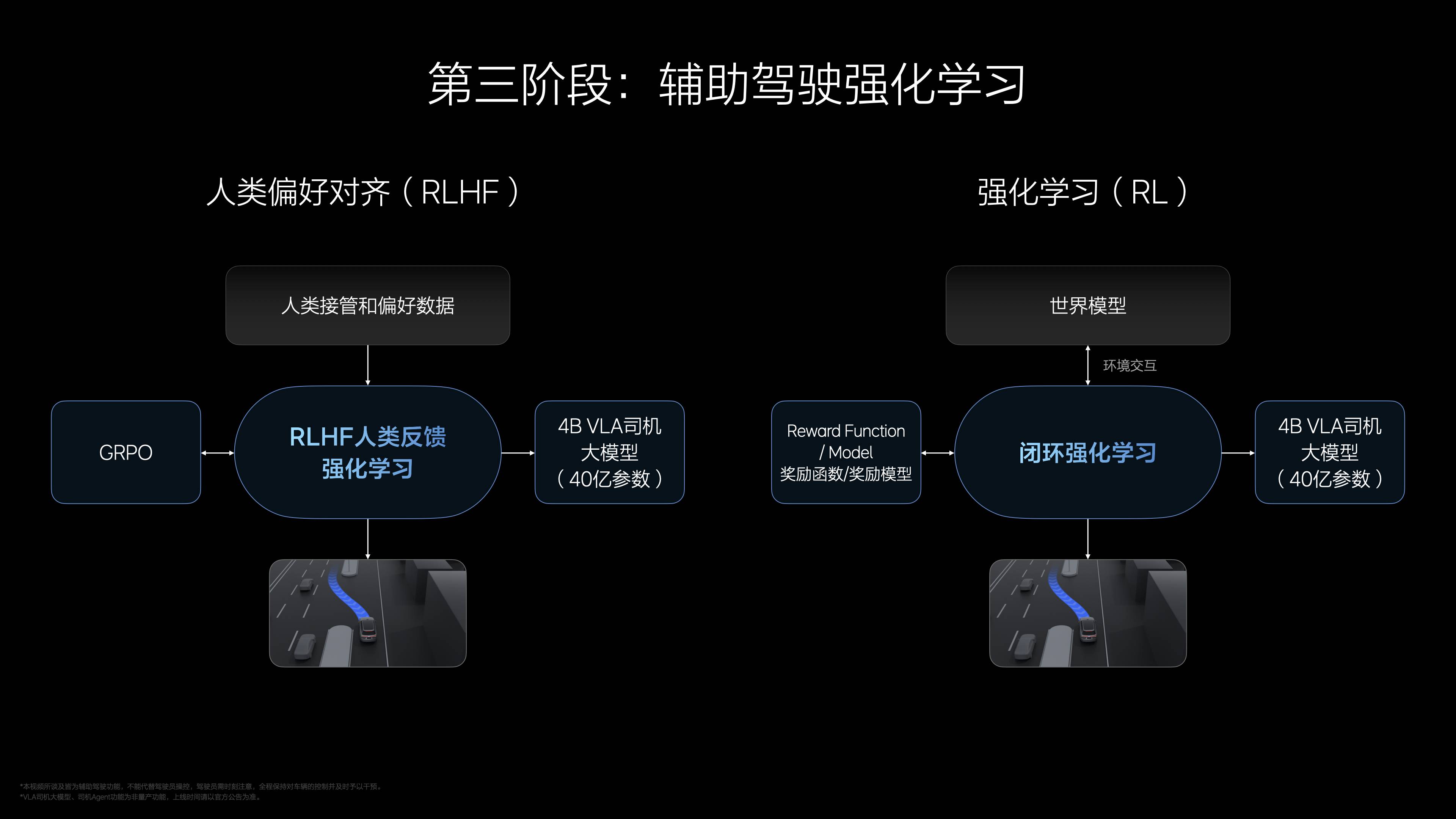
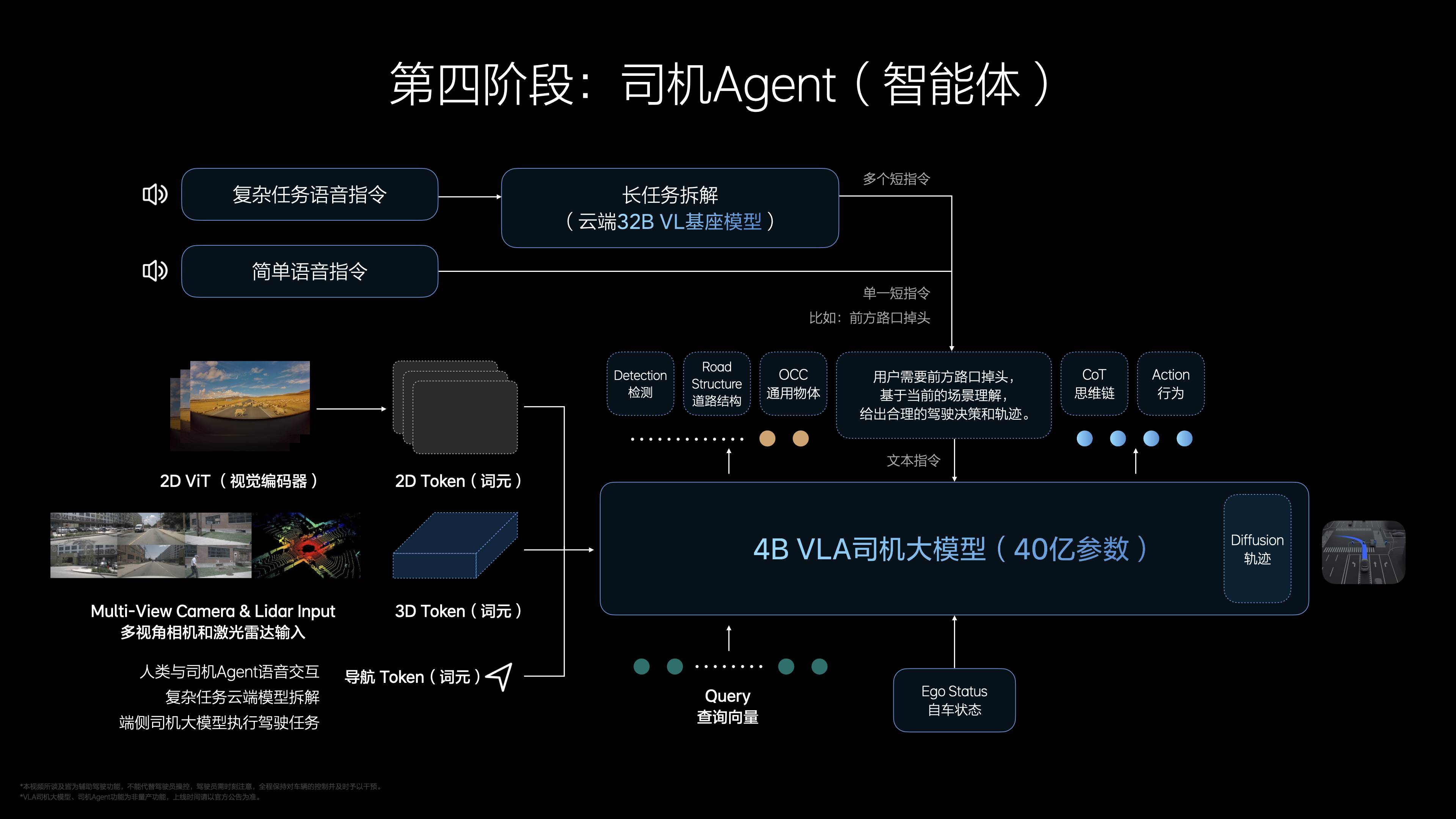
Cette méthode de formation garantit non seulement le progrès technologique, mais rend également VLA suffisamment fiable pour des applications pratiques.
Li Xiang a admis que le succès de VLA est indissociable de l’inspiration des références de l’industrie. L'architecture MoE de DeepSeek améliore non seulement l'efficacité de la formation, mais fournit également une expérience précieuse pour les idéaux. Il a déploré : "Nous nous appuyons sur les épaules de géants et accélérons la recherche et le développement de VLA". Cette attitude d'apprentissage ouvert permet à l'idéal d'aller plus loin dans le no man's land.
Des « outils d’information » aux « outils de production »
Actuellement, l'industrie de l'IA connaît une profonde transformation des « outils d'information » aux « outils de production ». À mesure que la technologie des grands modèles évolue, l’IA ne se limite plus au traitement des données et à la fourniture de suggestions, mais commence à avoir la capacité de prendre des décisions et d’effectuer des tâches de manière autonome.
Li Xiang a proposé dans la deuxième saison d'AI Talk que l'IA puisse être divisée en outils d'information (tels que la recherche), outils auxiliaires (tels que la navigation vocale) et outils de production. Il a souligné : "Au moment où l'intelligence artificielle deviendra un outil de production, elle explosera véritablement". À mesure que la technologie des grands modèles évolue, l’IA ne se limite plus au traitement des données, mais commence à avoir la capacité de prendre des décisions et d’effectuer des tâches de manière indépendante.
Cette tendance est particulièrement évidente dans le concept d'« intelligence incarnée » : les systèmes d'IA reçoivent des entités physiques et peuvent percevoir, comprendre et interagir avec l'environnement.

Le modèle VLA de Li Auto est une pratique vivante de cette tendance. En intégrant l'intelligence visuelle, linguistique et de mouvement, il transforme la voiture en une carrosserie intelligente capable de conduire de manière autonome et d'interagir naturellement avec les utilisateurs, interprétant parfaitement le concept central d'« intelligence incarnée ».
Tant que les humains embaucheront des chauffeurs professionnels, l’intelligence artificielle pourra devenir un outil de production. L’intelligence artificielle explosera véritablement lorsqu’elle deviendra un outil de production.
Les mots de Li Xiang illustrent la valeur fondamentale de VLA : il ne s'agit plus d'un simple outil auxiliaire, mais d'un « agent conducteur » capable d'effectuer des tâches de manière indépendante et d'assumer des responsabilités. Cette transformation améliore non seulement la valeur pratique des voitures, mais ouvre également la voie à l’imagination pour l’application de l’IA dans d’autres domaines.
La réflexion de Li Xiang sur l’IA adopte toujours une perspective hors des sentiers battus. Il a également mentionné : « VLA n'est pas un processus de mutation, mais un processus évolutif. » Cette phrase résume avec précision le parcours technique de la voiture idéale——
Depuis les premières règles, jusqu'aux percées de bout en bout, jusqu'au niveau actuel d'« intelligence humaine » de VLA. Ce type de réflexion évolutive rend non seulement le VLA plus réalisable sur le plan technique, mais fournit également un paradigme dont l'industrie peut tirer des leçons. Comparée à certaines tentatives visant à poursuivre aveuglément la subversion, la voie pragmatique idéale pourrait être plus adaptée au marché chinois complexe.
De la technologie à la croyance, l’exploration idéale de l’IA n’est pas un chemin facile. Li Xiang a déclaré franchement : « Nous avons rencontré de nombreux défis dans le domaine de l'IA, tout comme l'obscurité avant l'aube, mais nous pensons que si nous persistons, nous verrons la lumière. La recherche et le développement de VLA sont confrontés à des problèmes tels que les goulots d'étranglement de la puissance de calcul et l'éthique des données, mais Ideal a progressivement marqué le début de sa technologie grâce à des modèles de base et des modèles mondiaux auto-développés.
Li Xiang a également mentionné dans l'interview que le succès de VLA est indissociable de la montée en puissance de l'IA chinoise.
Il a déclaré que l'émergence de modèles tels que DeepSeek et Tongyi Qianwen a permis au niveau de l'IA de la Chine de se rapprocher rapidement de celui des États-Unis. Parmi eux, l’esprit open source défendu par DeepSeek est particulièrement passionnant, car il promeut directement le système d’exploitation open source Starlink idéal. Li Xiang a déclaré : « Cela n'est pas dû à des considérations stratégiques de l'entreprise. DeepSeek nous a apporté tellement d'aide et nous devrions apporter quelque chose à la société.

Tout en poursuivant les percées technologiques, Li Auto n’a pas ignoré les problèmes de sécurité et d’éthique de la technologie de l’IA. La technologie de « super alignement » introduite par VLA rapproche le comportement du modèle des habitudes humaines grâce à un apprentissage par renforcement basé sur le feedback humain (RLHF). Les données montrent que l'application du VLA a augmenté le MPI (kilométrage moyen d'intervention) à grande vitesse de 240 km à 300 km.
Plus important encore, Li Auto met l’accent sur la construction d’une « IA avec des valeurs humaines » et considère l’éthique et la confiance comme la pierre angulaire du développement technologique. D’un point de vue plus macro, l’importance de la VLA est qu’elle redéfinit le rôle des constructeurs automobiles.
Autrefois, les voitures étaient le moyen de transport à l’ère industrielle ; aujourd'hui, ils évoluent vers des « robots spatiaux » à l'ère de l'intelligence artificielle. Li Xiang a mentionné dans AI Talk : « L'idéal était autrefois dans le no man's land des voitures, mais à l'avenir, ce sera dans le no man's land de l'intelligence artificielle. Cette transformation d’Ideal a apporté un nouvel espace d’imagination au modèle économique de l’industrie automobile.
Bien entendu, le développement de VLA n’est pas sans défis. L’investissement continu dans la puissance de calcul, l’éthique des données et l’établissement de la confiance des consommateurs dans la conduite autonome sont autant de problèmes auxquels les voitures idéales doivent faire face. De plus, la concurrence dans le secteur de l’IA devient de plus en plus féroce. Des géants nationaux et étrangers tels que Tesla, Waymo et OpenAI accélèrent le déploiement de modèles multimodaux. Idéalement, ils doivent garder une longueur d’avance en matière d’itération technologique et de promotion sur le marché. "Nous n'avons pas de raccourcis, nous pouvons seulement creuser profondément", voulait dire Li.
Il ne fait aucun doute que la mise en œuvre de VLA sera un élément clé.
Li Auto prévoit de lancer le VLA simultanément avec le SUV purement électrique Li Li i8 en juillet 2025 et d'atteindre une production de masse en 2026. Il s'agit non seulement d'un examen complet de la technologie, mais également d'une pierre de touche importante pour le marché.
# Bienvenue pour suivre le compte public officiel WeChat d'Aifaner : Aifaner (WeChat ID : ifanr). Un contenu plus passionnant vous sera fourni dès que possible.
Ai Faner | Lien original · Voir les commentaires · Sina Weibo