
Le produit le plus compétitif d’OpenAI est mis à jour ! Simuler l’utilisation humaine des ordinateurs en une phrase, une avancée majeure avant l’éveil des agents IA

Le monde souffre depuis longtemps. OpenAI presse du dentifrice.
En regardant autour de Yunei, il n'y a qu'une poignée d'adversaires qui peuvent rivaliser avec OpenAI. Le modèle Claude d'Anthropic est au moins un rival fiable.
Dans l'attente des étoiles et de la lune, je n'ai pas attendu l'apparition de la "super grande tasse" Opus, mais heureusement, j'ai aussi attendu la grande tasse nouvellement améliorée Claude 3.5 Sonnet.
Un bref résumé des points forts de cette mise à jour :
- Poinçonnant GPT-4o et kickant Gemini 1.5 Pro, la nouvelle version de Claude 3.5 Sonnet est loin devant
- Claude 3.5 Haiku a la vitesse de réponse la plus rapide et ses performances sont comparables à celles du GPT-4o mini
- Créer une API pour apprendre à Claude à jouer aux ordinateurs
Apprenez à Claude à jouer à l'ordinateur, le guerrier du clavier IA est-il là ?
Le point culminant de cette mise à jour n’est en fait pas le nouveau modèle, mais la manière d’apprendre à l’IA à jouer sur ordinateur.
Anthropic a lancé une fonction révolutionnaire « utilisation de l'ordinateur » pour les tests publics : apprendre à Claude à utiliser l'ordinateur comme un humain grâce à l'API, il peut voir l'écran, déplacer le curseur, cliquer sur des boutons, taper…
En termes simples, Claude peut désormais utiliser des outils et logiciels standards conçus par des humains. Les développeurs peuvent l'utiliser pour libérer certaines tâches de processus répétitives ennuyeuses et même effectuer des tâches ouvertes telles que la recherche.
Pour doter Claude de cette compétence, Anthropic utilise une API pour permettre à Claude de percevoir et d'interagir avec l'interface de l'ordinateur.
Concrètement, les développeurs intègrent cette API lors du processus d'interaction, permettant à Claude de traduire des instructions (telles que : "Utiliser des données sur mon ordinateur et les combiner avec des informations en ligne pour remplir un formulaire") en instructions informatiques (telles que : vérifier un formulaire, move Déplacez la souris pour ouvrir un navigateur, accédez à la page Web appropriée, puis remplissez le tableau avec des données provenant d'Internet).
OSWorld est une plateforme de référence utilisée pour tester la capacité des agents multimodaux à effectuer des tâches ouvertes dans des environnements informatiques réels. Elle est généralement utilisée pour évaluer si les modèles d'IA ont la capacité d'utiliser des ordinateurs comme les humains.
Le Claude 3.5 Sonnet a obtenu un score de 14,9 % dans la catégorie des tests de capture d'écran uniquement, bien devant le score de deuxième place de 7,8 %. En prenant en compte plus de pas, Claude a obtenu un score de 22,0 %.
Les produits de certaines entreprises ont déjà utilisé cette fonctionnalité au préalable.
Par exemple, Replit exploite les capacités de fonctionnement informatique et de navigation de l'interface de Claude 3.5 Sonnet pour développer une fonctionnalité clé de son produit d'agent Replit pour évaluer les applications en construction.
Bien entendu, cette approche n’est pas nouvelle.
Car avant cela, Asana, Canva, Cognition, DoorDash, Replit et The Browser Company ont commencé à explorer ces possibilités, en effectuant des tâches qui nécessitent des dizaines, voire des centaines d'étapes.
Cependant, l’idéal est très complet et la réalité est très maigre.
Le responsable a également admis que cette fonctionnalité est encore au stade expérimental, qu'elle est lente et que des erreurs se produisent souvent lors de l'utilisation de l'ordinateur. Certaines opérations simples, comme le défilement, le déplacement et le zoom, qui semblent être effectuées par des humains d'un simple geste de la main, restent un grand défi pour Claude.
Lors de l’enregistrement de ces démos, nous avons découvert quelques épisodes intéressants. À une occasion, Claude a accidentellement mis fin à un long enregistrement d'écran en cours et toutes les images ont été perdues.
Plus tard, Claude a fait une pause entre nos démos de codage pour regarder des photos du parc national de Yellowstone.
De plus, Claude capture des images statiques de l'écran, puis combine ces images pour comprendre ce qui se passe à l'écran, mais de ce fait, il peut ne pas être en mesure de capturer de brèves actions ou notifications à l'écran, telles que des fenêtres contextuelles ou des notifications. icône qui change rapidement.
Le responsable a également déclaré que la raison de la publication anticipée d'un produit expérimental est d'obtenir les commentaires des développeurs. On s'attend à ce que cette fonction s'améliore progressivement au fil du temps.
Alex Albert, directeur des relations développeurs chez Anthropic, a également partagé une expérience intéressante.
Lors du développement de la fonctionnalité « utilisation de l'ordinateur », ils ont organisé une session de dépannage technique pour identifier tout problème potentiel dans l'API.
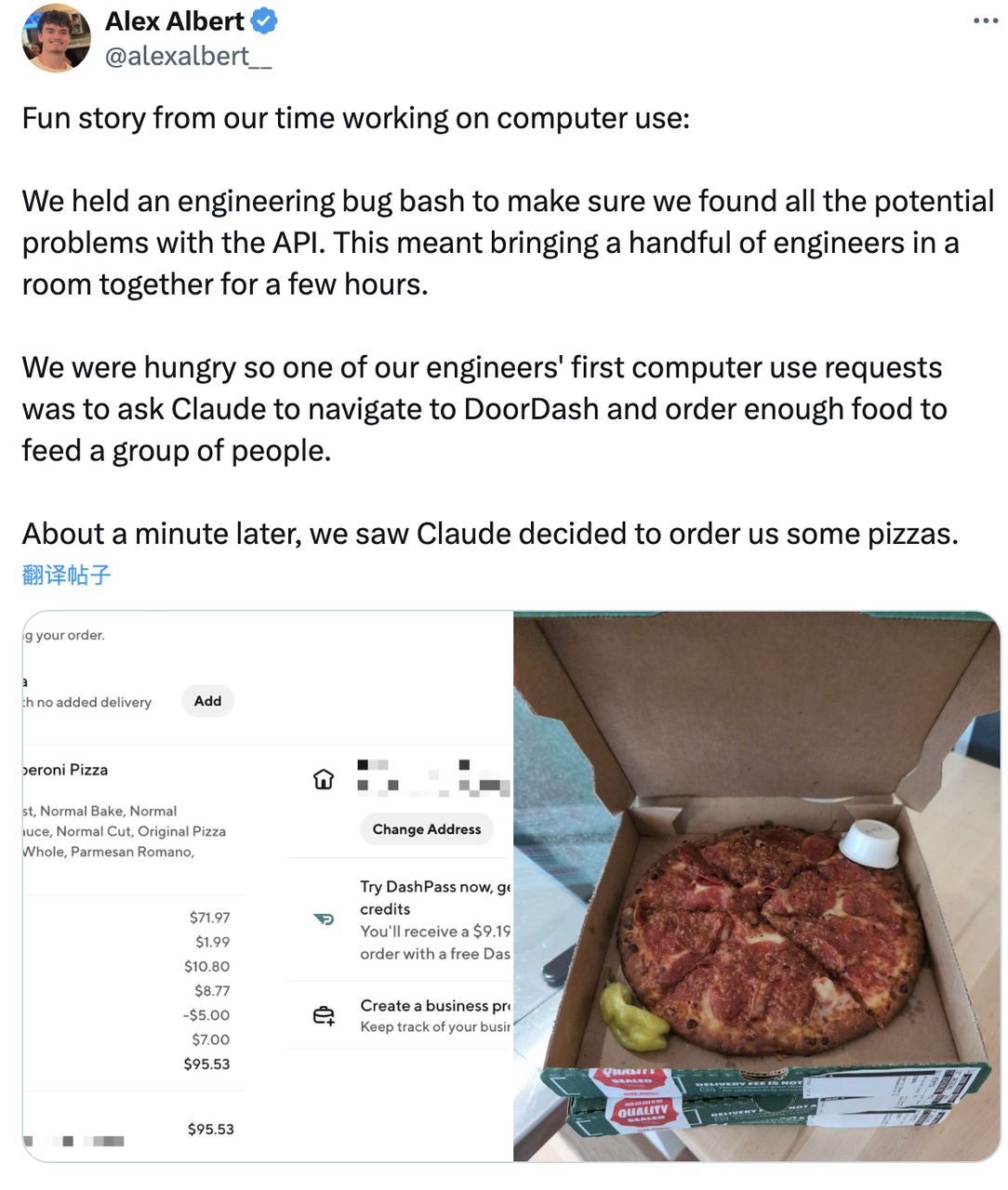
Plusieurs ingénieurs se sont rassemblés dans une pièce pour travailler pendant quelques heures, mais ont rapidement eu faim. L'une des premières demandes d'utilisation de l'ordinateur des ingénieurs était donc que Claude se rende sur la plateforme de livraison de nourriture DoorDash et commande suffisamment de nourriture pour nourrir tout le monde. .
Claude réfléchit environ une minute et commanda finalement de la pizza pour les ingénieurs.
Les internautes ont également rapidement dressé une liste de choses que la fonction d'utilisation de l'ordinateur refuse de faire :
- Créez un compte sur les réseaux sociaux ou d'autres plateformes
- Envoyer un e-mail ou un message
- Publier un commentaire sur les réseaux sociaux
- Effectuer un achat
- accéder à des informations privées
- Code de vérification complet (CAPTCHA)
- Générer, éditer ou modifier des images
- Appeler
- Accéder au contenu restreint
- Effectuer des actions qui nécessitent une authentification personnelle

Le roi des véritables modèles d'inférence, le nouveau codage de modèles est loin devant
Jetons un coup d’œil à la transcription soumise par Claude 3.5 Sonnet.
Bien que la crédibilité de la grande liste de modèles ne soit plus aussi bonne qu'avant, sur la base de la logique du même ensemble de questions de test, nous pouvons toujours avoir une compréhension préliminaire des modèles récemment publiés.
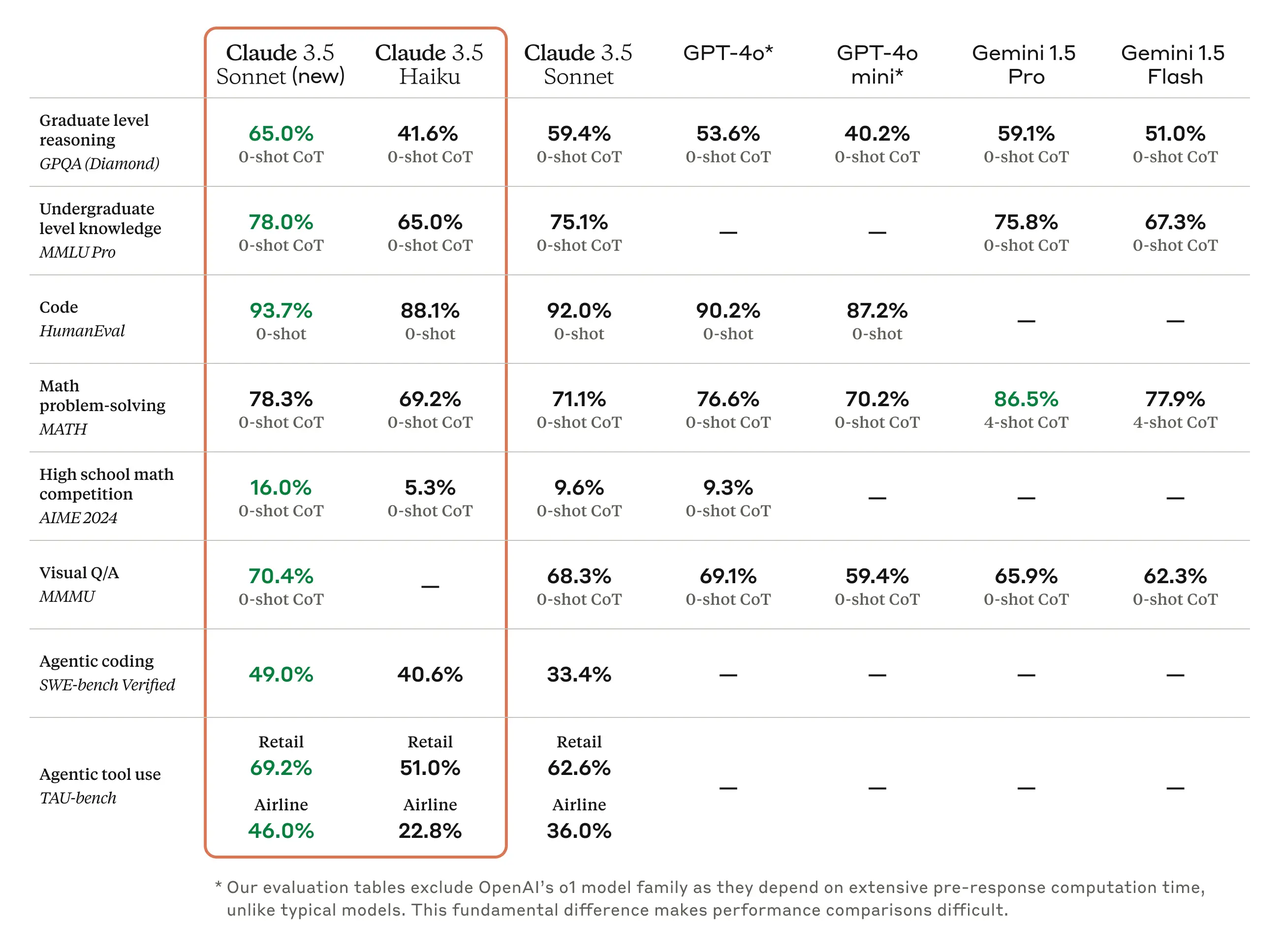
En frappant GPT-4o et en lançant Gemini 1.5 Pro, Claude 3.5 Sonnet a brillamment performé dans une série de tests de référence tels que GPQA, MMLU Pro et HumanEVal, et on peut dire qu'il est loin devant.
Surtout dans le domaine du codage, Claude 3.5 Sonnet a encore élargi son avance. Peut-être êtes-vous curieux de savoir pourquoi il n'y a pas de comparaison avec le modèle OpenAI o1 dans le test de référence.
Ne vous inquiétez pas, Anthropic a prédit votre prédiction. L’explication officielle est la suivante :
La raison pour laquelle la famille de modèles o1 d'OpenAI n'est pas incluse dans notre tableau d'évaluation est qu'ils nécessitent beaucoup de temps de calcul avant de répondre, contrairement à la plupart des modèles. Cette différence essentielle complique les comparaisons de performances.
Pour traduire, on veut comparer mais ce n’est pas possible de comparer.
Cependant, dans le test de codage vérifié du banc SWE, les performances de Claude 3.5 Sonnet ont augmenté de 33,4 % à 49,0 %, dépassant tous les modèles accessibles au public – y compris les modèles d'inférence tels que OpenAI o1-preview et divers systèmes de codage d'agents.
Claude 3.5 Sonnet est le roi des véritables modèles d'inférence.
De plus, Claude 3.5 Sonnet a également obtenu de bons résultats lors du test de l'outil d'agent de banc TAU.
TAU-bench fournit principalement un environnement d'évaluation plus proche des scénarios d'application du monde réel.
En ce qui concerne le secteur du commerce de détail, le score du Sonnet Claude 3.5 s'est amélioré de 62,6% à 69,2%, tandis que pour le secteur de l'aviation, son score a également augmenté de 36,0% à 46,0%.

De plus, ces améliorations n'augmentent ni le prix ni ne réduisent la vitesse, et le Claude 3.5 Sonnet conserve toujours le même rapport qualité-prix que son prédécesseur.
Le blog officiel mentionne que l'amélioration des capacités de codage est le plus grand point fort de Claude 3.5 Sonnet.
Les tests GitLab ont révélé que ses capacités de raisonnement ont augmenté de 10 % sans délais supplémentaires, ce qui le rend très adapté aux processus de développement logiciel en plusieurs étapes. The Browser Company a également noté que le Claude 3.5 Sonnet surpassait tous les modèles précédents testés en matière d'automatisation des flux de travail Web.
En tant qu'entreprise modèle qui recherche des facteurs de sécurité extrêmement élevés, Anthropic a naturellement mené une évaluation des risques de catastrophe sur le Claude 3.5 Sonnet, et les résultats ont répondu à la norme ASL-2. .
ASL-2 fait référence à des systèmes qui montrent des signes précoces de capacités dangereuses (comme la capacité de donner des instructions sur la façon de créer des armes biologiques), mais les informations ne sont pas d'une grande utilité en raison d'une fiabilité insuffisante ou de l'incapacité d'aller au-delà de ce qu'est un moteur de recherche. peut fournir.
Bref, aussi puissant soit-il, le Sonnet Claude 3.5 ne menace pas encore l'humanité.
Après avoir parlé du modèle le plus puissant, le suivant est le nouveau modèle amélioré avec la vitesse de réponse la plus rapide – Claude 3.5 Haiku.
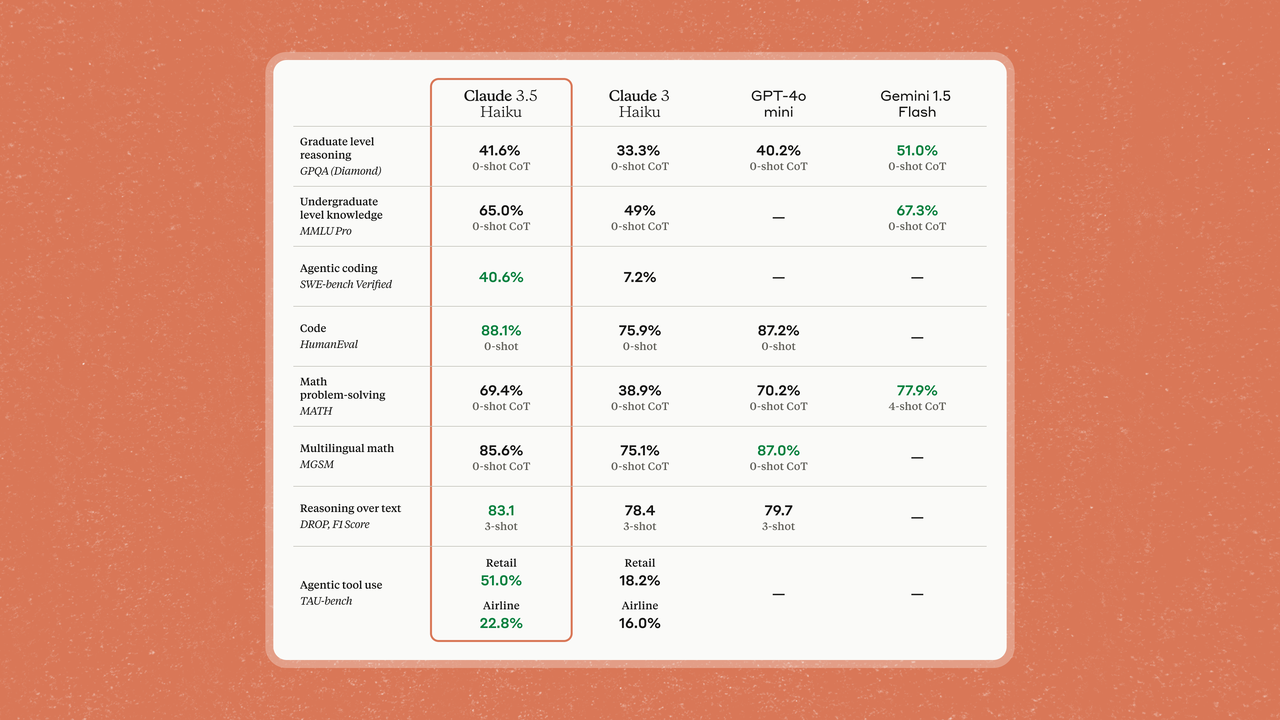
Rien qu'en regardant les paramètres papier, le Claude 3.5 Haiku de taille moyenne n'est presque pas inférieur au GPT-4o mini. On peut même dire qu'il a une petite victoire, et les performances globales sont à égalité avec la génération précédente Claude 3. Opus.
Mais le prix n'a pas changé et la vitesse de réponse n'a pas ralenti. Il existe une expérience erronée consistant à « augmenter la quantité sans augmenter le prix ».
De même, Claude 3.5 Haiku est particulièrement performant dans les tâches d'encodage. Par exemple, son score sur SWE-bench Verified est de 40,6 %, dépassant de nombreux agents dits de pointe, notamment son Claude 3.5 Sonnet (original) et GPT-4o.
Une faible latence, des capacités d'exécution de commandes améliorées et une utilisation plus précise des outils rendent Claude 3.5 Haiku particulièrement adapté aux scénarios nécessitant des services personnalisés.
Par exemple, il peut recommander des produits en fonction de vos habitudes d'achat précédentes, vous aider à déterminer le prix des produits ou même vous aider à gérer les stocks dans l'entrepôt.
Enfin, la version améliorée de Claude 3.5 Sonnet est désormais disponible pour tous les utilisateurs. Claude 3.5 Haiku sortira plus tard ce mois-ci, dans un premier temps, il ne prendra en charge que la saisie de texte, et la fonction de saisie d'images sera lancée plus tard.

Si vous prêtez attention au cercle de l'IA récemment, vous constaterez que plusieurs personnalités importantes de l'industrie ont joué au « prévoyant ».
Demis Hassabis, Yann LeCun, Sam Altman et Dario Amodei d'Anthropic affirment tous que l'AGI sera mis en œuvre dans les prochaines années, avec des délais allant de 2025 à 2030.
Ils ont dessiné un modèle d’AGI comparable à l’utopie, comme guérir la plupart des maladies, résoudre les problèmes climatiques, éradiquer la pauvreté, etc. Si l’on résume les idées centrales de plusieurs longs articles, l’IA est presque devenue un remède miracle pour toutes les maladies.
Cela dit, la confiance doit être prouvée par des produits réels.
En l’absence d’un modèle économique fiable et durable, l’industrie ne peut compter que sur une « confiance aveugle » en AGI pour maintenir des investissements et des dépenses élevés, tout comme la carotte qui pend devant l’âne.
En d'autres termes, une série de fonctionnalités de produit telles que le modèle Claude publié aujourd'hui rétablissent également notre confiance. Selon le rythme de sortie du produit précédent, OpenAI devrait être lancé prochainement.
La différence est que l’arsenal d’OpenAI est évidemment plus riche. Peut-être que la prochaine à être dévoilée sera la version officielle d'OpenAI o1, ou le "futur" Sora.
Ensuite, nous attendrons de voir comment OpenAI « montre son épée ».
# Bienvenue pour suivre le compte public officiel WeChat d'aifaner : aifaner (ID WeChat : ifanr). Un contenu plus passionnant vous sera fourni dès que possible.
Ai Faner | Lien original · Voir les commentaires · Sina Weibo