
Les puces phares fonctionnent mal, ce « pot » ne peut pas simplement laisser Samsung revenir

Même si vous n'êtes pas un passionné d'électronique grand public, vous devriez connaître la tige du "dragon de feu" au cours des deux dernières années.

▲ Image tirée de : "Game of Thrones"
La raison principale est que dans les dernières générations de puces phares d'Android, la consommation d'énergie a été "renversée" les unes après les autres.Les hautes performances s'accompagnent souvent d'une consommation d'énergie élevée, qui s'accompagne également d'une forte augmentation de la chaleur des téléphones portables.
Cela apporte un avantage et un inconvénient. L'avantage est que les fabricants obtiennent des niveaux de "dissipation thermique" de plus en plus élevés, tandis que l'inconvénient est que le réglage des puces devient plus conservateur, ainsi qu'un mur de contrôle de température plus bas.

Sous la compression haute performance continue (telle que l'exécution de "Yuan Shen"), essentiellement en 10 à 15 minutes, les produits réduiront activement la fréquence du super noyau de la puce. Si la température est encore élevée, la prochaine limite est la grande cœur.
D'autre part, en utilisant des puces phares avec une technologie plus avancée, dans des conditions quotidiennes, il devrait y avoir une amélioration de la durée de vie de la batterie.
Cependant, en cours d'utilisation, l'amélioration de la durée de vie de la batterie consiste à "arroser de l'eau", ce qui a peu d'effet et dépend d'une charge rapide à haute puissance pour continuer la vie.
De plus, il y a un autre point, la récente instabilité du processus 4 nm dans la fonderie de Samsung peut être considérée comme une raison. Sa propre puce phare Exynos 2200 a également sous-performé, pas intentionnellement.
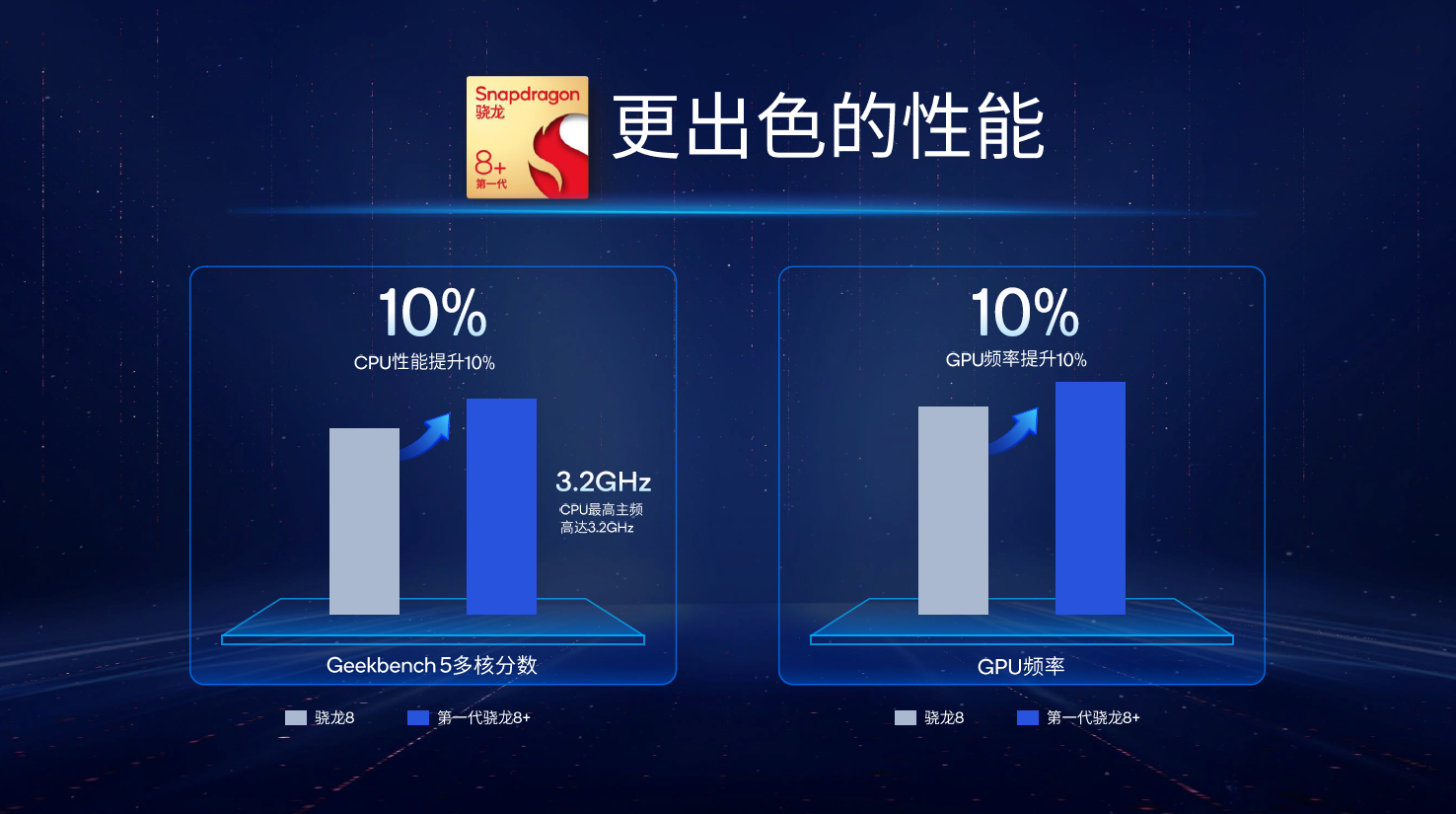
En conséquence, Qualcomm, qui a été "profondément affecté", a également annoncé l'utilisation du processus 4nm de TSMC sur le SoC Snapdragon 8+ Gen1 qui vient d'être annoncé , et a directement déclaré dans le PPT que les performances avaient été améliorées de 10% et la consommation d'énergie a été réduit de 30 %.
Il semble que les mauvaises performances des puces phares d'Android soient uniquement dues au fait que le processus 4 nm de Samsung est "dommage", alors TSMC est-il un "sauvetage" ?
Le 4 nm de TSMC n'est qu'un "tissu de figure"
TSMC et Samsung sont presque les deux principaux oligarques de la production mondiale de puces de processus avancés. Les deux dominent presque le marché mondial des puces produites en dessous de 10 nm.

▲ Photo de : wccftech.com
En quelques années, du 10nm au 4nm, et ils construisent aussi des lignes de production et des fonderies en 3nm, la concurrence s'intensifie.
Contrairement à la fonderie pure de TSMC, Samsung est une société de fabrication intégrée verticalement (IDM) qui intègre des puces de conception indépendantes, des puces de production et les propres puces d'Exynos.

Il y a 10 ans, Samsung voulait être en avance sur TSMC, et la puce A4 d'Apple a également été modifiée par magie à partir de Samsung Exynos, et elle a été fabriquée par lui.
En raison de l'identité particulière de Samsung et du fait que l'écran et la mémoire dépendent de Samsung, le risque est trop élevé et Apple a commencé à soutenir TSMC pour transférer le risque.

Après des rebondissements, TSMC a construit une nouvelle ligne de production, s'est doté d'une équipe professionnelle, et a finalement remporté la fonderie exclusive de la puce A8 d'Apple. Couplé aux ventes sans précédent des iPhone 6 et 6 Plus, TSMC en a beaucoup profité.
Par la suite, les puces de la série A d'Apple ont commencé à être liées à TSMC et ont contribué à son développement grâce à l'inclinaison des ressources. Aujourd'hui, les puces des séries A et M d'Apple sont toutes fondées par TSMC, et elles sont devenues les clients les plus prioritaires, aucun d'entre eux.

▲ TSMC et Apple sont profondément liés. Image tirée de : appuals.com
Dans le même temps, le "mythe" de la haute stabilité de la fonderie de puces TSMC a été créé.
5 nm et 4 nm sont tous deux en retard sur Samsung de TSMC, et ils ne sont pas découragés, mais ont un goujon. Il a annoncé un investissement de 133 000 milliards de wons (environ 800 milliards de yuans), visant le processus 3 nm, et devenant ainsi le plus grand fabricant de SoC au monde.
▲ Image de : Samsung
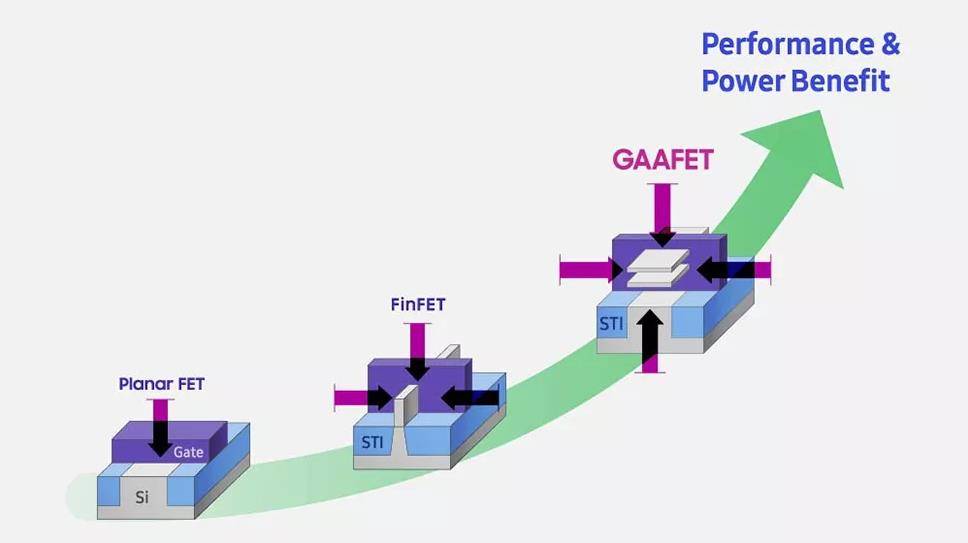
Et, abandonnant la technologie FinFEET, mais un pas vers la technologie des transistors GAAFET, afin de réaliser le dépassement de TSMC, le succès ou l'échec est là.
Pour en revenir au présent, la densité de tranches de 5 nm et 4 nm et la stabilité du processus de Samsung ne sont pas aussi bonnes que TSMC, il y a donc en effet un certain écart lorsqu'il est renvoyé à la puce phare.

Le MediaTek Dimensity 9000 au début de cette année utilise le processus 4 nm de TSMC, le noyau ultra-large Cortex-X2 (3,05 GHz), le grand noyau A710 (2,85 GHz) et le noyau moyen A510 (1,8 GHz) dans le 1+ 3 + 4 architecture à trois clusters. ) sont beaucoup plus élevés que le Qualcomm Snapdragon 8 Gen1.
En théorie, il a des performances plus élevées et une meilleure efficacité énergétique, ce qui en fait une puce phare parfaite.

Cependant, après quelques mois d'attente, lors du lancement des produits phares équipés du Dimensity 9000 , les performances réelles en matière d'efficacité énergétique ne sont finalement pas très différentes de la version Qualcomm.Si vous ne comparez pas attentivement, vous ne le remarquerez peut-être pas du tout. .
Dans cette promotion de haut niveau de Qualcomm, lorsque le Snapdragon 8+ Gen1 utilisant le processus 4 nm de TSMC aura de meilleures performances, je n'avais en fait pas de grandes attentes.

▲ Après la sortie du Snapdragon 8+ Gen1, la "Super Cup" de nombreux fabricants reviendra également, et le point culminant arrive.
Compte tenu de l'overclocking complet de Snapdragon 8+ Gen1 (Cortex-X2 3,2 GHz + A710 2,75 GHz + A510 2,0 GHz), les performances absolues seront améliorées.Quant à l'amélioration, cela dépend de l'ajustement des fabricants, et de même est vrai pour l'efficacité énergétique.
De cette façon, la technologie de processus 4 nm de TSMC ressemble plus à un "tissu de figue" pour les puces phares, couvrant la nouvelle architecture de la version publique extrêmement faible d'Arm.
L'architecture de la version publique Arm est le "coupable"
Au cours des dix dernières années, Arm a modifié 9 versions de l'architecture, et la dernière Armv9 est une mise à niveau relativement importante du jeu d'instructions.
Avec la mise à niveau du jeu d'instructions, Arm a également annoncé la version publique de l'IP CPU, qui est le Cortex-X2 à très gros cœur, le Cortex-A710 à gros cœur (cœur de performance) et le Cortex-A510 à cœur intermédiaire (cœur de performance). .

▲ Image de : Bras
La version publique de l'architecture CPU utilise toujours l'architecture triplex, à savoir 1+3+4. C'est une évolution de la précédente architecture big.LITTLE. L'objectif n'est rien de plus que "le bon noyau pour le bon travail" pour améliorer l'efficacité énergétique.
L'architecture mixte de grands et petits cœurs est maintenant largement utilisée dans les processeurs de bureau et mobiles des architectures X86 et Arm.

▲ Intel 12 adopte également l'architecture hybride P+E.
Version publique d'Arm de l'architecture à trois clusters, si chacun exécute ses propres tâches, le super-core X2 fournit des performances absolues, l'A710 à grand cœur partage les exigences de performances quotidiennes et l'A510 à cœur intermédiaire accomplit les tâches correspondantes avec une faible puissance consommation.
Les trois noyaux, chacun avec son propre but, devraient être inclinés dans la conception et l'invocation.
Cortex-X2, qui est une version entièrement optimisée de X1, double le cache L3 à 8 Mo, augmente la zone de cache, optimise le délai de communication et obtient une amélioration de 16 % de l'IPC (performances également compréhensibles).
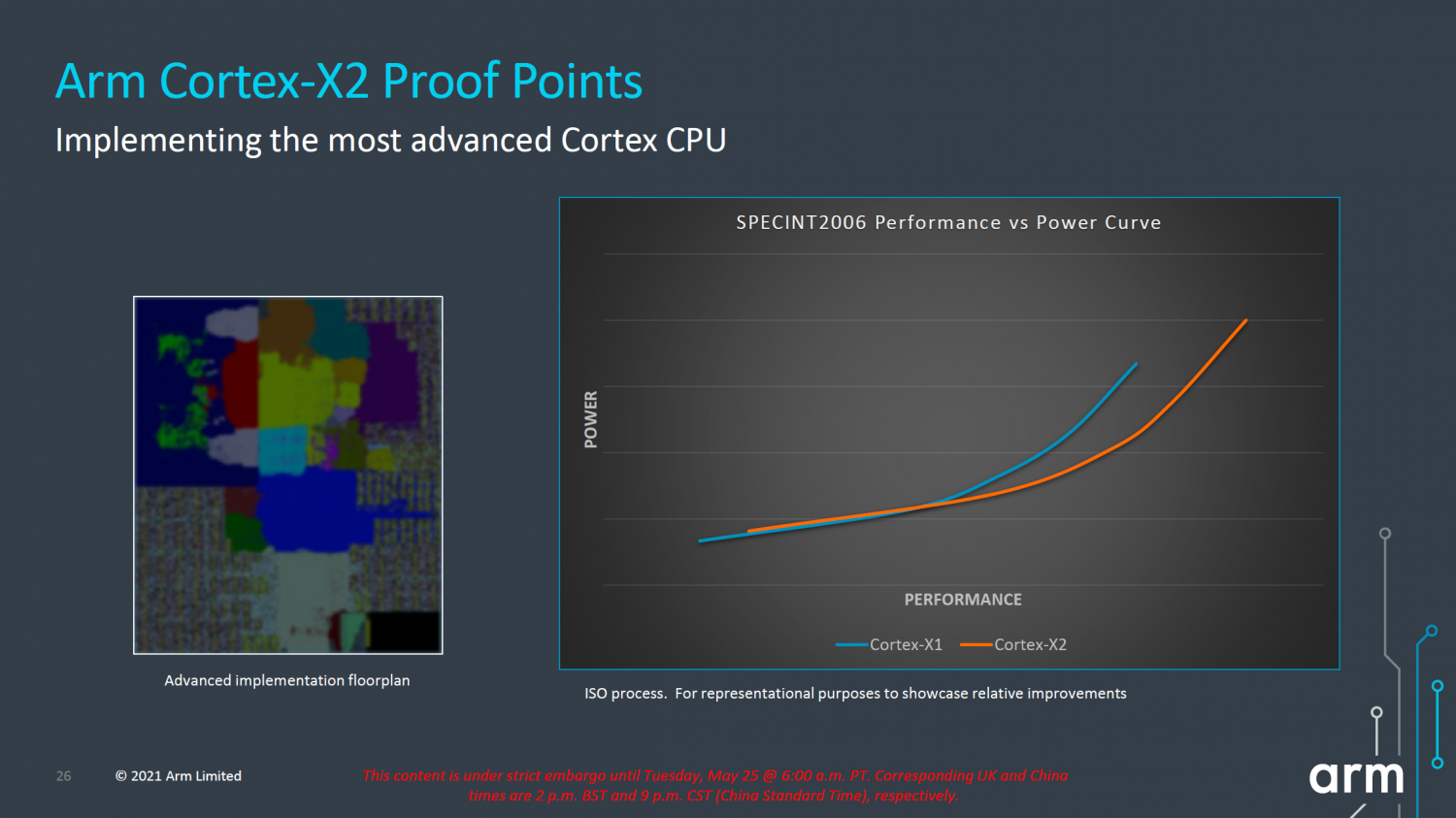
▲ Le noyau super large s'est considérablement amélioré.
Parmi les produits de suivi, le Snapdragon 8Gen1 et le Dimensity 9000 ont de meilleures performances que le Snapdragon 888 lorsque les performances sont pleinement activées et que la consommation d'énergie n'explose pas.
Il est raisonnable d'échanger une consommation d'énergie élevée contre des performances élevées.
Mais le gros cœur et le cœur du milieu ont de gros problèmes, et ce sont ces deux cœurs avec de nouveaux "noms" qui font fréquemment rouler les puces phares.
Cortex-A710 n'utilise pas une architecture plus récente, c'est toujours l'optimisation de l'A78 classique, et il serait peut-être plus juste de l'appeler A79.
Anandtech a qualifié ce nouveau nom de « friandise marketing intéressante », et les performances de l'A710 sont évidentes.
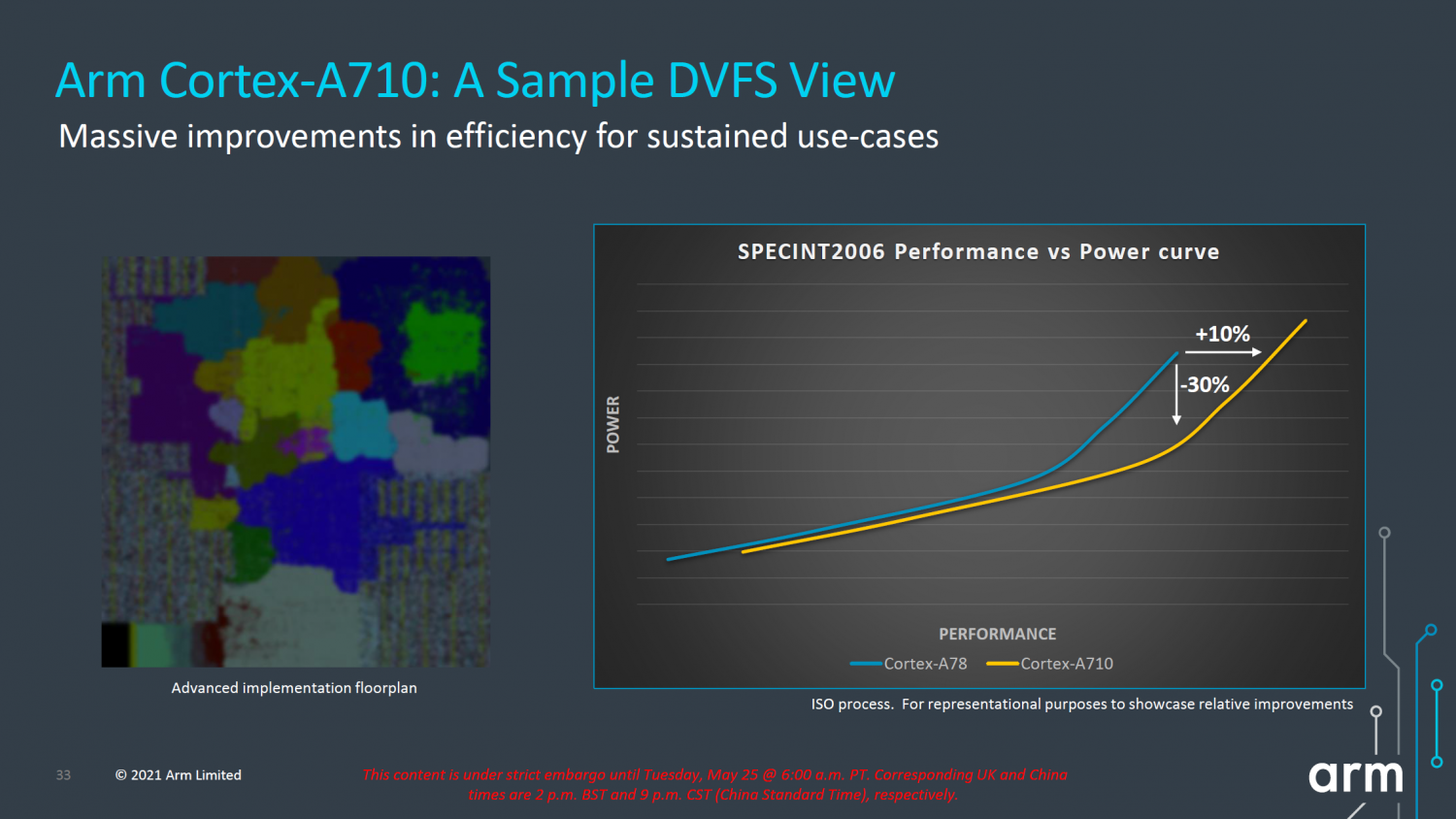
▲ Haute consommation d'énergie et hautes performances Image de : Arm
Sur le PPT d'Arm, l'A710 a une amélioration des performances de 10 %, tout en optimisant également l'efficacité énergétique de 30 %. Cependant, du point de vue de la courbe, les performances supérieures se situent principalement dans la partie à forte consommation d'énergie, et sont obtenues en doublant le cache L3 (8 Mo).
L'optimisation de l'efficacité énergétique ne fait que réduire le débit de distribution du cœur A710 (de 6 à 5), pas de l'optimisation de l'architecture.

▲ Ne pas imiter Image de : ténor
L'A710 est une version optimisée de l'A78, et l'A78 est une version overclockée de l'A77. Pendant quelques années, l'équipe de conception du gros cœur d'Arm explore toujours le potentiel de l'architecture A77, mais après que l'A78 ait atteint la fréquence idéale de l'architecture, le taux d'efficacité énergétique de l'A710 est étonnant, surtout lorsque le système a besoin de hautes performances. mais n'est pas suffisant pour passer au X2 ultra-large. Lorsque le cœur est utilisé, la consommation électrique décolle directement.
Même, Arm utilise directement le 4 nm A78 avec le noyau ultra-large X2, ce qui peut avoir de meilleurs résultats.
En tant que gros noyau, l'A710 a besoin de plus de performances que d'une conception écoénergétique. Le bras est dans la mauvaise direction.

▲ A510 nouvellement conçu Image de : Arm
Relativement parlant, le cœur du Cortex-A510 est une nouvelle architecture de conception. Et contrairement à l'équipe d'Austin qui a conçu les deux cœurs du X2 et de l'A710, il a été conçu par l'équipe de Cambridge.
L'architecture A510 adopte de nombreuses idées de conception innovantes, telles que l'utilisation de "l'hyper-threading" pour partager le cache L2, et en même temps, la bande passante L1, L2 et L3 est augmentée de deux fois celle de l'A55, améliorant ainsi les performances en virgule flottante de 50 % et les opérations sur les nombres entiers bénéficient également d'une amélioration de 35 %.
Cependant, l'A510 utilise toujours "l'exécution séquentielle" plutôt que "l'exécution dans le désordre" des cœurs économes en énergie des puces de la série A d'Apple. Pour éviter la latence des instructions, l'extrémité avant de l'A510 a été augmentée, le cache a été doublé et l'extrémité arrière a été agrandie.
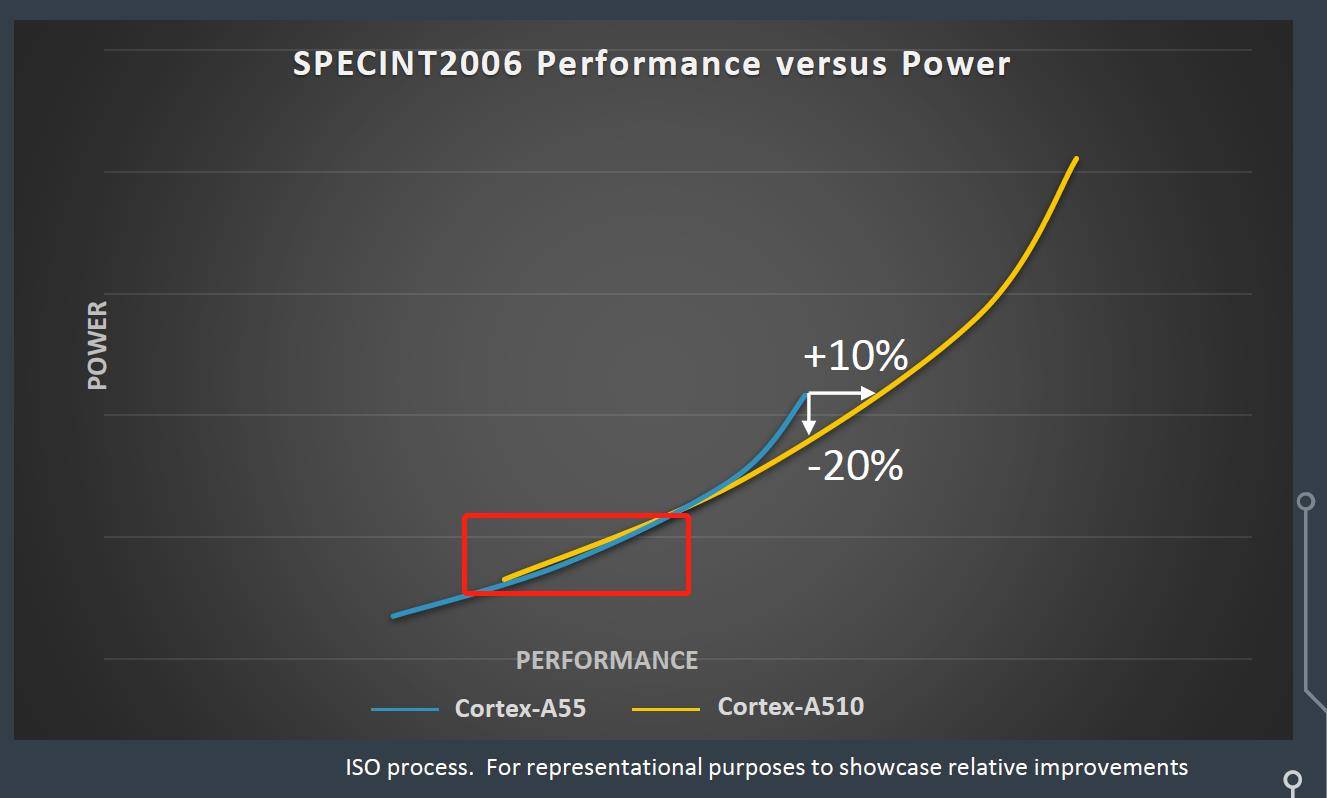
▲ Certains bras honnêtes, notez que l'axe vertical est la consommation d'énergie.
L'idée de conception est également relativement claire, juste pour une meilleure "performance". Juste le résultat final, mais avec peu de succès.
Issu du PPT d'Arm, l'A510 ne peut obtenir de meilleures performances que l'A55 qu'en cas de forte consommation d'énergie.
Cependant, en termes de faible consommation électrique, qui est au centre des préoccupations du noyau d'efficacité énergétique, il est difficile d'ouvrir l'écart avec l'A55, et il y a même des "retours en arrière".

▲ Ne pas imiter Image de : ténor
Dans l'ensemble, parmi les architectures à trois clusters qu'Arm a présentées ces dernières années, seul le cœur ultra-large Cortex-X2 est un changement relativement normal.Le Cortex-A710 à grand cœur se concentre sur l'efficacité énergétique, tandis que le cœur moyen A510 a commencé à se concentrer sur les performances de pointe.
La version publique Arm de l'IP CPU est toujours comme ça, alors ne vous attendez pas à ce que la puce phare soit modifiée sur cette base, à quel point les performances peuvent être bonnes.
Si vous ne voulez pas adopter l'écosystème d'applications 64 bits des grandes usines, vous devez sortir et prendre le "pot"
Après la sortie d'Armv9, le plus grand changement consiste à abandonner complètement les applications 32 bits et à adopter pleinement les applications 64 bits.

En d'autres termes, dans l'architecture à trois clusters, en théorie, tous les cœurs ne prennent plus en charge les applications 32 bits, mais pour l'environnement d'application Android sur le marché chinois, Arm a spécialement approuvé les cœurs de l'A710 pour être compatibles avec 32 bits. applications peu.
C'est-à-dire que lorsque vous ouvrez une application 32 bits, cela forcera l'A710, un cœur très énergivore, à rester actif, même si vous éteignez simplement l'écran pour écouter une chanson.

En fait, depuis Armv8, Arm fait la promotion des applications 64 bits, et le Google Store a également stipulé que les nouveaux programmes doivent prendre en charge les applications 64 bits en août 2019.
Cependant, de nombreux fabricants d'applications nationaux n'ont pas apporté d'améliorations. De nombreuses applications couramment utilisées, telles qu'Alipay, QQ et NetEase Cloud, sont toujours en 32 bits, et il n'y a pas de plan pour le lancement de la version 64 bits.
De plus, les magasins de logiciels de nombreux fabricants nationaux d'Android n'ont pas de partitions d'applications 64 bits correspondantes, et les applications 32 bits et 64 bits sont mélangées.

Cependant, OPPO, vivo et Xiaomi ont déjà commencé à populariser les applications 64 bits.La première étape consiste à limiter les nouvelles applications à 64 bits. En ce qui concerne les applications couramment utilisées, aucune mesure pertinente n'a été publiée pour le moment.
Ces dernières années, les puces phares d'Android ont fréquemment rencontré des problèmes.La raison la plus fondamentale est que la direction de conception de l'architecture de la version publique Arm viole l'intention initiale de l'architecture à trois clusters, et les fabricants nationaux n'adoptent pas activement les applications 64 bits. .
Quant à savoir s'il s'agit de TSMC ou de Samsung, de Dimensity ou de Qualcomm, côté appareil, la différence entre eux est bien inférieure aux chiffres du PPT.
![]()
#Bienvenue pour prêter attention au compte WeChat officiel d'Aifaner : Aifaner (WeChat : ifanr), un contenu plus excitant vous sera apporté dès que possible.
Love Faner | Lien d'origine · Voir les commentaires · Sina Weibo