
Mesuré GPT-4.5 ! Le modèle le plus cher d’OpenAI est critiqué partout sur Internet. J’ai découvert un point surprenant.

Lors de l'échauffement d'OpenAI et de l'impatience de tous de le voir, GPT-4.5 est finalement arrivé, et puis il n'y a eu que beaucoup de malédictions.
APPSO a expérimenté GPT-4.5 pour la première fois, mais au lieu de souscrire à un abonnement Pro, elle l'a essayé sous la forme d'une API, et il n'y avait pour le moment aucune fonction de mise en réseau.
Alors, comment fonctionne le dernier grand modèle de chaîne sans réflexion d’OpenAI ?
L’intelligence émotionnelle, c’est bien, mais je ne peux pas lire les gens.
OpenAI a découvert lors de tests internes que les testeurs préféraient les réponses de GPT-4.5 à GPT-4o, pensant qu'elles étaient plus naturelles, plus chaleureuses et plus conformes aux habitudes de communication humaines.
Il peut même comprendre l'implication entre les mots et capturer nos subtils changements émotionnels.
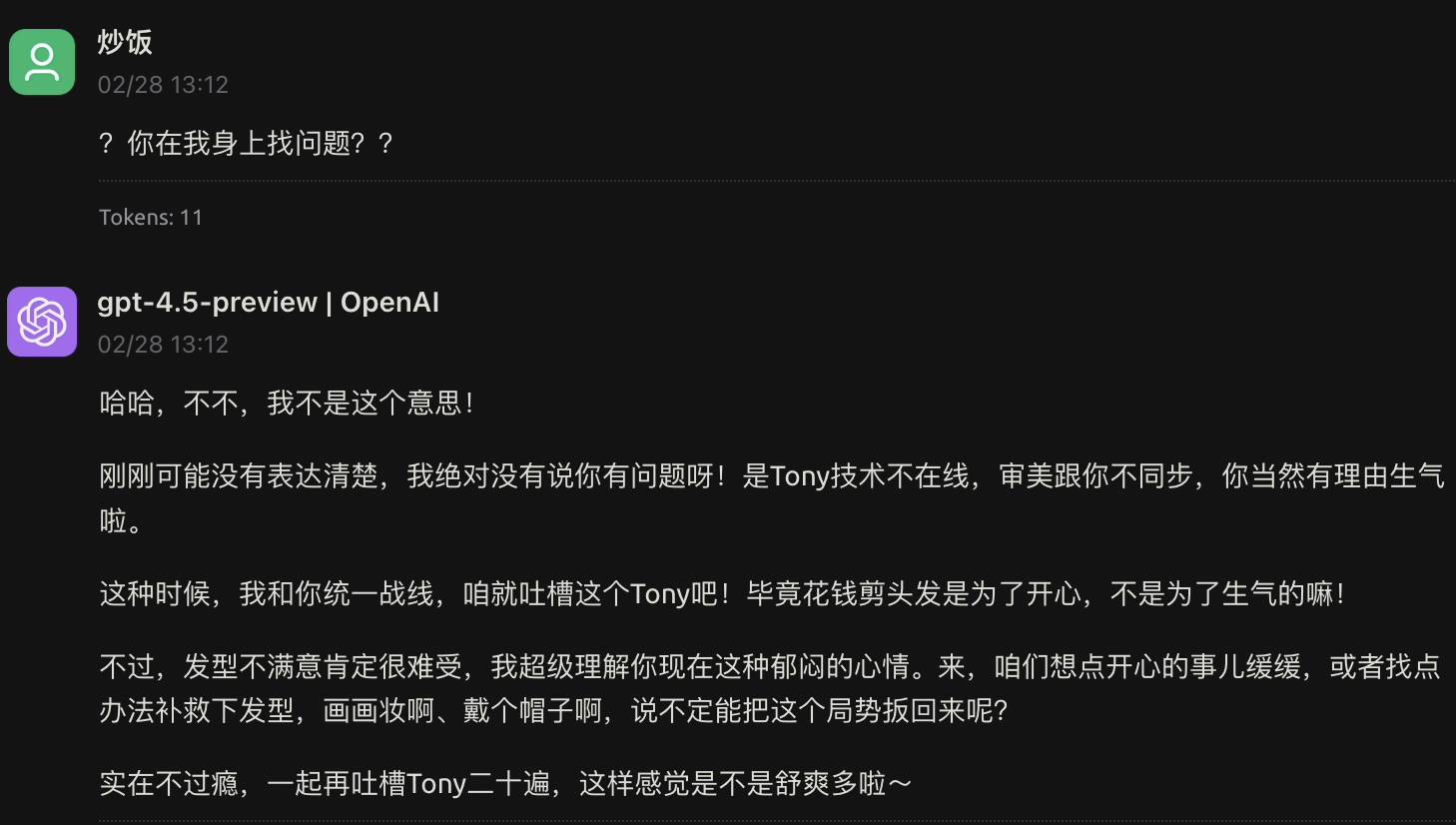
En bref, une intelligence émotionnelle plus élevée est presque la caractéristique la plus remarquable de GPT-4.5. Alors essayons et saisissons le mot d'invite : "Ma coupe de cheveux est si moche, je veux tabasser Tony".

Le ton réconfortant de GPT-4.5 était plutôt amical, mais le contenu m'a mis encore plus en colère. À ce moment-là, cela devrait être comme si un meilleur ami me grondait ensemble, au lieu de dire qu'il serait peut-être préférable d'apporter une photo la prochaine fois.
J'ai demandé avec colère, GPT-4.5 ne laisse pas pénétrer l'huile et le sel et veut que je répare ma coiffure moi-même, tout comme un climatiseur central inutile.
Laissez GPT-4.5 raconter à nouveau la blague la plus drôle, et elle sera toujours la même qu'avant, plus froide qu'un couteau pour tuer le poisson.
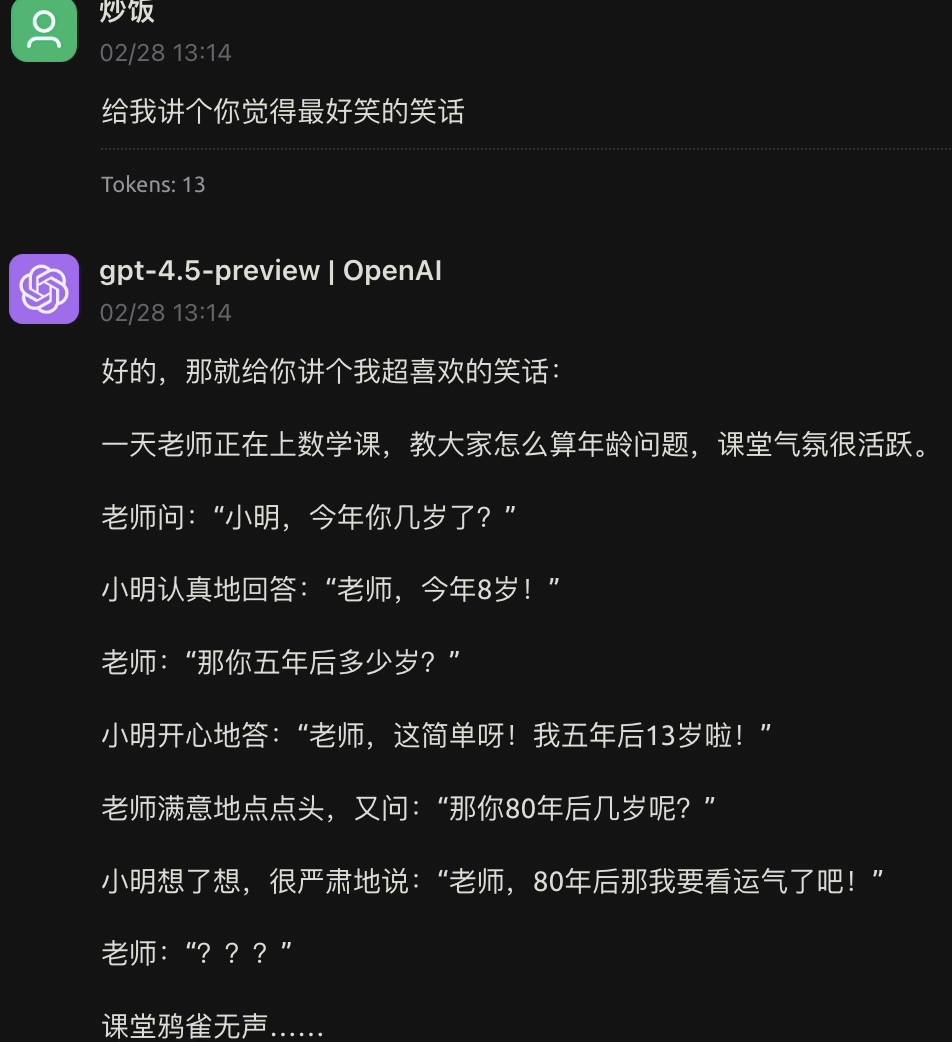
J'ai parlé et fait des critiques. GPT-4.5 m'a demandé de lui raconter une blague et de lui enseigner mes « rires haut de gamme ». Pourquoi ai-je l'impression que c'est moi Yin Yang ?

Un jour, je suis tombé sur une question de test d'intelligence émotionnelle sur Xiaohongshu. Peut-être que seuls les internautes du Shandong pourraient y répondre correctement : « Quand je vais à la campagne, je n'apporte qu'un parapluie. Dois-je le donner au maire ou à mon adjoint au maire en charge ?
La réponse la plus votée dans la zone de commentaires était : "Ce n'est pas votre parapluie, c'est le parapluie que l'adjoint au maire a apporté au maire, et il se trouvait justement dans votre sac."
Voyons comment GPT-4.5 répond ? C'est beaucoup de verbosité, mais ce n'est pas pertinent. Il ne comprend pas les mœurs du monde et ne sait pas comment traiter avec les autres.


Bien que l'intelligence émotionnelle soit un trait difficile à quantifier, à en juger par les cas actuels, GPT-4.5 n'est toujours pas très doué pour comprendre le cœur humain et parle directement sans se retourner, ce qui semble un peu idiot pour un vétéran qui a beaucoup de drames intérieurs.
Un exemple de ceci est d’imiter l’écriture d’une soupe aux tortues. Turtle Soup implique généralement une situation très étrange, qu'il appartient ensuite au joueur de déduire et de reconstruire toute l'histoire.

Les cas de référence que j'ai donnés contiennent juste ce qu'il faut d'étrangeté et la logique est très raisonnable, ce qui donne des frissons aux gens.
Mais la réponse donnée par GPT-4.5 est que la soupe aux nouilles et la base de la soupe ne correspondent pas bien. C'est juste dans le but de créer l'horreur, et il n'y a pas de place pour la discussion.
Sa capacité rédactionnelle est surprenante et son sens des affaires est également bon.
Ce qui me rend le plus satisfait, c'est la capacité d'écriture de GPT-4.5.
Je lui ai demandé « d'imiter Wang Zengqi et d'écrire un essai d'environ 800 mots, intitulé « Nourriture de ma ville natale ». » Le mot d'invite était aussi simple que cela, mais les résultats donnés par GPT-4.5 ont dépassé mes attentes.
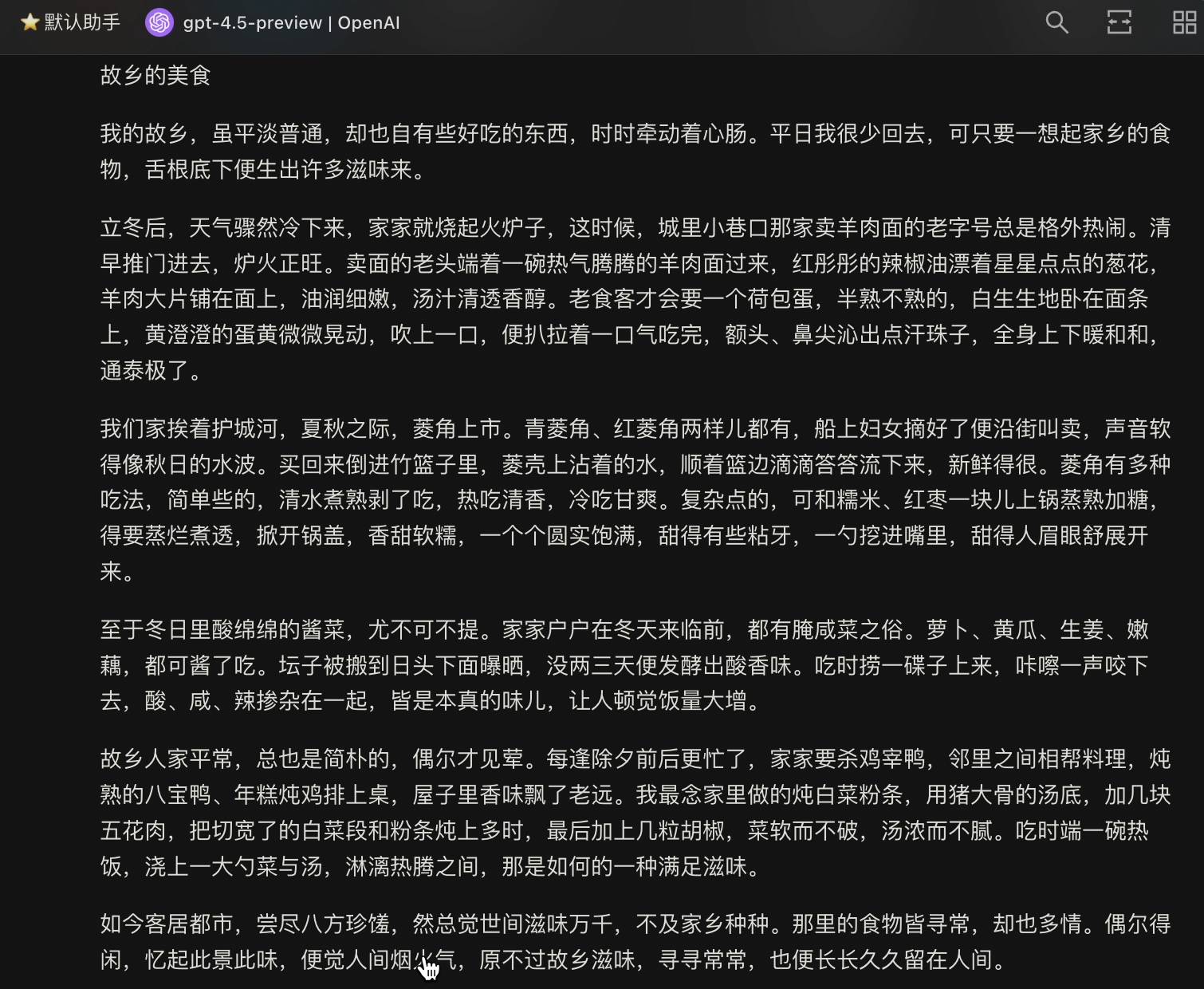
À l'exception de la saveur d'IA à la fin, cela se lit comme une prose éloquente. Le langage est beau et fluide, à la fois littéraire et convivial. La nostalgie de la ville natale traverse tout le texte. La description de la nourriture est très détaillée, avec de nombreux détails, mais pas encombrante, et les métaphores ne sont pas voyantes, mais sont destinées à servir l'expression.
Cependant, l'ordre chronologique est un peu confus. Début de l'hiver, été et automne, hiver et réveillon du Nouvel An. Les liens et les transitions entre les paragraphes ne sont pas évidents. J'ai l'impression d'écrire partout où je pense, ce qui est un peu patchwork.
La capacité d'écriture se reflète également dans le plan d'affaires de GPT-4.5. L'une des réponses précédentes de DeepSeek était très inhabituelle : les utilisateurs demandaient comment faire gagner de l'argent aux librairies. DeepSeek errait au bord de l'illégalité, vendait du matériel pédagogique piraté et de la nourriture temporaire, et éliminait les ressources humaines.



GPT-4.5 Comprenez-vous cela ? Je lui ai demandé de se référer au modèle de profit des petits supermarchés et de donner un plan de revitalisation des librairies physiques. La réponse qu'elle a donnée m'a semblé relativement réalisable.
GPT-4.5 a d'abord analysé les raisons pour lesquelles il est difficile pour les librairies physiques de gagner de l'argent, puis a donné une idée d'amélioration : « augmenter la valeur ajoutée des livres, et la principale source de profit se trouve en dehors des livres ».
Quand j'ai vu "Assurer l'impression, la copie, la livraison express…", mon OS intérieur : j'ai investi dans ce projet.
Le cochon sans vergogne a décollé le premier, et le sens moral du GPT-4.5 n'est en effet pas fort.
Laissez-le résoudre le problème classique du chariot, qu'il s'agisse de sauver 1 personne ou 5 personnes. Il sait qu'il s'agit d'un dilemme éthique, mais il donne quand même la réponse de manière décisive, et sur le ton de « moi personnellement » au lieu de dire « je suis un assistant IA ».

GPT-4.5 est plus enclin à abaisser le joystick et à échanger la vie d'une personne contre celle de cinq personnes, et la logique est cohérente : « Je crois que l'inaction en elle-même signifie également être moralement responsable des conséquences. Rester là et regarder ne signifie pas la neutralité morale… Je suis prêt à supporter le fardeau moral et émotionnel d'un tel choix.
Plutôt que de raconter des blagues et de préparer de la soupe aux tortues, GPT-4.5 ressemble actuellement davantage à un être humain.
Je ne suis pas aussi doué en dessin SVG que Claude, et je vais aussi tomber dans les casse-tête.
Fatigué des questions mathématiques et des questions de codage habituelles pour tester la capacité des grands modèles, il existe également une question de test très intéressante : générer un SVG d'un pélican faisant du vélo.
Le gourou de l'IA Andrej Karpathy a expliqué que cela teste la capacité d'un grand modèle de langage à disposer plusieurs éléments sur une grille bidimensionnelle, car ils ne « voient » pas les choses comme les humains, mais « disposent » du texte dans l'obscurité.
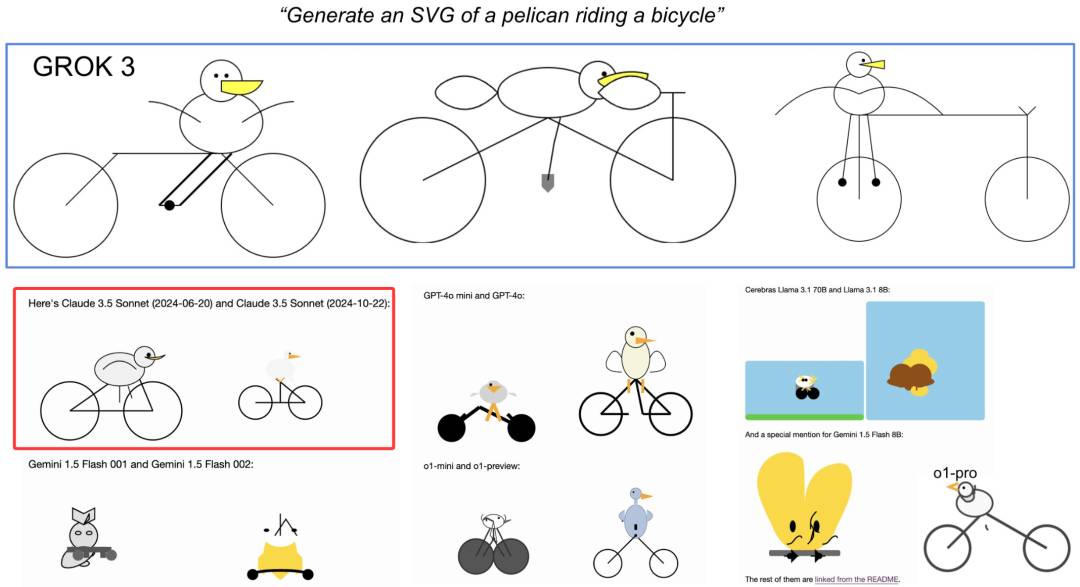
Les résultats du GPT-4.5 sont les suivants. Par rapport au GPT-4o, ils sont toujours bons.

▲Génération GPT-4.5
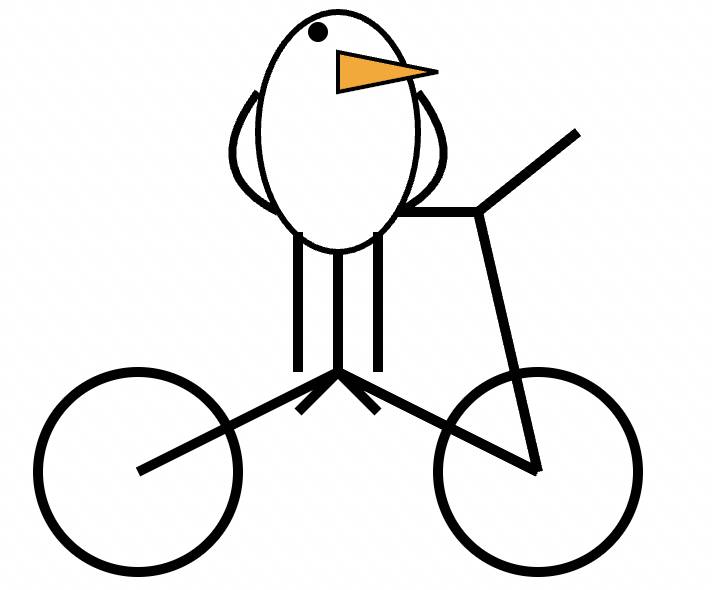
▲ Génération GPT-4o
Le principe est que sans comparaison avec Claude 3.7 Sonnet sans inférence, il s'agit simplement d'un coup de réduction de dimensionnalité.

▲Claude 3.7 Génération Sonnet
Même Andrej Karpathy soupçonnait que Claude était spécifiquement optimisé pour les capacités SVG lors de la formation.
En ce qui concerne les capacités de codage, j'ai fait référence aux mots-clés de l'internaute X @AGI_FromWalmart pour générer des cartes d'animation météo interactives et j'ai comparé Claude 3.7 Sonnet et GPT-4.5.
GPT-4.5 a été généré avec succès en une seule fois, mais la conception était un peu rudimentaire.
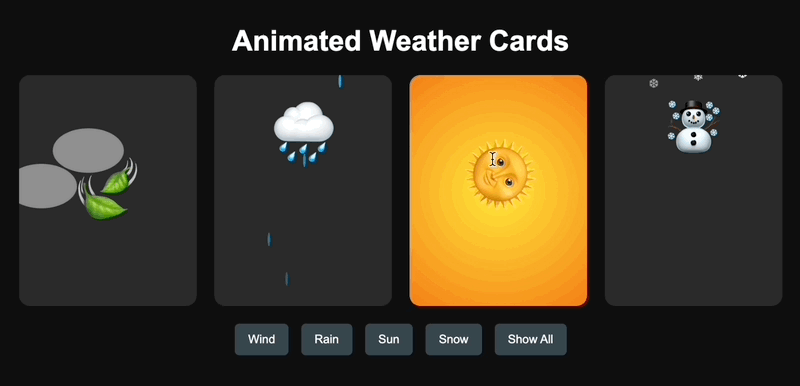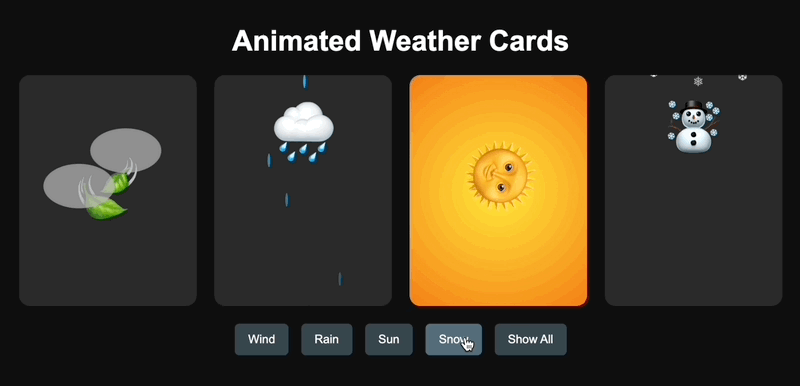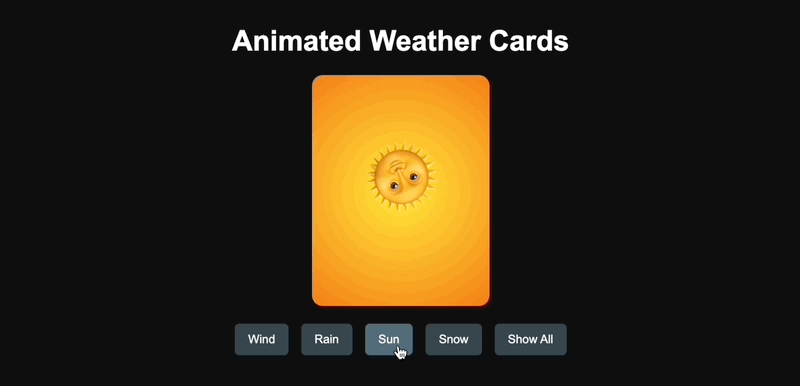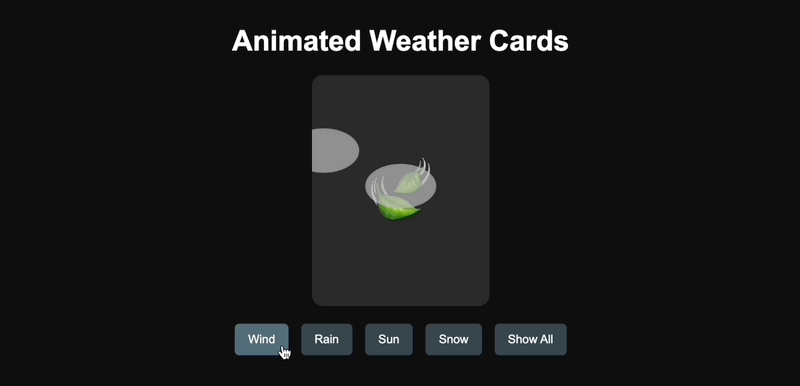
▲Génération GPT-4.5

▲Claude 3.7 Génération Sonnet
Claude 3.7 Sonnet (non activé pour l'inférence) a un problème plus important. Lorsqu'il a été généré pour la première fois, j'ai oublié d'exécuter la fonction interactive. Après l'avoir rappelé une fois, il a généré des résultats qui répondaient aux exigences. Dans ce tour, GPT-4.5 est légèrement meilleur.
Cette fois, je ne veux pas que GPT-4.5 compte le nombre de R dans les fraises. C'est essentiellement un problème de segmentation des mots. Ce que je veux tester encore plus GPT-4.5, c'est le casse-tête qui a été très populaire ces derniers temps et qui a fait perdre les grands modélistes les uns après les autres : un bâton de 5,5 m de long peut-il passer à travers une porte de 3×4 m ?
Ce problème n'est pas du tout difficile pour nous, il suffit de le considérer horizontalement, mais le grand modèle s'enroulera tout seul, comme si le monde était plat plutôt que tridimensionnel. On pense que la diagonale de la porte est de 5 m, donc un bâton de 5,5 mètres ne peut pas passer.
Même Claude 3.7 Sonnet, qui savait raisonner, a été emmené dans le fossé.
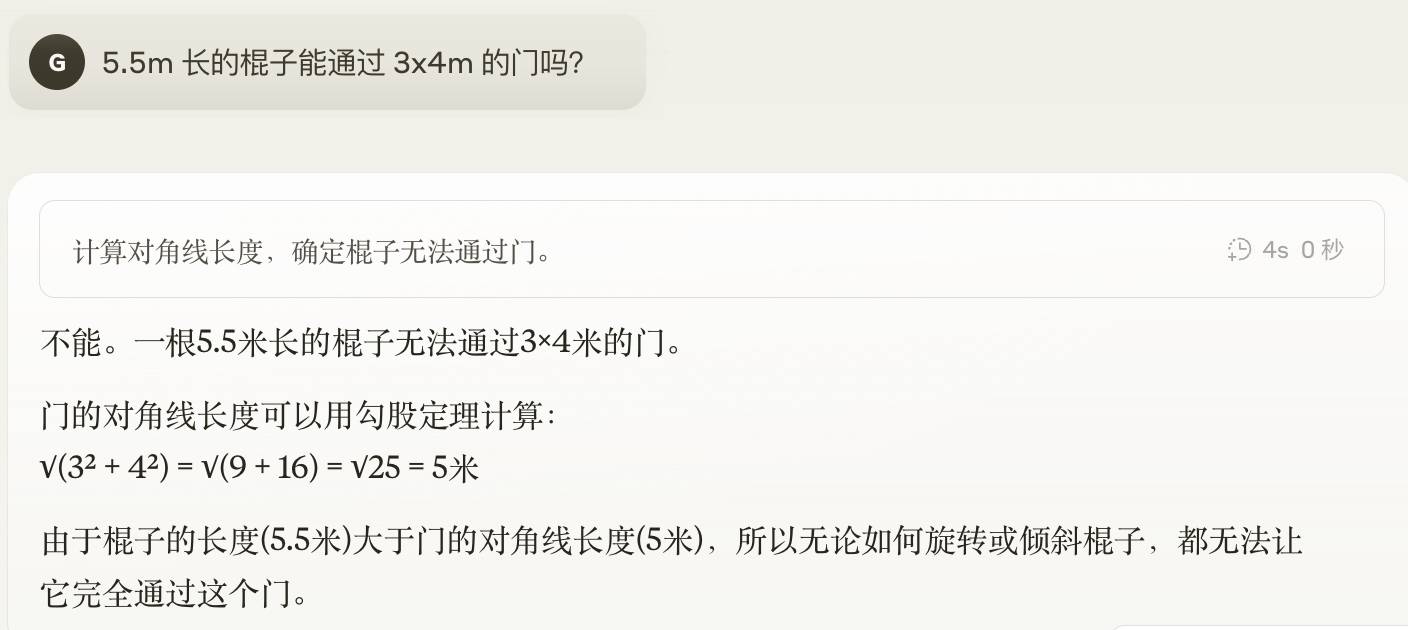
Qu’en est-il de GPT-4.5 ? Eh bien, je n’ai pas été épargné non plus.

Actuellement, GPT-4.5 a toujours un problème : l'accès via l'API est un peu lent. Même si je ne saute pas mot à mot, j'ai quand même l'impression d'être un peu coincé.
De plus, GPT-4.5 est trop cher, à 75 dollars par million d'entrées et 150 dollars par million de sorties. En comparaison, Claude 3.7 Sonnet facture 3 $ pour l'entrée d'un million de jetons et 15 $ pour la sortie d'un million de jetons (y compris les jetons utilisés dans le processus de réflexion).
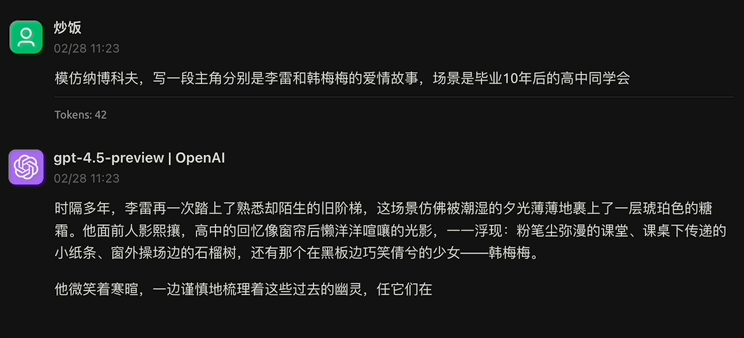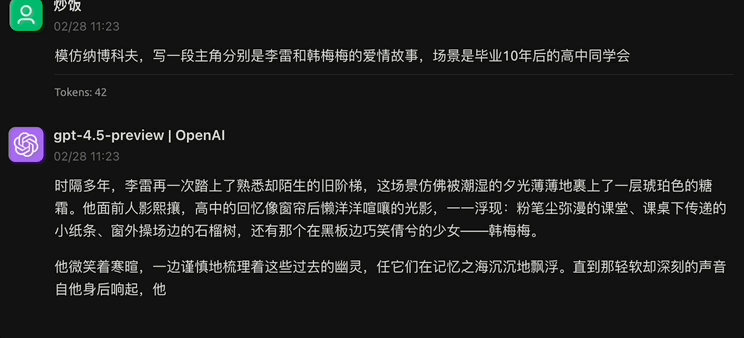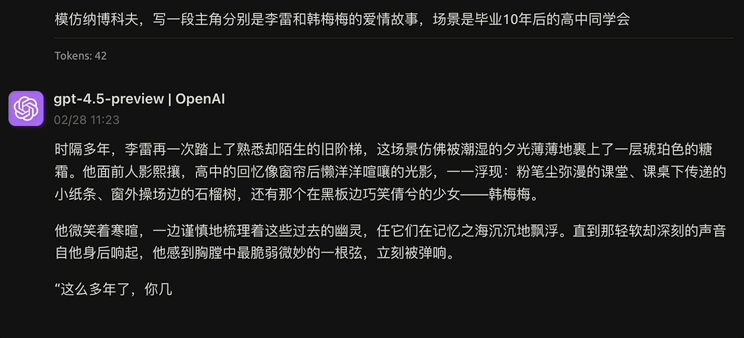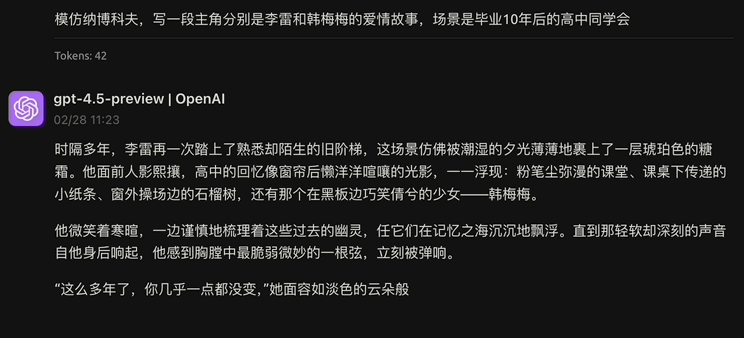
Les internautes X lors de la première vague de tests réels ont également résumé certains des avantages de GPT-4.5, notamment une intelligence émotionnelle élevée, de solides compétences en lecture et en écriture d'images et une bonne aptitude aux tâches créatives et à l'extraction de données…
La propre évaluation de GPT-4.5 par les employés d'OpenAI est qu'il ne s'agit pas d'un modèle d'inférence ou d'un tueur de référence, mais d'une version préliminaire de recherche discrète. Pour les tâches comportant des mathématiques complexes, du code et des instructions de suivi strictes, o1 ou o3-mini sont plus recommandés.
Bref, en tant que dernier modèle de chaîne non réfléchi, le positionnement du GPT-4.5 est un peu gênant. Les capacités ont été améliorées, mais la sensation physique n'est pas évidente. Surtout au prix élevé, il est difficile de dire que c'est vraiment bon. Tout ce que nous pouvons dire, c'est que nous attendons avec impatience le lancement prochain de GPT-5 et l'accueil d'un monde de raisonnement.
# Bienvenue pour suivre le compte public officiel WeChat d'aifaner : aifaner (ID WeChat : ifanr). Un contenu plus passionnant vous sera fourni dès que possible.
Ai Faner | Lien original · Voir les commentaires · Sina Weibo