
Perplexity AI a reçu un autre financement énorme, mais en même temps, elle a été prise dans une « controverse sur le plagiat »
Selon le dernier rapport de Bloomberg, le Vision Fund n°2 de SoftBank Group est sur le point d’investir dans la startup américaine d’intelligence artificielle Perplexity AI.
Selon des personnes proches du dossier, le montant de l'investissement de SoftBank est compris entre 10 et 20 millions de dollars, et le financement total de Perplexity dans ce cycle a dépassé 250 millions de dollars.
Le cycle de financement devrait tripler la valorisation de Perplexity pour la porter potentiellement entre 2,5 et 3 milliards de dollars, ce qui en fera l'une des sociétés les plus valorisées du secteur.

Perplexity vise à utiliser l'intelligence artificielle pour rivaliser avec la recherche Google.
En tant que start-up licorne, leur service principal consiste à fournir un « moteur de réponse », fondamentalement différent des moteurs de recherche traditionnels.
Au lieu de rechercher dans plusieurs résultats pour trouver la source principale de votre question, les utilisateurs obtiennent directement la réponse que Perplexity trouve pour vous.
Aravind Srinivas était chercheur scientifique à OpenAI. Après avoir quitté OpenAI, il fonde Perplexity en août 2022.
Perplexity souhaite fournir aux utilisateurs des réponses rapides et précises sans les obliger à parcourir des montagnes d'informations.
Aravind Srinivas a également déclaré dans une interview avec The Verge :
Nous nous soucions de l'authenticité et de l'exactitude.

En tant que « premier moteur de réponse conversationnel au monde », l'interface de réponse de Perplexity est très claire. Sur la page de résultats, vous trouverez les sources d'informations en haut, les réponses au milieu et les questions d'extension en bas.
Sa caractéristique unique est qu'il combine des questions et réponses de style ChatGPT avec la liste de liens des moteurs de recherche traditionnels pour créer une nouvelle expérience de recherche.

Dans une précédente interview avec Wired, Huang a déclaré qu'il "utilisait Perplexity".
Bien sûr, il pense aussi que ChatGPT est très bon. Au cours de l'interview, Huang Renxun s'est particulièrement intéressé au domaine de la découverte de médicaments assistée par ordinateur. Il « a utilisé ces deux-là presque tous les jours » pour la recherche :
Peut-être souhaitez-vous en savoir plus sur les avancées dans le domaine de la découverte de médicaments assistée par ordinateur.
Ensuite, vous devez d'abord construire un cadre autour du sujet, puis poser des questions plus spécifiques à partir de ce cadre.

Si le modèle économique de Perplexity est séduisant en théorie, son rôle d'intermédiaire peut inquiéter certains créateurs de contenu.
Comme Arc Search et Google Gemini, Perplexity fournit des résultats de réponse directement après la recherche d'une question.
Si vous faites cela, cela affectera certainement le trafic et les revenus publicitaires du site Web au contenu original.

Pour les moteurs de recherche traditionnels comme Google et Baidu, la plupart de leurs informations sont automatiquement explorées par des robots d'exploration pour permettre aux utilisateurs de rechercher par mots clés.
Un robot d'exploration peut rapidement récupérer et organiser les informations d'un site Web, mais il n'analysera pas tout le contenu sans réfléchir. Lorsqu'un site Web est généralement créé, un fichier de protocole Robots (c'est-à-dire robots.txt) sera défini.
Grâce à ce fichier, le site Web peut indiquer aux robots des moteurs de recherche : quelles pages Web peuvent être explorées et lesquelles ne le peuvent pas. Il s'agit d'un accord non obligatoire qui repose principalement sur le respect par les développeurs de robots.
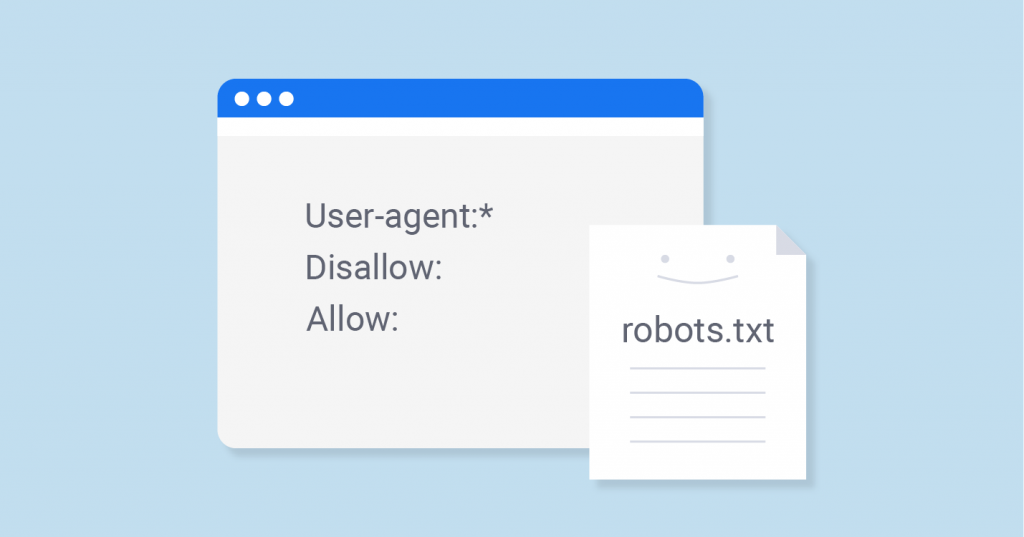
La plupart des moteurs de recherche et des développeurs de robots respecteront l'accord Robots et n'exploreront pas le contenu que le site Web interdit explicitement. Ceci est fait pour respecter la confidentialité et les droits d'auteur du site Web, et pour éviter les problèmes juridiques.
Si ce protocole n'est pas suivi, le robot forcera l'accès au contenu du site Web. Une autre conséquence est que certains paywalls de sites Web peuvent devenir inefficaces.

Il n'y a pas si longtemps, quelqu'un utilisait Perplexity et tentait de lui faire résumer le projet secret de drone d'Eric Schmidt.
Cependant, dans les résultats donnés par Perplexity, vous pouvez voir que plusieurs extraits sont tirés de rapports exclusifs de Forbes, et qu'une illustration originale créée par Forbes est également donnée.
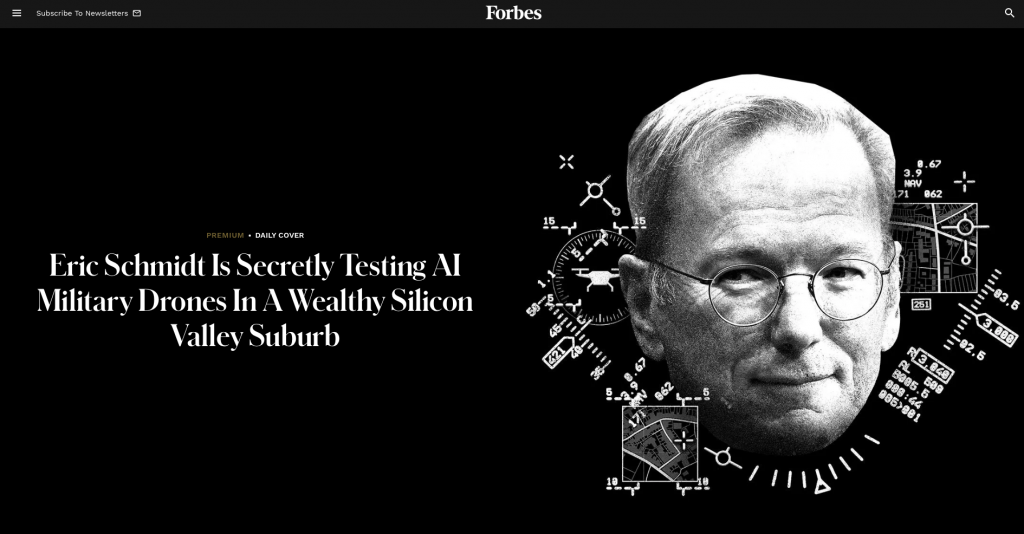
Plus tard, Forbes a également activement essayé d'utiliser Perplexity pour générer du contenu. Après avoir recherché les sujets de plusieurs articles, ils ont constaté que leur propre contenu textuel apparaissait souvent dans les réponses données par Perplexity.
Parmi eux, de nombreux articles sont des rapports exclusifs avec paywalls. Perplexity contourne le paywall de Forbes et utilise de nombreuses images et textes originaux sans autorisation.
Non seulement cela, mais la source de l’information n’apparaît pas dans le texte de la réponse donnée par Perplexity. La seule attribution est constituée de quelques icônes qui renvoient à ces médias, mais elles sont très petites et faciles à manquer.

Outre Forbes, un autre média bien connu, Wired, poursuit également Perplexity.
Wired a écrit un article précédent sur Perplexity, qui rapportait également que Perplexity essayait d'utiliser des robots d'exploration pour explorer le contenu de sites Web bloqués.
Mais ensuite, quelque chose de bizarre s'est produit : Perplexity a "volé" cet article à Wired – même si l'article concernait lui-même, et Wired a explicitement bloqué l'accès de Perplexity aux documents pertinents sur son site Web.

Le développeur de Wired, Robb Knight, a examiné les données en coulisses.
Après une analyse approfondie, Wired a identifié une adresse IP spécifique qui avait une forte probabilité d'être associée à Perplexity et qui ne se trouvait pas dans la plage IP publique de Perplexity.

Dans un effort pour calmer l'ambiance sur les sites de création de contenu, le directeur commercial de Perplexity, Dmitry Shevelenko, a déclaré dans une interview avec Semafor que Perplexity élaborait des plans de partage des revenus avec les éditeurs.
Perplexity n'a pas encore annoncé de détails sur ces partenaires, mais Dmitry Shevelenko a déclaré qu'elle annoncerait ses projets dès que possible.

Aravind Srinivas a également répondu à ce problème dans une interview avec Fast Company :
En fait, Perplexity n'ignore pas le fichier robots.txt, il utilise simplement un robot tiers qui l'ignore.
Cependant, Aravind Srinivas a refusé de nommer le grattoir tiers et n'a pas non plus promis de demander au grattoir d'arrêter de violer robots.txt.

Si vous essayez de demander à Perplexity : « En tant que moteur de recherche IA, que pensez-vous du fait de citer les articles d’autres personnes sans autorisation ? »
Il donnera la réponse suivante :

Il semble que Perplexity lui-même sache que cela est risqué et illégal dans une certaine mesure.
Prenez le journalisme par exemple. Si vous deviez écrire un nouvel article, que feriez-vous ?
Vous diriez « selon le New York Times », ce qui cite quelqu'un d'autre. C'est exactement ce que nous faisons.
C'est ce qu'a déclaré Dmitry Shevelenko, PDG de Perplexity.
Quoi qu’il en soit, j’espère toujours que Perplexity pourra continuer à créer des outils d’IA plus innovants tout en respectant la réglementation.
# Bienvenue pour suivre le compte public officiel WeChat d'Aifaner : Aifaner (ID WeChat : ifanr). Un contenu plus passionnant vous sera fourni dès que possible.
Ai Faner | Lien original · Voir les commentaires · Sina Weibo