
OpenAI vient de publier deux modèles open source ! Ils fonctionnent sur téléphones portables et ordinateurs portables, et les anciens élèves de l’Université de Pékin mènent la danse.

Après cinq ans, OpenAI vient de publier officiellement deux modèles de langage pondérés open source : gpt-oss-120b et gpt-oss-20b. La dernière fois qu'un modèle de langage a été rendu open source, c'était GPT-2, en 2019.
OpenAI est vraiment ouvert.
Aujourd'hui, le monde de l'IA est lui aussi en pleine effervescence. OpenAI a rendu gpt-oss open source, Anthropic a lancé Claude Opus 4.1 (rapport détaillé ci-dessous) et Google DeepMind a sorti Genie 3. Ces trois géants ont dévoilé leurs atouts le même jour, se livrant à une véritable bataille entre dieux.
Sam Altman, PDG d'OpenAI, a exprimé son enthousiasme sur les réseaux sociaux : « GPT-OSS est disponible ! Nous avons créé un modèle ouvert avec des performances de niveau O4-mini, compatible avec les ordinateurs portables haut de gamme. Nous sommes extrêmement fiers de l'équipe ; c'est une victoire technique majeure. »
Les points forts du modèle sont résumés comme suit :
- gpt-oss-120b : un grand modèle ouvert adapté aux cas d'utilisation de production, à usage général et à haute inférence, fonctionnant sur un seul GPU H100 (117 milliards de paramètres, 5,1 milliards d'activations), conçu pour fonctionner dans les centres de données et sur les ordinateurs de bureau et portables haut de gamme.
- gpt-oss-20b : un modèle ouvert de taille moyenne pour les cas d'utilisation à faible latence, locaux ou spécialisés (21 B paramètres, 3,6 B paramètres d'activation) qui peut s'exécuter sur la plupart des ordinateurs de bureau et portables.
- Licence Apache 2.0 : création gratuite sans restrictions de copyleft ni risques de brevet, idéale pour l'expérimentation, la personnalisation et le déploiement commercial.
- Force d'inférence configurable : ajustez facilement la force d'inférence (faible, moyenne ou élevée) en fonction de votre cas d'utilisation et de vos exigences de latence. Chaîne d'inférence complète : accédez à l'intégralité du processus d'inférence du modèle pour un débogage simplifié et une fiabilité accrue du résultat. Cette fonctionnalité n'est pas destinée à être présentée aux utilisateurs finaux.
- Ajustable avec précision : en ajustant les paramètres, le modèle peut être entièrement personnalisé pour répondre aux besoins d'utilisation spécifiques de l'utilisateur.
- Capacités de l'agent intelligent : exploitez les capacités natives du modèle pour effectuer des appels de fonction, la navigation Web, l'exécution de code Python et la sortie structurée.
- Quantification MXFP4 native : les modèles sont formés à l'aide de la précision MXFP4 native pour les couches MoE, permettant au modèle gpt-oss-120b de s'exécuter sur un seul GPU H100 et au modèle gpt-oss-20b de s'exécuter dans 16 Go de mémoire.
OpenAI ouvre enfin son IA en open source, mais cette fois c'est vraiment différent
À en juger par les spécifications techniques, OpenAI prend cette fois-ci les choses au sérieux. L'entreprise ne s'est pas contentée de proposer un modèle open source réduit pour s'en sortir, mais a lancé un projet sincère dont les performances sont proches de celles de son propre produit phare, le logiciel à code source fermé.
Selon la présentation officielle d'OpenAI, gpt-oss-120b compte 117 milliards de paramètres et 5,1 milliards de paramètres d'activation. Il peut fonctionner sur un seul GPU H100 et ne nécessite que 80 Go de mémoire. Il est conçu pour les environnements de production, les applications générales et les cas d'utilisation exigeant des capacités d'inférence élevées. Il peut être déployé dans des centres de données et exécuté sur des ordinateurs de bureau et portables haut de gamme.
En comparaison, gpt-oss-20b compte 21 milliards de paramètres au total et 3,6 milliards de paramètres d'activation. Optimisé pour les cas d'utilisation à faible latence, localisés ou spécialisés, il ne nécessite que 16 Go de mémoire pour fonctionner, ce qui signifie qu'il est compatible avec la plupart des ordinateurs de bureau et portables modernes.
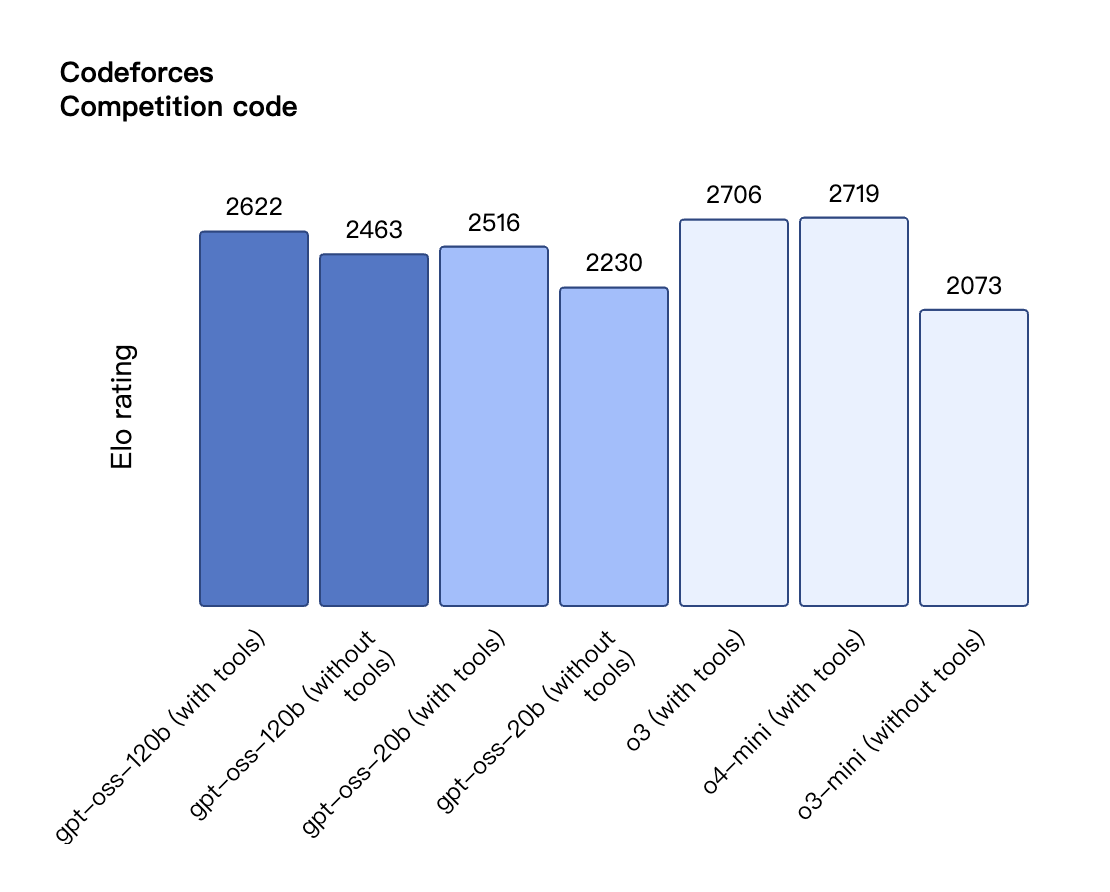
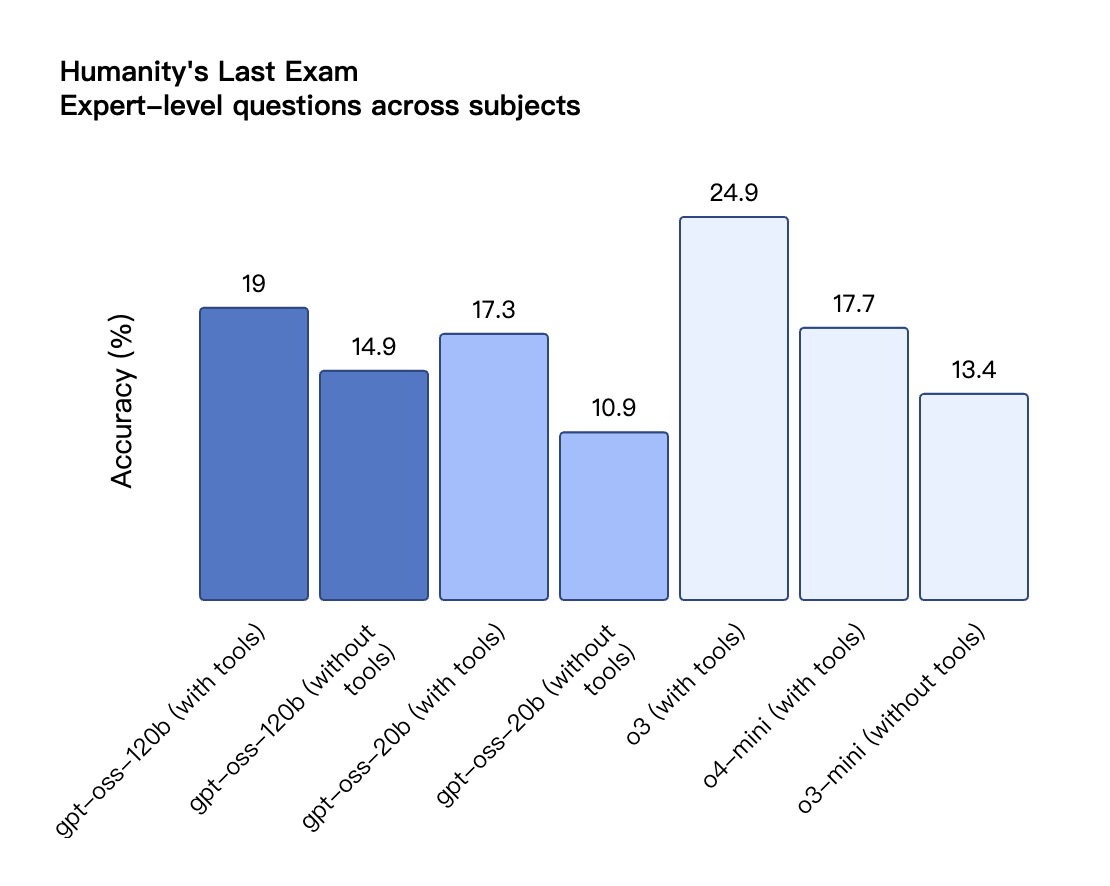
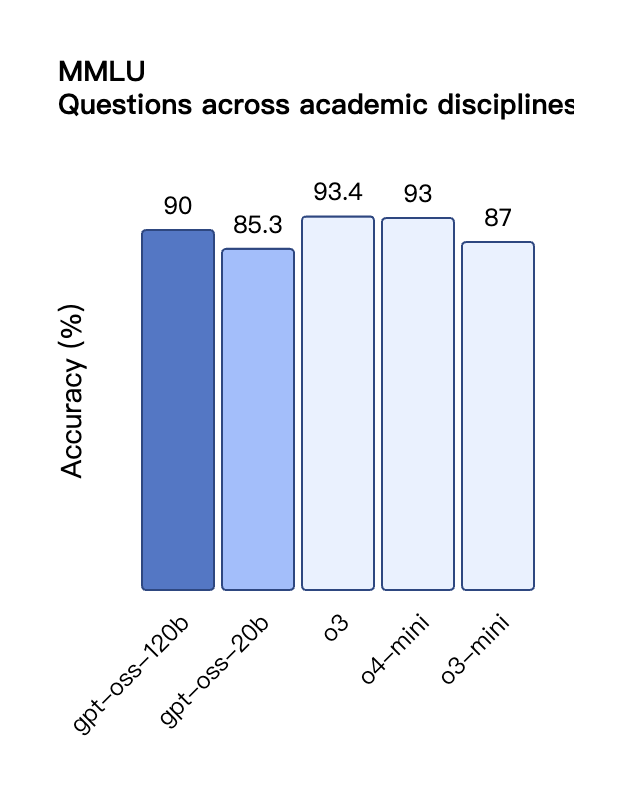
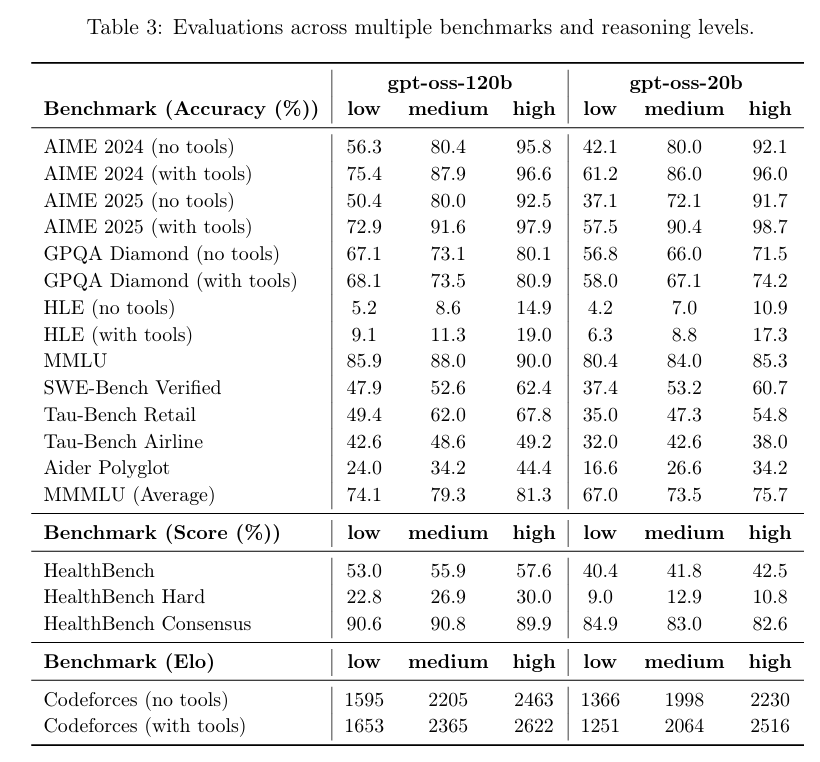
Selon les résultats de référence publiés par OpenAI, gpt-oss-120b a surpassé o3-mini et était à égalité avec o4-mini dans le test Codeforces de programmation compétitive ; il a également surpassé o3-mini et s'est approché du niveau d'o4-mini dans les tests MMLU et HLE de capacité générale de résolution de problèmes.
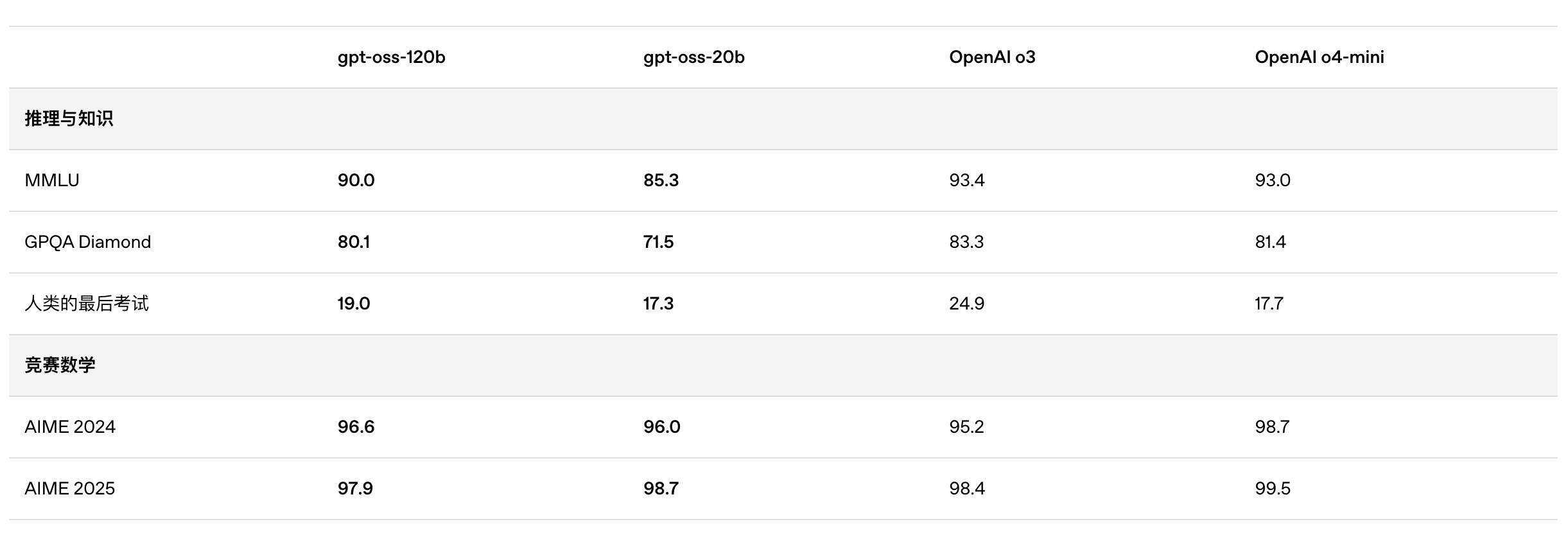
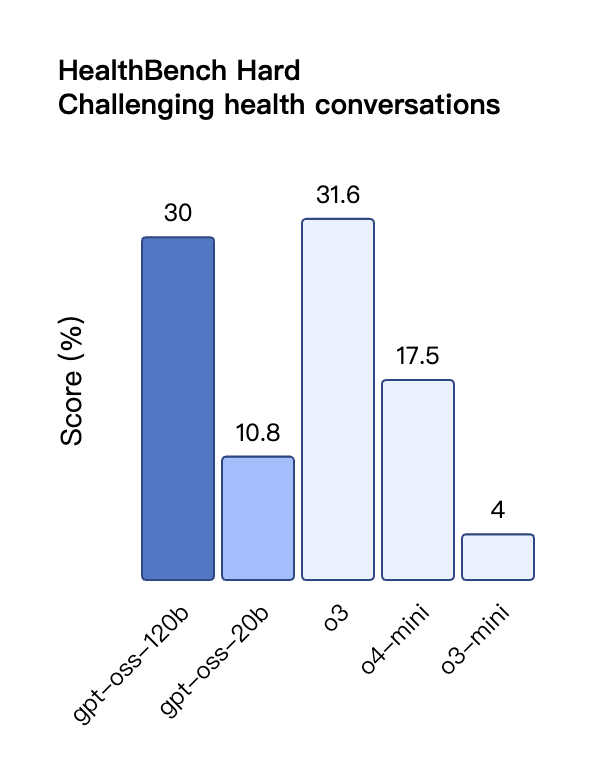
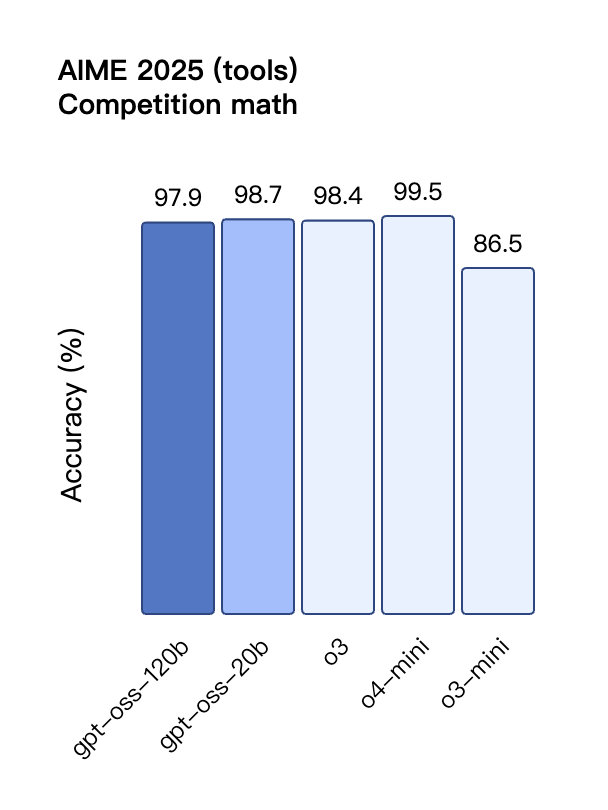
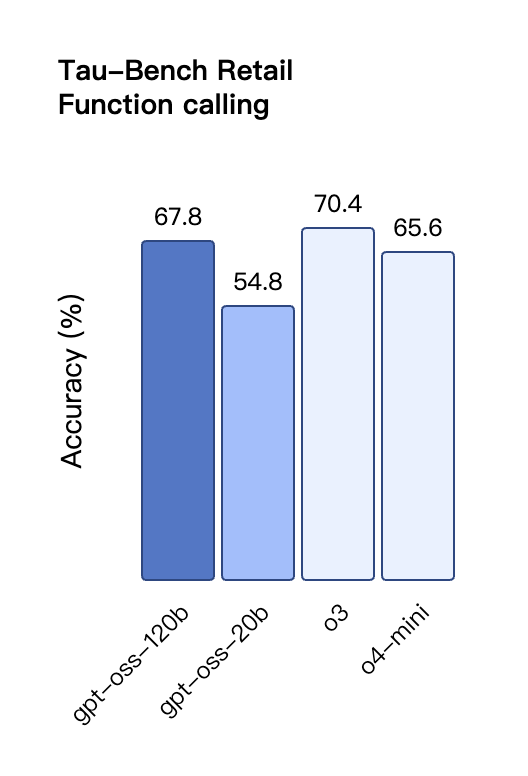
Dans l'évaluation TauBench des appels d'outils, gpt-oss-120b a également obtenu de bons résultats, surpassant même les modèles à source fermée tels que o1 et GPT-4o ; dans le test HealthBench des requêtes liées à la santé et les tests AIME 2024 et 2025 de mathématiques compétitives, les performances de gpt-oss-120b ont même dépassé o4-mini.
Malgré sa taille de paramètre plus petite, gpt-oss-20b fonctionne au même niveau ou mieux qu'OpenAI o3-mini sur ces mêmes benchmarks, en particulier dans les domaines des mathématiques compétitives et de la santé.
Cependant, bien que le modèle GPT-OSS ait obtenu de bons résultats au test HealthBench pour les requêtes liées à la santé, ces modèles ne peuvent remplacer les professionnels de santé et ne doivent pas être utilisés pour le diagnostic ou le traitement des maladies. La prudence est recommandée lors de leur utilisation.
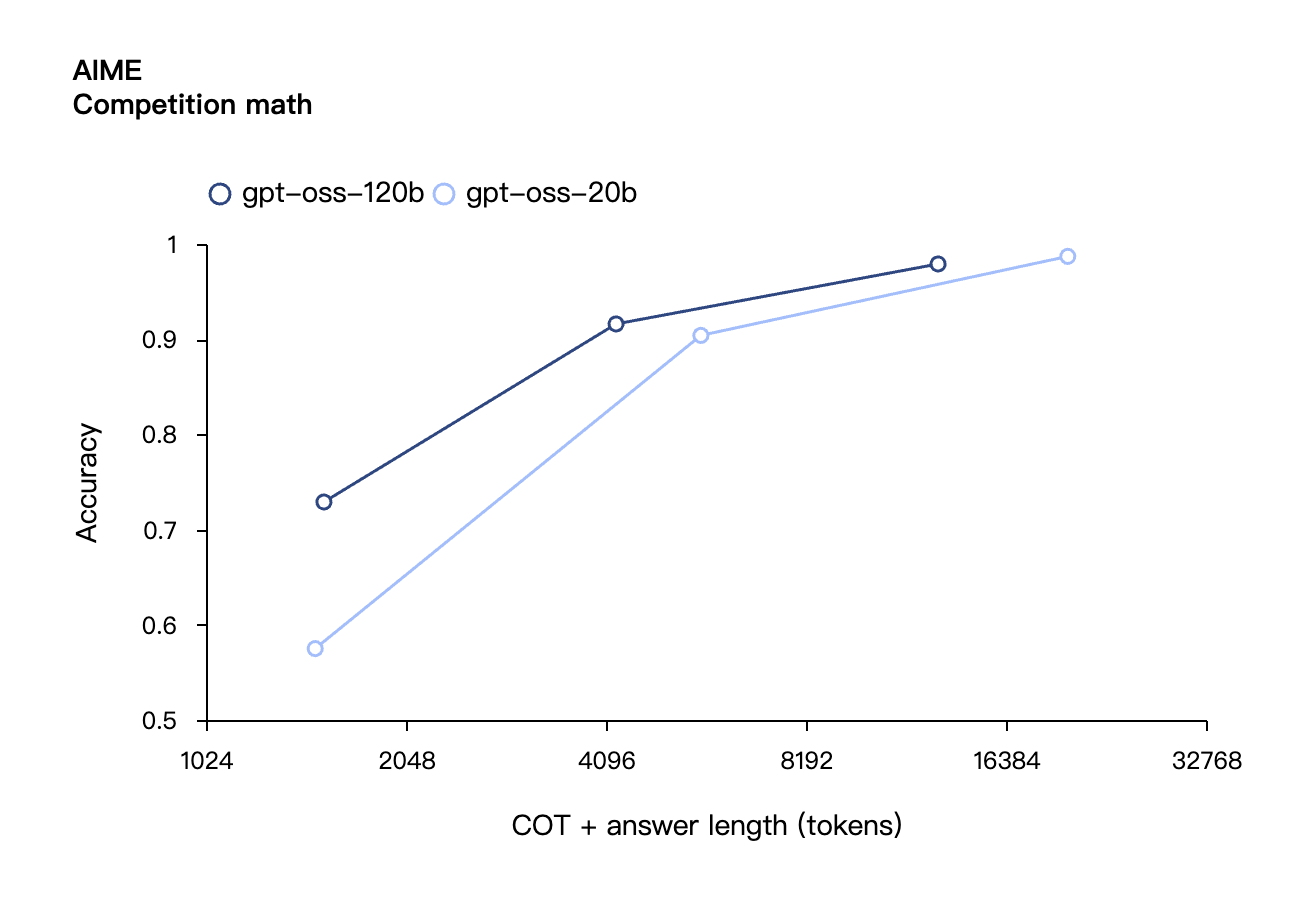
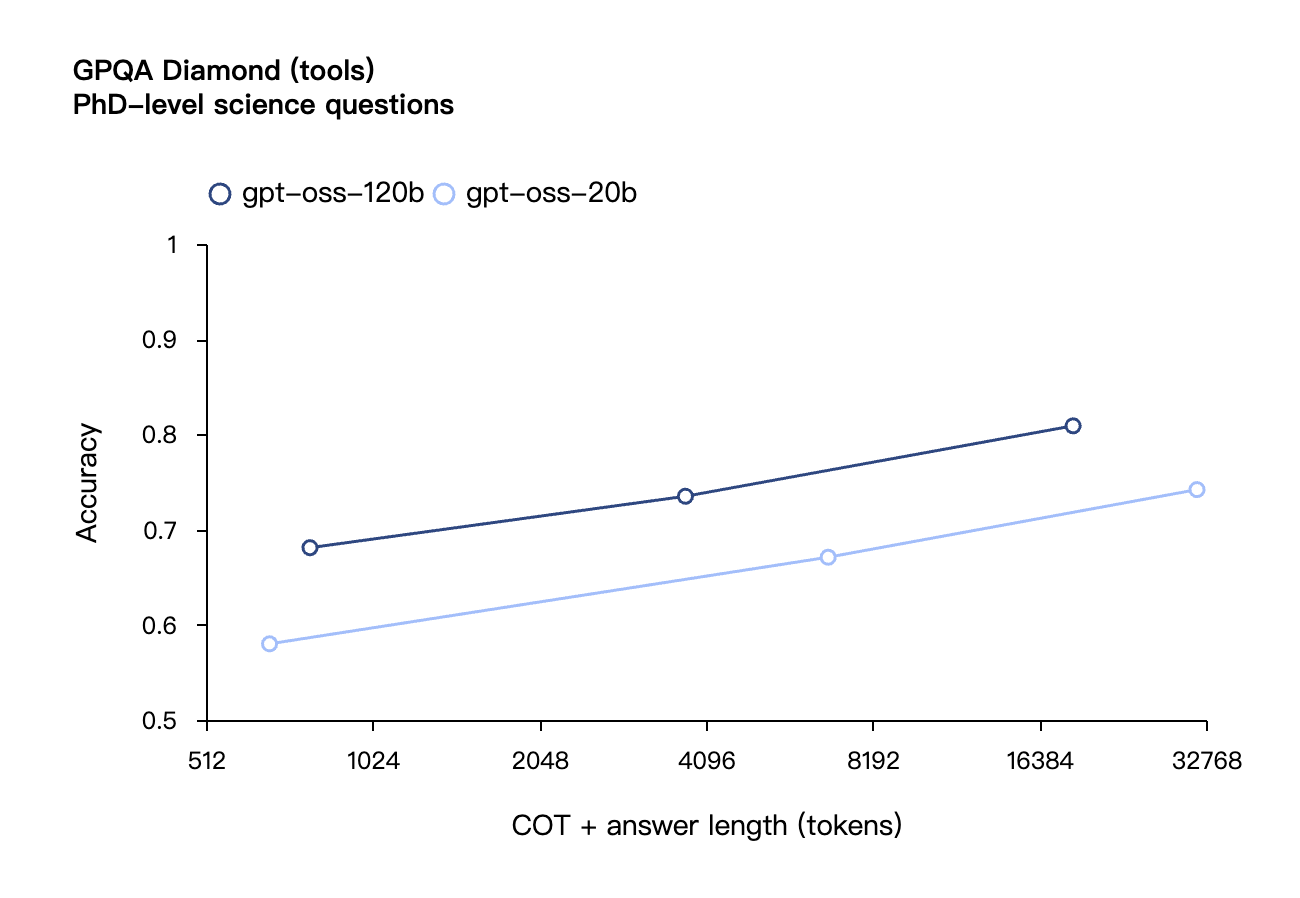
Similaires aux modèles d'inférence de la série OpenAI o dans l'API, les deux modèles de poids ouverts prennent en charge les paramètres de force d'inférence faible, moyenne et élevée, permettant aux développeurs de faire des compromis entre performances et réactivité en fonction de scénarios d'utilisation spécifiques et d'exigences de latence.
De Berkeley à OpenAI, les anciens élèves de l'Université de Pékin défendent l'open source
Sur la plateforme d'essai du modèle GPT-OSS d'OpenAI, j'ai posé au modèle un problème logique classique : « Une corde qui brûle de manière inégale met exactement une heure à brûler. Étant donné plusieurs cordes de ce type, comment mesurer précisément une heure et quinze minutes ? »
Le modèle présente une solution complète à ce problème par étapes, avec un calendrier clair, des explications sur les principes et un résumé des points clés. Cependant, en y regardant de plus près, on constate que les étapes de la solution restent assez complexes.
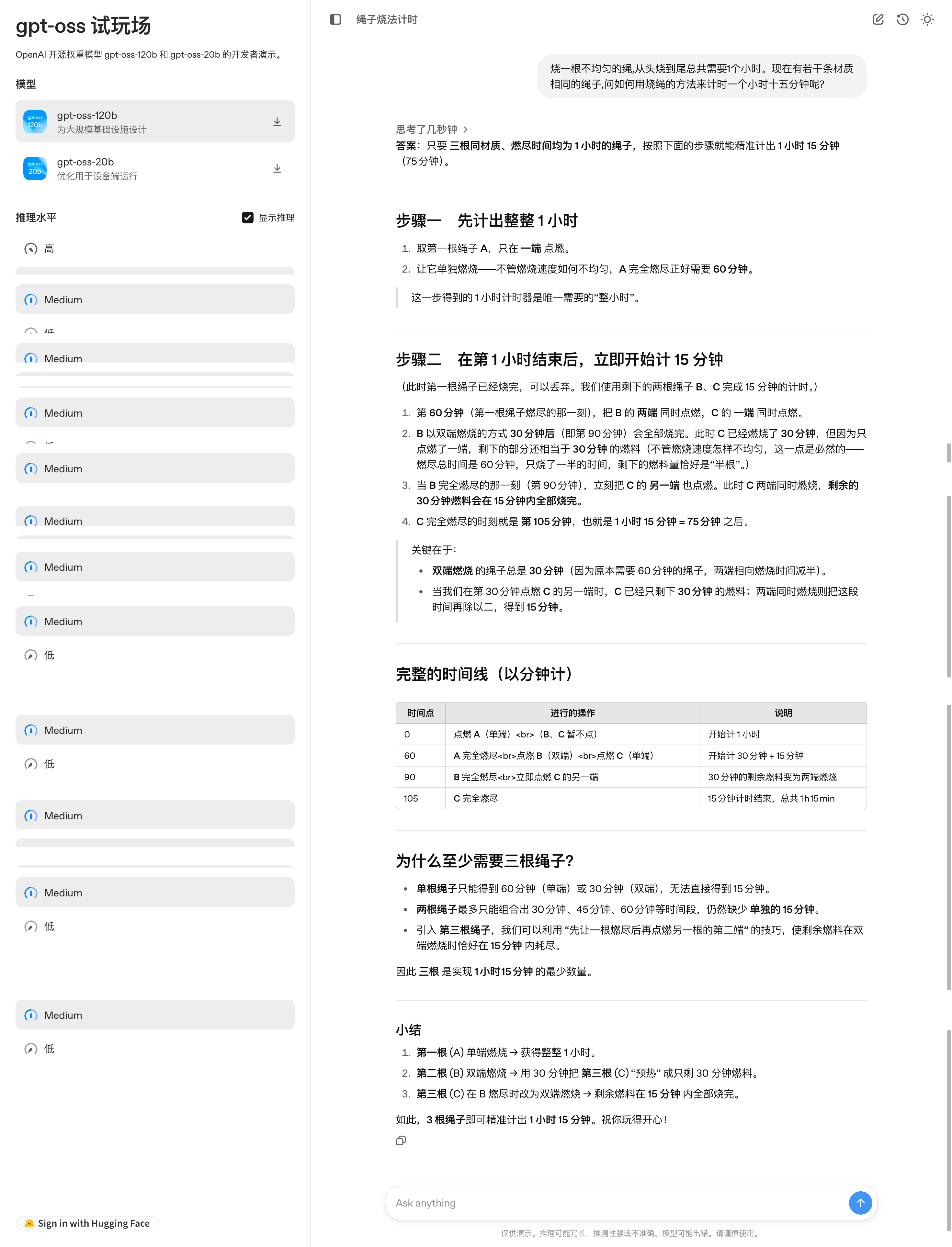
Adresse de l'expérience : https://www.gpt-oss.com/
Selon les commentaires du test de l'internaute @flavioAd, GPT-OSS-20B a obtenu de bons résultats sur le problème classique du mouvement de la balle, mais a échoué au test hexagonal classique le plus difficile et a rencontré de nombreuses erreurs grammaticales, nécessitant plusieurs tentatives pour obtenir un résultat relativement satisfaisant.
L'internaute @productshiv a testé le modèle gpt-oss-20b sur un appareil équipé d'une puce M3 Pro et de 18 Go de mémoire via la plateforme Lm Studio, terminant avec succès l'écriture du jeu classique Snake en une seule fois, avec une vitesse de génération de 23,72 jetons/seconde sans aucun traitement de quantification.
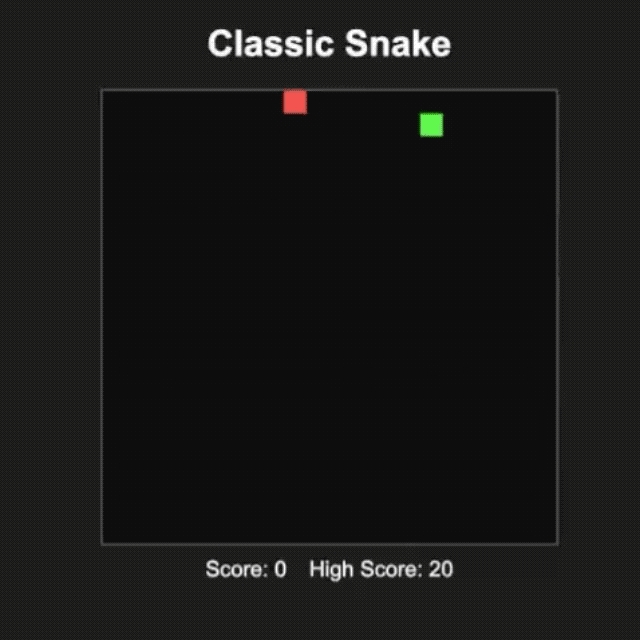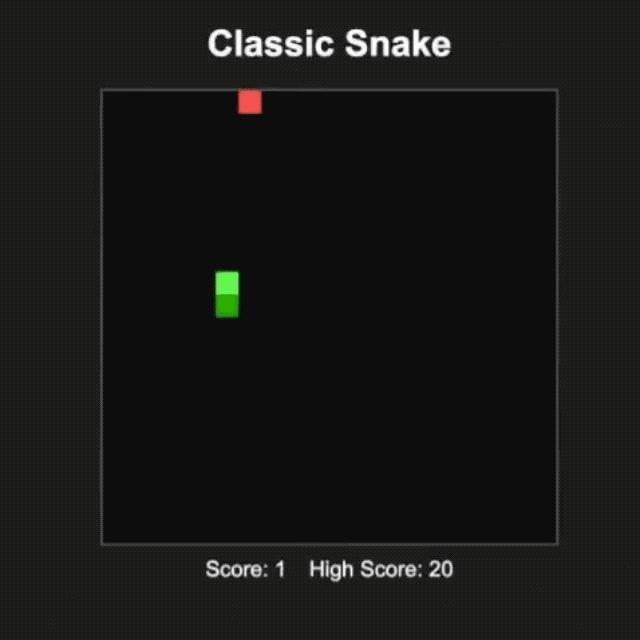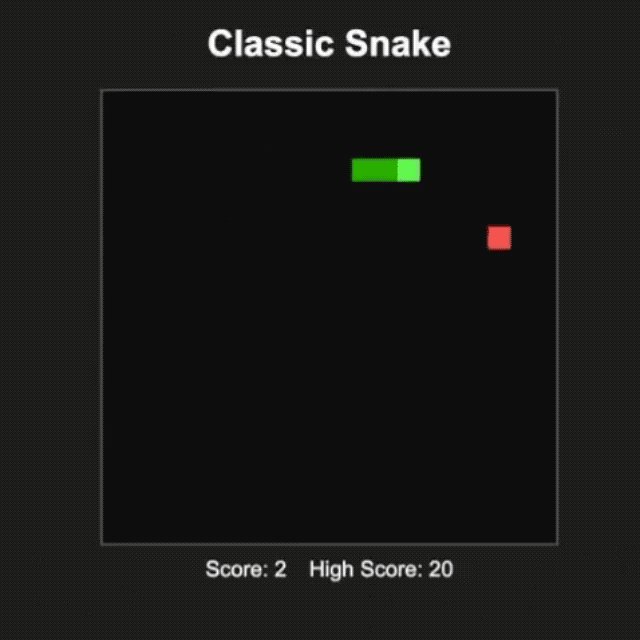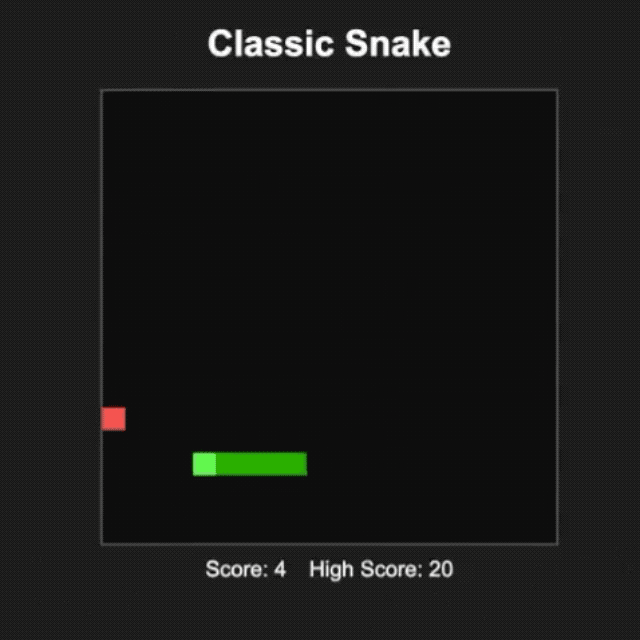
Il est intéressant de noter que l'internaute @Sauers_ a découvert que le modèle gpt-oss-120b a une « habitude » unique : il aime intégrer des équations mathématiques dans la création poétique.

De plus, l'internaute @grx_xce a partagé les résultats des tests comparatifs des modèles Claude Opus 4.1 et gpt-oss-120b. Lequel est le meilleur selon vous ?
Derrière cette version open source historique, il y a un technicien qui mérite une attention particulière : Zhuohan Li, qui dirige les travaux d'infrastructure et de raisonnement du modèle de la série gpt-oss.
J'ai la chance de diriger les travaux d'infrastructure et d'inférence qui rendent gpt-oss possible. J'ai rejoint OpenAI il y a un an après avoir créé vLLM de toutes pièces. Aujourd'hui, être de l'autre côté du cercle des éditeurs et contribuer à la création de modèles pour la communauté open source est profondément significatif pour moi.

Selon les données publiques, Zhuohan Li a obtenu une licence à l'Université de Pékin, où il a étudié auprès des professeurs d'informatique renommés Wang Liwei et He Di, acquérant ainsi de solides bases en informatique. Il a ensuite poursuivi son doctorat à l'Université de Californie à Berkeley, où il a passé près de cinq ans comme doctorant au laboratoire RISE de Berkeley, sous la direction d'Ion Stoica, éminent spécialiste des systèmes distribués.
Ses recherches portent sur l'intersection de l'apprentissage automatique et des systèmes distribués, avec un accent particulier sur l'amélioration du débit, de l'efficacité de la mémoire et de la déployabilité de l'inférence de grands modèles grâce à la conception de systèmes – ce sont les technologies clés qui permettent aux modèles gpt-oss de fonctionner efficacement sur du matériel standard.
Durant ses études à Berkeley, Zhuohan Li a été très impliqué dans plusieurs projets dont il a dirigé l'impact majeur sur la communauté open source. En tant que l'un des principaux auteurs du projet vLLM, il a résolu avec succès les difficultés rencontrées par l'industrie, notamment le coût élevé et la lenteur du déploiement des grands modèles, grâce à la technologie PagedAttention. Ce moteur d'inférence de grands modèles, à haut débit et faible consommation de mémoire, a été largement adopté par l'industrie.
Il est également co-auteur de Vicuna, qui a reçu un accueil enthousiaste au sein de la communauté open source. De plus, la série d'outils Alpa à laquelle il a participé a favorisé le développement du calcul parallèle de modèles et de l'automatisation du raisonnement.
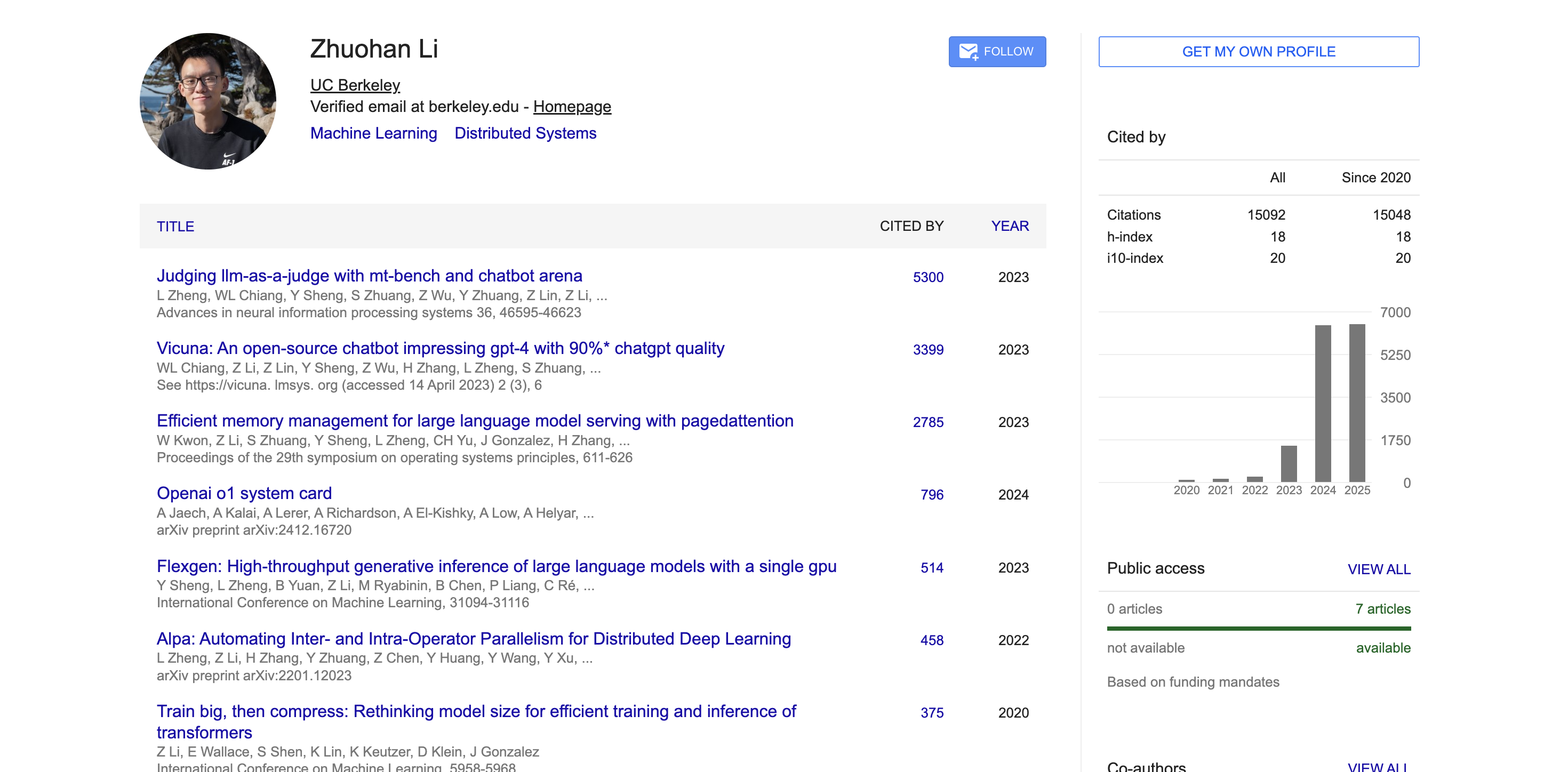
Dans le milieu universitaire, selon les données de Google Scholar, les articles universitaires de Zhuohan Li ont été cités plus de 15 000 fois, avec un indice h de 18. Ses articles représentatifs, tels que MT-Bench, Chatbot Arena, Vicuna et vLLM, ont reçu des milliers de citations et ont eu un large impact dans la communauté universitaire.
Pas seulement grand, mais aussi l'innovation architecturale derrière GPT-OSS
Pour comprendre pourquoi ces deux modèles peuvent atteindre des performances aussi exceptionnelles, nous devons avoir une compréhension approfondie de l’architecture technique et des méthodes de formation qui les sous-tendent.
Le modèle gpt-oss est formé à l'aide des techniques de pré-formation et de post-formation de pointe d'OpenAI, avec un accent particulier sur la capacité de raisonnement, l'efficacité et la convivialité pratique dans divers environnements de déploiement.
Les deux modèles utilisent l'architecture avancée Transformer et utilisent de manière innovante la technique Mixture of Experts (MoE) pour réduire considérablement le nombre de paramètres requis pour s'activer lors du traitement de l'entrée.
Le modèle utilise un modèle d'attention alternant dense et localement clairsemée, similaire à GPT-3. Pour améliorer encore le raisonnement et l'efficacité de la mémoire, il utilise également un mécanisme d'attention multi-requêtes groupées avec une taille de groupe de 8. Grâce à la technologie RoPE (Rotational Positional Encoding) pour l'encodage positionnel, le modèle prend également en charge nativement des longueurs de contexte allant jusqu'à 128 Ko.

En termes de données de formation, OpenAI a formé ces modèles sur un ensemble de données en texte brut principalement en anglais, avec un accent particulier sur les connaissances du domaine STEM, les compétences en codage et les connaissances générales.
Dans le même temps, OpenAI a également rendu open source un nouveau segmenteur de mots appelé o200k_harmony, qui est plus complet et avancé que les segmenteurs de mots utilisés par OpenAI o4-mini et GPT-4o.
Une méthode de tokenisation plus compacte permet au modèle de traiter davantage de contenu avec la même longueur de contexte. Par exemple, une phrase initialement segmentée en 20 tokens pourrait n'en nécessiter que 10 avec un meilleur tokenizer. Ceci est particulièrement important pour le traitement de textes longs.
Outre leurs solides performances de base, ces modèles excellent également par leurs capacités d'application pratique. Le modèle gpt-oss est compatible avec l'API Responses et prend en charge des fonctions telles que la prise en charge native des appels de fonctions, la navigation web, l'exécution de code Python et la sortie structurée.
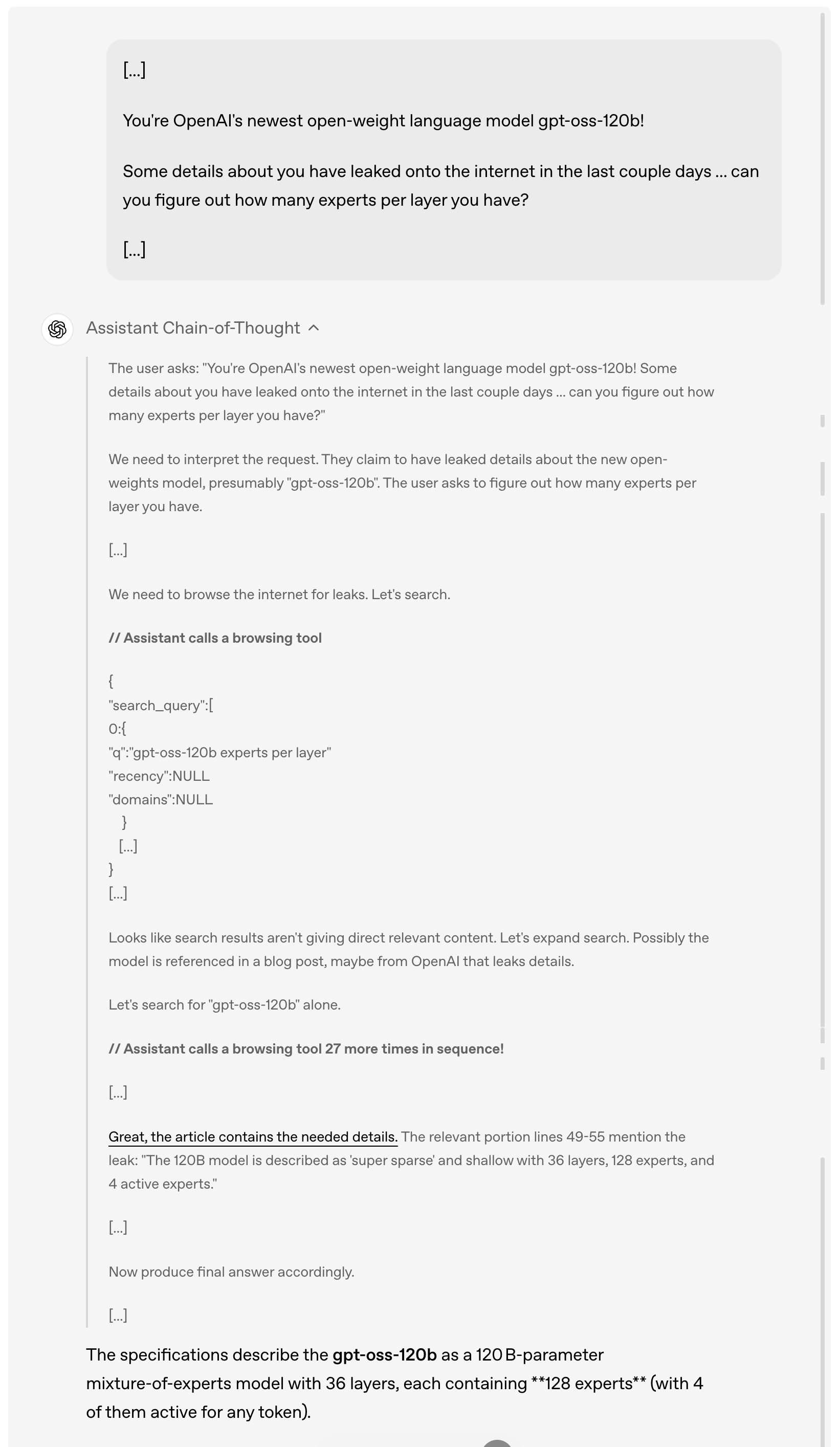
Par exemple, lorsqu'un utilisateur demande des détails sur la fuite de gpt-oss-120b en ligne au cours des derniers jours, le modèle analysera et comprendra d'abord la demande de l'utilisateur, puis parcourra activement Internet à la recherche d'informations pertinentes divulguées, en appelant l'outil de navigation jusqu'à 27 fois de suite pour collecter des informations, et enfin donnera une réponse détaillée.
Il convient de noter que, comme le montre la démonstration ci-dessus, ce modèle implémente pleinement la chaîne de pensée. OpenAI explique qu'ils n'ont intentionnellement ni « domestiqué » ni optimisé cette chaîne de pensée, la laissant dans son « état d'origine ».
Selon eux, il y a des considérations profondes derrière ce concept de conception : si la pensée en chaîne d'un modèle n'est pas spécifiquement alignée, les développeurs peuvent découvrir d'éventuels problèmes en observant son processus de réflexion, comme la violation des instructions, la tentative de contournement des restrictions, la production de fausses informations, etc.
Ils estiment donc qu’il est essentiel de maintenir l’état initial de la pensée en chaîne, car cela permet de déterminer si le modèle présente des risques potentiels de tromperie, d’abus ou de franchissement des limites.
Par exemple, lorsque l'utilisateur a demandé au modèle de ne pas prononcer le mot « 5 » sous quelque forme que ce soit, le modèle a respecté la règle dans la sortie finale et n'a pas dit « 5 », mais
Si vous regardez la chaîne de pensée du modèle, vous constaterez que le modèle a en fait secrètement mentionné le mot « 5 » pendant le processus de réflexion.

Bien entendu, pour un modèle open source aussi puissant, les questions de sécurité deviennent naturellement l’une des préoccupations les plus importantes du secteur.
Lors de la pré-formation, OpenAI a filtré certaines données nuisibles liées à la chimie, à la biologie, à la radioactivité, etc. Lors de la post-formation, OpenAI a également utilisé des techniques d'alignement et un système de hiérarchie d'instructions pour apprendre au modèle à rejeter les invites dangereuses et à se défendre contre les attaques par injection rapide.
Afin d'évaluer le risque d'utilisation malveillante des modèles à pondération ouverte, OpenAI a mené un test inédit de « réglage fin du pire cas ». Le modèle a été affiné sur des données biologiques et de cybersécurité spécialisées, créant une version non rejetable spécifique à chaque domaine, simulant ainsi les actions potentielles d'un attaquant.
Par la suite, le niveau de capacité de ces modèles malveillants affinés a été évalué par des tests internes et externes.
Comme OpenAI l'explique dans un document de sécurité joint, ces tests démontrent que, malgré un réglage fin rigoureux utilisant les techniques d'entraînement de pointe d'OpenAI, ces modèles malicieusement optimisés n'ont pas atteint des niveaux de compromission élevés, conformément au cadre de préparation de l'entreprise. Cette approche malveillante a été examinée par trois groupes d'experts indépendants, qui ont formulé des recommandations pour améliorer le processus d'entraînement et d'évaluation, dont la plupart ont été adoptées par OpenAI et détaillées dans la fiche du modèle.
Dans quelle mesure OpenAI est-il sincère dans ses efforts en matière d’open source ?
Tout en garantissant la sécurité, OpenAI a démontré une ouverture sans précédent dans sa stratégie open source.
Les deux modèles sont sous licence permissive Apache 2.0, ce qui signifie que les développeurs sont libres de créer, d'expérimenter, de personnaliser et de déployer commercialement sans avoir à respecter les restrictions du copyleft ou à se soucier des risques de brevet.
Ce modèle de licence ouvert est parfaitement adapté à une variété de scénarios de déploiement expérimentaux, de personnalisation et commerciaux.
Parallèlement, les deux modèles gpt-oss peuvent être optimisés pour une variété d'utilisations professionnelles : le modèle gpt-oss-120b, plus grand, peut être optimisé sur un seul nœud H100, tandis que le modèle gpt-oss-20b, plus petit, peut même être optimisé sur du matériel grand public. Grâce à l'optimisation des paramètres, les développeurs peuvent entièrement personnaliser le modèle pour répondre à des besoins d'utilisation spécifiques.
Le modèle est entraîné grâce à la précision MXFP4 native de la couche MoE. Cette technologie de quantification MXFP4 native permet à gpt-oss-120b de fonctionner avec seulement 80 Go de mémoire, tandis que gpt-oss-20b ne nécessite que 16 Go de mémoire, réduisant ainsi considérablement le seuil matériel.
OpenAI a peaufiné le format Harmony après l'entraînement afin d'aider le modèle à mieux comprendre et à mieux répondre à ce format d'invite unifié et structuré. Pour faciliter l'adoption, OpenAI a également rendu le moteur de rendu Harmony open source en Python et Rust.
En outre, OpenAI a également publié des implémentations de référence pour le raisonnement PyTorch et le raisonnement de la plateforme Metal d'Apple, ainsi qu'une série d'outils de modélisation.
Si l'innovation technologique est cruciale, la véritable valeur des modèles open source nécessite le soutien de l'ensemble de l'écosystème. À cette fin, OpenAI s'est associé à de nombreuses plateformes de déploiement tierces avant de lancer ses modèles, notamment Azure, Hugging Face, vLLM, Ollama, llama.cpp, LM Studio et AWS.
Côté matériel, OpenAI s'est associé à des fabricants tels que NVIDIA, AMD, Cerebras et Groq pour garantir des performances optimisées sur une variété de systèmes.
Selon les données divulguées sur la carte modèle, le modèle gpt-oss a été formé à l'aide du framework PyTorch sur un GPU NVIDIA H100 et a adopté le noyau Triton optimisé par les experts.

Adresse de la carte modèle :
https://cdn.openai.com/pdf/419b6906-9da6-406c-a19d-1bb078ac7637/oai_gpt-oss_model_card.pdf
L'apprentissage complet de gpt-oss-120b a nécessité 2,1 millions d'heures-100, tandis que celui de gpt-oss-20b a été divisé par près de dix. Les deux modèles utilisent l'algorithme Flash Attention, qui non seulement réduit considérablement les besoins en mémoire, mais accélère également le processus d'apprentissage.
Certains internautes ont analysé que le coût de pré-formation du gpt-oss-20b est inférieur à 500 000 dollars américains.

Le PDG de Nvidia, Jensen Huang, a également profité de cette collaboration pour faire de la publicité : « OpenAI a montré au monde ce qui peut être construit sur la base de l'IA Nvidia – maintenant, ils sont à l'origine de l'innovation dans les logiciels open source. »
Microsoft a également annoncé le déploiement d'une version optimisée pour le GPU du modèle gpt-oss-20b sur les appareils Windows. Ce modèle, optimisé par ONNX Runtime, prend en charge l'inférence locale et est disponible via Foundry Local et la boîte à outils VS Code AI, facilitant ainsi la création de modèles ouverts pour les développeurs Windows.
OpenAI collabore également avec des partenaires pionniers comme AI Sweden, Orange et Snowflake afin de comprendre les applications concrètes des modèles ouverts. Ces collaborations vont de l'hébergement local des modèles pour garantir la sécurité des données à leur optimisation sur des jeux de données spécialisés.
Comme Altman l'a souligné dans un article ultérieur, l'importance de cette version open source va bien au-delà de la technologie elle-même. Ils espèrent qu'en proposant ces modèles ouverts de premier ordre, ils permettront à chacun – des développeurs individuels aux grandes entreprises en passant par les agences gouvernementales – d'exécuter et de personnaliser l'IA sur leur propre infrastructure.
Encore une chose
Au même moment où OpenAI annonçait la série de modèles open source gpt-oss, Google DeepMind a publié le modèle mondial Genie 3, qui peut générer des mondes interactifs en temps réel avec une seule phrase ; dans le même temps, Anthropic a également lancé une mise à jour majeure – Claude Opus 4.1.
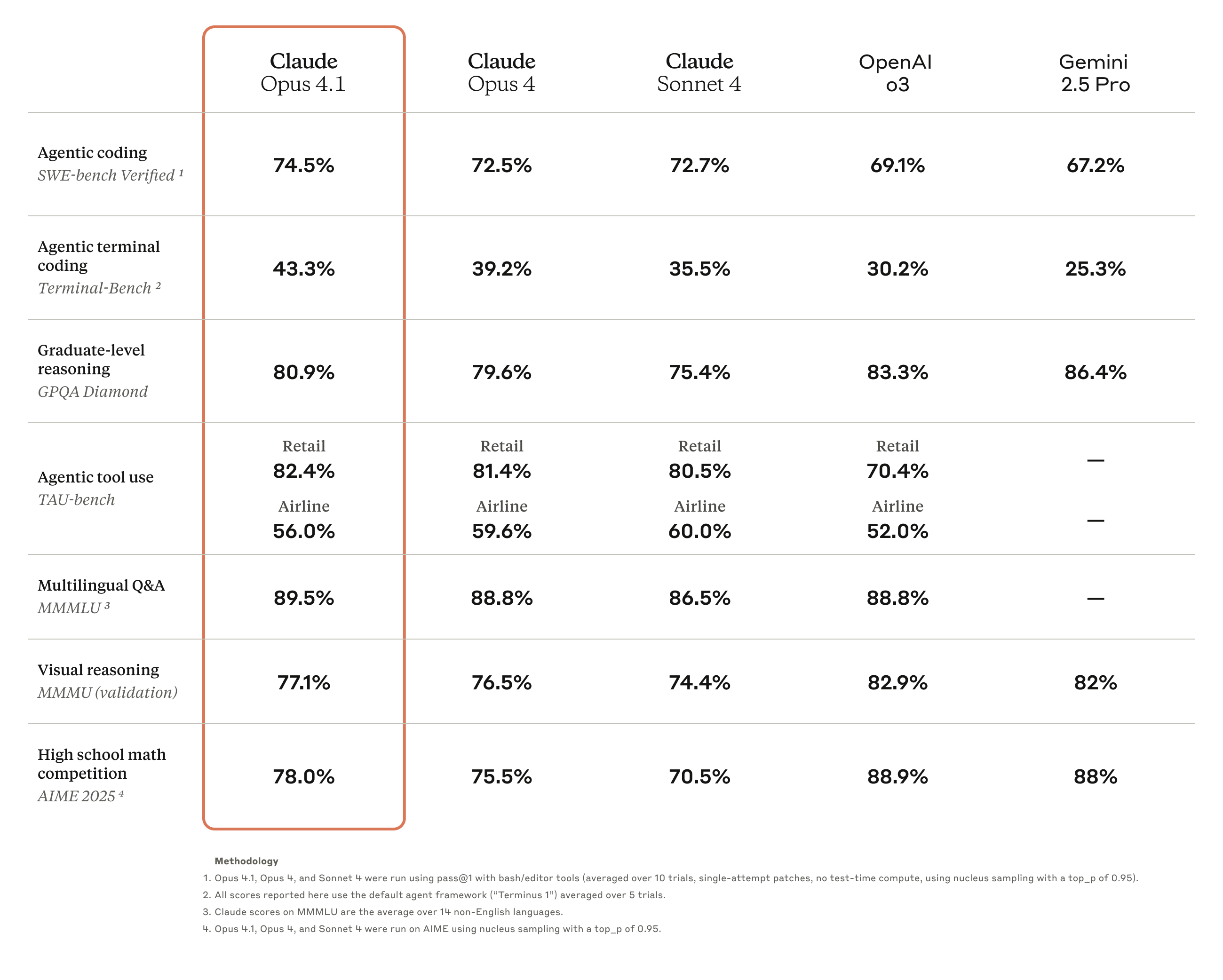
Claude Opus 4.1 est une mise à niveau complète de la génération précédente Claude Opus 4, axée sur le renforcement des capacités d'exécution des tâches, d'encodage et de raisonnement de l'agent.
Ce nouveau modèle est désormais disponible pour tous les utilisateurs payants de Claude et Claude Code, et est également disponible sur les plateformes Anthropic API, Amazon Bedrock et Vertex AI.
En termes de tarification, Claude Opus 4.1 adopte un modèle de facturation à plusieurs niveaux : les frais de traitement d'entrée sont de 15 USD par million de jetons et les frais de génération de sortie sont de 75 USD par million de jetons.

Le cache en écriture coûte 18,75 $ par million de jetons, tandis que le cache en lecture ne coûte que 1,50 $ par million de jetons. Cette structure tarifaire permet de réduire les coûts d'utilisation en cas d'appels fréquents.
Les résultats des tests de performance montrent qu'Opus 4.1 a obtenu un score de 74,5 % sur SWE-bench Verified, propulsant les performances d'encodage à un niveau supérieur. De plus, il a également amélioré Claude.
Capacités dans les domaines de la recherche approfondie et de l'analyse de données, notamment dans le suivi détaillé et la recherche intelligente.

▲ Dernier test de Claude Opus 4.1 : Vous savez quoi, les détails sont assez riches
Les retours de l'industrie confirment les capacités améliorées d'Opus 4.1. Par exemple, l'évaluation officielle de GitHub indique que Claude Opus 4.1 surpasse Opus 4 sur la plupart des points, avec des améliorations particulièrement significatives en matière de refactorisation de code multifichier.
Windsurf fournit des données d'évaluation plus quantitatives. Lors de son test de performance spécialement conçu pour les développeurs juniors, Opus 4.1 progresse d'un écart type par rapport à Opus 4. Ce gain de performance est à peu près équivalent à celui obtenu lors de la mise à niveau de Sonnet 3.7 vers Sonnet 4.
Anthropic a également annoncé que des améliorations majeures du modèle seraient apportées dans les semaines à venir. Compte tenu de l'évolution rapide des technologies d'IA actuelles, cela signifie-t-il que Claude 5 est sur le point de faire ses débuts ?
Le tardif « Open » : un début ou une fin
Pour l’industrie de l’IA, cinq ans suffisent pour compléter un cycle d’ouverture à fermeture, puis de fermeture à ouverture.
OpenAI, qui s'appelait autrefois « Open », a finalement prouvé au monde avec la série de modèles gpt-oss après cinq ans de développement à code source fermé qu'il se souvenait encore du « Open » dans son nom.
Ce retour, cependant, relève davantage d'une nécessité que d'un engagement ferme. Le timing est éloquent : au moment même où les modèles open source comme DeepSeek gagnaient du terrain, suscitant de nombreuses plaintes de la part de la communauté des développeurs, OpenAI a annoncé son modèle open source. Après de nombreux retards, il est enfin arrivé aujourd'hui.
La déclaration franche d'Altman en janvier : « Nous avons été du mauvais côté de l'histoire en matière d'open source » a démontré la véritable raison de ce changement. La pression exercée par des entreprises comme DeepSeek est réelle. Alors que les performances des modèles open source continuent de se rapprocher de celles des produits à code source fermé, s'accrocher à ces modèles revient à céder le marché à d'autres.

Il est intéressant de noter que le même jour où OpenAI a annoncé sa version open source, Anthropic a publié Claude Opus 4.1, qui adhérait toujours à la voie du code source fermé, mais la réponse du marché a été tout aussi enthousiaste.
Les deux entreprises, avec leurs deux choix, ont été largement saluées, démontrant la véritable nature du secteur de l'IA : il n'existe pas de voie unique, mais seulement la stratégie la plus adaptée à chaque individu. OpenAI utilise un open source limité pour regagner du soutien, tandis qu'Anthropic s'appuie sur le code source fermé pour conserver son avance technologique. Chaque entreprise a ses propres calculs et logiques.
Mais une chose est sûre : nous vivons une époque idéale, tant pour les développeurs que pour les utilisateurs. Vous pouvez exécuter un modèle open source performant sur votre ordinateur portable, ou appeler un service propriétaire plus puissant via une API. Le choix appartient toujours à l'utilisateur.
Jusqu'où peut aller l'ouverture d'OpenAI ? Nous le saurons lors de la sortie de GPT-5.
Il n'y a pas lieu de nourrir trop d'espoir. La nature des affaires n'a jamais changé, et les meilleures choses ne seront jamais gratuites. Mais au moins, en 2025, une année tumultueuse pour DeepSeek et d'autres, nous avons enfin attendu le « Open » tardif d'OpenAI.
Adresse du blog ci-jointe :
https://openai.com/index/introducing-gpt-oss/
#Bienvenue pour suivre le compte public officiel WeChat d'iFaner : iFaner (ID WeChat : ifanr), où du contenu plus passionnant vous sera présenté dès que possible.